Apache Cassandra — это одна из популярных распределенных дисковых NoSQL баз данных с открытым исходным кодом. Она применяется в ключевых частях инфраструктуры такими гигантами как Netflix, eBay, Expedia, и снискала популярность за свою скорость, способность линейно масштабироваться на тысячи узлов и “best-in-class” репликацию между различными центрами обработки данных.
Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.

Для начала хочу кратко пройтись по основным ограничениям Cassandra, с которыми будем работать:
Можно поспорить, что я хочу использовать Cassandra не по назначению, и я полностью соглашусь. Моя цель — показать, что если решить эти проблемы, “назначение” Cassandra можно значительно расширить. Совмещая человека и лошадь, получаем всадника, который может уже совсем иной перечень вещей, нежели человек и лошадь по-отдельности.
Как же можно обойти эти ограничения?
Я бы сказал, что классическим вариантом является фрагментация данных, когда часть лежит в Cassandra, а часть — в других системах, которые поддерживают необходимые гарантии.
Минусы этого подхода, которые видны навскидку: увеличение сложности (а значит, потенциально, и ухудшение скорости и качества) разработки и поддержки приложений. Намного проще стучаться в одни ворота, нежели на уровне приложения или слоя микросервисов совмещать разрозненную информацию из различных источников. Также деградация любой из двух систем может приводить к значительным негативным последствиям, вынуждая инфраструктрную команду гнаться сразу за двумя зайцами.
Ещё один способ — поставить другую систему поверх Cassandra, разделив ответственность между ними. Я считаю, что Apache Ignite — идеальный кандидат для этой схемы:
В такой схеме Apache Ignite встает поверх Apache Cassandra, которая играет роль слоя постоянного энергонезависимого хранения. Несмотря на то, что уже в ближайших версиях Apache Ignite появится свое собственное решение Persistence с поддержкой расширения памяти диском, lazy run и сквозным SQL, Cassandra всё равно может быть интересна в этой роли за счет своей вылизанности за долгие годы развития, распространенности и возможности разделить ответственность, не складывая все яйца в одну корзину там, где это не нужно.
Кластер Apache Ignite вбирает в себя из Apache Cassandra все или часть данных (например, за исключением архивных), по которым нужно выполнять запросы, после чего работает в режиме write-through, самостоятельно обслуживая API- или SQL-запросы на чтение, и дублируя в синхронном или асинхронном режиме запросы на запись в Cassandra, надежно сохраняя их на диск.
Далее эти данные анализируются в реальном времени, могут использоваться средства визуализации наподобие Tableau, применяться распределенные алгоритмы машинного обучения, а также формироваться витрины.
Далее я приведу пример простой «синтетической» интеграции Apache Cassandra и Apache Ignite, чтобы показать, как это работает и что это совсем не сложно, пусть и требует определенной доли boilerplate-кода.
Для начала я создам необходимые таблицы в Cassandra и заполню их данными, затем инициализирую Java-проект и напишу DTO-классы, после чего покажу основную часть — конфигурирование Apache Ignite для работы с Cassandra.
Я буду использовать Mac OS Sierra, Cassandra 3.10 и Apache Ignite 2.0. В Linux команды должны быть аналогичны.
Для начала загрузим дистрибутив Cassandra в директорию ~/Downloads, пройдя по ссылке, либо используя curl/wget.
Далее зайдем в директорию и распакуем его:
Запустим Cassandra с настройками по умолчанию, для тестирования этого будет достаточно.
Далее запустим интерактивный шелл Cassandra и создадим тестовые структуры данных (выберем обычный суррогатный id как ключ — для таблиц в Cassandra зачастую имеет смысл выбирать ключи, более осмысленные с точки зрения последующего извлечения данных, но мы упростим пример):
Проверим, что все данные записались корректно:
Есть 2 способа работы с Ignite: можно скачать дистрибутив с сайта ignite.apache.org, подложить ему необходимые Jar-файлы с собственными классами и XML с конфигурацией, либо использовать Ignite как зависимость в Java-проекте. В этой статье я рассмотрю второй вариант.
