Из всех моих разговоров с коллегами о разных аспектах разработки программного обеспечения одна тема всплывает чаще других. Да что там «чаще» — она повторяется снова и снова, как заезженная пластинка — это беседы на тему того, чем плох GitFlow и почему его стоит избегать.
Статья "Удачная модель ветвления для Git" описывающая метод, получивший в последствии название «GitFlow» стала де-факто стандартом того, как нужно начинать использовать Git в вашем проекте. Если поискать в Google что-то типа "git branching strategy" то вот как раз этот метод будет описан по первой ссылке (а скорее всего и по нескольким следующим).
Лично я ненавижу GitFlow и за последние годы убедил много команд разработчиков перестать его использовать, чем, как мне кажется, сохранил им уйму времени и нервов. GitFlow заставляет команды организовывать управление изменениями кода хуже, чем оно может быть реализовано. Но поскольку это такой популярный метод (по крайней мере в результатах поисковика), то команды без достаточного опыта, которые ищут «что-то, хотя бы как-то работающее» находят именно его при быстром поиске, да ещё и видят слово «успешный» прямо в заголовке статьи с его описанием — ну и начинают бездумно использовать. Я хочу хотя бы немного изменить этот паттерн поведения, описав в этой статье более простую и не менее успешную стратегию использования веток Git, которую я внедрил во многих командах. Часто эти команды пробовали использовать GitFlow, но испытывали проблемы, которые, пропали с переходом на ThreeFlow.
Я называю эту стратегию ThreeFlow потому, что в ней есть ровно три ветки. Не четыре. Не две. Три.
Ну и сразу предупреждение: серебряной пули нет и ThreeFlow тоже не панацея. Она подойдёт не всегда. Я думаю она будет плохо работать для embedded-разрботки и для опенсорсных проектов. Но она очень успешна для ситуаций, когда вся команда проекта работает в одной компании и нет никаких пул-реквестов от внешних разработчиков. Т.е. каждый в команде имеет полный доступ к коду и все необходимые права на запись в репозиторий.
Если коротко, то «не так» с GitFlow его идея создания ветки для каждой разрабатываемой фичи. Ветки для фич — корень зла. Всё, что дают эти ветки — это проблемы, проблемы и снова проблемы. Если вы вообще больше ничего полезного не вынесете из этой статьи или прекратите читать её вот здесь — просто запомните мысль, что ветки для фич — это ужасно.
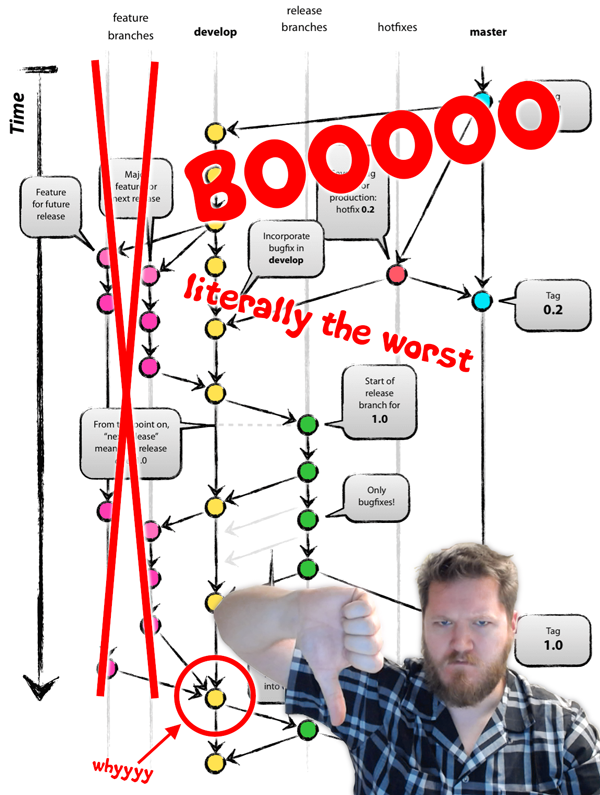
Справедливости ради стоит отметить, что оригинальная статья говорит о ветках для фич, что они «как правило, существуют лишь на машинах отдельных разработчиков, но не в главном репозитории (origin)». Но в этой же статье иллюстрирующие GitFlow рисунки показывают это иначе. Мы видим «origin» с ветками фич. Более того, я видел много команд разработчиков, использующих GitFlow и ни одна из них не обратила внимание на рекомендацию автора использовать ветки лишь на отдельных машинах разработчиков. Все, кого я видел, использовали ветки фич как долговременный инструмент, существующий в «origin».
Нет вообще ничего плохого в том, чтобы делать ветки для фич на своей машине. Это хороший способ переключаться между задачами, если потребности вашего проекта требуют работы над несколькими из них одновременно. Это хороший способ держать ветку master чистой, на случай необходимости сделать небольшой фикс без необходимости синхронизации всей вашей работы с удалённым репозиторием. Но я бы пошел дальше рекомендаций оригинального GitFlow и жестко запретил бы создание веток фич в origin.
Если вы используете длительно существующие ветки для отдельных фич, то ад их интеграции будет вашей постоянной реальностью. Два инженера успешно работают каждый над своей фичей, каждый в своей ветке, ничего вроде бы не предвещает беды. Но ни один из них не видит работы другого. Даже если они регулярно синхронизируют свои ветки с основной веткой разработки, то видят лишь комиты уже законченных и смердженных фич, но не текущую работу друг друга. И вот разработчик А вливает заканчивает разработку своей фичи и вливает код в основную ветку. Разработчик Б забирает эти изменения и получает классическую проблему «кто последний, тот и разгребает конфликты». Он, возможно, опоздал всего на минутку, но теперь потратит часы на попытки понять, что же здесь понаписывал разработчик А и как всё это должно быть смерджено. И чем дольше велась вот такая «изолированная» разработка в отдельных ветках фич — тем больше будет боли и страданий при мердже.
Длительно существующие ветки для фич — это вовсе не упрощение работы. Это просто откладывание проблем «на потом». Главной формой коммуникаций между разработчиками является исходный код. Вы можете сколько угодно утешать себя тем, что у вас есть регулярные стендапы, планнинг-митинги и ретроспективы, но это всё не важно. Представьте себе репетицию оркестра, где музыканты долго обсуждают, как они будут играть какое-то произведение, но потом дирижер просит их разойтись по комнатам и репетировать свои партии отдельно. Будет ли от таких репетиций толк? Так и с разработкой ПО — работа в ветках фич по сути своей является аналогом гробовой тишины в коммуникациях между разработчиками. Ветки для фич — это ужасно.
