

Всё чаще от клиентов поступают такие запросы: «Хотим как Amazon RDS, но дешевле»; «Хотим как RDS, но везде, в любой инфраструктуре». Чтобы реализовать подобное managed-решение на Kubernetes, мы посмотрели на текущее состояние наиболее популярных операторов для PostgreSQL (Stolon, операторы от Crunchy Data и Zalando) и сделали свой выбор.
Эта статья — полученный нами опыт и с теоретической точки зрения (обзор решений), и с практической стороны (что было выбрано и что из этого получилось). Но для начала давайте определимся, какие вообще требования предъявляются к потенциальной замене RDS…
Что же такое RDS
Когда люди говорят про RDS, по нашему опыту, они подразумевают управляемый (managed) сервис СУБД, которая:
- легко настраивается;
- имеет возможность работы со снапшотами и восстанавливаться из них (желательно — с поддержкой PITR);
- позволяет создавать топологии master-slave;
- имеет богатый список расширений;
- предоставляет аудит и управление пользователями/доступами.
Если говорить вообще, то подходы к реализации поставленной задачи могут быть весьма разными, однако путь с условным Ansible нам не близок. (К схожему выводу пришли и коллеги из 2GIS в результате своей попытки создать «инструмент для быстрого развертывания отказоустойчивого кластера на основе Postgres».)
Именно операторы — общепринятый подход для решения подобных задач в экосистеме Kubernetes. Подробнее о них применительно к базам данных, запускаемым внутри Kubernetes, уже рассказывал техдир «Фланта», distol, в одном из своих докладов.
NB: Для быстрого создания несложных операторов рекомендуем обратить внимание на нашу Open Source-утилиту shell-operator. Используя её, можно это делать без знаний Go, а более привычными для сисадминов способами: на Bash, Python и т.п.
Для PostgreSQL существует несколько популярных K8s-операторов:
- Stolon;
- Crunchy Data PostgreSQL Operator;
- Zalando Postgres Operator.
Посмотрим на них более внимательно.
Выбор оператора
Помимо тех важных возможностей, что уже были упомянуты выше, мы — как инженеры по эксплуатации инфраструктуры в Kubernetes — также ожидали от операторов следующего:
- деплой из Git и с Custom Resources;
- поддержку pod anti-affinity;
- установку node affinity или node selector;
- установку tolerations;
- наличие возможностей тюнинга;
- понятные технологии и даже команды.
Не вдаваясь в детали по каждому из пунктов (спрашивайте в комментариях, если останутся вопросы по ним после прочтения всей статьи), отмечу в целом, что эти параметры нужны для более тонкого описания специализации узлов кластера с тем, чтобы заказывать их под конкретные приложения. Так мы можем добиться оптимального баланса в вопросах производительности и стоимости.
Теперь — к самим операторам PostgreSQL.
1. Stolon
Stolon от итальянской компании Sorint.lab в уже упомянутом докладе рассматривался как некий эталон среди операторов для СУБД. Это довольно старый проект: первый его публичный релиз состоялся еще в ноябре 2015 года(!), а GitHub-репозиторий может похвастать почти 3000 звёздами и 40+ контрибьюторами.
И действительно, Stolon — отличный пример продуманной архитектуры:
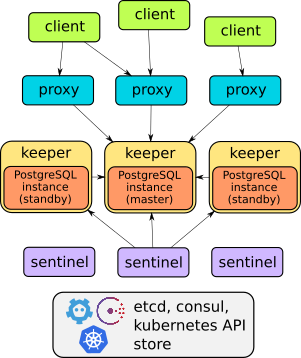
С устройством этого оператора в подробностях можно ознакомиться в докладе или документации проекта. В целом же, достаточно сказать, что он умеет всё описанное: failover, прокси для прозрачного доступа клиентов, бэкапы… Причем прокси предоставляют доступ через один сервис endpoint — в отличие от двух других решений, рассмотренных дальше (у них по два сервиса для доступа к базе).
