
У большинства крупных поисковиков и сервисов есть механизм похожих поисковых запросов, когда пользователю предлагаются варианты, тематически близкие к тому, что он искал. Так делают в google, yandex, bing, amazon, несколько дней назад это появилось и у нас на hh.ru!
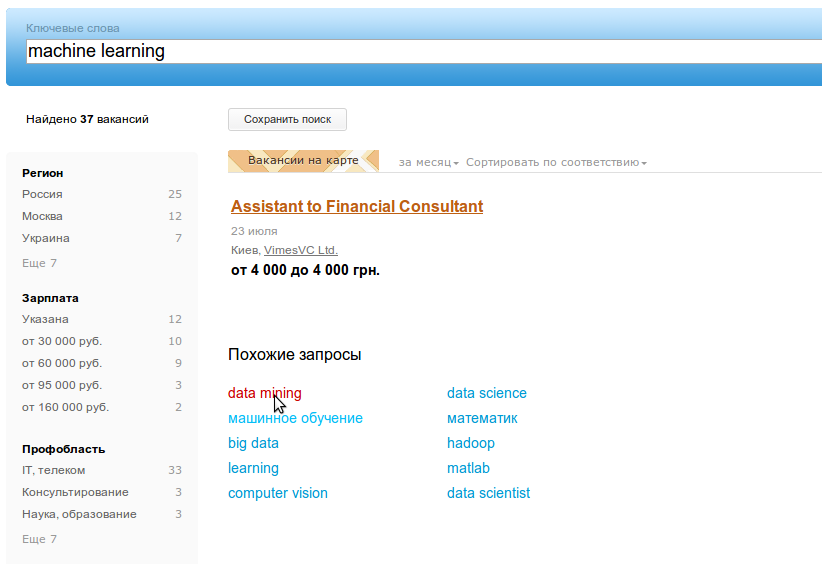
В этой статье я расскажу о том, как мы добывали похожие поисковые запросы из логов сайта hh.ru.
Для начала несколько слов о том, что такое “похожие запросы” (related searches) и зачем они нужны.
Мы давно думали об этой фиче, но окончательный толчок дала прекрасная статья от LinkedIn про их реализацию похожих запросов — metaphor. В ней описаны три метода извлечения таких запросов из поисковой активности пользователей, которые мы и реализовали.
Самый простой и очевидный из алгоритмов извлечения связанных запросов — это overlap или поиск пересекающихся запросов.
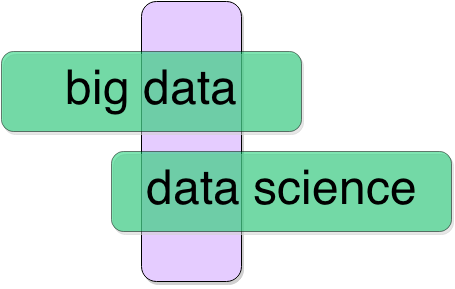
Все поисковые фразы разбиваем на токены и находим запросы с общими токенами. В реальности таких запросов может быть очень много, поэтому встает вопрос о выборе самых подходящих. Следуя здравому смыслу, можно определить два правила: чем больше токенов пересекается, тем ближе запросы, и пересечение в редких токенах весомее, чем в широкоиспользуемых. Отсюда получаем формулу:
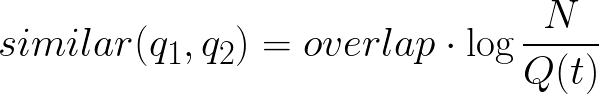
где overlap — количество общих токенов в запросах q1 и q2,
Q(t) — количество запросов с токенов t,
N — число уникальных запросов.
Следующий способ — коллаборативная фильтрация (CF). Он часто используется в рекомендательных системах и хорошо подходит для рекомендации похожих запросов. За сложным названием стоит простое предположение, что в течение одной сессии пользователь делает связанные запросы. Причём для поиска работы длинной сессией можно пренебречь, потому что предпочтения пользователя меняются медленно. Трудно представить, что соискатель, который сегодня делает запрос “персональный водитель”, завтра будет искать вакансии “java разработчика”. Но такое допущение не верно для работодателей, они могут искать кандидатов на очень разные вакансии даже в течение одного часа.
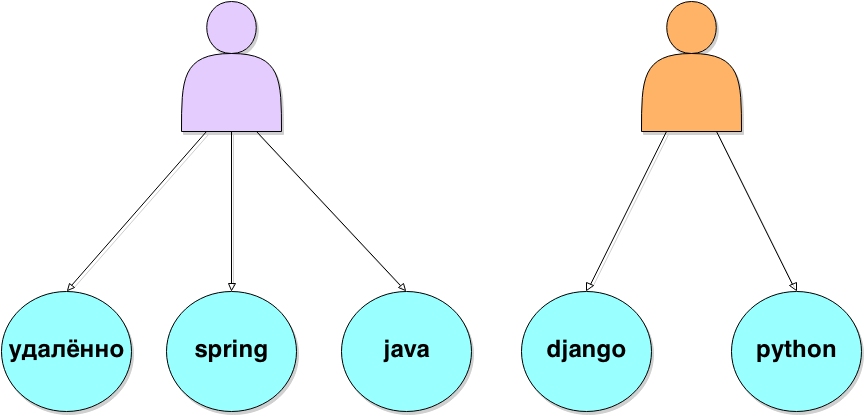
Итак, при коллаборативной фильтрации мы для каждого пользователя находим все сделанные им запросы за некий период и формируем из них пары. Чтобы выбрать самые частотные пары используем вариацию формулы tf-idf.
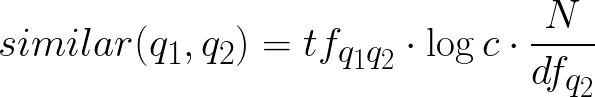
где tf — число пар запросов q1 и q2,
df — количество пар, содержащих запрос q2,
N — число уникальных запросов,
c = 0.1, это значение пока захардкодили, но его можно подобрать из поведения пользователей.
df не дает самым распространенным запросам вроде “менеджер” и “бухгалтер” появляться в рекомендациях слишком часто.
Третий алгоритм QRQ (query-result-query) похож на CF, но пары запросов мы строим не по пользователю, а по вакансии.

Т.е. похожими считаем запросы, по которым переходят на одну и ту же вакансию. Найдя все пары запросов, нам остается выбрать из них самые подходящие. Для этого нам нужно найти самые популярные пары, не забыв понизить вес у частотных запросов и вакансий. LinkedIn в своей статье предлагает следующие формулы, и они дают интересные результаты даже для редких запросов: например, для “теория вероятностей” связанные запросы — “алгоритмическая торговля” и “фьючерс”.
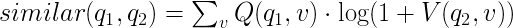


Несмотря на то что формулы выглядят сложно, за ними стоят простые вещи. V — это вклад вакансии в общий ранк: отношение числа просмотров вакансии по запросу q к общему числу просмотров этой вакансии. Аналогично, Q — вклад запроса: отношение числа просмотров вакансии по запросу q к количеству просмотров других вакансий по этому запросу.
Нужно заметить, что последние два метода не симметричны, т.е.

Мы реализовали описанные выше алгоритмы с помощью hadoop и hive. Hadoop — это система для распределенного хранения “больших данных”, управления кластером и выполнения распределённых вычислений. Каждую ночь мы загружаем туда access логи сайта за прошедший день, при этом трансформируем их в удобную структуру для анализа.

Также мы используем Apache Hive, надстройку над Hadoop, позволяющую формулировать запросы к данным в виде HiveQL (SQL-like язык заросов). HiveQL не соответствует стандартам SQL, но позволяет делать join и subselect, содержит много функций для работы со строками, датами, числами и массивами. Умеет делать Group By и поддерживает разные агрегатные функции и window-функции. Позволяет писать свои map, reduce и transform функции на любом языке программирования. Например, для того чтобы получить самые популярные поисковые запросы за день, нужно выполнить такой HiveQL:
Перед тем как начинать “добычу” похожих запросов, их нужно почистить от мусора и нормализовать. Мы сделали следующее:
После такой модификации запрос “тендерный отдел начальник” превратился в “#0d26431546 начальник отдел”. Показывать пользователям такое нельзя, поэтому подобный код меняем на самую популярную форму запроса “начальник тендерного отдела”.
Затем приступаем к реализации описанных выше алгоритмов, которая заключается в применении нескольких последовательных трансформаций исходных логов. Все трансформации написаны на HiveQL, что, возможно, не очень оптимально с точки зрения производительности, зато просто, наглядно и занимает несколько строк кода. На рисунке показаны преобразования данных для коллаборативной фильтрации. QRQ реализуется аналогично.
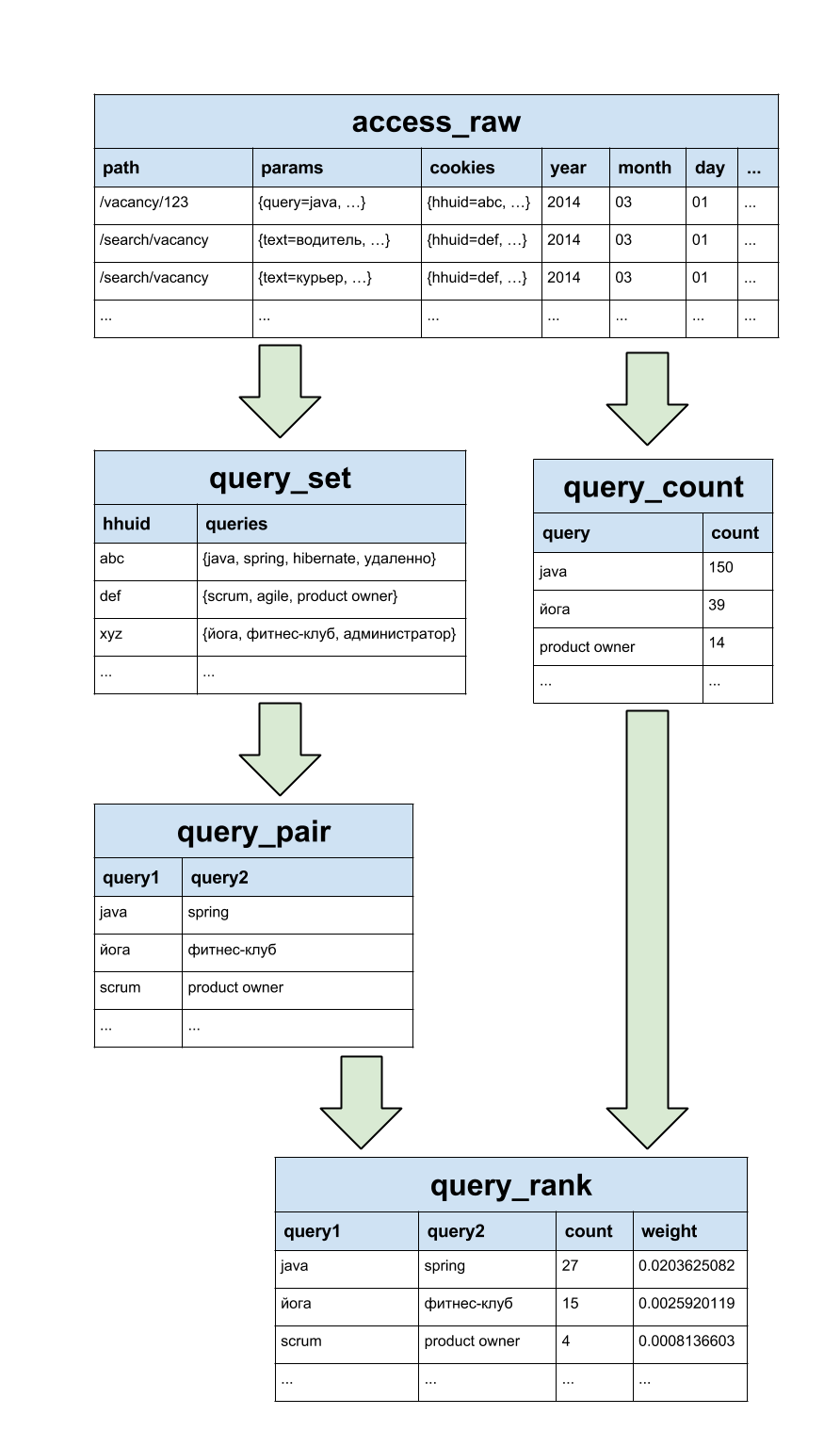
Чтобы не рекомендовать “мусорные” запросы, мы каждый запрос прогнали через поиск вакансий на hh.ru и выкинули все, для которых находится менее 5 результатов.
Последний этап задачи — это объединение результатов трех алгоритмов. Мы рассматривали два варианта: показывать пользователям по три топ-запроса из каждого метода или попытаться просуммировать веса. Мы выбрали второй способ, нормализовав перед суммированием веса:

И все вроде получилось неплохо, но для некоторых запросов вылезли странные результаты: “начинающий специалист” -> “начальник карьера”. Во-первых, тут нас подвел стемминг, который “карьер” и “карьеру” приводит к одной форме. А во-вторых, оказалось, что у трех найденных весов разное распределение и просто так суммировать их нельзя.

Пришлось привести их к одному масштабу. Для этого отсортировали каждый вес по возрастанию, пронумеровали и полученный порядковый номер поделили на общее количество пар запросов для определенного алгоритма. Это число и стало новым весом, проблема с “начальником карьера” исчезла.
Для нахождения похожих поисковых запросов мы использовали логи hh.ru за 4 месяца, а это — 270 миллионов поисков и 1.2 миллиарда просмотров вакансий. Всего пользователями было сделано около 1.5 миллионов уникальных текстовых запроса, после чистки и нормализации мы оставили чуть более 70 тысяч.
Уже за первый день работы этой фичи исправлением запросов воспользовалось около 50 тысяч человек. Самые популярные исправления:
водитель -> персональный водитель
администратор -> администратор салона красоты
водитель -> водитель с личным автомобилем
бухгалтер -> бухгалтер на первичную документацию
бухгалтер -> заместитель главного бухгалтера
Исправления популярных запросов в it-сфере:
Интересно было посмотреть, в каких профессиональных областях эта фича наиболее востребована:
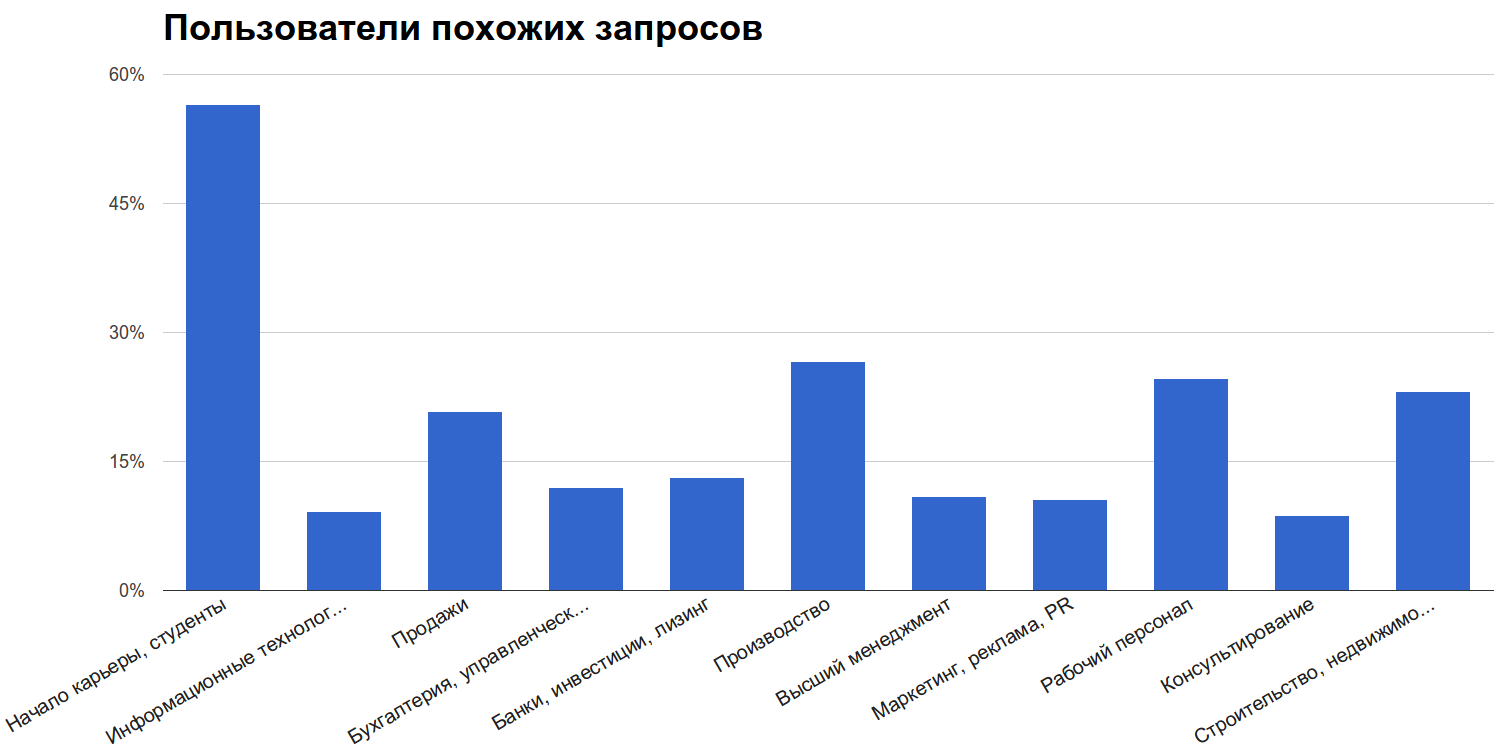
Видно, что больше половины студентов, которые искали вакансии, пробовали другие запросы. Менее всего функция популярна в IT и Консультировании.
Что еще хотелось бы сделать:
Metaphor: A System for Related Search Recommendations
Apache Hadoop
Apache Hive
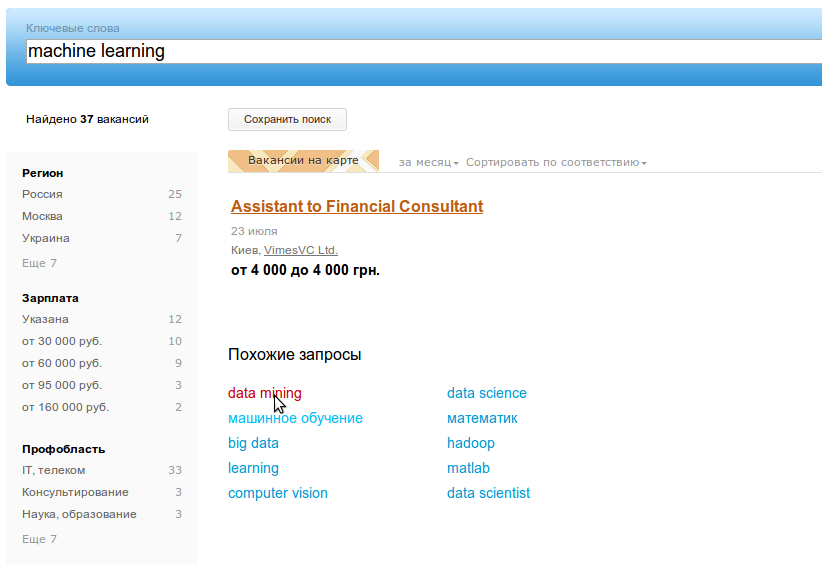
В этой статье я расскажу о том, как мы добывали похожие поисковые запросы из логов сайта hh.ru.
Для начала несколько слов о том, что такое “похожие запросы” (related searches) и зачем они нужны.
- Во-первых, не все люди, ищущие работу, точно представляют, что они хотят найти. Часто они просто исследуют предложения в нескольких сферах деятельности, вводя разные запросы. Это поведение особенно ярко проявляется у студентов, начинающих свою карьеру, и у соискателей без определенной специальности. Для такого серфинга будут полезны подсказки правильных запросов.
- Часто соискатели вводят слишком общий запрос, например, “менеджер в Москве”, по которому находится более 18 000 вакансий. Из них сложно выбрать что-то подходящее, поэтому запрос нужно сузить, например до “менеджер по продажам строительных материалов”.
- Слишком узкие запросы, наоборот, могут приводить к пустой выдаче. Например, по запросу “стажер бухгалтер по расчету заработной платы” ничего не находится, но если его исправить на более общий “бухгалтер стажер”, то появляется несколько результатов.
- Иногда соискатели и работодатели разговаривают на разных языках. Например вакансия называется “водитель автобетоносмесителя”, а соискатель ищет “водитель миксера”. Обычно мы эту проблему пытаемся решать с помощью синонимов, но не всегда это удается. Похожие запросы должны помочь пользователю сформулировать поиск на языке работодателей.
- Самый интересный случай, на мой взгляд, когда соискатель знает, что хочет найти, и четко формулирует свой запрос. Но он может не догадываться о существующей рядом сфере деятельности, которая могла бы его заинтересовать. Например, “почвовед” захочет заняться “экологией”. Эту задачу обычно решают персональными рекомендациями, но и похожие запросы могут натолкнуть такого специалиста на интересные вакансии, “сдвинуть” его в другую область поиска работы.
Мы давно думали об этой фиче, но окончательный толчок дала прекрасная статья от LinkedIn про их реализацию похожих запросов — metaphor. В ней описаны три метода извлечения таких запросов из поисковой активности пользователей, которые мы и реализовали.
Способы определения похожих запросов
Самый простой и очевидный из алгоритмов извлечения связанных запросов — это overlap или поиск пересекающихся запросов.

Все поисковые фразы разбиваем на токены и находим запросы с общими токенами. В реальности таких запросов может быть очень много, поэтому встает вопрос о выборе самых подходящих. Следуя здравому смыслу, можно определить два правила: чем больше токенов пересекается, тем ближе запросы, и пересечение в редких токенах весомее, чем в широкоиспользуемых. Отсюда получаем формулу:

где overlap — количество общих токенов в запросах q1 и q2,
Q(t) — количество запросов с токенов t,
N — число уникальных запросов.
Следующий способ — коллаборативная фильтрация (CF). Он часто используется в рекомендательных системах и хорошо подходит для рекомендации похожих запросов. За сложным названием стоит простое предположение, что в течение одной сессии пользователь делает связанные запросы. Причём для поиска работы длинной сессией можно пренебречь, потому что предпочтения пользователя меняются медленно. Трудно представить, что соискатель, который сегодня делает запрос “персональный водитель”, завтра будет искать вакансии “java разработчика”. Но такое допущение не верно для работодателей, они могут искать кандидатов на очень разные вакансии даже в течение одного часа.

Итак, при коллаборативной фильтрации мы для каждого пользователя находим все сделанные им запросы за некий период и формируем из них пары. Чтобы выбрать самые частотные пары используем вариацию формулы tf-idf.

где tf — число пар запросов q1 и q2,
df — количество пар, содержащих запрос q2,
N — число уникальных запросов,
c = 0.1, это значение пока захардкодили, но его можно подобрать из поведения пользователей.
df не дает самым распространенным запросам вроде “менеджер” и “бухгалтер” появляться в рекомендациях слишком часто.
Третий алгоритм QRQ (query-result-query) похож на CF, но пары запросов мы строим не по пользователю, а по вакансии.

Т.е. похожими считаем запросы, по которым переходят на одну и ту же вакансию. Найдя все пары запросов, нам остается выбрать из них самые подходящие. Для этого нам нужно найти самые популярные пары, не забыв понизить вес у частотных запросов и вакансий. LinkedIn в своей статье предлагает следующие формулы, и они дают интересные результаты даже для редких запросов: например, для “теория вероятностей” связанные запросы — “алгоритмическая торговля” и “фьючерс”.



Несмотря на то что формулы выглядят сложно, за ними стоят простые вещи. V — это вклад вакансии в общий ранк: отношение числа просмотров вакансии по запросу q к общему числу просмотров этой вакансии. Аналогично, Q — вклад запроса: отношение числа просмотров вакансии по запросу q к количеству просмотров других вакансий по этому запросу.
Нужно заметить, что последние два метода не симметричны, т.е.
Реализация
Мы реализовали описанные выше алгоритмы с помощью hadoop и hive. Hadoop — это система для распределенного хранения “больших данных”, управления кластером и выполнения распределённых вычислений. Каждую ночь мы загружаем туда access логи сайта за прошедший день, при этом трансформируем их в удобную структуру для анализа.

Также мы используем Apache Hive, надстройку над Hadoop, позволяющую формулировать запросы к данным в виде HiveQL (SQL-like язык заросов). HiveQL не соответствует стандартам SQL, но позволяет делать join и subselect, содержит много функций для работы со строками, датами, числами и массивами. Умеет делать Group By и поддерживает разные агрегатные функции и window-функции. Позволяет писать свои map, reduce и transform функции на любом языке программирования. Например, для того чтобы получить самые популярные поисковые запросы за день, нужно выполнить такой HiveQL:
SELECT lower(query_all_values['text']), count(*) c
FROM access_raw
WHERE
year=2014 AND month=7 AND day=16
AND path='/search/vacancy' AND query_all_values['text'] IS NOT NULL
GROUP BY lower(query_all_values['text'])
ORDER BY c DESC LiMIT 10;
Перед тем как начинать “добычу” похожих запросов, их нужно почистить от мусора и нормализовать. Мы сделали следующее:
- выкинули длинные запросы (более 5 слов и 100 символов),
- удалили мусорные символы и слова грамматики запросов,
- применили стемминг,
- объединили синонимы,
- отсортировали слова.
После такой модификации запрос “тендерный отдел начальник” превратился в “#0d26431546 начальник отдел”. Показывать пользователям такое нельзя, поэтому подобный код меняем на самую популярную форму запроса “начальник тендерного отдела”.
Затем приступаем к реализации описанных выше алгоритмов, которая заключается в применении нескольких последовательных трансформаций исходных логов. Все трансформации написаны на HiveQL, что, возможно, не очень оптимально с точки зрения производительности, зато просто, наглядно и занимает несколько строк кода. На рисунке показаны преобразования данных для коллаборативной фильтрации. QRQ реализуется аналогично.

Чтобы не рекомендовать “мусорные” запросы, мы каждый запрос прогнали через поиск вакансий на hh.ru и выкинули все, для которых находится менее 5 результатов.
Последний этап задачи — это объединение результатов трех алгоритмов. Мы рассматривали два варианта: показывать пользователям по три топ-запроса из каждого метода или попытаться просуммировать веса. Мы выбрали второй способ, нормализовав перед суммированием веса:

И все вроде получилось неплохо, но для некоторых запросов вылезли странные результаты: “начинающий специалист” -> “начальник карьера”. Во-первых, тут нас подвел стемминг, который “карьер” и “карьеру” приводит к одной форме. А во-вторых, оказалось, что у трех найденных весов разное распределение и просто так суммировать их нельзя.

Пришлось привести их к одному масштабу. Для этого отсортировали каждый вес по возрастанию, пронумеровали и полученный порядковый номер поделили на общее количество пар запросов для определенного алгоритма. Это число и стало новым весом, проблема с “начальником карьера” исчезла.
Результаты
Для нахождения похожих поисковых запросов мы использовали логи hh.ru за 4 месяца, а это — 270 миллионов поисков и 1.2 миллиарда просмотров вакансий. Всего пользователями было сделано около 1.5 миллионов уникальных текстовых запроса, после чистки и нормализации мы оставили чуть более 70 тысяч.
Уже за первый день работы этой фичи исправлением запросов воспользовалось около 50 тысяч человек. Самые популярные исправления:
водитель -> персональный водитель
администратор -> администратор салона красоты
водитель -> водитель с личным автомобилем
бухгалтер -> бухгалтер на первичную документацию
бухгалтер -> заместитель главного бухгалтера
Исправления популярных запросов в it-сфере:
| системный администратор | помощник системного администратора, helpdesk, системный администратор windows |
| программист | программист с++, удаленный программист, программист c# |
| технический директор | директор по эксплуатации, заместитель технического директора, технический руководитель |
| тестировщик | специалист по тестированию, тестировщик игр, тестировщик удаленно |
| junior | java junior, junior c++, junior qa |
Интересно было посмотреть, в каких профессиональных областях эта фича наиболее востребована:

Видно, что больше половины студентов, которые искали вакансии, пробовали другие запросы. Менее всего функция популярна в IT и Консультировании.
TODO
Что еще хотелось бы сделать:
- Aвтоматизировать. Cейчас связанные запросы построены один раз за период с 1 января по 1 мая 2014 года. При автоматизации нужно не забыть про защиту от уязвимостей, потому что, зная алгоритмы, вместо связанных запросов легко создать рекламные или просто хулиганские.
- Поэкспериментировать с весами алгоритмов и провести AB-тестирование, чтобы показывать самые полезные запросы.
- Учитывать число результатов по запросу: подсказывать только те запросы, по которым гарантированно есть результаты. Еще при большом числе найденных вакансий будет полезно показывать сужающие запросы, а при малом — расширяющие.
- Похожие запросы в поиске резюме.
- Использовать в suggest.
Ссылки
Metaphor: A System for Related Search Recommendations
Apache Hadoop
Apache Hive
