

На прошлую статью, где мы рассмотрели три оператора PostgreSQL для Kubernetes (Stolon, Crunchy Data и Zalando), поделились своим выбором и опытом эксплуатации, — поступила отличная обратная связь от сообщества*.
Продолжая эту тему, мы добавили в обзор два других решения, на которые нам указали в комментариях: StackGres и KubeDB, — и сделали сводную таблицу сравнения. Также за время эксплуатации оператора от Zalando у нас появились новые интересные кейсы — спешим поделиться и ими.
* Первую часть статьи заметили даже разработчики Zalando, благодаря чему(?) они решили активизироваться в приёме некоторых PR. Это не может не радовать!
Итак, сначала дополним обзор ещё двумя решениями…
KubeDB

Оператор KubeDB разрабатывается командой AppsCode c 2017 года и хорошо известен в Kubernetes-сообществе. Он претендует на звание платформы для запуска различных stateful-сервисов в Kubernetes и поддерживает:
- PostgreSQL;
- Elasticsearch;
- MySQL;
- MongoDB;
- Redis;
- Memcache.
Однако в контексте статьи мы рассмотрим только PostgreSQL.
В KubeDB реализован интересный подход с использованием нескольких CRD, которые содержат в себе различные настройки, такие как:
- версия с образом базы и вспомогательными утилитами — за это отвечает ресурс
postgresversions.catalog.kubedb.com; - параметры восстановления — ресурс бэкапа
snapshots.kubedb.com; - собственно, корневой ресурс
postgreses.kubedb.com, который собирает в себе все эти ресурсы и запускает кластер PostgreSQL.
Особой кастомизации KubeDB не предоставляет (в отличие от оператора Zalando), но вы всегда можете управлять конфигом PostgreSQL через ConfigMap.
Интересной особенностью является ресурс
dormantdatabases.kubedb.com, который предоставляет «защиту от дурака»: все удалённые базы сначала переводятся в такое архивное состояние и могут быть легко восстановлены в случае необходимости. Жизненный цикл БД в KubeDB описывается следующей схемой:
Что же касается самого технологического стека, то тут используются свои наработки для управления кластерами, а не знакомые всем Patroni или Repmgr. Хотя для полинга соединений используется pgBouncer, который также создается отдельным CRD (
pgbouncers.kubedb.com). Кроме того, разработчики предоставляют плагин для kubectl, который позволяет удобно управлять базами через всем привычную утилиту, и это огромный плюс на фоне Stolon или Crunchy Data.KubeDB интегрируется с другими решениями AppsCode, чем напоминает Crunchy Data. Если вы везде используете решения этого вендора, то KubeDB, безусловно, отличный выбор.
Наконец, хочется отметить отличную документацию этого оператора, которая находится в отдельном репозитории GitHub. В ней есть развернутые примеры использования, включая полные примеры конфигураций CRD.
Есть минусы у KubeDB. Многие возможности: бэкапы, полинг соединений, снапшоты, dormant-базы — доступны только в enterprise-версии, а для её использования требуется купить подписку у AppsCode. Кроме того, самой старшей поддерживаемой версией PostgreSQL «из коробки» является 11.x. Перечеркивают ли эти моменты изящную архитектуру KubeDB — решать вам.
StackGres

В твиттере и в комментариях к предыдущей статье нам резонно указали на оператор StackGres. Разработка данного оператора началась совсем недавно, в мае 2019 году. В нем используются известные и проверенные технологии: Patroni, PgBouncer, WAL-G и Envoy.
