
Соединения (Joins) являются одними из наиболее фундаментальных преобразований в типичной процедуре обработки данных.
Оператор Join позволяет коррелировать, обогащать и фильтровать два входных набора (пакета / блока) данных (Datasets).Обычно два входных набора данных классифицируются как левый и правый на основе их расположения по отношению к пункту/оператору Join.По сути, соединение работает на основе условного оператора, который включает логическое выражение, основанное на сравнении между левым ключом, полученным из записи левого блока данных, и правым ключом, полученным из записи правого комплекса данных. Левый и правый ключи обычно называются соединительными ключами (Join Keys). Логическое выражение оценивается для каждой пары записей из двух входных наборов данных. На основе логического вывода, полученного в результате оценки выражения, условный оператор включает условие выбора — для отбора либо одной из записей (из пары), либо комбинированной записи (из записей, образующих пару).Применение соединений к перекошенным наборам данных: блок данных считается перекошенным для операции соединения, если распределение соединительных ключей по записям в наборе перекошено в сторону их небольшого подмножества. Например, когда 80% записей в блоке данных вносят вклад только в 20% соединительных ключей.
Воздействие перекошенных наборов данных на соединения: перекошенные пакеты данных, если не обрабатывать их должным образом, могут привести к появлению отсечек на этапе соединения (для подробной информации вы можете ознакомиться с этой статьёй). Это снижает общую эффективность выполнения задач в Spark. Кроме того, перекошенные комплексы данных могут вызвать перерасход памяти на некоторых исполнителях (Executors), что, в свою очередь, может привести к полному сбою выполнения задачи Spark. Поэтому так важно своевременно выявлять и решать проблемы на этапах, основанных на соединениях (Stages), куда обычно вовлечены самые большие перекошенные наборы данных.
Методы работы с перекошенными соединениями: До этого момента вы наверняка уже встречали много разрозненной информации о том, как работать с перекошенными соединениями (Skewed Joins), но в основном — в ней акцентируют внимание лишь на одной или двух методиках и при этом очень кратко описывают все подробности и ограничения. С учётом такого поверхностного описания в общедоступных источниках, данная статья является попыткой предоставить вам полный и исчерпывающий список из пяти важных техник для работы с перекошенными соединениями во всех возможных сценариях.
Транслируемое хеш-соединение
При транслируемом хеш-соединении (Broadcast Hash Join) исполнителю передаётся либо левый, либо правый входной набор данных. Транслируемое хеш-соединение невосприимчиво к перекошенным входным пакетам данных. Это связано с тем, что разбиение в соответствии с соединительными ключами не является обязательным для левого и правого блока данных. В данном случае один из наборов данных будет транслироваться, а другой — может быть соответствующим образом разделён для достижения равномерного параллелизма при любом требуемом масштабе.
Spark выбирает транслируемое хеш-соединение на основе типа соединения и размера входного набора(-ров) данных. Если тип соединения благоприятен, а размер транслируемого блока остаётся ниже настраиваемого предела (
spark.sql.autoBroadcastJoinThreshold (по умолчанию 10 МБ)), то для выполнения соединения выбирается транслируемое хеш-соединение. Поэтому если вы увеличите предел spark.sql.autoBroadcastJoinThreshold до большего значения, то будет выбрано только транслируемое хеш-соединение.Можно также использовать транслируемые подсказки (hints) в SQL-запросах на любом из входных наборов данных на основе типа соединения, чтобы заставить Spark использовать транслируемое хеш-соединение независимо от значения spark.sql.autoBroadcastJoinThreshold.Поэтому, если есть возможность выделить память для исполнителей, для выполнения более быстрого перекошенного соединения — следует использовать метод транслируемого хеш-соединения.Вот несколько важных моментов, которые необходимо учесть при использовании метода транслируемого хеш-соединения:
- Метод неприменим для полного внешнего соединения (Full Outer Join).
- Для внутреннего соединения (Inner Join) память исполнителя должна вмещать, по крайней мере, меньший из двух входных наборов данных.
- Для левого, анти-левого и полу-левого соединений (Left, Left Anti, Left Semi Join) память исполнителя должна вмещать правый входной набор данных, так как правый должен транслироваться.
- Для правого, анти-правого и полу-правого соединений (Right, Right Anti, Right Semi Join) память исполнителя должна вмещать левый входной набор данных, так как левый должен транслироваться.
- Также существует значительная потребность в доступной памяти для исполнителей в зависимости от размера транслируемого набора данных.
Итеративное транслируемое соединение
Техника итеративной трансляции (Iterative Broadcast) — это адаптация соединения транслируемого хеша для работы с большими наборами перекошенных данных. Она полезна в ситуациях, когда ни один из входных блоков данных не может быть передан исполнителям. Это может произойти из-за ограничений на память у исполнителей.
Чтобы справиться с такими сценариями, техника итеративной трансляции разбивает один из наборов входных данных (предпочтительно меньший) на один или несколько более мелких фрагментов, обеспечивая тем самым простоту трансляции каждого из полученных фрагментов. Затем эти меньшие куски соединяются один за другим с другими не разбитыми пакетами входных данных с помощью стандартного метода соединения транслируемого хеша. Выходы из этих множественных соединений в конечном итоге объединяются вместе с помощью оператора объединения
Union для получения конечного результата.Один из способов разбиения комплекса данных на более мелкие фрагменты заключается в присвоении случайного числа из желаемого количества фрагментов каждой записи набора данных в новом добавленном столбце
chunkId. Как только этот новый столбец готов, запускается цикл for для итерации номеров чанков. Для каждой итерации записи сначала фильтруются по столбцу chunkId, соответствующему номеру чанка текущей итерации. Затем с помощью стандартного метода транслируемого хеш-соединения и для получения частично соединённого вывода — отфильтрованный набор данных в каждой итерации соединяется с другим не разбитым входным комплексом. Далее, полученный, частично соединённый вывод объединяется с предыдущим, частично соединённым выводом. После выхода из цикла получается общий результат операции соединения двух исходных комплектов данных.Эта техника показана ниже на рисунке 1:
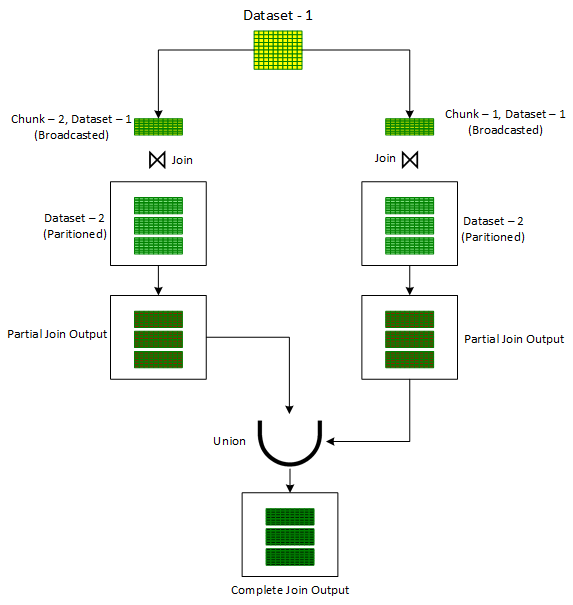
Однако, в отличие от транслируемого хеш-соединения, итеративное транслируемое соединение ограничено только внутренними соединениями. Оно не может обрабатывать полные внешние, левые и правые соединения. Однако для внутренних соединений оно может обрабатывать перекос в обоих наборах данных.
Соединение по методу «засоленного» сортировочного слияния
Прим. переводчика: В Apache Spark «соль» (Salt) добавляет случайные значения для равномерного распределения данных по разделам.Подход сортировочного слияния (Sort Merge) очень надёжен при обработке соединений в случае нехватки ресурсов. Продолжая эту идею — так называемая «засоленная» версия сортировочного слияния может очень эффективно применяться в тех случаях, когда необходимо соединить большой перекошенный набор данных с небольшим и неперекошенным блоком данных, но есть некоторые ограничения по памяти у исполнителя.
Кроме того, засоленная версия сортировочного слияния (Salted Sort Merge) может также использоваться для выполнения левого соединения небольших и неперекошенных наборов данных с большим и перекошенным пакетом данных, что невозможно при использовании транслируемого хеш-соединения, даже если меньший блок может быть передан исполнителям. Однако, чтобы убедиться, что Spark выберет именно соединение по методу сортировочного слияния, необходимо отключить подход транслируемого хеш-соединения. Это можно сделать, установив для параметра
spark.sql.autoBroadcastJoinThreshold значение -1.Работа соединения на основе засоленного сортировочного слияния в некотором роде похожа на транслируемое хеш-соединение. В один из перекошенных входных пакетов данных вводится дополнительный столбец
salt key. После этого для каждой записи случайным образом назначается число из выбранного диапазона значений «солевых ключей» для столбца salt key.После засолки перекошенного набора входных данных запускается цикл перебора значений солевого ключа в выбранном диапазоне. Для каждого значения солевого ключа, итерируемого в цикле, засоленный набор входных данных сначала фильтруется для итерируемого значения солевого ключа и после фильтрации — засоленный и уже отфильтрованный комплект входных данных объединяется с другим незасоленным блоком для получения частичного объединённого вывода. Для получения окончательного объединённого вывода все частично объединённые выводы объединяются вместе с помощью оператора объединения
Union.Для засоленного сортировочного слияния существует также и альтернативный подход. При его использовании для каждого значения солевого ключа, итерируемого в цикле, второй неискажённый входной набор данных обогащается текущим итерируемым значением ключа соли путём повторения того же значения в новом столбце со значением «соль»
salt для получения частичного обогащённого солью пакетом данных. Все эти частично обогащённые наборы данных объединяются с помощью оператора объединения Union, чтобы получить комбинированную версию второго неискажённого блока данных, обогащённого солью. После этого первый перекошенный засоленный набор данных объединяется со вторым обогащённым солью пакетом данных для получения окончательного объединённого результата.Этот подход показан ниже на рисунке 2:
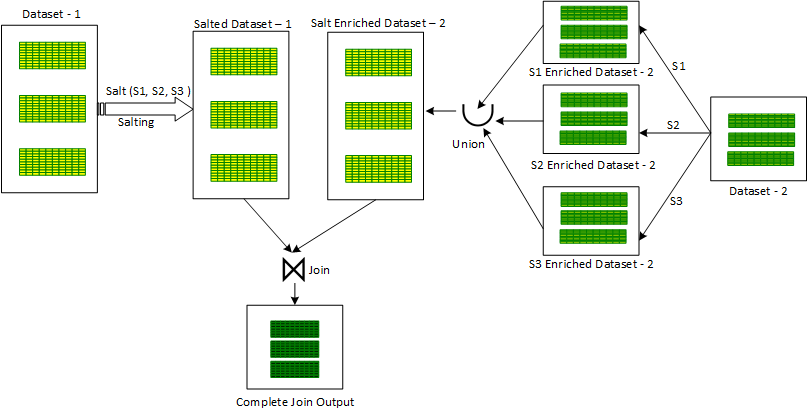
Засоленное сортировочное слияние также имеет ещё один альтернативный подход. В этом подходе после засолки перекошенного входного набора данных дополнительным столбцом «солевого ключа» в несолёный и неперекошенный блок данных также вводится столбец «соли». Колонка
salt содержит фиксированное значение (по всем записям), равное массиву, составленному из всех значений солевых ключей в ранее выбранном диапазоне. Затем этот комплекс взрывается по столбцу salt. Взорванный пакет данных затем объединяется с предыдущим солёным перекошенным входным набором данных с дополнительным условием объединения по равенству salt и salt key для получения окончательного объединённого результата.Соединение на основе засоленного сортировочного слияния не может обрабатывать полное внешнее соединение. Кроме того, оно не может обрабатывать перекос в обоих входных блоках данных. Оно может обрабатывать перекос только в левом наборе данных, в категории для левого (анти-левого и полу-левого) соединений. Аналогично — оно также может обрабатывать перекос только в правом наборе данных, в категории правых соединений.
AQE (Адаптивное выполнение запросов)
AQE — это пакет средств для оптимизации работы среды выполнения, который теперь включён по умолчанию, начиная с версии Spark 3.0. Одной из ключевых особенностей этого пакета является возможность автоматической оптимизации объединений для перекошенных блоков данных.
AQE выполняет эту оптимизацию, как правило, для соединений сортировочного слияния перекошенного набора данных с неперекошенным комплектом данных. AQE работает на этапе разделения в соединениях сортировочного слияния, где два входных комплекта данных сначала разделяются на основе соответствующего соединительного ключа. После записи блоков перемешивания в MapTasks во время разбиения механизм исполнения Spark (Spark Execution Engine) получает статистику о размере каждого перемешанного раздела. С помощью этих статистических данных, полученных от механизма исполнения и в сочетании с определёнными настраиваемыми параметрами, AQE может определить — являются ли определённые разделы перекошенными или нет. В случае если определённые разделы признаны перекошенными — AQE разбивает эти разделы на более мелкие. Это разбиение контролируется комплексом настраиваемых параметров. Меньшие разделы, полученные в результате разбиения большего перекошенного раздела, затем соединяются с копией соответствующего раздела другого неперекошенного входного блока.
Процесс показан ниже на рисунке 3:
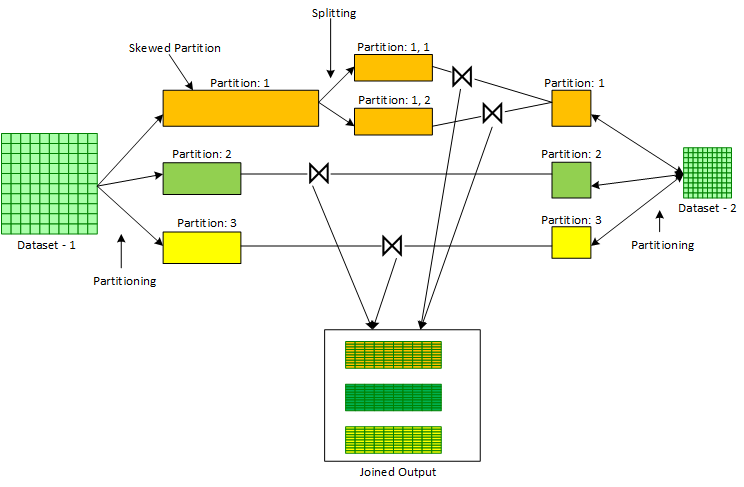
Ниже также будут перечислены параметры конфигурации, которые влияют на функцию оптимизации перекошенного соединения в AQE:
spark.sql.adaptive.skewJoin.enabled: Этот логический параметр определяет, включена или выключена оптимизация перекошенного соединения. Значение по умолчанию — true.spark.sql.adaptive.skewJoin.skewedPartitionFactor: Этот целочисленный параметр управляет интерпретацией перекошенного раздела. Значение по умолчанию равно 5.spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes: Этот параметр в мегабайтах также управляет интерпретацией перекошенного раздела. Значение по умолчанию равно 256 MB.Раздел считается перекошенным, если оба параметра (
partition size (размер раздела) > skewedPartitionFactor * median partition size (медианный размер раздела)) и (partition size > skewedPartitionThresholdInBytes) соответствуют действительности.AQE, такие как транслируемые хеш-соединения и соединения по методу засоленного сортировочного слияния — не могут обрабатывать полные внешние соединения. Кроме того, они не могут обрабатывать перекосы в обоих входных наборах данных. Поэтому, как и в случае с соединениями по методу засоленного сортировочного слияния — AQE может обрабатывать перекос только в левом блоке данных, в категории левых (анти-левых и полу-левых) соединений и перекос в правом наборе данных, в категории правых соединений.
Транслируемое соединение по методу карт разделов
Транслируемое соединение по методу карт разделов (Broadcast MapPartitions Join) — это единственный механизм по ускорению перекошенного полного внешнего соединения, между большим перекошенным и меньшим неперекошенным наборами данных. В этом подходе меньший из двух входных наборов данных транслируется исполнителям, а логика соединения вручную вводится в преобразовании карт разделов, которое вызывается на большем комплексе данных без трансляции.
Хотя транслируемое соединение по методу карт разделов поддерживает все типы соединений и может обрабатывать перекос в любом или обоих наборах данных, единственным ограничением является то, что оно требует значительного объёма памяти у исполнителей. Большая память исполнителя требуется для трансляции одного из меньших входных блоков данных, а также для поддержки промежуточного сбора в памяти для обеспечения ручного соединения.Надеюсь, что эта статья дала вам хорошее представление об обработке перекошенных соединений в ваших приложениях Spark. Основываясь на полученных знаниях, я рекомендую вам рассмотреть к использованию один из перечисленных выше вариантов, как только вы столкнётесь с перегрузками или перерасходом памяти на этапах соединения в ваших приложениях Spark.
Если вы хотите получить части кода, связанные с каждым из методов, вы можете связаться с автором на LinkedIn.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