Создадим новый проект — я буду использовать maven как классический и понятный максимально широкой, на мой взгляд, аудитории инструмент.
В зависимости пропишем:
Транзитивно будет также загружен ignite-core, который содержит основные классы Apache Ignite.
Далее необходимо создать DTO-классы, которые будут представлять таблицы Cassandra в мире Java:
Мы помечаем аннотацией @QuerySqlField те поля, которые будут участвовать в SQL-запросах. Если поле не помечено данной аннотацией, его невозможно будет извлечь его посредством SQL или фильтровать по нему.
Также можно сделать более тонкие настройки для определения индексов и полнотекстовых индексов, которые выходят за рамки данного примера. Подробнее о настройке SQL в Apache Ignite можно прочитать в соответствующем разделе документации.
Создадим в src/main/resources нашу конфигурацию в файле apacheignite-cassandra.xml (название выбрано произвольно). Я приведу полную конфигурацию, которая достаточно объемна, после чего рассмотрю ее по частям:
Формат конфигурации — Spring Beans.
Конфигурацию можно поделить на два раздела: определение DataSource для установки связи с Cassandra и определение настроек Apache Ignite, которые сводятся в данном примере к указанию рабочих кешей, полностью соответствующих таблицам в Cassandra.
Первая часть конфигурации лаконична:
Мы определяем источник данных Cassandra, указываем адреса, по которым можно попытаться установить соединение.
Далее задается конфигурация Apache Ignite. В рамках этого теста будет минимальное отклонение от настроек по-умолчанию, поэтому переопределяем только свойство
Первый кеш — представляющий таблицу catalog_category:
В нем включаем режим сквозных чтения и записи (если будем что-то писать в кеш, операция записи будет автоматически дублироваться в Cassandra), указываем, что в SQL будет использоваться схема catalog_category, а также перечисляем типы, которые будут храниться в этом кеше и должны быть обработаны для обращения к ним через SQL. Типы указываются всегда парами ключ-значение, поэтому количество элементов списка всегда должно быть четным.
Наконец, зададим связь с Cassandra, здесь будет два основных подраздела. Во-первых, укажем ссылку на созданный ранее DataSource: cassandra. Во-вторых, нам нужно будет указать, как соотносить между собой таблицы Cassandra и записи «ключ-значение» Ignite. Это будет делаться через свойство
Конфигурация меппинга выглядит достаточно интутивно понятно:
На верхнем уровне (тег
Подробнее о более тонких настройках меппинга, которые выходят за рамки данного примера, можно прочитать в соответствующем разделе документации.
Конфигурация второго кеша, содержащего данные о товарах аналогична.
Для запуска создадим класс
Здесь мы используем инструкцию
Для выполнения SQL-запросов можно использовать любой клиент, который поддерживает JDBC, например, встроенный в IntelliJ IDEA, либо SquirrelSQL. В последнем случае, например, нужно будет добавить драйвер Apache Ignite (который находится в Jar-файле ignite-core, его можно скачать в составе дистрибутива):

Создадим новое соединение по URL вида jdbc:ignite://localhost/CatalogGood, где localhost — адрес одного из узлов Apache Ignite, а CatalogGood — кеш, к которому будут идти по умолчанию запросы.
Пара примеров возможных SQL-запросов:
На этом простом примере можно видеть, как используя Apache Ignite можно поверх Apache Cassandra поднять распределенный SQL-движок с ACID-транзакциями и скоростью оперативной памяти.
Столкнувшись с Apache Cassandra в существующей инфраструктуре либо в greenfield-проекте, вспомните об этой статье и о том, что Cassandra хороша со вкусом Ignite. Или можно уже сейчас попробовать сочинить какой-то проект, например, из мира интернета вещей, использующий сильные стороны Ignite и Cassandra.
Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.

Ограничения Cassandra
Для начала хочу кратко пройтись по основным ограничениям Cassandra, с которыми будем работать:
- Пропускная способность и время отклика ограничены характеристиками жесткого диска или твердотельного накопителя;
- Специфическая структура хранения данных, оптимизированная под последовательные запись и чтение, не адаптирована под оптимальное выполнение классических реляционных операций над данными. Это не позволяет нормализовать данные и эффективно сопоставлять при помощи JOIN-ов, а также накладывает значительные ограничения, например, на такие операции, как GROUP BY и ORDER;
- Как следствие из п. 2 — отсутствие поддержки SQL в пользу своей более ограниченной вариации — CQL;
- Отсутствие ACID-транзакций.
Можно поспорить, что я хочу использовать Cassandra не по назначению, и я полностью соглашусь. Моя цель — показать, что если решить эти проблемы, “назначение” Cassandra можно значительно расширить. Совмещая человека и лошадь, получаем всадника, который может уже совсем иной перечень вещей, нежели человек и лошадь по-отдельности.
Как же можно обойти эти ограничения?
Я бы сказал, что классическим вариантом является фрагментация данных, когда часть лежит в Cassandra, а часть — в других системах, которые поддерживают необходимые гарантии.
Минусы этого подхода, которые видны навскидку: увеличение сложности (а значит, потенциально, и ухудшение скорости и качества) разработки и поддержки приложений. Намного проще стучаться в одни ворота, нежели на уровне приложения или слоя микросервисов совмещать разрозненную информацию из различных источников. Также деградация любой из двух систем может приводить к значительным негативным последствиям, вынуждая инфраструктрную команду гнаться сразу за двумя зайцами.
Apache Ignite
Ещё один способ — поставить другую систему поверх Cassandra, разделив ответственность между ними. Я считаю, что Apache Ignite — идеальный кандидат для этой схемы:
- Исчезает накладываемое диском ограничение производительности: Apache Ignite работает с оперативной памятью, сейчас нет ничего быстрее. Кроме того, она дешевеет настолько стремительно, что поставить достаточное количество RAM на пул серверов (Apache Ignite — распределенная система, как и Cassandra) — посильная задача;
- Полная поддержка классического SQL99, включая JOIN-ы, GROUP BY, ORDER BY, а также INSERT, UPDATE, DELETE, MERGE и так далее, позволяет нормализовать данные, облегчает аналитику, а с учетом производительности при работе с RAM — открывает потенциал HTAP, аналитики в реальном времени по операционным данным;
- Поддержка стандартов JDBC и ODBC облегчает интеграцию с существующими инструментами, например, Tableau, и фреймворками вроде Hibernate или Spring Data;
- Поддержка ACID-транзакций, гибкие и глубокие настройки обеспечения отказоустойчивости и дублирования данных;
- Распределенные вычисления, потоковая обработка данных, машинное обучение — можно легко реализовать множество новых для бизнеса сценариев использования, приносящих дивиденды.
В такой схеме Apache Ignite встает поверх Apache Cassandra, которая играет роль слоя постоянного энергонезависимого хранения. Несмотря на то, что уже в ближайших версиях Apache Ignite появится свое собственное решение Persistence с поддержкой расширения памяти диском, lazy run и сквозным SQL, Cassandra всё равно может быть интересна в этой роли за счет своей вылизанности за долгие годы развития, распространенности и возможности разделить ответственность, не складывая все яйца в одну корзину там, где это не нужно.
Кластер Apache Ignite вбирает в себя из Apache Cassandra все или часть данных (например, за исключением архивных), по которым нужно выполнять запросы, после чего работает в режиме write-through, самостоятельно обслуживая API- или SQL-запросы на чтение, и дублируя в синхронном или асинхронном режиме запросы на запись в Cassandra, надежно сохраняя их на диск.
Далее эти данные анализируются в реальном времени, могут использоваться средства визуализации наподобие Tableau, применяться распределенные алгоритмы машинного обучения, а также формироваться витрины.
А на примере?
Далее я приведу пример простой «синтетической» интеграции Apache Cassandra и Apache Ignite, чтобы показать, как это работает и что это совсем не сложно, пусть и требует определенной доли boilerplate-кода.
Для начала я создам необходимые таблицы в Cassandra и заполню их данными, затем инициализирую Java-проект и напишу DTO-классы, после чего покажу основную часть — конфигурирование Apache Ignite для работы с Cassandra.
Я буду использовать Mac OS Sierra, Cassandra 3.10 и Apache Ignite 2.0. В Linux команды должны быть аналогичны.
Cassandra: таблицы и данные
Для начала загрузим дистрибутив Cassandra в директорию ~/Downloads, пройдя по ссылке, либо используя curl/wget.
Далее зайдем в директорию и распакуем его:
$ cd ~/Downloads
$ tar xzvf apache-cassandra-3.10-bin.tar.gz
$ cd apache-cassandra-3.10Запустим Cassandra с настройками по умолчанию, для тестирования этого будет достаточно.
$ bin/cassandraДалее запустим интерактивный шелл Cassandra и создадим тестовые структуры данных (выберем обычный суррогатный id как ключ — для таблиц в Cassandra зачастую имеет смысл выбирать ключи, более осмысленные с точки зрения последующего извлечения данных, но мы упростим пример):
$ cd ~/Downloads/apache-cassandra-3.10
$ bin/cqlshCREATE KEYSPACE IgniteTest WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 1};
USE IgniteTest;
CREATE TABLE catalog_category (id bigint primary key, parent_id bigint, name text, description text);
CREATE TABLE catalog_good (id bigint primary key, categoryId bigint, name text, description text, price bigint, oldPrice bigint);
INSERT INTO catalog_category (id, parentId, name, description) VALUES (1, NULL, 'Бытовая техника', 'Различная бытовая техника для вашего дома!');
INSERT INTO catalog_category (id, parentId, name, description) VALUES (2, 1, 'Холодильники', 'Самые холодные холодильники!');
INSERT INTO catalog_category (id, parentId, name, description) VALUES (3, 1, 'Стиральные машинки', 'Замечательные стиралки!');
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (1, 2, 'Холодильник Buzzword', 'Лучший холодильник 2027!', 1000, NULL);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (2, 2, 'Холодильник Foobar', 'Дешевле не найти!', 300, 900);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (3, 2, 'Холодильник Barbaz', 'Люкс на вашей кухне!', 500000, 300000);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (4, 3, 'Машинка Habr#', 'Стирает, отжимает, сушит!', 10000, NULL);Проверим, что все данные записались корректно:
cqlsh:ignitetest> SELECT * FROM catalog_category;
id | description | name | parentId
----+--------------------------------------------+--------------------+-----------
1 | Различная бытовая техника для вашего дома! | Бытовая техника | null
2 | Самые холодные холодильники! | Холодильники | 1
3 | Замечательные стиралки! | Стиральные машинки | 1
(3 rows)
cqlsh:ignitetest> SELECT * FROM catalog_good;
id | categoryId | description | name | oldPrice | price
----+-------------+---------------------------+----------------------+-----------+--------
1 | 2 | Лучший холодильник 2027! | Холодильник Buzzword | null | 1000
2 | 2 | Дешевле не найти! | Холодильник Foobar | 900 | 300
4 | 3 | Стирает, отжимает, сушит! | Машинка Habr# | null | 10000
3 | 2 | Люкс на вашей кухне! | Холодильник Barbaz | 300000 | 500000
(4 rows)Инициализация Java-проекта
Есть 2 способа работы с Ignite: можно скачать дистрибутив с сайта ignite.apache.org, подложить ему необходимые Jar-файлы с собственными классами и XML с конфигурацией, либо использовать Ignite как зависимость в Java-проекте. В этой статье я рассмотрю второй вариант.
Создадим новый проект — я буду использовать maven как классический и понятный максимально широкой, на мой взгляд, аудитории инструмент.
В зависимости пропишем:
- ignite-cassandra-store для обеспечения интеграции с Cassandra;
- ignite-spring для загрузки XML-конфигурации в формате Spring Context, отсюда транзитивно нам прилетит кусок Spring, альтернативно можно не включать данный пакет и самим создать необходимые классы (в первую очередь IgniteConfiguration).
Транзитивно будет также загружен ignite-core, который содержит основные классы Apache Ignite.
<dependencies>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-cassandra-store</artifactId>
<version>2.0.0</version>
</dependency>
</dependencies>Далее необходимо создать DTO-классы, которые будут представлять таблицы Cassandra в мире Java:
import org.apache.ignite.cache.query.annotations.QuerySqlField;
public class CatalogCategory {
@QuerySqlField private long id;
@QuerySqlField private Long parentId;
@QuerySqlField private String name;
@QuerySqlField private String description;
// public getters and setters
}
public class CatalogGood {
@QuerySqlField private long id;
@QuerySqlField private long categoryId;
@QuerySqlField private String name;
@QuerySqlField private String description;
@QuerySqlField private long price;
@QuerySqlField private long oldPrice;
// public getters and setters
}...или на Kotlin
import org.apache.ignite.cache.query.annotations.QuerySqlField
data class CatalogCategory(@QuerySqlField var id: Long,
@QuerySqlField var parentId: Long?,
@QuerySqlField var name: String?,
@QuerySqlField var description: String?) {
constructor() : this(0, null, null, null)
}
data class CatalogGood(@QuerySqlField var id: Long,
@QuerySqlField var categoryId: Long,
@QuerySqlField var name: String?,
@QuerySqlField var description: String?,
@QuerySqlField var price: Long,
@QuerySqlField var oldPrice: Long) {
constructor() : this(0, 0, null, null, 0, 0)
}Мы помечаем аннотацией @QuerySqlField те поля, которые будут участвовать в SQL-запросах. Если поле не помечено данной аннотацией, его невозможно будет извлечь его посредством SQL или фильтровать по нему.
Также можно сделать более тонкие настройки для определения индексов и полнотекстовых индексов, которые выходят за рамки данного примера. Подробнее о настройке SQL в Apache Ignite можно прочитать в соответствующем разделе документации.
Конфигурация Apache Ignite
Создадим в src/main/resources нашу конфигурацию в файле apacheignite-cassandra.xml (название выбрано произвольно). Я приведу полную конфигурацию, которая достаточно объемна, после чего рассмотрю ее по частям:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean class="org.apache.ignite.cache.store.cassandra.datasource.DataSource" name="cassandra">
<property name="contactPoints" value="127.0.0.1"/>
</bean>
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="cacheConfiguration">
<list>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="CatalogCategory"/>
<property name="writeThrough" value="true"/>
<property name="sqlSchema" value="catalog_category"/>
<property name="indexedTypes">
<list>
<value type="java.lang.Class">java.lang.Long</value>
<value type="java.lang.Class">com.gridgain.test.model.CatalogCategory</value>
</list>
</property>
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSource" ref="cassandra"/>
<property name="persistenceSettings">
<bean class="org.apache.ignite.cache.store.cassandra.persistence.KeyValuePersistenceSettings">
<constructor-arg type="java.lang.String"><value><![CDATA[
<persistence keyspace="IgniteTest" table="catalog_category">
<keyPersistence class="java.lang.Long" strategy="PRIMITIVE" column="id"/>
<valuePersistence class="com.gridgain.test.model.CatalogCategory" strategy="POJO"/>
</persistence>]]></value></constructor-arg>
</bean>
</property>
</bean>
</property>
</bean>
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="CatalogGood"/>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="sqlSchema" value="catalog_good"/>
<property name="indexedTypes">
<list>
<value type="java.lang.Class">java.lang.Long</value>
<value type="java.lang.Class">com.gridgain.test.model.CatalogGood</value>
</list>
</property>
<property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSource" ref="cassandra"/>
<property name="persistenceSettings">
<bean class="org.apache.ignite.cache.store.cassandra.persistence.KeyValuePersistenceSettings">
<constructor-arg type="java.lang.String"><value><![CDATA[
<persistence keyspace="IgniteTest" table="catalog_good">
<keyPersistence class="java.lang.Long" strategy="PRIMITIVE" column="id"/>
<valuePersistence class="com.gridgain.test.model.CatalogGood" strategy="POJO"/>
</persistence>]]></value></constructor-arg>
</bean>
</property>
</bean>
</property>
</bean>
</list>
</property>
</bean>
</beans>Формат конфигурации — Spring Beans.
Конфигурацию можно поделить на два раздела: определение DataSource для установки связи с Cassandra и определение настроек Apache Ignite, которые сводятся в данном примере к указанию рабочих кешей, полностью соответствующих таблицам в Cassandra.
Первая часть конфигурации лаконична:
<bean class="org.apache.ignite.cache.store.cassandra.datasource.DataSource" name="cassandra">
<property name="contactPoints" value="127.0.0.1"/>
</bean>Мы определяем источник данных Cassandra, указываем адреса, по которым можно попытаться установить соединение.
Далее задается конфигурация Apache Ignite. В рамках этого теста будет минимальное отклонение от настроек по-умолчанию, поэтому переопределяем только свойство
cacheConfiguration, которое будет содержать список кешей, запускаемых на кластере: <bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="cacheConfiguration">
<list>
...
</list>
</property>
</bean>Первый кеш — представляющий таблицу catalog_category:
<bean class="org.apache.ignite.configuration.CacheConfiguration">
<property name="name" value="CatalogCategory"/>
...
</bean>В нем включаем режим сквозных чтения и записи (если будем что-то писать в кеш, операция записи будет автоматически дублироваться в Cassandra), указываем, что в SQL будет использоваться схема catalog_category, а также перечисляем типы, которые будут храниться в этом кеше и должны быть обработаны для обращения к ним через SQL. Типы указываются всегда парами ключ-значение, поэтому количество элементов списка всегда должно быть четным.
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="sqlSchema" value="catalog_category"/>
<property name="indexedTypes">
<list>
<value type="java.lang.Class">java.lang.Long</value>
<value type="java.lang.Class">com.gridgain.test.model.CatalogCategory</value>
</list>
</property>Наконец, зададим связь с Cassandra, здесь будет два основных подраздела. Во-первых, укажем ссылку на созданный ранее DataSource: cassandra. Во-вторых, нам нужно будет указать, как соотносить между собой таблицы Cassandra и записи «ключ-значение» Ignite. Это будет делаться через свойство
persistenceSettings, в котором лучше сослаться на внешний XML-файл с конфигурацией меппинга, но для простоты встроим этот XML непосредственно в Spring-конфигурацию как CDATA-элемент: <property name="cacheStoreFactory">
<bean class="org.apache.ignite.cache.store.cassandra.CassandraCacheStoreFactory">
<property name="dataSource" ref="cassandra"/>
<property name="persistenceSettings">
<bean class="org.apache.ignite.cache.store.cassandra.persistence.KeyValuePersistenceSettings">
<constructor-arg type="java.lang.String"><value><![CDATA[
<persistence keyspace="IgniteTest" table="catalog_category">
<keyPersistence class="java.lang.Long" strategy="PRIMITIVE" column="id"/>
<valuePersistence class="com.gridgain.test.model.CatalogCategory" strategy="POJO"/>
</persistence>]]></value></constructor-arg>
</bean>
</property>
</bean>
</property>Конфигурация меппинга выглядит достаточно интутивно понятно:
<persistence keyspace="IgniteTest" table="catalog_category">
<keyPersistence class="java.lang.Long" strategy="PRIMITIVE" column="id"/>
<valuePersistence class="com.gridgain.test.model.CatalogCategory" strategy="POJO"/>
</persistence>На верхнем уровне (тег
persistence) указывается Keyspace (IgniteTest в данном случае) и Table (catalog_category), которые мы будем соотносить. Затем указывается, что ключом Ignite-кеша будет тип Long, который является примитивным и должен соотноситься с колонкой id в таблице Cassandra. При этом значением является класс CatalogCategory, который должен при помощи Reflection (stategy="POJO") формироваться из колонок таблицы Cassandra.Подробнее о более тонких настройках меппинга, которые выходят за рамки данного примера, можно прочитать в соответствующем разделе документации.
Конфигурация второго кеша, содержащего данные о товарах аналогична.
Запуск
Для запуска создадим класс
com.gridgain.test.Starter:package com.gridgain.test;
import org.apache.ignite.Ignite;
import org.apache.ignite.Ignition;
public class Starter {
public static void main(String... args) throws Exception {
final Ignite ignite = Ignition.start("apacheignite-cassandra.xml");
ignite.cache("CatalogCategory").loadCache(null);
ignite.cache("CatalogGood").loadCache(null);
}
}
Здесь мы используем инструкцию
Ignition.start(...) для запуска узла Apache Ignite, указав в качестве источника конфигурации лежащий на classpath файл apacheignite-cassandra.xml.SQL
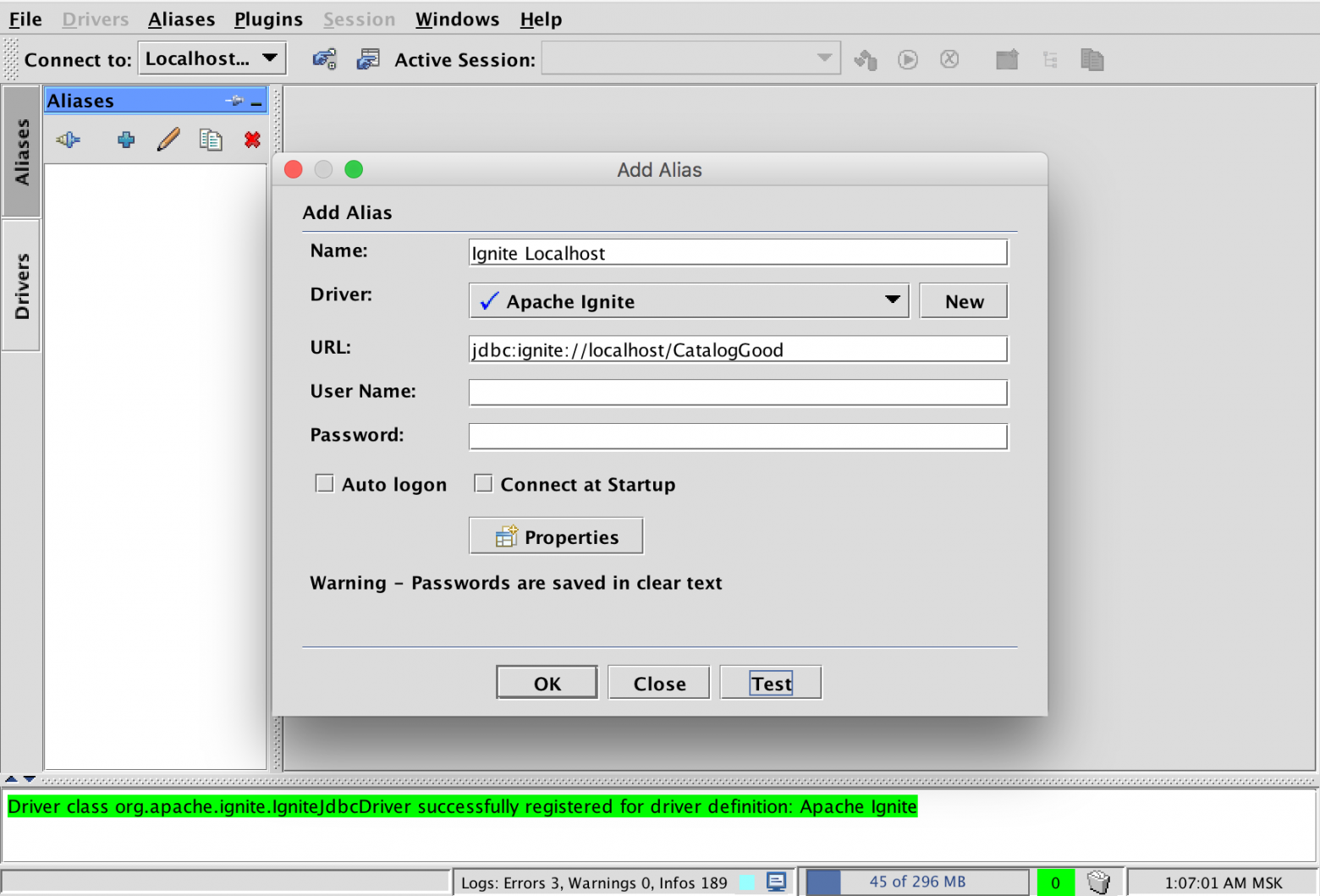
Для выполнения SQL-запросов можно использовать любой клиент, который поддерживает JDBC, например, встроенный в IntelliJ IDEA, либо SquirrelSQL. В последнем случае, например, нужно будет добавить драйвер Apache Ignite (который находится в Jar-файле ignite-core, его можно скачать в составе дистрибутива):

Создадим новое соединение по URL вида jdbc:ignite://localhost/CatalogGood, где localhost — адрес одного из узлов Apache Ignite, а CatalogGood — кеш, к которому будут идти по умолчанию запросы.

Пара примеров возможных SQL-запросов:
SELECT cg.name goodName, cg.price goodPrice, cc.name category, pcc.name parentCategory
FROM catalog_category.CatalogCategory cc
JOIN catalog_category.CatalogCategory pcc
ON cc.parentId = pcc.id
JOIN catalog_good.CatalogGood cg
ON cg.categoryId = cc.id;| goodName | goodPrice | category | parentCategory |
|---|---|---|---|
| Холодильник Buzzword | 1000 | Холодильники | Бытовая техника |
| Холодильник Foobar | 300 | Холодильники | Бытовая техника |
| Холодильник Barbaz | 500000 | Холодильники | Бытовая техника |
| Машинка Habr# | 10000 | Стиральные машинки | Бытовая техника |
SELECT cc.name, AVG(cg.price) avgPrice
FROM catalog_category.CatalogCategory cc
JOIN catalog_good.CatalogGood cg
ON cg.categoryId = cc.id
WHERE cg.price <= 100000
GROUP BY cc.id;| name | avgPrice |
|---|---|
| Холодильники | 650 |
| Стиральные машинки | 10000 |
Заключение
На этом простом примере можно видеть, как используя Apache Ignite можно поверх Apache Cassandra поднять распределенный SQL-движок с ACID-транзакциями и скоростью оперативной памяти.
Столкнувшись с Apache Cassandra в существующей инфраструктуре либо в greenfield-проекте, вспомните об этой статье и о том, что Cassandra хороша со вкусом Ignite. Или можно уже сейчас попробовать сочинить какой-то проект, например, из мира интернета вещей, использующий сильные стороны Ignite и Cassandra.
