В этом посте мы расскажем, как реализовывали плагин для поддержки функционального языка Frege в IntelliJ IDEA. Если вам интересно, как IDE от JetBrains работают внутри, или вы хотите поконтрибьютить в языковые плагины (а может даже написать свой!), эта статья для вас. Мы пройдемся по этапам создания языкового плагина для IDEA, расскажем, с какими трудностями столкнулись, и как подружили этот язык с JVM-миром.

У нас получился очень большой пост, поэтому мы решили разбить его на две части. В первой расскажем, как вообще пишутся языковые плагины для IDEA, как мы реализовывали лексер, парсер, подсветку кода и навигацию.
Во второй части поделимся, как сделали автодополнения, систему сборки, интерпретатор и систему типов. И как все это тестировали. Вторую часть выпустим через неделю.
План
Кто мы
Над этим проектом работали Петр Сурков, Кирилл Карнаухов и Юрий Худяков, почти третьекурсники программы «Прикладная математика и информатика» в Питерской Вышке. Идея разработать плагин возникла у нас в середине второго курса, когда нужно было выбирать семестровый проект по Java.
В самом начале хотим сказать спасибо Семёну Атамасю за менторство и Dierk König — одному из создателей языка Frege — за поддержку нашей идеи.
Что такое Frege и зачем ему наш плагин?
Наверняка вы слышали о Scala — функциональном языке, особенностью которого является совместимость с другими JVM-языками. Но есть и другой функциональный JVM-язык — Frege. Он очень похож на Haskell, но компилируется в JVM-байткод. Ниже представлен пример кода на Frege. Тот же Haskell, не так ли?

Однако благодаря совместимости с Java, в нем больше ключевых слов и конструкций, позволяющих импортировать классы и методы из Java, инлайнить Java-код и, наоборот, звать Frege-методы из Java. Например, здесь можно видеть, как импортируется List:

К сожалению, удобных вариантов для разработки на Frege сейчас нет. Можно пользоваться текстовыми редакторами, но ничего кроме подсветки синтаксиса (скорее всего еще и от Haskell) у вас не будет, компилятор придется скачивать самим, запускать в несколько этапов через консоль. Есть плагин для Eclipse от создателей языка, но в нем отсутствуют довольно примитивные функции. Например, если вы ошиблись в одном месте программы, то дальше этого места она анализироваться не будет. Для IDEA тоже существует плагин, но он даже не умеет разбирать грамматику языка. При этом в JetBrains Plugin Ideas поддержка Frege находилась на первом месте по количеству запросов. Сейчас в списке его нет, потому что появился наш плагин, но issue все еще можно посмотреть.
Как пишутся языковые плагины для IntelliJ IDEA
Существует документация, в которой кратко описывается создание плагинов для IDEA. В ней можно найти туториал, который бегло рассказывает, как написать собственный языковой плагин. К сожалению, там нет многих подробностей, и практически всю информацию нужно брать из гугла, исходников IDEA и других плагинов.
Основная идея разработки любого плагина в IDEA — использование точек расширения, позволяющих добавлять функциональность. Разработчик плагина в xml-файле указывает, какие точки он реализовал, и перечисляет классы, отвечающие за реализацию.
Теперь давайте немного разберемся в основных шагах, которые требуются для поддержки нового языка в IDEA, а позже уже под соответствующими подзаголовками углубимся в них. Для начала необходимо зарегистрировать расширение языка (если быть точнее, здесь мы регистрируем тип файла, а всю информацию расписываем в соответствующем классе). Тогда все файлы с указанным вами расширением будут автоматически включать поддержку вашего плагина. Также IDEA будет предлагать установить ваш плагин пользователям, которые открыли файл с поддержанным вами расширением.
По сути это минимальные действия, необходимые для поддержки языка. Но как можно говорить о поддержке без парсера? Конечно, следующим шагом должна быть возможность распарсить ваш язык и построить с его помощью PSI-дерево. Program Structure Interface — это в какой-то степени аналог привычного всем Abstract Syntax Tree — хранит в себе огромное количество информации (детей, родителя, текущий проект, язык и другую метаинформацию) и очень удобен в использовании.
Стоит отметить, что для реализации парсера также необходим и лексер, который сильно упрощает дальнейшую работу. На основе того же лексера основана базовая часть подсветки, и по сути это уже неплохая поддержка языка. Все, что остается дальше, — добавлять новые фичи, например, навигацию и автодополнение. Большая часть фичей использует построенное PSI-дерево, и очень важно построить его правильно, учитывая всю грамматику языка.
Теперь давайте узнаем подробнее, как реализовать все эти интересные вещи.
Лексер
Простейший лексер при помощи JFlex
Первое, что делает языковой плагин с введенным пользователем кодом — разбивает его на так называемые токены, для этого и используется лексер. Классический способ написание лексера для плагина — использование JFlex.

Конечно, задавать можно и более сложные правила: добавлять состояния в лексер (например, состояние “нахождение внутри многострочного комментария”) или определять токен в зависимости от следующих за ним символов (это называется look-ahead). Полную версию нашего лексера вы можете найти в FregeLexer.flex. При сборке плагина мы сначала с помощью JFlex генерируем Java-код, а затем уже начинаем сборку. Посмотреть, как это настроено, можно в build.gradle.
Под спойлером вы можете прочитать об одной из проблем, с которой мы столкнулись, работая с лексером.
Многозначность точек в Frege
В Frege точка имеет множество смыслов:
Точка как оператор композиции
f . gТочка в range списков
[1..10]Точками можно заканчивать float
x = 1.Точками задаются полные имена
Data.TreeMapТочками задаются primary выражения
people.[42].ageОператоры с точкой в начале
.|.
Несложно придумать такой ввод, что его можно будет распознать минимум двумя способами. Поэтому чтобы избежать неоднозначности грамматики, создатели языка сделали специальные правила, которые определяют, когда чем точка может являться.
Эти правила завязаны на пробелах, а потому их необходимо поддерживать в лексере, ведь для парсера (о котором мы поговорим дальше) токена “пробел” просто нет. Это создало бы многие другие проблемы: пробел можно вставлять практически куда угодно, и грамматика парсера усложнилась бы в разы.
Для поддержки точек по большей части используются look-ahead как здесь и отдельные состояния.
Layout rule
Во Frege существует так называемое Layout rule, которое лексер, представленный выше, никак не поддерживает. С чем-то похожим вы наверняка знакомы благодаря Python. В Frege вы можете писать так:
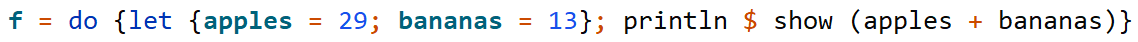
Но можно писать и так:

Эти стили можно комбинировать по-разному. Всего есть семь правил, которые задают Layout rule, при этом поддерживать их нужно в лексере (по тем же причинам, что описаны выше в спойлере про многозначность точек).

Для поддержки придумаем три “виртуальных” токена, заменяющих скобки и точку с запятой. А затем напишем обертку над лексером, которая согласно правилам будет расставлять эти самые виртуальные токены:

Виртуальные токены создают множество проблем, о главной из которых мы написали в спойлере ниже. Мы специально вынесли этот раздел в спойлер, так как он сложный и не влияет на понимание остальной статьи, так что можете смело его пропускать.
Layout rule: проблемы с производительностью
Рассмотрим фрагмент уже показанного выше кода.

Допустим, что лексер только что обработал число 29. Проблема в том, что мы не знаем, что закончилось — выражение или вся секция, — иначе говоря, вставлять END_DECL или END_SECTION. И главное, что мы должны вставить виртуальный токен именно после 29, а не когда дойдем до bananas в следующей строчке, ведь между выражениями может быть сколько угодно как однострочных, так и многострочных комментариев. Тогда все они попадут в текст первого выражения, что создаст кучу проблем для рефакторинга, поиска использований и т.д.
Таким образом, мы понимаем, что вставлять — END_DECL или END_SECTION — только когда ушли лексером уже куда-то вперед. А значит, виртуальные токены надо вставлять как бы “назад” — в уже обработанную часть. Но раз токены появляются где-то сзади во время обработки, мы не можем лексить не только с произвольного места, но и лениво — весь файл токен за токеном, — когда потребуется очередной.
Это создает серьезные проблемы производительности: вся дальнейшая работа с кодом файла будет ожидать завершения этапа лексинга вместо того, чтобы параллельно лексить, парсить, разрешать ссылки и так далее.
К счастью, эта проблема решаема: мы разбили программу на блоки специальным образом так, что не можем лениво лексить токены внутри блока, но можем делать это с самими блоками, один за другим. При этом размер блоков будет достаточно мал, так что мы практически получили ленивый лексинг. Реализацию этого подхода можно посмотреть тут.
Парсер
В результате работы лексера мы получили представление нашего кода в виде токенов, они отправляются в парсер. Стандартный способ написания парсера в языковом плагине — использование библиотеки Grammar-Kit. Она позволяет описывать грамматику в форме Бэкуса-Наура.
Научимся парсить простейшие декларации нового типа данных в языке Frege. Выглядеть они могут так:

После чего можно будет писать IP “192.168.0.1”, создавая тем самым объект типа данных IPAddress. Также можно делать параметризованные типы данных.

Чтобы запарсить их с помощью Grammar-Kit, мы используем следующее правило:

Давайте его разберем. Сначала идет название правила, за ним следует ::=, после которого мы записываем что это правило из себя представляет. А именно:
ABSTRACT?— токен ключевого слова abstract, оно не является обязательным при объявлении нового типа, а потому после него ставится вопрос.NEWTYPE— токен ключевого слова newtype, оно уже является обязательным при задании нового типа через конструкцию newtype.conidUsage— это другое правило нашего парсера. Если упрощать, ему соответствуют любые слова, начинающиеся с большой буквы. Оно будет означать имя нового типа данных.typedVarid— еще одно правило из нашего же парсера. Упрощенно ему соответствуют любые слова с маленькой буквы. Обратите внимание, что после него стоит звездочка, это значит, что это правило может быть применено сколько угодно раз (в том числе можно и 0 раз). Это параметризации конструктора.EQUAL— это токен, соответствующий знаку равно.construct— это наше правило, которое описывает, как может выглядеть конструктор в языке Frege. В простейшем случае это название конструктора — слово с большой буквы, а затем его аргументы — слова с маленькой буквы.whereSectionснова отсылает нас к другому правилу в парсере. Его разбирать не будем, заметим лишь, что так как после него идет вопрос, то обязательным оно не является.
Под правилами в фигурных скобках указывается дополнительная информация для Grammar-Kit.
Свойство pin=2 означает, что как только мы успешно запарсим второе правило из определения newtypeDecl, Grammar-Kit сразу начнет ждать только текущее объявление, а не думать, что, возможно, сейчас идет какое-то другое выражение (например, у двух правил может быть общий префикс). В нашем случае pin стоит на NEWTYPE, и как только встретится это ключевое слово, парсер будет ожидать только продолжения newtypeDecl. Нужно это не только в целях оптимизации, но и для восстановления ошибок: если пользователь плагина ошибся в синтаксисе newtype-выражения или еще просто не успел его дописать, мы хотим, чтобы парсер понял, что здесь идет newtype-выражение, показал в нем ошибку и продолжил парсить дальнейший код, а не сломался бы при первой же ошибке.
Следующее свойство — implements. Дело в том, что по описанной грамматике Grammar-Kit во время компиляции производит кодогенерацию парсера на Java, представляя каждое правило в виде отдельного класса. Implements позволяет указать, какие интерфейсы должен реализовывать сгенерированный класс. Где же реализовывать методы из интерфейсов? Для этого есть свойство mixin, от указанного в нем класса наследуется сгенерированный Grammar-Kit’ом класс для правила. И наконец, stubClass позволяет формировать сжатое представление информации, которой соответствует это правило, — о них мы еще расскажем позже.
Нашу грамматику вы можете посмотреть в Frege.bnf. На ее основе IDEA генерирует так называемое PSI-дерево. Оно многим похоже на AST-дерево, но имеет дополнительные возможности, например, методы по манипулированию языковыми конструкциями. В нашем случае дерево выглядит так:

Подсветка кода
Подсветка кода в большинстве своем устроена на информации из лексера: некоторым лексемам сопоставляются конкретные цвета, настраиваются они так. Но иногда хочется делать более умную раскраску. Например, пользователям было бы удобно видеть выделенными названия функций в их декларациях. Но как лексер поймет, что идентификатор является названием функции, а не ее использованием? Никак, это становится понятно только на этапе парсинга. Поэтому в IDEA существует Annotator: специальный обработчик, который гуляет по дереву и спрашивает, не хотим ли мы выделить тот или иной элемент. С помощью него и раскрашиваются нетривиальные конструкции языка. Ниже можно видеть пример раскраски кода нашим плагином:


Мы предоставляем две стандартные темы, также вы можете настроить свою собственную:

Навигация
Теперь поговорим о навигации. Это одна из самых тяжелых частей, ведь нужно учесть все способы объявления функций, классов, инстансов, задать типы данных и т.д. Сначала определим, что такое навигация. По сути, это нахождение места определения того или иного объекта. Для каждого объекта, к которому имеет смысл применять навигацию, можно ввести понятие “ссылка” — указатель на место определения объекта. Поэтому нахождение места определения также называется разрешением ссылок. Посмотрим, как оно работает изнутри, и что для этого вообще нужно.
Навигация внутри одного файла
Начнем с простого примера. У нас есть слово с маленькой буквы внутри определения функции — чем оно может быть? Это точно не тип, потому что Frege, как и Haskell, запрещает типы с маленькой буквы. Значит, это либо функция, либо ее параметр. Но где этот объект мог быть определен? Во-первых, в глобальной области определения модуля:

Во-вторых, в let-выражении:

В-третьих, совсем в другой области определения:

И таких примеров можно привести еще очень много, ведь бывают и другие синтаксические конструкции.
Для навигации внутри одного файла была продумана и реализована система скоупов. В итоге разрешение ссылок для функций состоит из шагов вида:
Найти ближайший сверху скоуп.
Поискать внутри него объявление функции.
Если нашлась функция с таким же именем, то добавить в результат, иначе перейти к шагу 1.
Было необходимо продумать и расставить скоупы так, чтобы навигация, с одной стороны, находила все определения, а с другой, не находила лишних деклараций, которые на самом деле не являются определением нужной нам функции. Удачным решением было сделать декларацию функции скоупом, потому что под ней может быть where-expression, содержащее определения:

Это позволило никак дополнительно не проверять при навигации наличие where-блока.
Мы разобрали только навигацию к функциям, но в языке есть еще множество других объектов, к определениям которых хочется уметь обращаться. Например, для параметров функций разрешение ссылок выглядит как:
Подняться до ближайшего элемента, который умеет хранить параметры (например, объявление функции или лямбды).
Проверить наличие искомого параметра.
Если не нашлось, перейти к шагу 1.

Для удобства во время разработки мы создали много интерфейсов-меток (например, вышеупомянутые элементы, которые умеют хранить параметры). Также при навигации активно используется PSI-дерево, построенное парсером, и по сути, вся навигация внутри одного файла устроена на правильном хождении по дереву. Поэтому в целях оптимизации необходимо строить такую грамматику языка, чтобы итоговое PSI-дерево не разрасталось вглубь.
Навигация между файлами и индексация
А теперь давайте подумаем, что делать, если искомый элемент находится в другом файле. Простейшая идея — просто пройтись по всем файлам проекта и подключенным библиотекам и поискать нужное нам определение. Однако работать это будет очень долго, а пользователю придется ждать по несколько секунд для rename рефакторинга, поиска использований и т.д.
Поэтому в IntelliJ Platform существуют так называемые stub’ы. Если кратко, то один stub сжато, в бинарном формате, хранит основную информацию об одном элементе из дерева. Например, в нашем плагине stub’ы для классов хранят полные и сокращенные имена, для методов — имена, а stub’ы для модулей также дополнительно запоминают список импортов (специфика языка, о ней будет немного позже). Также для stub’ов существуют специальные индексы, которые позволяют по ключу класть и доставать оттуда stub’ы — что-то вроде Map, но с автоматическим хранением на диске. Ключом может быть, например, полное имя класса, но в целях оптимизации мы решили использовать hashCode имени.
Stub’ы сами по себе образуют другое дерево, параллельно живущее с PSI-деревом. Оно удобно, например, в следующем случае: у нас есть stub для метода и мы хотим узнать класс, хранящий его. Тогда для этого достаточно посмотреть на родителя этого stub’а и получим stub класса.
Вообще, имеет смысл хранить stub’ы только для элементов, которые доступны нам из других файлов. Основное преимущество их в том, что IDEA единожды парсит файлы, строит из указанных нами элементов stub’ы (для каждого вида stub’а нужно написать, как именно его строить) и кладет их в специальные индексы.
Теперь чтобы получить доступ к элементу, нам не нужно просить IDEA снова перепарсить весь файл, ведь основную информацию она может забрать именно из stub’ов. Когда вы видите в IDE ползунок с надписью “Indexing”, то одна из задач, которая происходит, — как раз построение stub’ов.
Вернемся к навигации. Как же узнать, в каком из модулей, допустим, находится определение функции с конкретным названием? Как уже говорилась, IDEA кладет построенные stub’ы в указанные нами индексы, которые по ключу умеют доставать сами stub’ы. На этой простой идее, по сути, и основана вся навигация между файлами. Конечно, у этого решения есть много подводных камней, но мы не будем вдаваться в подробности.
Проблема импортов во Frege
Ранее мы уже упоминали, что решили для каждого модуля хранить список импортов, которые в нем написаны. Конечно, сначала это может показаться странным. Дело в том, что импорты во Frege значительно отличаются от Java или Kotlin. Пример: пусть у нас есть три модуля A, B и C. Во Frege есть такое понятие, как публичный импорт, и если модуль A заимпортит B, а B публично заимпортит C, то модулю A будут доступны определения из C. И это работает на цепочке public-импортов любой длины.
В первую очередь при навигации между файлами нужно смотреть на то, какие импорты доступны из текущего модуля. Таким образом, если бы мы не запоминали список импортов, нам бы пришлось каждый раз при навигации просить IDEA перепарсить все модули, доступные во время обхода по импортам.
Вообще, у импортов еще много особенностей. Например, можно импортировать не весь модуль, а только конкретные типы/функции (а можно наоборот заимпортировать все, кроме некоторых элементов, с помощью hiding), или указывать public только у конкретных импортированных элементов. Также каждому импортированному элементу можно присвоить уникальный алиас, чтобы поменять имя, по которому к нему обращаются. Публичность и алиасы можно комбинировать, и потому навигация между файлами становится достаточно сложной.
Наш плагин умеет обрабатывать множество случаев, но до алиасов руки так пока и не дошли. Однако публичность и частичные импорты работают отлично в большинстве случаев. Ниже можно видеть пример частичных импортов.

Совместимость с другими JVM-языками
Для навигации между различными JVM языками (например между Java и Kotlin) IDEA использует общие интерфейсы, реализовав которые можно поддержать навигацию с остальным JVM-зоопарком. Для функционального языка Frege было иногда довольно трудно подобрать аналогии в Java. Если вы хотите подружить свой язык с JVM-миром, то стоит посмотреть в сторону интерфейсов PsiMethod, PsiClass и т.д. Нам же удалось добиться навигации в Java как на гифке ниже:
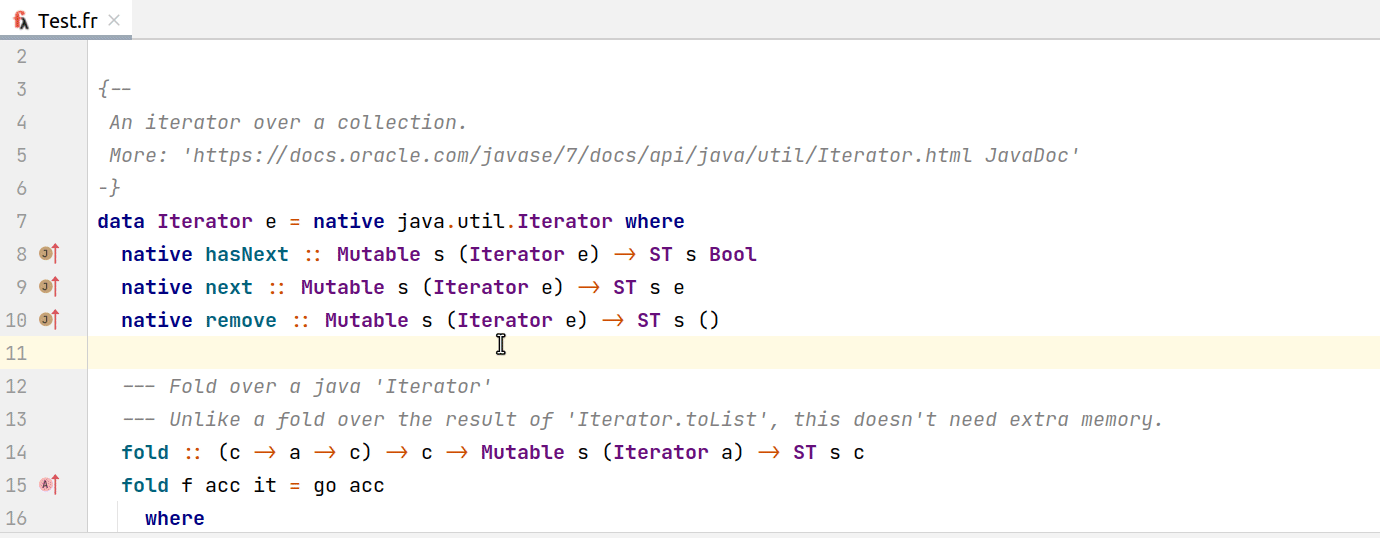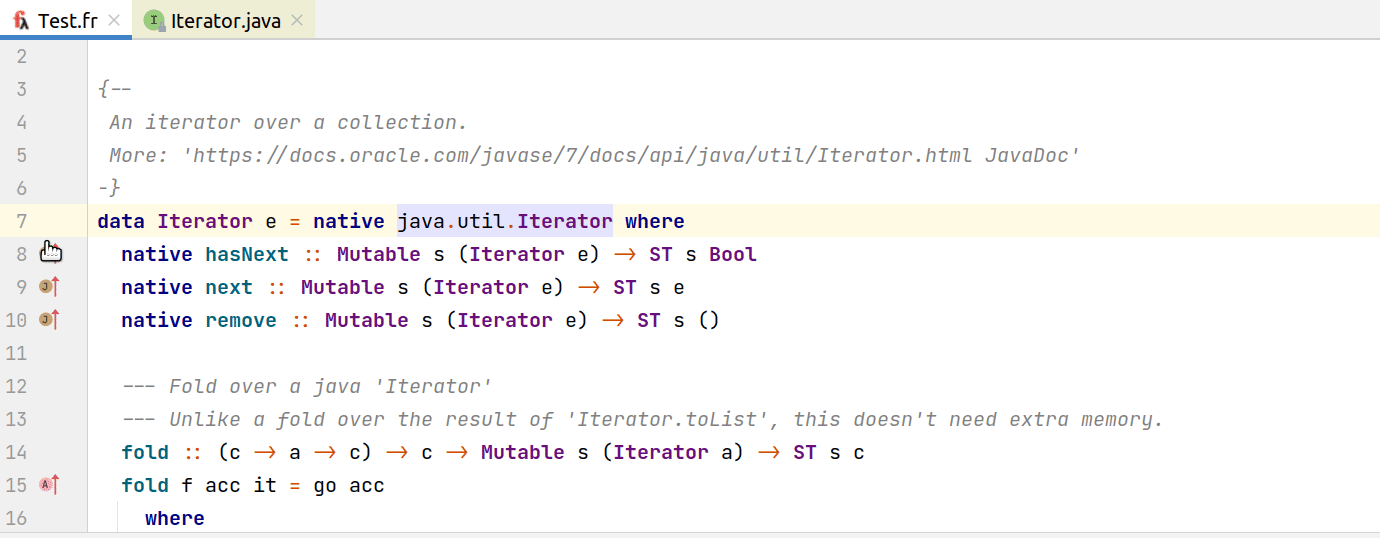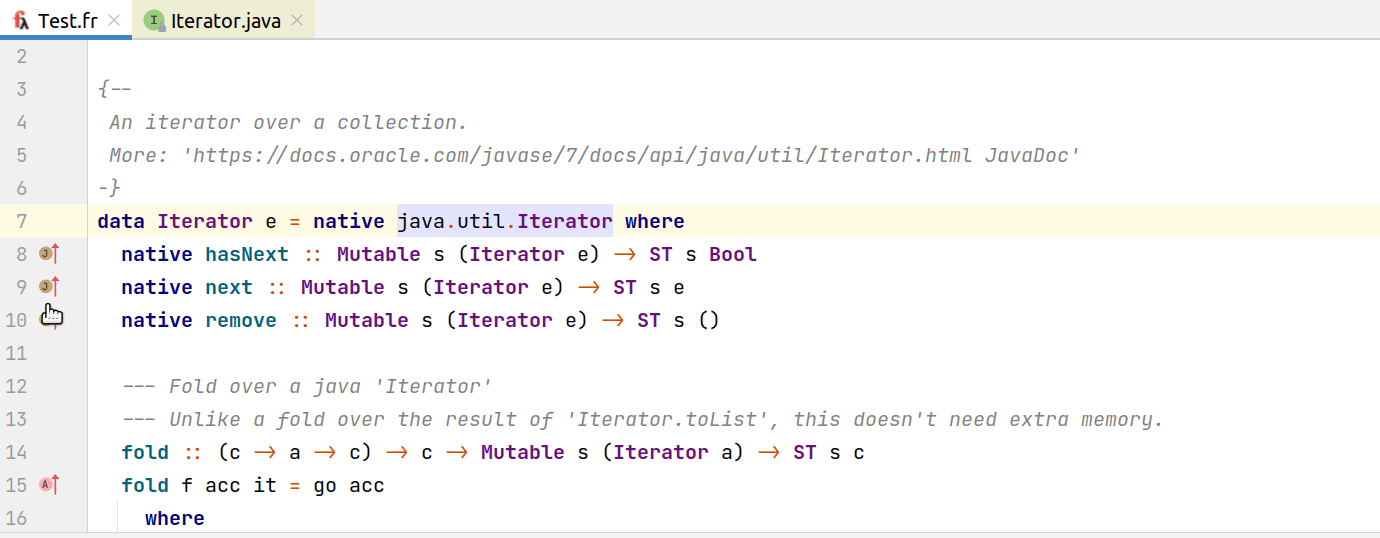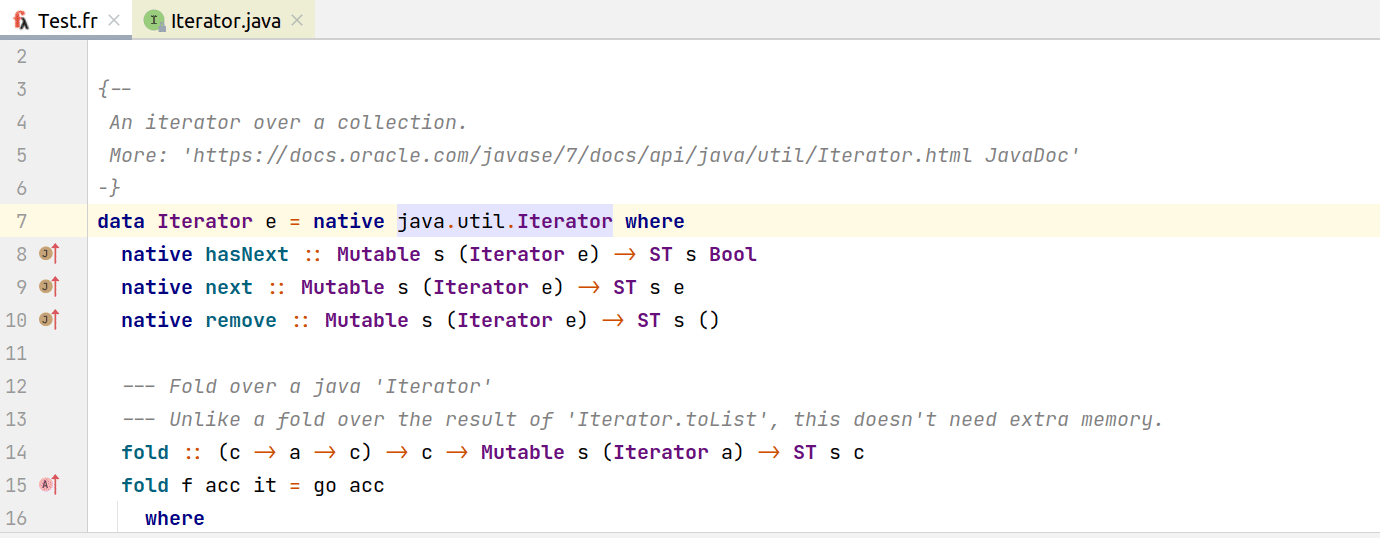
И из Java:
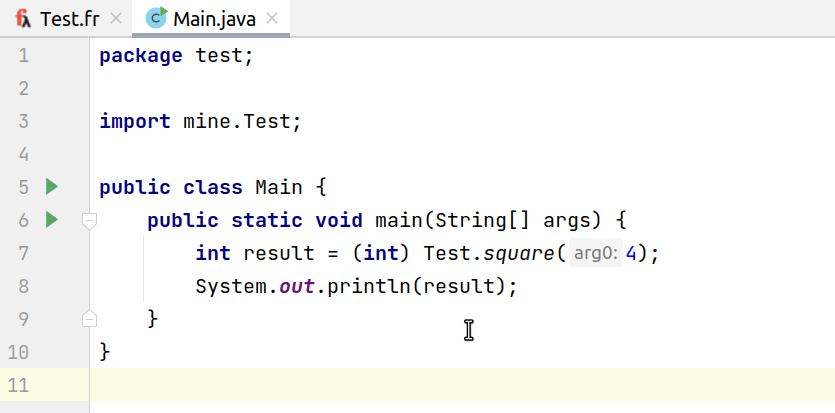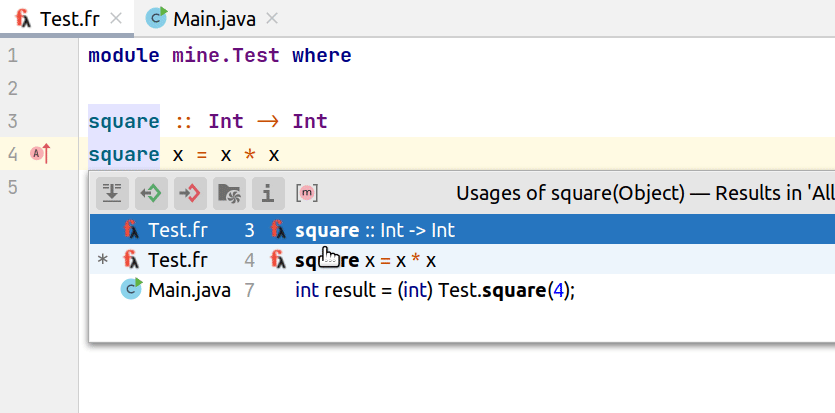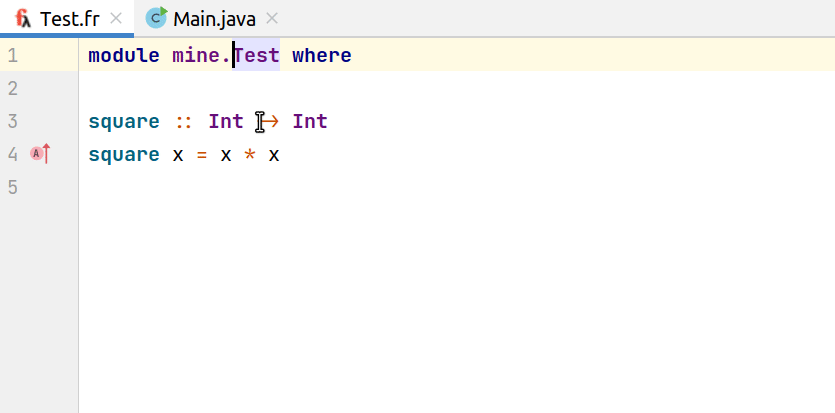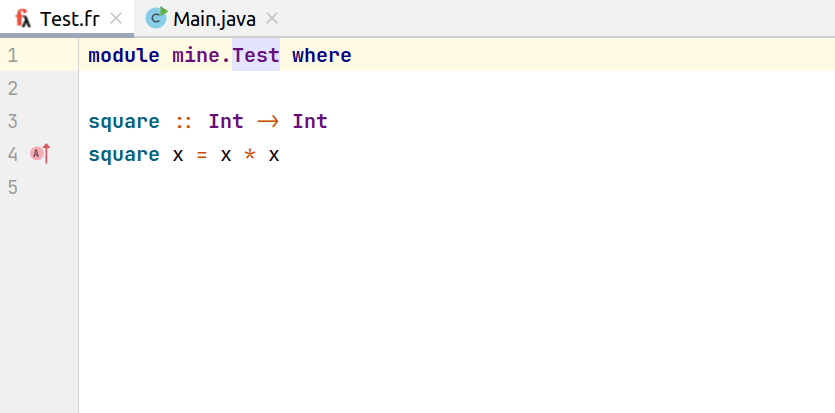
На нижней гифке видно, что в Java-коде мы кастуем к Int результат выполнения функции из Frege. Так как система типов у нас отсутствует, то для корректной работы плагина в этих случаях мы вынуждены явно задавать тип. Стоит все же отметить, что без кастов все компилируется и корректно работает.
Line markers для навигации
Все, кто пользуются IDEA, знают о значках, которые находятся рядом с номерами строк. Они позволяют навигироваться к определению функции, имплементации интерфейса и т.д. Имя им line markers. В нашем плагине они тоже есть, а именно:
навигация к методам/полям из Java;
навигация к аннотации типа;
навигация к определению функций из инстансов классов и наоборот;
запуск функции main.
Line marker из первого пункта вы могли видеть на гифках, покажем вам другие:


Find usages
Имея на руках навигацию, довольно легко реализовать find usages — поиск всех использований какого-либо элемента. Все, что нужно сделать, — это зарегистрировать FindUsagesProvider (у нас он такой). В нем нужно указать, у каких элементов целесообразно искать использования, как получить из них имена элементов и немного другой информации. Также нужно отдать специальную абстракцию scanner, который разбивает текст на свои токены, основываясь на лексере (например, может соединить некоторые лексемы вместе или пропустить некоторые из них), у нас он стандартный. А дальше IDE при поиске всех использований какого-либо элемента сканирует файлы проекта, с помощью scanner’а разбивает его на слова, смотрит на те, которые совпадают по имени с нашим элементом, от каждого из них вызывает разрешение ссылки и проверяет, что ссылка совпала с исходным элементом. Это, в общем-то, все, но подробнее можно прочитать здесь.

Ссылки: плагин, репозиторий
Другие материалы из нашего блога о проектах студентов младших курсов:
