У нас было несколько сотен тысяч чатов в месяц, восемь языков разных групп, миллионы строк неразмеченных данных, тысячи тематик чатов из разных областей нашей экосистемы и команда из 7 человек. Не то чтобы всё это было категорически необходимо, но если уж начал автоматизацию чатов, то к делу надо подходить серьёзно. Единственное, что нас беспокоило, — это процент автоматизации. В мире нет ничего более непонятного, сложного и запутанного, чем естественный язык и поведение клиентов. И я знал, что довольно скоро мы в это окунёмся.

Все, что будет сказано ниже, не сильно привязано к специфике нашего продукта или конкретного решения. А даже наоборот: какие-то подробности умышленно опущены. Поэтому статья будет полезна для всех, у кого в компании есть клиентский сервис. У кого он еще и мультиязычный, то тем более. В общем
life.set_seed(hash("Garage Eight")) Мне нужна твоя поддержка
Клиентский сервис — это одно из конкурентных преимуществ нашего продукта. Поддержка клиентов в чатах реального времени является важной составляющей клиентского сервиса.
Продукт рос, число клиентов увеличивалось, как и нагрузка на клиентский сервис. Это в свою очередь провоцировало снижение SLA. Клиенты долго ждут в очереди, долго ждут ответы на свои реплики, получают менее качественную поддержку. Как следствие, расстраиваются или даже остаются без решения своих проблем. Агенты поддержки перегружены, берут увеличенное количество чатов в обработку, теряют фокус. Как следствие, не справляются или даже выгорают.
С этим определенно надо было что-то делать. Мы и раньше снижали нагрузку в чатах. Улучшали UI/UX, упрощали взаимодействие с продуктом, исправляли баги, разрабатывали инструменты для агентов поддержки. Это уже классическая ситуация, когда продукт выходит на стадию взрывного, экспоненциального роста, и оказывается, что не только технические системы не предусмотрены для этого, но в том числе и человеческие, сопровождающие ресурсы. Поэтому в данном случае был необходим принципиально новый подход. Требовалось разработать решение, которое снимет не фиксированное количество чатов, а позволит снижать нагрузку кратно её росту. Позволит наращивать снижение нагрузки до необходимого уровня. Этим решением была — Эйнштейн автоматизированная система первой линии поддержки, иными словами — чат-бот.
А почему не взять готовое решение? Ведь все мы знаем, что каждый день на Хабре выходит статья, как написать бота в Телеграм или ВК. Под которой также, уже традиционно, тратят нервные клетки и свои минусы читатели. К сожалению, готовые решения нам не подошли. В основном все проприетарные решения берут деньги за каждый решенный чат, что особенно невыгодно в условиях быстрого роста. Это дорого. Часть готовых решений подразумевает переход на новую систему. Это долго. Наши чаты ведутся на восьми языках: пяти основных и трех дополнительных. Подружить готовые решения с хинди или урду — та еще история. Это сложно.
Это главные причины. Еще можно отметить, что мы разрабатываем экосистему финансовых продуктов на международных рынках. Многие из этих продуктов уникальны и обладают своей терминологией. Это накладывает ограничения, в том числе на возможность использования готовых сценариев, публичных моделей и открытых датасетов. Это специфично.
Так мы пришли к решению создать собственного чат-бота с блэкджеком и NLP.
Conversation design
При разработке диалоговых систем обычно начинают с составления свода правил, идей, гипотез. На их основе задается вектор разработки и развития диалоговой системы, в том числе чат-бота. Как он должен общаться? На какие вопросы отвечать? Насколько формально? Как обращаться к клиенту? Обычно такой набор договоренностей называют «Conversation design». Похожие правила есть и у реальных агентов поддержки, для ботов они более формализованы.
- Бот явно отличается от живых агентов
Наш бот должен явно отличаться от живых агентов и отвечать только формально. Да, некоторые компании наоборот создают ботов, маскирующихся под людей неформальной манерой общения — и это иногда работает. Мы решили, что такой путь не для нас.
- Бот отвечает только формально
- Боту лучше не давать консультации, чем отвечать клиенту неправильно
- Чат при участии бота не удлиняется по времени
Чат не должен удлиняться по времени. Это вместе с предыдущим пунктом закрывает нам путь к попыткам вывода клиента на «допрос», если мы не поняли вопрос.
- Клиент всегда может попасть к агенту без препятствий
Если клиенту принципиально нужен человек или он не хочет говорить с ботом.

- Агенты решают сложные кейсы, где реально нужен человек
Рутина — боту, сложные случаи — человеку.
- Вместо автоматизации чатов по багам лучше решать сам баг
Очень важно решать баги, иначе вся система поддержки выльется в то, что мы затыкаем дыры, которые когда-нибудь рванут.
- Одновременно решается только одна проблема клиента
В первую очередь для упрощения диалоговой системы и автоматизации.
- Улучшается клиентский опыт
Ну а куда без этого :)
Для всех этих пунктов есть соображения, почему именно так, а не иначе. Не буду в статье вдаваться в подробности, но готов с удовольствием обсудить их в комментариях, если у кого-то есть идеи по этому поводу.
Тест-драйв: как MVP поменял наш флоу

Первый шаг по проектированию автоматизированной поддержки был сделан. Далее нам предстояло понять, как мы можем спрогнозировать рост нагрузки и полезен ли нам бот для её снижения. В нашем случае было понятно, что нагрузка будет расти, причем довольно быстро. Этот прогноз оправдался. Но нам очень хотелось спрогнозировать то, как ее можно снижать. Команда была скептично настроена, а некоторые даже считали, что клиенты могут плохо воспринять бота и автоматизация закончится быстрее, чем начнется. Поэтому мы сделали простой MVP бота без ML-моделей и всяких усложнений, чтобы:
автоматизировать рутинные операции агента;
проверить гипотезу о возможности автоматизации чатов;
оценить эффективность автоматизации чатов.
Какая схема была раньше:
Клиент: инициирует чат
Агент: уточняет язык
Агент: передает другому агенту?
Агент: уточняет проблему
Клиент и Агент: ведут диалог
Нет вопросов? Закрываем
Или клиент закрывает
Или клиент не отвечает
В 1—4 пунктах до решения проблемы агент тратит время на «подготовку» чата. В 6—8 пунктах агент ждет, и его слот для другого чата занят. Агент в этой схеме реально нужен, когда он ведет диалог (пункт 5). Все остальное желательно автоматизировать.
Как стало:
Клиент: инициирует чат
Бот: привет, проблема, язык
Бот: переводит чат на агента
Клиент и Агент: ведут диалог
Агент: выходит из чата
Бот: ожидает еще вопросов
Бот: Еще вопросы?
Клиент по-прежнему инициирует чат, но агент вступает только при необходимости. У каждого агента есть лимиты на одновременное количество чатов. Один чат занимает один слот. Бот проводит подготовку («preset» чата), освобождая слот агента, и это время агент тратит на более полезные дела. Также агент моментально выходит из чата, и если потом клиент начнет что-то уточнять, бот вернет его обратно агенту. Это MVP снижает бесполезную нагрузку на агента.
Но самое замечательное не это. Некоторые пользователи приходят в чат без вопроса.
Кто-то хочет проверить, жив ли продукт, а кто-то — просто из праздного любопытства. В нашем случае таких клиентов было от 5 до 8 процентов. Поэтому, даже не отвечая на вопросы, мы уже автоматизировали эти 5—8 процентов.

Клиенты на ура восприняли бота. Дальше было необходимо выделить направления для автоматизации сценариев, чтобы быстрее снижать нагрузку, давать клиентам ответы, разгружать агентов. В этот момент появляется задача о прогнозировании снижения нагрузки. Но как её решать, если данных по автоматизации нет?
Статистика знает все: прогнозирование снижения нагрузки
С помощью модификации схемы обработки чатов и автоматизации рутинных процессов мы закрыли около 5% чатов. Но как быть с чатами, где есть конкретный вопрос, конкретная тема или даже несколько? Прогноз снижения нагрузки зависит от приоритизации тем. Что будем автоматизировать в первую очередь? Сначала удобнее выделить самые простые темы, которые закрываются одним сообщением и не вызывают у клиентов двоякого восприятия. Также можно выделить самые проблемные темы по сложности или самые объемные темы по количеству чатов.
Чтобы ответить на эти вопросы, нужно, конечно, в первую очередь смотреть на данные. На исторические данные, которые у нас были, где агенты общались с клиентами без участия бота. Выделили критерии, по которым можно приоритизировать темы: разбивка по языкам, структура чата, индекс удовлетворенности, статистика по целевым бизнес-действиям, сколько было сообщений до и после определенной консультации агента.
Но не все так просто: напомню, согласно Conversation design, бот решает одновременно только один вопрос в один момент времени. Но это упрощение: часто бывает, что клиент задал последовательно несколько вопросов, и если бот ответит лишь на два из трех, то чат попадет агенту. Да, ему не нужно будет отвечать на уже закрытые ботом вопросы, но чат в таком случае все равно не считается автоматизированным. Допустим, у нас есть три темы и мы можем автоматизировать их в разном порядке.

Видно, что в конечном итоге будет автоматизировано одинаковое количество чатов. Но, как правило, мы ограничены в ресурсах и времени. Обычно нам нужна не 100% автоматизация, а достаточно какой-то доли за приемлемый промежуток времени. Основная концепция первой линии поддержки — автоматизировать темы, на которые можно не тратить человеческий ресурс. Задействовать человеческий ресурс на чаты, где действительно нужен человек.
Посмотрим, как этот график выглядит в реальности для 250 тем.

Закрытые темы в совокупности друг с другом могут давать больше закрытых чатов, чем по отдельности. Соответственно, не всегда нужно автоматизировать самые объемные темы, поскольку комбинация менее объемных может привести к большему увеличению закрытых чатов. Тут появляется многокритериальная задача оптимизации, которую решить не так просто.
Допустим, если у нас 5000 тем, мы получим 5000! возможностей автоматизировать чаты — слишком много вариантов, и не совсем понятно, по какому из них идти. Все 5000 тем автоматизировать ни у кого не получится, тем более, постоянно появляются новые темы, а другие пропадают. Какие-то темы исключительно уникальны, какие-то периодичны. Поэтому логичнее зафиксировать цель (например, 30%) и выяснить, как оптимально к ней можно прийти, потратив минимальные усилия.
Аналитически получить точное решение этой задачи сложно. Такую задачу помогут решить стохастические методы оптимизации. В простом случае можно воспользоваться методом Монте-Карло. Суть решения следующая. Мы моделируем разные варианты последовательностей тем для автоматизации. Но моделируем не 5000! вариаций, а меньшее число случайным образом, и получаем примерный оптимум и картину, приближенную к реальности. Можно увеличивать точность, вводя ограничения или используя более продвинутыми методы, например, использовать генетические алгоритмы.
Если у нас есть цель автоматизировать половину чатов, мы смотрим, по какому пути мы автоматизируем эту половину быстрее. Тут стоит заметить, что если бы мы шли по пути наипростейших или наибольших тем, мы могли бы получить далеко не самый оптимальный вариант.

Для решения этой задачи можно вводить различные ограничения и веса. Например, разные темы автоматизируются с разной сложностью: какая-то один спринт, какая-то два. Разные темы закрываются по-разному: где-то клиент удовлетворится ответом, а где-то нет. Можно также учесть различные характеристики чатов. Мне кажется, эта обширная тема достойна отдельной статьи, которая применима не только для автоматизации чатов.
Разработка: еще не ML, но уже YAML
Бот получает сообщение, после пробует на него ответить или провести чат дальше по флоу. Для того чтобы ответить на сообщение, бот обращается в другой сервис, который решает задачу классификации сообщения клиента. Так, в сильно упрощенном виде, выглядит автоматизация тем. В реальности все, конечно, сложнее: есть диалоги с ветвлением, диалоги с условиями, контекст клиента. Технически все обвязано метриками, алертами, аналитикой и взаимодействиями с другими сервисами. Но это не сильно влияет на суть этой статьи.
Когда мы начали автоматизировать темы, поняли, что лучше сценарии конфигурировать, чтобы не писать код для каждой темы или сценария. Для этого мы составили YAML-конфигурацию. Спроектировали её таким образом, чтобы можно было легко расширять и менять в зависимости от темы.
...
restore_password:
- action: answer
when: verified_user && !user_blocked
text:
web: ~msg_restore_password
tags:
- ba_restore_password
alternatives:
web: ~msg_restore_password_alt
- action: answer
when: cabinet_locked_by_password
text:
web: ~msg_blocked_by_password
tags:
- ba_blocked_by_password
alternatives:
web: ~msg_blocked_by_password_alt
invite_agent:
- action: transfer
unsubscribe_email:
- action: answer
text:
web: ~msg_unsubscribe_email_web
app: ~msg_unsubscribe_email_app
ios_app: ~msg_unsubscribe_email_ios
tags:
- ba_unsubscribe_email
alternatives:
web: ~msg_unsubscribe_email_web_alt
app: ~msg_unsubscribe_email_app_alt
ios_app: ~msg_unsubscribe_email_ios_alt
...
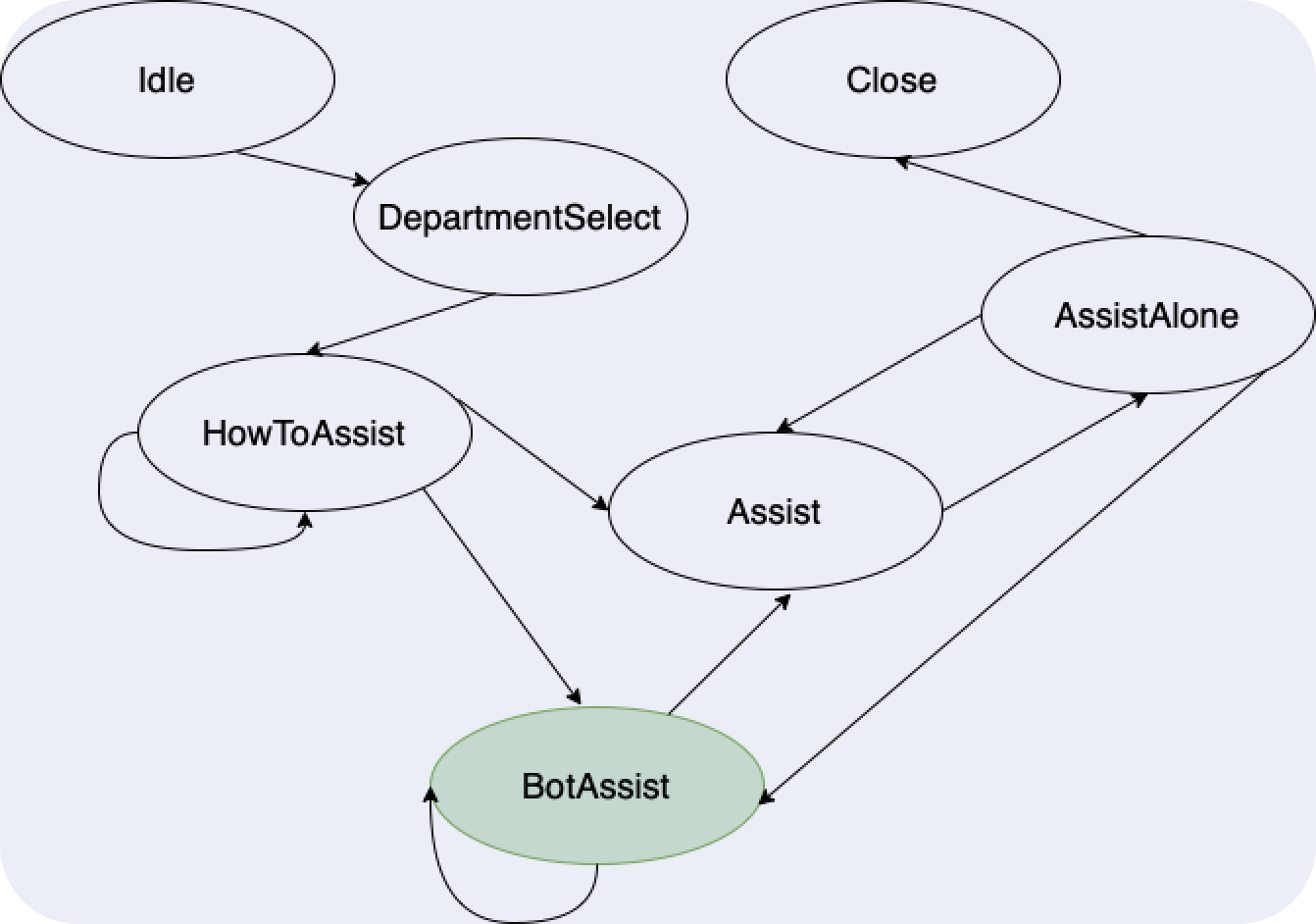
Такая конфигурация описывает конечный автомат. Ниже на картинке нарисованы основные состояния, которые были введены для встраивания бота в чаты. Состояния и переходы можно моделировать с помощью цепей Маркова. Каждый чат движется по такой цепи из состояния Idle к состоянию Close. Фактически вся автоматизация с ответами по конкретным темам происходит в состоянии BotAssist. Это состояние является еще одним конечным автоматом, который динамически генерируется на основании YAML-конфигурации.
Гамарджоба, do you have таблетки от кашля?