Общая схема оператора выглядит так:
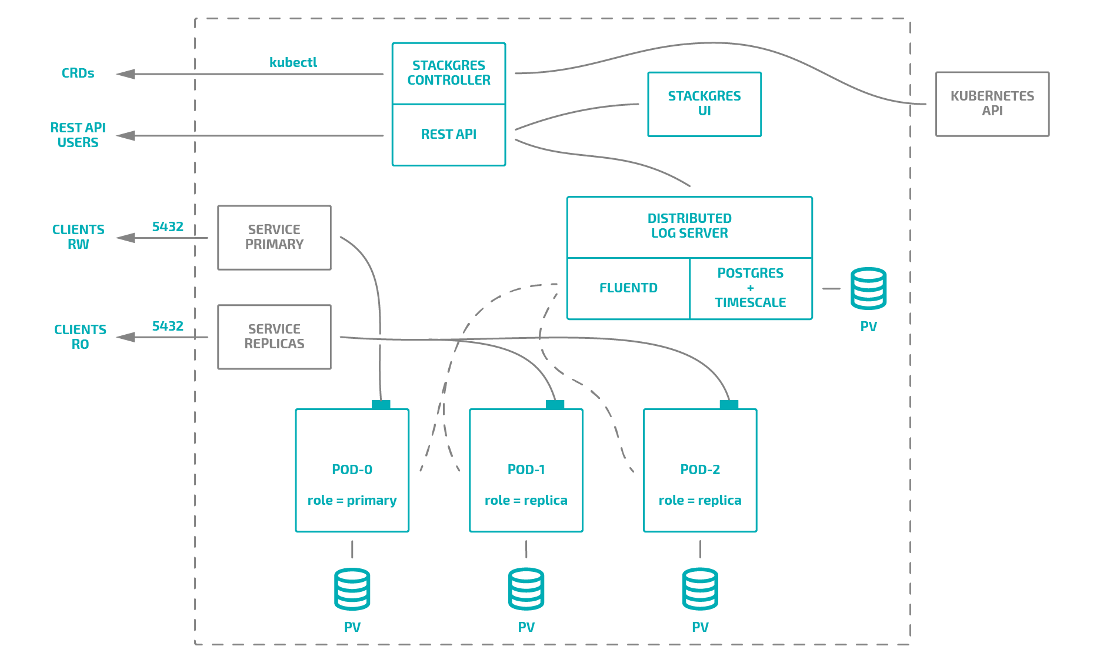
Кроме того, в комплекте с оператором можно установить:
- веб-панель, как в Zalando;
- систему сбора логов;
- систему мониторинга, аналогичную Crunchy Data, о которой мы говорили в первой части;
- систему сбора бэкапов на основе MinIO, хотя можно подключить и внешнее хранилище.
В целом же, данный оператор использует подход, очень схожий с KubeDB: он предоставляет сразу несколько ресурсов для описания компонентов кластера, создания конфигов и задания ресурсов.
Вкратце про все CRD:
-
sgbackupconfigs.stackgres.io,sgpgconfigs.stackgres.io,sgpoolconfigs.stackgres.io— описание кастомных конфигов; -
sginstanceprofiles.stackgres.io— размер инстанса Postgres, который будет использоваться как limit/request для контейнера с PostgreSQL/Patroni. Для остальных контейнеров лимитов нет; -
sgclusters.stackgres.io— когда есть конфигурации для базы, пула коннектов и бэкапа, можно создать кластер PostgreSQL, который описывается этим CRD; -
sgbackups.stackgres.io— ресурс, схожий со snapshot у KubeDB и позволяющий обратиться к конкретному бэкапу из кластера K8s.
Однако оператор не позволяет использовать свои кастомные сборки образов или же несколько вспомогательных sidecar для сервера баз данных. Pod c Postgres содержит 5 контейнеров:

Из них мы можем отключить экспортер метрик, пулер коннектов и контейнер со вспомогательными утилитами администратора (
psql, pg_dump и так далее). Да, оператор позволяет при инициализации кластера баз данных подключить скрипты с SQL-кодом для инициализации БД или создания пользователей, но не более того. Это сильно ограничивает нас в кастомизации, например, в сравнении с тем же оператором Zalando, где можно добавлять нужные sidecar с Envoy, PgBouncer и любыми другими вспомогательными контейнерами (хороший пример подобной связки будет ниже).Подводя итог, можно сказать, что этот оператор понравится тем, кто хочет «просто управлять» PostgreSQL в кластере Kubernetes. Отличный выбор для тех, кому нужен инструмент с простой документацией, покрывающей все аспекты работы оператора, и кому не нужно делать сложные связки контейнеров и баз.
Итоговое сравнение
Мы знаем, что наши коллеги нежно любят сводные таблицы, поэтому приводим подобную для Postgres-операторов в Kubernetes.
Забегая вперед: после рассмотрения двух дополнительных кандидатов мы остаёмся при мнении, что решение от Zalando — оптимальный для нашего случая продукт, так как позволяет реализовывать очень гибкие решения, имеет большой простор для кастомизации.
В таблице первая часть посвящена сравнению основных возможностей работы с БД, а вторая — более специфичным особенностям, следуя нашему пониманию об удобстве работы с оператором в Kubernetes.
Не будет лишним также сказать, что при формулировании критериев для итоговой таблицы использовались примеры из документации KubeDB.
| Stolon | Crunchy Data | Zalando | KubeDB | StackGres | |
| Текущая версия | 0.16.0 | 4.5.0 | 1.5.0 | 0.13 | 0.9.2 |
| Версии PostgreSQL | 9.4—9.6, 10, 11, 12 | 9.5, 9.6, 10, 11, 12 | 9.6, 10, 11, 12 | 9.6, 10, 11 | 11, 12 |
| Общие возможности | |||||
| Кластеры PgSQL | ✓ | ✓ | ✓ | ✓ | ✓ |
| Теплый и горячий резерв | ✓ | ✓ | ✓ | ✓ | ✓ |
| Синхронная репликация | ✓ | ✓ | ✓ | ✓ | ✓ |
| Потоковая репликация | ✓ | ✓ | ✓ | ✓ | ✓ |
| Автоматический failover | ✓ | ✓ | ✓ | ✓ | ✓ |
| Непрерывное архивирование | ✓ | ✓ | ✓ | ✓ | ✓ |
| Инициализация: из WAL-архива | ✓ | ✓ | ✓ | ✓ | ✓ |
| Бэкапы: мгновенные, по расписанию | ✗ | ✓ | ✓ | ✓ | ✓ |
| Бэкапы: управляемость из кластера | ✗ | ✗ | ✗ | ✓ | ✓ |
| Инициализация: из снапшота, со скриптами | ✓ | ✓ | ✓ | ✓ | ✓ |
| Специализированные возможности | |||||
| Встроенная поддержка Prometheus | ✗ | ✓ | ✗ | ✓ | ✓ |
| Кастомная конфигурация | ✓ | ✓ | ✓ | ✓ | ✓ |
| Кастомный Docker-образ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Внешние CLI-утилиты | ✓ | ✓ | ✗ | ✓ (kubectl-плагин) |
✗ |
| Конфигурация через CRD | ✗ | ✓ | ✓ | ✓ | ✓ |
| Кастомизация Pod'ов | ✓ | ✗ | ✓ | ✓ | ✗ |
| NodeSelector и NodeAffinity | ✓ | ✓ | ✓ (через патчи) |
✓ | ✗ |
| Tolerations | ✓ | ✗ | ✓ | ✓ | ✗ |
| Pod anti-affinity | ✓ | ✓ | ✓ | ✓ | ✓ |
Бонусы про оператор от Zalando
Ежедневно пользуясь решением от Zalando, мы столкнулись с некоторыми сложностями, и этим опытом хотелось бы поделиться с сообществом.
1. Приватные репозитории
Недавно нам потребовалось запустить через оператор наряду с PostgreSQL контейнер с SFTP, который позволил бы получать выгрузки из базы в формате CSV. Сам SFTP-сервер со всеми нужными параметрами был собран в закрытом registry.
И тут стало ясно, что оператор не умеет работать с registry secrets. К счастью, с такой проблемой мы были не одни с такой проблемой: все легко решилось коллегами на GitHub. Оказалось, что достаточно добавить в описание ServiceAccount имя с доступами в registry:
pod_service_account_definition: '{ "apiVersion": "v1", "kind": "ServiceAccount", "metadata": { "name": "zalando-postgres-operator" }, "imagePullSecrets": [ { "name": "my-fine-secret" } ] }'
2. Дополнительные хранилища и init-контейнеры
Для работы SFTP нам также требовалось корректно выставлять права на директории, чтобы заработал chroot. Возможно, не все знают, но OpenSSH-сервер требует особых привилегий на директории. Например, чтобы пользователь видел только свой
/home/user, необходимо, чтобы /home принадлежал root с правами 755, а уже /home/user был доступен пользователю. Соответственно, мы решили использовать init-контейнер, который исправлял бы права на директории.Но оператор не умеет пробрасывать дополнительные диски в init-контейнеры! Благо, есть подходящий PR, которым мы и дополнили свою сборку оператора.
3. Перезапуск PgSQL при проблемах с control plane
В процессе эксплуатации кластеров на основе Patroni в Kubernetes мы получили от клиента странную проблему: ровно в 4 часа ночи по Москве обрывались все подключения PostgeSQL. Разбираясь в ситуации, мы обнаружили следующее в логах Spilo:
2020-10-21 01:01:10,538 INFO: Lock owner: production-db-0; I am production-db-0
2020-10-21 01:01:14,759 ERROR: failed to update leader lock
2020-10-21 01:01:15,236 INFO: demoted self because failed to update leader lock in DCS
2020-10-21 01:01:15,238 INFO: closed patroni connection to the postgresql cluster
2020-10-21 01:01:15 UTC [578292]: [1-1] 5f8f885b.8d2f4 0 LOG: Auto detecting pg_stat_kcache.linux_hz parameter...Согласно issue на GitHub, это означает, что Patoni не смог обработать ошибку Kubernetes API и упал с ошибкой. А проблемы с API были связаны с тем, что в 4 часа стартовали сразу 50 CronJob, что приводило к проблемам в etcd:
2020-10-21 01:01:14.589198 W | etcdserver: read-only range request "key:\"/registry/deployments/staging/db-worker-db1\" " with result "range_response_count:1 size:2598" took too long (3.688609392s) to executeСитуация исправлена в версии Patroni 2.0. По этой причине мы собрали версию Spilo из мастера. При сборке стоит учитывать, что требуется взять PR с исправлениями сборки, который на данный момент уже принят в мастер.
4. Пересоздание контейнеров
Напоследок, еще одна интересная проблема. В последнем релизе в оператор была добавлена возможность делать sidecar-контейнеры с их полным описанием в CRD оператора. Разработчики заметили, что базы периодически перезапускаются. В логах оператора было следующее:
time="2020-10-28T20:58:25Z" level=debug msg="spec diff between old and new statefulsets: \nTemplate.Spec.Volumes[2].VolumeSource.ConfigMap.DefaultMode: &int32(420) != nil\nTemplate.Spec.Volumes[3].VolumeSource.ConfigMap.DefaultMode: &int32(420) != nil\nTemplate.Spec.Containers[0].TerminationMessagePath: \"/dev/termination-log\" != \"\"\nTemplate.Spec.Containers[0].TerminationMessagePolicy: \"File\" != \"\"\nTemplate.Spec.Containers[1].Ports[0].Protocol: \"TCP\" != \"\"\nTemplate.Spec.Containers[1].TerminationMessagePath: \"/dev/termination-log\" != \"\"\nTemplate.Spec.Containers[1].TerminationMessagePolicy: \"File\" != \"\"\nTemplate.Spec.RestartPolicy: \"Always\" != \"\"\nTemplate.Spec.DNSPolicy: \"ClusterFirst\" != \"\"\nTemplate.Spec.DeprecatedServiceAccount: \"postgres-pod\" != \"\"\nTemplate.Spec.SchedulerName: \"default-scheduler\" != \"\"\nVolumeClaimTemplates[0].Status.Phase: \"Pending\" != \"\"\nRevisionHistoryLimit: &int32(10) != nil\n" cluster-name=test/test-psql pkg=cluster worker=0Ни для кого не секрет, что при создании контейнера и pod’а добавляются директивы, которые не обязательно описывать. К ним относятся:
-
DNSPolicy; -
SchedulerName; -
RestartPolicy; -
TerminationMessagePolicy; - …
Логично предположить, чтобы такое поведение учитывалось в операторе, однако, как оказалось, он плохо воспринимает секцию портов:
ports:
- name: sftp
containerPort: 22При создании pod’а автоматически добавляется протокол TCP, что не учитывается оператором. Итог: чтобы решить проблему, надо или удалить порты, или добавить протокол.
Заключение
Управление PostgreSQL в рамках Kubernetes — нетривиальная задача. Пожалуй, на текущий момент на рынке нет оператора, который покрывал бы все потребности DevOps-инженеров. Однако среди уже существующих инструментов есть продвинутые и довольно зрелые варианты, из которых можно выбрать то, что лучше всего соответствует имеющимся потребностям.
Наш опыт говорит о том, что не стоит ждать стремительного и магического решения всех проблем. Тем не менее, мы в целом довольны имеющимся результатом, пусть он и требует периодического внимания с нашей стороны.
Говоря же об операторах, рассмотренных в этой части статьи (KubeDB и StackGres), стоит отметить, что они оснащены уникальными функциями для управления бэкапами из кластера, что может стать одним из факторов роста их популярности в ближайшем будущем.
P.S.
Читайте также в нашем блоге:
