
Господа, хватит уже рассматривать ссылки исключительно в контексте их количества, купли/продажи и считать PR сайта, где они расположены. Пора заботиться не о роботах, а о людях. Работать с интернетом становится все невыносимее. Цветут и множатся фермы автогенерируемых сайтов с говнотекстами, да простят меня дамы. Из-за них невозможно найти даже технические материалы, не говоря про обыкновенные. Но я бы так не переживал про поиск технических материалов, если бы в них были корректные ссылки. Ссылки дохнут как мухи и, читая пост годичной давности в форуме или блоге, нет почти никаких надежд перейти по указанным ссылкам.
Я считаю нерабочие ссылки очень большой проблемой современного интернета, хотя про нее как-то не говорят или не задумываются. Думаю пора делать хоть что-то. Мы уже что-то делаем, про это и расскажу. Надеюсь, пример кого-то воодушевит, и он тоже захочет позаботиться о своих пользователях.
Неработающих ссылок в интернете такое количество, что даже невозможно выбрать что-то для примера. Каждый сталкивался, что прочитав интересную информацию о чем то, он уверенно нажимал на ссылку и попадал в никуда. Причем конечная цель обычно вовсе не мертвый сайт, а вполне живой. Причем настолько живой, что постоянно правится без заботы о перенаправлении пользователей приходящих с внешних ресурсов. Впрочем, часто не заботятся и о переходах с внутренних ресурсов. Хороший тому пример статьи в MSDN.
Кто-то возразит, что в том, что материал куда то переехал, нет ничего страшного. Его всегда можно легко найти в Google. Во-первых даже если можно, то это тратит огромное количество времени. И эта большая проблема. Один единственный, но полезный ресурс, перемещенный по прихоти администратора сайта, отнимет время у тысяч, а в некоторых случаях и миллионов людей. Каждый из них будет вынужден искать нужный материал и переходить по ссылкам.
В других случаях найти материал бывает крайне сложно или тот, кому он нужен, не может это сделать. Приведу два примера, когда «отправляйтесь в Google» не помогает.
Первый пример. Для того чтобы выпустить плагин для Microsoft Visual Studio необходимо для каждой версии получать на сайте Microsoft специальный ключ (PLK). Несколько лет этот ключ выдавали на странице msdn.microsoft.com/en-us/vsx/cc655795.aspx (ссылка не работает). Пару месяцев назад кто-то решил, что называть раздел «vsx» идеологически не верно, и его переименовали в «vstudio», соответственно ссылка стала новой http://msdn.microsoft.com/en-us/vstudio/cc655795.aspx. Но ВЕЗДЕ включая сайты Microsoft ссылки были старыми, а не новыми. Поиск Google также выдавал только старую ссылку, поскольку новая нигде не фигурировала. Помогли в форуме Microsoft, где явно указали новую страницу. Вопрос — кому-то стало лучше от того, что поменяли ссылку? Какое количество людей по всему миру было вынуждено искать ответ на этот вопрос? Если так хочется поменять ссылку, неужели было сложно сделать редирект?
А вот другой, более эмоциональный пример. Есть такая книга «C# для школьников», выпущенная при поддержке Microsoft и ориентированная на детей 12-16 лет.

Я лично не уверен, что в таком возрасте рационально заниматься изучением C#, но книга в целом производит весьма приятное впечатление. По крайне веселых поясняющих картинок там очень и очень много.
Так вот представьте, сколько сил люди приложили, чтобы создать такую книгу. Кем-то была придумана рекламная инициатива Microsoft познакомить детей с C# еще в школе, человек книгу написал, затем ее переводили, художник рисунки перерисовывал, чтобы текст был на русском и, наверное, на других языках. Было потрачено много денег и времени. И какой результат? А уверен, что никакого!
Я очень сомневаюсь, что ребенок продвинется дальше «Часть 1. Первое знакомство», ибо там ему объясняется о необходимости скачать и установить Microsoft Visual C# 2008 Express Edition. Я не сомневаюсь в способностях школьника. Starcraft 2 они без сторонней помощи выкачивают и устанавливают, а в разных iPhone лучше меня разбираются. Все банальнее. Просто там предлагается скачать с адреса, которого уже не существует:

Результат перехода:
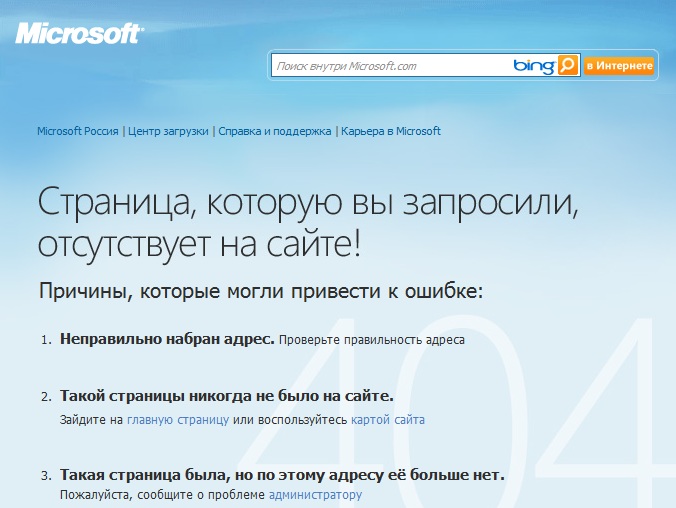
И спрашивается, зачем было заниматься с созданием этой книги, если все разбивается о бездумное перекладывание данных на сайте с места на место? Я очень сомневаюсь, что школьник тринадцати лет после этого отправится в Google искать для скачивания чудо-зверя «Microsoft Visual C# 2008 Express Edition». С вероятностью 90% на этой главе с изучением C# все будет покончено.
Да, может показаться, что я критикую Microsoft. Нет, на других сайтах не лучше, просто такие примеры получились.
Какие я делаю из всего этого выводы?
Очень легко испортить весь свой материал, пост в блоге, сервис, книгу или любой другой проект из-за того что кто-то другой (или вы сами) возьмет и поменяет адрес ресурса на который вы ссылаетесь. После этого ценность вашего творения если не станет равна нулю, то по крайней станет значительно ниже, так как вашим читателям/пользователям придется тратить нервы и время на самостоятельный поиск нужной ссылки.
Как мы решаем эту проблему
Мы пишем технические статьи и часто ссылаемся на различную документацию, инструменты, записи в сторонних блогах. Как следствие мы также часто сталкиваемся с проблемой перемещения материалов и статей на сторонних сайтах. Особенно этим почему-то грешат такие сайты крупных компаний, как Microsoft, Intel или AMD. Они перемещают целые разделы и в результате, например, искать помощи в статьях сотрудников Microsoft/Intel, которым исполнился хотя бы год весьма неблагородное дело. На какую ссылку не кликни — попадаешь в никуда. Думаю, что многие программисты поймут мои переживания.
Уверен многим на это наплевать, не работает переход куда-то, ну и ладно. Собственно так и есть, раз в интернете такое количество мертвых ссылок. Однако мы пишем статьи для людей, а не для поисковых систем. И заявляю я об этом с гордостью. Хоть миллионы не заработали пока, но хоть на минутку хочется себя д'Артаньяном почувствовать.
Так вот, нам важно чтобы в статьях были корректные ссылки не только на материалы на нашем собственном сайте, но и на внешние сайты. Следовательно, нам необходимо исправлять те ссылки, которые начинают вести в никуда. Задача осложняется тем, что мы публикуем наши статьи на многих других сайтах. И естественно править ссылки в них нет никаких сил, а иногда и технической возможности.
Естественным решением является создание системы редиректа. Я расскажу как у нас все это работает, возможно, кто-то захочет сделать у себя нечто подобное. Я даже очень хочу, чтоб кого-то это заинтересовало, так надоели дороги в никуда!
Система состоит из базы, хранящей пару короткая ссылка — ссылка на внешний ресурс. Пользовательский интерфейс добавления ссылок достаточно прост и показан на рисунке ниже.
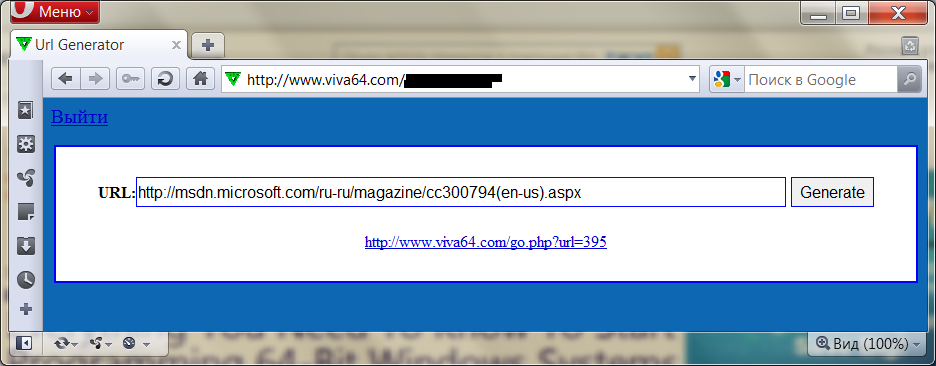
Просто вводим ссылку на внешнем ресурсе и получаем короткую ссылку для вставки в статьи, блоги и так далее. Если адрес внешнего ресурса уже находится в базе, то возвращается уже созданная ранее короткая ссылка:
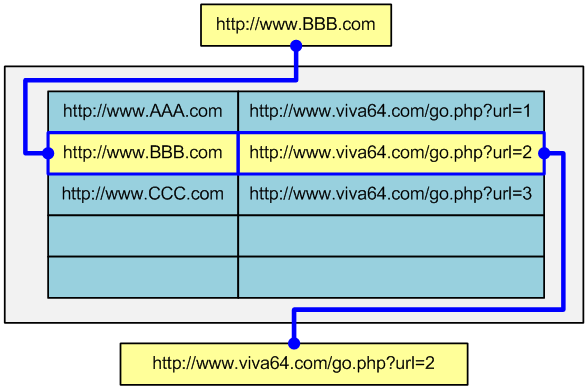
Если в базе такой ссылки нет, то создается новая пара и генерируется новая короткая ссылка:
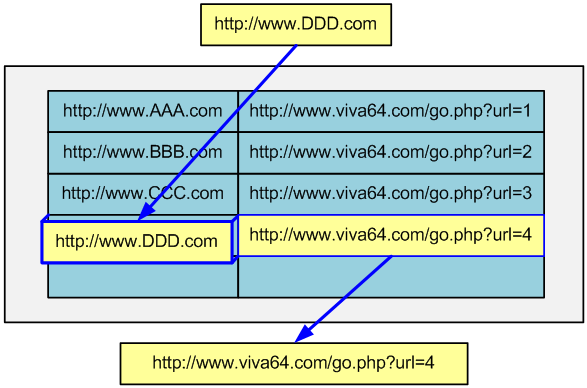
Технически запись хранится в базе данных в таблице links и представляет собой набор следующих полей:
- id — первичный ключ
- num — номер ссылки, как раз по этому номеру определяется какую ссылку достанет из базы скрипт qwerty.php
- link — собственно сам текст ссылки
- link_category_id — номер категории в которой находится ссылка, для работы скрипта это поле несущественно, но для удобства пользователя введены категории ссылок
При нажатии кнопки «Generate» сайту viva64.com посылается запрос, содержащий адрес ссылки, которую необходимо добавить. Скрипт обрабатывающий запрос выглядит примерно так:
$sql = "select * from links where link='".$add_url."'";
$link = mysql_query($sql);
if(mysql_num_rows($link)){
$row = mysql_fetch_array($link,MYSQL_ASSOC);
$new_url = "http://www.viva64.com/qwerty.php?url=".$row['num'];
}
else{
$sql = "select * from links order by num desc";
$link = mysql_query($sql);
$row = mysql_fetch_array($link, MYSQL_ASSOC);
$last_num = $row['num']+1;
$sql = "insert into links (num,link) values
(".$last_num.",'".$add_url."')";
$link = mysql_query($sql);
$new_url = "http://www.viva64.com/qwerty.php?url=".$last_num;
}Скрипт получает этот адрес переменной $add_url и проверяет, есть ли в базе данных такой адрес:
$sql = "select * from links where link='".$add_url."'"; $link = mysql_query($sql);
Если есть, то в переменную $new_url будет просто записана ссылка для вызова скрипта перенаправления с идентификатором адреса полученного из базы:
if(mysql_num_rows($link)){
$row = mysql_fetch_array($link,MYSQL_ASSOC);
$new_url = "http://www.viva64.com/qwerty.php?url=".$row['num'];
}Если же адрес не найден, то произойдет вычисление максимального уникального идентификатора адреса из тех, что содержаться в таблице links и добавление новой записи в базу данных с инкрементированным максимальным идентификатором, после чего в переменную $new_url записывается значение новой ссылки для вызова скрипта перенаправления:
else{
$sql = "select * from links order by num desc";
$link = mysql_query($sql);
$row = mysql_fetch_array($link, MYSQL_ASSOC);
$last_num = $row['num']+1;
$sql = "insert into links (num,link) values
(".$last_num.",'".$add_url."')";
$link = mysql_query($sql);
$new_url = "http://www.viva64.com/qwerty.php?url=".$last_num;
}После чего пользователь получает ссылку перенаправления, независимо от того была ли добавлен новый адрес в базу данных или же просто получена один из уже существующих
Механизм перенаправления
Скрипт перенаправления на сайте viva64.com не сложен. По сути все, что он делает, это принимает номер ссылки в качестве параметра, затем получает из базы данных саму ссылку с таким номером и осуществляет переадресацию по ссылке. В коде это выглядит:
$s = substr($HTTP_GET_VARS['url'], 0, 15);
$u = "http://www.viva64.com/";
$isConnect = mysql_connect($sqlserver,$sqluser,$sqlpassword);
if($isConnect){
$isSelectDatabase = mysql_select_db($database);
if($isSelectDatabase){
$currentLink = $s;
$sql = "SELECT * FROM links WHERE num='".$currentLink."'";
$link = mysql_query($sql);
if($link && mysql_num_rows($link)){
$row = mysql_fetch_array($link,MYSQL_ASSOC);
$u = $row['link'];
}
}
}
print Header('Location: '.$u);Поиск и исправление неработающих ссылок
Задача поиска неработающих ссылок решается средствами программы Fast Link Checker. Программа обходит все страницы сайта и пытается пройти по всем найденным ссылкам. Затем результаты фильтруются и, на заранее заданные e-mail адреса, отправляется письмо со списком неработающих ссылок. Запуск программы автоматизирован, раз в неделю происходит проверка работоспособности ссылок.
После определения неработающей ссылки вручную осуществляется поиск материала, на который указывает ссылка. Обычно можно легко определить новый адрес, по которому доступен материал. На таких сайтах как Microsoft, Intel, AMD очень любят просто перенести материал в другой раздел.
Если найти этот или практически идентичный ресурс невозможно, что бывает крайне редко, то ссылка удаляется из статей сайта. На внешних сайтах ссылка в нашей статье будет указывать в никуда, но тут уже ничего сделать невозможно. Раз пропал некоторый материал/сайт, значит пропал.
Когда новая ссылка определена она заносится в базу данных и таким образом во всех статьях сайта ссылка снова рабочая.
Для изменения ссылки через интерфейс администратора будет выполнен запрос вида:
UPDATE 'links' SET 'link' = 'http://msdn.microsoft.com/en-us/isv/bb190527.aspx' WHERE 'links'.'numn = 341 LIMIT 1 ;
Совсем уж в подробно работу системы я расписывать не стал, я, если честно пользователь это системы, а не разработчик. Но если будет интерес со стороны читателей, то мой коллега Антон Дубровин опишет все подробнее и ответит на вопросы.
Инициатива для Intel
Сам я не сотрудник Intel, но знаю, что этот блог читают многие из сотрудников компании. Именно поэтому я пишу сюда, так как хочу предложить инициативу. Я знаю что Intel постоянно проводит различные программы и летние школы, где стажируются студенты, выполняя различные интересные задания. Если кто-то из читателей Хабрахабре не в курсе, то вот несколько ссылок по этой тематике: 1, 2, 3, 4.
Хочу предложить в качестве одного из заданий поразмышлять над реализацией системы, которая позволит содержать имеющихся ссылки на сайте Intel в адекватном состоянии. К сожалению нерабочих ссылок на сайте Intel, пожалуй не меньше чем на сайте Microsoft. Начать можно с небольшой части. Например, подумать, над поддержкой русскоязычной части ISN (статей, форумов, блогов). То что я описал в статье, это все таки некоторая поделка, решающая только одну задачу и очень узко. А проблема неверных ссылок требует более серьезных исследований и работы.
Заранее спасибо тем, кто захочет тоже немного улучшить мир.
