Сейчас перед программистами стоит сложная задача - как внедрить такую громоздкую структуру, как нейронная сеть - в, допустим, браслет? Как оптимизировать энергопотребление модели? Какова цена таких оптимизации, а также насколько обосновано внедрение моделей в небольшие устройства, и почему без этого нельзя обойтись.

А в чем польза?
Представим дорогой промышленный сенсор - 1000 измерений в секунду, температурный датчик, измерение вибраций, передача данных на 10 км, мощный процессор - 20 млн операций в секунду! Его работа это посылать на сервер данные о температуре, вибрации, а также значения других параметров для предупреждения поломокоборудования. Но вот незадача - 99% посылаемых им данных бесполезна, от неё - чистый убыток за электричество. А таких датчиков на производстве могут быть десятки и сотни.
В действительности нас интересуют не сами данные с этого устройства, а инсайды из них - всё ли работает в штатном режиме? Нет ли аварийных ситуаций? Быть может, вскоре потребуется ремонт? Так почему бы не задеплоить нейронку на сам датчик, и вместо бесконечного потока данных лишь иногда посылать сигналы "Всё в порядке" или "Аномалии в показателях!" Вот именно этим вопросом и занимается TinyML.

Всё крутится вокруг того, как бы нам максимально ужать модель, чтобы она влезла в небольшое устройство. В качестве "устройства" сойдет всё: чайник, промышленный сенсор, утюг, телефон, браслет и т.д.
 AI работает на самом устройстве")
Преимущества подхода
Во-первых - экономия ресурсов. Так как постоянной связи с сервером не требуется, это весомо экономит электроэнергию, ведь можно обойтись без постоянного подключения к WiFi, Bluetooth и так далее.
Во-вторых - быстрая скорость работы. Перекачивать данные на сервер - слишком долго, когда нужен результат "здесь и немедленно".
В-третьих - это экономия на облачных вычислениях. В облачном подходе данные требуется отослать на сервер не только для обучения модели, но и для предикта. Представьте, что для приложения замены лица на вашем телефоне будет постоянно требоваться связь с интернетом, как в случае с навигатором... Весьма неудобно и затратно. Собственно, поэтому такие технологии уже встроены в наш телефон (а это - работа TinyML).
В-четвертых - безопасность. Посылать данные куда-то всегда связано с риском, гораздо безопаснее получать результат уже на устройстве, а с устройства посылать только предикт.
В-пятых - скорость работы самих нейронных сетей становится быстрее, ибо работа с int внутри нейронки идёт быстрее, чем с float - об этом расскажу ниже.
Quantization
А помочь засунуть жирную нейронку в худенький датчик поможет такой трюк, как Квантизация. Суть метода проста - а давайте сократим место, занимаемое числами в памяти. Обычные нейронки используют такой тип данных, как толстый 32 битный флоат. Что будет, если мы заменим их на худые 8 битные инты? Места занимать они станут меньше, но и качество упадёт.

Недостижимая мечта - использовать 1 бит. Тогда мы получим гигантский выигрыш в размере. Жаль, что это невозможно.
Или возможно? Бинаризированные свёрточные нейронные сети к вашим услугам. Почитать о них подробнее можно здесь.

От теории к практике
А теперь, дабы было задорнее, немного кода. Сделаем простейшую модель, предсказывающую синус числа.
# Генерируем данные для нашей нейронки
x_values = np.random.uniform(
low=0, high=2*math.pi, size=1000).astype(np.float32)
# Перемешиваем
np.random.shuffle(x_values)
y_values = np.sin(x_values).astype(np.float32)
# Добавляем шум, чтобы было "как в реальной жизни"
y_values += 0.1 * np.random.randn(*y_values.shape)
plt.plot(x_values, y_values, 'b.')
plt.show()
Данные готовы. Теперь делим их на тренировочную, тестовую и валидационную выборку (эту и некоторые другие части кода я пропущу для экономии вашего времени, полный ноутбук с кодом вот тут).

Время строить нашу нейронку!
# Создаём нейронную сеть
model = tf.keras.Sequential()
model.add(keras.layers.Dense(16, activation='relu', input_shape=(1,)))
model.add(keras.layers.Dense(16, activation='relu'))
model.add(keras.layers.Dense(1))
model.compile(optimizer='adam', loss="mse", metrics=["mae"])
# Тренируем модельку
history = model.fit(x_train, y_train, epochs=500, batch_size=64,
validation_data=(x_validate, y_validate))
# Сохраняем
model.save(MODEL_TF)Теперь давайте посмотрим, что получилось:

Итак, основная модель готова. Настало время "посжимать" её самыми разными способами. А поможет в этом нам TFLiteConverter, созданный специально для облегчения ваших нейронок.
# Конвертируем нашу нейронку в формат TensorFlow Lite БЕЗ квантизации
converter = tf.lite.TFLiteConverter.from_saved_model(MODEL_TF)
model_no_quant_tflite = converter.convert()
# Сохраняем
open(MODEL_NO_QUANT_TFLITE, "wb").write(model_no_quant_tflite)
# Конвертируем нашу нейронку в формат TensorFlow Lite ИСПОЛЬЗУЯ квантизацию
def representative_dataset():
for i in range(500):
yield([x_train[i].reshape(1, 1)])
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# Задаем параметры, по котором в нейронке всё будет конвертировано в int
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
# Задаем репрезентативный набор данных, чтобы обеспечить правильность квантизации
converter.representative_dataset = representative_dataset
model_tflite = converter.convert()
open(MODEL_TFLITE, "wb").write(model_tflite)Итого имеем три нейронные сети: обычную, конвертированную TensorFlow Lite без квантизации, конвертированную TensorFlow Lite с квантизацей. Самое время сравнить, сколько же места они занимают.
pd.DataFrame.from_records(
[["TensorFlow", f"{size_tf} bytes", ""],
["TensorFlow Lite", f"{size_no_quant_tflite} bytes ", f"(reduced by {size_tf - size_no_quant_tflite} bytes)"],
["TensorFlow Lite Quantized", f"{size_tflite} bytes", f"(reduced by {size_no_quant_tflite - size_tflite} bytes)"]],
columns = ["Model", "Size", ""], index="Model")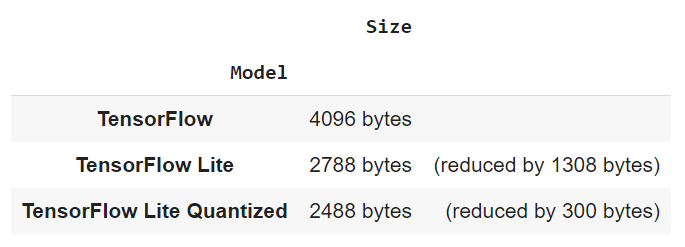
Итак, по сравнению с первоначальной нейронкой, конвертация с помощью TensorFlow Lite даёт 32% выигрыша в размере, а квантизация целых 40% ! Весьма впечатляющий результат, однако, какой ценой мы его достигли?
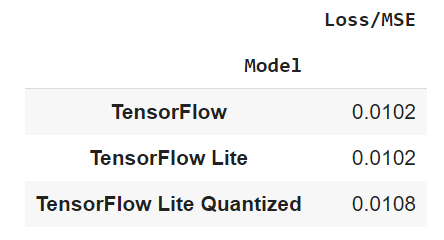
Потеря качества почти не существенна, на уровне погрешности. Но стоит иметь ввиду, что мы используем весьма простую модельку для теста, на более крупных моделях результат может быть не настолько оптимистичным!
Конвертация в С код
Все предыдущие действия мы делали на Python в ноутбуке, но ведь нас интересует, как задеплоить модель в микроконтроллер, правильно? А для этого требуется сконвертировать полученную модель в код, с которым эти сами микроконтроллеры привыкли работать. ВАЖНО! Приведенный ниже код я запускал на Ubuntu, если хотите подобное сделать на Windows - придётся искать обходные пути.
# Ставим xxd
!apt-get update && apt-get -qq install xxd
# А теперь конвертируем
!xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}
# Меняем имя переменных
REPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')
!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}
# Давайте глянем, что из себя представляет сконвертированная в C код модель
!cat {MODEL_TFLITE_MICRO}
Я вставил лишь первые несколько строк сконвертированной модели, однако вообще их около 400.
Код на микроконтроллере
Модель у нас есть, а теперь посмотрим, как будет выглядеть наш С код на, собственно, микроконтроллере. Перед деплоем на микроконтроллер код можно (и нужно) сперва запустить на компьютере. Сразу скажу, что я выцепил только самые интересные куски кода, однако если вы хотите запустить его на своем компе - то вот.
// Определяем входное значение, а также ожидаемое выходное
float x = 0.0f;
float y_true = sin(x);
// Логирование
tflite::MicroErrorReporter micro_error_reporter;
// Подтягиваем ранее сохранённую модельку
const tflite::Model* model = ::tflite::GetModel(g_model);Далее выделяем место на нашем устройстве. Сколько его взять? На самом деле, вопрос решается в лоб: берем некое рандомное, разумное число. Если модель вмещается и всё работает- хорошо, пробуем сократить место. Продолжать сей процесс, пока система не перестанет работать.
Ну и наконец, вот так выглядит предсказание синуса на микроконтроллере:
x = 5.f;
y_true = sin(x);
input->data.int8[0] = x / input_scale + input_zero_point;
interpreter.Invoke();
y_pred = (output->data.int8[0] - output_zero_point) * output_scale;
TF_LITE_MICRO_EXPECT_NEAR(y_true, y_pred, epsilon);Edge Impulse
Отдельно стоит упомянуть платформу Edge Impulse от ребят, плотно занимающихся TinyML.

Она берет на себя много работы по деплою моделей непосредственно на микроконтроллеры, достаточно всего лишь подключить какую нибудь ардуинку к компьютеру, и в пару кликов накатить на неё модельку. Сам не пользовался, и не думаю, что что нибудь очень серьезное на её базе сделать получится, однако желающим немного поиграться - точно сюда.
Ну и вместо заключения - тема с TinyML набирает обороты. В некоторых сферах (браслеты отслеживания состояния людей с больным сердцем, обнаружение рака языка встроенной нейронной сетью через фотографию и т.д.) у неё просто нет альтернатив. Рост количества подобных устройств прогнозируется на уровне 20% в год, а значит, об этой технологии мы будем слышать всё чаще и чаще.
Если хотите знать больше по теме, то присоединяйтесь к нашему NoML Community - https://t.me/noml_community.
Список источников
Ноутбук для создания модели https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb#scrollTo=l4-WhtGpvb-E
Код на С для деплоя модели https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/hello_world_test.cc
Бинаризированные свёрточные нейронные сети https://arxiv.org/abs/1602.02830
Сайт комьюнити TinyML https://www.tinyml.org/
Специализированный ютуб канал (здесь и обзорные видео, и применение технологии в промышленности) https://www.youtube.com/channel/UC9iWqvsWjhowkHWVJquHwkg
Платформа для разработки Edge Impulse https://www.edgeimpulse.com/
Книга, полностью посвященная TinyML https://www.amazon.com/_/dp/1492052043?tag=oreilly20-20
