
Тема статьи достаточно узконаправленная, но, возможно, окажется полезной тем, кто разрабатывает свои собственные хранилища данных и думает об интеграции со Spring Framework.
Предпосылки
Разработчики обычно не очень любят менять свои привычки (зачастую, в список привычек входят и фреймворки). Когда я начал работать с CUBA, мне не пришлось учить слишком много всего нового, активно включаться в работу над проектом можно было почти сразу. Но была одна вещь, над которой пришлось посидеть подольше — это была работа с данными.
В Spring есть несколько библиотек, которые можно использовать для работы с БД, одна из наиболее популярных — spring-data-jpa, которая позволяет в большинстве случаев не писать SQL или JPQL. Нужно всего лишь создать специальный интерфейс с методами, которые названы специальным образом и Spring сгенерирует и выполнит за вас всю оставшуюся часть работы по выборке данных из БД и созданию экземпляров объектов-сущностей.
Ниже представлен интерфейс, с методом для подсчета клиентов с заданной фамилией.
interface CustomerRepository extends CrudRepository<Customer, Long> {
long countByLastName(String lastName);
}Этот интерфейс можно напрямую использовать в Spring сервисах, не создавая никакой имплементации, что сильно ускоряет работу.
В CUBA есть API для работы с данными, который включает в себя различную функциональность вроде частично загружаемых сущностей или хитрую систему безопасности с контролем доступа к атрибутам сущностей и строкам в таблицах БД. Но этот API немного отличается от того, к чему привыкли разработчики в Spring Data или JPA/Hibernate.
Почему же в CUBA нет JPA репозиториев и можно ли их добавить?
Работа с данными в CUBA
В CUBA три основных класса, отвечающих за работу с данными: DataStore, EntityManager и DataManager.
DataStore — высокоуровневая абстракция для любого хранилища данных: БД, файловой системы или облачного хранилища. Этот API позволяет выполнять базовые операции над данными. В большинстве случаев разработчикам нет нужды работать с DataStore напрямую, кроме случаев разработки своего собственного хранилища, или если требуется какой-то очень специальный доступ к данным в хранилище.
EntityManager — копия всем хорошо известного JPA EntityManager. В отличие от стандартной имплементации, в нем есть специальные методы для работы с представлениями CUBA, для "мягкого"(логического) удаления данных, а также для работы с запросами в CUBA. Как и в случае с DataStore, в 90% проектов обычному разработчику не придется иметь дело с EntityManager, кроме случаев, когда нужно выполнять какие-то запросы в обход системы ограничения доступа к данным.
DataManager — основной класс для работы с данными в CUBA. Предоставляет API для манипулирования данными и поддерживает контроль доступа к данным, включая доступ к атрибутам и row-level ограничения. DataManager неявно модифицирует все запросы, которые выполняются в CUBA. Например, он может исключить поля таблицы, к которым у текущего пользователя нет доступа, из оператора select и добавить условия where для исключения строк таблиц из выборки. И это сильно облегчает жизнь разработчикам, потому что не надо думать, как правильно писать запросы с учетом прав доступа, CUBA это делает автоматически на основе данных из служебных таблиц БД.
Ниже — диаграмма взаимодействия компонентов CUBA, которые участвуют в выборке данных через DataManager.
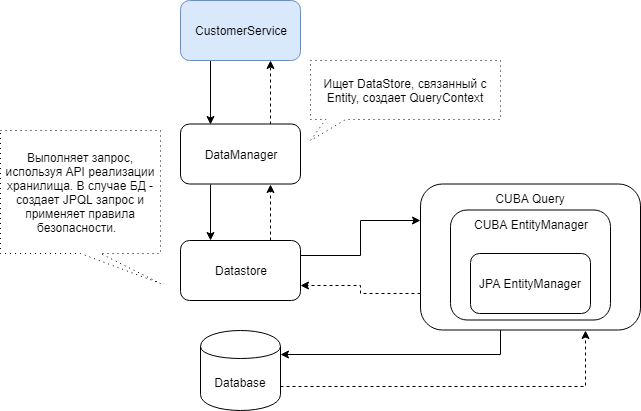
При помощи DataManager можно относительно просто загружать сущности и целые иерархии сущностей, при помощи предствлений CUBA. В самом простом виде запрос выглядит так:
dataManager.load(Customer.class).list();Как уже упоминалось, DataManager отфильтрует "логически удаленные" записи, уберет из запроса запрещенные атрибуты, а также откроет и закроет транзакцию автоматически.
Но, когда дело доходит до запросов посложнее, то в CUBA приходится писать JPQL.
Например, если нужно посчитать клиентов с заданной фамилией, как в примере из предыдущего раздела, то нужно написать примерно такой код:
public Long countByLastName(String lastName) {
return dataManager
.loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class)
.parameter("lastName", lastName)
.one();
}или такой:
public Long countByLastName(String lastName) {
LoadContext<Customer> loadContext = LoadContext.create(Customer.class);
loadContext
.setQueryString("select c from sample$Customer c where c.lastName = :lastName")
.setParameter("lastName", lastName);
return dataManager.getCount(loadContext);
}В CUBA API нужно передавать JPQL выражение в виде строки (Criteria API ещё не поддерживается), это читаемый и понятный способ создания запросов, но отладка таких запросов может принести немало веселых минут. Кроме того, строки JPQL не верифицируются ни компилятором, ни Spring Framework во время инициализации контейнера, что приводит к возникновению ошибок только в Runtime.
Сравните это со Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> {
long countByLastName(String lastName);
}Код в три раза короче, и никаких строк. Вдобавок, название метода countByLastName проверяется во время инициализации Spring контейнера. Если допущена опечатка и вы написали countByLastNsme, то приложение вылетит с ошибкой во время деплоя:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer! CUBA построена вокруг Spring Framework, так что в приложение, написанное с использованием CUBA, можно подключить библиотеку spring-data-jpa, но есть небольшая проблема — контроль доступа. Имплементация CrudRepository в Spring использует свой EntityManager. Таким образом, все запросы будут выполняться в обход DataManager. Таким образом, чтобы использовать JPA репозитории в CUBA, нужно заменить все вызовы EntityManager на вызовы DataManager и добавить поддержку CUBA представлений.
Кто-то может сказать, что spring-data-jpa — это такой неконтролируемый черный ящик и всегда предпочтительнее писать чистый JPQL или даже SQL. Это вечная проблема баланса между удобством и уровнем абстракции. Каждый выбирает тот способ, который ему больше по душе, но иметь в арсенале дополнительный способ работы с данными никогда не помешает. А тем, кому нужно больше управления, в Spring есть способ определить свой собственный запрос для методов JPA репозиториев.
Реализация
JPA репозитории реализованы в виде CUBA модуля, с использованием библиотеки spring-data-commons. Мы отказались от идеи модификации spring-data-jpa, потому что объем работы был бы сильно больше по сравнению с написанием собственного генератора запросов. Тем более, что spring-data-commons делает большую часть работы. Например, разбор имени метода и связывание имени с классами и свойствами полностью делается в этой библиотеке. Spring-data-commons содержит все необходимые базовые классы для имплементации собственных репозиториев и требуется не так много усилий, чтобы это реализовать. Например, эта библиотека используется в spring-data-mongodb.
Самым сложным было аккуратно реализовать генерацию JPQL на основе иерархии объектов — результата разбора имени метода. Но, к счастью, в Apache Ignite уже была реализована похожая задача, поэтому код был взят оттуда и немного адаптирован для генерации JPQL вместо SQL и поддержки оператора delete.
В spring-data-commons используется проксирование для динамического создания реализаций интерфейсов. Когда инициализируется контекст CUBA приложения, то все ссылки на интерфейсы заменяются на ссылки на прокси-бины, опубликованные в контексте. При вызове метода интерфейса он перехватывается соответствующим прокси-объектом. Затем этот объект генерирует JPQL запрос по имени метода, подставляет параметры и отдает запрос с параметрами в DataManager на выполнение. Следующая диаграмма отображает упрощенный процесс взаимодействия ключевых компонентов модуля.

Использование репозиториев в CUBA
Чтобы исплоьзовать репозитории в CUBA, нужно просто подключить модуль в файле сборки проекта:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")Можно использовать XML конфигурацию для того, чтобы "включить" репозитории:
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd
http://www.cuba-platform.org/schema/data/jpa
http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd">
<!-- Annotation-based beans -->
<context:component-scan base-package="com.company.sample"/>
<repositories:repositories base-package="com.company.sample.core.repositories"/>
</beans:beans>А можно воспользоваться аннотациями:
@Configuration
@EnableCubaRepositories
public class AppConfig {
//Configuration here
}После того, как поддержка репозиториев активирована, можно их создавать в привычном виде, например:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> {
long countByLastName(String lastName);
List<Customer> findByNameIsIn(List<String> names);
@CubaView("_minimal")
@JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')")
List<Customer> findByNameStartingWith(String name);
}Для каждого метода можно использовать аннотации:
@CubaView— для задания представления CUBA, которое будет использоваться в DataManager@JpqlQuery— для задания JPQL запроса, который будет выполняться, вне зависимости от названия метода.
Этот модуль используется в модуле global фреймворка CUBA, следовательно, можно использовать репозитории как в модуле core, так и в web. Единственное, что нужно не забыть — активировать репозитории в конфигурационных файлах обоих модулей.
Пример использования репозитория в сервисе CUBA:
@Service(CustomerService.NAME)
public class CustomerServiceBean implements PersonService {
@Inject
private CustomerRepository customerRepository;
@Override
public List<Date> getCustomersBirthDatesByLastName(String name) {
return customerRepository.findByNameStartingWith(name)
.stream().map(Customer::getBirthDate).collect(Collectors.toList());
}
}Заключение
CUBA — гибкий фреймворк. Если есть желание что-то в него добавить, то нет необходимости исправлять ядро самостоятельно или ждать новую версию. Я надеюсь, что этот модуль сделает разработку с CUBA более эффективной и быстрой. Первая версия модуля доступна на GitHub, протестировано на CUBA версии 6.10
