

Современная веб-инфраструктура состоит из множества компонентов разного назначения, имеющих очевидные и не очень взаимосвязи. Это становится особенно хорошо видно при эксплуатации приложений, использующих разные программные стеки, что с приходом микросервисов стало встречаться буквально на каждом шагу. Ко всеобщему «веселью» добавляются и внешние факторы (сторонние API, сервисы и т.п.), что усложняют и без того непростую картину.
В общем, даже если эти приложения и будут объединены общими архитектурными идеями и решениями, для устранения необычных проблем в них зачастую приходится пробираться через очередные незнакомые дебри. Случатся ли такие проблемы — лишь вопрос времени. Вот таким примерам из нашей последней практики и посвящена эта статья. В ролях: Golang, Sentry, RabbitMQ, nginx, PostgreSQL и другие.
История №1. Golang и HTTP/2
Запуск бенчмарка, выполняющего множество HTTP-запросов к веб-приложению привел к неожиданным результатам. Простое приложение на Go в процессе бенчмарка идёт в другое приложение на Go, находящееся за ingress/openresty. При включенном HTTP/2 на часть запросов мы получаем ошибки с кодом 400. Чтобы понять причину этого поведения, мы убрали из цепочки Go-приложение на дальнем конце и сделали простой location в Ingress, который всегда отдаёт 200. Поведение не изменилось!
Тогда было решено воспроизвести сценарий вне окружения Kubernetes — на другой железке. В итоге получился Makefile, с помощью которого запускаются два контейнера: в одном — бенчмарки, идущие в nginx, в другом — в Apache. И тот, и другой слушают HTTP/2 с самоподписанным сертификатом. Итоговые наработки см. в этом репозитории.
Запустим бенчмарки с
concurrency=200:1.1. Nginx:
Completed 0 requests
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
----- Bench results begin -----
Requests per second: 10336.09
Failed requests: 1623
----- Bench results end -----1.2. Apache:
…
----- Bench results begin -----
Requests per second: 11427.60
Failed requests: 0
----- Bench results end -----Предполагаем, что тут дело в менее строгой реализации HTTP/2 в Apache.
Попробуем с
concurrency=1000:2.1. Nginx:
…
----- Bench results begin -----
Requests per second: 11274.92
Failed requests: 4205
----- Bench results end -----2.2. Apache:
…
----- Bench results begin -----
Requests per second: 11211.48
Failed requests: 5
----- Bench results end -----При этом отметим, что результаты не воспроизводятся каждый раз: часть запусков проходит без проблем.
Поиск по issues в GitHub’е проекта Golang привел к #25009 и #32441. Через них мы вышли на PR 903: отключение HTTP/2 в Go по умолчанию!
Интерпретировать результаты benchmark’ов без глубокого погружения в архитектуру вышеуказанных веб-серверов довольно сложно. В конкретном случае достаточно было отключить HTTP/2 для указанного сервиса.
История №2. Старая symfony и Sentry
В одном из проектов по-прежнему функционирует очень старая версия PHP-фреймворка symfony (v2.3). К ней «в комплекте» прилагается старый Raven-клиент и самописный класс в PHP, что немного осложняет отладку.
После переноса одного из сервисов в Kubernetes в Sentry, используемой для отслеживания ошибок в приложении этого проекта, внезапно перестали приходить события. Чтобы воспроизвести такое поведение, мы воспользовались примерами с сайта Sentry, взяв два варианта и скопировав DSN из настроек Sentry. Визуально всё работало: сообщения об ошибках (якобы) отправлялись одно за другим.
Вариант проверки на JavaScript:
<!DOCTYPE html>
<html>
<body>
<script src="https://browser.sentry-cdn.com/5.6.3/bundle.min.js" integrity="sha384-/Cqa/8kaWn7emdqIBLk3AkFMAHBk0LObErtMhO+hr52CntkaurEnihPmqYj3uJho" crossorigin="anonymous">
</script>
<h2>JavaScript in Body</h2>
<p id="demo">A Paragraph.</p>
<button type="button" onclick="myFunction()">Try it</button>
<script>
Sentry.init({ dsn: 'http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12' });
try {
throw new Error('Caught');
} catch (err) {
Sentry.captureException(err);
}
</script>
</body>
</html>
Аналогично на Python:
from sentry_sdk import init, capture_message
init("http://33dddd76e9f0c4ddcdb51@sentry.kube-dev.test//12")
capture_message("Hello World") # Will create an event.
raise ValueError()Однако в Sentry они не попадали. При отправке сообщения создается иллюзия, что сообщение отправлено, потому что клиенты сразу генерируют хэш для issue.
В итоге, проблема решилась очень просто: отправка событий шла на HTTP, а сервис Sentry слушал только на HTTPS. Редирект с HTTP на HTTPS был предусмотрен, однако старый клиент (код на стороне symfony) не умел следовать редиректам, чего по умолчанию в наши дни не ожидаешь.
История №3. RabbitMQ и стороннее прокси
В одном из проектов для подключения кассовых аппаратов используется облако Evotor. По сути оно работает как прокси: POST-запросы из Evotor попадают напрямую в RabbitMQ — через плагин STOMP, реализованный поверх WebSocket-подключений.
Один из разработчиков делал тестовые запросы с помощью Postman и получал ожидаемые ответы
200 OK, однако запросы через облако приводили к неожиданным 405 Method Not Allowed.200 OK
source: kubernetes
namespace: kube-nginx-ingress
host: kube-node-2
pod_name: nginx-2bpt7
container_name: nginx
stream: stdout
app: nginx
controller-revision-hash: 5bdbfd564
pod-template-generation: 25
time: 2019-09-10T09:42:50+00:00
request_id: 1271dba228f0943ab2df0196ff0d7f67
user: client
address: 100.200.300.400
protocol: HTTP/1.1
scheme: http
method: POST
host: rmq-review.kube-dev.client.domain
path: /api/queues/vhost/queue.gen.eeeeffff111:1.onlinecassa:55556666/get
request_query:
referrer:
user_agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36
content_kind: cacheable
namespace: review
ingress: stomp-ws
service: rabbitmq
service_port: stats
vhost: rmq-review.kube-dev.client.domain
location: / nginx_upstream_addr: 10.127.1.1:15672
nginx_upstream_bytes_received: 2538
nginx_upstream_response_time: 0.008
nginx_upstream_status: 200
bytes_received: 757
bytes_sent: 1254
request_time: 0
status: 200
upstream_response_time: 0
upstream_retries: 0405 Method Not Allowed
source: kubernetes
namespace: kube-nginx-ingress
host: kube-node-1
pod_name: nginx-4xx6h
container_name: nginx
stream: stdout
app: nginx
controller-revision-hash: 5bdbfd564
pod-template-generation: 25
time: 2019-09-10T09:46:26+00:00
request_id: b8dd789604864c95b4af499ed6805630
user: client
address: 200.100.300.400
protocol: HTTP/1.1
scheme: http
method: POST
host: rmq-review.kube-dev.client.domain
path: /api/queues/vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get
request_query:
referrer:
user_agent: ru.evotor.proxy/37
content_kind: cache-headers-not-present
namespace: review
ingress: stomp-ws
service: rabbitmq
service_port: stats
vhost: rmq-review.kube-dev.client.domain
location: /
nginx_upstream_addr: 10.127.1.1:15672
nginx_upstream_bytes_received: 134
nginx_upstream_response_time: 0.004
nginx_upstream_status: 405
bytes_received: 878
bytes_sent: 137
request_time: 0
status: 405
upstream_response_time: 0
upstream_retries: 0Tcpdump запроса от Evotor
200.100.300.400.21519 > 100.200.400.300: Flags [P.], cksum 0x8e29 (correct), seq 1:879, ack 1, win 221, options [nop,nop,TS val 2313007107 ecr 79097074], length 878: HTTP, length: 878
POST /api/queues//vhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1
device-model: ST-5
device-os: android
Accept-Encoding: gzip
content-type: application/json; charset=utf-8
connection: close
accept: application/json
x-original-forwarded-for: 10.11.12.13
originhost: rmq-review.kube-dev.client.domain
x-original-uri: /api/v2/apps/e114-aaef-bbbb-beee-abadada44ae/requests
x-scheme: https
accept-encoding: gzip
user-agent: ru.evotor.proxy/37
Authorization: Basic
X-Evotor-Store-Uuid: 20180417-73DC-40C9-80B7-00E990B77D2D
X-Evotor-Device-Uuid: 20190909-A47B-40EA-806A-F7BC33833270
X-Evotor-User-Id: 01-000000000147888
Content-Length: 58
Host: rmq-review.kube-dev.client.domain
{"count":1,"encoding":"auto","ackmode":"ack_requeue_true"}[!http]
12:53:30.095385 IP (tos 0x0, ttl 64, id 5512, offset 0, flags [DF], proto TCP (6), length 52)
100.200.400.300:80 > 200.100.300.400.21519: Flags [.], cksum 0xfa81 (incorrect -> 0x3c87), seq 1, ack 879, win 60, options [nop,nop,TS val 79097122 ecr 2313007107], length 0
12:53:30.096876 IP (tos 0x0, ttl 64, id 5513, offset 0, flags [DF], proto TCP (6), length 189)
100.200.400.300:80 > 200.100.300.400.21519: Flags [P.], cksum 0xfb0a (incorrect -> 0x03b9), seq 1:138, ack 879, win 60, options [nop,nop,TS val 79097123 ecr 2313007107], length 137: HTTP, length: 137
HTTP/1.1 405 Method Not Allowed
Date: Tue, 10 Sep 2019 10:53:30 GMT
Content-Length: 0
Connection: close
allow: HEAD, GET, OPTIONS
Tcpdump запроса, сделанного curl
777.10.74.11.61211 > 100.200.400.300:80: Flags [P.], cksum 0x32a8 (correct), seq 1:397, ack 1, win 2052, options [nop,nop,TS val 734012594 ecr 4012360530], length 396: HTTP, length: 396
POST /api/queues/%2Fvhost/queue.gen.ef7fb93387ca9b544fc1ecd581cad4a9:1.onlinecassa:55556666/get HTTP/1.1
Host: rmq-review.kube-dev.client.domain
User-Agent: curl/7.54.0
Authorization: Basic =
Content-Type: application/json
Accept: application/json
Content-Length: 58
{"count":1,"ackmode":"ack_requeue_true","encoding":"auto"}[!http]
12:40:11.001442 IP (tos 0x0, ttl 64, id 50844, offset 0, flags [DF], proto TCP (6), length 52)
100.200.400.300:80 > 777.10.74.11.61211: Flags [.], cksum 0x2d01 (incorrect -> 0xfa25), seq 1, ack 397, win 59, options [nop,nop,TS val 4012360590 ecr 734012594], length 0
12:40:11.017065 IP (tos 0x0, ttl 64, id 50845, offset 0, flags [DF], proto TCP (6), length 2621)
100.200.400.300:80 > 777.10.74.11.61211: Flags [P.], cksum 0x370a (incorrect -> 0x6872), seq 1:2570, ack 397, win 59, options [nop,nop,TS val 4012360605 ecr 734012594], length 2569: HTTP, length: 2569
HTTP/1.1 200 OK
Date: Tue, 10 Sep 2019 10:40:11 GMT
Content-Type: application/json
Content-Length: 2348
Connection: keep-alive
Vary: Accept-Encoding
cache-control: no-cache
vary: accept, accept-encoding, originНатренированный глаз инженера сразу видит разницу:
- curl:
POST /api/queues/%2Fclient… - Evotor:
POST /api/queues//client…
Дело было в том, что в одном случае прилетал непонятный (для RabbitMQ)
//vhost, а в другом — закодированный обычным образом %2Fvhost, что является вполне ожидаемым поведением при:# rabbitmqctl list_vhosts
Listing vhosts ...
/vhostВ issue проекта RabbitMQ по этой теме разработчик разъясняет:
We will not be replacing %-encoding. It's a standard way of URL path encoding and has been for ages. Assuming that %-encoding in HTTP-based tools will go away because of even the most popular framework assuming such URL paths are «malicious» is shortsighted and naive. Default virtual host name can be changed to any value (such as one that does not use slashes or any other characters that require %-encoding) and at least with the Pivotal BOSH release of RabbitMQ, the default virtual host is deleted at deployment time anyway.
Проблема решилась без дальнейшего участия наших инженеров (на стороне Evotor после обращения к ним).
История №4. Джин в PostgreSQL
СУБД PostgreSQL может похвастать очень полезным индексом, о котором часто забывают. Эта история началась с жалоб на тормоза в работе приложения. В недавней статье мы уже приводили в пример приблизительный workflow при анализе подобных ситуаций. Вот и здесь наш APM — Atatus — показал следующую картину:

В 10 утра наблюдается рост времени, которое приложение тратит на работу с базой. Как и ожидалось, причина кроется в медленных ответах СУБД. Для нас анализ запросов, выявление проблемных мест и «навешивание» индексов — понятная рутина. В ней очень помогает используемый нами okmeter: есть как стандартные панели для мониторинга состояния серверов, так и возможность быстро построить свою — с выводом проблемных метрик:

Графики загрузки CPU указывают, что одна из баз нагружена на 100%. Почему? Подскажут новые панели PostgreSQL:

Сразу налицо причина проблем — главный потребитель CPU:
SELECT u.* FROM users u WHERE
u.id = ? & u.field_1 = ? AND u.field_2 LIKE '%somestring%'
ORDER BY u.id DESC LIMIT ?Рассматривая план работы проблемного запроса, мы выяснили, что фильтрация по индексированным полям таблицы дает слишком большую выборку: база получает более 70 тысяч строк по
id и field_1, а затем занимается поиском подстроки среди них. Получается, что LIKE по подстроке перебирает большой объем текстовых данных, что и приводит к серьезному замедлению выполнения запроса и росту нагрузки на CPU.Здесь можно справедливо заметить, что не исключена архитектурная проблема (требуется корректировка логики приложения или даже полнотекстовый движок…), но времени на переделку нет, а работать быстро оно было должно 15 минут назад. При этом поисковое слово — фактически идентификатор (и почему не в отдельном поле?..), который выдает единицы строк. Фактически, если бы мы могли составить индекс по этому текстовому полю, все прочие станут ненужными.
Итоговое текущее решение — добавление GIN-индекса по полю
field_2. Вот и виновник торжества — тот самый «джин». Если вкратце, GIN — это разновидность индекса, который отлично себя показывает при полнотекстовом поиске, качественно ускоряя его. Подробнее почитать о нём можно, например, в этом замечательном материале.
Как видно, эта простая операция позволила убрать лишнюю нагрузку, а вместе с ней — и сэкономить денег клиенту.
История №5. Кэширование s3 в nginx
S3-совместимые облачные хранилища давно и прочно вошли в списки используемых технологий многих проектов. Если вам нужно надежное хранилище картинок для сайта или для данных нейросети, Amazon S3 — отличный выбор. Надежность хранения и высокая доступность данных (и отсутствие необходимости «городить огород») подкупает.
Однако порой для экономии денег — ведь обычно оплата за S3 идет за запросы и за трафик — неплохим решением станет установка кэширующего прокси-сервера перед хранилищем. Такой способ позволит уменьшить затраты, когда речь идет, например, об аватарках пользователей, коих на каждой странице бывает много.
Казалось бы, что проще, чем взять nginx и настроить проксирование с кэшированием, ревалидацией, фоновым обновлением и прочим блэкджеком? Однако, как и везде, есть свои нюансы…
Примерный конфиг такого проксирования с кэшированием выглядел у нас так:
proxy_cache_key $uri;
proxy_cache_methods GET HEAD;
proxy_cache_lock on;
proxy_cache_revalidate on;
proxy_cache_background_update on;
proxy_cache_use_stale updating error timeout invalid_header http_500 http_502 http_503 http_504;
proxy_cache_valid 200 1h;
location ~ ^/(?<bucket>avatars|images)/(?<filename>.+)$ {
set $upstream $bucket.s3.amazonaws.com;
proxy_pass http://$upstream/$filename;
proxy_set_header Host $upstream;
proxy_cache aws;
proxy_cache_valid 200 1h;
proxy_cache_valid 404 60s;
}И в целом он работал: картинки отображались, с кэшем все было отлично… однако всплыли проблемы с AWS S3-клиентами. В частности, перестал работать клиент из aws-sdk-php. Анализ логов nginx показал, что на HEAD-запросы upstream возвращал код 403, а ответ содержал конкретную ошибку:
SignatureDoesNotMatch. Когда мы увидели, что nginx при этом делает GET-запрос к upstream’у, всё встало на свои места.Дело в том, что S3-клиент подписывает каждый свой запрос, а сервер эту подпись проверяет. В случае простого проксирования все работает отлично: запрос доходит до сервера в неизменном виде. Однако при включении кэширования nginx начинает оптимизировать работу с backend’ом и заменяет HEAD-запросы на GET. Логика проста: лучше получить и сохранить объект целиком, а потом все HEAD-запросы тоже выполнять из кэша. Однако в нашем случае запрос модифицировать нельзя — ведь он подписан.
Решений по сути два:
- не гонять S3-клиенты через прокси;
- если же «так надо» — необходимо выключить опцию
proxy_cache_convert_headи добавить$request_methodв ключ кэширования. В этом случае nginx передает HEAD-запросы «как есть» и кэширует ответы на них отдельно.
История №6. DDoS и Google User Content
Воскресный вечер не предвещал проблем, пока — внезапно! — не выросла очередь инвалидации кэша на edge-серверах, что отдают трафик реальным пользователям. Это очень странный симптом: ведь кэш реализован в памяти и не завязан на жесткие диски. Сброс кэша в используемой архитектуре — дешевая операция, поэтому данная ошибка может появиться только в случае реально высокой нагрузки. Это подтвердилось тем, что те же самые серверы начали оповещать о появлении 500-х ошибок (всплески красной линии на графике ниже).

Такой резкий всплеск привёл и к перерасходу CPU:
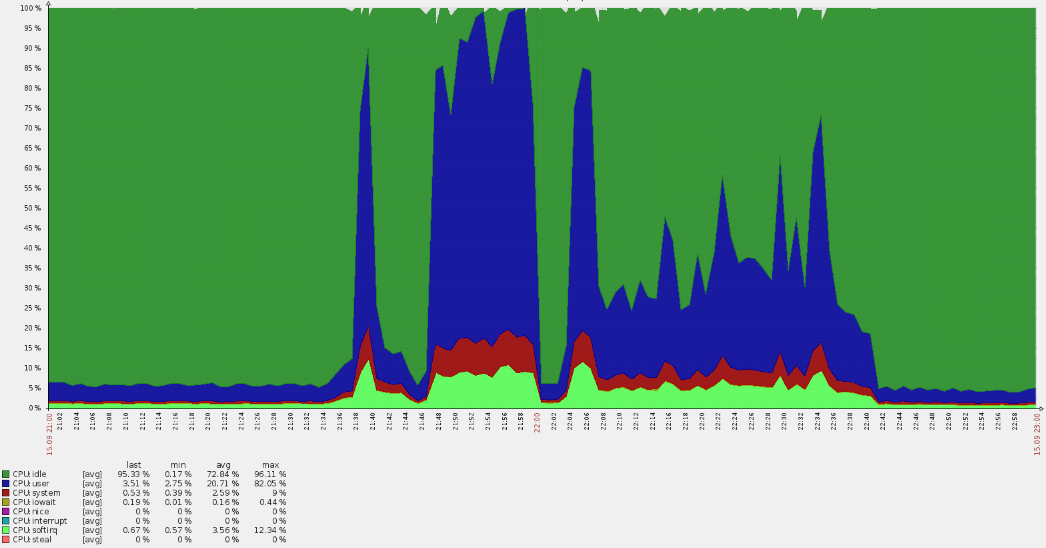
Беглый анализ показал, что запросы приходили не на основные домены, а из логов стало ясно, что они попадают в default vhost. Попутно выяснилось, что на российский ресурс пришло множество американских пользователей. Такие обстоятельства всегда сразу вызывают вопросы.
Собрав данные с логов nginx, мы выявили, что имеем дело с неким ботнетом:
35.222.30.127 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?ITPDH=XHJI" HTTP/1.1 301 178 "http://example.ru/ORQHYGJES" "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?ITPDH=XHJI" "redirect=http://www.example.ru/?ITPDH=XHJI" ancient=1 cipher=- "LM=-;EXP=-;CC=-"
107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?REVQSD=VQPYFLAJZ" HTTP/1.1 301 178 "http://www.usatoday.com/search/results?q=MLAJSBZAK" "Mozilla/5.0 (Windows; U; MSIE 7.0; Windows NT 6.0; en-US)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?REVQSD=VQPYFLAJZ" "redirect=http://www.example.ru/?REVQSD=VQPYFLAJZ" ancient=1 cipher=- "LM=-;EXP=-;CC=-"
107.178.215.0 US [15/Sep/2019:21:40:00 +0300] GET "http://example.ru/?MPYGEXB=OMJ" HTTP/1.1 301 178 "http://engadget.search.aol.com/search?q=MIWTYEDX" "Mozilla/5.0 (Windows; U; Windows NT 6.1; en; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3 (.NET CLR 3.5.30729)" "-" "upcache=-" "upaddr=-" "upstatus=-" "uplen=-" "uptime=-" spdy="" "loc=wide-closed.example.ru.undef" "rewrited=/?MPYGEXB=OMJ" "redirect=http://www.example.ru/?MPYGEXB=OMJ" ancient=1 cipher=- "LM=-;EXP=-;CC=-"В логах прослеживается понятный шаблон:
- верный user-agent;
- запрос на корневой URL со случайным GET-аргументом, чтобы избежать попадания в кэш;
- referer показывает, будто запрос пришел из поискового движка.
Собираем адреса и проверяем их принадлежность — все они относятся к
googleusercontent.com, причём двум подсетям (107.178.192.0/18 и 34.64.0.0/10). В этих подсетях находятся виртуальные машины GCE и различные сервисы, такие как перевод страниц.К счастью, атака продолжалась не так долго (около часа) и постепенно уменьшалась. Похоже, сработали защитные алгоритмы внутри Google, благодаря чему проблема решилась «сама собой».
Эта атака не оказалась разрушительной, но подняла полезные вопросы на будущее:
- Почему не сработал anti-ddos? Используется внешний сервис, в который мы отправили соответствующий запрос. Однако адресов было очень много…
- Как защититься от подобного в дальнейшем? В нашем случае возможны даже варианты закрытия доступа по географическому принципу.
P.S.
Читайте также в нашем блоге:
