Напомним, что в основе Elastic Stack лежат нереляционная база данных Elasticsearch, веб-интерфейс Kibana и сборщики-обработчики данных (самый известный Logstash, различные Beats, APM и другие). Одно из приятных дополнений всего перечисленного стека продуктов — анализ данных при помощи алгоритмов машинного обучения. В статье мы разбираемся что из себя представляют эти алгоритмы. Просим под кат.
Машинное обучение — платная функция условно-бесплатного Elastic Stack и входит в пакет X-Pack. Чтобы начать им пользоваться достаточно после установки активировать 30-дневный триальник. После истечения пробного периода можно запросить поддержку о его продлении или купить подписку. Стоимость подписки рассчитывается не от объёма данных, а от количества используемых нод. Нет, объём данных влияет, конечно, на количество необходимых нод, но всё же такой подход к лицензированию более гуманный по отношению к бюджету компании. Если нет нужды в высокой производительности — можно и сэкономить.
ML в Elastic Stack написан на С++ и работает за пределами JVM, в которой крутится сам Elasticsearch. То есть процесс (он, кстати, называется autodetect) потребляет всё, что не проглотит JVM. На демо-стенде это не так критично, а вот в продуктивной среде важно выделить отдельные ноды для задач ML.
Алгоритмы машинного обучения делятся на две категории — с учителем и без учителя. В Elastic Stack алгоритм из категории «без учителя». По этой ссылке можно посмотреть математический аппарат алгоритмов машинного обучения.
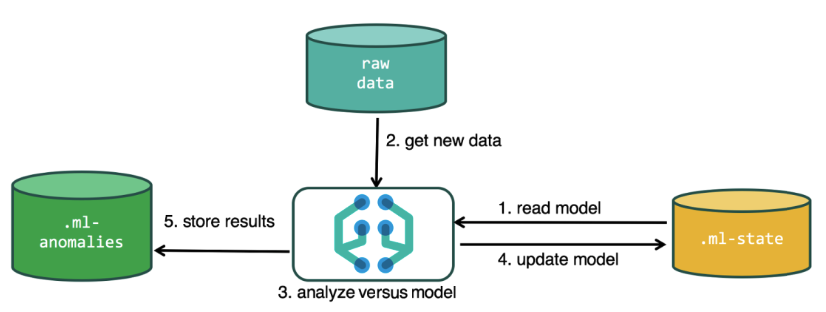
Для проведения анализа алгоритм машинного обучения использует данные, хранящиеся в индексах Elasticsearch. Создавать задания для анализа можно как из интерфейса Kibana так и через API. Если делать это через Kibana, то некоторые вещи знать необязательно. Например, дополнительные индексы, которые использует алгоритм в процессе работы.
Дополнительные индексы, используемые в процессе анализа
.ml-state — информация о статистических моделях (настройках анализа);
.ml-anomalies-* — результаты работы алгоритмов ML;
.ml-notifications — настройки оповещений по результатам анализа.
.ml-anomalies-* — результаты работы алгоритмов ML;
.ml-notifications — настройки оповещений по результатам анализа.
Структура данных в базе Elasticsearch состоит из индексов и хранящихся в них документах. Если сравнивать с реляционной базой данных, то индекс можно сравнить со схемой базы данных, а документ с записью в таблице. Это сравнение условно и приведено для упрощения понимания дальнейшего материала для тех, кто только слышал про Elasticsearch.
Через API доступен тот же функционал, что и через веб-интерфейс, поэтому для наглядности и понимания концепций мы будем показывать как настраивать через Kibana. В меню слева есть раздел Machine Learning, в котором можно создать новое задание (Job). В интерфейсе Kibana это выглядит как на картинке ниже. Сейчас мы разберем каждый типа задания и покажем виды анализа, которые можно тут сконструировать.
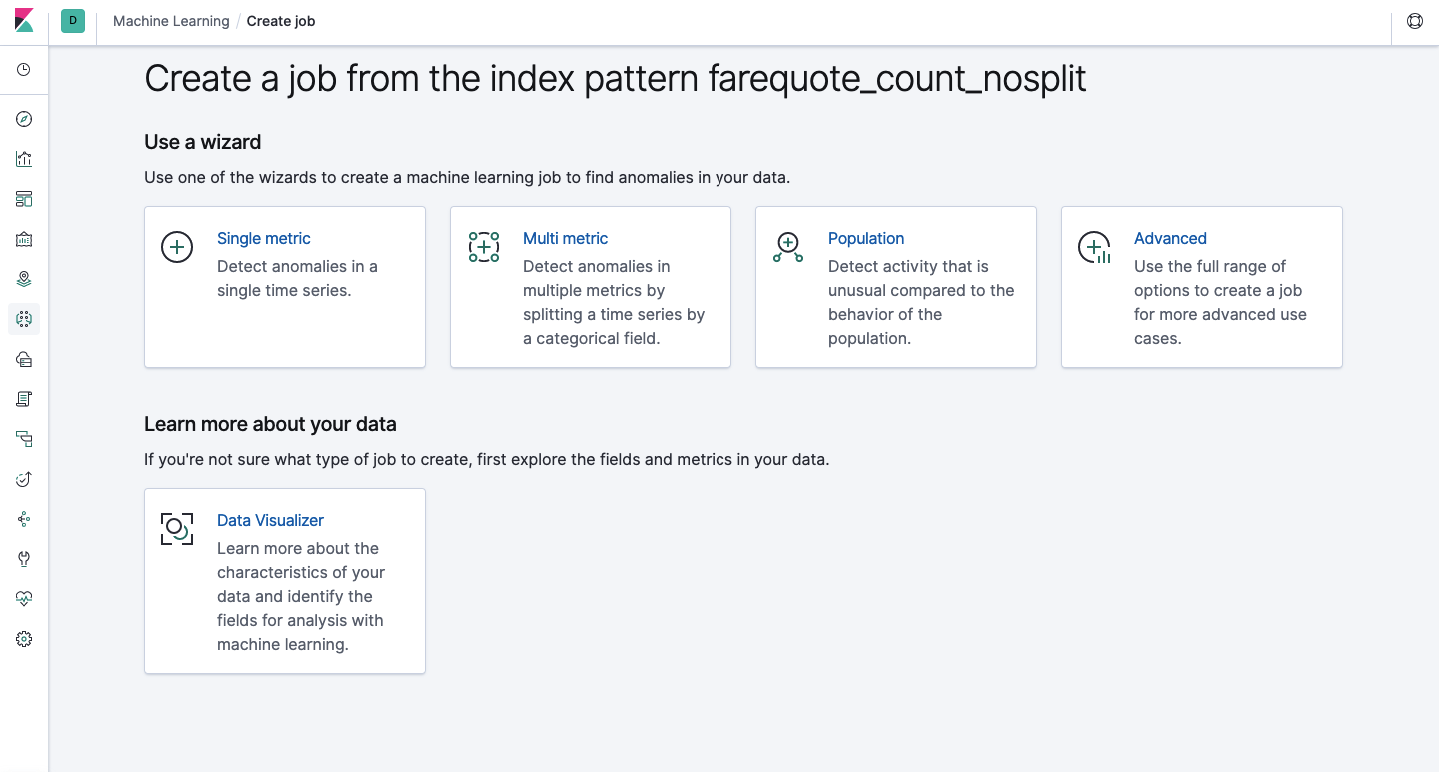
Single Metric — анализ одной метрики, Multi Metric — анализ двух и более метрик. В обоих случаях каждая метрика анализируется в изолированной среде, т.е. алгоритм не учитывает поведение параллельно анализируемых метрик как это могло показаться в случае Multi Metric. Чтобы провести расчёт с учётом корреляции различных метрик можно применить Population-анализ. А Advanced — это тонкая настройка алгоритмов дополнительными опциями для определённых задач.
Single Metric
Анализ изменений одной единственной метрики — самое простое, что можно тут сделать. После нажатия на Create Job, алгоритм поищет аномалии.
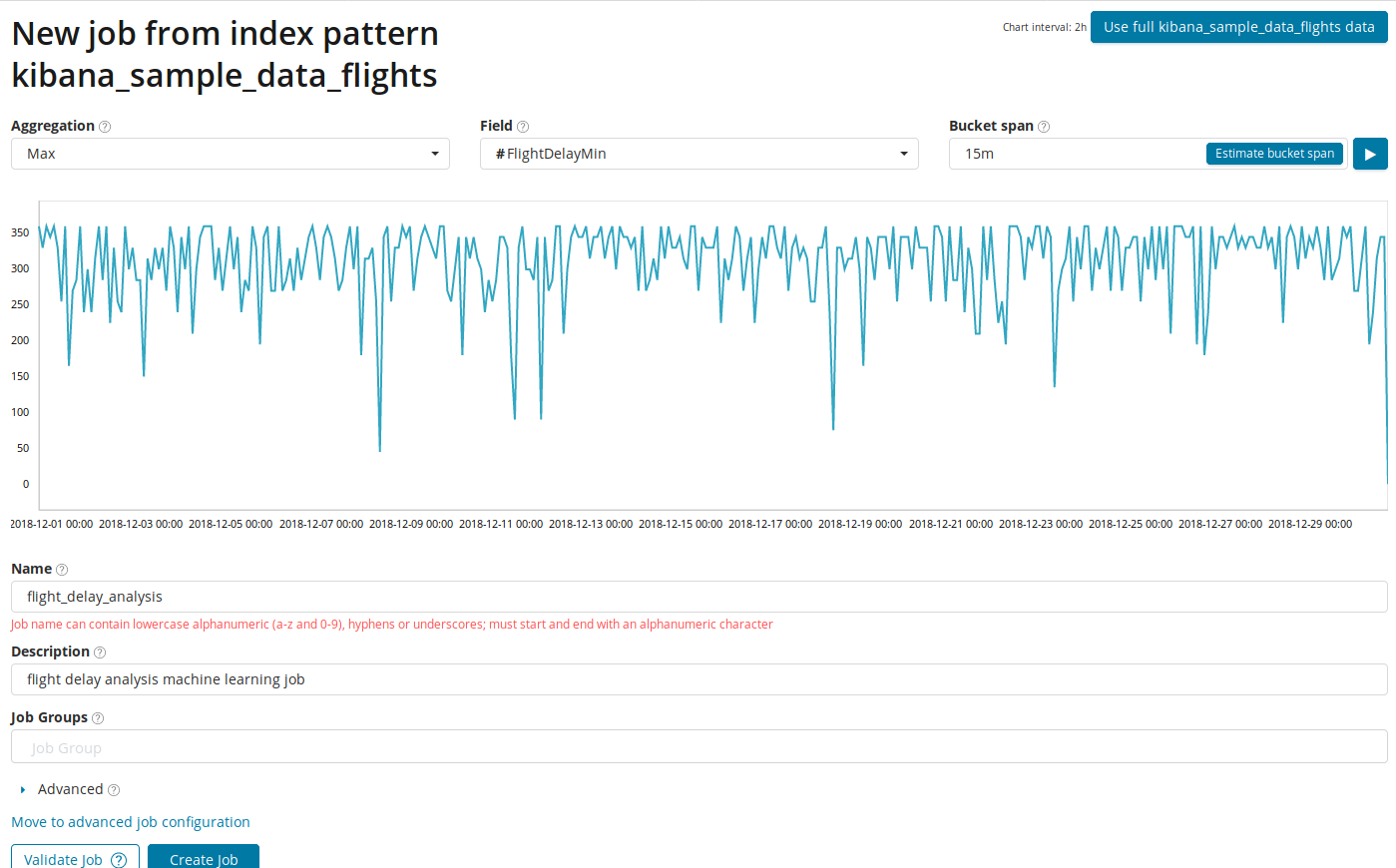
В поле Aggregation можно выбрать подход к поиску аномалий. Например, при Min аномальными будут считаться значения ниже типичных. Есть Max, Hign Mean, Low, Mean, Distinct и другие. Описание всех функций можно посмотреть по ссылке.
