
Осенью прошлого года на конференции DevOops 2019 прозвучал доклад «10 лет on-call. Чему мы научились?». В нём рассказывается о том, почему мы отказались от внутреннего «акселератора» по развитию дежурных до DevOps-инженеров, как эволюционировала наша служба технической поддержки и система обработки инцидентов в целом.

Представляем видео с докладом (~63 минуты, гораздо информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
Начнём с определения той области, о которой пойдёт речь. Есть множество способов мониторить что-либо (на слайде не представлен и 1 % из них). Все они отправляют нечто, что нужно обработать (алерты), причём сделать это по-настоящему качественно (как условный Нео из «Матрицы»):

Доклад о том, какие инструменты нам — компании «Флант», имеющей достаточно специфичный контекст, — пришлось придумать, чтобы приблизиться к возможностям Нео.
80 % выступления посвящено тому, как летят алерты и что мы делаем, чтобы с ними справиться. Остальные 20 % — про культурные и организационные моменты, которые нам пришлось применять за историю существования компании.
Повторюсь, что у нас достаточно специфичный случай: мы берём ответственность за чужую инфраструктуру, переделывая её и отвечая за её доступность. Поэтому обработка инцидентов — один из ключевых вопросов для нас, к которому мы постоянно возвращались на протяжении всей жизни компании.
Что у нас было 10-11 лет назад? В компании работало несколько человек. Все алерты приходили на мой мобильный телефон, я их просматривал и уходил чинить то, что требовало внимания.
В действительности всё было не так плохо, потому что мы не пытались отправлять алерты по любому поводу (вроде закончившегося места на диске). Мониторинг работал для бизнес-показателей высокого уровня: грубо говоря, были cron-скрипты, которые проверяли, что что-то важное для бизнеса точно работает, и отправляли SMS в случае проблем. Система очень примитивная, но на тот момент она устраивала.
Шло время, росло число инцидентов. В какой-то момент я осознал, что страшно просыпаться утром: ведь в телефоне можно увидеть, например, 600 непрочитанных сообщений. Тогда мы решили ситуацию так: «Давайте я не буду это делать один. Давайте все по очереди». В компании было 5-6 человек: когда подобное дежурство происходит раз в неделю, всё уже не так плохо.
Шло время, росло количество проектов и сотрудников. Мы дошли до состояния: «Давайте не будем сами смотреть SMS'ки [именно так мы по-прежнему называли алерты], а попросим делать это кого-нибудь ещё». И сделали первую линию поддержку, хотя ещё тогда понимали, что это неправильно.
К слову, такие изменения в организации требовали и изменений в технике. Когда дежуришь один, всё отправляется в одну точку, а здесь уже требуется возможность определения многих мест и переключения между ними. У нас даже была «мощнейшая» система под названием «Журнал SMS»: в ней были все записи (алерты), которые специальный человек просматривал. Если какие-то из алертов часто появлялись, он звонил дежурному и указывал на эту проблему.
Всё это по-прежнему ужасно, но до какого-то момента решало наши задачи. Когда сотрудников стало около 30, несмотря на наличие выделенной группы L1, ситуация была проблемной с обеих сторон:
Остановлюсь подробнее на том, что мы сделали и осознали на этот период.

Алерты разделяются на два типа:

Таким образом, у алерта может быть состояние. И обязательно использовать протокол, который понимает такие состояния.
Ещё одна популярная проблема — «мигание» алерта, когда он то загорается, то пропадает. Благодаря тому, что набор лейблов — уникальный идентификатор алерта, мы можем делать дедупликацию, объединяя такие алерты в серии. Каждая серия — группа событий, с которой удобно работать (вместо того, чтобы проводить такое объединение каждый раз мысленно).
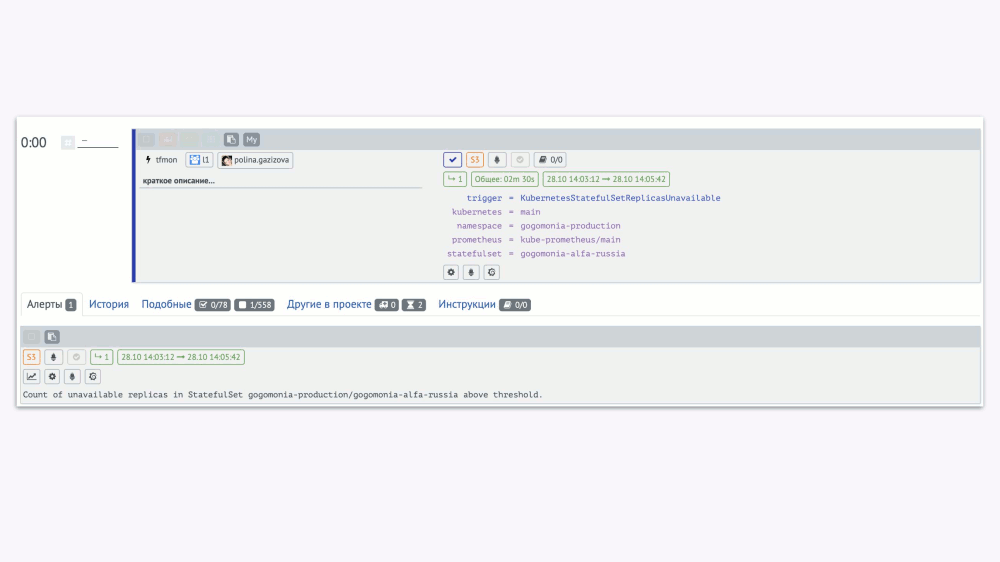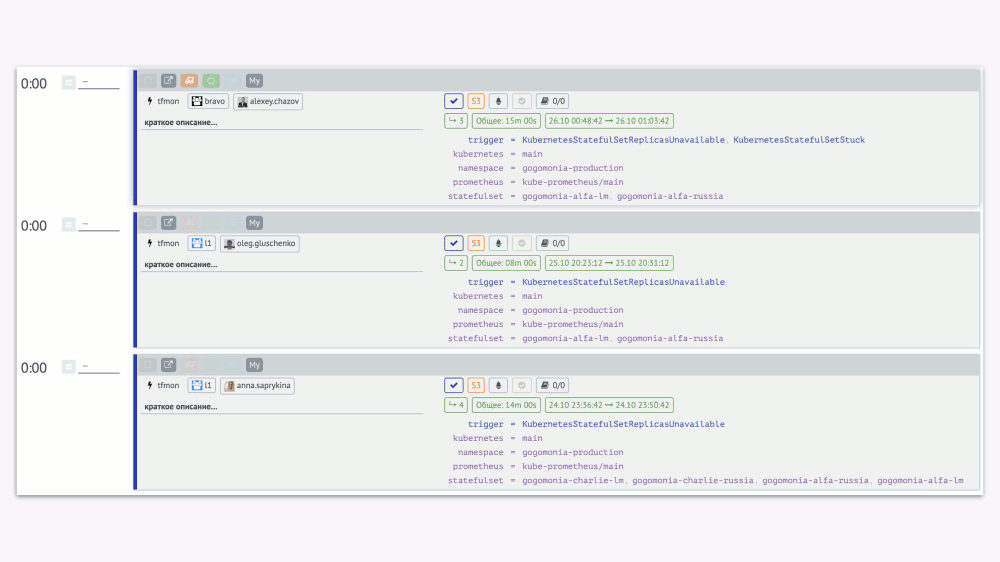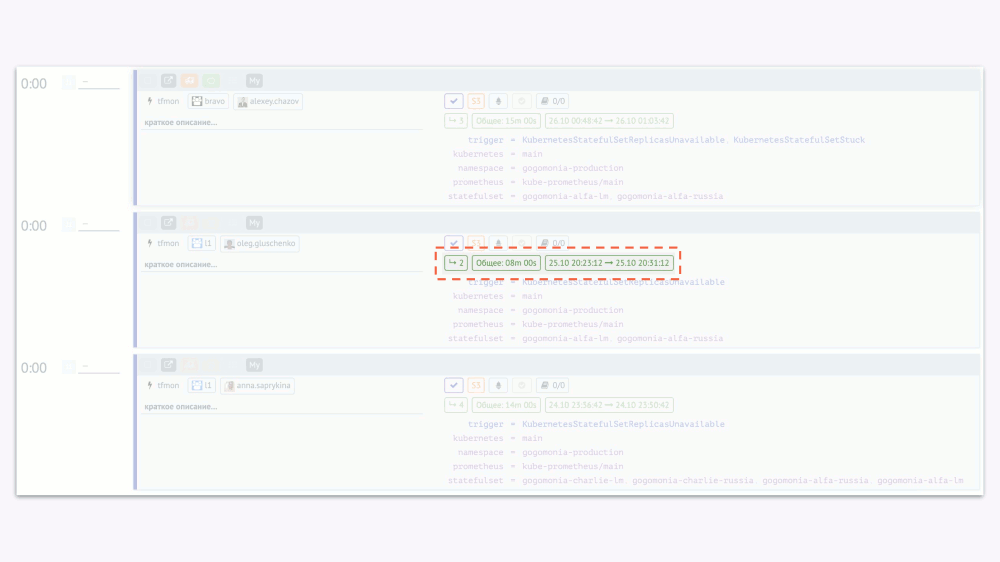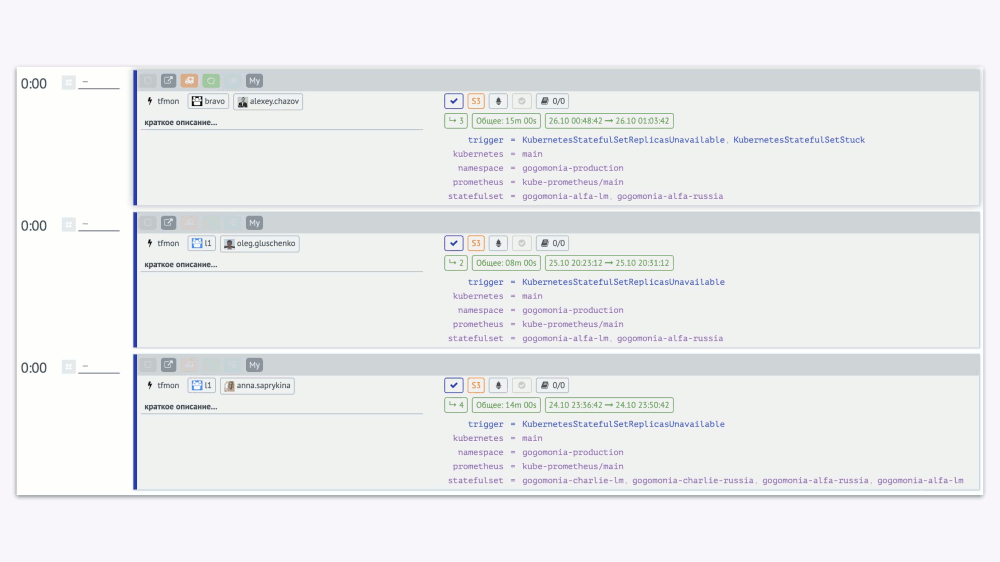
Вот как это автоматическое склеивание выглядит у нас в интерфейсе. В верхней части — инцидент, а ниже — набор из алертов (всего их 7, но в экран на скриншоте поместились только 2).
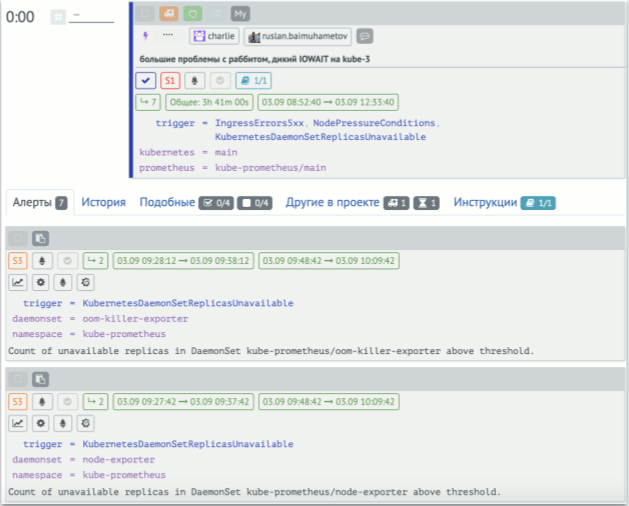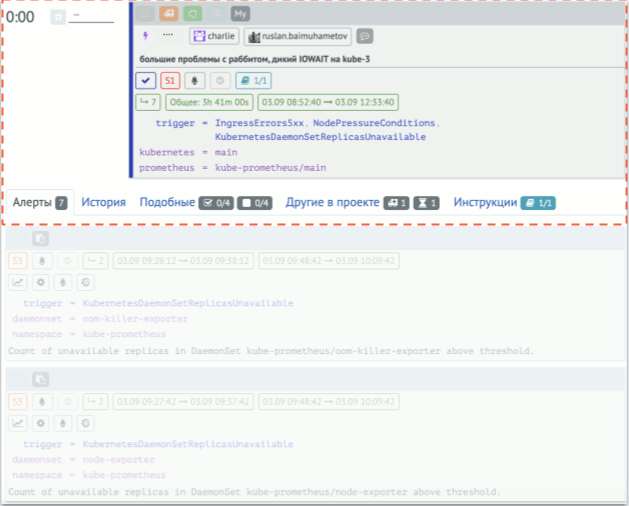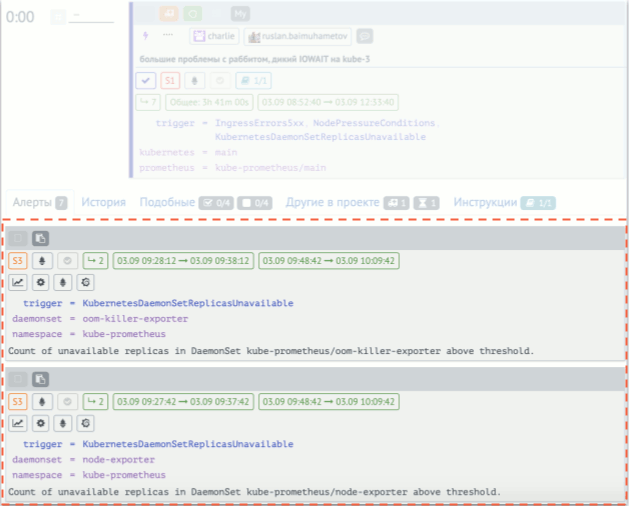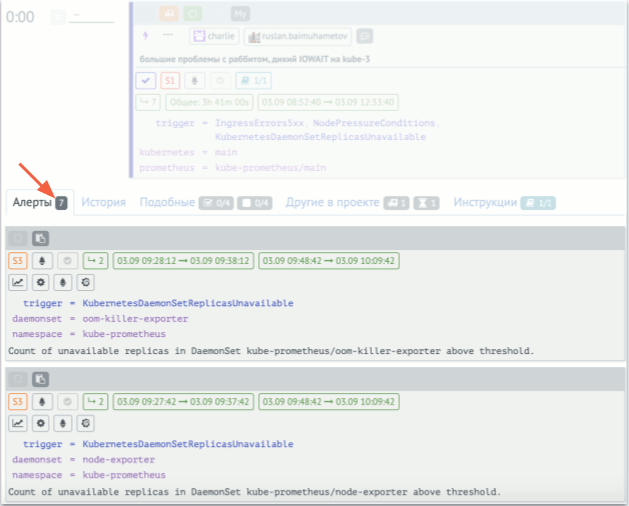
Если у алерта есть статус (горит/не горит), то инциденты уже практически становятся тикетами, у которых есть рабочий процесс. В его основе — триаж (медицинская сортировка) и последующая «неотложка» или «надо делать» (или же просто сразу закрыть). У нас процесс чуть более сложный, но подробно останавливаться на нём не буду:

Ключевая же идея в том, что, если вы начали всерьёз подходить к обработке инцидентов, то каждый инцидент должен стать тикетом, который имеет свой рабочий процесс, соответствующий вашим требованиям и особенностям.
Однако ни одна система тикетов не рассчитана на то, чтобы обеспечить гарантию доставки. Если кто-то завёл тикет, а его увидели не сразу, то ничего страшного, как правило, не произошло. У этих решений попросту нет первичной важности в таком вопросе. А для нас критично, чтобы в течение десятков секунд дежурные на L1 увидели алерт, чтобы в течение минуты подтвердили это (не вникли в него, не приняли решение, но уже увидели, начали им заниматься).
Когда вы меняете исполнителя в тикете, он подтверждает, что согласен с этим изменением? В нашем случае такое подтверждение обязано быть — это как эстафетная палочка, передаваемая между инженерами.
Когда мы всё это сделали, жизнь стала сильно лучше: мы перестали что-либо упускать, заметно (раз в 5) выросла пропускная способность в обработке инцидентов.
Однако через 2-3 года мы столкнулись со старой проблемой: наша техподдержка, которая теперь уже состояла из двух линий (L1 и L2), не успевала диагностировать инциденты. Её работа преимущественно сводилась к тому, чтобы либо сразу кому-то звонить об инциденте, либо ожидать, что он «сам пройдёт».
Культурно-организационная проблема, лежащая в основе, никуда не делась. Однако перед тем, как перейти к разным организационным схемам, которые мы успели попробовать, поделюсь ещё несколькими менее очевидными соображениями про технологии для работы с инцидентами.
Слово «инцидент» вызывает эмоции, схожие со словом «пожар». Однако в случае с пожаром всем понятно, что надо взять огнетушитель и тушить до тех пор, пока он не будет полностью ликвидирован, и останавливаться до этого времени недопустимо. С инцидентом же возможен случай, когда он «наполовину потушен»: первые меры были приняты, а дальше от нас ничего не зависит.
Например, сервер с одной из реплик сломался и ему надо заказать новый диск. Диск заказали, а поскольку это лишь одна из реплик, которая может быть недоступна несколько дней, пока диск едет, мы не будем исправлять алерты во всех используемых системах мониторинга — это трудозатратно. В результате, у нас висит инцидент, но каких-либо действий сейчас он не требует.
А представьте себе, что три таких инцидента горят, хотя на самом деле они не горят. Когда появится четвёртый, отношение к нему уже будет такое: «Ещё одна вещь, которая горит… Ну и что?» Чтобы избавиться от подобного психологического эффекта, «полупотушенные» инциденты надо попросту убрать, но сделать это правильно. Я называю это умный игнор, а его идея сводится к операции «отложить инцидент»:
Однако тут есть важный момент: если алерт был отложен, но каких-то ошибок (например, 500-х кодов у страницы веб-приложения) сначала было мало (0,1%), а потом стало много (20%), эту ситуацию можно упустить. Поэтому мы делаем разные уровни severity у алертов на разную частоту ошибок: если уровень меняется, такое изменение считается существенным, поэтому отложенный алерт снова всплывает и требует принятия решения.
В мониторинге в целом есть сложная проблема: мониторинг мониторинга. Правильный подход в его реализации по сути сводится к тому, что каждый источник алертов должен постоянно отправлять специальные сообщения «Я всё ещё жив», а система, принимающая алерты, — отслеживать наличие таких сообщений и поднимать тревогу в случае их отсутствия. Ещё одна полезная необходимость здесь — это отслеживать все алерты, отправляемые в некорректном формате (иначе они будут потеряны, а вы об этом даже не узнаете).
Следующая проблема — поиск. Поскольку всё сделано на лейблах, сходу получился понятный язык (MQL) для поиска алертов и инцидентов:

Наличие языка запросов принесло и другое важное удобство. С помощью маршрутизации алертов инженер, выполняющий какие-то временные работы, может в той же единой системе зафиксировать себя как ответственное лицо для конкретных алертов. Так дежурный будет сразу знать, к кому обращаться, если возникает проблема, попадающая под определённые условия:

Когда обработкой алертов занимаются много сотрудников, вам потребуется очень много времени, чтобы узнать о каком-либо надоедливом алерте, что случается каждый день, но один раз. Решению этой проблемы способствует горячая аналитика. Возле каждого инцидента мы показываем другие «подобные». Можно увидеть их количество, увидеть их полный список, кем они обрабатывались, когда и за какое время. А после этого поднять проблему на очередной встрече:
Теперь я расскажу о вариантах организации работы, через которые мы прошли:

Но начать стоит с объяснения, почему L1 в нашем случае не работает в принципе. У меня есть несколько связанных примеров:
Это всё о том, когда рациональное поведение одного человека не приводит к рациональному поведению группы.
В контексте алертов: инженер понимает, что этот алерт куда-то там придёт (к дежурному), там с ним разберутся, поэтому нормально можно не делать. Мы решим проблему людьми (дежурными). А со временем, когда таких алертов становится всё больше, случается уже описанная проблема: дежурные на L1 страдают, что вообще не успевают ничего делать из-за количества алертов, а инженеры тоже недовольны: им казалось, что на L1 ничего не делают.
Наша попытка исправить это была такова:

Однако закончилось всё плачевно. На L1 и L2 люди исполняли свои обязанности с чувством, что это временно, а в целом они такой работой заниматься не хотят (потому что хотят быть инженерами). Итог: ни первая, ни вторая цели не были достигнуты.
К чему мы пришли? Всех дежурных убрали, а на обработке инцидентов работают люди, которые отвечают только за две функции: 1) эскалация, 2) коммуникация. Они ничего не знают о том, что это за инцидент и что с ним (технически) делать. А сами проблемы разбирают те же инженеры из команд, которые создавали алерты и отвечают за соответствующую инфраструктуру.

Вернёмся к общей схеме:
В компаниях, где часто что-то меняется, весьма актуальна ещё одна проблема: документация. У вас 10 человек, которые дежурят по очереди. Пришёл очередной алерт: кто его сделал и чего от меня здесь хотят? И каждое изменение в ответе на этот вопрос нужно доносить до всех дежурных. Очевидное решение: документирование всего, что не входит в сам алерт, в отдельной системе, где с помощью уже упомянутого языка запросов (MQL) описаны алерты, к которым инструкции относятся.
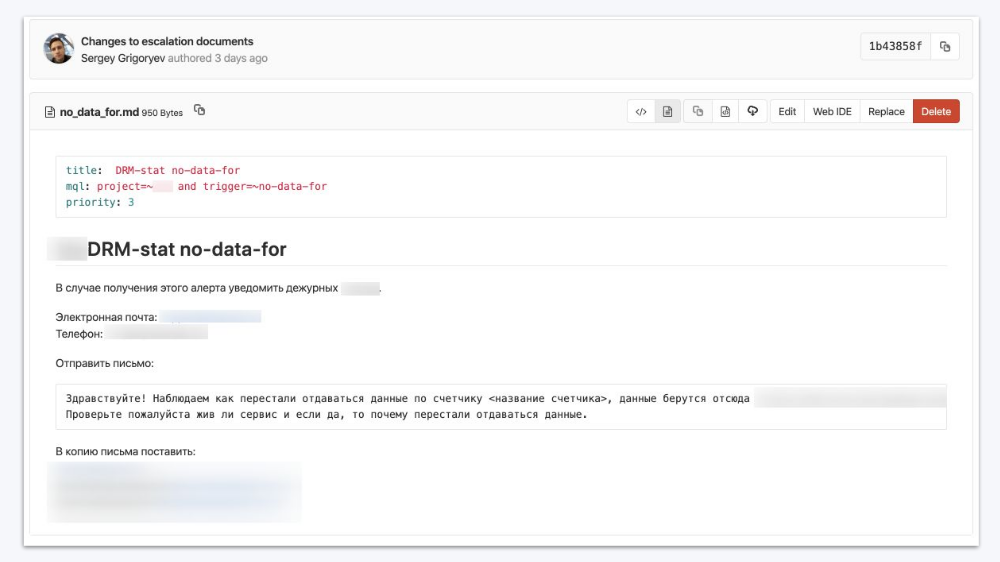
Эта документация показывается при открытии алерта, у неё есть кнопка «Прочитал(а)». Если при следующем срабатывании алерта что-то в документации изменилось, дежурному будет показан соответствующий diff.
Остался главный вопрос, о котором говорили уже миллионы раз… Вот три основных варианта ответов:

Если мы используем внутренние показатели, у нас появляется очень много «шума». А если мы смотрим на показатели доступности или бизнес-метрики, то узнаём об аварии только тогда, когда она уже произошла. Эта дилемма — в основе всего вопроса, что же мониторить. Как мы попытались ответить на такой вопрос (для себя)?..
У каждого есть своё представление том, чему соответствуют разные уровни severity и priority, и каждый по-своему прав:

Мы пришли к тому, что определяем severity в двух координатах (влияние и вероятность):
Например, закончилось место на диске:
С таким фреймворком мы и измеряем severity по шкале от 1 до 9. Так мы между собой договорились, что это не абстрактные WARNING или INFO, а что-то более конкретное.
В контексте необходимости отделения окружения мы пошли дальше и ввели для себя уровни обслуживания (service level). При поступлении алерта требуется ответить на вопрос: надо ли нам его обрабатывать? Если да, то как срочно?

Отправляя множество алертов, мы на них по сути вручную не реагируем — спасибо автоматизации разбора. Часть алертов не требует быстрого вмешательства: о них мы вспомним во время ретроспективы. Другая часть собирается в группы, которые обрабатываются в обычное рабочее время — пачками, что гораздо удобнее. В результате, алертов, требующих обработки сразу, остаётся не так много:

Когда вы создаёте алерт, то указываете некое пороговое значение и период. Например: «если у меня load average больше такого порога на протяжении такого периода». С этим периодом есть дилемма. С одной стороны, 20 минут для того же load average — много, потому что всё уже умрёт. С другой стороны — о всплесках в 2 минуты можно ничего не узнать, а если поставить порог в 1 минуту, то дежурного завалит сообщениями.
Мы для себя решили ставить периоды очень маленькими и всегда слать алерты в систему. Но алерты приходят в статусе «pending» и для них определяется то время, которое они должны гореть, чтобы стать «настоящими». Таким образом, мы перенесли pending из источников мониторинга в центральную систему. Благодаря этому, если алерт так и не стал «настоящим», он себя не проявил для дежурного, однако в системе остался — его можно увидеть при ретроспективе.
С появлением Kubernetes стали актуальными два момента:
А сейчас мы обдумываем идею написания ботов, которые будут разбирать алерты и (как минимум) автоматизировать эскалацию: на основании severity и service level мы определили, что проблема должна быть решена за 30 минут, поэтому, если инженер за 10 минут не справился, то автоматически зовём тимлида.
Чему мы научились?
Немного статистики, показывающей, к чему мы пришли:
На графике алерты — это не отдельные алерты, а их серии. События — когда что-то сломалось, починилось, сломалось, починилось… Благодаря имеющейся автоматике, огромное количество сообщений (миллионы в день!) сокращается до такого числа, которое по-прежнему реально обрабатывать каждый день.
Мы любим Open Source. Однако получившаяся система довольно специфична из-за своих масштабов и подходит далеко не для каждой компании. Если вам было бы интересно увидеть её в Open Source — пожалуйста, поделитесь ссылкой на этот доклад в Twitter/Facebook с хэштегом
Если же вы хотите рассмотреть вопрос внедрения такой системы, мы готовы заняться этим (с адаптацией под ваши потребности) — пишите на
А если у вас есть амбиции сделать из такой системы продукт — станьте нашим бизнес-партнёром! (Пишите на
Видео с выступления (~63 минуты):
Презентация доклада:
Среди других наших докладов:

Представляем видео с докладом (~63 минуты, гораздо информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
Введение
Начнём с определения той области, о которой пойдёт речь. Есть множество способов мониторить что-либо (на слайде не представлен и 1 % из них). Все они отправляют нечто, что нужно обработать (алерты), причём сделать это по-настоящему качественно (как условный Нео из «Матрицы»):

Доклад о том, какие инструменты нам — компании «Флант», имеющей достаточно специфичный контекст, — пришлось придумать, чтобы приблизиться к возможностям Нео.
80 % выступления посвящено тому, как летят алерты и что мы делаем, чтобы с ними справиться. Остальные 20 % — про культурные и организационные моменты, которые нам пришлось применять за историю существования компании.
Повторюсь, что у нас достаточно специфичный случай: мы берём ответственность за чужую инфраструктуру, переделывая её и отвечая за её доступность. Поэтому обработка инцидентов — один из ключевых вопросов для нас, к которому мы постоянно возвращались на протяжении всей жизни компании.
Предыстория
Что у нас было 10-11 лет назад? В компании работало несколько человек. Все алерты приходили на мой мобильный телефон, я их просматривал и уходил чинить то, что требовало внимания.
В действительности всё было не так плохо, потому что мы не пытались отправлять алерты по любому поводу (вроде закончившегося места на диске). Мониторинг работал для бизнес-показателей высокого уровня: грубо говоря, были cron-скрипты, которые проверяли, что что-то важное для бизнеса точно работает, и отправляли SMS в случае проблем. Система очень примитивная, но на тот момент она устраивала.
Шло время, росло число инцидентов. В какой-то момент я осознал, что страшно просыпаться утром: ведь в телефоне можно увидеть, например, 600 непрочитанных сообщений. Тогда мы решили ситуацию так: «Давайте я не буду это делать один. Давайте все по очереди». В компании было 5-6 человек: когда подобное дежурство происходит раз в неделю, всё уже не так плохо.
Шло время, росло количество проектов и сотрудников. Мы дошли до состояния: «Давайте не будем сами смотреть SMS'ки [именно так мы по-прежнему называли алерты], а попросим делать это кого-нибудь ещё». И сделали первую линию поддержку, хотя ещё тогда понимали, что это неправильно.
К слову, такие изменения в организации требовали и изменений в технике. Когда дежуришь один, всё отправляется в одну точку, а здесь уже требуется возможность определения многих мест и переключения между ними. У нас даже была «мощнейшая» система под названием «Журнал SMS»: в ней были все записи (алерты), которые специальный человек просматривал. Если какие-то из алертов часто появлялись, он звонил дежурному и указывал на эту проблему.
Всё это по-прежнему ужасно, но до какого-то момента решало наши задачи. Когда сотрудников стало около 30, несмотря на наличие выделенной группы L1, ситуация была проблемной с обеих сторон:
- другие инженеры жаловались, что первая линия ничего не делает;
- L1-инженеры жаловались, как много алертов на них постоянно сыпется.
Остановлюсь подробнее на том, что мы сделали и осознали на этот период.
Очевидное об алертах
- Центральное хранилище. Нельзя слать алерты разными путями — все они должны приходить в одно место.
- Переключатель. В этом центральном месте должна быть возможность куда-то «заворачивать» алерты. Иначе невозможно разделять с кем-либо ответственность за их обработку.
- Транспорт. Мы пришли к выводу, что электронная почта совсем не подходит для доставки алертов: если вы их так отправляете, то скорее всего не читаете сразу (они не приходят своевременно). SMS'ки тоже не годятся: сложно найти тонкую грань между «засыпало спамом» и «ничего не приходит». И отправка алертов в Telegram или Slack имеет проблемы: в таких местах коллективная ответственность (кто отвечает за обработку?) и нет механизма структурированного поиска. В итоге, мы решили, что существующие способы транспорта для алертов не подходят и сделали свою систему. В ней ответственный сотрудник вынужден для каждого алерта нажимать на кнопку «я увидел(а)»: если этого не происходит, к нему приходят запросы по другим каналам.
- Алерт не может быть текстом. У нас был эволюционный путь: сначала к тексту ошибки добавили название сервера, потом — severity, затем другие дополнительные поля. И постепенно пришли к тому, что вовсе убрали текстовое сообщение из алерта. Точнее, основой для алертов стали именно лейблы (метки), а текстом может быть сопроводительная информация.
- Инцидент не равен алерту. Чтобы это окончательно осознать, у нас ушло несколько лет. Алерт — это сообщение о проблеме, а инцидент — это сама проблема. Инцидент может содержать много сообщений о проблеме с разных сторон, и мы стали их объединять.
- Лейблы. Всю идентификацию алертов надо строить на лейблах (key=value) — это стало особенно актуальным с приходом Kubernetes. Если алерт с физического сервера — в лейбле указано название этого сервера, а если с DaemonSet'а — там его название и пространство имён.

Алерты разделяются на два типа:
- Мгновенные. Например: бэкап не прошёл, дата-центр сообщает об отключении сервера через 24 часа. У них нет состояния, есть только факт о событии.
- Длящиеся. Например: место на диске заканчивается. Есть состояние: горит или не горит. Ещё может быть неизвестное состояние, если произошёл сбой, в результате в которого актуальный статус проблемы более не мог быть отправлен.

Таким образом, у алерта может быть состояние. И обязательно использовать протокол, который понимает такие состояния.
Ещё одна популярная проблема — «мигание» алерта, когда он то загорается, то пропадает. Благодаря тому, что набор лейблов — уникальный идентификатор алерта, мы можем делать дедупликацию, объединяя такие алерты в серии. Каждая серия — группа событий, с которой удобно работать (вместо того, чтобы проводить такое объединение каждый раз мысленно).
Вот как это автоматическое склеивание выглядит у нас в интерфейсе. В верхней части — инцидент, а ниже — набор из алертов (всего их 7, но в экран на скриншоте поместились только 2).
Если у алерта есть статус (горит/не горит), то инциденты уже практически становятся тикетами, у которых есть рабочий процесс. В его основе — триаж (медицинская сортировка) и последующая «неотложка» или «надо делать» (или же просто сразу закрыть). У нас процесс чуть более сложный, но подробно останавливаться на нём не буду:
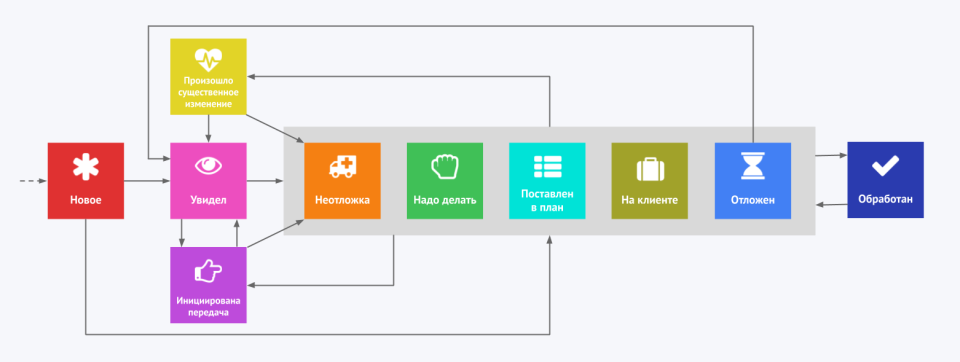
Ключевая же идея в том, что, если вы начали всерьёз подходить к обработке инцидентов, то каждый инцидент должен стать тикетом, который имеет свой рабочий процесс, соответствующий вашим требованиям и особенностям.
Однако ни одна система тикетов не рассчитана на то, чтобы обеспечить гарантию доставки. Если кто-то завёл тикет, а его увидели не сразу, то ничего страшного, как правило, не произошло. У этих решений попросту нет первичной важности в таком вопросе. А для нас критично, чтобы в течение десятков секунд дежурные на L1 увидели алерт, чтобы в течение минуты подтвердили это (не вникли в него, не приняли решение, но уже увидели, начали им заниматься).
Когда вы меняете исполнителя в тикете, он подтверждает, что согласен с этим изменением? В нашем случае такое подтверждение обязано быть — это как эстафетная палочка, передаваемая между инженерами.
Менее очевидные особенности
Когда мы всё это сделали, жизнь стала сильно лучше: мы перестали что-либо упускать, заметно (раз в 5) выросла пропускная способность в обработке инцидентов.
Однако через 2-3 года мы столкнулись со старой проблемой: наша техподдержка, которая теперь уже состояла из двух линий (L1 и L2), не успевала диагностировать инциденты. Её работа преимущественно сводилась к тому, чтобы либо сразу кому-то звонить об инциденте, либо ожидать, что он «сам пройдёт».
Культурно-организационная проблема, лежащая в основе, никуда не делась. Однако перед тем, как перейти к разным организационным схемам, которые мы успели попробовать, поделюсь ещё несколькими менее очевидными соображениями про технологии для работы с инцидентами.
Слово «инцидент» вызывает эмоции, схожие со словом «пожар». Однако в случае с пожаром всем понятно, что надо взять огнетушитель и тушить до тех пор, пока он не будет полностью ликвидирован, и останавливаться до этого времени недопустимо. С инцидентом же возможен случай, когда он «наполовину потушен»: первые меры были приняты, а дальше от нас ничего не зависит.
Например, сервер с одной из реплик сломался и ему надо заказать новый диск. Диск заказали, а поскольку это лишь одна из реплик, которая может быть недоступна несколько дней, пока диск едет, мы не будем исправлять алерты во всех используемых системах мониторинга — это трудозатратно. В результате, у нас висит инцидент, но каких-либо действий сейчас он не требует.
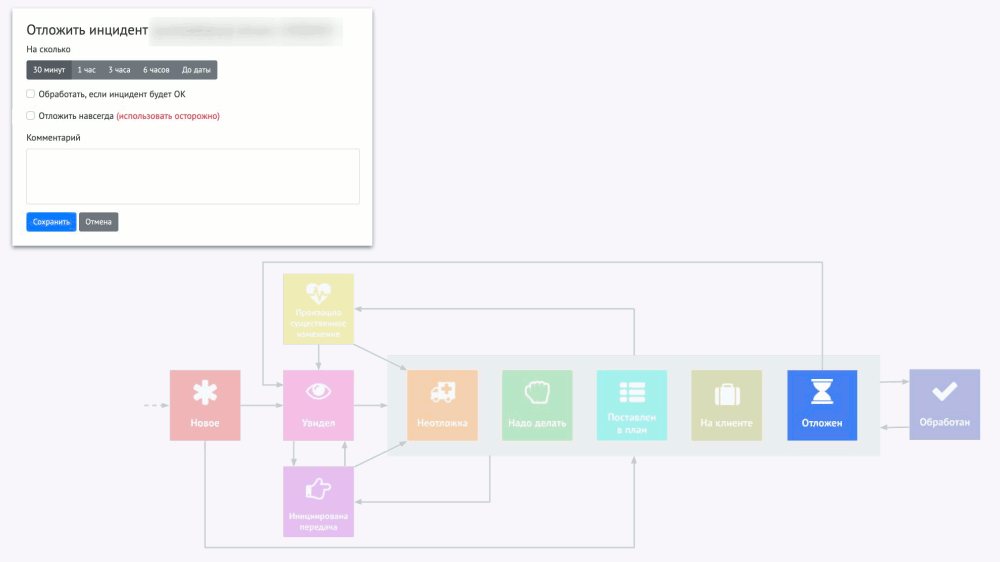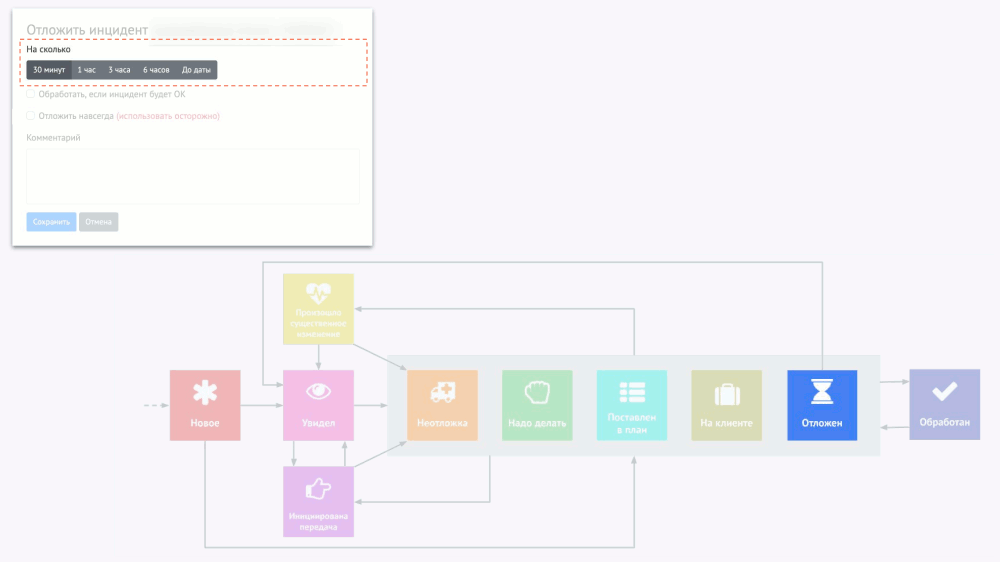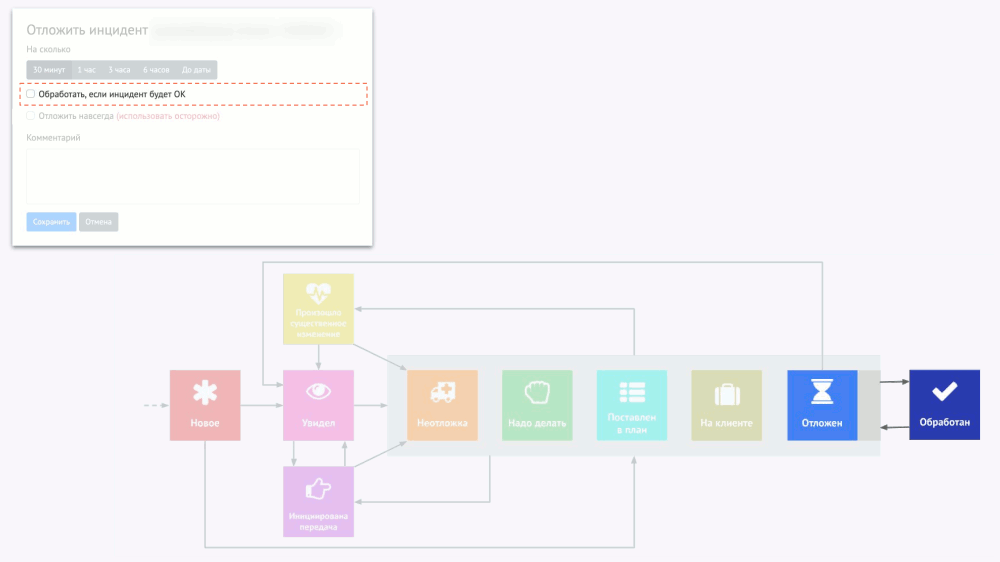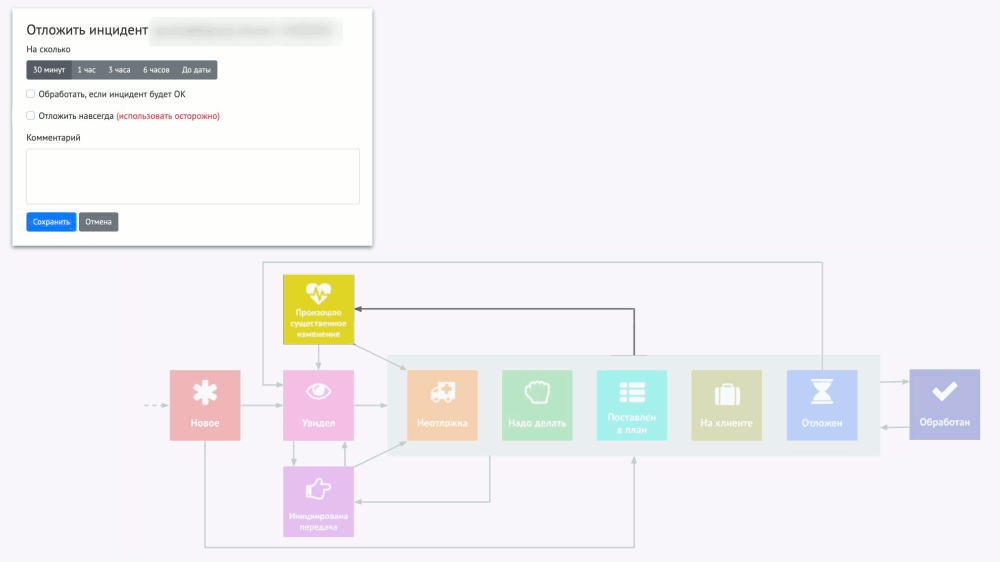
А представьте себе, что три таких инцидента горят, хотя на самом деле они не горят. Когда появится четвёртый, отношение к нему уже будет такое: «Ещё одна вещь, которая горит… Ну и что?» Чтобы избавиться от подобного психологического эффекта, «полупотушенные» инциденты надо попросту убрать, но сделать это правильно. Я называю это умный игнор, а его идея сводится к операции «отложить инцидент»:
Однако тут есть важный момент: если алерт был отложен, но каких-то ошибок (например, 500-х кодов у страницы веб-приложения) сначала было мало (0,1%), а потом стало много (20%), эту ситуацию можно упустить. Поэтому мы делаем разные уровни severity у алертов на разную частоту ошибок: если уровень меняется, такое изменение считается существенным, поэтому отложенный алерт снова всплывает и требует принятия решения.
В мониторинге в целом есть сложная проблема: мониторинг мониторинга. Правильный подход в его реализации по сути сводится к тому, что каждый источник алертов должен постоянно отправлять специальные сообщения «Я всё ещё жив», а система, принимающая алерты, — отслеживать наличие таких сообщений и поднимать тревогу в случае их отсутствия. Ещё одна полезная необходимость здесь — это отслеживать все алерты, отправляемые в некорректном формате (иначе они будут потеряны, а вы об этом даже не узнаете).
Следующая проблема — поиск. Поскольку всё сделано на лейблах, сходу получился понятный язык (MQL) для поиска алертов и инцидентов:

Наличие языка запросов принесло и другое важное удобство. С помощью маршрутизации алертов инженер, выполняющий какие-то временные работы, может в той же единой системе зафиксировать себя как ответственное лицо для конкретных алертов. Так дежурный будет сразу знать, к кому обращаться, если возникает проблема, попадающая под определённые условия:

Когда обработкой алертов занимаются много сотрудников, вам потребуется очень много времени, чтобы узнать о каком-либо надоедливом алерте, что случается каждый день, но один раз. Решению этой проблемы способствует горячая аналитика. Возле каждого инцидента мы показываем другие «подобные». Можно увидеть их количество, увидеть их полный список, кем они обрабатывались, когда и за какое время. А после этого поднять проблему на очередной встрече:
Организационная структура и зоны ответственности
Теперь я расскажу о вариантах организации работы, через которые мы прошли:
- Мы начинали с того, что дежурил один я.
- Позже эту обязанность разделили на всех сотрудников.
- Когда компания выросла, дежурить стали не все, а только часть сотрудников.
- Появилась выделенная первая линия поддержки (L1), которая работала 12-часовыми сменами.
- Сменили график на 8-часовые смены.
- Добавилась вторая линия (L2), которая сначала работала только в будни, а потом — тоже круглосуточно.
- Провели эксперименты с выведением на дежурство главных инженеров DevOps-команд, которые отвечали за определённые проекты. Так полностью нарушились процессы передачи знаний и была утрачена отказоустойчивость в реакции на инциденты.
- В дежурстве начали участвовать тимлиды DevOps-команд, потом их заместители (сами тимлиды и так фактически являются постоянной L3)…
- На этом этапе мы решили наконец-то переделать всё, что мы делаем, и сделать правильно. Как это?..
Но начать стоит с объяснения, почему L1 в нашем случае не работает в принципе. У меня есть несколько связанных примеров:
- Если вы готовите еду, то вы и убираете на кухне. Потому что в ином случае (если убирает кто-то другой) вы не будете действовать рационально.
- Если вы покупали посудомоечную машину, то, возможно, заметили, что с её появлением стали расходовать в 3 раза больше посуды.
- Если у вас есть семья (жена, дети), то могли заметить: когда они уезжают, вы можете пользоваться всего одной тарелкой и одной вилкой.
Это всё о том, когда рациональное поведение одного человека не приводит к рациональному поведению группы.
В контексте алертов: инженер понимает, что этот алерт куда-то там придёт (к дежурному), там с ним разберутся, поэтому нормально можно не делать. Мы решим проблему людьми (дежурными). А со временем, когда таких алертов становится всё больше, случается уже описанная проблема: дежурные на L1 страдают, что вообще не успевают ничего делать из-за количества алертов, а инженеры тоже недовольны: им казалось, что на L1 ничего не делают.
Наша попытка исправить это была такова:
- Изначально мы платили небольшую ЗП для дежурных на L1 и L2. Человек работал только на L1, со временем он мог перейти на L2, а потом — в DevOps-инженеры. Но по факту это практически не происходило, потому что, разбирая инциденты, сложно начучиться чему-то.
- Мы решили удвоить ЗП и изменить принцип работы дежурных. Теперь график состоял из двух смен на L1, отдыха, двух смен на L2, отдыха, недели стажёрства в DevOps-команде. Мы были уверены, что такая схема заработает, потому что команда станет учить людей.
- Идея была в том, чтобы обеспечить круглосуточное дежурство (смены L1/L2) + кадровые резервы (проект стажировки, который мы внутри назвали «DevOps-акселератором»).

Однако закончилось всё плачевно. На L1 и L2 люди исполняли свои обязанности с чувством, что это временно, а в целом они такой работой заниматься не хотят (потому что хотят быть инженерами). Итог: ни первая, ни вторая цели не были достигнуты.
К чему мы пришли? Всех дежурных убрали, а на обработке инцидентов работают люди, которые отвечают только за две функции: 1) эскалация, 2) коммуникация. Они ничего не знают о том, что это за инцидент и что с ним (технически) делать. А сами проблемы разбирают те же инженеры из команд, которые создавали алерты и отвечают за соответствующую инфраструктуру.

Документация
Вернёмся к общей схеме:

В компаниях, где часто что-то меняется, весьма актуальна ещё одна проблема: документация. У вас 10 человек, которые дежурят по очереди. Пришёл очередной алерт: кто его сделал и чего от меня здесь хотят? И каждое изменение в ответе на этот вопрос нужно доносить до всех дежурных. Очевидное решение: документирование всего, что не входит в сам алерт, в отдельной системе, где с помощью уже упомянутого языка запросов (MQL) описаны алерты, к которым инструкции относятся.
Эта документация показывается при открытии алерта, у неё есть кнопка «Прочитал(а)». Если при следующем срабатывании алерта что-то в документации изменилось, дежурному будет показан соответствующий diff.
Что мониторить?
Остался главный вопрос, о котором говорили уже миллионы раз… Вот три основных варианта ответов:

Если мы используем внутренние показатели, у нас появляется очень много «шума». А если мы смотрим на показатели доступности или бизнес-метрики, то узнаём об аварии только тогда, когда она уже произошла. Эта дилемма — в основе всего вопроса, что же мониторить. Как мы попытались ответить на такой вопрос (для себя)?..
У каждого есть своё представление том, чему соответствуют разные уровни severity и priority, и каждый по-своему прав:

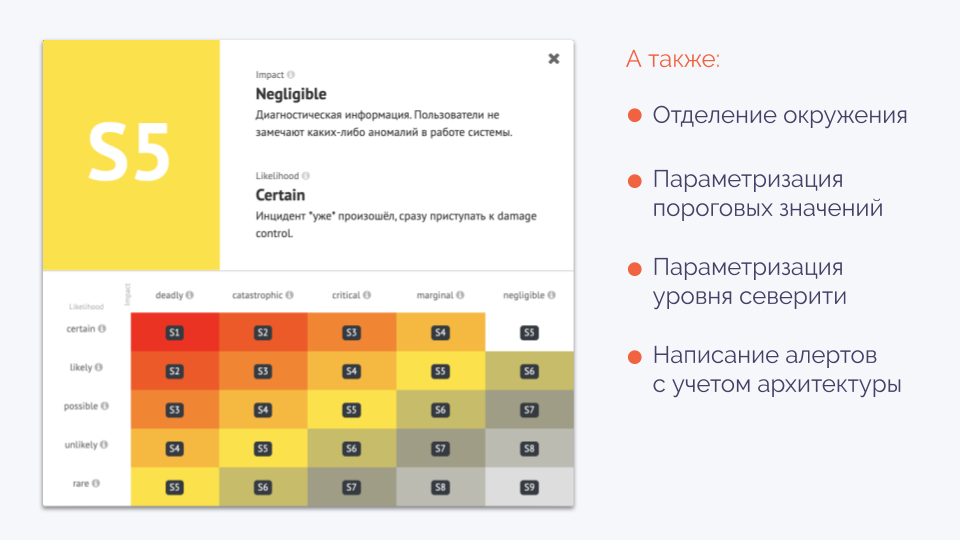
Мы пришли к тому, что определяем severity в двух координатах (влияние и вероятность):

Например, закончилось место на диске:
- impact: Каково влияние этого события в терминальной стадии?
- likelihood: Какая вероятность того, что мы в эту стадию попадём в настоящий момент времени? У диска осталось 20 %? Это possible. 10 % — likely, 0 % — certain (уже случилось).
С таким фреймворком мы и измеряем severity по шкале от 1 до 9. Так мы между собой договорились, что это не абстрактные WARNING или INFO, а что-то более конкретное.
В контексте необходимости отделения окружения мы пошли дальше и ввели для себя уровни обслуживания (service level). При поступлении алерта требуется ответить на вопрос: надо ли нам его обрабатывать? Если да, то как срочно?
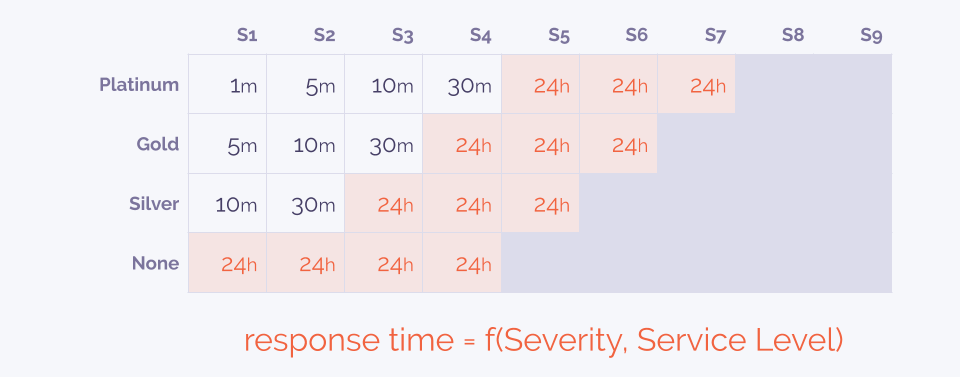
Отправляя множество алертов, мы на них по сути вручную не реагируем — спасибо автоматизации разбора. Часть алертов не требует быстрого вмешательства: о них мы вспомним во время ретроспективы. Другая часть собирается в группы, которые обрабатываются в обычное рабочее время — пачками, что гораздо удобнее. В результате, алертов, требующих обработки сразу, остаётся не так много:

Когда вы создаёте алерт, то указываете некое пороговое значение и период. Например: «если у меня load average больше такого порога на протяжении такого периода». С этим периодом есть дилемма. С одной стороны, 20 минут для того же load average — много, потому что всё уже умрёт. С другой стороны — о всплесках в 2 минуты можно ничего не узнать, а если поставить порог в 1 минуту, то дежурного завалит сообщениями.
Мы для себя решили ставить периоды очень маленькими и всегда слать алерты в систему. Но алерты приходят в статусе «pending» и для них определяется то время, которое они должны гореть, чтобы стать «настоящими». Таким образом, мы перенесли pending из источников мониторинга в центральную систему. Благодаря этому, если алерт так и не стал «настоящим», он себя не проявил для дежурного, однако в системе остался — его можно увидеть при ретроспективе.
С появлением Kubernetes стали актуальными два момента:
- Частичная недоступность — нормальное состояние.
- Многие вещи лечатся сами, и это тоже нормально.
А сейчас мы обдумываем идею написания ботов, которые будут разбирать алерты и (как минимум) автоматизировать эскалацию: на основании severity и service level мы определили, что проблема должна быть решена за 30 минут, поэтому, если инженер за 10 минут не справился, то автоматически зовём тимлида.
Итоги
Чему мы научились?
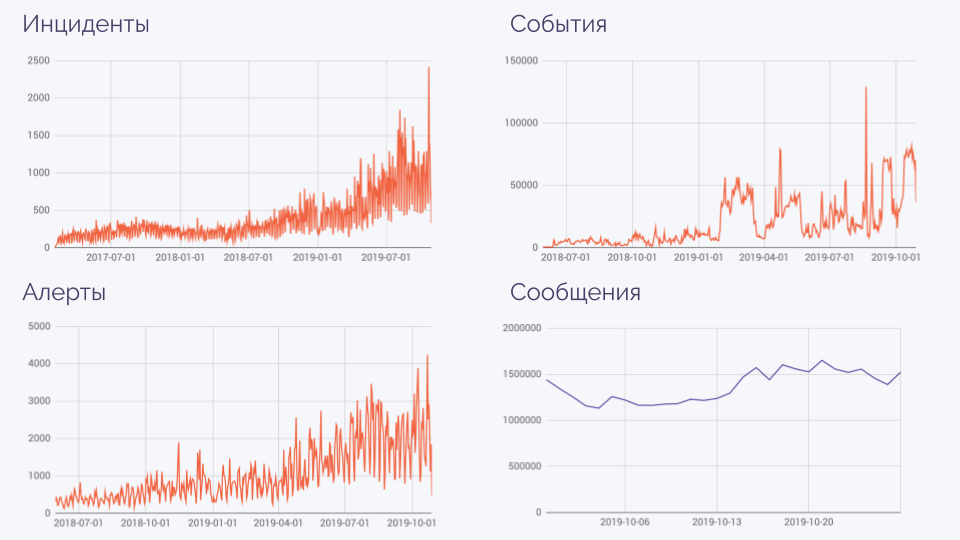
Немного статистики, показывающей, к чему мы пришли:
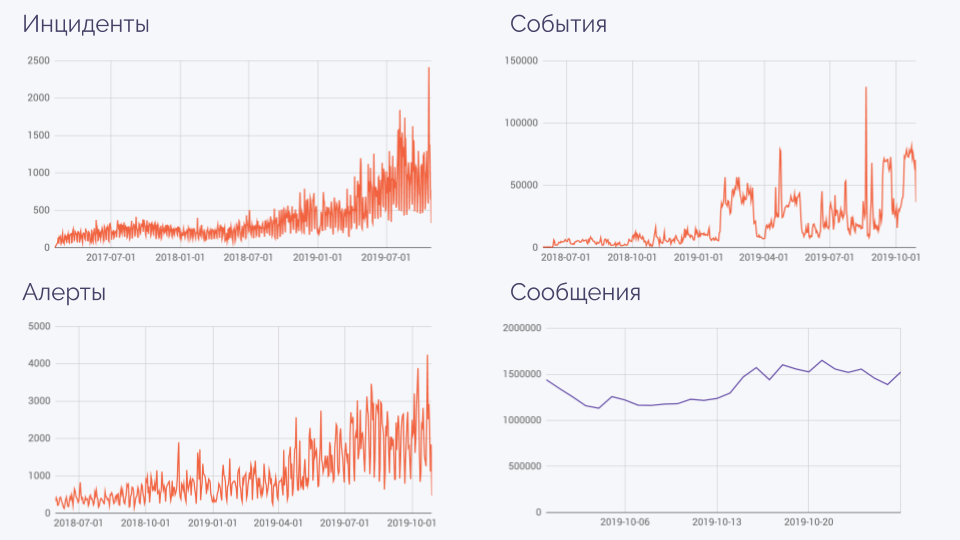
На графике алерты — это не отдельные алерты, а их серии. События — когда что-то сломалось, починилось, сломалось, починилось… Благодаря имеющейся автоматике, огромное количество сообщений (миллионы в день!) сокращается до такого числа, которое по-прежнему реально обрабатывать каждый день.
Вам это нужно?
Мы любим Open Source. Однако получившаяся система довольно специфична из-за своих масштабов и подходит далеко не для каждой компании. Если вам было бы интересно увидеть её в Open Source — пожалуйста, поделитесь ссылкой на этот доклад в Twitter/Facebook с хэштегом
#Флант, чтобы мы увидели спрос.Если же вы хотите рассмотреть вопрос внедрения такой системы, мы готовы заняться этим (с адаптацией под ваши потребности) — пишите на
sales@flant.ru с темой Система управления инцидентами.А если у вас есть амбиции сделать из такой системы продукт — станьте нашим бизнес-партнёром! (Пишите на
hr@flant.ru с темой Система управления инцидентами.)Видео и слайды
Видео с выступления (~63 минуты):
Презентация доклада:
P.S.
Среди других наших докладов:
- «Управление распределенной командой в режиме многопроектности» (Сергей Гончарук; 24 сентября 2019 на Saint TeamLead Conf);
- «Мониторинг и Kubernetes» (Дмитрий Столяров; 28 мая 2018 на RootConf);
- «werf — наш инструмент для CI/CD в Kubernetes» (Дмитрий Столяров; 27 мая 2019 на DevOpsConf).
