Облачные вычисления так популярны по нескольким причинам: они гибкие, относительно дешевые по сравнению с поддержкой внутренней инфраструктуры и позволяют отлично автоматизировать распределение ресурсов (и тут тоже экономия). Когда объем обрабатываемых данных растет из года в год, нельзя полагаться на вертикальную масштабируемость, покупая все более и более дорогие серверы. Данные должны быть распределены по нескольким более дешевым системам (кластерам), где могут надежно храниться, обрабатываться и возвращаться к пользователю при необходимости. Создание таких систем — непростая задача, но, к счастью, есть решения, которые отлично вписываются в облачную архитектуру. Я говорю об Apache Ignite.
Я собираюсь использовать AWS-облако для развертывания кластера Ignite. Для целей обучения нам хватит бесплатных машин базового уровня (AWS free tier). Я выбрал образ Ubuntu 18.04, но в целом это неважно. Перед развертыванием первых машин нам надо настроить группу безопасности (Security Group). В ней должны быть определены сетевые правила для портов, необходимых для узлов Ignite.

Рисунок 1 – Конфигурация Security Group
Два диапазона портов были настроены явным образом: диапазон портов 47500-47600 для discovery (механизм обнаружения, он позволяет узлам находить друг друга и формировать кластер), а диапазон 47100-47200 — для подсистемы связи (communication), которая позволяет узлам посылать друг другу прямые сообщения.
Теперь, после настройки Security Group, пора запустить и настроить наши машины.

Рисунок 2 — Security group выбирается во время подготовки инстанса AWS
Машины запущены, но им не хватает основного ПО: Java. Нет проблем, просто используйте следующую команду для установки Java:
Команда для пакетов RedHat/Centos выглядит слегка иначе:
Отлично! Мы всего в шаге от первого инстанса Ignite, запущенного и работающего в облаке!
Я скачал с официального сайта бинарный пакет версии 2.7.6 и распаковал его:

Рисунок 3 – Первый узел запущен
Мы уже сильно продвинулись: подготовили среду, выяснили, где взять бинарные файлы и как их запустить. Пора собрать кластер. Запуска группы узлов недостаточно для построения кластера, и это становится очевидным из логов: у каждого узла есть такая строка в логах:

Рисунок 4 – Два узла сформировали два независимых кластера
Это сообщение означает, что два узла сформировали два независимых кластера вместо того, чтобы обнаружить друг друга и объединиться в один.
Чтобы создать настоящую кластерную среду, надо глубже разобраться в том, как узлы объединяются в кластер. Особую роль в этом процессе играет специальный сервис Discovery. Именно он позволяет узлам находить друг друга и формировать кластер.
Когда узел запускается, он первым делом запрашивает свой экземпляр сервиса Discovery для поиска существующего кластера и пытается присоединиться вместо того, чтобы создавать новый.
Настройки DiscoverySPI, позволяющие сервису обнаружить кластер, должен предоставить конечный пользователь, однако они просты и интуитивны. Всё, что нам нужно сделать, — это сконфигурировать IpFinder (компонент для поиска ip-адресов существующих узлов) и передать его в Discovery. Сделаем это и соберем изолированные узлы в единую систему.
Откройте конфигурационный файл в вашем любимом текстовом редакторe…
… и добавьте следующий блок:
Этот блок нужно разместить прямо под корневым элементом файла конфигурации. Самое важное здесь — значение, переданное в свойстве addresses. Для каждого сервера это должен быть либо частный, внутрисетевой IP-адрес, либо публичный IP-адрес другого сервера.
Вкладка Description каждого узла содержит информацию о публичных и частных IP-адресах наших AWS-узлов:
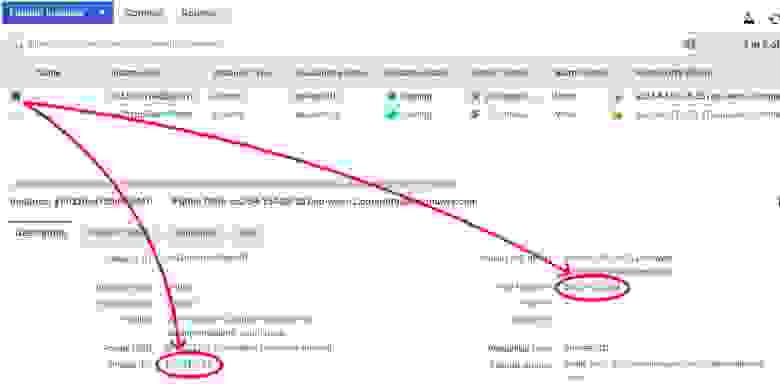
Рисунок 5 – Частные и публичные IP-адреса в консоли управления AWS
Пока что мы создали облачную среду с нуля, развернули, настроили и собрали кластер Ignite, а также расширили наше понимание распределенных систем на этом пути. Настало время сделать что-то полезное с нашим новеньким кластером: подключиться к нему с помощью удаленного клиента, загрузить некоторые данные и убедиться, что они там есть.
Ignite предоставляет несколько способов подключения к кластеру: тонкие клиенты, интерфейсы JDBC/ODBC и так далее. Но я собираюсь использовать подключение толстого клиента, что делается очень просто. Фактически, толстый клиент является почти обычным серверным узлом Ignite, за исключением того, что он не хранит данные кэшей локально (и некоторых других технических деталей, но мы не будем углубляться в них прямо сейчас), поэтому его конфигурация очень похожа.
Я начинаю с моей любимой IDE и создаю простейший Java-проект: проект командной строки. Я добавляю в путь к классам проекта три jar-файла из того самого бинарного пакета, который мы использовали для развертывания наших серверов Ignite в облаке. Вот эти jar-файлы: ignite-core-2.7.6.jar, cache-api-1.0.0.jar и annotations-13.0.jar.
Вот конфигурация в Java для моего клиента:
Здесь мы видим те же свойства, которые уже настроили для серверных узлов: DiscoverySPI, IpFinder и так далее. Здесь много общего, за исключением флажка
Используя эту конфигурацию, я запускаю клиентский узел, отправляю в кластер запрос на создание кэша, помещаю туда простую строку и снова читаю это значение:
Хм, я вижу, что что-то не так. Моя простенькая программа запускается, но не выводит никаких результатов. В то же время я вижу в серверных логах, что серверы добавили клиентский узел в топологию:

Рисунок 6 – Сообщение в серверных логах о подключенном клиенте
Так в чём же дело? А вот в чём — в облачных средах на стороне сервера необходимо настроить еще одну вещь: преобразователь адресов AddressResolver.
Поскольку наши серверы работают в AWS, между ними и внешним миром работает сервис NAT (Network Address Translation). Серверы знают свои внутренние (находящиеся за NAT) IP-адреса, но не знают, какие им назначены публичные IP-адреса. Чтобы предоставить серверам информацию об этом сопоставлении и тем самым позволить им взаимодействовать с удаленными клиентами, нам нужно настроить преобразователи адресов на стороне сервера.
Сначала остановите оба серверных узла.
Затем добавьте еще один блок в конфигурацию каждого сервера, снова прямо под корневым элементом config xml. Здесь частный и публичный IP-адреса — это адреса того сервера, чья конфигурация изменяется:
Перезагрузите узлы Ignite, чтобы изменения вступили в силу. Имейте в виду, что публичный IP-адрес может измениться после перезапуска виртуальной машины, тогда придется редактировать настройку addressResolver.
Снова запустите программу с клиентским узлом. Теперь мы видим ожидаемый результат: программа завершает работу и извлекает из кэша только что помещенное туда значение.
Для развертывания кластера Ignite в облаке AWS требуется несколько простых шагов. А после них мы сможем делать более интересные вещи вроде потоковой передачи данных в кластер с помощью стримеров данных, выполнения запросов или использования других интерфейсов, таких как JDBC/ODBC соединение, для подключения к кластеру.
Только помните, что для разработки более полезных приложений требуется больше ресурсов, а бесплатные экземпляры AWS очень быстро израсходуются. Независимо от того, используется ли Ignite в качестве основной базы данных или в качестве in-memory-кэша, больший объем памяти означает лучшую производительность, и для промышленной эксплуатации лучше всего подходят мощные экземпляры уровня x1.
Подготовка среды
Я собираюсь использовать AWS-облако для развертывания кластера Ignite. Для целей обучения нам хватит бесплатных машин базового уровня (AWS free tier). Я выбрал образ Ubuntu 18.04, но в целом это неважно. Перед развертыванием первых машин нам надо настроить группу безопасности (Security Group). В ней должны быть определены сетевые правила для портов, необходимых для узлов Ignite.
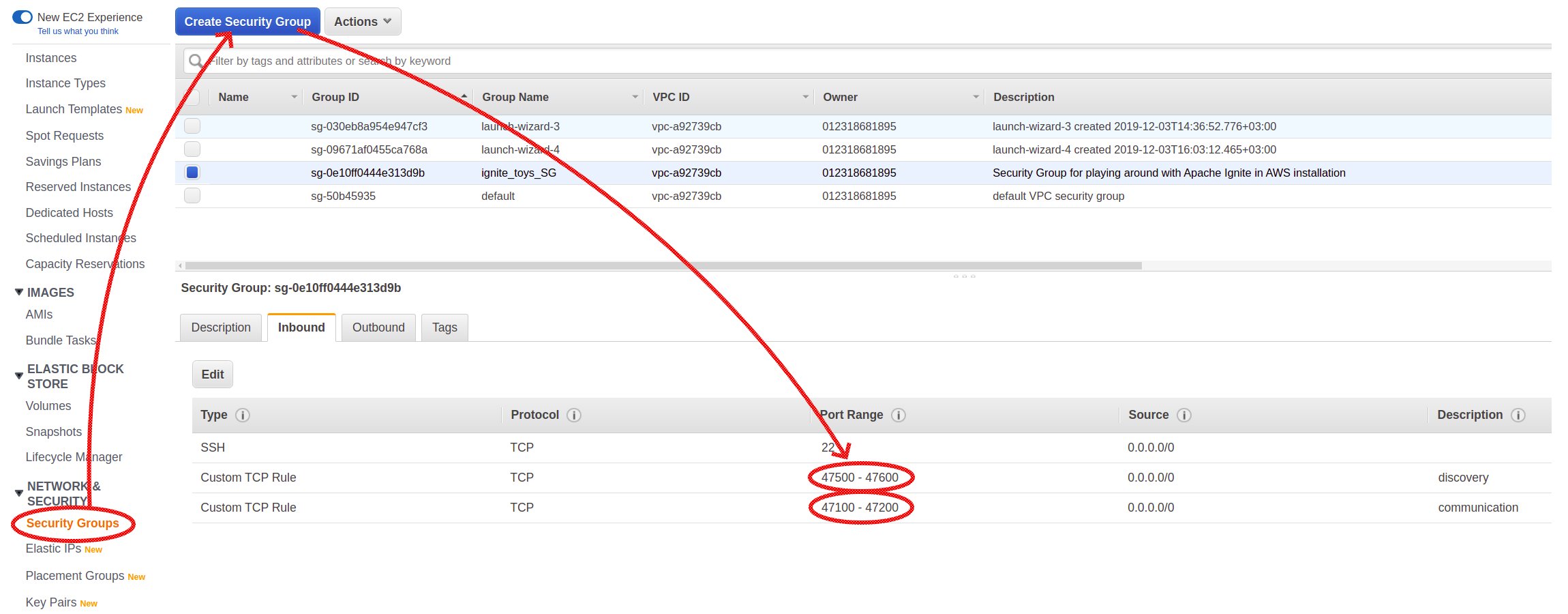
Рисунок 1 – Конфигурация Security Group
Два диапазона портов были настроены явным образом: диапазон портов 47500-47600 для discovery (механизм обнаружения, он позволяет узлам находить друг друга и формировать кластер), а диапазон 47100-47200 — для подсистемы связи (communication), которая позволяет узлам посылать друг другу прямые сообщения.
Теперь, после настройки Security Group, пора запустить и настроить наши машины.

Рисунок 2 — Security group выбирается во время подготовки инстанса AWS
Машины запущены, но им не хватает основного ПО: Java. Нет проблем, просто используйте следующую команду для установки Java:
~/sudo apt install openjdk-8-jdkсКоманда для пакетов RedHat/Centos выглядит слегка иначе:
~/sudo yum install java-1.8.0-openjdk.x86_64Отлично! Мы всего в шаге от первого инстанса Ignite, запущенного и работающего в облаке!
Я скачал с официального сайта бинарный пакет версии 2.7.6 и распаковал его:
~/ignite$ wget http://mirror.linux-ia64.org/apache//ignite/2.7.6/apache-ignite-2.7.6-bin.zip
~/ignite$ unzip apache-ignite-2.7.6-bin.zip
~/ignite/apache-ignite-2.7.6-bin$ ./bin/ignite.sh 
Рисунок 3 – Первый узел запущен
Мы уже сильно продвинулись: подготовили среду, выяснили, где взять бинарные файлы и как их запустить. Пора собрать кластер. Запуска группы узлов недостаточно для построения кластера, и это становится очевидным из логов: у каждого узла есть такая строка в логах:

Рисунок 4 – Два узла сформировали два независимых кластера
Это сообщение означает, что два узла сформировали два независимых кластера вместо того, чтобы обнаружить друг друга и объединиться в один.
Чтобы создать настоящую кластерную среду, надо глубже разобраться в том, как узлы объединяются в кластер. Особую роль в этом процессе играет специальный сервис Discovery. Именно он позволяет узлам находить друг друга и формировать кластер.
Когда узел запускается, он первым делом запрашивает свой экземпляр сервиса Discovery для поиска существующего кластера и пытается присоединиться вместо того, чтобы создавать новый.
Настройки DiscoverySPI, позволяющие сервису обнаружить кластер, должен предоставить конечный пользователь, однако они просты и интуитивны. Всё, что нам нужно сделать, — это сконфигурировать IpFinder (компонент для поиска ip-адресов существующих узлов) и передать его в Discovery. Сделаем это и соберем изолированные узлы в единую систему.
Откройте конфигурационный файл в вашем любимом текстовом редакторe…
~/ignite/apache-ignite-2.7.6-bin$ vim config/default-config.xml… и добавьте следующий блок:
<property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi">
<property name="ipFinder">
<bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder">
<property name="addresses">
<list>
<value>172.31.3.57</value>
</list>
</property>
</bean>
</property>
</bean>
</property>Этот блок нужно разместить прямо под корневым элементом файла конфигурации. Самое важное здесь — значение, переданное в свойстве addresses. Для каждого сервера это должен быть либо частный, внутрисетевой IP-адрес, либо публичный IP-адрес другого сервера.
Вкладка Description каждого узла содержит информацию о публичных и частных IP-адресах наших AWS-узлов:
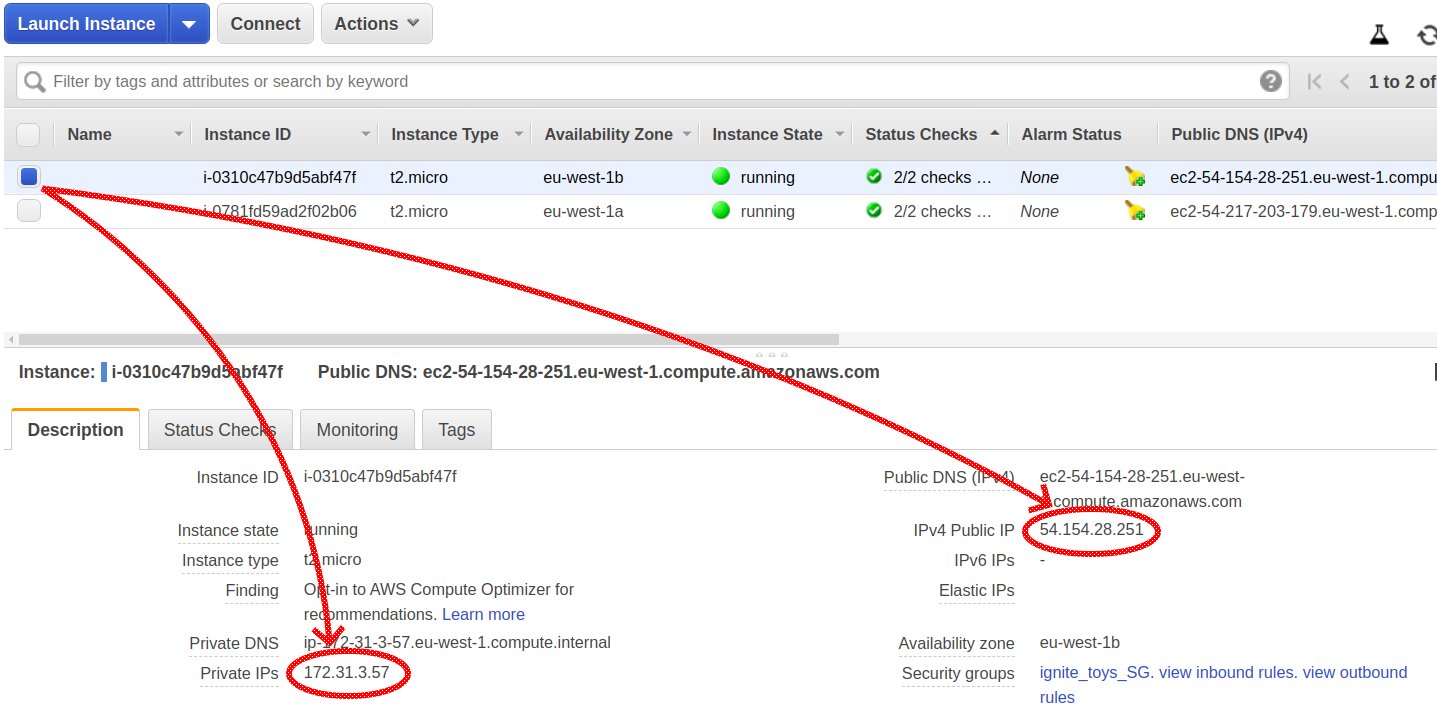
Рисунок 5 – Частные и публичные IP-адреса в консоли управления AWS
Подключение к кластеру с помощью толстого клиента
Пока что мы создали облачную среду с нуля, развернули, настроили и собрали кластер Ignite, а также расширили наше понимание распределенных систем на этом пути. Настало время сделать что-то полезное с нашим новеньким кластером: подключиться к нему с помощью удаленного клиента, загрузить некоторые данные и убедиться, что они там есть.
Ignite предоставляет несколько способов подключения к кластеру: тонкие клиенты, интерфейсы JDBC/ODBC и так далее. Но я собираюсь использовать подключение толстого клиента, что делается очень просто. Фактически, толстый клиент является почти обычным серверным узлом Ignite, за исключением того, что он не хранит данные кэшей локально (и некоторых других технических деталей, но мы не будем углубляться в них прямо сейчас), поэтому его конфигурация очень похожа.
Я начинаю с моей любимой IDE и создаю простейший Java-проект: проект командной строки. Я добавляю в путь к классам проекта три jar-файла из того самого бинарного пакета, который мы использовали для развертывания наших серверов Ignite в облаке. Вот эти jar-файлы: ignite-core-2.7.6.jar, cache-api-1.0.0.jar и annotations-13.0.jar.
Вот конфигурация в Java для моего клиента:
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setClientMode(true);
TcpDiscoveryVmIpFinder ipFinder = new TcpDiscoveryVmIpFinder();
ipFinder.setAddresses(Arrays.asList("54.154.28.251"));
TcpDiscoverySpi spi = new TcpDiscoverySpi();
spi.setIpFinder(ipFinder);
cfg.setDiscoverySpi(spi);
Здесь мы видим те же свойства, которые уже настроили для серверных узлов: DiscoverySPI, IpFinder и так далее. Здесь много общего, за исключением флажка
cfg.setClientMode(true), который превращает обычный узел Ignite в клиентский.Используя эту конфигурацию, я запускаю клиентский узел, отправляю в кластер запрос на создание кэша, помещаю туда простую строку и снова читаю это значение:
try (Ignite client = Ignition.start(cfg)) {
IgniteCache cache = client.getOrCreateCache(
new CacheConfiguration("clientCache")
.setBackups(1)
.setAffinity(new RendezvousAffinityFunction(false, 4))
);
cache.put(1, "myString");
System.out.println("-->>-->> value of key ‘1’: " + cache.get(1));
}Хм, я вижу, что что-то не так. Моя простенькая программа запускается, но не выводит никаких результатов. В то же время я вижу в серверных логах, что серверы добавили клиентский узел в топологию:

Рисунок 6 – Сообщение в серверных логах о подключенном клиенте
Так в чём же дело? А вот в чём — в облачных средах на стороне сервера необходимо настроить еще одну вещь: преобразователь адресов AddressResolver.
Поскольку наши серверы работают в AWS, между ними и внешним миром работает сервис NAT (Network Address Translation). Серверы знают свои внутренние (находящиеся за NAT) IP-адреса, но не знают, какие им назначены публичные IP-адреса. Чтобы предоставить серверам информацию об этом сопоставлении и тем самым позволить им взаимодействовать с удаленными клиентами, нам нужно настроить преобразователи адресов на стороне сервера.
Сначала остановите оба серверных узла.
Затем добавьте еще один блок в конфигурацию каждого сервера, снова прямо под корневым элементом config xml. Здесь частный и публичный IP-адреса — это адреса того сервера, чья конфигурация изменяется:
<property name="addressResolver">
<bean class="org.apache.ignite.configuration.BasicAddressResolver">
<constructor-arg>
<map>
<entry key="<private IP>" value="<public IP>"/>
</map>
</constructor-arg>
</bean>
</property>Перезагрузите узлы Ignite, чтобы изменения вступили в силу. Имейте в виду, что публичный IP-адрес может измениться после перезапуска виртуальной машины, тогда придется редактировать настройку addressResolver.
Снова запустите программу с клиентским узлом. Теперь мы видим ожидаемый результат: программа завершает работу и извлекает из кэша только что помещенное туда значение.
Заключение
Для развертывания кластера Ignite в облаке AWS требуется несколько простых шагов. А после них мы сможем делать более интересные вещи вроде потоковой передачи данных в кластер с помощью стримеров данных, выполнения запросов или использования других интерфейсов, таких как JDBC/ODBC соединение, для подключения к кластеру.
Только помните, что для разработки более полезных приложений требуется больше ресурсов, а бесплатные экземпляры AWS очень быстро израсходуются. Независимо от того, используется ли Ignite в качестве основной базы данных или в качестве in-memory-кэша, больший объем памяти означает лучшую производительность, и для промышленной эксплуатации лучше всего подходят мощные экземпляры уровня x1.