Кроме того, ветки для фич ужасно масштабируются. Один разработчик, создающий себе по ветке на фичу ради собственного комфорта — это ещё не беда. Но вот ваша команда растёт, и каждый разработчик имеет по ветке на каждую активно разрабатываемую фичу. Поздравляю, у вас теперь по проблеме на каждую пару веток. Пускай у вас всего 8 программистов и каждый из них работает всего над одной фичей в своей ветке. И вот у вас уже 28 (количество пар) оборванных коммуникационных линий. Добавляем ещё одного разработчика с ещё одной веткой — и вот у вас уже 36 «обрывов».
Вместо использования веток для разработки фич, попробуйте использовать флаги для их включения-выключения. Это просто. Начните разработку новой фичи с объявления булевого флага, по которому она будет включаться. Установите его по-умолчанию в false — и в этом случае вызывайте старый код, без кода для новой фичи:
 Сам флаг может быть как жестко зашит в код, так и вынесен во внешний конфиг (возможно с использованием чего-то типа Consul или Zookeeper), что даст возможность включать и выключать новую функциональность для тестирования или даже в продакшене. Руководители проекта и заказчики очень любят видеть перед собой панель управления продуктом со списком фич, которые они сами могут включить или выключить, без необходимости привлечения разработчиков и пересборки проекта.
Сам флаг может быть как жестко зашит в код, так и вынесен во внешний конфиг (возможно с использованием чего-то типа Consul или Zookeeper), что даст возможность включать и выключать новую функциональность для тестирования или даже в продакшене. Руководители проекта и заказчики очень любят видеть перед собой панель управления продуктом со списком фич, которые они сами могут включить или выключить, без необходимости привлечения разработчиков и пересборки проекта.
Когда два разработчика работают в одной (основной) ветке над разными фичами, то создают по флагу на каждую из них. И просто комитят\забирают код регулярно. Шансы на возникновение конфликта в таком случае минимальны. Каждый может комитнуть код, когда считает нужным. Каждый может синхронизировать свой локальный репозиторий с основным — и рассинхрон будет минимальным (уж точно не больше одного рабочего дня). Конфликтов либо не будет вовсе, либо они будут минимальны. Значительно проще понять, что изменил твой коллега вот в этом десятке строк за последний час, чем разгребать глобальные изменения за дни или недели, как предлагает нам GitFlow.
И да, если вы пишете тесты для своего кода (а ведь вы пишете их, да?), то нужно тестировать и ветку кода с отключенным флагом, и ту, где флаг включен. Если ведётся разработка двух взаимозависимых фич — на время разработки вам понадобится 4 теста для всех их комбинаций. Это звучит как угроза усложнения и замедления разработки, но не забывайте, что после окончания разработки новых фич «старые» блоки кода (и тесты для них) будут удалены, так что геометрического увеличения сложности вы не получите.
Флаги для новых фич могут использоваться и более динамично. Вы можете привязать их к определённым группам пользователей для бета-тестирования или A/B тестов.
Когда разработка фичи завершена и она включена по-умолчанию в продакшене, вы можете запланировать небольшую низкоприоритетную задачу по удалению старого кода и самого флага. Или, если вы по каким-то причинам хотите сохранить возможность отключения фичи (проблемы со стабильностью нового кода, регулирование нагрузки на backend), этого можно и не делать. В любом случае, важно осознанно принять решение об удалении или оставлении флага и старого кода — если об этом забыть, то со временем ваш код обрастёт мхом старого неиспользуемого функционала, который будет только отвлекать разработчиков и не приносить никакой реальной пользы.
Ценность подхода с флагами для включения новых фич просто невозможно переоценить. Я гарантирую, что как только вы начнёте использовать флаги для фич вместо веток для них же, то никогда не захотите вернуться обратно. На моей памяти почти всегда разработка большой новой фичи в отдельной долгоживущей ветке рано или поздно приводила к проблемам, требующим внимания сразу нескольких программистов и глубокого знания Git. В то же время подход с работой в одной ветке и флагами для новых фич ни разу не привёл к каким-то конфликтам, которые нельзя было бы решить за пару минут одним человеком.
Так, мы разобрались с тем почему ветки для фич это плохо и на что мы их можем заменить. Теперь мы можем поговорить собственно о модели ветвления ThreeFlow, которая из этого следует.
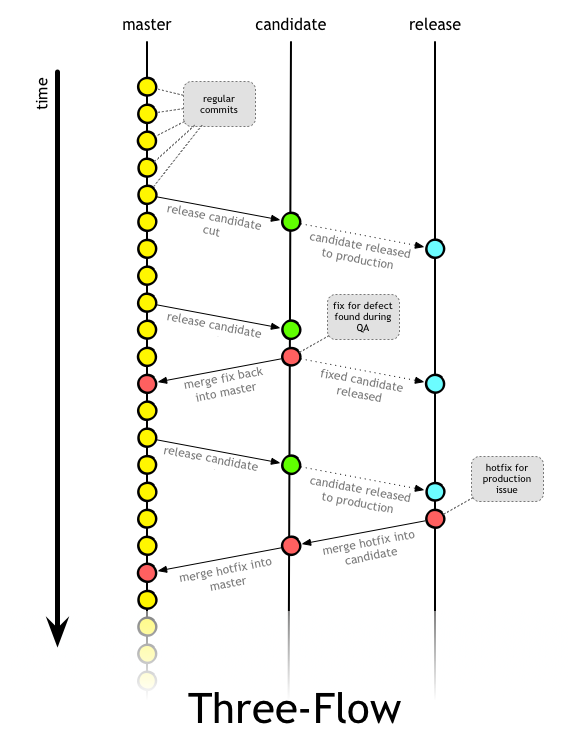
В этом подходе все разработчики работают в одной мастер-ветке. Если фича тривиальна — она просто реализуется и добавляется одним комитом. Если разработка фичи займёт какое-то время, то сначала добавляется флаг (по-умолчанию выключенный) для её активизации. Разработчик включает данный флаг локально для разработки и тестирования новой фичи, но код в основном репозитории по-прежнему использует «старые» ветки кода. Для добавления коммитов в master используется перемещение (rebase). Если вы использовали локальную ветку для работы над фичей, она должна быть перемещена в master, таким образом в origin у нас не будет никаких следов этой ветки.
Вот и всё. Так и происходит весь процесс разработки. Одна ветка, master. Весь код в ней. Всё необходимое включается или выключается флагами. У всех разработчиков один и тот же, часто синхронизируемый друг с другом код. Всё остальное в ThreeFlow касается уже только стратегии релизов, а не разработки.
Когда приходит время релиза (по графику или когда скажет руководство) делается «срез» ветки master в ветку релиз-кандидатов. Одна и та же ветка используется для всех релиз-кандидатов.
Предназначение данной ветки — дать билд, который получит команда QA для выполнения регрессионных (и других) тестов. Теоретически, новые фичи данного релиз-кандидата уже были проверены QA по ходу их разработки и включения, но, возможно, QA захотят перепроверить их в релиз-кандидате.
Для создания релиз-кандидата вы делаете что-то вроде этого:
Причина использования флага "--no-ff" здесь в том, что мы хотим создать merge-коммит (новый коммит с двумя родителями). Одним из его родителей будет предыдущий HEAD ветки релиз-кандидатов, а второй — HEAD ветки master. Это позволит вам легко отслеживать в истории кто и когда создал релиз-кандидат, а также что конкретно в него вошло (какие коммиты ветки master).
Также вы могли заметить, что мы создали тег для релиз-кандидата. Чуть детальнее об этом.
Если при тестировании релиз-кандидата обнаружатся баги, то они будут исправлены прямо в ветке релиз-кандидата, там же будет промаркирован новый релиз-кандидат, а изменения с исправлениями будут смерджены обратно в master. Эти изменения тоже должны быть применены с параметром "--no-ff", ведь мы хотим аккуратно показать, какой именно код был перемещен между ветками.
Когда релиз-кандидат протестирован и одобрен, мы обновляем ветку релизов таким образом, чтобы её HEAD указывал на HEAD ветки релиз-кандидатов. Поскольку у нас есть тег для каждого релиз-кандидата, то мы можем именно его запушить в ветку релизов:
Параметр "--force" здесь означает, что мы игнорируем все изменения в ветке релизов и просто насильно устанавливаем её HEAD на тот же коммит, который обозначает последний созданный тег релиз-кандидата (candidate-3.2.647 в примере выше). Заметьте, что это вовсе не является слиянием (merge), но это потому, что нам оно здесь и не нужно. Мы не хотим усложнять историю в Git, да и вообще единственной причиной создания ветки релизов является теоретическая необходимость экстренного фикса обнаруженной на продакшене критической проблемы. Да, этот "--force" перетрёт все хотфиксы в ветке релизов. Но знаете, если вы релизите следующую версию продукта с новыми фичами в то же время, пока другой член вашей команды фиксит баги на продакшене — у вас серьёзные проблемы с управлением проектом и коммуникациями. Их стоит решить ещё до начала всех этих танцев вокруг веток и релизов. Фиксы в ветке релизов должны быть очень редкими и, конечно, должны быть потом смерджены в ветки релиз-кандидатов и master.
Причина, по которой мы используем "--force", а не merge в том, что при merge коммит в HEAD ветки релиз-кандидатов и коммит в HEAD ветки релизов могут иметь разные sha-1, а это не то, что нам нужно. Мы не хотим создавать новый коммит с релизом, мы хотим назвать релизом именно тот коммит, который был выбран релиз-кандидатом, который тестировался командой QA и был одобрен к релизу тем, кто за это отвечает. Именно это и делает "--force".
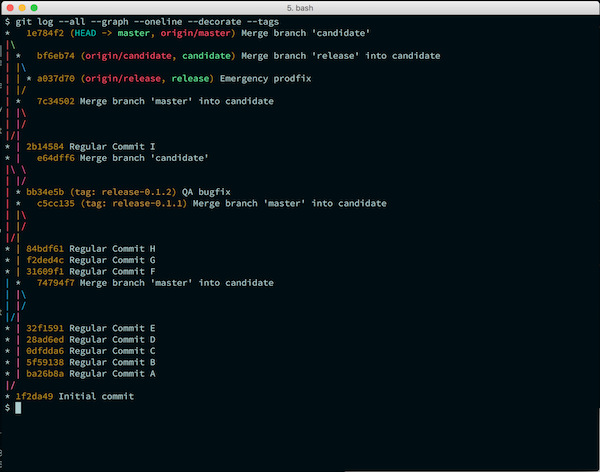
Если вы будете следовать этим рекомендациям, то история в вашем git-репозитории будет выглядеть очень похоже на рисунок выше, показывая в точности какие коммиты перемещались между ветками.
Вы можете легко генерировать «release notes» к новым релизам. Нужно всего лишь получить разницу между прошлым тегом релиза и текущим тегом релиз-кандидата. Поскольку в ветке релизов у нас лежит то, что когда-то точно было релиз-кандидатом, мы можем узнать каким именно:
Теперь, когда мы знаем, что в релиз-кандидате у нас сейчас candidate-3.2.259, можно получить разницу между этими двумя тегами:
Ну или даже проще, без тегов, просто сравниваем HEAD веток release и candidate:
Вот некоторые часто используемые операции при работе по ThreeFlow. Все примеры предполагают, что ваши локальные ветки правильно соотнесены с удалёнными ветками и содержат актуальные изменения. Если вы не уверены в этом — всегда будет хорошей идеей лишний раз сделать git fetch и потом использовать имена вроде origin/master вместо просто master
Как мне сделать релиз-кандидат из ветки master?
Как мне сделать релиз из релиз-кандидата?
Если вы почему-то решили не тегировать релиз-кандидаты, то придётся сделать:
Как мне найти ветку, в которой есть некоторый конкретный коммит?
Иногда люди хотят убедиться, что какое-то конкретное изменение вошло в релиз-кандидат или в релиз. Вот как это проверить:
Как мне найти тег, на который указывает HEAD некоторой ветки?
Как мне узнать, какие коммиты войдут в некоторый новый релиз?
или:
Как мне настроить ветки релиз-кандидатов и релизов?
Любой проект начинается с первого коммита. Обычно это что-то простое, вроде добавления readme-файла. Я советую просто сделать ветки релиз-кандидатов и релизов из этого коммита. Что нам нужно получить, это первый merge-коммит с двумя родителями. Таким образом мы получим корректную историю. Так что подойдёт, в общем, любой коммит master-ветки. Почему бы не взять первый?
Чтобы сделать ветку для релизов:
А это разве описана не «модель кактуса»?
Вы можете подумать, что описанная в статье стратегия ветвления очень похожа на "модель кактуса", описанную Jussi Judin (тоже в качестве альтернативы GitFlow и тоже использующую ветку master для всей работы). Да, большей частью так оно и есть. Ключевым отличием является то, что Judin предлагает перемещать коммиты из ветки master в ветку релизов выборочно («cherry-picks»). Я категорически против этого. Выборочное перемещение коммитов — крайняя мера, которая должна использоваться в последнюю очередь при каком-то уж совсем катастрофическом состоянии master и большой необходимостью срочного релиза. Я предпочитаю использовать перемещение (rebase), а не слияние (merge). И избегать выборочности.
Другим отличием является существование в ThreeFlow ветки релиз-кандидатов, которую я принимаю как минимально необходимое зло. Лично моей целью является поддержание ветки master в таком состоянии, чтобы в каждый коммит можно было ткнуть пальцем и тут же спокойно выложить его в продакшн. Но я заметил, что многим коммандам трудно и некомфортно работать в таком режиме. Люди предпочитают иметь буффер в виде команды QA, которым нужно дать одобренный разработчиками билд («вот этот бери, а не вот тот, тот плохой») и получить от них фидбек о его качестве. И модель ThreeFlow даёт им такую возможность. В тщательно подходящим к качеству продукта командах различия между ветками релиз-кандидатов и релизов будут минимальными.
А это разве описана не GitFlow просто без веток для фич?
На самом деле я объяснял данную стратегию тем, кто до этого использовал GitFlow похожим образом: «Вы не используете ветки для фич, вся разработка идёт в ветке develop, которую мы теперь будем называть master, а то, что вы называли master мы будем называть веткой релизов». Основной идеей ThreeFlow была минимизация сложности. GitFlow поощряет создание новых сущностей (веток) по любому поводу (для фич, релизов, хотфиксов). Чем больше проект и чем дольше он идёт — тем страшнее выглядит его история. ThreeFlow стремиться минимизировать количество веток — никаких веток для фич или хотфиксов. Фичи пишутся в мастере, хотфиксы накатываются на релиз-кандидат или даже на релиз. И вместо кучи веток релизов у нас всегда есть то, что мы называем текущим релиз-кандидатом и текущим релизом. Всего лишь три ветки. Всегда.
Нам также не нужно придумывать систему именования веток (у нас их всего три и их имена константны): master, candidate, release.
Всегда есть ответ на вопрос «а куда положить мой код?». Если это хот-фикс проблемы на продакшене — в release. Если это фикс бага в релиз-кандидате — в candidate. Если это обычная ежедневная работа — в master.
Что на счёт ревью кода?
Если у вас есть правило ревьювить весь код перед тем, как он попадёт в основную ветку разработки, то будет логичным добавить ещё одну ветку (давайте назовём её develop — да, украдём это название у GitFlow, почему бы и нет). Итак, вся разработка будет идти в ней, а затем ревьювер будет переносить одобренные коммиты из неё в мастер (ну или просить их доработать). Конечно, нужно будет как-то отслеживать, что было перенесено, а что нет и это может вызвать затруднения. Нужно признать, что строгое следование идее ревью кода перед комитом в основную ветку может не сработать для вашей команды при использовании ThreeFlow или потребует дальнейшей адаптации этого подхода. Я слышал, что люди успешно применяли инструменты типа Gerrit для подобных целей, хотя сам его никогда не использовал.
Что на счёт кодовых баз, в которых хранятся несколько артефактов?
Во многих случаях в одной кодовой базе действительно хранится код, из которого может собираться несколько проектов. Эти индивидуальные артефакты сборки требуют отдельных циклов проверки QA-отделом, будут иметь отдельные версии релиз-кандидатов. Как ThreeFlow будет работать в данном случае?
Будет работать хорошо. Совсем недавно я как-раз работал в подобном проекте. У нас был один Git-репозиторий, из которого собиралось и деплоилось несколько разных артефактов. Решение очевидно: каждый артефакт добавляет в репозиторий по две ветки. Вы всё так же пишете весь код в master и работаете над фичами с помощью отключаемых флагов. Для этого вам не нужно знать, сколько и каких артефактов будет собираться из репозитория. Но вот дело доходит до релиза и здесь каждому артефакту становятся необходимыми свои ветки для релиз-кандидатов и релизов: foo_candidate, foo_release, bar_candidate, bar_release. Вот и всё.
Это масштабируется лучше, чем вы думаете. В одном из моих последних проектов у нас была одна большая кодовая база, из которой собиралось 4 разных артефакта. Кое-какой общий код, что-то индивидуально для каждого подпроекта — ну, вы понимаете. С одной стороны — 8 веток для релиз-кандидатов и релизов, плюс один master. Но с другой стороны — над каждым артефактом работала своя отдельная команда, и для каждой из них актуальными были лишь их три ветки, так что их общее количество мало кого волновало.
А можно как-то избежать набора дополнительных аргументов команд Git?
Одной из особенностей предлагаемого подхода является то, что почти каждая используемая команда действительно имеет дополнительные аргументы. Каждый раз, когда вы делаете слияние (merge), нужно не забыть добавить "--no-ff". Когда вы делаете релиз и тегируете его — я советую применять "--follow-tags" при пуше, чтобы сохранить теги в origin. Вы можете сделать так, чтобы эти теги применялись по-умолчанию:
Теперь вы можете использовать команду merge без параметра "--no-ff" (он будет добавляться неявно)
Аналогично с тегами при пуше:
Также можно настроить автоматический rebase при pull:
Вы можете даже сделать так, чтобы все новые ветки автоматически ребейзелись при pull в случае если вы используете локальные ветки для работы над отдельными фичами:
Также можно убрать ключ "--global" из вышеуказанных комманд, если вы хотите применить данные правила лишь к текущему репозиторию, а не ко всем вообще.
А можно я буду использовать слияние для релиз-ветки?
Ну, во-первых, вы свободный человек и можете делать всё, что захотите. Я просто описываю стратегию, которая хорошо работает для меня и некоторых других людей. Мне кажется, что она лучше, чем GitFlow (потому, что проще).
Во-вторых, да, если вам не нравится идея делать push с ключом "--force" и терять какую-то часть исторической информации, вы можете делать merge с ключом "--no-ff". Плюс тут ещё и в том, что не нужно запоминать разных способов переноса комита между ветками. Просто делайте себе merge --no-ff всегда, да и всё.
На самом деле первая версия ThreeFlow описывала как-раз именно такое поведение, слияние с параметром --no-ff для релизов. Это работало нормально, история была хорошо читаема. Единственное, что мне не нравилось, так это то, что артефакт сборки из релиз-ветки формально не был тем же коммитом, который до этого считался релиз-кандидатом и прошел через QA и утверждение к релизу. Получается, мы протестировали одно, потом сделали что-то другое и вот это другое релизнули. Плохо. Можно, конечно, заменить слияние на fast forwarding, но это тоже ведёт к потере информации, да ещё и не факт, что гарантированно удастся.