Однако у Stolon нет Custom Resources, из-за чего его нельзя так деплоить, чтобы просто и быстро — «как горячие пирожки» — создавать экземпляры СУБД в Kubernetes. Управление осуществляется через утилиту
stolonctl, деплой — через Helm-чарт, а пользовательские настройки определяются задаются в ConfigMap.С одной стороны, получается, что оператор не очень-то является оператором (ведь он не использует CRD). Но с другой — это гибкая система, которая позволяет настраивать ресурсы в K8s так, как вам удобно.
Резюмируя, лично для нас не показался оптимальным путь заводить отдельный чарт под каждую БД. Поэтому мы стали искать альтернативы.
2. Crunchy Data PostgreSQL Operator
Оператор от Crunchy Data, молодого американского стартапа, выглядел логичной альтернативой. Его публичная история начинается с первого релиза в марте 2017 года, с тех пор GitHub-репозиторий получил чуть менее 1300 звёзд и 50+ контрибьюторов. Последний релиз от сентября был протестирован на работу с Kubernetes 1.15—1.18, OpenShift 3.11+ и 4.4+, GKE и VMware Enterprise PKS 1.3+.
Архитектура Crunchy Data PostgreSQL Operator также соответствует заявленным требованиям:
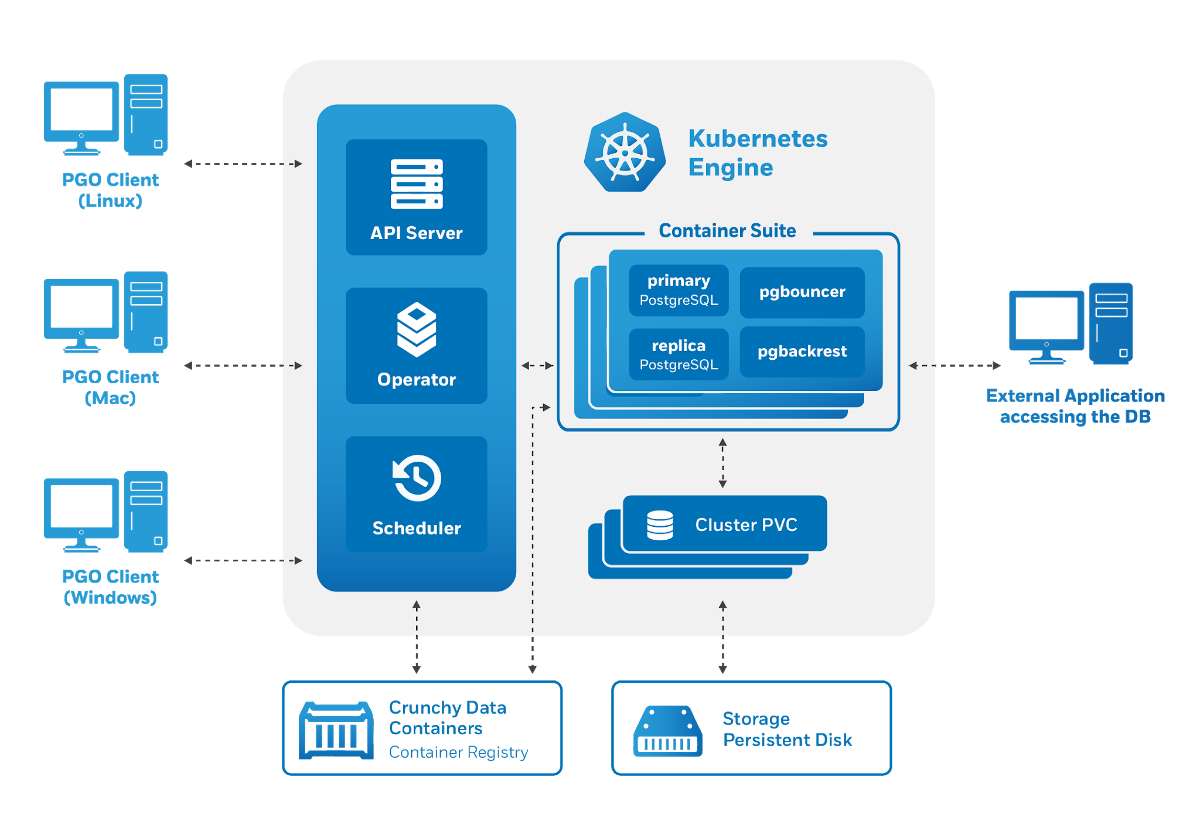
Управление происходит через утилиту
pgo, однако она в свою очередь генерирует Custom Resources для Kubernetes. Поэтому нас как потенциальных пользователей оператор порадовал:- есть управление через CRD;
- удобное управление пользователями (тоже через CRD);
- интеграция с другими компонентами Crunchy Data Container Suite — специализированной коллекции образов контейнеров для PostgreSQL и утилит для работы с ней (включая pgBackRest, pgAudit, расширения из contrib и т.д.).
Однако попытки начать использовать оператор от Crunchy Data выявили несколько проблем:
- Не оказалось возможности tolerations — предусмотрен только nodeSelector.
- Создаваемые pod’ы были частью Deployment’а, несмотря на то, что мы деплоили stateful-приложение. В отличие от StatefulSet, Deployment’ы не умеют создавать диски.
Последний недостаток приводит к забавным моментам: на тестовой среде удалось запустить 3 реплики с одним диском local storage, в результате чего оператор сообщал, что 3 реплики работают (хотя это было не так).
Ещё одной особенностью этого оператора является его готовая интеграция с различными вспомогательными системами. Например, легко установить pgAdmin и pgBounce, а в документации рассматриваются преднастроенные Grafana и Prometheus. В недавнем релизе 4.5.0-beta1 отдельно отмечается улучшенная интеграция с проектом pgMonitor, благодаря чему оператор предлагает наглядную визуализацию метрик по PgSQL «из коробки».
Тем не менее, странный выбор генерируемых Kubernetes-ресурсов привел нас к необходимости найти иное решение.
3. Zalando Postgres Operator
Продукты Zalando нам известны давно: есть опыт использования Zalenium и, конечно, мы пробовали Patroni — их популярное HA-решение для PostgreSQL. О подходе компании к созданию Postgres Operator рассказывал один из его авторов — Алексей Клюкин — в эфире Postgres-вторника №5, и нам он приглянулся.
Это самое молодое решение из рассматриваемых в статье: первый релиз состоялся в августе 2018 года. Однако, даже несмотря на небольшое количество формальных релизов, проект прошёл большой путь, уже опередив по популярности решение от Crunchy Data с 1300+ звёздами на GitHub и максимальным числом контрибьюторов (70+).
«Под капотом» этого оператора используются решения, проверенные временем:
Вот как представлена архитектура оператора от Zalando:
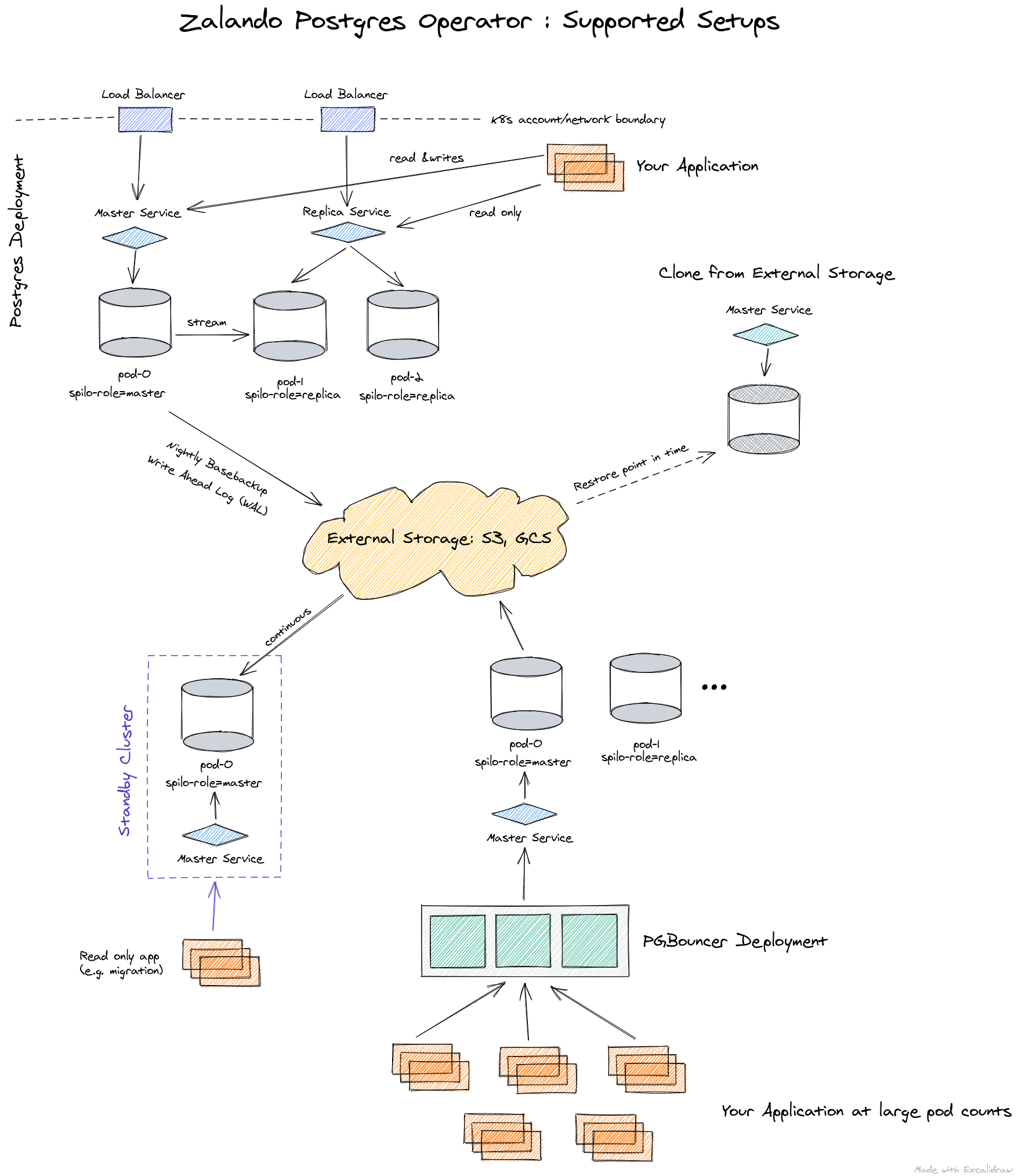
Оператор полностью управляется через Custom Resources, автоматически создает StatefulSet из контейнеров, которые затем можно кастомизировать, добавляя в pod различные sidecar'ы. Всё это — значительный плюс в сравнении с оператором от Crunchy Data.
Поскольку именно решение от Zalando мы выбрали среди 3 рассматриваемых вариантов, дальнейшее описание его возможностей будет представлено ниже, сразу вместе с практикой применения.
Практика с Postgres Operator от Zalando
Деплой оператора происходит очень просто: достаточно скачать актуальный релиз с GitHub и применить YAML-файлы из директории manifests. Как вариант, можно также воспользоваться OperatorHub.
После установки стоит озаботиться настройкой хранилищ для логов и бэкапов. Она производится через ConfigMap
postgres-operator в пространстве имён, куда вы установили оператор. Когда хранилища настроены, можно развернуть первый кластер PostgreSQL.Например, стандартный деплой у нас выглядит следующим образом:
apiVersion: acid.zalan.do/v1
kind: postgresql
metadata:
name: staging-db
spec:
numberOfInstances: 3
patroni:
synchronous_mode: true
postgresql:
version: "12"
resources:
limits:
cpu: 100m
memory: 1Gi
requests:
cpu: 100m
memory: 1Gi
sidecars:
- env:
- name: DATA_SOURCE_URI
value: 127.0.0.1:5432
- name: DATA_SOURCE_PASS
valueFrom:
secretKeyRef:
key: password
name: postgres.staging-db.credentials
- name: DATA_SOURCE_USER
value: postgres
image: wrouesnel/postgres_exporter
name: prometheus-exporter
resources:
limits:
cpu: 500m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
teamId: staging
volume:
size: 2Gi
Данный манифест деплоит кластер из 3 экземпляров с sidecar в виде postgres_exporter, с которого мы снимаем метрики приложения. Как видите, всё очень просто, и при желании можно сделать буквально неограниченное количество кластеров.
Стоит обратить внимание и на веб-панель для администрирования — postgres-operator-ui. Она поставляется вместе с оператором и позволяет создавать и удалять кластеры, а также работать с бэкапами, которые делает оператор.
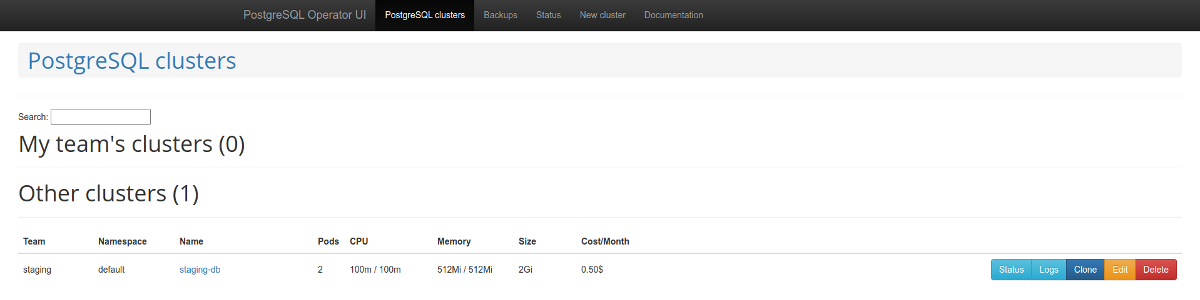
Список кластеров PostgreSQL
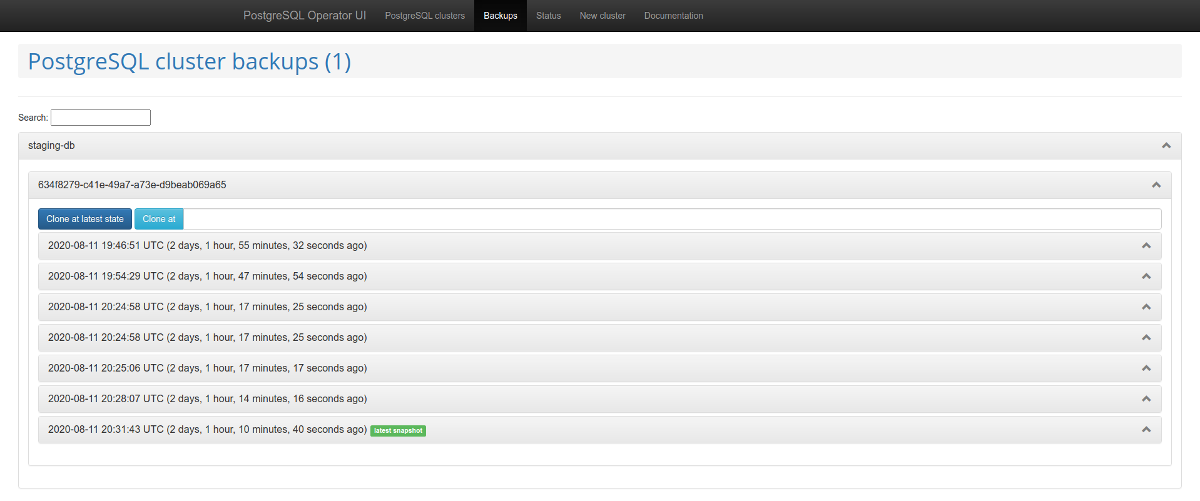
Управление бэкапами
Другой интересной особенностью является поддержка Teams API. Данный механизм автоматически создаёт роли в PostgreSQL, исходя из полученного списка имён пользователей. После этого API позволяет вернуть список пользователей, для которых автоматически создаются роли.
Проблемы и их решение
Однако использование оператора вскоре выявило несколько весомых недостатков:
- отсутствие поддержки nodeSelector;
- невозможность отключить бэкапы;
- при использовании функции создания баз не появляются привилегии по умолчанию;
- периодически не хватает документации или же она находится в неактуальном состоянии.
К счастью, многие из них могут быть решены. Начнём с конца — проблем с документацией.
Скорее всего вы столкнетесь с тем, что не всегда ясно, как прописать бэкап и как подключить бэкапный бакет к Operator UI. Об этом в документации говорится вскользь, а реальное описание есть в PR:
- нужно сделать секрет;
- передать его оператору в параметр
pod_environment_secret_nameв CRD с настройками оператора или в ConfigMap (зависит от того, как вы решили устанавливать оператор).
Однако, как оказалось, на текущий момент это невозможно. Именно поэтому мы собрали свою версию оператора с некоторыми дополнительными сторонними наработками. Подробнее о ней — см. ниже.
Если передавать оператору параметры для бэкапа, а именно —
wal_s3_bucket и ключи доступа в AWS S3, то он будет бэкапить всё: не только базы в production, но и staging. Нас это не устроило.В описании параметров к Spilo, что является базовой Docker-обёрткой для PgSQL при использовании оператора, выяснилось: можно передать параметр
WAL_S3_BUCKET пустым, тем самым отключив бэкапы. Более того, к большой радости нашёлся и готовый PR, который мы тут же приняли в свой форк. Теперь достаточно просто добавить enableWALArchiving: false в ресурс кластера PostgreSQL.Да, была возможность сделать иначе, запустив 2 оператора: один для staging (без бэкапов), а второй — для production. Но так мы смогли обойтись одним.
Ок, мы научились передавать в базы доступ для S3 и бэкапы начали попадать в хранилище. Как заставить работать страницы бэкапов в Operator UI?

В Operator UI потребуется добавить 3 переменные:
-
SPILO_S3_BACKUP_BUCKET -
AWS_ACCESS_KEY_ID -
AWS_SECRET_ACCESS_KEY
После этого управление бэкапами станет доступно, что в нашем случае упростит работу со staging, позволив доставлять туда срезы с production без дополнительных скриптов.
В качестве еще одного плюса называлась работа с Teams API и широкие возможности для создания баз и ролей средствами оператора. Однако создаваемые роли не имели прав по умолчанию. Соответственно, пользователь с правами на чтение не мог читать новые таблицы.
Почему так? Несмотря на то, что в коде есть необходимые
GRANT, они применяются далеко не всегда. Есть 2 метода: syncPreparedDatabases и syncDatabases. В syncPreparedDatabases — несмотря на то, что в секции preparedDatabases есть есть условие defaultRoles и defaultUsers для создания ролей, — права по умолчанию не применяются. Мы в процессе подготовки патча, чтобы данные права автоматически применялись.И последний момент в актуальных для нас доработках — патч, добавляющий Node Affinity в создаваемый StatefulSet. Наши клиенты зачастую предпочитают сокращать расходы, используя spot-инстансы, а на них явно не стоит размещать сервисы БД. Этот вопрос можно было бы решить и через tolerations, но наличие Node Affinity даёт большую уверенность.
Что получилось?
По итогам решения перечисленных проблем мы форкнули Postgres Operator от Zalando в свой репозиторий, где он собирается со столь полезными патчами. А для пущего удобства собрали и Docker-образ.
Список PR, принятых в форк:
- сборка в Docker безопасного легкого образа для оператора;
- отключение бэкапов;
- обновление версий ресурсов для актуальных версий k8s;
- внедрение Node Affinity.
Будет здорово, если сообщество поддержит эти PR, чтобы они попали в upstream со следующей версией оператора (1.6).
Бонус! История успеха с миграцией production
Если вы используете Patroni, на оператор можно мигрировать живой production с минимальным простоем.
Spilo позволяет делать standby-кластеры через S3-хранилища с Wal-E, когда бинарный лог PgSQL сначала сохраняется в S3, а затем выкачивается репликой. Но что делать, если у вас не используется Wal-E в старой инфраструктуре? Решение этой проблемы уже было предложено на хабре.
На помощь приходит логическая репликация PostgreSQL. Однако не будем вдаваться в детали, как создавать публикации и подписки, потому что… наш план потерпел фиаско.
