
Кажется, это уже стало традицией: каждый раз, когда я выхожу на новое рабочее место, моя деятельность начинается с бенчмарков различных SDS-решений. Мой приход во «Флант» не стал исключением. Я попал в команду разработки Kubernetes-платформы Deckhouse, где решили развивать возможность запуска виртуальных машин в Kubernetes. Но для этого сначала потребовалось найти простое и надежное хранилище блочного типа, которое можно предложить клиентам платформы.
Я взял несколько свободных решений и протестировал, как они поведут себя в тех или иных условиях. В первую очередь интересовала производительность DRBD в различных конфигурациях и сравнение с Ceph.
Но рынок программно-определяемых хранилищ не стоит на месте и постоянно растёт. Появляются новые амбициозные проекты, включая недавно релизнутый Mayastor и pet-проект моего товарища-соратника Vitastor. Результаты оказались очень интересными.

Тестовый стенд
Железо
Три сервера: AX61.
CPU: AMD Ryzen 9 3900 (24) @ 3.100GHz.
RAM: Micron 32GB DDR4-3200 ECC UDIMM 2Rx8 CL22 (по четыре в каждом сервере).
Диски: SAMSUNG MZQLB1T9HAJR-00007 1.92 TB (по два в каждом сервере).
Сеть: 10GbE (Intel 82599ES); 1GbE (Intel I210).
Софт
OS: Ubuntu 20.04.3 LTS (Focal Fossa).
Ядро: 5.4.0-54-generic.
Версии компонентов
DRBD: 9.1.4 (linstor-server v1.17.0).
Ceph: 16.2.7 (rook v1.8.2).
Mayastor: 1.0.0
Vitastor: 0.6.12 (kernel 5.13.0-27-generic).
ZFS: 0.8.3
LVM: 2.03.07
Прочее
Размер виртуальных томов: 100 GB (в тестах с одним клиентом); 10 GB (в тестах с несколькими клиентами).
Протокол синхронизации DRBD: C (fully synchronous), битмап включён.
Тесты
Тестирование проводилось в несколько этапов:
производительность «сырых» NVMe;
определение оверхеда для бэкенда (LVM vs LVMThin vs ZFS);
определение оверхеда DRBD;
единичные тесты;
тест в гигабитной сети;
нагрузочное тестирование.
Для того, чтобы подобрать наиболее оптимальные тесты, которые будут отражать реальную действительность, а не просто рисовать красивые цифры, я обратился за помощью к @vitalif. Он активный участник Сeph- и русскоговорящего SDS-комьюнити, к тому же разрабатывает свою собственную кластерную файловую систему — Vitastor. Считаю, что он как никто другой подкован в данном вопросе. И вот уже много лет использует следующие тесты:
fio -name=randwrite_fsync -ioengine=libaio -direct=1 -randrepeat=0 -rw=randwrite -bs=4k -numjobs=1 -iodepth=1 -fsync=1
fio -name=randwrite_jobs4 -ioengine=libaio -direct=1 -randrepeat=0 -rw=randwrite -bs=4k -numjobs=4 -iodepth=128 -group_reporting
fio -name=randwrite -ioengine=libaio -direct=1 -randrepeat=0 -rw=randwrite -bs=4k -numjobs=1 -iodepth=128
fio -name=write -ioengine=libaio -direct=1 -randrepeat=0 -rw=write -bs=4M -numjobs=1 -iodepth=16
fio -name=randread_fsync -ioengine=libaio -direct=1 -randrepeat=0 -rw=randread -bs=4k -numjobs=1 -iodepth=1 -fsync=1
fio -name=randread_jobs4 -ioengine=libaio -direct=1 -randrepeat=0 -rw=randread -bs=4k -numjobs=4 -iodepth=128 -group_reporting
fio -name=randread -ioengine=libaio -direct=1 -randrepeat=0 -rw=randread -bs=4k -numjobs=1 -iodepth=128
fio -name=read -ioengine=libaio -direct=1 -randrepeat=0 -rw=read -bs=4M -numjobs=1 -iodepth=16Приведу небольшой фрагмент из его статьи:
«Почему нужно тестировать именно так?»
Ведь в целом производительность диска зависит от многих параметров:
Размер блока.
Режим — чтение, запись или смешанный режим чтение+запись в разных пропорциях.
Параллелизм — размер очереди и число потоков, то есть, в целом число одновременно запрашиваемых у диска операций.
Длительность теста.
Исходное состояние — пуст, заполнен линейной записью, заполнен случайной записью, заполнен случайной записью на протяжении какого-то времени и т. п.
Распределение данных — например, 10% горячих данных и 90% холодных — или, например, определённое расположение горячих данных (в начале диска).
Другие смешанные режимы тестов, например, тестирование одновременно с разными размерами блоков.
Также и результаты можно интерпретировать с разной степенью детализации — вместо простого среднего числа операций или мегабайт в секунду можно также приводить графики, гистограммы, перцентили и так далее — это, естественно, даст больше информации о поведении тестируемого образца.
Есть и философская сторона тестов — например, производители серверных SSD иногда заявляют о необходимости подготовки диска к тестам путём полной 2-кратной случайной перезаписи, чтобы нагрузить слой трансляции адресов диска, а я считаю, что это на самом деле ставит SSD в неправдоподобно плохие по сравнению с реальной нагрузкой условия; есть сторонники рисования графиков формата «задержка в зависимости от числа операций в секунду», что я считаю немного странным, но тоже возможным подходом — в нём, по сути, строится график F1(q) в зависимости от F2(q) и график обычно получается достаточно замысловатый — но для каких-то применений, может быть, и тоже разумный.
В общем, бенчмаркингом заниматься можно бесконечно, и уж несколько дней, чтобы предоставить полную информацию, точно уйдёт. Этим обычно и занимаются ресурсы типа 3dnews в своих обзорах SSD. А мы не хотим сидеть несколько дней. Мы хотим обозначить набор тестов, которые можно провести быстро и сразу составить примерное представление о производительности.
Посему общая идея — выделить несколько наиболее «крайних» режимов, протестировать диск в них и представить, что остальная часть «амплитудно-скоростной характеристики» диска является некоторой гладкой функцией в пределах изменения параметров между крайними точками. Тем более, что каждому из крайних режимов соответствует и реальное применение в своей категории приложений:
Использующих в основном линейный или крупноблочный доступ. Для таких приложений наиболее важная характеристика — производительность линейного доступа в мегабайтах в секунду. Отсюда режим тестирования линейным доступом 4 МБ блоком со средней очередью — 16-32 операции.
Использующих случайный доступ мелким блоком и при этом способных к распараллеливанию. Отсюда — режимы тестирования случайным доступом 4 КБ блоком (стандартный блок для большинства ФС и, плюс-минус, СУБД) с большой очередью — 128 операций или, если диск не удаётся нагрузить одним потоком CPU с глубиной очереди 128 — тогда в несколько (2-4-8 или больше) потоков по 128 операций.
Использующих случайный доступ мелким блоком и при этом НЕспособных к распараллеливанию. Таких приложений больше, чем вы могли подумать — например, в части записи сюда относятся все транзакционные СУБД. Отсюда вытекают режимы тестирования случайным доступом 4 КБ блоком с очередью 1 и, для записи, с fsync после каждой операции, чтобы диск/СХД не могли нас обмануть и положить запись во внутренний кэш.
На базе этой информации я сделал скрипт, который запускает каждый тест, затем собирает и парсит полученную информацию. Дальнейшие графики в статье будут отражать результаты этих восьми тестов. Каждый тест работал ровно минуту, что нельзя назвать идеальным показателем, однако вполне достаточно для общего сравнения различных решений.
1. Производительность сырых NVMe
Любое тестирование следует начинать с теста самих накопителей. Это стартовая точка, от которой мы будем отталкиваться, чтобы понимать, сколько на самом деле потеряли. По результатам такого теста могу сразу сказать, что диски мне достались разной степени изношенности и выдают немного разные результаты:
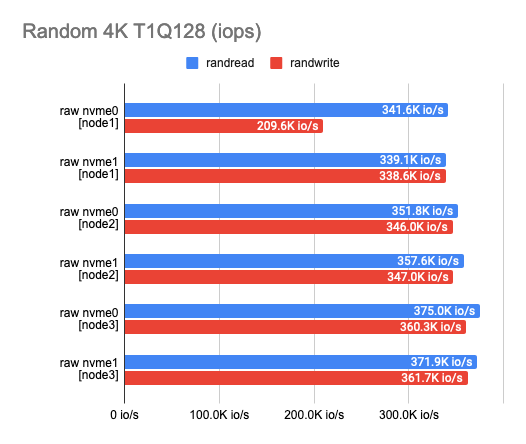

