
В нашем блоге уже были статьи, рассказывающие про возможности операторов в Kubernetes и о том, как написать простой оператор самому. На этот раз хотим представить вашему вниманию наше Open Source-решение, которое выводит создание операторов на суперлёгкий уровень, — познакомьтесь с shell-operator!
Идея shell-operator довольно проста: подписаться на события от объектов Kubernetes, а при получении этих событий запустить внешнюю программу, предоставив ей информацию о событии:

Потребность в нём возникла у нас, когда при эксплуатации кластеров стали появляться мелкие задачи, которые очень хотелось автоматизировать правильным путём. Все эти мелкие задачи решались с помощью простых bash-скриптов, хотя, как известно, операторы лучше писать на Golang. Очевидно, что вкладываться в полномасштабную разработку оператора под каждую такую мелкую задачу было бы неэффективно.
Рассмотрим на примере, что может быть автоматизировано в Kubernetes-кластере и чем поможет shell-operator. Пример же будет следующим: тиражирование секрета для доступа к docker registry.
Pod'ы, которые используют образы из private registry, должны содержать в своём манифесте ссылку на секрет с данными для доступа к registry. Этот секрет должен быть создан в каждом namespace перед созданием pod'ов. Это вполне можно делать и вручную, но если мы настроим динамические окружения, то namespace для одного приложения станет много. А если приложений тоже не 2-3… количество секретов становится очень большим. И ещё один момент про секреты: ключ для доступа к registry хотелось бы изменять время от времени. В итоге, ручные операции в качестве решения совершенно неэффективны — нужно автоматизировать создание и обновление секретов.
Напишем shell-скрипт, который запускается раз в N секунд и проверяет namespace'ы на наличие секрета, а если секрета нет, то он создаётся. Плюс этого решения, что оно выглядит как shell-скрипт в cron'е — классический и всем понятный подход. Минус же в том, что в промежутке между его запусками может быть создан новый namespace и какое-то время он останется без секрета, что приведёт к ошибкам запуска pod'ов.
Для корректной работы нашего скрипта классический запуск по cron'у нужно заменить на запуск при событии добавления namespace: в таком случае можно успеть создать секрет до его использования. Посмотрим, как это реализовать с помощью shell-operator.
Во-первых, разберём скрипт. Скрипты в терминах shell-operator называются хуками. Каждый хук при запуске с флагом
Здесь описано, что нас интересуют события добавления (
Теперь нужно добавить код, который будет выполняться при наступлении события:
Отлично! Получился небольшой, красивый скрипт. Чтобы «оживить» его, остаётся два шага: подготовить образ и запустить его в кластере.
Если посмотреть на скрипт, то видно, что используются команды
Ещё раз посмотрим на хук и на этот раз выпишем, какие действия и с какими объектами он производит в кластере:
Получается, что pod, в котором будет запущен наш образ, должен иметь разрешения на эти действия. Это можно сделать с помощью создания своего ServiceAccount. Разрешение нужно делать в виде ClusterRole и ClusterRoleBinding, т.к. нам интересны объекты со всего кластера.
Итоговое описание в YAML получится примерно таким:
Запустить собранный образ можно в виде простого Deployment:
Для удобства создаётся отдельный namespace, где будет запускаться shell-operator и применяются созданные манифесты:
На этом всё: shell-operator запустится, подпишется на события создания namespace'ов и будет запускать хук, когда нужно.

Таким образом, простой shell-скрипт превратился в настоящий operator для Kubernetes и работает как составная часть кластера. И всё это — без сложного процесса разработки операторов на Golang:
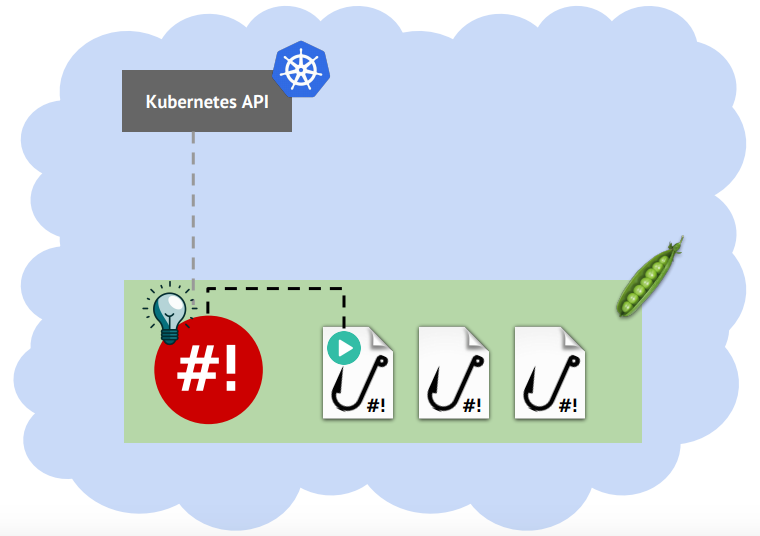
Слежение за объектами — это хорошо, но зачастую бывает необходимость реагировать на изменение каких-то свойств объекта, например, на изменение количества реплик в Deployment’е или на изменение лейблов объекта.
Когда приходит событие, shell-operator получает JSON-манифест объекта. Можно выделить в этом JSON интересующие нас свойства и запускать хук только при их изменениях. Для этого предусмотрено поле
Например, чтобы реагировать на изменение лейблов у объектов Deployment, нужно отфильтровать поле
Это выражение в jqFilter превращает длинный JSON-манифеста Deployment'а в короткий JSON с лейблами:

shell-operator будет запускать хук только в тех случаях, когда изменится этот короткий JSON, а изменения в других свойствах будут игнорироваться.
Конфиг хука позволяет указать несколько вариантов событий — например, 2 варианта для событий от Kubernetes и 2 расписания:
Небольшое отступление: да, shell-operator поддерживает запуск скриптов в стиле crontab. Более подробно можно почитать в документации.
Чтобы различать, в связи с чем был запущен хук, shell-operator создаёт временный файл и передаёт хуку путь к нему в переменной
… а в понедельник запустится с таким:
Для
Содержимое полей можно понять из их имён, а более подробно — прочесть в документации. Пример получения имени ресурса из поля
Аналогичным образом можно получать и остальные поля.
В репозитории проекта, в директории /examples, есть примеры хуков, которые готовы для запуска в кластере. При написании своих хуков можно брать их за основу.
Есть поддержка сбора метрик с помощью Prometheus — о доступных метриках написано в разделе METRICS.
Как легко догадаться shell-operator написан на Go и распространяется под Open Source-лицензией (Apache 2.0). Мы будем благодарны любой помощи по развитию проекта на GitHub: и звёздочкам, и issues, и pull requests.
Приоткрывая завесу тайны, также сообщим, что shell-operator — это небольшая часть нашей системы, которая умеет поддерживать в актуальном состоянии дополнения, установленные в кластере Kubernetes, и осуществляет различные автоматические действия. Подробнее об этой системе мы рассказали буквально в понедельник на HighLoad++ 2019 в Санкт-Петербурге — видео и расшифровку этого доклада вскоре опубликуем.
У нас есть план открыть и остальные части этой системы: addon-operator и нашу коллекцию хуков и модулей. Кстати, addon-operator уже доступен на GitHub, но документация к нему пока в пути. Релиз коллекции модулей планируется летом.
Stay tuned!
Читайте также в нашем блоге:
Зачем?
Идея shell-operator довольно проста: подписаться на события от объектов Kubernetes, а при получении этих событий запустить внешнюю программу, предоставив ей информацию о событии:
Потребность в нём возникла у нас, когда при эксплуатации кластеров стали появляться мелкие задачи, которые очень хотелось автоматизировать правильным путём. Все эти мелкие задачи решались с помощью простых bash-скриптов, хотя, как известно, операторы лучше писать на Golang. Очевидно, что вкладываться в полномасштабную разработку оператора под каждую такую мелкую задачу было бы неэффективно.
Оператор за 15 минут
Рассмотрим на примере, что может быть автоматизировано в Kubernetes-кластере и чем поможет shell-operator. Пример же будет следующим: тиражирование секрета для доступа к docker registry.
Pod'ы, которые используют образы из private registry, должны содержать в своём манифесте ссылку на секрет с данными для доступа к registry. Этот секрет должен быть создан в каждом namespace перед созданием pod'ов. Это вполне можно делать и вручную, но если мы настроим динамические окружения, то namespace для одного приложения станет много. А если приложений тоже не 2-3… количество секретов становится очень большим. И ещё один момент про секреты: ключ для доступа к registry хотелось бы изменять время от времени. В итоге, ручные операции в качестве решения совершенно неэффективны — нужно автоматизировать создание и обновление секретов.
Простая автоматизация
Напишем shell-скрипт, который запускается раз в N секунд и проверяет namespace'ы на наличие секрета, а если секрета нет, то он создаётся. Плюс этого решения, что оно выглядит как shell-скрипт в cron'е — классический и всем понятный подход. Минус же в том, что в промежутке между его запусками может быть создан новый namespace и какое-то время он останется без секрета, что приведёт к ошибкам запуска pod'ов.
Автоматизация с shell-operator
Для корректной работы нашего скрипта классический запуск по cron'у нужно заменить на запуск при событии добавления namespace: в таком случае можно успеть создать секрет до его использования. Посмотрим, как это реализовать с помощью shell-operator.
Во-первых, разберём скрипт. Скрипты в терминах shell-operator называются хуками. Каждый хук при запуске с флагом
--config сообщает shell-operator'у о своих binding'ах, т.е. по каким событиям его нужно запускать. В нашем случае воспользуемся onKubernetesEvent:#!/bin/bash
if [[ $1 == "--config" ]] ; then
cat <<EOF
{
"onKubernetesEvent": [
{ "kind": "namespace",
"event":["add"]
}
]}
EOF
fiЗдесь описано, что нас интересуют события добавления (
add) объектов типа namespace.Теперь нужно добавить код, который будет выполняться при наступлении события:
#!/bin/bash
if [[ $1 == "--config" ]] ; then
# конфигурация
cat <<EOF
{
"onKubernetesEvent": [
{ "kind": "namespace",
"event":["add"]
}
]}
EOF
else
# реакция:
# узнать, какой namespace появился
createdNamespace=$(jq -r '.[0].resourceName' $BINDING_CONTEXT_PATH)
# создать в нём нужный секрет
kubectl create -n ${createdNamespace} -f - <<EOF
apiVersion: v1
kind: Secret
metadata:
...
data:
...
EOF
fiОтлично! Получился небольшой, красивый скрипт. Чтобы «оживить» его, остаётся два шага: подготовить образ и запустить его в кластере.
Подготовка образа с хуком
Если посмотреть на скрипт, то видно, что используются команды
kubectl и jq. Это означает, что в образе должны быть следующие вещи: наш хук, shell-operator, который будет следить за событиями и запускать хук, а также используемые хуком команды (kubectl и jq). На hub.docker.com уже есть готовый образ, в котором упакованы shell-operator, kubectl и jq. Остаётся добавить хук простым Dockerfile:$ cat Dockerfile
FROM flant/shell-operator:v1.0.0-beta.1-alpine3.9
ADD namespace-hook.sh /hooks
$ docker build -t registry.example.com/my-operator:v1 .
$ docker push registry.example.com/my-operator:v1Запуск в кластере
Ещё раз посмотрим на хук и на этот раз выпишем, какие действия и с какими объектами он производит в кластере:
- подписывается на события создания namespace'ов;
- создаёт секрет в namespace'ах, отличных от того, где запущен.
Получается, что pod, в котором будет запущен наш образ, должен иметь разрешения на эти действия. Это можно сделать с помощью создания своего ServiceAccount. Разрешение нужно делать в виде ClusterRole и ClusterRoleBinding, т.к. нам интересны объекты со всего кластера.
Итоговое описание в YAML получится примерно таким:
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: monitor-namespaces-acc
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: monitor-namespaces
rules:
- apiGroups: [""]
resources: ["namespaces"]
verbs: ["get", "watch", "list"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "list", "create", "patch"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: monitor-namespaces
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: monitor-namespaces
subjects:
- kind: ServiceAccount
name: monitor-namespaces-acc
namespace: example-monitor-namespacesЗапустить собранный образ можно в виде простого Deployment:
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-operator
spec:
template:
spec:
containers:
- name: my-operator
image: registry.example.com/my-operator:v1
serviceAccountName: monitor-namespaces-accДля удобства создаётся отдельный namespace, где будет запускаться shell-operator и применяются созданные манифесты:
$ kubectl create ns example-monitor-namespaces
$ kubectl -n example-monitor-namespaces apply -f rbac.yaml
$ kubectl -n example-monitor-namespaces apply -f deployment.yaml
На этом всё: shell-operator запустится, подпишется на события создания namespace'ов и будет запускать хук, когда нужно.

Таким образом, простой shell-скрипт превратился в настоящий operator для Kubernetes и работает как составная часть кластера. И всё это — без сложного процесса разработки операторов на Golang:
Есть и другая иллюстрация на этот счёт…

Её смысл мы раскроем подробнее в одной из следующих публикаций. ОБНОВЛЕНО (1 мая 2019): см. «Расширяем и дополняем Kubernetes (обзор и видео доклада)».

Её смысл мы раскроем подробнее в одной из следующих публикаций. ОБНОВЛЕНО (1 мая 2019): см. «Расширяем и дополняем Kubernetes (обзор и видео доклада)».
Фильтрация
Слежение за объектами — это хорошо, но зачастую бывает необходимость реагировать на изменение каких-то свойств объекта, например, на изменение количества реплик в Deployment’е или на изменение лейблов объекта.
Когда приходит событие, shell-operator получает JSON-манифест объекта. Можно выделить в этом JSON интересующие нас свойства и запускать хук только при их изменениях. Для этого предусмотрено поле
jqFilter, где нужно указать выражение jq, которое будет применено к JSON-манифесту.Например, чтобы реагировать на изменение лейблов у объектов Deployment, нужно отфильтровать поле
labels из поля metadata. Конфиг будет такой:cat <<EOF
{
"onKubernetesEvent": [
{ "kind": "deployment",
"event":["update"],
"jqFilter": ".metadata.labels"
}
]}
EOFЭто выражение в jqFilter превращает длинный JSON-манифеста Deployment'а в короткий JSON с лейблами:

shell-operator будет запускать хук только в тех случаях, когда изменится этот короткий JSON, а изменения в других свойствах будут игнорироваться.
Контекст запуска хука
Конфиг хука позволяет указать несколько вариантов событий — например, 2 варианта для событий от Kubernetes и 2 расписания:
{"onKubernetesEvent":[
{"name":"OnCreatePod",
"kind": "pod",
"event":["add"]
},
{"name":"OnModifiedNamespace",
"kind": "namespace",
"event":["update"],
"jqFilter": ".metadata.labels"
}
],
"schedule": [
{ "name":"every 10 min",
"crontab":"0 */10 * * * *"
}, {"name":"on Mondays at 12:10",
"crontab": "0 10 12 * * 1"
]}Небольшое отступление: да, shell-operator поддерживает запуск скриптов в стиле crontab. Более подробно можно почитать в документации.
Чтобы различать, в связи с чем был запущен хук, shell-operator создаёт временный файл и передаёт хуку путь к нему в переменной
BINDING_CONTEXT_TYPE. В файле лежит JSON-описание причины запуска хука. Например, каждые 10 минут хук будет запускаться с таким содержимым:[{ "binding": "every 10 min"}]… а в понедельник запустится с таким:
[{ "binding": "every 10 min"}, { "binding": "on Mondays at 12:10"}]Для
onKubernetesEvent срабатываний JSON будет побольше, т.к. оно содержит описание объекта:[
{
"binding": "onCreatePod",
"resourceEvent": "add",
"resourceKind": "pod",
"resourceName": "foo",
"resourceNamespace": "bar"
}
]Содержимое полей можно понять из их имён, а более подробно — прочесть в документации. Пример получения имени ресурса из поля
resourceName с помощью jq уже был показан в хуке, который тиражирует секреты:jq -r '.[0].resourceName' $BINDING_CONTEXT_PATHАналогичным образом можно получать и остальные поля.
Что дальше?
В репозитории проекта, в директории /examples, есть примеры хуков, которые готовы для запуска в кластере. При написании своих хуков можно брать их за основу.
Есть поддержка сбора метрик с помощью Prometheus — о доступных метриках написано в разделе METRICS.
Как легко догадаться shell-operator написан на Go и распространяется под Open Source-лицензией (Apache 2.0). Мы будем благодарны любой помощи по развитию проекта на GitHub: и звёздочкам, и issues, и pull requests.
Приоткрывая завесу тайны, также сообщим, что shell-operator — это небольшая часть нашей системы, которая умеет поддерживать в актуальном состоянии дополнения, установленные в кластере Kubernetes, и осуществляет различные автоматические действия. Подробнее об этой системе мы рассказали буквально в понедельник на HighLoad++ 2019 в Санкт-Петербурге — видео и расшифровку этого доклада вскоре опубликуем.
У нас есть план открыть и остальные части этой системы: addon-operator и нашу коллекцию хуков и модулей. Кстати, addon-operator уже доступен на GitHub, но документация к нему пока в пути. Релиз коллекции модулей планируется летом.
Stay tuned!
P.S.
Читайте также в нашем блоге:
- «Готовить Kubernetes-кластер просто и удобно? Анонсируем addon-operator»;
- «Расширяем и дополняем Kubernetes (обзор и видео доклада)»;
- «Операторы для Kubernetes: как запускать stateful-приложения»;
- «Представляем новый плагин для Grafana — Statusmap panel»;
- «Представляем loghouse — Open Source-систему для работы с логами в Kubernetes»;
- «Официально представляем dapp — DevOps-утилиту для сопровождения CI/CD».