В поле Field указывается числовое поле в документе, по которому будем проводить анализ.
В поле Bucket span — гранулярность промежутков на таймлайне, по которым будет вестись анализ. Можно довериться автоматике или выбрать вручную. На изображении ниже приведён пример слишком низкой гранулярности — вы можете пропустить аномалию. С помощью этой настройки можно изменять чувствительность алгоритма к аномалиям.

Длительность собранных данных — ключевая вещь, которая влияет на эффективность анализа. При анализе алгоритм определяет повторяющиеся промежутки, рассчитывает доверительный интервал (базовые линии) и выявляет аномалии — нетипичные отклонения от обычного поведения метрики. Просто для примера:
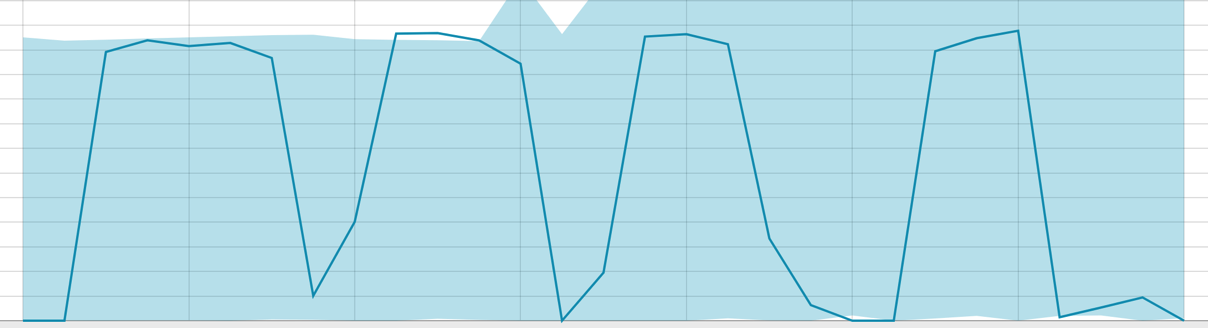
Базовые линии при небольшом отрезке данных:
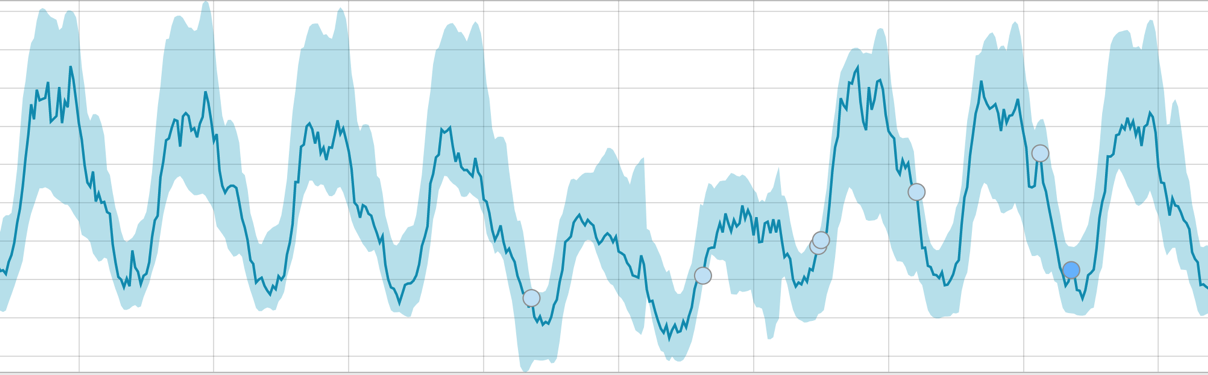
Когда алгоритму есть на чём поучиться — базовые линии выглядит так:
После запуска задания, алгоритм определяет аномальные отклонения от нормы и ранжирует их по вероятности аномалии (в скобках указан цвет соответствующей метки):
Warning (голубой): менее 25
Minor (yellow): 25-50
Major (orange): 50-75
Critical (red): 75-100
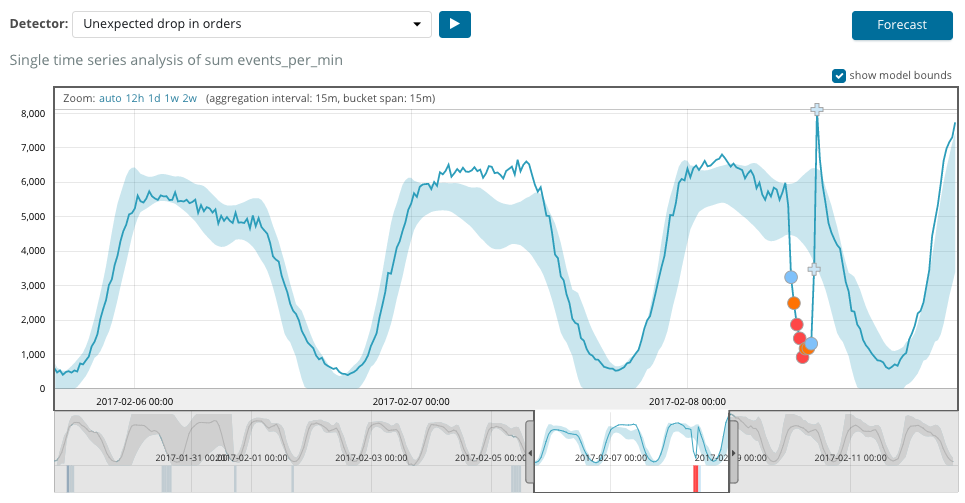
На графике ниже пример с найденными аномалиями.
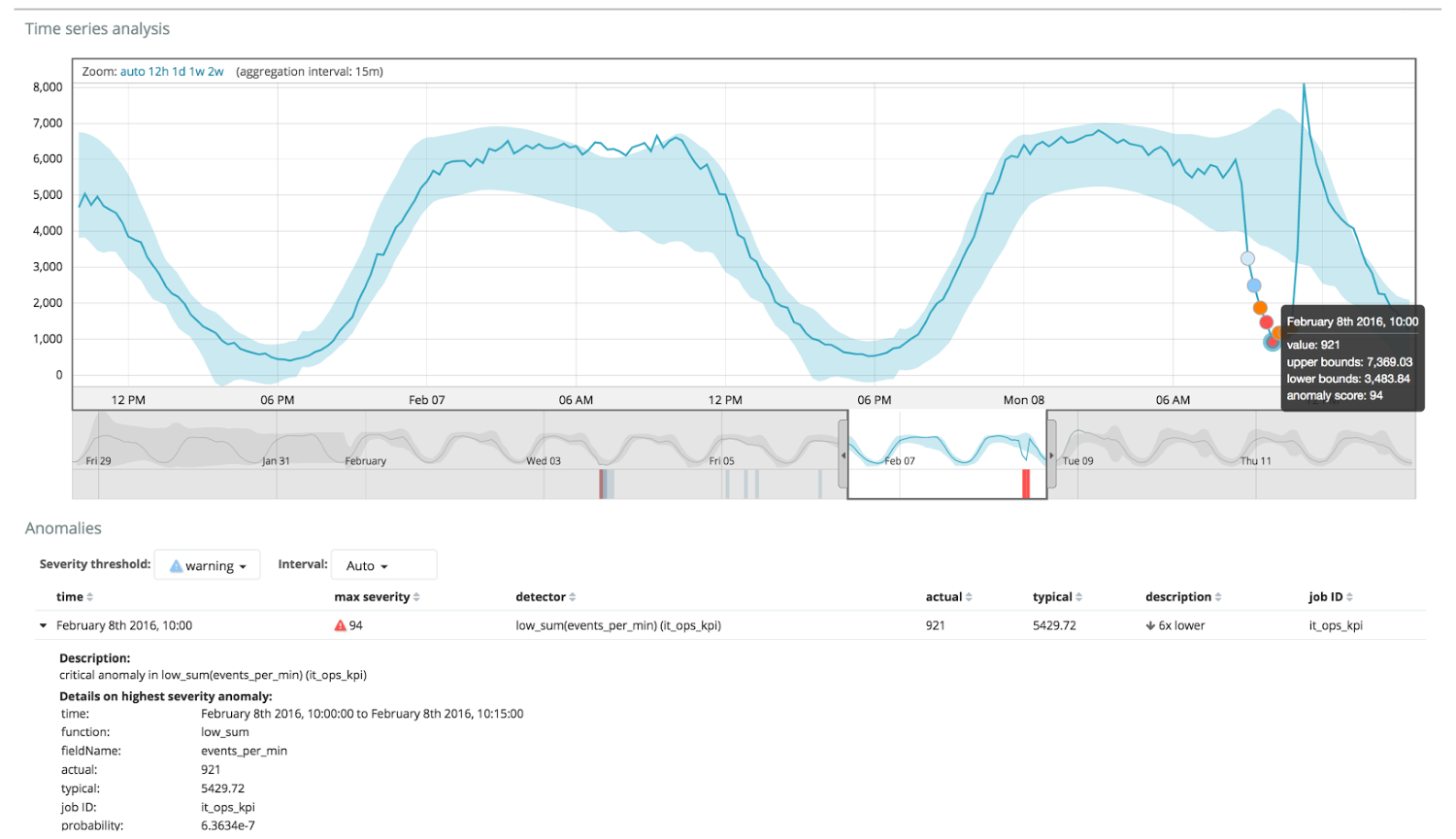
Тут видно цифру 94, которая обозначает вероятность аномалии. Понятно, что раз значение близкое к 100, значит перед нами аномалия. В столбце под графиком указана уничижительно малая вероятность 0.000063634% появления там значения метрики.
Кроме поиска аномалий в Kibana можно запустить прогнозирование. Делается это элементарно и из того же самого представления с аномалиями — кнопка Forecast в верхнем правом углу.

Прогноз строится максимум на 8 недель вперёд. Даже если очень хочется — больше нельзя by design.
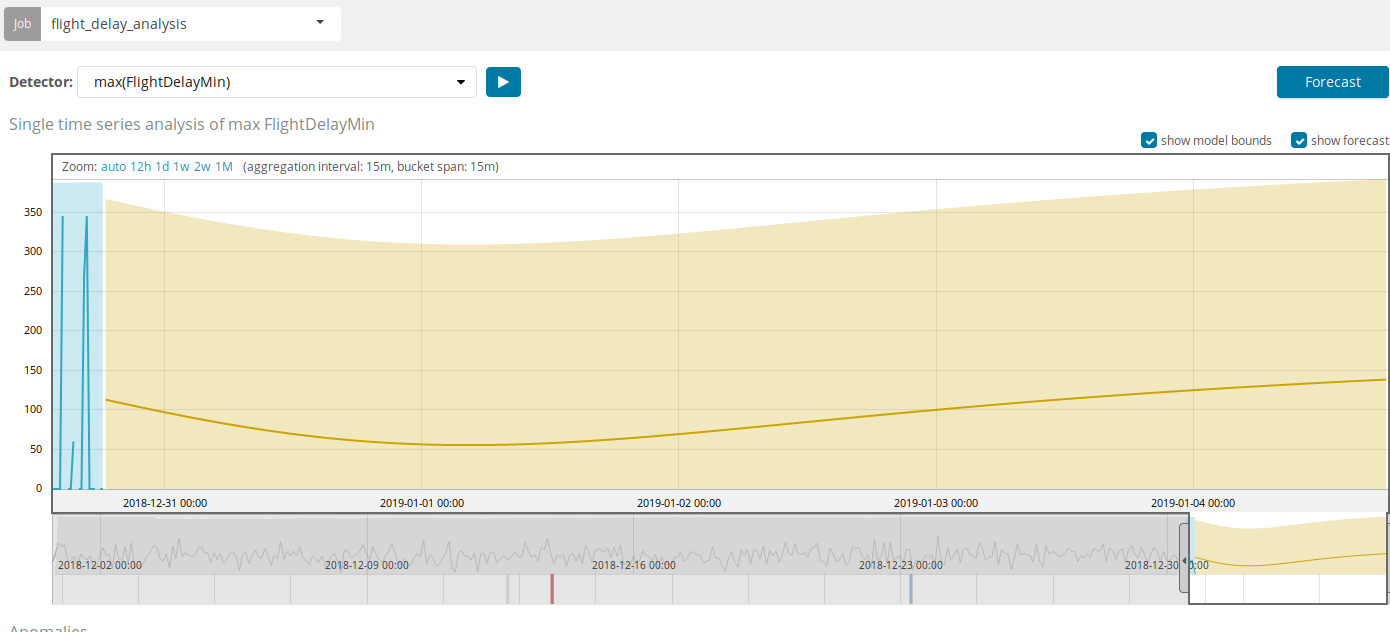
В некоторых ситуациях прогноз будет очень полезен, например, когда отслеживается пользовательская нагрузка на инфраструктуру.
Multi Metric
Переходим к следующей возможности ML в Elastic Stack — анализу нескольких метрик одной пачкой. Но это не значит, что будет анализироваться зависимость одной метрики от другой. Это то же самое, что и Single Metric только с множеством метрик на одном экране для удобства сравнения влияния одного на другое. Про анализ зависимости одной метрики от другой расскажем в части Population.
После нажатия на квадрат с Multi Metric появится окно с настройками. На них остановимся подробнее.
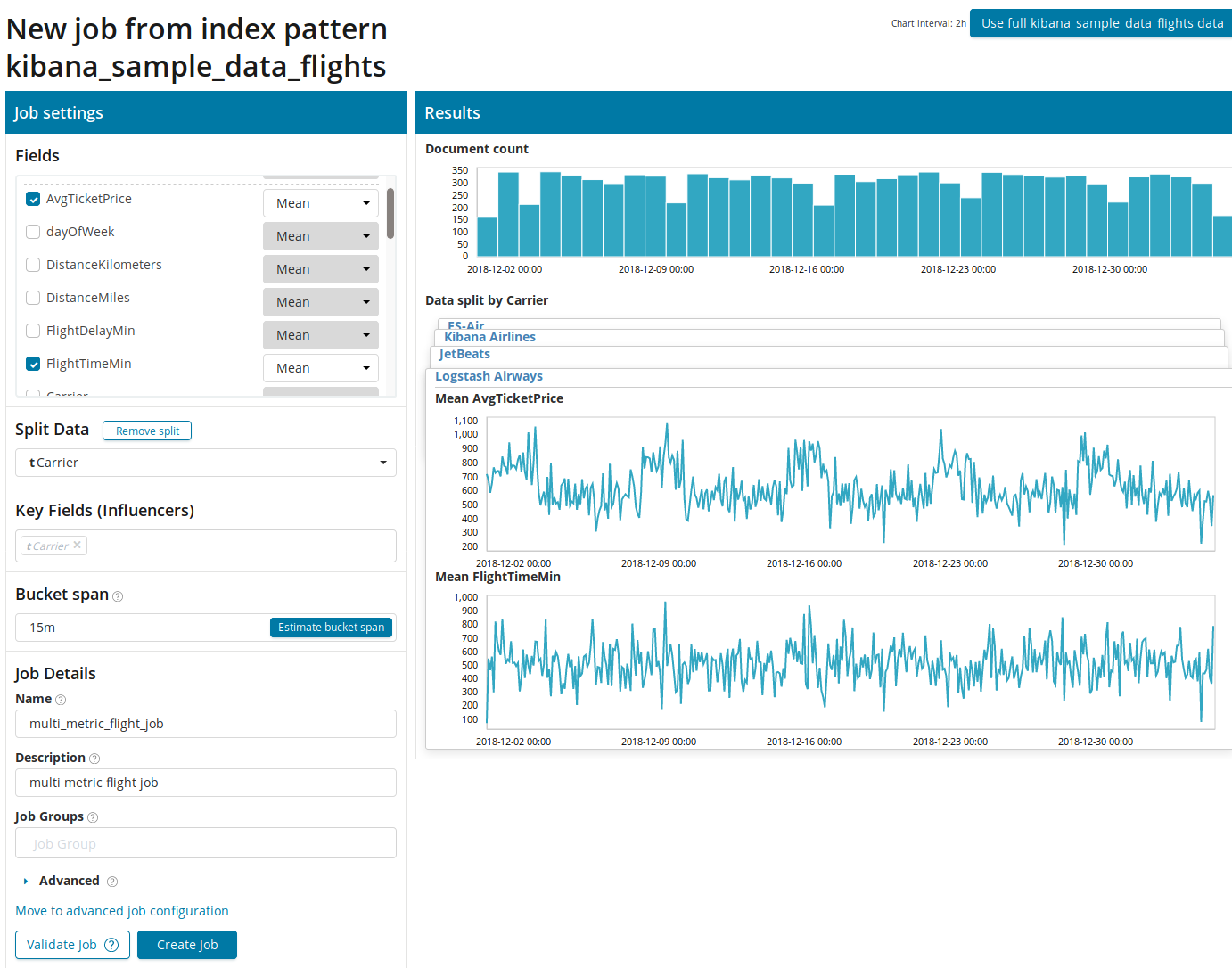
Для начала нужно выбрать поля для анализа и агрегацию данных по ним. Варианты агрегации тут те же, что и для Single Metric (Max, Hign Mean, Low, Mean, Distinct и другие). Далее данные при желании разбиваются по одному из полей (поле Split Data). В примере мы это сделали по полю OriginAirportID. Обратите внимание, что график метрик справа теперь представлен в виде множества графиков.
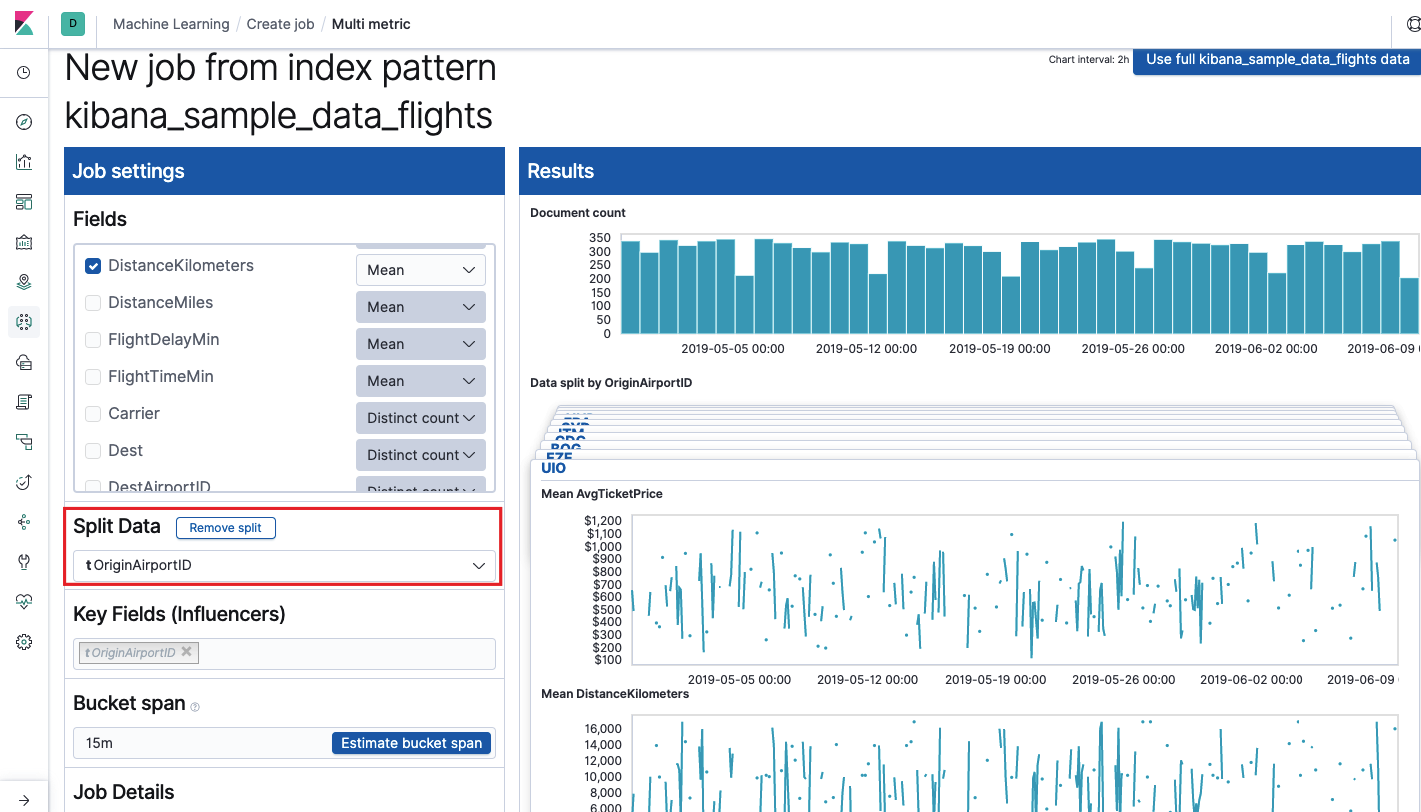
Поле Key Fields (Influencers) напрямую влияет на найденные аномалии. По умолчанию тут всегда будет хотя бы одно значение, а вы можете добавить дополнительные. Алгоритм будет учитывать влияние этих полей при анализе и показывать самые «влиятельные» значения.
После запуска в интерфейсе Kibana появится примерно такая картина.
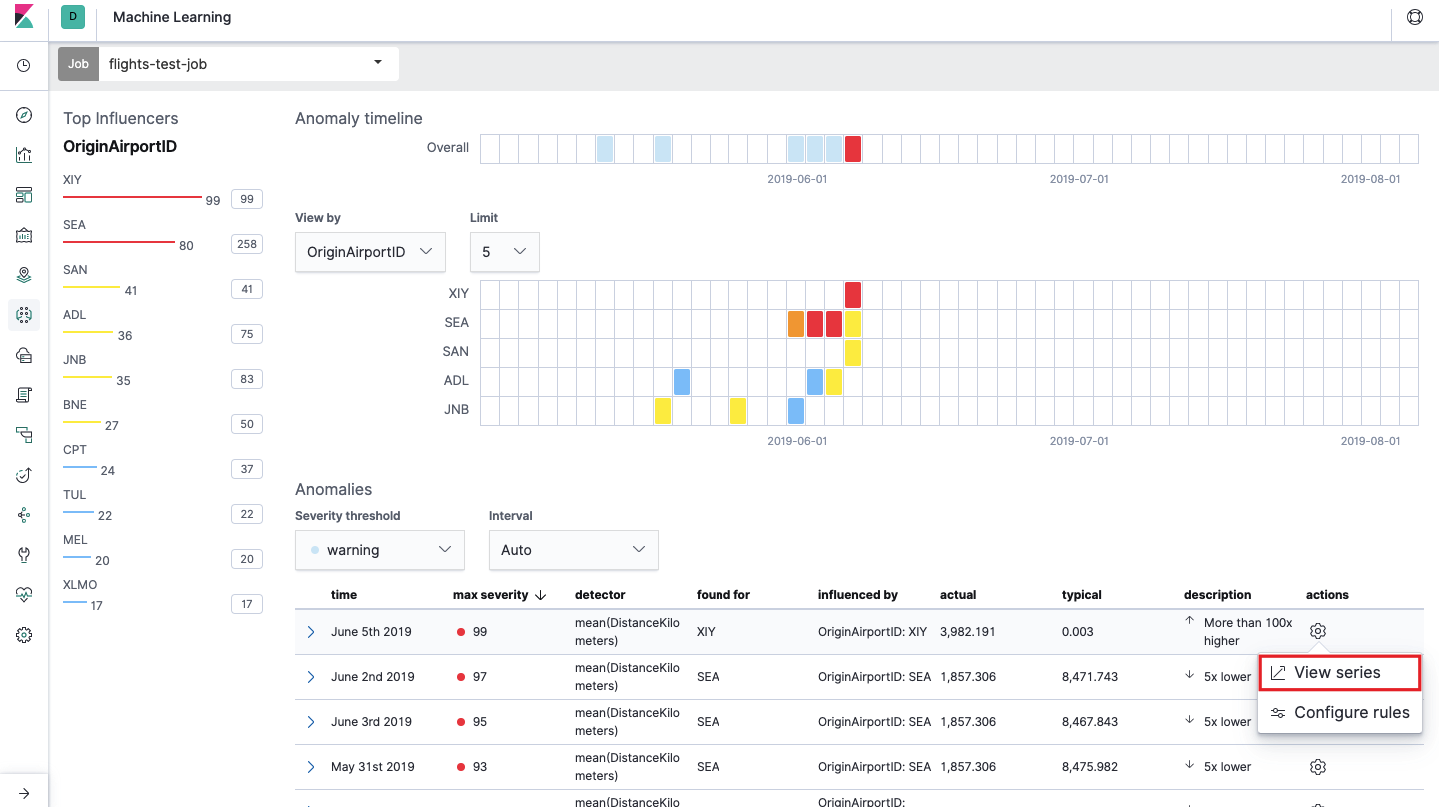
Это т.н. тепловая карта аномалий по каждому значению поля OriginAirportID, которое мы указали в Split Data. Как и в случае с Single Metric, цвет обозначает уровень аномального отклонения. Похожий анализ удобно делать, например, по рабочим станциям для отслеживания тех, где подозрительно много авторизаций и т.д. Мы уже писали о подозрительных событиях в EventLog Windows, которые также можно сюда собирать и анализировать.
Под тепловой картой список аномалий, с каждого можно перейти на представление Single Metric для детального анализа.
Population
Чтобы искать аномалии среди корреляций между разными метриками в Elastic Stack есть специализированный Population-анализ. Именно с помощью него можно поискать аномальные значения в производительности какого-либо сервера по сравнению с остальными при, например, увеличении количества запросов к целевой системе.
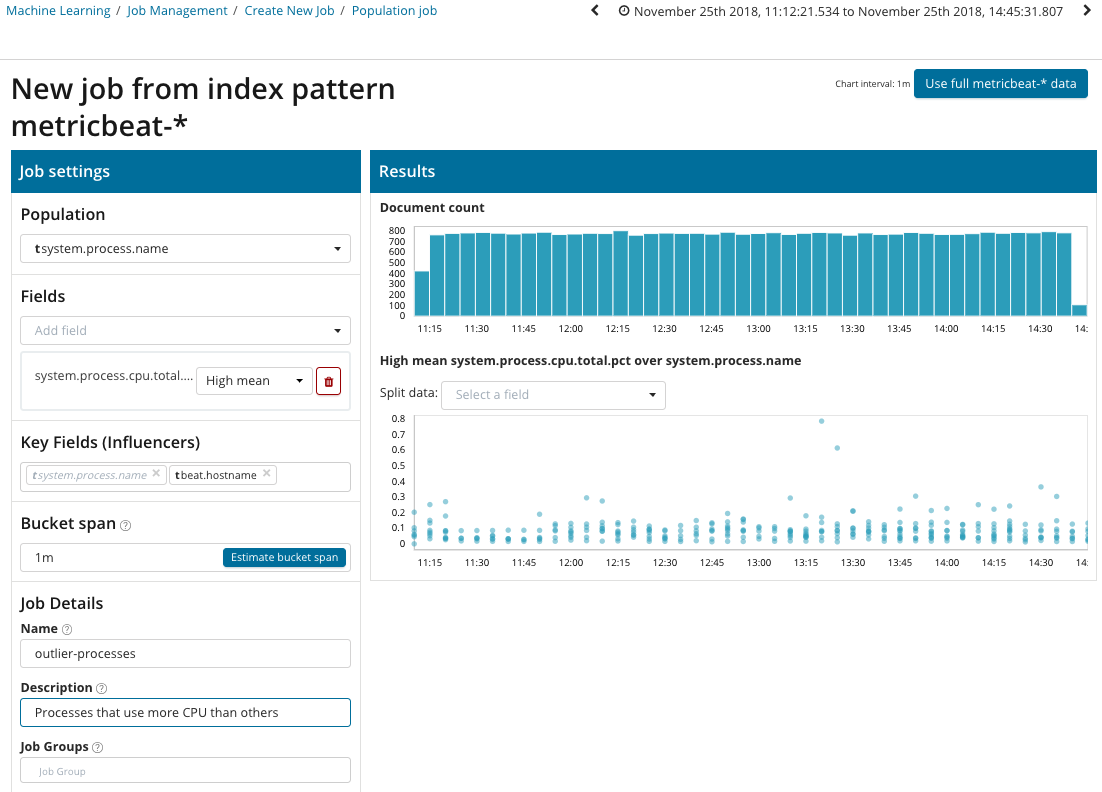
На этой иллюстрации в поле Population указано значение, к которому будут относиться анализируемые метрики. В данном это имя процесса. В результате мы увидим как загрузка процессора каждым из процессов влияла друг на друга.
Обратите внимание, что график анализируемых данных отличается от случаев с Single Metric и Multi Metric. Это сделано в Kibana by design для улучшенного восприятия распределения значений анализируемых данных.

Из графика видно, что аномально вёл себя процесс stress (к слову сказать, порождённый специальной утилитой) на сервере poipu, который повлиял (или оказался инфлюэнсером) на возникновение этой аномалии.
Advanced
Аналитика с тонкой настройкой. При Advanced анализе в Kibana появляются дополнительные настройки. После нажатия в меню создания на плитку Advanced появляется вот такое окно с вкладками. Вкладку Job Details пропустили намеренно, там базовые настройки не относящиеся непосредственно к настройке анализа.
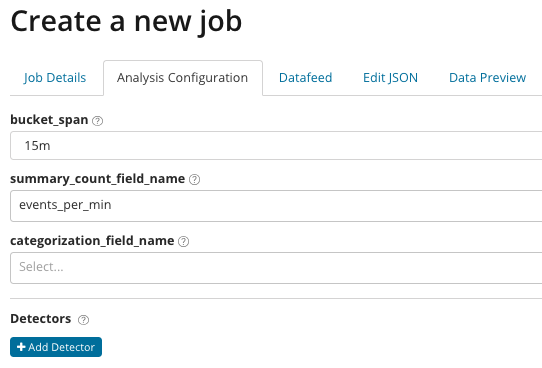
В summary_count_field_name опционально можно указать название поля из документов, содержащего агрегированные значения. В этом примере — количество событий в минуту. В categorization_field_name указывается название значение поля из документа, которое содержит некое переменное значение. По маске на это поле можно разбивать анализируемые данные на подмножества. Обратите внимание на кнопку Add detector на предыдущей иллюстрации. Ниже результат нажатия на эту кнопку.

Здесь дополнительный блок настроек для настройки детектора аномалий под определённую задачу. Конкретные кейсы использования (особенно по безопасности) мы планируем разобрать в следующих статьях. Для примера, посмотрите один из разобранных кейсов. Он связан с поиском редко появляющихся значений и реализуется функцией rare.
В поле function можно выбрать определённую функцию для поиска аномалий. Кроме rare, есть ещё пара интересных функций — time_of_day и time_of_week. Они вывляют аномалии в поведении метрик на протяжении дня или недели соответственно. Остальные функции анализа есть в документации.
В field_name указывается поле документа, по которому будет вестись анализ. By_field_name может использоваться для разделения результатов анализа по каждому отдельному значению указанного здесь поля документа. Если заполнить over_field_name получится population-анализ, который мы рассматривали выше. Если указать значение в partition_field_name, то по этому полю документа будут рассчитываться отдельные базовые линии для каждого значения (в роли значения могут выступать, например, название сервера или процесса на сервере). В exclude_frequent можно выбрать all или none, что будет означать исключение (или включение) часто встречающихся значений полей документов.
В статье мы попытались максимально сжато дать представление о возможностях машинного обучения в Elastic Stack, за кадром осталось ещё немало подробностей. Расскажите в комментариях какие кейсы удалось решить при помощи Elastic Stack и для каких задач вы его используете. Для связи с нами можно использовать личные сообщения на Хабре или форму обратной связи на сайте.
А ещё у нас есть:
Как лицензируется и чем отличаются лицензии Elastic Stack (Elasticsearch)
Elasticsearch: сайзинг шардов как завещал Elastic
Elastic под замком: включаем опции безопасности кластера Elasticsearch для доступа изнутри и снаружи
Мы разработали обучающий курс по основам работы с Elastic Stack, который адаптируется под конкретные потребности заказчика. Подробная программа обучения по запросу.