Дело в том, что в БД было несколько нагруженных таблиц с миллионами строк, которые, к тому же, постоянно пополнялись и удалялись. Простая подписка с
copy_data, когда новая реплика копирует всё содержимое с мастера, просто не успевала за мастером. Копирование контента работало неделю, но так и не догнало мастер. В итоге, разобраться с проблемой помогла статья коллег из Avito: можно перенести данные, используя pg_dump. Опишу наш (немного доработанный) вариант этого алгоритма.Идея заключается в том, что можно сделать выключенную подписку, привязанную к конкретному слоту репликации, а затем исправить номер транзакции. В наличии были реплики для работы production’а. Это важно, потому что реплика поможет создать консистентный dump и продолжить получать изменения из мастера.
В последующих командах, описывающих процесс миграции, будут использоваться следующие обозначения для хостов:
- master — исходный сервер;
- replica1 — потоковая реплика на старом production;
- replica2 — новая логическая реплика.
План миграции
1. Создадим на мастере подписку на все таблицы в схеме
public базы dbname:psql -h master -d dbname -c "CREATE PUBLICATION dbname FOR ALL TABLES;"
2. Cоздадим слот репликации на мастере:
psql -h master -c "select pg_create_logical_replication_slot('repl', 'pgoutput');"
3. Остановим репликацию на старой реплике:
psql -h replica1 -c "select pg_wal_replay_pause();"
4. Получим номер транзакции с мастера:
psql -h master -c "select replay_lsn from pg_stat_replication where client_addr = 'replica1';"
5. Снимем dump со старой реплики. Будем делать это в несколько потоков, что поможет ускорить процесс:
pg_dump -h replica1 --no-publications --no-subscriptions -O -C -F d -j 8 -f dump/ dbname
6. Загрузим dump на новый сервер:
pg_restore -h replica2 -F d -j 8 -d dbname dump/
7. После загрузки дампа можно запустить репликацию на потоковой реплике:
psql -h replica1 -c "select pg_wal_replay_resume();"
7. Создадим подписку на новой логической реплике:
psql -h replica2 -c "create subscription oldprod connection 'host=replica1 port=5432 user=postgres password=secret dbname=dbname' publication dbname with (enabled = false, create_slot = false, copy_data = false, slot_name='repl');"
8. Получим
oid подписки:psql -h replica2 -d dbname -c "select oid, * from pg_subscription;"
9. Допустим, был получен
oid=1000. Применим номер транзакции к подписке:psql -h replica2 -d dbname -c "select pg_replication_origin_advance('pg_1000', 'AA/AAAAAAAA');"
10. Запустим репликацию:
psql -h replica2 -d dbname -c "alter subscription oldprod enable;"
11. Проверим статус подписки, репликация должна работать:
psql -h replica2 -d dbname -c "select * from pg_replication_origin_status;"
psql -h master -d dbname -c "select slot_name, restart_lsn, confirmed_flush_lsn from pg_replication_slots;"
12. После того, как репликация запущена и базы синхронизированы, можно совершать переключение.
13. После отключения репликации надо исправить последовательности. Это хорошо описано в статье на wiki.postgresql.org.
Благодаря такому плану переключение прошло с минимальными задержками.
Заключение
Операторы Kubernetes позволяют упростить различные действия, сведя их к созданию K8s-ресурсов. Однако, добившись замечательной автоматизации с их помощью, стоит помнить, что она может принести и ряд неожиданных нюансов, поэтому подходите к выбору операторов с умом.
Рассмотрев три самых популярных Kubernetes-оператора для PostgreSQL, мы остановили свой выбор на проекте от Zalando. И с ним пришлось преодолеть определенные трудности, но результат действительно порадовал, так что мы планируем расширить этот опыт и на некоторые другие инсталляции PgSQL. Если у вас есть опыт использования схожих решений — будем рады увидеть подробности в комментариях!
ОБНОВЛЕНО (13 ноября 2020 г.): у статьи вышла вторая часть, где также рассмотрены операторы KubeDB и StackGres, представлена общая сравнительная таблица.
P.S.
Читайте также в нашем блоге:
