Комментарии 31
Интересная тема.
Вот как раз недавно думал о голосовом управлении с помощью слогов. Это позволит собирать любые слова… Как дальше бы работало — все, думаю, понимают. И база небольшая — такую програмку можно при желании в телефон запихать, все только упирается в настройке и поиске совпадения (хотя бы близжайшего).
Я 100% могу сказать, что через несколько лет это появится.
Я 100% могу сказать, что через несколько лет это появится.
Подскажите, каким софтом пользовались для написания статьи? Ну кроме gnuplot. Вижу, что всё opensourse?
Повторно перечитал, очень похоже на заготовку статьи в научный журнал к диссертационной работе. Какую работу пишете, если не секрет?
На счёт графика habr.habrastorage.org/post_images/ee1/2f2/164/ee12f2164543c2359f5041deacc4a09d.jpg — смущает количество гармоник, наводит на мысль, что не очень хорошо подобран механизм БПФ и окна. Поскольку вряд ли столько кратных гармоник будет. Есть ли проверочное АЧХ, снятия вашим прибором, например звучания чистого синуса?
Даже учитывая нелинейности звуковоспроизводящего тракта и микрофона, можно провести калибровку преобразования.
На счёт графика habr.habrastorage.org/post_images/ee1/2f2/164/ee12f2164543c2359f5041deacc4a09d.jpg — смущает количество гармоник, наводит на мысль, что не очень хорошо подобран механизм БПФ и окна. Поскольку вряд ли столько кратных гармоник будет. Есть ли проверочное АЧХ, снятия вашим прибором, например звучания чистого синуса?
{kind=link}
Даже учитывая нелинейности звуковоспроизводящего тракта и микрофона, можно провести калибровку преобразования.
Здравствуйте!
Диссертационную работу сейчас к сожалению не пишу, надеюсь когда-нибудь дойти и до этого.
По-поводу заинтересовавшего Вас графика — конкретно данный график, и непосредственно за ним следующий были взяты с ресурса www.phys.unsw.edu.au/jw/glottis-vocal-tract-voice.html Я сначала забыл указать данный ресурс в первоисточниках — оплошность уже исправлена. В нашей компании нету исследовательской лаборатории с рабочим электроглатографом, а хотелось показать именно «живой», а не восстановленный сигнал. Ответить на Ваши вопросы касательно настройки измерительных приборов я к сожалению не смогу.
Диссертационную работу сейчас к сожалению не пишу, надеюсь когда-нибудь дойти и до этого.
По-поводу заинтересовавшего Вас графика — конкретно данный график, и непосредственно за ним следующий были взяты с ресурса www.phys.unsw.edu.au/jw/glottis-vocal-tract-voice.html Я сначала забыл указать данный ресурс в первоисточниках — оплошность уже исправлена. В нашей компании нету исследовательской лаборатории с рабочим электроглатографом, а хотелось показать именно «живой», а не восстановленный сигнал. Ответить на Ваши вопросы касательно настройки измерительных приборов я к сожалению не смогу.
Забыл ответить про софт. Для данной работы использовался Matlab, Audacity и OpenOffice Draw :) Опять же в Матлабе не применялось ничего такого, чего не было бы, скажем, в Octave.
Во, узнал Audacity. У него весьма хреновый БПФ. Для домашнего развлечения подойдёт, а вот для серъёзных работ имеет смысл смотреть в свёртки прямо в Matlab. Это ИМХО, и готов ошибаться.
А на счёт диссертации, редко на хабре встретишь статьи написанные таким сухим научным языком. Это не замечание или снобизм, просто отметил. В любом случае очень интересно! И диссертацию советую сделать, есть хорошее начало :)
А на счёт диссертации, редко на хабре встретишь статьи написанные таким сухим научным языком. Это не замечание или снобизм, просто отметил. В любом случае очень интересно! И диссертацию советую сделать, есть хорошее начало :)
Поясните, что понимается под «хреновым БПФ»? Особая, ухудшенная версия алгоритма, или что? Как оно может быть «хреновым»?
Проблема БПФ, что он в чистом виде выводимые данные не соответствуют действительности. Одну мы знаем из теоремы Котельникова. Другое дело, что выбор временного окна свёртки делает нам ложными некоторые гармоники. Можно кратко посмотреть тут
ru.wikipedia.org/wiki/%D0%9E%D0%BA%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A4%D1%83%D1%80%D1%8C%D0%B5
Пример ошибок преобразования. У нас есть двухмерная волновая функция чистого синуса, с одной гармоникой (в данном случае беру это, т.к. есть под рукой картинки).

Синусоида, высоты определяются градацией серого.
Если представить в виде трёхмерного объекта, то выглядит вот так:
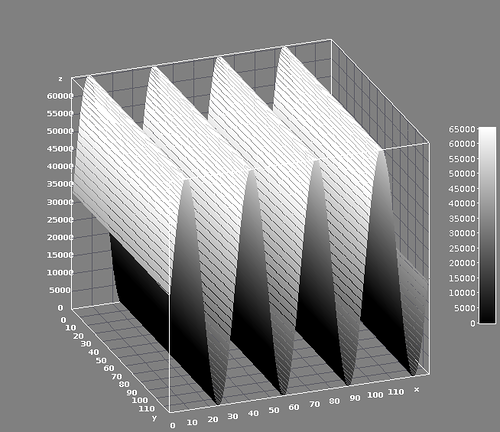
Делаем БПФ её, получаем не одну чистую гармонику, а множество гармоник:

В трёхмерном виде:

При правильном подобранном окне, когда период чётко умещается должны были получить вот такую картину:

Трёхмерной картинки нет, но должны были получиться ровные столбцы.
Надеюсь ответил на ваш вопрос.
ru.wikipedia.org/wiki/%D0%9E%D0%BA%D0%BE%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BF%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A4%D1%83%D1%80%D1%8C%D0%B5
Пример ошибок преобразования. У нас есть двухмерная волновая функция чистого синуса, с одной гармоникой (в данном случае беру это, т.к. есть под рукой картинки).
Синусоида, высоты определяются градацией серого.
Если представить в виде трёхмерного объекта, то выглядит вот так:

Делаем БПФ её, получаем не одну чистую гармонику, а множество гармоник:

В трёхмерном виде:

При правильном подобранном окне, когда период чётко умещается должны были получить вот такую картину:
Трёхмерной картинки нет, но должны были получиться ровные столбцы.
Надеюсь ответил на ваш вопрос.
Нет, не ответили. Кстати, теперь я ещё не понимаю, зачем вам понадобились трёхмерные картинки, физический смысл третьего измерения ускользает от меня.
Я прекрасно представляю, что такое БПФ, оконирование, что такое преобразование Фурье, знаю про предельный переход в интеграл Фурье и так далее. В общем, в теории пробелов, я думаю, нет.
Вопрос был вполне конкретным. Вот есть алгоритм, БПФ скажем, Кули-Тьюки (именно он в аудасити). Он очень простой. Есть функции оконирования. Они тоже довольно простые и в каждом конкретном случае вырождаются в таблицу значений, на которые умножаются отсчёты сигнала.
Итого: выбираем окно подходящего размера (степень двойки для Кули-Тьюки), считаем таблицу значений оконной функции, потом для каждого очередного окна входного сигнала умножаем окно на сигнал и результат преобразуем БПФ. Получили наш образ.
Как это может быть в одной программе это «хреновым», а в другой — нет? Вы сравнивали на одинаковых данных, с одинаковым размером окна и одинаковой функцией оконирования результаты БПФ в аудасити и где-то ещё? Аудасити даёт другой результат?
Потому как если сигнал периодический и «умещается» в окно, аудасити даёт острые пики, как положено. Если не умещается, кто угодно даст ненулевые боковые «лепестки», и многое зависит от оконной функции.
Вообще меня в аудасити расстраивает только отсутствие оконной функции Натолла (подавляет боковые лепестки до -98 дБ).
Я прекрасно представляю, что такое БПФ, оконирование, что такое преобразование Фурье, знаю про предельный переход в интеграл Фурье и так далее. В общем, в теории пробелов, я думаю, нет.
Вопрос был вполне конкретным. Вот есть алгоритм, БПФ скажем, Кули-Тьюки (именно он в аудасити). Он очень простой. Есть функции оконирования. Они тоже довольно простые и в каждом конкретном случае вырождаются в таблицу значений, на которые умножаются отсчёты сигнала.
Итого: выбираем окно подходящего размера (степень двойки для Кули-Тьюки), считаем таблицу значений оконной функции, потом для каждого очередного окна входного сигнала умножаем окно на сигнал и результат преобразуем БПФ. Получили наш образ.
Как это может быть в одной программе это «хреновым», а в другой — нет? Вы сравнивали на одинаковых данных, с одинаковым размером окна и одинаковой функцией оконирования результаты БПФ в аудасити и где-то ещё? Аудасити даёт другой результат?
Потому как если сигнал периодический и «умещается» в окно, аудасити даёт острые пики, как положено. Если не умещается, кто угодно даст ненулевые боковые «лепестки», и многое зависит от оконной функции.
Вообще меня в аудасити расстраивает только отсутствие оконной функции Натолла (подавляет боковые лепестки до -98 дБ).
Трёхмерные картинки были под рукой. Я просто учился обрабатывать их в своё время, и картинки остались на фотохостинге. Всё просто. Считайте измерения всего два. И я тут не поумничать пришёл. Вы бы сразу говорили, что владеете матчастью.
Коллега, я не хочу спорить. Просто мне показался аудасити не дотасточно полным для обработки, ибо я много поюзал осцилогрофических программ (например отечественный осциллограф Актаком даёт в плане софта просто фантастические возможности по обработке аналоговых данных — фильтрации, АЧХ, с разными окнами и т.п.). После которых звуковые программы выглядят мягко скажем малофункциональными.
>>Потому как если сигнал периодический и «умещается» в окно, аудасити даёт острые пики, как положено. Если не умещается, кто угодно даст ненулевые боковые «лепестки», и многое зависит от оконной функции.
Здесь полносттью согласен.
Не судите строго, говорю — могу ошибаться.
Коллега, я не хочу спорить. Просто мне показался аудасити не дотасточно полным для обработки, ибо я много поюзал осцилогрофических программ (например отечественный осциллограф Актаком даёт в плане софта просто фантастические возможности по обработке аналоговых данных — фильтрации, АЧХ, с разными окнами и т.п.). После которых звуковые программы выглядят мягко скажем малофункциональными.
>>Потому как если сигнал периодический и «умещается» в окно, аудасити даёт острые пики, как положено. Если не умещается, кто угодно даст ненулевые боковые «лепестки», и многое зависит от оконной функции.
Здесь полносттью согласен.
Не судите строго, говорю — могу ошибаться.
Добрый день! merlin-vrn совершенно правильно изложил суть проблеммы. Если необходимо быстро и наглядно получить спектрограмму для анализа, audacity — вполне приемлемый софт. Самые базовые вещи, такие как длина окна анализа и тип оконной функции, audacity вполне позволяет выбрать, и тут уже все в руках инженера. Если анализировать речевой сигнал с частотой дискретизации 44 кГц, длина окна в 1024, либо 2048 самплов дает достаточно реалистичные результаты, позволяющие увидеть основные тенденции в изменении спектра сигнала.
В случае, если необходимо «дотошно» анализировать каждую гармонику и её поведение во времени, возможно использовать другие подходы к рассчету спектра (банки фильтров например) и выбирать меньший шаг во времени при рассчете спектрограммы. В данной работе такой цели не стояло.
В случае, если необходимо «дотошно» анализировать каждую гармонику и её поведение во времени, возможно использовать другие подходы к рассчету спектра (банки фильтров например) и выбирать меньший шаг во времени при рассчете спектрограммы. В данной работе такой цели не стояло.
Как раз сегодня размышлял на эту тему. Спасибо!
Отдельно стоит напомнить про наличие вокодеров. Если упростить, то это устройство для преобразования звуков голоса в двоичный поток, те кодирование его. За счет учета того факта, что передается именно голос, эффективность кодирования была гораздо выше, чем обычное кодирование уровней. Речь разбивается на фонемы, и уже о них передается информация. В свое время при изучении устройства старой военной аппаратуры связи очень подробно вникали в эту теорию по книгам, которые рассыпались в руках, годов 70х-80х. Реализовано это было на железе в котором кроме простейшей логики никаких микросхем не было. Но потом почти все вокодеры дружно поменяли на липредеры, ибо звук, синтезированный на основе информации с вокодера, терял узнаваемость, те вне зависимости от того, кто говорил, голос из трубки шел «железный». Потому отличить командира от противника было достаточно сложно.
Вопрос, немного не по теме, но всё же.
С Вашей точки зрения, возможно ли распознавание звуков, слов, слогов во временной области, без использования частотной?
С Вашей точки зрения, возможно ли распознавание звуков, слов, слогов во временной области, без использования частотной?
Здравствуйте!
Я не являюсь специалистом по части распознавания и мои знания в данной области весьма ограничены. «На вскидку» можно сказать следующее:
1) Обработка во временной области как правило является вычислительно более дорогой.
2) Существуют алгоритмы обработки звука, работающие исключительно во временной области. Но там какого-либо серьезного распознавания звуков не делается, лишь решается вопрос «является ли текущий обрабатываемый сегмент вокализованным, либо нет?».
3) Сама процедура рассчета спектра подразумевает под собой интегрирование, и это позволяет получить усредненные оценки свойств сигнала на некотором интервале. Таким образом устраняются незначительные флуктуации анализируемого сигнала от «ожидаемого». Хорошо это или плохо — зависит от задачи.
4) Насколько я знаю, в алгоритмах распознавания очень важна размерность вектора характеристик, описывающих распознаваемый объект. Частотная область здесь пожалуй более удобна, т.к. позволяет более компактно описать основные свойства сигнала.
Большинство работ по разпознаванию, которые я видел, используют характеристики сигнала в частотной област (MFCC, LPC, кепстр, банки фильтров, etc). Есть работы, которые использую частотную область и при этом опираются на какие-то характеристики во временной области, что во многом оправданно. Работы, в которых используется исключительно временная область для решения задачи распознавания, мне лично не попадались. Но опять же, как было упомянуто, в этой области я не силен.
P.S. Гугл на запрос «time domain speech recognition» выдает ссылки на различные диссертации, но насколько эффективны данные методы мне сказать тяжело.
Я не являюсь специалистом по части распознавания и мои знания в данной области весьма ограничены. «На вскидку» можно сказать следующее:
1) Обработка во временной области как правило является вычислительно более дорогой.
2) Существуют алгоритмы обработки звука, работающие исключительно во временной области. Но там какого-либо серьезного распознавания звуков не делается, лишь решается вопрос «является ли текущий обрабатываемый сегмент вокализованным, либо нет?».
3) Сама процедура рассчета спектра подразумевает под собой интегрирование, и это позволяет получить усредненные оценки свойств сигнала на некотором интервале. Таким образом устраняются незначительные флуктуации анализируемого сигнала от «ожидаемого». Хорошо это или плохо — зависит от задачи.
4) Насколько я знаю, в алгоритмах распознавания очень важна размерность вектора характеристик, описывающих распознаваемый объект. Частотная область здесь пожалуй более удобна, т.к. позволяет более компактно описать основные свойства сигнала.
Большинство работ по разпознаванию, которые я видел, используют характеристики сигнала в частотной област (MFCC, LPC, кепстр, банки фильтров, etc). Есть работы, которые использую частотную область и при этом опираются на какие-то характеристики во временной области, что во многом оправданно. Работы, в которых используется исключительно временная область для решения задачи распознавания, мне лично не попадались. Но опять же, как было упомянуто, в этой области я не силен.
P.S. Гугл на запрос «time domain speech recognition» выдает ссылки на различные диссертации, но насколько эффективны данные методы мне сказать тяжело.
Что значит «коартикулировать»?
Коартикуляция это когда звуки влияют друг на друга. Вот здесь можно почитать
мне тоже это слово понравилось
Если вдруг опытный исследователь оглохнет, то сможет ли понять собеседника, глядя на показания приборов?
«В круге первом» Солженицына не читали? Вопрос фактически оттуда :)
К сожалению, не читал. Только сериал смотрел немного. Буду читать. Спасибо.
Читал. Книга, как всегда, оказалась интереснее сериала.
Да, сможет. Проводились эксперименты по визуальному распознаванию речи по спектрограммам. Вроде как довольно успешно. Только давно это было.
А почему у вокалоида-II Мику Хацунэ (Первый Звук Будущего) русский текст так сложно сделать? :)
На самом деле — вопрос про фонетику звуков в разных языках. Есть ли общие паттерны? Прослеживается ли генеалогическое родство фонетики (с точки зрения спектральной обработки) в языковых группах? Есть ли какие-то ФИЗИЧЕСКИЕ причины у лингвистических законов типа «озвончение лабиального согласного после неударной е» (пример высосан из пальца для имитации терминологии). Интересно, этим кто-нибудь занимается?
Грубо — можно ли опознать язык по фрагменту речи?
На самом деле — вопрос про фонетику звуков в разных языках. Есть ли общие паттерны? Прослеживается ли генеалогическое родство фонетики (с точки зрения спектральной обработки) в языковых группах? Есть ли какие-то ФИЗИЧЕСКИЕ причины у лингвистических законов типа «озвончение лабиального согласного после неударной е» (пример высосан из пальца для имитации терминологии). Интересно, этим кто-нибудь занимается?
Грубо — можно ли опознать язык по фрагменту речи?
Здравствуйте. Не смогу однозначно ответить на Ваш вопрос, поскольку не имею опыта в решении подобных задач. Позвольте внести свои «5 копеек». Опознавание языка диктора по записи фрагмента его речи — особая задача, которая решается не только силами одной фонетики, но с привлечением в первую очередь лингвистических знаний. Как и в остальных задачах распознавания, достигнуть 100% правильного результата не видится возможным. Некоторые авторы утверждают о достигаемой точности порядка 90% при поддержке вплоть до 12 языков и при анализе фрагмента речи буквально в несколько секунд. Конечно сразу возникают вопросы о базе, на которой проводилось тестирование, о качестве записи обрабатываемых сигналов и многие другие вопросы, сопутствующие НЕ лабораторному применению любой системы.
Немало работ можно найти просто набрав в Гугле automatic language indentification. А если заглянуть в первоисточники данных работ — информации для исследования станет ещё больше :)
Насчет «патернов» в произношении звуков, возможно процитировать Ирину Алдошину:
«Артикуляционные возможности речевого тракта при образовании звуков чрезвычайно разнообразны, и могут быть использованы для создания огромного многообразия звуков. Однако для речи используется ограниченный набор звуков (количество фонем в разных языках мира в основном не превышает 50…70). Такой разрыв между возможностями голосового аппарата и его применением объясняется с помощью квантальной теории, в соответствии с которой из всех звуков в речи используются только те, которые создают достаточно четкие слуховые контрасты и легко различимы слуховой системой (т.е. речь была приспособлена к слуху). Например, гласные „и“, „у“, „а“ резко контрастируют на слух, поэтому они используются почти во всех языках мира. Поэтому для разных звуков для речи были отобраны те виды артикуляции, которые создают существенные акустические и слуховые различия.»
Немало работ можно найти просто набрав в Гугле automatic language indentification. А если заглянуть в первоисточники данных работ — информации для исследования станет ещё больше :)
Насчет «патернов» в произношении звуков, возможно процитировать Ирину Алдошину:
«Артикуляционные возможности речевого тракта при образовании звуков чрезвычайно разнообразны, и могут быть использованы для создания огромного многообразия звуков. Однако для речи используется ограниченный набор звуков (количество фонем в разных языках мира в основном не превышает 50…70). Такой разрыв между возможностями голосового аппарата и его применением объясняется с помощью квантальной теории, в соответствии с которой из всех звуков в речи используются только те, которые создают достаточно четкие слуховые контрасты и легко различимы слуховой системой (т.е. речь была приспособлена к слуху). Например, гласные „и“, „у“, „а“ резко контрастируют на слух, поэтому они используются почти во всех языках мира. Поэтому для разных звуков для речи были отобраны те виды артикуляции, которые создают существенные акустические и слуховые различия.»
Сколько времени ушло на изучение темы и написания статьи?
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Задача изменения голоса. Часть 1. Что такое голос?