Расскажу подробнее о сложностях определения темы сообщения и о специфике, с которой мы работаем. Первое — это мультиязычность. Казалось бы, что все уже пишут на английском и французском. Но нет. Наши продукты представлены в юго-восточной Азии, и там есть языки, непохожие на европейские, – китайский, урду, хинди, малайский и др. А английский, на котором пишут в этих регионах, сильно отличается от британского и американского. Некоторые из языков транслитерируются, а другие – нет, и это уже сложнее. Единого подхода не существует, но перед тем, как обучать какую-то модель, нужно транслитерировать либо лингвистической схемой сопоставления, либо через модели машинной транслитерации.
Помимо того что клиенты пишут на тяжело воспринимаемых нами языках, они используют много сокращений — с таким объемом я не сталкивался, когда работал с диалоговыми системами на русском и английском. Например,
Salamat malam kek! Saya punya pertanyaan bagaimana memulihkan kata sandi? ->mlm kk saya pertayan bagama memulihkan pass?
Часто используют комбинации языков:
Salamat malam kek! Saya punya pertanyaan bagaimana memulihkan kata sandi? -> good morning kk i want bagama memulihkan pass?
Все эти культурные особенности нужно учитывать при разработке, при автоматизации чатов. Нашим решением стало построение пайплайна для каждого языка отдельно: в зависимости от необходимости убирать ненужное, транслитерировать, исправлять ошибки, дополнять гласными, сокращать размерности и т.д.. То есть, строить диалоговую систему для урду так, как мы делали это на английском языке, не получилось бы. Обычно пайплайн выглядит примерно так
predict_pipeline = make_pipeline(
...,
transform_to_lower,
predict_contains_ignore_words,
transform_numbers_to_one,
transform_punctuation_clean,
transform_devanagari_to_latin,
transform_remove_duplicate_letters,
transform_fix_mistakes,
transform_remove_double_spaces,
predict_by_hi_en_variants,
predict_by_hi_en_model,
...,
)Помимо языковых особенностей есть и культурные. Даже хорошо понимая, о чем пишет клиент, не всегда получается угадать, что он имеет в виду. Ниже примеры реальных случаев.
Agent: I was able to solve your issue?
Client: yes no
Еще смешных историй
Agent: Hello, what language will you speak?
Client: English
Agent: Ok, elaborate your question please
Client: Lupa sandi, kak. Tolong bantu aku
Agent: I will transfer to Indonesian agent
Client: No, I will speak in english!!! Lalu bagaimana dengan permintaanku?
Agent: Please, follow the link
Client: Can you follow the link for me?
Client: hi
Client: thank you good bye
Bot: Please choose option:
1. Restore password
2. Restore secret word
3. Restore pin-code
Client: 1
Client: First point
Client: pwd of course
Нейро-ML

Как говорилось ранее, изначально размеченных данных у нас не было. Ждать разметки мы не могли: нужно было снижать нагрузку и давать результаты.
В первую очередь, можно выделить популярные выражения, ведь некоторые вопросы формулируются очень похоже, а другие – наоборот, очень по-разному, причем, это не зависит от сложности вопроса. Вариативность фраз о забытом пароле составляет примерно 3–4 процента. А сообщение о поломке мобильного приложения может быть настолько вариативным, что работать без размеченных данных не получится вовсе. Для оценки вариативности внутри темы можно использовать коэффициент энтропии. На графике ниже видно, что некоторые темы формулируются разнообразно, а некоторые очень схоже.

Также эффективным приемом в NLP, как и в других областях, является сокращение размерности. Как думаете, сколько есть вариантов написать «спасибо»? 1? 2? 10? Я видел как минимум тысячи различных паттернов.
Некоторые варианты спасибо
[..., 'tqy', 'lthanks', 'nothanks', 'nthanks', 'okthank', 'okthanx', 'thank','thanx', 'thanka', 'thankbyou', 'thankc', 'thankd', 'thankful', 'thonck', 'thankgod', 'thanki', 'thanking', 'thankiu', 'thankjs', 'thankk', 'thankks', 'tank', 'muchas gracias', 'thnk', 'thans', 'thankkyou', 'thankls', 'thankn', sanknyou', 'thanko', 'thankou', 'thankoyy', 'thankq', 'thanks', 'thanksn', 'thanksp', 'thankss', 'thanksyou', 'thankt', 'thanku', 'thankuu', 'thankx', 'thanky', 'thku', 'thankyu', 'thankyo', 'thankyou', 'thankyouu', 'thankyoy', 'thankyu', 'thankz', 'tthank', 'tthanks', 'tq', 'taky', 'tanx', 'tkyou', 'tanku', 'thankas', 'tanku', 'thanktq', 'thansk', 'thankq', 'thansk' …]
Сокращать размерность можно лингвистическими приемами, выделяя морфемы, синонимы, похожие слова. Можно сводить слова и фразы одни к другим по смыслу или с помощью расстояний для исключения ошибок и опечаток. А можно численными методами, такими как SVD, если у вас есть качественные эмбеддинги. В любом случае это полезно для точности моделей и для скорости их обучения. При сокращении размерности нужно помнить о культурных особенностях: очень важно не потерять слова, которые сокращаются до 1-2 букв.
В первую очередь мы исчерпали маловариативные тематики и привели набор данных к минимальному виду. После уже начали размечать данные за счет эвристик, регулярных выражений, перепрогона по линейным моделям и, конечно же, вручную. Сначала использовали переобучение: у нас был суперкласс, из которого мы выделяли маленькие темы, и в этот момент нас не беспокоила ошибка второго рода.
Далее следовало обучение на частично размеченных данных. Использовали только линейные тяжелые модели, которые легко контролировать в эксплуатации и интерпретировать результаты. Для непопулярных языков очень важно пользоваться замыкающими моделями, например, моделями из топ-6 языков ООН в зависимости от региона. Во многих странах, помимо национальных языков, используют языки «глобальные».
Пока у нас были частично размеченные данные, мы дошли до третьего пункта нашей эволюционной цепи: полное сравнение, сравнение по вхождению, переобученные линейные модели.

Как только у нас появились размеченные данные, мы перешли на четвертый этап. Количество чатов еще больше возросло, но к этому времени довольно много было автоматизировано. После использования размеченных данных точность уже существующих моделей возросла почти в два раза. Точнее, возрос recall, precision остался примерно на том же уровне.
Что же дальше делать, если точность стремится к 99.999..., оставлять все так? Нет, нужно идти дальше. Например, использовать контекст пользователя:
откуда пришел клиент;
что он до этого делал с продуктом;
информация по прошлым обращениям;
информация, напрямую связанная с темами;
...

Метрики

Какие метрики мы используем? В плане мониторинга — это все стандартное по нагрузке. Еще мониторим контекст пользователей, которые к нам пришли. Мониторим разбиение чатов по всевозможным параметрам: локаль, язык, оператор сотовой сети, устройство, локация, сегмент и др. Если метрики быстро меняются, вероятнее всего, что-то сломалось и нужно не сокращать чаты, а идти смотреть проблему. Конечно, мониторим нагрузку на агентов. По точности моделей тоже ничего особенного — это f1, precision-recall, accuracy и взвешенный accuracy.
Бизнес-метрики. Тут интереснее. Основные метрики — это доля распознанных чатов, c консультацией бота, закрытых чатов.

Удобно также сравнивать бота с производительностью абстрактных кластеров агентов.

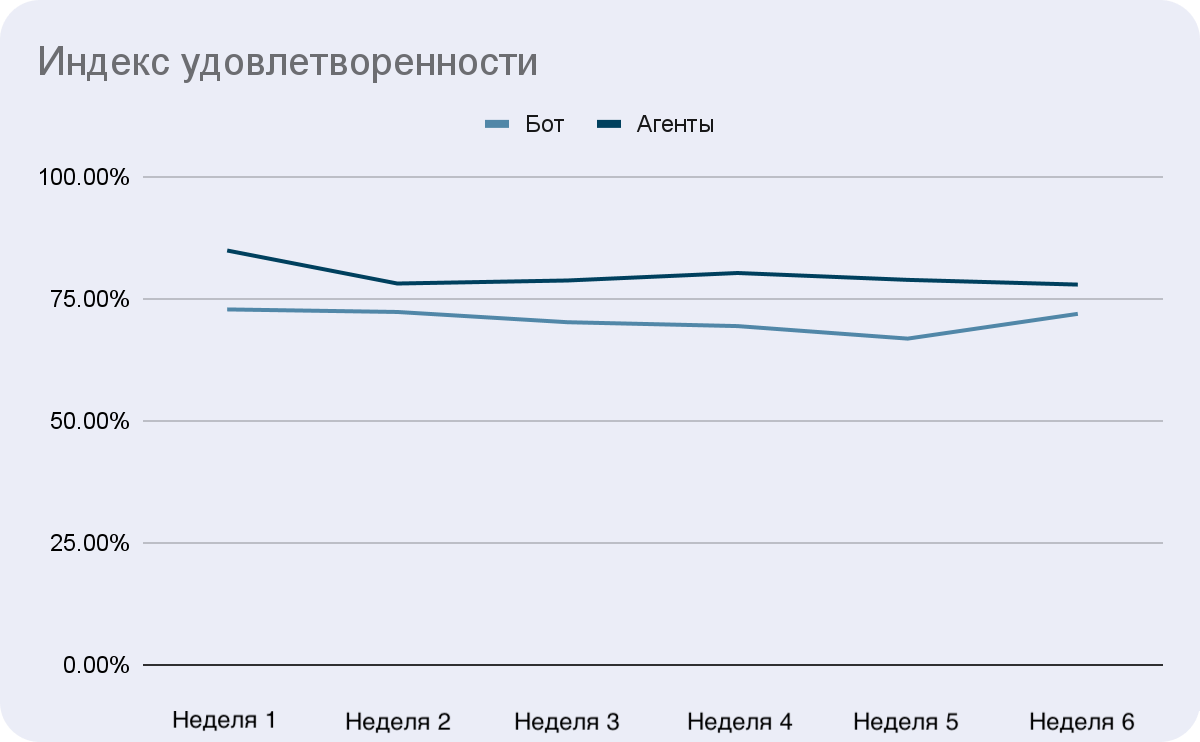
Все метрики для лучшего понимания важно контролировать не только в общей сумме, но и по темам, языкам и времени отдельно.
Из самых полезных могу еще выделить ожидание в очереди, долю ключевых действий, количество пропущенных чатов, эффективность коммуникации.
Как чат-бот изменил клиентский сервис и что будет дальше
У нас получилась полноценная поддержка пяти языков + частично еще трёх. До разметки данных автоматизация за счет внедрения бота и автоматизации первых тем составила 10—15 процентов. Благодаря автоматизированной поддержке удалось снизить нагрузку агентов в среднем с 7 до 4 одновременных чатов. Это большая доля всех чатов, и она равна эффективности работы нескольких десятков агентов. Такое сравнение упрощено: понятно, что бот не решает сложные кейсы как агенты.
Разметка данных позволила повысить автоматизацию еще на 10 процентов на старых моделях и открыла возможность миграции с линейных на нелинейные модели. То есть, на момент написания статьи автоматизировано чуть менее четверти чатов. И это при довольно строгом Conversation design. При более навязчивой автоматизации можно было бы получить 30—40 процентов автоматизированных чатов, что чуть меньше количества чатов, с которыми идет взаимодействие по теме вопроса клиента. При описанном подходе доля автоматизированных чатов продолжает расти за счет наращивания количества автоматизированных тем по разметке, использования контекста, улучшения копирайтинга.
В такой обширной теме сложно охватить все сразу, поэтому постарался выделить самое интересное. Каждый раздел интересно раскрыть подробнее, с техническими деталями. А на сегодня, как сказали в одном чате, всем пока ...