По моему мнению, push + force более ясно говорит о том, что содержимое релиза на самом деле не является веткой в терминологии цепочки наследуемых коммитов и не должно трактоваться так. Это просто указатель на актуальный код, который сейчас работает в продакшене. А сама ветка release просто указывает на серию тегов, которые когда-то выкладывались в продакшн. Ну и поскольку это всё-таки ветка с актуальным кодом, то вы всегда можете сделать хотфикс для продакшена прямо в ней.
Использовать Git без внятной стратегии ветвления — опасное дело. Поэтому возьмите вот эту:

Вот и всё. По моему мнению ThreeFlow это одна из простейших стратегий ветвления для Git, которая в то же время даёт вам всё необходимое.
Попробовали и вам подошло? Попробовали и не подошло? Почитали описание и считаете того, кто предлагает использовать "--force" в качестве регулярной операции, полным идиотом? Не стесняйтесь рассказать об этом в комментариях!
Статья "Удачная модель ветвления для Git" описывающая метод, получивший в последствии название «GitFlow» стала де-факто стандартом того, как нужно начинать использовать Git в вашем проекте. Если поискать в Google что-то типа "git branching strategy" то вот как раз этот метод будет описан по первой ссылке (а скорее всего и по нескольким следующим).
Лично я ненавижу GitFlow и за последние годы убедил много команд разработчиков перестать его использовать, чем, как мне кажется, сохранил им уйму времени и нервов. GitFlow заставляет команды организовывать управление изменениями кода хуже, чем оно может быть реализовано. Но поскольку это такой популярный метод (по крайней мере в результатах поисковика), то команды без достаточного опыта, которые ищут «что-то, хотя бы как-то работающее» находят именно его при быстром поиске, да ещё и видят слово «успешный» прямо в заголовке статьи с его описанием — ну и начинают бездумно использовать. Я хочу хотя бы немного изменить этот паттерн поведения, описав в этой статье более простую и не менее успешную стратегию использования веток Git, которую я внедрил во многих командах. Часто эти команды пробовали использовать GitFlow, но испытывали проблемы, которые, пропали с переходом на ThreeFlow.
Я называю эту стратегию ThreeFlow потому, что в ней есть ровно три ветки. Не четыре. Не две. Три.
Ну и сразу предупреждение: серебряной пули нет и ThreeFlow тоже не панацея. Она подойдёт не всегда. Я думаю она будет плохо работать для embedded-разрботки и для опенсорсных проектов. Но она очень успешна для ситуаций, когда вся команда проекта работает в одной компании и нет никаких пул-реквестов от внешних разработчиков. Т.е. каждый в команде имеет полный доступ к коду и все необходимые права на запись в репозиторий.
Так а что же не так с GitFlow?
Если коротко, то «не так» с GitFlow его идея создания ветки для каждой разрабатываемой фичи. Ветки для фич — корень зла. Всё, что дают эти ветки — это проблемы, проблемы и снова проблемы. Если вы вообще больше ничего полезного не вынесете из этой статьи или прекратите читать её вот здесь — просто запомните мысль, что ветки для фич — это ужасно.

Справедливости ради стоит отметить, что оригинальная статья говорит о ветках для фич, что они «как правило, существуют лишь на машинах отдельных разработчиков, но не в главном репозитории (origin)». Но в этой же статье иллюстрирующие GitFlow рисунки показывают это иначе. Мы видим «origin» с ветками фич. Более того, я видел много команд разработчиков, использующих GitFlow и ни одна из них не обратила внимание на рекомендацию автора использовать ветки лишь на отдельных машинах разработчиков. Все, кого я видел, использовали ветки фич как долговременный инструмент, существующий в «origin».
Нет вообще ничего плохого в том, чтобы делать ветки для фич на своей машине. Это хороший способ переключаться между задачами, если потребности вашего проекта требуют работы над несколькими из них одновременно. Это хороший способ держать ветку master чистой, на случай необходимости сделать небольшой фикс без необходимости синхронизации всей вашей работы с удалённым репозиторием. Но я бы пошел дальше рекомендаций оригинального GitFlow и жестко запретил бы создание веток фич в origin.
Если вы используете длительно существующие ветки для отдельных фич, то ад их интеграции будет вашей постоянной реальностью. Два инженера успешно работают каждый над своей фичей, каждый в своей ветке, ничего вроде бы не предвещает беды. Но ни один из них не видит работы другого. Даже если они регулярно синхронизируют свои ветки с основной веткой разработки, то видят лишь комиты уже законченных и смердженных фич, но не текущую работу друг друга. И вот разработчик А вливает заканчивает разработку своей фичи и вливает код в основную ветку. Разработчик Б забирает эти изменения и получает классическую проблему «кто последний, тот и разгребает конфликты». Он, возможно, опоздал всего на минутку, но теперь потратит часы на попытки понять, что же здесь понаписывал разработчик А и как всё это должно быть смерджено. И чем дольше велась вот такая «изолированная» разработка в отдельных ветках фич — тем больше будет боли и страданий при мердже.
Длительно существующие ветки для фич — это вовсе не упрощение работы. Это просто откладывание проблем «на потом». Главной формой коммуникаций между разработчиками является исходный код. Вы можете сколько угодно утешать себя тем, что у вас есть регулярные стендапы, планнинг-митинги и ретроспективы, но это всё не важно. Представьте себе репетицию оркестра, где музыканты долго обсуждают, как они будут играть какое-то произведение, но потом дирижер просит их разойтись по комнатам и репетировать свои партии отдельно. Будет ли от таких репетиций толк? Так и с разработкой ПО — работа в ветках фич по сути своей является аналогом гробовой тишины в коммуникациях между разработчиками. Ветки для фич — это ужасно.
Кроме того, ветки для фич ужасно масштабируются. Один разработчик, создающий себе по ветке на фичу ради собственного комфорта — это ещё не беда. Но вот ваша команда растёт, и каждый разработчик имеет по ветке на каждую активно разрабатываемую фичу. Поздравляю, у вас теперь по проблеме на каждую пару веток. Пускай у вас всего 8 программистов и каждый из них работает всего над одной фичей в своей ветке. И вот у вас уже 28 (количество пар) оборванных коммуникационных линий. Добавляем ещё одного разработчика с ещё одной веткой — и вот у вас уже 36 «обрывов».
Использование флагов для включения фич
Вместо использования веток для разработки фич, попробуйте использовать флаги для их включения-выключения. Это просто. Начните разработку новой фичи с объявления булевого флага, по которому она будет включаться. Установите его по-умолчанию в false — и в этом случае вызывайте старый код, без кода для новой фичи:
if(newCodeEnabled) {
// новый код
} else {
// старый код
} Сам флаг может быть как жестко зашит в код, так и вынесен во внешний конфиг (возможно с использованием чего-то типа Consul или Zookeeper), что даст возможность включать и выключать новую функциональность для тестирования или даже в продакшене. Руководители проекта и заказчики очень любят видеть перед собой панель управления продуктом со списком фич, которые они сами могут включить или выключить, без необходимости привлечения разработчиков и пересборки проекта.
Сам флаг может быть как жестко зашит в код, так и вынесен во внешний конфиг (возможно с использованием чего-то типа Consul или Zookeeper), что даст возможность включать и выключать новую функциональность для тестирования или даже в продакшене. Руководители проекта и заказчики очень любят видеть перед собой панель управления продуктом со списком фич, которые они сами могут включить или выключить, без необходимости привлечения разработчиков и пересборки проекта. Когда два разработчика работают в одной (основной) ветке над разными фичами, то создают по флагу на каждую из них. И просто комитят\забирают код регулярно. Шансы на возникновение конфликта в таком случае минимальны. Каждый может комитнуть код, когда считает нужным. Каждый может синхронизировать свой локальный репозиторий с основным — и рассинхрон будет минимальным (уж точно не больше одного рабочего дня). Конфликтов либо не будет вовсе, либо они будут минимальны. Значительно проще понять, что изменил твой коллега вот в этом десятке строк за последний час, чем разгребать глобальные изменения за дни или недели, как предлагает нам GitFlow.
И да, если вы пишете тесты для своего кода (а ведь вы пишете их, да?), то нужно тестировать и ветку кода с отключенным флагом, и ту, где флаг включен. Если ведётся разработка двух взаимозависимых фич — на время разработки вам понадобится 4 теста для всех их комбинаций. Это звучит как угроза усложнения и замедления разработки, но не забывайте, что после окончания разработки новых фич «старые» блоки кода (и тесты для них) будут удалены, так что геометрического увеличения сложности вы не получите.
Флаги для новых фич могут использоваться и более динамично. Вы можете привязать их к определённым группам пользователей для бета-тестирования или A/B тестов.
Когда разработка фичи завершена и она включена по-умолчанию в продакшене, вы можете запланировать небольшую низкоприоритетную задачу по удалению старого кода и самого флага. Или, если вы по каким-то причинам хотите сохранить возможность отключения фичи (проблемы со стабильностью нового кода, регулирование нагрузки на backend), этого можно и не делать. В любом случае, важно осознанно принять решение об удалении или оставлении флага и старого кода — если об этом забыть, то со временем ваш код обрастёт мхом старого неиспользуемого функционала, который будет только отвлекать разработчиков и не приносить никакой реальной пользы.
Ценность подхода с флагами для включения новых фич просто невозможно переоценить. Я гарантирую, что как только вы начнёте использовать флаги для фич вместо веток для них же, то никогда не захотите вернуться обратно. На моей памяти почти всегда разработка большой новой фичи в отдельной долгоживущей ветке рано или поздно приводила к проблемам, требующим внимания сразу нескольких программистов и глубокого знания Git. В то же время подход с работой в одной ветке и флагами для новых фич ни разу не привёл к каким-то конфликтам, которые нельзя было бы решить за пару минут одним человеком.
Итак, ThreeFlow
Так, мы разобрались с тем почему ветки для фич это плохо и на что мы их можем заменить. Теперь мы можем поговорить собственно о модели ветвления ThreeFlow, которая из этого следует.

В этом подходе все разработчики работают в одной мастер-ветке. Если фича тривиальна — она просто реализуется и добавляется одним комитом. Если разработка фичи займёт какое-то время, то сначала добавляется флаг (по-умолчанию выключенный) для её активизации. Разработчик включает данный флаг локально для разработки и тестирования новой фичи, но код в основном репозитории по-прежнему использует «старые» ветки кода. Для добавления коммитов в master используется перемещение (rebase). Если вы использовали локальную ветку для работы над фичей, она должна быть перемещена в master, таким образом в origin у нас не будет никаких следов этой ветки.
Вот и всё. Так и происходит весь процесс разработки. Одна ветка, master. Весь код в ней. Всё необходимое включается или выключается флагами. У всех разработчиков один и тот же, часто синхронизируемый друг с другом код. Всё остальное в ThreeFlow касается уже только стратегии релизов, а не разработки.
Релизы
Когда приходит время релиза (по графику или когда скажет руководство) делается «срез» ветки master в ветку релиз-кандидатов. Одна и та же ветка используется для всех релиз-кандидатов.
Предназначение данной ветки — дать билд, который получит команда QA для выполнения регрессионных (и других) тестов. Теоретически, новые фичи данного релиз-кандидата уже были проверены QA по ходу их разработки и включения, но, возможно, QA захотят перепроверить их в релиз-кандидате.
Для создания релиз-кандидата вы делаете что-то вроде этого:
$ git checkout candidate # предполагаем, что candidate указывает на origin/candidate
$ git pull # убедимся, что у нас актуальная копия репозитория
$ git merge --no-ff origin/master
$ git tag candidate-3.2.645
$ git push --follow-tagsПричина использования флага "--no-ff" здесь в том, что мы хотим создать merge-коммит (новый коммит с двумя родителями). Одним из его родителей будет предыдущий HEAD ветки релиз-кандидатов, а второй — HEAD ветки master. Это позволит вам легко отслеживать в истории кто и когда создал релиз-кандидат, а также что конкретно в него вошло (какие коммиты ветки master).
Также вы могли заметить, что мы создали тег для релиз-кандидата. Чуть детальнее об этом.
Если при тестировании релиз-кандидата обнаружатся баги, то они будут исправлены прямо в ветке релиз-кандидата, там же будет промаркирован новый релиз-кандидат, а изменения с исправлениями будут смерджены обратно в master. Эти изменения тоже должны быть применены с параметром "--no-ff", ведь мы хотим аккуратно показать, какой именно код был перемещен между ветками.
Когда релиз-кандидат протестирован и одобрен, мы обновляем ветку релизов таким образом, чтобы её HEAD указывал на HEAD ветки релиз-кандидатов. Поскольку у нас есть тег для каждого релиз-кандидата, то мы можем именно его запушить в ветку релизов:
$ git push --force origin candidate-3.2.647:releaseПараметр "--force" здесь означает, что мы игнорируем все изменения в ветке релизов и просто насильно устанавливаем её HEAD на тот же коммит, который обозначает последний созданный тег релиз-кандидата (candidate-3.2.647 в примере выше). Заметьте, что это вовсе не является слиянием (merge), но это потому, что нам оно здесь и не нужно. Мы не хотим усложнять историю в Git, да и вообще единственной причиной создания ветки релизов является теоретическая необходимость экстренного фикса обнаруженной на продакшене критической проблемы. Да, этот "--force" перетрёт все хотфиксы в ветке релизов. Но знаете, если вы релизите следующую версию продукта с новыми фичами в то же время, пока другой член вашей команды фиксит баги на продакшене — у вас серьёзные проблемы с управлением проектом и коммуникациями. Их стоит решить ещё до начала всех этих танцев вокруг веток и релизов. Фиксы в ветке релизов должны быть очень редкими и, конечно, должны быть потом смерджены в ветки релиз-кандидатов и master.
Причина, по которой мы используем "--force", а не merge в том, что при merge коммит в HEAD ветки релиз-кандидатов и коммит в HEAD ветки релизов могут иметь разные sha-1, а это не то, что нам нужно. Мы не хотим создавать новый коммит с релизом, мы хотим назвать релизом именно тот коммит, который был выбран релиз-кандидатом, который тестировался командой QA и был одобрен к релизу тем, кто за это отвечает. Именно это и делает "--force".

Если вы будете следовать этим рекомендациям, то история в вашем git-репозитории будет выглядеть очень похоже на рисунок выше, показывая в точности какие коммиты перемещались между ветками.
Release Notes
Вы можете легко генерировать «release notes» к новым релизам. Нужно всего лишь получить разницу между прошлым тегом релиза и текущим тегом релиз-кандидата. Поскольку в ветке релизов у нас лежит то, что когда-то точно было релиз-кандидатом, мы можем узнать каким именно:
$ git describe --tags release
candidate-3.1.248Теперь, когда мы знаем, что в релиз-кандидате у нас сейчас candidate-3.2.259, можно получить разницу между этими двумя тегами:
$ git log --oneline candidate-3.1.248..candidate-3.2.259Ну или даже проще, без тегов, просто сравниваем HEAD веток release и candidate:
$ git log --oneline release..candidateПрименяемые операции
Вот некоторые часто используемые операции при работе по ThreeFlow. Все примеры предполагают, что ваши локальные ветки правильно соотнесены с удалёнными ветками и содержат актуальные изменения. Если вы не уверены в этом — всегда будет хорошей идеей лишний раз сделать git fetch и потом использовать имена вроде origin/master вместо просто master
Как мне сделать релиз-кандидат из ветки master?
$ git checkout candidate
$ git pull
$ git merge --no-ff master
$ git tag candidate-3.2.645 #optionally tag the candidate
$ git push --follow-tagsКак мне сделать релиз из релиз-кандидата?
$ git push --force origin <tag for the candidate>:releaseЕсли вы почему-то решили не тегировать релиз-кандидаты, то придётся сделать:
$ git push --force origin candidate:releaseКак мне найти ветку, в которой есть некоторый конкретный коммит?
Иногда люди хотят убедиться, что какое-то конкретное изменение вошло в релиз-кандидат или в релиз. Вот как это проверить:
$ git branch -r -contains <sha of commit>Как мне найти тег, на который указывает HEAD некоторой ветки?
$ git describe --tags <branch>Как мне узнать, какие коммиты войдут в некоторый новый релиз?
$ git log --oneline release..<tag of release candidate>или:
$ git log --oneline release..origin/candidateКак мне настроить ветки релиз-кандидатов и релизов?
Любой проект начинается с первого коммита. Обычно это что-то простое, вроде добавления readme-файла. Я советую просто сделать ветки релиз-кандидатов и релизов из этого коммита. Что нам нужно получить, это первый merge-коммит с двумя родителями. Таким образом мы получим корректную историю. Так что подойдёт, в общем, любой коммит master-ветки. Почему бы не взять первый?
$ git branch candidate `git log --format=%H --reverse | head -1`
$ git checkout candidate
$ git pushЧтобы сделать ветку для релизов:
$ git branch release
$ git branch release --set-upstream-to=origin/releaseВопросы
А это разве описана не «модель кактуса»?
Вы можете подумать, что описанная в статье стратегия ветвления очень похожа на "модель кактуса", описанную Jussi Judin (тоже в качестве альтернативы GitFlow и тоже использующую ветку master для всей работы). Да, большей частью так оно и есть. Ключевым отличием является то, что Judin предлагает перемещать коммиты из ветки master в ветку релизов выборочно («cherry-picks»). Я категорически против этого. Выборочное перемещение коммитов — крайняя мера, которая должна использоваться в последнюю очередь при каком-то уж совсем катастрофическом состоянии master и большой необходимостью срочного релиза. Я предпочитаю использовать перемещение (rebase), а не слияние (merge). И избегать выборочности.
Другим отличием является существование в ThreeFlow ветки релиз-кандидатов, которую я принимаю как минимально необходимое зло. Лично моей целью является поддержание ветки master в таком состоянии, чтобы в каждый коммит можно было ткнуть пальцем и тут же спокойно выложить его в продакшн. Но я заметил, что многим коммандам трудно и некомфортно работать в таком режиме. Люди предпочитают иметь буффер в виде команды QA, которым нужно дать одобренный разработчиками билд («вот этот бери, а не вот тот, тот плохой») и получить от них фидбек о его качестве. И модель ThreeFlow даёт им такую возможность. В тщательно подходящим к качеству продукта командах различия между ветками релиз-кандидатов и релизов будут минимальными.
А это разве описана не GitFlow просто без веток для фич?
На самом деле я объяснял данную стратегию тем, кто до этого использовал GitFlow похожим образом: «Вы не используете ветки для фич, вся разработка идёт в ветке develop, которую мы теперь будем называть master, а то, что вы называли master мы будем называть веткой релизов». Основной идеей ThreeFlow была минимизация сложности. GitFlow поощряет создание новых сущностей (веток) по любому поводу (для фич, релизов, хотфиксов). Чем больше проект и чем дольше он идёт — тем страшнее выглядит его история. ThreeFlow стремиться минимизировать количество веток — никаких веток для фич или хотфиксов. Фичи пишутся в мастере, хотфиксы накатываются на релиз-кандидат или даже на релиз. И вместо кучи веток релизов у нас всегда есть то, что мы называем текущим релиз-кандидатом и текущим релизом. Всего лишь три ветки. Всегда.
Нам также не нужно придумывать систему именования веток (у нас их всего три и их имена константны): master, candidate, release.
Всегда есть ответ на вопрос «а куда положить мой код?». Если это хот-фикс проблемы на продакшене — в release. Если это фикс бага в релиз-кандидате — в candidate. Если это обычная ежедневная работа — в master.
Что на счёт ревью кода?
Если у вас есть правило ревьювить весь код перед тем, как он попадёт в основную ветку разработки, то будет логичным добавить ещё одну ветку (давайте назовём её develop — да, украдём это название у GitFlow, почему бы и нет). Итак, вся разработка будет идти в ней, а затем ревьювер будет переносить одобренные коммиты из неё в мастер (ну или просить их доработать). Конечно, нужно будет как-то отслеживать, что было перенесено, а что нет и это может вызвать затруднения. Нужно признать, что строгое следование идее ревью кода перед комитом в основную ветку может не сработать для вашей команды при использовании ThreeFlow или потребует дальнейшей адаптации этого подхода. Я слышал, что люди успешно применяли инструменты типа Gerrit для подобных целей, хотя сам его никогда не использовал.
Что на счёт кодовых баз, в которых хранятся несколько артефактов?
Во многих случаях в одной кодовой базе действительно хранится код, из которого может собираться несколько проектов. Эти индивидуальные артефакты сборки требуют отдельных циклов проверки QA-отделом, будут иметь отдельные версии релиз-кандидатов. Как ThreeFlow будет работать в данном случае?
Будет работать хорошо. Совсем недавно я как-раз работал в подобном проекте. У нас был один Git-репозиторий, из которого собиралось и деплоилось несколько разных артефактов. Решение очевидно: каждый артефакт добавляет в репозиторий по две ветки. Вы всё так же пишете весь код в master и работаете над фичами с помощью отключаемых флагов. Для этого вам не нужно знать, сколько и каких артефактов будет собираться из репозитория. Но вот дело доходит до релиза и здесь каждому артефакту становятся необходимыми свои ветки для релиз-кандидатов и релизов: foo_candidate, foo_release, bar_candidate, bar_release. Вот и всё.
Это масштабируется лучше, чем вы думаете. В одном из моих последних проектов у нас была одна большая кодовая база, из которой собиралось 4 разных артефакта. Кое-какой общий код, что-то индивидуально для каждого подпроекта — ну, вы понимаете. С одной стороны — 8 веток для релиз-кандидатов и релизов, плюс один master. Но с другой стороны — над каждым артефактом работала своя отдельная команда, и для каждой из них актуальными были лишь их три ветки, так что их общее количество мало кого волновало.
А можно как-то избежать набора дополнительных аргументов команд Git?
Одной из особенностей предлагаемого подхода является то, что почти каждая используемая команда действительно имеет дополнительные аргументы. Каждый раз, когда вы делаете слияние (merge), нужно не забыть добавить "--no-ff". Когда вы делаете релиз и тегируете его — я советую применять "--follow-tags" при пуше, чтобы сохранить теги в origin. Вы можете сделать так, чтобы эти теги применялись по-умолчанию:
$ git config --global merge.ff noТеперь вы можете использовать команду merge без параметра "--no-ff" (он будет добавляться неявно)
Аналогично с тегами при пуше:
$ git config --global push.followTags trueТакже можно настроить автоматический rebase при pull:
$ git config --global branch.master.rebase trueВы можете даже сделать так, чтобы все новые ветки автоматически ребейзелись при pull в случае если вы используете локальные ветки для работы над отдельными фичами:
$ git config --global branch.autosetuprebase alwaysТакже можно убрать ключ "--global" из вышеуказанных комманд, если вы хотите применить данные правила лишь к текущему репозиторию, а не ко всем вообще.
А можно я буду использовать слияние для релиз-ветки?
Ну, во-первых, вы свободный человек и можете делать всё, что захотите. Я просто описываю стратегию, которая хорошо работает для меня и некоторых других людей. Мне кажется, что она лучше, чем GitFlow (потому, что проще).
Во-вторых, да, если вам не нравится идея делать push с ключом "--force" и терять какую-то часть исторической информации, вы можете делать merge с ключом "--no-ff". Плюс тут ещё и в том, что не нужно запоминать разных способов переноса комита между ветками. Просто делайте себе merge --no-ff всегда, да и всё.
На самом деле первая версия ThreeFlow описывала как-раз именно такое поведение, слияние с параметром --no-ff для релизов. Это работало нормально, история была хорошо читаема. Единственное, что мне не нравилось, так это то, что артефакт сборки из релиз-ветки формально не был тем же коммитом, который до этого считался релиз-кандидатом и прошел через QA и утверждение к релизу. Получается, мы протестировали одно, потом сделали что-то другое и вот это другое релизнули. Плохо. Можно, конечно, заменить слияние на fast forwarding, но это тоже ведёт к потере информации, да ещё и не факт, что гарантированно удастся.
По моему мнению, push + force более ясно говорит о том, что содержимое релиза на самом деле не является веткой в терминологии цепочки наследуемых коммитов и не должно трактоваться так. Это просто указатель на актуальный код, который сейчас работает в продакшене. А сама ветка release просто указывает на серию тегов, которые когда-то выкладывались в продакшн. Ну и поскольку это всё-таки ветка с актуальным кодом, то вы всегда можете сделать хотфикс для продакшена прямо в ней.
Подытожим
Использовать Git без внятной стратегии ветвления — опасное дело. Поэтому возьмите вот эту:
- Есть три ветки: master, candidate, release
- Работаем в master. Все новые комиты добавляются с помощью перемещения (rebase).
- Фичи в процессе разработки отключаются флагами. Включаются тогда, когда будут готовы.
- Когда приходит время сделать релиз-кандидата — он делается из master путём слияния (merge с ключом "--no-ff") его коммитов с веткой candidate
- Все баги, которые QA найдут в релиз-кандидате, фиксятся прямо там и затем вливаются (тот же merge с ключом "--no-ff") в master
- Когда принимается решение выложить релиз-кандидат в продакшн, он пушится с ключом "--forced" в ветку release
- Все хотфиксы для продакшена делаются на ветке release и затем вливаются в candidate и master

Вот и всё. По моему мнению ThreeFlow это одна из простейших стратегий ветвления для Git, которая в то же время даёт вам всё необходимое.
Попробовали и вам подошло? Попробовали и не подошло? Почитали описание и считаете того, кто предлагает использовать "--force" в качестве регулярной операции, полным идиотом? Не стесняйтесь рассказать об этом в комментариях!
