
Прим. перев.: Сотрудники всемирно известного сервиса Tinder недавно поделились некоторыми техническими деталями миграции своей инфраструктуры на Kubernetes. Процесс занял почти два года и вылился в запуск на K8s весьма масштабной платформы, состоящей из 200 сервисов, размещённых на 48 тысячах контейнеров. С какими интересными сложностями столкнулись инженеры Tinder и к каким результатам пришли — читайте в этом переводе.

Почти два года назад Tinder решил перевести свою платформу на Kubernetes. Kubernetes позволил бы команде Tinder провести контейнеризацию и перейти на эксплуатацию с минимальными усилиями посредством неизменного развертывания (immutable deployment). В этом случае сборка приложений, их деплой и сама инфраструктура были бы однозначно определены кодом.
Также мы искали решение проблемы с масштабируемостью и стабильностью. Когда масштабирование приобрело критическое значение, нам часто приходилось по несколько минут ждать запуска новых экземпляров EC2. Поэтому очень привлекательной для нас стала идея запуска контейнеров и начала обслуживания трафика за секунды вместо минут.
Процесс оказался непростым. Во время миграции, в начале 2019 года, кластер Kubernetes достиг критической массы и мы начали сталкиваться с различными проблемами из-за объёма трафика, размера кластера и DNS. В этом путешествии мы решили массу интересных задач, связанных с переносом 200 сервисов и обслуживанием кластера Kubernetes, состоящего из 1000 узлов, 15000 pod'ов и 48000 работающих контейнеров.
С января 2018 года мы прошли через различные этапы миграции. Начали с контейнеризации всех наших сервисов и их развёртывания в тестовых окружениях Kubernetes. С октября стартовал процесс методического переноса всех существующих сервисов в Kubernetes. К марту следующего года было закончено «переселение» и теперь платформа Tinder работает исключительно на Kubernetes.
У нас более 30 репозиториев исходного кода для микросервисов, работающих в кластере Kubernetes. Код в этих репозиториях написан на разных языках (например, на Node.js, Java, Scala, Go) со множеством runtime-окружений для одного и того же языка.
Система сборки разработана таким образом, чтобы обеспечивать полностью настраиваемый «контекст сборки» для каждого микросервиса. Обычно он состоит из Dockerfile и списка shell-команд. Их содержимое полностью настраиваемо, и в то же время все эти контексты сборки написаны в соответствии со стандартизированным форматом. Стандартизация контекстов сборки позволяет единственной системе сборки обрабатывать все микросервисы.
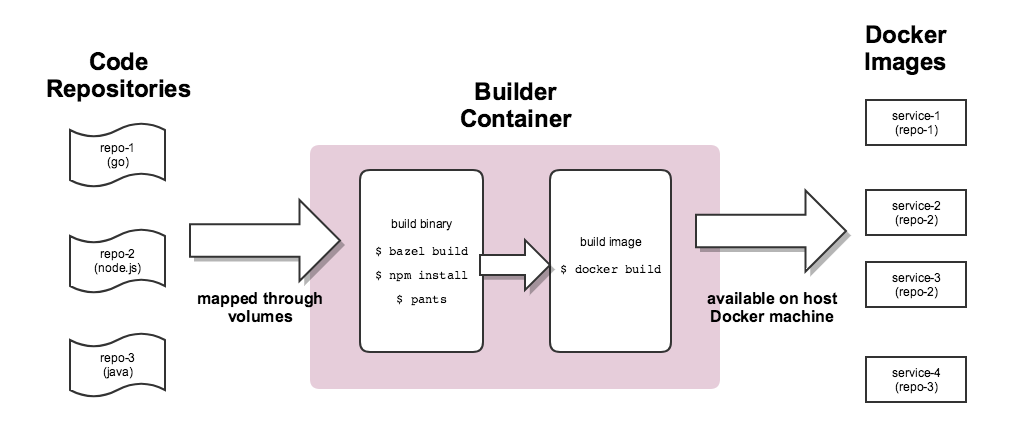
Рисунок 1-1. Стандартизованный процесс сборки через контейнер-сборщик (Builder)
Для достижения максимальной согласованности между средами выполнения один и тот же процесс сборки используется во время разработки и тестирования. Мы столкнулись с очень интересной задачей: пришлось разработать способ, гарантирующий согласованность сборочной среды по всей платформе. Для этого все сборочные процессы проводятся внутри специального контейнера Builder.
Его реализация потребовала продвинутых приёмов работы с Docker. Builder наследует локальный ID пользователя и секреты (например, ключ SSH, учетные данные AWS и т. д.), требующиеся для доступа к закрытым репозиториям Tinder. Он монтирует локальные директории, содержащие исходники, чтобы естественным образом хранить артефакты сборки. Подобный подход повышает производительность, поскольку устраняет потребность в копировании артефактов сборки между контейнером Builder и хостом. Хранящиеся артефакты сборки можно использовать повторно без дополнительной настройки.
Для некоторых сервисов нам пришлось создавать ещё один контейнер, чтобы сопоставить среду компиляции со средой выполнения (например, в процессе установки библиотека Node.js bcrypt генерирует специфичные для платформы бинарные артефакты). В процессе компиляции требования могут различаться для разных сервисов, и конечный Dockerfile составляется на лету.
Мы решили использовать kube-aws для автоматизированного развёртывания кластера на экземплярах EC2 от Amazon. В самом начале всё работало в одном общем пуле узлов. Мы быстро осознали необходимость разделения рабочих нагрузок по размерам и типам экземпляров для более эффективного использования ресурсов. Логика была в том, что запуск нескольких нагруженных многопоточных pod'ов оказывался более предсказуемым по производительности, нежели их сосуществование с большим числом однопоточных pod'ов.
В итоге мы остановились на:
Одним из подготовительных шагов для миграции со старой инфраструктуры на Kubernetes стало перенаправление существующего прямого взаимодействия между сервисами в новые балансировщики нагрузки (ELB, Elastic Load Balancers). Они были созданы в определённой подсети виртуального частного облака (VPC). Эта подсеть была подключена к VPC Kubernetes. Это позволило нам переносить модули постепенно, не учитывая конкретный порядок зависимостей от сервисов.
Эти endpoints были созданы с использованием взвешенных наборов DNS-записей, у которых CNAME указывали на каждый новый ELB. Для переключения мы добавляли новую запись, указывающую на новый ELB службы Kubernetes с весом, равным 0. Затем устанавливали Time To Live (TTL) набора записей на 0. После этого старые и новые весовые коэффициенты медленно корректировались, и в конечном итоге 100% нагрузки направлялись на новый сервер. После завершения переключения значение TTL возвращалось на более адекватный уровень.
Имеющиеся у нас Java-модули справлялись с низким TTL DNS, а Node-приложения — нет. Один из инженеров переписал часть кода пула соединений, обернув его в менеджера, который обновлял пулы каждые 60 секунд. Выбранный подход сработал очень хорошо и без заметного снижения производительности.
Ранним утром 8 января 2019 года платформа Tinder неожиданно «упала». В ответ на несвязанное увеличение времени ожидания платформы ранее тем же утром в кластере возросло число pod'ов и узлов. Это привело к исчерпанию кэша ARP на всех наших узлах.
Есть три параметра Linux, связанных с кэшем ARP:

(источник)
gc_thresh3 — это жёсткий предел. Появление в логе записей вида «neighbor table overflow» означало, что даже после синхронного сбора мусора (GC) в кэше ARP оказывалось недостаточно места для хранения соседней записи. В этом случае ядро просто полностью отбрасывало пакет.
Мы используем Flannel в качестве сетевого решения (network fabric) в Kubernetes. Пакеты передаются через VXLAN. VXLAN представляет собой L2-тоннель, поднятый поверх L3-сети. Технология использует инкапсуляцию MAC-in-UDP (MAC Address-in-User Datagram Protocol) и позволяет расширять сетевые сегменты 2-го уровня. Транспортный протокол в физической сети центра обработки данных — IP плюс UDP.
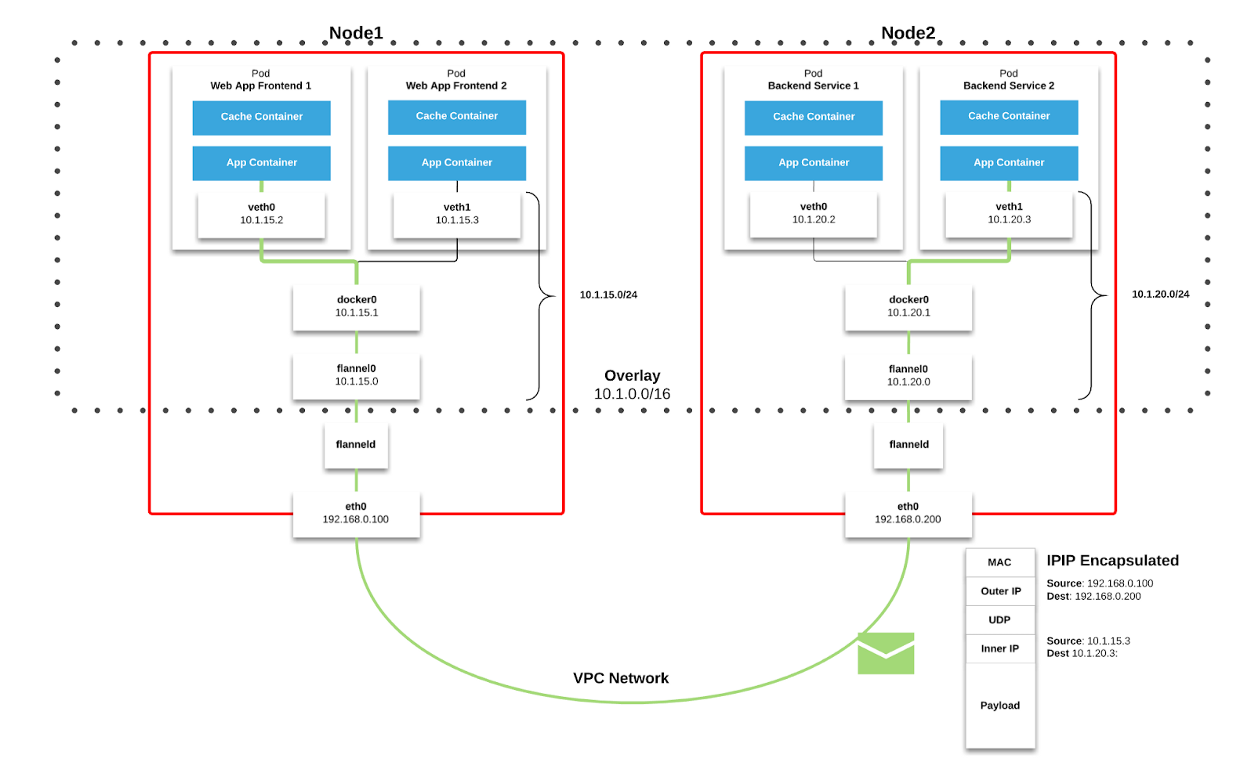
Рисунок 2–1. Диаграмма Flannel (источник)
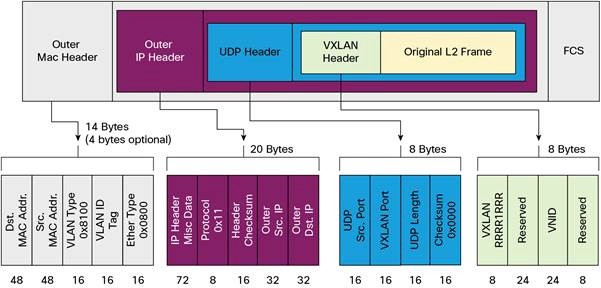
Рисунок 2–2. Пакет VXLAN (источник)
Каждый рабочий узел Kubernetes выделяет виртуальное адресное пространство с маской /24 из большего блока /9. Для каждого узла это означает одну запись в таблице маршрутизации, одну запись в таблице ARP (на интерфейсе flannel.1) и одну запись в таблице коммутации (FDB). Они добавляются при первом запуске рабочего узла или при обнаружении каждого нового узла.
Кроме того, связь узел-pod (или pod-pod) в конечном итоге идёт через интерфейс eth0 (как показано на диаграмме Flannel выше). Это приводит к появлению дополнительной записи в таблице ARP для каждого соответствующего источника и адресата узла.
В нашей среде подобный тип связи весьма распространён. Для объектов типа сервис в Kubernetes создаётся ELB и Kubernetes регистрирует каждый узел в ELB. ELB ничего не знает о pod'ах и выбранный узел может не являться конечным пунктом назначения пакета. Дело в том, что когда узел получает пакет от ELB, он рассматривает его с учётом правил iptables для конкретного сервиса и случайным образом выбирает pod на другом узле.
На момент сбоя в кластере было 605 узлов. По причинам, изложенным выше, этого оказалось достаточно, чтобы преодолеть значение gc_thresh3, заданное по умолчанию. Когда такое происходит, не только пакеты начинают отбрасываться, но и всё виртуальное адресное пространство Flannel с маской /24 пропадает из таблицы ARP. Связь узел-pod и DNS-запросы прерываются (DNS размещён в кластере; подробности читайте далее в этой статье).
Чтобы решить эту проблему, необходимо увеличить значения gc_thresh1, gc_thresh2 и gc_thresh3 и перезапустить Flannel для перерегистрации пропавших сетей.
В процессе миграции мы активно использовали DNS для управления трафиком и постепенного перевода сервисов со старой инфраструктуры на Kubernetes. Мы устанавливали относительно низкие значения TTL для связанных RecordSets в Route53. Когда старая инфраструктура работала на экземплярах EC2, конфигурация нашего resolver'а указывала на DNS Amazon. Мы воспринимали это как должное и воздействие низкого TTL на наши сервисы и сервисы Amazon (например, DynamoDB) оставалось практически незамеченным.
По мере переноса сервисов в Kubernetes мы обнаружили, что DNS обрабатывает по 250 тысяч запросов в секунду. В результате приложения стали испытывать постоянные и серьёзные timeout'ы по DNS-запросам. Это произошло несмотря на неимоверные усилия по оптимизации и переключению DNS-провайдера на CoreDNS (который на пике нагрузки достиг 1000 pod'ов, работающих на 120 ядрах).
Исследуя другие возможные причины и решения, мы обнаружили статью, описывающую race conditions, влияющие на фреймворк фильтрации пакетов netfilter в Linux. Наблюдаемые нами timeout'ы вкупе с увеличивающимся счетчиком insert_failed в интерфейсе Flannel соответствовали выводам статьи.
Проблема возникает на этапе Source и Destination Network Address Translation (SNAT и DNAT) и последующего внесения в таблицу conntrack. Одним из обходных путей, обсуждавшемся внутри компании и предложенным сообществом, стал перенос DNS на сам рабочий узел. В этом случае:
Мы решили придерживаться этого подхода. CoreDNS был развернут как DaemonSet в Kubernetes и мы внедрили локальный DNS-сервер узла в resolv.conf каждого pod'a настроив флаг --cluster-dns команды kubelet . Это решение оказалось эффективным для timeout'ов DNS.
Однако мы по-прежнему наблюдали потерю пакетов и увеличение счетчика insert_failed в интерфейсе Flannel. Такое положение сохранялось и после внедрения обходного пути, поскольку мы сумели исключить SNAT и/или DNAT только для DNS-трафика. Race conditions сохранялись для других типов трафика. К счастью, большинство пакетов у нас — TCP, и при возникновении проблемы они просто передаются повторно. Мы до сих пор пытаемся найти подходящее решение для всех типов трафика.
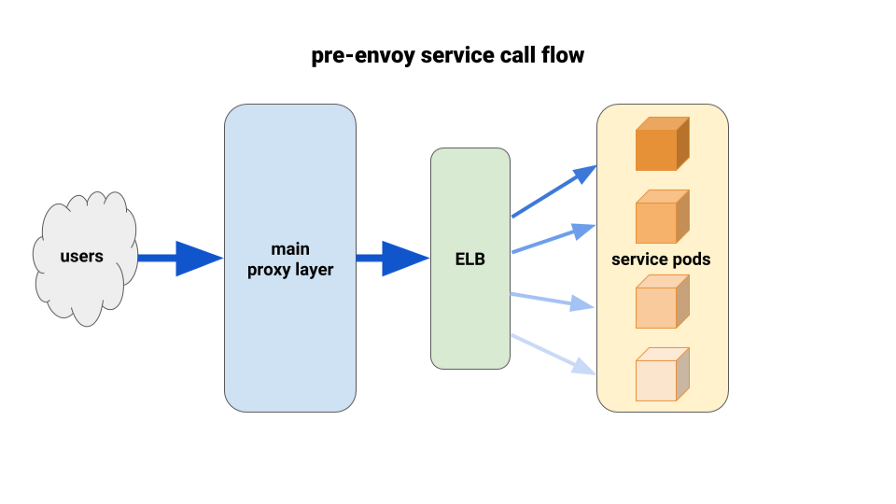
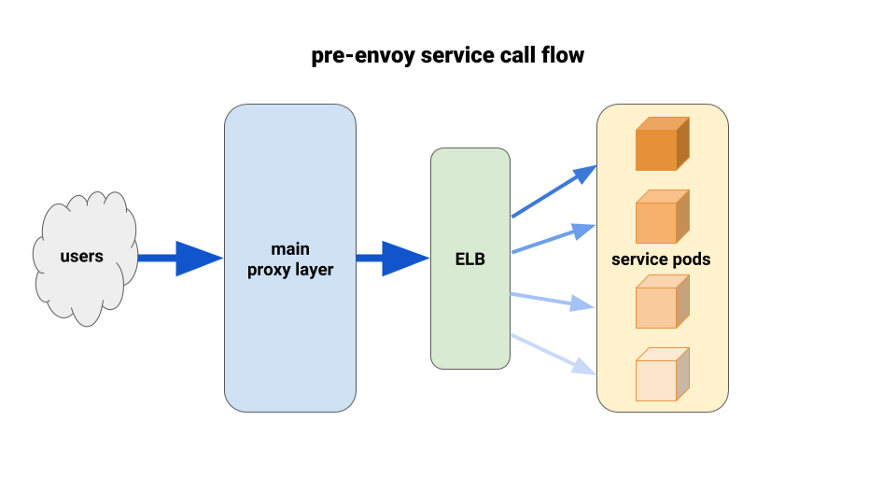
По мере миграции backend-сервисов в Kubernetes мы начали страдать от несбалансированной нагрузки между pod'ами. Мы обнаружили, что из-за HTTP Keepalive соединения ELB зависали на первых готовых pod'ах каждого выкатываемого deployment'а. Таким образом, основная часть трафика шла через небольшой процент доступных pod'ов. Первым решением, испытанным нами, стала установка параметра MaxSurge на 100% на новых deployment’ах для худших случаев. Эффект оказался незначительным и неперспективным в плане более крупных deployment'ов.
Ещё одно использованное нами решение заключалось в том, чтобы искусственно наращивать запросы на ресурсы для критически важных сервисов. В этом случае у размещённых по соседству pod'ов было бы больше пространства для манёвра по сравнению с другими тяжелыми pod'ами. В долгосрочной перспективе оно бы также не сработало из-за пустой траты ресурсов. Кроме того, наши Node-приложения были однопоточными и, соответственно, могли задействовать только одно ядро. Единственным реальным решением было использование лучшей балансировки нагрузки.
Мы давно хотели в полной мере оценить Envoy. Сложившаяся ситуация позволила нам развернуть его крайне ограниченным образом и получить незамедлительные результаты. Envoy — это высокопроизводительный прокси седьмого уровня с открытым исходным кодом, разработанный для крупных SOA-приложений. Он умеет применять передовые методы балансировки нагрузки, включая автоматические повторы, circuit breakers и глобальное ограничение скорости. (Прим. перев.: Подробнее об этом можно почитать в недавней статье про Istio — service mesh, в основе которого используется Envoy.)
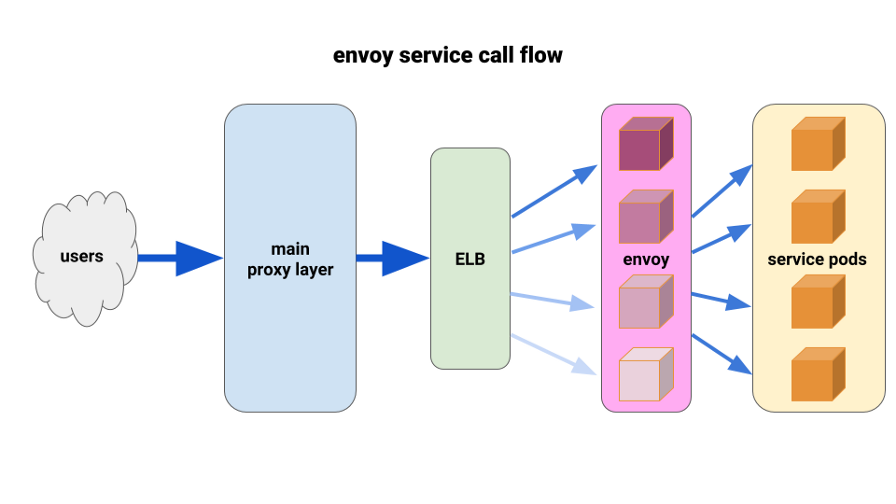
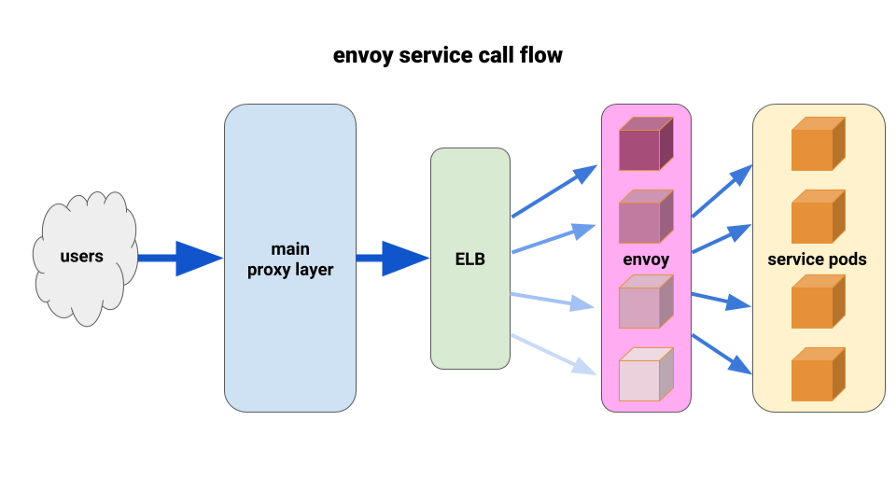
Мы придумали следующую конфигурацию: иметь по Envoy sidecar'у для каждого pod'а и единственный маршрут, а кластер — подключать к контейнеру локально по порту. Чтобы свести к минимуму потенциальное каскадирование и сохранить небольшой радиус «поражения», мы использовали парк front-proxy pod'ов Envoy, по одному на каждую зону доступности (Availability Zone, AZ) для каждого сервиса. Они обращались к простому механизму обнаружения сервисов, написанному одним из наших инженеров, который просто возвращал список pod'ов в каждой AZ для данного сервиса.
Затем сервисные front-Envoy'и использовали этот механизм обнаружения сервисов с одним upstream-кластером и маршрутом. Мы задали адекватные timeout'ы, увеличили все настройки circuit breaker’а и добавили минимальную конфигурацию повторов, чтобы помочь с одиночными сбоями и обеспечить беспрепятственные развёртывания. Перед каждым из этих сервисных front-Envoy'ев мы расположили TCP ELB. Даже если keepalive с нашего основного прокси-слоя зависал на некоторых Envoy pod'ах, они всё же могли гораздо лучше справляться с нагрузкой и были настроены на балансировку через least_request в backend.
Для deployment’ов мы использовали хук preStop как на pod'ах приложений, так и на pod'ах sidecar'ов. Хук инициировал ошибку в проверке состояния у админского endpoint'а, расположенного на sidecar-контейнере, и «спал» некоторое время с тем, чтобы дать возможность завершиться активным соединениям.
Одна из причин, по которой мы смогли так быстро продвинуться в решении проблем, связана с подробными метриками, которые мы смогли легко интегрировать в обычную установку Prometheus. С ними стало возможным точно видеть, что происходит, пока мы подбирали параметры конфигурации и перераспределяли трафик.
Результаты были незамедлительными и очевидными. Мы начали с самых несбалансированных сервисов, а на данный момент он функционирует уже перед 12 самыми важными сервисами в кластере. В этом году мы планируем переход на полноценный service mesh с более продвинутым обнаружением сервисов, circuit breaking'ом, обнаружением выбросов, ограничением скорости и трассировкой.
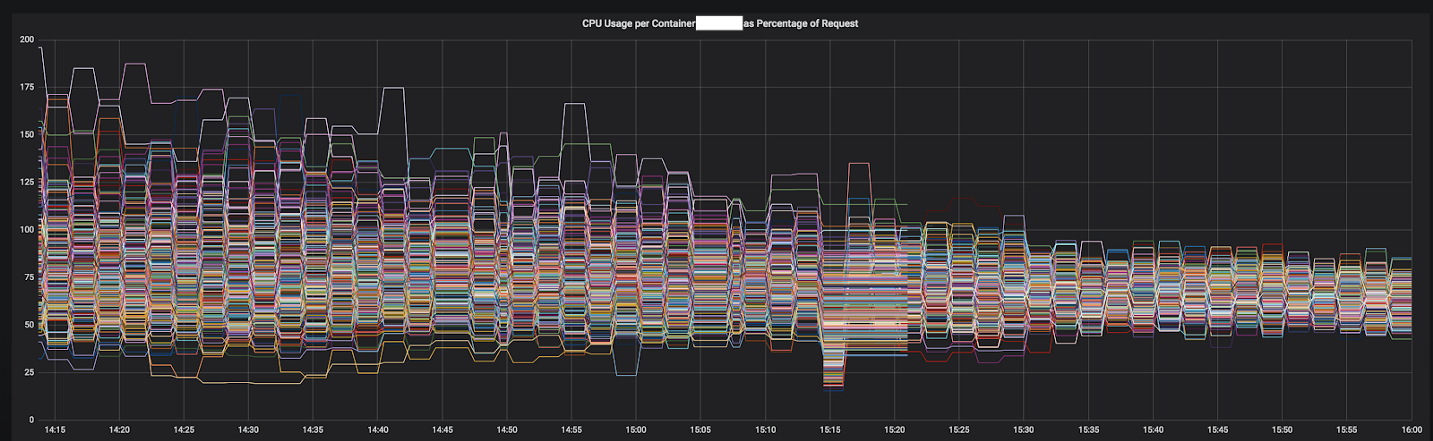
Рисунок 3–1. Конвергенция CPU одного сервиса во время перехода на Envoy
Благодаря полученному опыту и дополнительным исследованиям мы создали сильную команду по инфраструктуре с хорошими навыками в отношении проектирования, развёртывания и эксплуатации крупных кластеров Kubernetes. Теперь все инженеры Tinder обладают знаниями и опытом о том, как упаковывать контейнеры и развёртывать приложения в Kubernetes.
Когда на старой инфраструктуре возникала потребность в дополнительных мощностях, нам приходилось по нескольку минут ждать запуска новых экземпляров EC2. Теперь контейнеры запускаются и начинают обрабатывать трафик в течение нескольких секунд вместо минут. Планирование работы нескольких контейнеров на одном экземпляре EC2 также обеспечивает улучшенную горизонтальную концентрацию. Как итог в 2019-м году мы прогнозируем значительное снижение затрат на EC2 по сравнению с прошлым годом.
На миграцию ушло почти два года, но мы завершили её в марте 2019-го. В настоящее время платформа Tinder работает исключительно на кластере Kubernetes, состоящем из 200 сервисов, 1000 узлов, 15 000 pod'ов и 48 000 запущенных контейнеров. Инфраструктура более не является уделом исключительно команд по эксплуатации. Все наши инженеры разделяют эту ответственность и контролируют процесс сборки и развёртывания своих приложений только с помощью кода.
Читайте также в нашем блоге цикл статей:

Зачем?
Почти два года назад Tinder решил перевести свою платформу на Kubernetes. Kubernetes позволил бы команде Tinder провести контейнеризацию и перейти на эксплуатацию с минимальными усилиями посредством неизменного развертывания (immutable deployment). В этом случае сборка приложений, их деплой и сама инфраструктура были бы однозначно определены кодом.
Также мы искали решение проблемы с масштабируемостью и стабильностью. Когда масштабирование приобрело критическое значение, нам часто приходилось по несколько минут ждать запуска новых экземпляров EC2. Поэтому очень привлекательной для нас стала идея запуска контейнеров и начала обслуживания трафика за секунды вместо минут.
Процесс оказался непростым. Во время миграции, в начале 2019 года, кластер Kubernetes достиг критической массы и мы начали сталкиваться с различными проблемами из-за объёма трафика, размера кластера и DNS. В этом путешествии мы решили массу интересных задач, связанных с переносом 200 сервисов и обслуживанием кластера Kubernetes, состоящего из 1000 узлов, 15000 pod'ов и 48000 работающих контейнеров.
Как?
С января 2018 года мы прошли через различные этапы миграции. Начали с контейнеризации всех наших сервисов и их развёртывания в тестовых окружениях Kubernetes. С октября стартовал процесс методического переноса всех существующих сервисов в Kubernetes. К марту следующего года было закончено «переселение» и теперь платформа Tinder работает исключительно на Kubernetes.
Сборка образов для Kubernetes
У нас более 30 репозиториев исходного кода для микросервисов, работающих в кластере Kubernetes. Код в этих репозиториях написан на разных языках (например, на Node.js, Java, Scala, Go) со множеством runtime-окружений для одного и того же языка.
Система сборки разработана таким образом, чтобы обеспечивать полностью настраиваемый «контекст сборки» для каждого микросервиса. Обычно он состоит из Dockerfile и списка shell-команд. Их содержимое полностью настраиваемо, и в то же время все эти контексты сборки написаны в соответствии со стандартизированным форматом. Стандартизация контекстов сборки позволяет единственной системе сборки обрабатывать все микросервисы.

Рисунок 1-1. Стандартизованный процесс сборки через контейнер-сборщик (Builder)
Для достижения максимальной согласованности между средами выполнения один и тот же процесс сборки используется во время разработки и тестирования. Мы столкнулись с очень интересной задачей: пришлось разработать способ, гарантирующий согласованность сборочной среды по всей платформе. Для этого все сборочные процессы проводятся внутри специального контейнера Builder.
Его реализация потребовала продвинутых приёмов работы с Docker. Builder наследует локальный ID пользователя и секреты (например, ключ SSH, учетные данные AWS и т. д.), требующиеся для доступа к закрытым репозиториям Tinder. Он монтирует локальные директории, содержащие исходники, чтобы естественным образом хранить артефакты сборки. Подобный подход повышает производительность, поскольку устраняет потребность в копировании артефактов сборки между контейнером Builder и хостом. Хранящиеся артефакты сборки можно использовать повторно без дополнительной настройки.
Для некоторых сервисов нам пришлось создавать ещё один контейнер, чтобы сопоставить среду компиляции со средой выполнения (например, в процессе установки библиотека Node.js bcrypt генерирует специфичные для платформы бинарные артефакты). В процессе компиляции требования могут различаться для разных сервисов, и конечный Dockerfile составляется на лету.
Архитектура кластера Kubernetes и миграция
Управление размером кластера
Мы решили использовать kube-aws для автоматизированного развёртывания кластера на экземплярах EC2 от Amazon. В самом начале всё работало в одном общем пуле узлов. Мы быстро осознали необходимость разделения рабочих нагрузок по размерам и типам экземпляров для более эффективного использования ресурсов. Логика была в том, что запуск нескольких нагруженных многопоточных pod'ов оказывался более предсказуемым по производительности, нежели их сосуществование с большим числом однопоточных pod'ов.
В итоге мы остановились на:
- m5.4xlarge — для мониторинга (Prometheus);
- c5.4xlarge — для рабочей нагрузки Node.js (однопоточная рабочая нагрузка);
- c5.2xlarge — для Java и Go (многопоточная рабочая нагрузка);
- c5.4xlarge — для контрольной панели (3 узла).
Миграция
Одним из подготовительных шагов для миграции со старой инфраструктуры на Kubernetes стало перенаправление существующего прямого взаимодействия между сервисами в новые балансировщики нагрузки (ELB, Elastic Load Balancers). Они были созданы в определённой подсети виртуального частного облака (VPC). Эта подсеть была подключена к VPC Kubernetes. Это позволило нам переносить модули постепенно, не учитывая конкретный порядок зависимостей от сервисов.
Эти endpoints были созданы с использованием взвешенных наборов DNS-записей, у которых CNAME указывали на каждый новый ELB. Для переключения мы добавляли новую запись, указывающую на новый ELB службы Kubernetes с весом, равным 0. Затем устанавливали Time To Live (TTL) набора записей на 0. После этого старые и новые весовые коэффициенты медленно корректировались, и в конечном итоге 100% нагрузки направлялись на новый сервер. После завершения переключения значение TTL возвращалось на более адекватный уровень.
Имеющиеся у нас Java-модули справлялись с низким TTL DNS, а Node-приложения — нет. Один из инженеров переписал часть кода пула соединений, обернув его в менеджера, который обновлял пулы каждые 60 секунд. Выбранный подход сработал очень хорошо и без заметного снижения производительности.
Уроки
Ограничения в устройстве сети
Ранним утром 8 января 2019 года платформа Tinder неожиданно «упала». В ответ на несвязанное увеличение времени ожидания платформы ранее тем же утром в кластере возросло число pod'ов и узлов. Это привело к исчерпанию кэша ARP на всех наших узлах.
Есть три параметра Linux, связанных с кэшем ARP:

(источник)
gc_thresh3 — это жёсткий предел. Появление в логе записей вида «neighbor table overflow» означало, что даже после синхронного сбора мусора (GC) в кэше ARP оказывалось недостаточно места для хранения соседней записи. В этом случае ядро просто полностью отбрасывало пакет.
Мы используем Flannel в качестве сетевого решения (network fabric) в Kubernetes. Пакеты передаются через VXLAN. VXLAN представляет собой L2-тоннель, поднятый поверх L3-сети. Технология использует инкапсуляцию MAC-in-UDP (MAC Address-in-User Datagram Protocol) и позволяет расширять сетевые сегменты 2-го уровня. Транспортный протокол в физической сети центра обработки данных — IP плюс UDP.
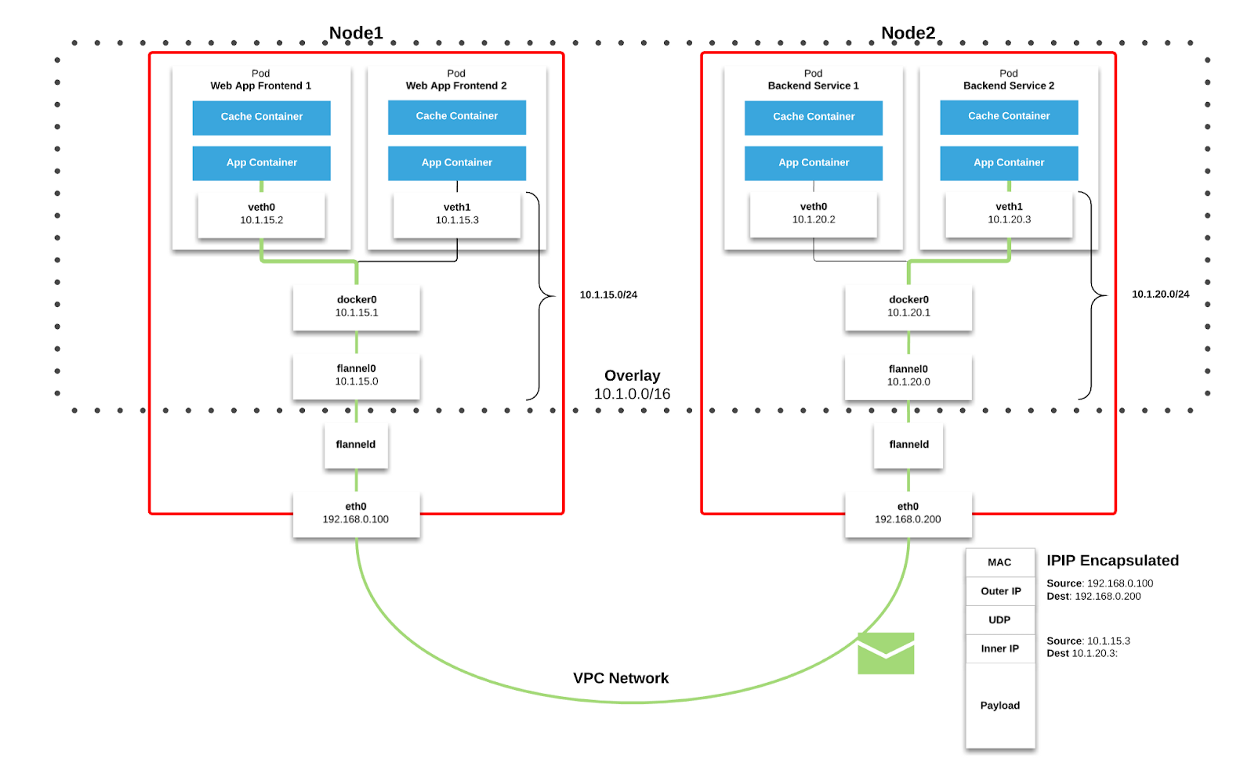
Рисунок 2–1. Диаграмма Flannel (источник)

Рисунок 2–2. Пакет VXLAN (источник)
Каждый рабочий узел Kubernetes выделяет виртуальное адресное пространство с маской /24 из большего блока /9. Для каждого узла это означает одну запись в таблице маршрутизации, одну запись в таблице ARP (на интерфейсе flannel.1) и одну запись в таблице коммутации (FDB). Они добавляются при первом запуске рабочего узла или при обнаружении каждого нового узла.
Кроме того, связь узел-pod (или pod-pod) в конечном итоге идёт через интерфейс eth0 (как показано на диаграмме Flannel выше). Это приводит к появлению дополнительной записи в таблице ARP для каждого соответствующего источника и адресата узла.
В нашей среде подобный тип связи весьма распространён. Для объектов типа сервис в Kubernetes создаётся ELB и Kubernetes регистрирует каждый узел в ELB. ELB ничего не знает о pod'ах и выбранный узел может не являться конечным пунктом назначения пакета. Дело в том, что когда узел получает пакет от ELB, он рассматривает его с учётом правил iptables для конкретного сервиса и случайным образом выбирает pod на другом узле.
На момент сбоя в кластере было 605 узлов. По причинам, изложенным выше, этого оказалось достаточно, чтобы преодолеть значение gc_thresh3, заданное по умолчанию. Когда такое происходит, не только пакеты начинают отбрасываться, но и всё виртуальное адресное пространство Flannel с маской /24 пропадает из таблицы ARP. Связь узел-pod и DNS-запросы прерываются (DNS размещён в кластере; подробности читайте далее в этой статье).
Чтобы решить эту проблему, необходимо увеличить значения gc_thresh1, gc_thresh2 и gc_thresh3 и перезапустить Flannel для перерегистрации пропавших сетей.
Неожиданное масштабирование DNS
В процессе миграции мы активно использовали DNS для управления трафиком и постепенного перевода сервисов со старой инфраструктуры на Kubernetes. Мы устанавливали относительно низкие значения TTL для связанных RecordSets в Route53. Когда старая инфраструктура работала на экземплярах EC2, конфигурация нашего resolver'а указывала на DNS Amazon. Мы воспринимали это как должное и воздействие низкого TTL на наши сервисы и сервисы Amazon (например, DynamoDB) оставалось практически незамеченным.
По мере переноса сервисов в Kubernetes мы обнаружили, что DNS обрабатывает по 250 тысяч запросов в секунду. В результате приложения стали испытывать постоянные и серьёзные timeout'ы по DNS-запросам. Это произошло несмотря на неимоверные усилия по оптимизации и переключению DNS-провайдера на CoreDNS (который на пике нагрузки достиг 1000 pod'ов, работающих на 120 ядрах).
Исследуя другие возможные причины и решения, мы обнаружили статью, описывающую race conditions, влияющие на фреймворк фильтрации пакетов netfilter в Linux. Наблюдаемые нами timeout'ы вкупе с увеличивающимся счетчиком insert_failed в интерфейсе Flannel соответствовали выводам статьи.
Проблема возникает на этапе Source и Destination Network Address Translation (SNAT и DNAT) и последующего внесения в таблицу conntrack. Одним из обходных путей, обсуждавшемся внутри компании и предложенным сообществом, стал перенос DNS на сам рабочий узел. В этом случае:
- SNAT не нужен, поскольку трафик остаётся внутри узла. Его не нужно проводить через интерфейс eth0.
- DNAT не нужен, поскольку IP адресата является локальным для узла, а не случайно выбранным pod'ом по правилам iptables.
Мы решили придерживаться этого подхода. CoreDNS был развернут как DaemonSet в Kubernetes и мы внедрили локальный DNS-сервер узла в resolv.conf каждого pod'a настроив флаг --cluster-dns команды kubelet . Это решение оказалось эффективным для timeout'ов DNS.
Однако мы по-прежнему наблюдали потерю пакетов и увеличение счетчика insert_failed в интерфейсе Flannel. Такое положение сохранялось и после внедрения обходного пути, поскольку мы сумели исключить SNAT и/или DNAT только для DNS-трафика. Race conditions сохранялись для других типов трафика. К счастью, большинство пакетов у нас — TCP, и при возникновении проблемы они просто передаются повторно. Мы до сих пор пытаемся найти подходящее решение для всех типов трафика.
Использование Envoy для лучшей балансировки нагрузки
По мере миграции backend-сервисов в Kubernetes мы начали страдать от несбалансированной нагрузки между pod'ами. Мы обнаружили, что из-за HTTP Keepalive соединения ELB зависали на первых готовых pod'ах каждого выкатываемого deployment'а. Таким образом, основная часть трафика шла через небольшой процент доступных pod'ов. Первым решением, испытанным нами, стала установка параметра MaxSurge на 100% на новых deployment’ах для худших случаев. Эффект оказался незначительным и неперспективным в плане более крупных deployment'ов.
Ещё одно использованное нами решение заключалось в том, чтобы искусственно наращивать запросы на ресурсы для критически важных сервисов. В этом случае у размещённых по соседству pod'ов было бы больше пространства для манёвра по сравнению с другими тяжелыми pod'ами. В долгосрочной перспективе оно бы также не сработало из-за пустой траты ресурсов. Кроме того, наши Node-приложения были однопоточными и, соответственно, могли задействовать только одно ядро. Единственным реальным решением было использование лучшей балансировки нагрузки.
Мы давно хотели в полной мере оценить Envoy. Сложившаяся ситуация позволила нам развернуть его крайне ограниченным образом и получить незамедлительные результаты. Envoy — это высокопроизводительный прокси седьмого уровня с открытым исходным кодом, разработанный для крупных SOA-приложений. Он умеет применять передовые методы балансировки нагрузки, включая автоматические повторы, circuit breakers и глобальное ограничение скорости. (Прим. перев.: Подробнее об этом можно почитать в недавней статье про Istio — service mesh, в основе которого используется Envoy.)
Мы придумали следующую конфигурацию: иметь по Envoy sidecar'у для каждого pod'а и единственный маршрут, а кластер — подключать к контейнеру локально по порту. Чтобы свести к минимуму потенциальное каскадирование и сохранить небольшой радиус «поражения», мы использовали парк front-proxy pod'ов Envoy, по одному на каждую зону доступности (Availability Zone, AZ) для каждого сервиса. Они обращались к простому механизму обнаружения сервисов, написанному одним из наших инженеров, который просто возвращал список pod'ов в каждой AZ для данного сервиса.
Затем сервисные front-Envoy'и использовали этот механизм обнаружения сервисов с одним upstream-кластером и маршрутом. Мы задали адекватные timeout'ы, увеличили все настройки circuit breaker’а и добавили минимальную конфигурацию повторов, чтобы помочь с одиночными сбоями и обеспечить беспрепятственные развёртывания. Перед каждым из этих сервисных front-Envoy'ев мы расположили TCP ELB. Даже если keepalive с нашего основного прокси-слоя зависал на некоторых Envoy pod'ах, они всё же могли гораздо лучше справляться с нагрузкой и были настроены на балансировку через least_request в backend.
Для deployment’ов мы использовали хук preStop как на pod'ах приложений, так и на pod'ах sidecar'ов. Хук инициировал ошибку в проверке состояния у админского endpoint'а, расположенного на sidecar-контейнере, и «спал» некоторое время с тем, чтобы дать возможность завершиться активным соединениям.
Одна из причин, по которой мы смогли так быстро продвинуться в решении проблем, связана с подробными метриками, которые мы смогли легко интегрировать в обычную установку Prometheus. С ними стало возможным точно видеть, что происходит, пока мы подбирали параметры конфигурации и перераспределяли трафик.
Результаты были незамедлительными и очевидными. Мы начали с самых несбалансированных сервисов, а на данный момент он функционирует уже перед 12 самыми важными сервисами в кластере. В этом году мы планируем переход на полноценный service mesh с более продвинутым обнаружением сервисов, circuit breaking'ом, обнаружением выбросов, ограничением скорости и трассировкой.
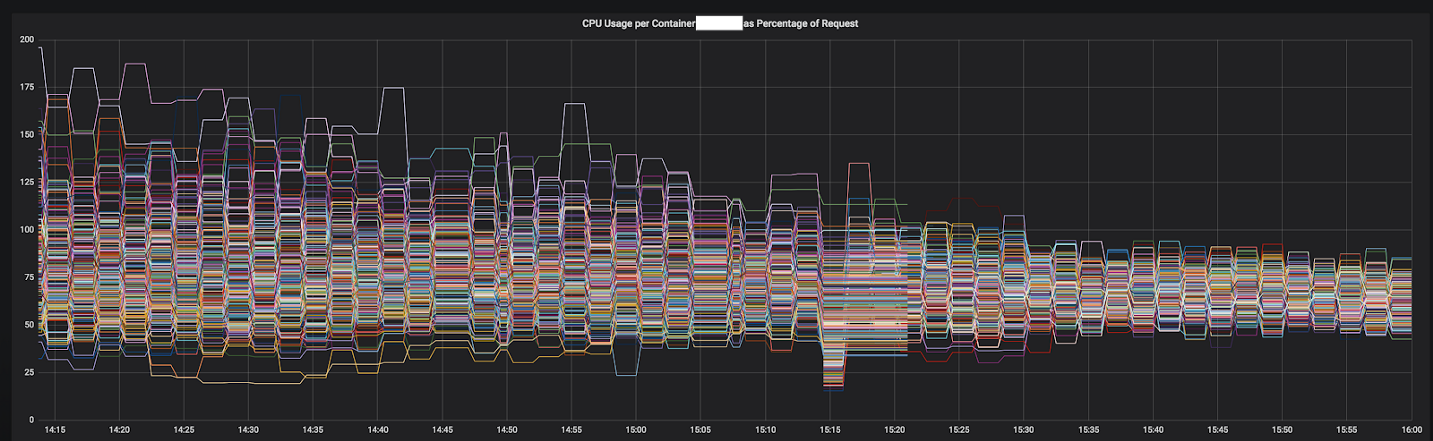
Рисунок 3–1. Конвергенция CPU одного сервиса во время перехода на Envoy
Конечный результат
Благодаря полученному опыту и дополнительным исследованиям мы создали сильную команду по инфраструктуре с хорошими навыками в отношении проектирования, развёртывания и эксплуатации крупных кластеров Kubernetes. Теперь все инженеры Tinder обладают знаниями и опытом о том, как упаковывать контейнеры и развёртывать приложения в Kubernetes.
Когда на старой инфраструктуре возникала потребность в дополнительных мощностях, нам приходилось по нескольку минут ждать запуска новых экземпляров EC2. Теперь контейнеры запускаются и начинают обрабатывать трафик в течение нескольких секунд вместо минут. Планирование работы нескольких контейнеров на одном экземпляре EC2 также обеспечивает улучшенную горизонтальную концентрацию. Как итог в 2019-м году мы прогнозируем значительное снижение затрат на EC2 по сравнению с прошлым годом.
На миграцию ушло почти два года, но мы завершили её в марте 2019-го. В настоящее время платформа Tinder работает исключительно на кластере Kubernetes, состоящем из 200 сервисов, 1000 узлов, 15 000 pod'ов и 48 000 запущенных контейнеров. Инфраструктура более не является уделом исключительно команд по эксплуатации. Все наши инженеры разделяют эту ответственность и контролируют процесс сборки и развёртывания своих приложений только с помощью кода.
P.S. от переводчика
Читайте также в нашем блоге цикл статей:
- «Истории успеха Kubernetes в production. Часть 1: 4200 подов и TessMaster у eBay».
- «Истории успеха Kubernetes в production. Часть 2: Concur и SAP».
- «Истории успеха Kubernetes в production. Часть 3: GitHub».
- «Истории успеха Kubernetes в production. Часть 4: SoundCloud (авторы Prometheus)».
- «Истории успеха Kubernetes в production. Часть 5: цифровой банк Monzo».
- «Истории успеха Kubernetes в production. Часть 6: BlaBlaCar».
- «Истории успеха Kubernetes в production. Часть 7: BlackRock».
- «Истории успеха Kubernetes в production. Часть 8: Huawei».
- «Истории успеха Kubernetes в production. Часть 9: ЦЕРН и 210 кластеров K8s».
- «Истории успеха Kubernetes в production. Часть 10: Reddit».