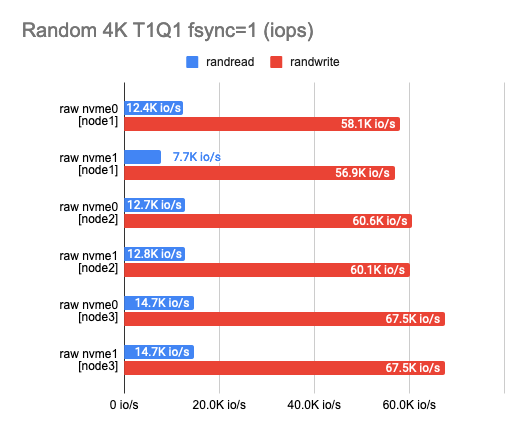

2. Определение оверхеда для бэкенда
После того, как мы сделали замер для локальных дисков, нужно измерить производительность каждого из бэкендов. Как мы знаем, DRBD может работать поверх любого блочного устройства. Это может быть и сырой неразмеченный диск. Однако с приходом DRBD9 стала основной идея использования отдельного устройства (DRBD resource) под каждую виртуалку/контейнер – так лучше масштабирование и меньше область отказа всей системы. А для того, чтобы пачками нарезать новые тома нужного размера, гораздо удобнее иметь logical volume manager. Кроме того, с ним сразу станут доступны и различные фишки вроде live-ресайза, снапшотов, дедупликации и прочего.
LINSTOR поддерживает несколько различных бэкендов, основные — это LVM, LVMThin и ZFS. Между ними и будем сравнивать. Я взял самый быстрый диск на node3 и потестировал каждый из них. Вот что вышло:
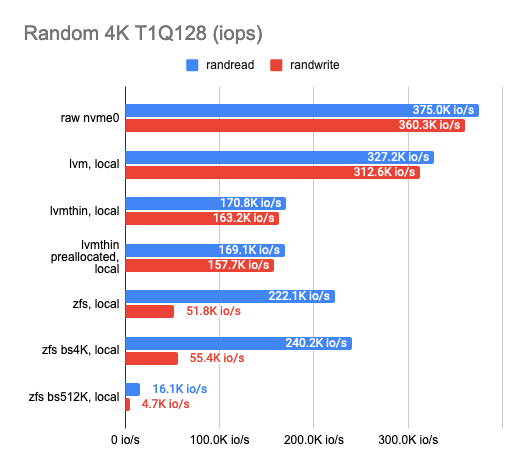



Классический LVM почти не даёт накладных расходов в сравнении с LVMThin и ZFS, но и фич в нем почти никаких нет.
Если мы хотим снапшоты, нужен LVMThin или ZFS, которые по своей природе являются COW-системами и предоставляют возможность делать снапшоты, не влияющие на производительность.
С последовательным чтением/записью у LVMThin всё в порядке, а вот случайные операции на чтение/запись оставляют желать лучшего. Если весь том изначально забить нулями (сделать его preallocated), производительность становится лучше и в целом составляет половину от «сырого» накопителя.
Результаты ZFS заметно хуже. Я попытался потюнить её, чтобы исправить ситуацию, поиграв с размером блока, но к сожалению, это почти не сказалось на результатах теста (пробовал 512, 4K, 32K и 512K; по умолчанию стоит 8K). Пониженный размер блока незначительно увеличил показатели, но также сильно возросла latency. Повышенный размер блока увеличил скорость последовательного чтения и записи, но это не то, чего мы хотели добиться.
Тогда я оставил ZFS и решил попробовать тот же финт с LVMThin, но изменение размера блока почти не оказало влияния на результаты теста.
Таким образом делаем вывод: LVM или LVMThin с настройками по умолчанию — наш выбор.
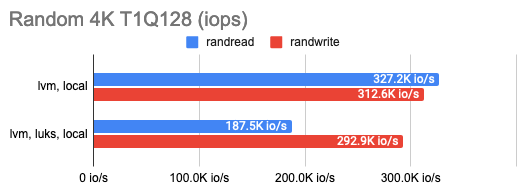
LINSTOR умеет шифровать тома с помощью LUKS, и мне было любопытно, сколько потеряется на таком шифровании. Оказалось, немного: почти нисколько при мелком случайном чтении/записи или последовательных операциях, а при большом количестве случайных операций — всего половину. Это можно увидеть на графиках:

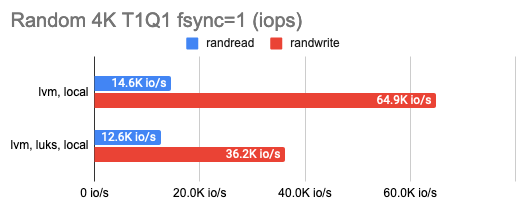
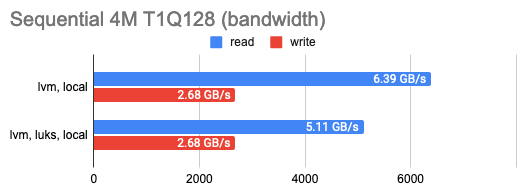
3. Определение оверхеда DRBD
После того, как определились с желаемым бэкендом, я начал работать над определением оверхеда на DRBD-репликацию. Для этого протестировал каждый из доступных бэкендов, но приведу здесь только LVM как самый наглядный пример. Я протестировал DRBD в конфигурации: 1 реплика (чистый оверхед на DRBD), 2 реплики локально, 2 реплики с удалённым diskless-клиентом. Результаты:
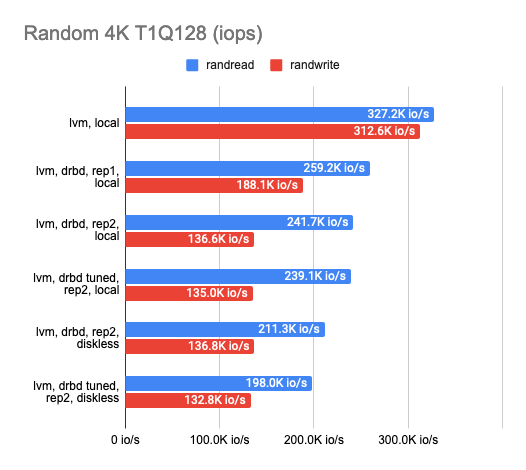
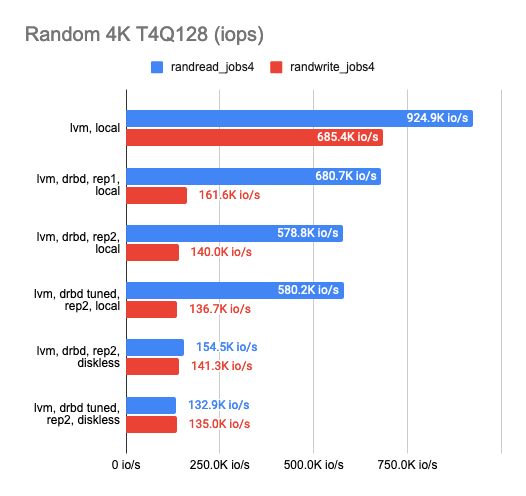

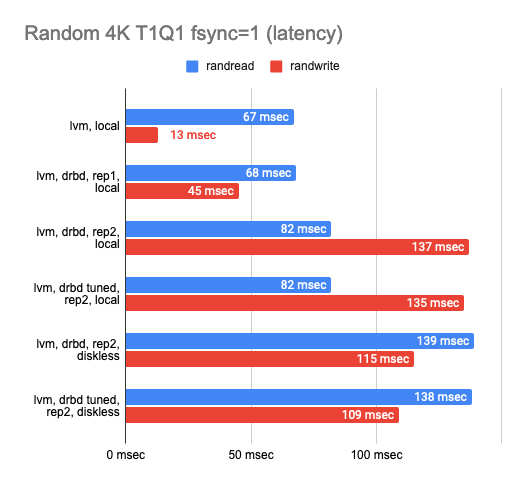

Из графика видно, что DRBD заметно снижает скорость случайной записи/чтения, оставляя последовательные операции почти без оверхеда.
При включении второй реплики скорость операций еще немного снижается, а также растет latency в тестах без параллелизма. Но это правильно: мы же пишем в обе реплики сразу и ждём окончания операции с каждой из них.
В случае diskless-клиента обе реплики находятся на удаленном сервере, поэтому клиенту нужно добраться до каждой из них, а отсюда — ухудшение показателей скорости и увеличение latency.
В целом можно сделать следующие выводы:
С двумя репликами и локальным использованием одной из них мы имеем только треть изначальной производительности «сырого» устройства и вдвое растёт latency, хотя фактически это просто оверхед на CPU.
С двумя репликами и удалённым diskless-клиентом имеем только четверть, а то и меньше с ещё двукратным увеличением latency.
Тюнинг DRBD практически не повлиял на финальный результат и в дальнейших тестах не использовался.
4. Единичные тесты
Кажется, что уже много потеряно на всех уровнях абстракций, так что на этом этапе я начал сравнивать стек DRBD с другими решениями. Таковых было три: Ceph RBD, Mayastor и экспериментальное хранилище моего друга — Vitastor. Чтобы сравнение было более честным, выберем не самый быстрый бэкенд — LVMThin, который поддерживает COW и создание снапшотов, как и многие другие кластерные ФС (за исключением Mayastor).
И вот что вышло:

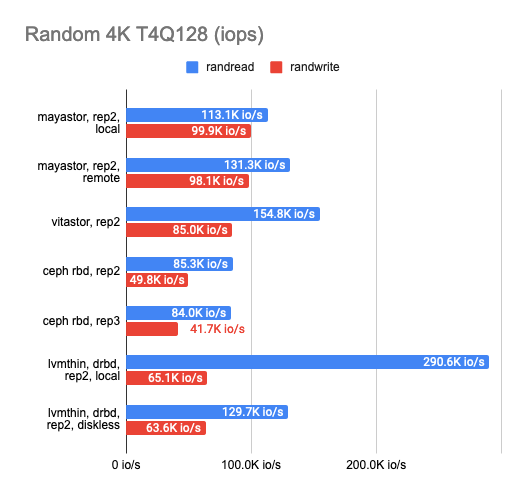



Результаты удивили. Локальный Mayastor оказался на первом месте по операциям случайной записи, на втором — Vitastor, на третьем — локальный DRBD, а затем Ceph и diskless DRBD. Локальный DRBD проявил себя лучше в тестах на чтение, продемонстрировав хорошие результаты и наименьшую latency.
5. Тест в гигабитной сети
Также было интересно, как каждое из решений поведёт себя в условиях гигабитной сети:

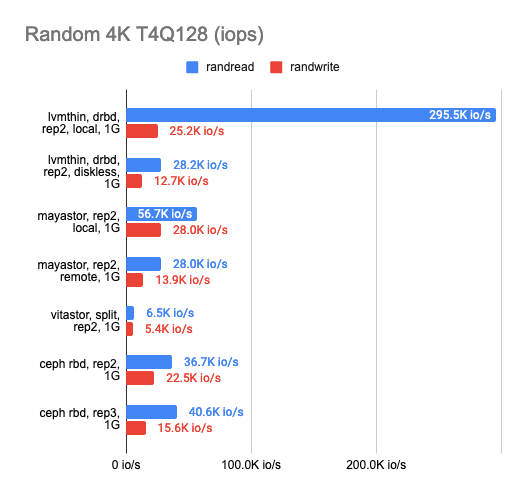

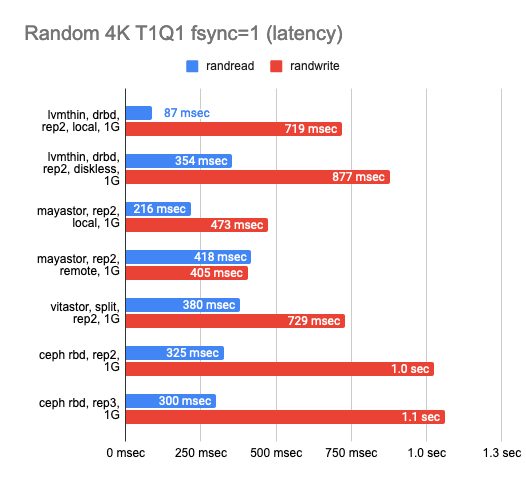
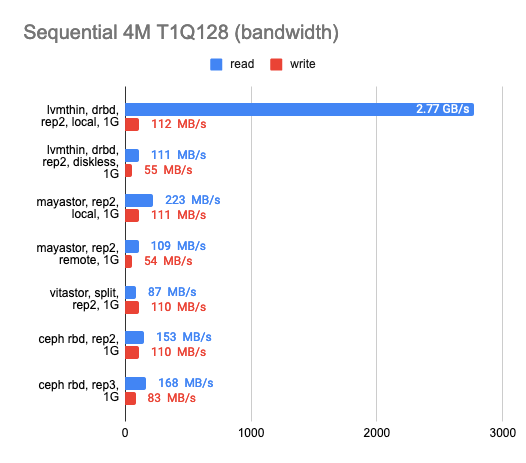
По результатам можно видеть, что все четыре решения без проблем «прокачали» гигабитную сеть, но результаты оставляют желать лучшего. Mayastor показал себя чуть лучше других. Локальный DRBD показал просто превосходное чтение, но запись одинаково плоха у всех решений.
6. Нагрузочное тестирование
Но вот мы и подобрались к самому интересному — нагрузочному тестированию. Тесты выше были предназначены в первую очередь для понимания возможностей хранилища. Сейчас же попробуем сэмулировать реальную нагрузку и посмотреть, как каждое из решений сможет с ней справиться.
Запускать будем стандартный r/w-тест, где смешаем 75% операций случайного чтения и 25% случайной записи, и запустим его в нескольких экземплярах.
fio -name=test -filename=/dev/xvda -ioengine=libaio -direct=1 -rw=randrw -rwmixread=75 -bs=4k -numjobs=1 -iodepth=64 -size=4GВ этот раз установим ограничение по времени в 15 минут и посмотрим, сколько тестов успеют отработать за это время, а затем соберём обобщенную статистику.
Так как LINSTOR и Mayastor предлагают установить volumeBindingMode: WaitForFirstConsumer, т.е. произвести provisioning томов на тот же узел, куда прилетит наш Pod, и всегда иметь локальный том, они имеют небольшую фору перед другими решениями. Я решил отключить эту функцию, чтобы посмотреть сравнить решения в максимально схожих условиях.
Так же в данном тесте Ceph был настроен так, чтобы иметь по два OSD на каждый диск и большее количество Placement Groups (512).

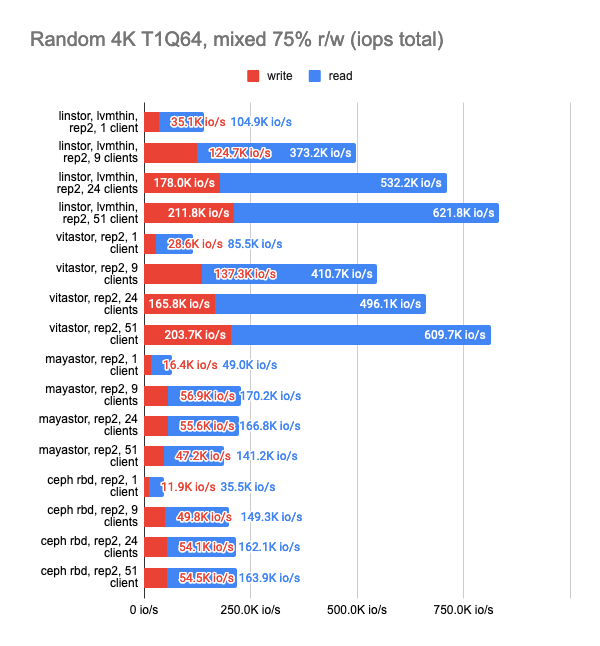



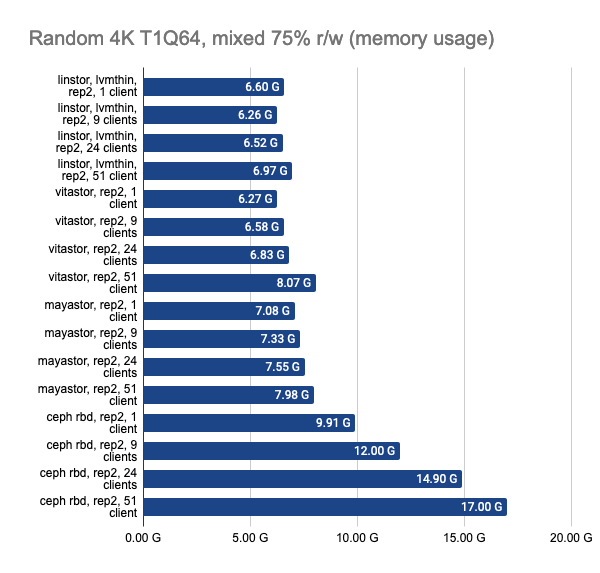
Последние два графика показывают общее потребление ресурсов на узле, но они отображают не совсем объективную информацию, поэтому не стоит их сходу принимать за чистую воду, а для более детального изучения предлагается взглянуть на снапшоты из Grafana.
Снапшоты из Grafana:
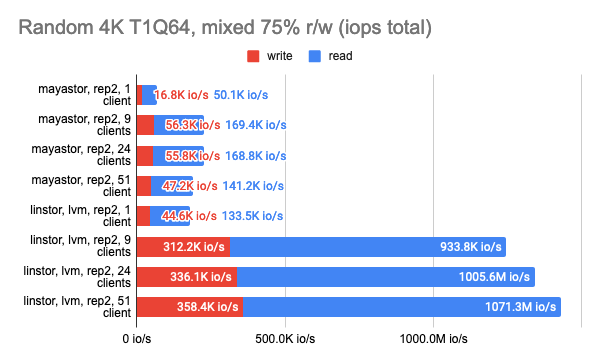
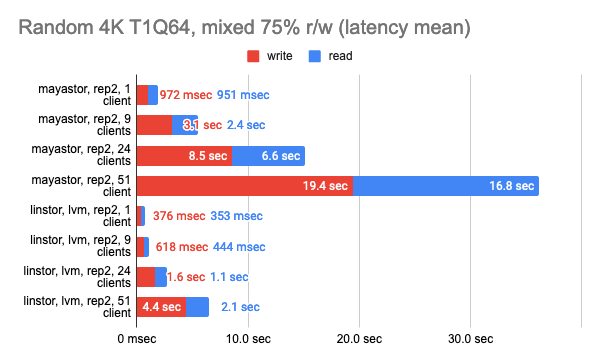
LINSTOR показал стабильно хорошую производительность даже при большом количестве клиентов, однако Vitastor практически не уступает ему. За ними с большим отрывом следуют Mayastor и Ceph. К тому же, Ceph значительно больше потребляет оперативной памяти и процессорного времени, чего нельзя не заметить на графиках в Grafana.
Здесь стоит напомнить, что Mayastor на данный момент не поддерживает COW и снапшоты, поэтому можно смело сравнивать его с LINSTOR с LVM-бэкендом:
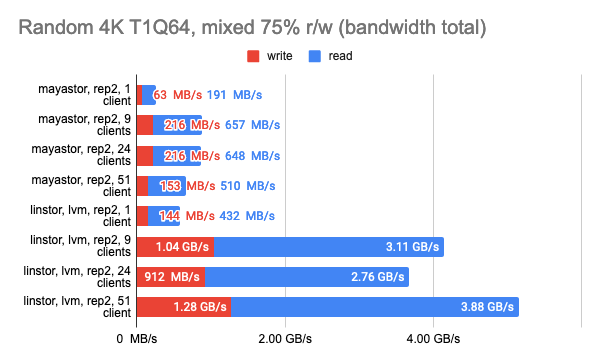


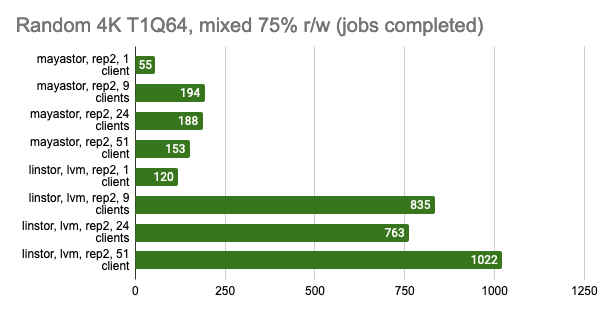

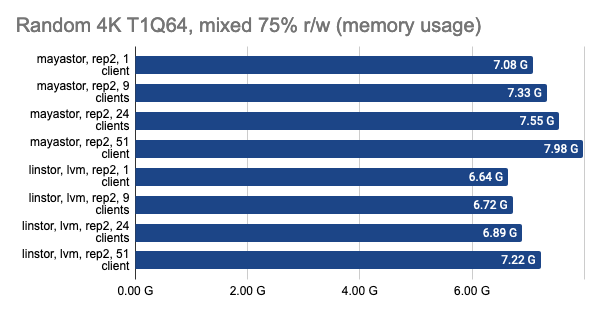
Снапшоты из Grafana:
Тест LINSTOR с 24 локальными клиентами показал довольно странный результат — видимо, в этот момент кластер был загружен чем-то ещё. Но в целом тенденция заметна: LINSTOR в конфигурации LVM сильно превзошел Mayastor. Зато Mayastor показал меньший Load Average на процессор.
А также мы можем принудительно включить volumeBindingMode: WaitForFirstConsumer и посмотреть, насколько изменятся результаты теста. Напомню, в этом режиме мы всегда имеем хотя бы одну реплику локально там же, где и запущен Pod:


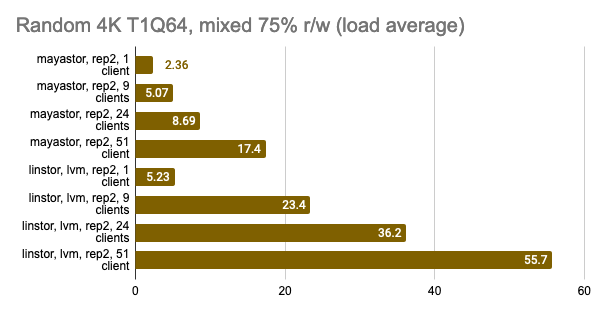

Снапшоты из графаны:
Выводы
Исходя из проведенных нами тестов можно сказать, что в данной конфигурации:
LINSTOR является одним из самых быстрых хранилищ.
За ним практически не отстаёт Vitastor, который, имея Ceph-подобную архитектуру, выглядит очень интересно. Например, в кластерах с большим количеством узлов это позволило бы распределять нагрузку отдельных блочных устройств между всеми узлами в кластере.
Mayastor показывает неплохую производительность, но на данный момент совершенно не имеет фич. LINSTOR в схожей конфигурации заметно превосходит его с большим количеством клиентов.
Ceph потребляет много ресурсов узла и, как правило, всё упирается именно в них. Надеемся, что авторы допилят новый бэкенд Crimson, после чего результаты станут лучше.
Для себя мы пока решили остановиться на LINSTOR как на наиболее зрелом для production решении. Попробовать LINSTOR уже можно в текущем релизе Deckhouse — v1.31 (инструкции по установке доступны здесь).
Также не поленитесь почитать наши заметки о производительности и рекомендации по выбору бэкенда для хранилища LINSTOR в Deckhouse.
Напоминание про надёжность
По данным тестам можно судить о производительности того или иного решения, однако не стоит забывать об отказоустойчивости. Прежде чем делать какие-то выводы, крайне необходимо удостовериться в надежности выбранного решения и провести краш-тесты, однако это уже выходит за рамки данной статьи.
Мы, по имеющемуся опыту, уверены в надёжности Ceph и LINSTOR, но решили оставить свой выбор на LINSTOR, так как это наиболее простое решение, не требующее внешней базы данных для хранения метаданных. LINSTOR может хранить свою конфигурацию напрямую в Kubernetes CRDs. К тому же, за несколько лет у меня уже скопилась большая экспертиза по внедрению и использованию LINSTOR в production-окружениях.
Тем не менее, мой опыт не стоит рассматривать как абсолютную истину. Принимайте решение исходя из результатов своих собственных требований, экспериментов и опыта. А эта статья пусть послужит вдохновением для проведения подобных экспериментов.
P.S.
Читайте также в нашем блоге:
