Я работаю с программными моделями центральных процессоров в составе полноплатформенного симулятора. Занятие это, конечно же, очень интересное — приходится иметь дело с технологиями интерпретации, двоичной трансляции, виртуализации (об этом я уже писал здесь). Однажды моё внимание привлёк тот факт, что значительную часть времени я вожусь над единственной, казалось бы, не самой вычислительно интенсивной инструкцией. Причина в том, что типов процессоров существует много, и все они во многом похожи; однако при этом критически важно очень точно представлять различия между ними.
В этой статье я описываю, зачем и как процессоры умеют сообщать о своих возможностях, и как к этому вопросу подошли разные производители. В её продолжении я расскажу об эволюции и особенностях инструкции CPUID для Intel IA-32, например, почему её описание занимает в Intel SDM [1] около 40 страниц.

Для начала хочу заострить внимание на привычном и потому не слишком удивительном факте: одна и та же программа для ПК без всяких переделок двоичного кода может запускаться на системах, различно устроенных внутри. Ведь у ЦПУ разных производителей, разных поколений и внутреннее строение не повторяется: размеры транзисторов другие, частота варьируется, память по-другому организована, конвеер имеет различное число стадий и т.д. Иногда и процессора-то никакого нет — вместо него виртуальная машина подсунула что-то странное. Тем не менее, один и тот же двоичный код почти всегда работает! Это возможно благодаря договорённости разработчиков аппаратуры и программистов, закреплённой в форме спецификации на набор инструкций (ISA, instruction set architecture). Неизменность этого интерфейса — зачастую залог коммерческого успеха начинания в микропроцессорной индустрии.
И всё же, почти каждая «взрослая» архитектура центрального процессора за время своей эволюции обзаводится разными расширениями ISA. Они приносят улучшения в скорости вычислений, понижение энергопотребления, средства обеспечения безопасности, ускорения шифрования, обработки сигналов, виртуализации и т.д. Возникает противоречивая ситуация: с одной стороны, есть нужда в стабильности; с другой — постоянные добавки от конкурирующих производителей.
Расхлёбывать приходится программистам, если не прикладным, то писателям операционных систем и компиляторов так точно. Их программы должны «уметь» различать особенности той аппаратуры, на которой они запущены, и выбирать ветви исполнения, оптимально задействующие обнаруженные расширения.
В спецификациях на архитектуры процессоров для этого обычно описываются средства идентификации в виде специализированных регистров и инструкций. Однажды мне стало интересно — какие различия существуют в том, какую информацию, насколько подробно и в каком формате разные вендоры доносят до системных программистов?
Предлагаю краткий обзор средств идентификации ряда популярных семейств центральных процессоров. Я подготовил его с помощью изучения доступной в Интернете документации, собственных экспериментов там, где удалось заполучить железку и найти время на поиграться, изучения исходников архитектурно-зависимых частей ядер открытых операционных систем, таких как Linux и FreeBSD, а также благодаря обсуждениям с друзьями, занятыми разработкой системного ПО под эти архитектуры. В каждом случае я буду оценивать полную ёмкость предоставляемого архитектурного состояния в битах.
Архитектура MIPS32 [6, 7] (ныне принадлежащая Imagination Technologies) хранит идентификационную информацию в регистре PRid — 15-ый регистр нулевого сопроцессора [8]. В нём содержится всего 32 бита:
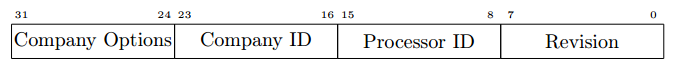
Кроме того, для описания возможностей модуля работы с числами с плавающей запятой (FPU) задействован Floating Point Implementation Register (FIR). Он также работает только на чтение и имеет ширину в 32 бита.

Эта популярная RISC архитектура не балует разработчиков удобными средствами идентификации присутствующих расширений. Такой вывод можно сделать из того факта, что унификация кода поддержки ARM в Linux была произведена лишь в релизе 3.7. Примерно такое же мнение высказал один мой знакомый разработчик из Samsung. Меня это несколько удивляет, учитывая, что ARM — архитектура, с которой процессоры выпускают многие вендоры. Почему это так, я попробую порассуждать ближе к концу этой заметки.
32-разрядный регистр cpuid [10] из состава System Сontrol Сoprоcessor определяет несколько свойств, включая код вендора и ревизию:

Примеры значений этого регистра для разных продуктов: Intel (XScale) PXA272 – 0x69054117, Qualcomm MSM7200A — 0x4117b362.
Значительно больше информации можно получить через Debug-регистры, однако для этого потребуются привилегии ядра. Теоретически в 18 регистрах по 32 бита каждой можно закодировать 576 бит. Пользователь yulyugin написал модуль ядра Linux [2] и собрал данные для ARM1176JZFS, используемого в Raspberry Pi, за что ему большое спасибо.

IBM System z [4], ведущая родословную от мейнфреймов, сильно отличается в организации от более привычных большинству систем, произошедших от «калькуляторов». Но и на мейнфреймах необходимо было уметь распознавать расширения, которых с 60-х годов могло набраться немало. Для этого в архитектуре есть инструкции STSI и STIDP.
STSI используется для получения информации о модели, идентификатор ёмкости базовой конфигурации.
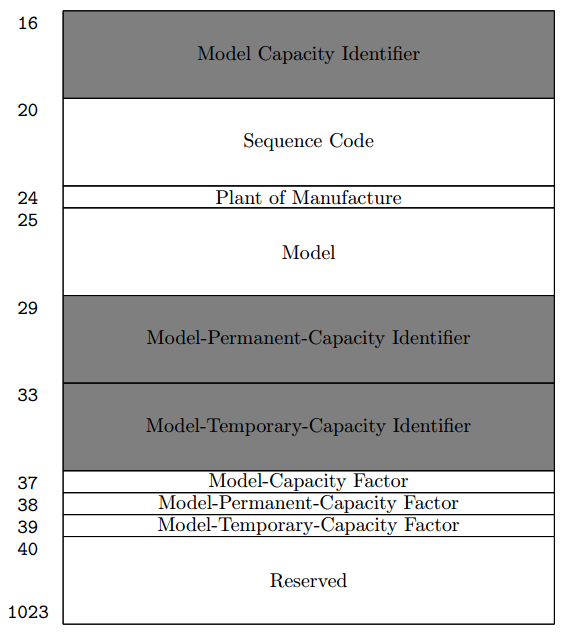
В 44 регистрах по 32 бита можно поместить около 1,4 кбит данных.
STIDP сообщает тип процессора, серийный номер и идентификатор логической партиции, которые используются для виртуализации.

Единственный в PowerPC [5] регистр PVR имеет ширину в 32 бита и содержит лишь идентификатор вендора и ревизию.

Однако, для расширения ISA предусмотрен механизм APU (application processor units) — отдельных «устройств», предоставляющих декодирование и исполнение дополнительных команд. К сожалению, я не смог найти подробной информации о том, можно ли программно перечислить все доступные APU. Буду признателен, если мне подскажут.
Стандарт SPARC v9 [9] с самого начала не был привязан к какому-либо вендору и поэтому его спецификации смотрятся очень «политкорректно». Сравнительно много пунктов в документации намеренно помечены как «зависящие от реализации». Для идентификации введён 64-битный регистр VER:

Intel IA-64, также известный как Itanium, был спроектирован после серии Intel 80x86 и изначально был предназначен для вытеснения последнего (что было дальше — уже история). Неудивительно, что набор регистров cpuid, используемых для идентификации IA-64 [8], отдалённо напоминает структуру вывода инструкции CPUID на Intel IA-32 a.k.a x86.
В данный момент системы IA-64 предлагают до пяти регистров cpuid. В случае, если потребуется расширение в будущем, биты 0–7 в составе cpuid3 хранят полное число таких регистров (т.е. максимально их может быть 256).
Содержимое регистров cpuid для Intel Itanium 9100 (кодовое имя Montvale), полученное с помощью программы ggg-cpuid [2]:

Полную ёмкость данных об идентификации можно оценить как 5 × 64 = 320 бит.
Всем знакомые современные ПК, произошедшие от IBM PC, используют Intel IA-32. Начиная с Intel Pentium (и его клонов), в процессорах данной архитектуры есть инструкция CPUID. 64-битное расширение, известное как Intel 64 [1] или AMD64 [3], не внесло принципиальных изменений в её работу, поэтому не будем их различать в дальнейшем.
CPUID принимает на вход два 32-битных значения в EAX и ECX, называемых лист и подлист (англ. leaf и subleaf), и помещает результаты в четыре 32-битных регистра: EAX, EBX, ECX и EDX. Отмечу, что в 64-битном режиме всё равно используются только 32 бита всех регистров.
Теоретически лист и подлист кодируют 64 бита ключа, а вывод содержит 128 бит данных. К счастью, далеко не все комбинации к настоящему моменту допустимы. К несчастью, комбинации листов с подлистами имеют специфическую логику. С момента введения команды объём вывода CPUID (т.е. число допустимых комбинаций листов и подлистов) был расширен во много раз.
CPUID достаточно интересна, чтобы посвятить ей отдельную статью. Здесь скажу лишь, что по её выводу можно понять, сколько ядер есть у процессора, как устроены его кэши, какие инструкции в нём присутствуют, ну и, конечно же, кто его произвёл.
Вывод CPUID для Intel Xeon CPU E5-2690, полученное с помощью ggg-cpuid [2]:
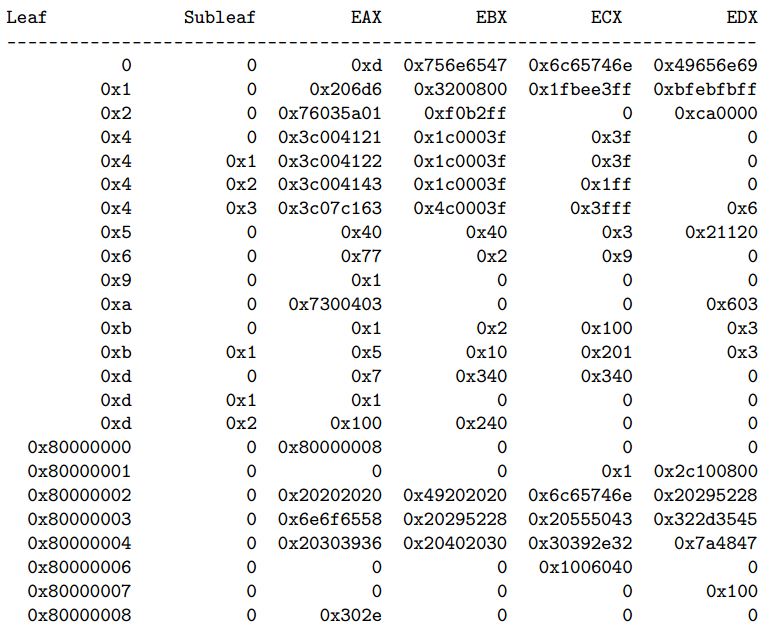
В текущем своём состоянии CPUID способно закодировать около 3 кбит данных.
Настоящего сравнения, увы, тут не будет. Уж слишком различными по составу заявляемых расширений оказываются разные процессоры. Но общее всё-таки есть. Все рассмотренные системы позволяют выяснить как минимум два параметра: производителя и некоторый номер «ревизии» процессора. Действительно, это представляется минимальным необходимым набором для идентификации. Если хранить в программном приложении таблицу соответствия «вендор» → «продукт» → «список расширений», то оно сможет однозначно идентифицировать свойства конкретной железки, на которой его запустили. Именно такой подход, кстати, я обнаружил в исходниках операционных систем: один или два (вложенных) больших switch'а.
Нельзя сказать, что минимализм этот удобен. Во-первых, надо как-то сформировать и хранить такую таблицу, а для этого придётся перерыть изрядное количество документации и провести натурных экспериментов. Во-вторых, налицо крайняя негибкость получаемого кода по отношению к будущим системам. Достаточно новому вендору выйти на рынок или уже присутствующему выпустить совместимый вроде бы ЦПУ с новым номером ревизии, и такая программа не сможет распознать его без обновления таблицы с последующей перекомпиляцией. Использование битовых масок для кодирования доступных расширений позволяет «старому» коду игнорировать новые расширения, но узнавать известные, что полезно для обратной совместимости.
Что действительно разнится у всех архитектур, так это объём предоставляемых данных идентификации. В этом графике я собрал вместе приблизительные значения ёмкости связанного с этим архитектурного состояния в битах для всех описанных выше процессоров.

Затем я попытался найти какую-то корреляцию значений от особенностей каждой архитектуры, но не очень преуспел. Например, «возраст» системы не влияет на объём данных. Вообще довольно сложно определить возраст архитектуры, так как одна часто растёт из другой. Сначала я хотел написать, что system z была объявлена в 2005 году, но вспомнил, что происходит она от System/360, которая появилась в 1960-x. Та же история с Intel IA-32. Идентификация для неё в современном виде появилась в 1993 году (что было до этого, я напишу во второй части); но 8086-то родом из 1970-х! Intel IA-64 (объявленный в начале двухтысячных) просто не успел вобрать в себя несчётные расширения, чтобы суметь «блеснуть» запутанным содержимым cpuid. MIPS и ARM тоже нельзя назвать молодыми системами, они уже существовали как минимум в 1980-х, но вот надёжной идентификацией как-то не прирасли.
Что мне показалось на самом деле наблюдаемым, так это факт зависимости количества и качества средств идентификации расширений от свойства «встраиваемости» архитектуры. Если система изначально была предназначена для рынка встраиваемых систем, в которых переносимость двоичного кода не является продающим фактором, то средства идентификации у неё относительно скромны. Наоборот, рынок ПК, ЦПУ для которых в своё время производили чуть ли не десять компаний (с удивлением вчера узнал, что клон 8086 был даже у Siemens!), а диапазон применений архитектуры варьируется от IoT до суперкомпьютеров со специализированными ускорителями, продиктовал необходимость в чёткой дифференциации одновременно с переносимостью двоичного кода, что привело к «разбуханию» IA-32 CPUID до невероятных размеров.
В этом небольшом обзоре мне не удалось достаточно подробно расписать детали идентификации конкретных моделей ЦПУ с примерами. Также некоторые менее популярные семейства процессоров вообще не были упомянуты: ARC, Alpha, AVR, Z80, 68000, 6502, Cell, Эльбрус… И, если для Intel IA-32 я ещё могу попробовать сделать подробное описание, то по другим архитектурам, увы, мои знания достаточно скудны. Однако, я надеюсь постепенно добраться и до них. Поэтому я буду признателен, если в комментариях читатели поделятся ссылками на документацию или просто расскажут о своём опыте работы с кодом, требующим идентификации расширений процессора.
Спасибо за внимание!
В этой статье я описываю, зачем и как процессоры умеют сообщать о своих возможностях, и как к этому вопросу подошли разные производители. В её продолжении я расскажу об эволюции и особенностях инструкции CPUID для Intel IA-32, например, почему её описание занимает в Intel SDM [1] около 40 страниц.

Зачем нужна идентификация процессоров
Для начала хочу заострить внимание на привычном и потому не слишком удивительном факте: одна и та же программа для ПК без всяких переделок двоичного кода может запускаться на системах, различно устроенных внутри. Ведь у ЦПУ разных производителей, разных поколений и внутреннее строение не повторяется: размеры транзисторов другие, частота варьируется, память по-другому организована, конвеер имеет различное число стадий и т.д. Иногда и процессора-то никакого нет — вместо него виртуальная машина подсунула что-то странное. Тем не менее, один и тот же двоичный код почти всегда работает! Это возможно благодаря договорённости разработчиков аппаратуры и программистов, закреплённой в форме спецификации на набор инструкций (ISA, instruction set architecture). Неизменность этого интерфейса — зачастую залог коммерческого успеха начинания в микропроцессорной индустрии.
И всё же, почти каждая «взрослая» архитектура центрального процессора за время своей эволюции обзаводится разными расширениями ISA. Они приносят улучшения в скорости вычислений, понижение энергопотребления, средства обеспечения безопасности, ускорения шифрования, обработки сигналов, виртуализации и т.д. Возникает противоречивая ситуация: с одной стороны, есть нужда в стабильности; с другой — постоянные добавки от конкурирующих производителей.
Расхлёбывать приходится программистам, если не прикладным, то писателям операционных систем и компиляторов так точно. Их программы должны «уметь» различать особенности той аппаратуры, на которой они запущены, и выбирать ветви исполнения, оптимально задействующие обнаруженные расширения.
В спецификациях на архитектуры процессоров для этого обычно описываются средства идентификации в виде специализированных регистров и инструкций. Однажды мне стало интересно — какие различия существуют в том, какую информацию, насколько подробно и в каком формате разные вендоры доносят до системных программистов?
Сравнение разных архитектур
Предлагаю краткий обзор средств идентификации ряда популярных семейств центральных процессоров. Я подготовил его с помощью изучения доступной в Интернете документации, собственных экспериментов там, где удалось заполучить железку и найти время на поиграться, изучения исходников архитектурно-зависимых частей ядер открытых операционных систем, таких как Linux и FreeBSD, а также благодаря обсуждениям с друзьями, занятыми разработкой системного ПО под эти архитектуры. В каждом случае я буду оценивать полную ёмкость предоставляемого архитектурного состояния в битах.
MIPS32
Архитектура MIPS32 [6, 7] (ныне принадлежащая Imagination Technologies) хранит идентификационную информацию в регистре PRid — 15-ый регистр нулевого сопроцессора [8]. В нём содержится всего 32 бита:
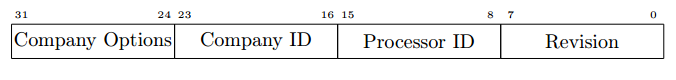
Кроме того, для описания возможностей модуля работы с числами с плавающей запятой (FPU) задействован Floating Point Implementation Register (FIR). Он также работает только на чтение и имеет ширину в 32 бита.

ARM
Эта популярная RISC архитектура не балует разработчиков удобными средствами идентификации присутствующих расширений. Такой вывод можно сделать из того факта, что унификация кода поддержки ARM в Linux была произведена лишь в релизе 3.7. Примерно такое же мнение высказал один мой знакомый разработчик из Samsung. Меня это несколько удивляет, учитывая, что ARM — архитектура, с которой процессоры выпускают многие вендоры. Почему это так, я попробую порассуждать ближе к концу этой заметки.
32-разрядный регистр cpuid [10] из состава System Сontrol Сoprоcessor определяет несколько свойств, включая код вендора и ревизию:

Примеры значений этого регистра для разных продуктов: Intel (XScale) PXA272 – 0x69054117, Qualcomm MSM7200A — 0x4117b362.
Значительно больше информации можно получить через Debug-регистры, однако для этого потребуются привилегии ядра. Теоретически в 18 регистрах по 32 бита каждой можно закодировать 576 бит. Пользователь yulyugin написал модуль ядра Linux [2] и собрал данные для ARM1176JZFS, используемого в Raspberry Pi, за что ему большое спасибо.
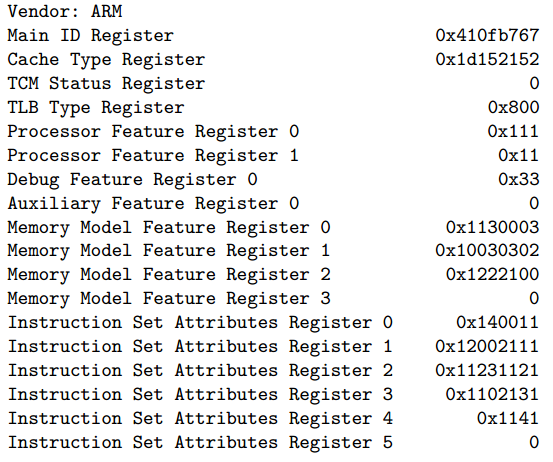
IBM system z
IBM System z [4], ведущая родословную от мейнфреймов, сильно отличается в организации от более привычных большинству систем, произошедших от «калькуляторов». Но и на мейнфреймах необходимо было уметь распознавать расширения, которых с 60-х годов могло набраться немало. Для этого в архитектуре есть инструкции STSI и STIDP.
STSI используется для получения информации о модели, идентификатор ёмкости базовой конфигурации.
В 44 регистрах по 32 бита можно поместить около 1,4 кбит данных.
STIDP сообщает тип процессора, серийный номер и идентификатор логической партиции, которые используются для виртуализации.

PowerPC
Единственный в PowerPC [5] регистр PVR имеет ширину в 32 бита и содержит лишь идентификатор вендора и ревизию.

Однако, для расширения ISA предусмотрен механизм APU (application processor units) — отдельных «устройств», предоставляющих декодирование и исполнение дополнительных команд. К сожалению, я не смог найти подробной информации о том, можно ли программно перечислить все доступные APU. Буду признателен, если мне подскажут.
SPARC
Стандарт SPARC v9 [9] с самого начала не был привязан к какому-либо вендору и поэтому его спецификации смотрятся очень «политкорректно». Сравнительно много пунктов в документации намеренно помечены как «зависящие от реализации». Для идентификации введён 64-битный регистр VER:

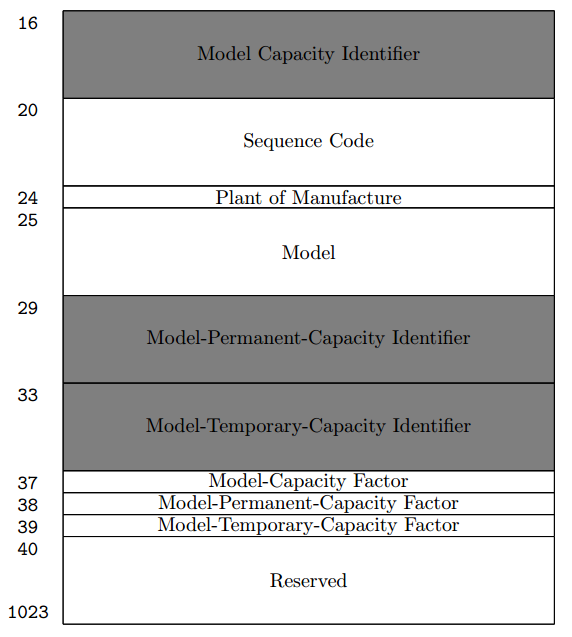
Intel IA-64 (Itanium)
Intel IA-64, также известный как Itanium, был спроектирован после серии Intel 80x86 и изначально был предназначен для вытеснения последнего (что было дальше — уже история). Неудивительно, что набор регистров cpuid, используемых для идентификации IA-64 [8], отдалённо напоминает структуру вывода инструкции CPUID на Intel IA-32 a.k.a x86.
В данный момент системы IA-64 предлагают до пяти регистров cpuid. В случае, если потребуется расширение в будущем, биты 0–7 в составе cpuid3 хранят полное число таких регистров (т.е. максимально их может быть 256).
Содержимое регистров cpuid для Intel Itanium 9100 (кодовое имя Montvale), полученное с помощью программы ggg-cpuid [2]:
Полную ёмкость данных об идентификации можно оценить как 5 × 64 = 320 бит.
Intel IA-32 и Intel 64
Всем знакомые современные ПК, произошедшие от IBM PC, используют Intel IA-32. Начиная с Intel Pentium (и его клонов), в процессорах данной архитектуры есть инструкция CPUID. 64-битное расширение, известное как Intel 64 [1] или AMD64 [3], не внесло принципиальных изменений в её работу, поэтому не будем их различать в дальнейшем.
CPUID принимает на вход два 32-битных значения в EAX и ECX, называемых лист и подлист (англ. leaf и subleaf), и помещает результаты в четыре 32-битных регистра: EAX, EBX, ECX и EDX. Отмечу, что в 64-битном режиме всё равно используются только 32 бита всех регистров.
Теоретически лист и подлист кодируют 64 бита ключа, а вывод содержит 128 бит данных. К счастью, далеко не все комбинации к настоящему моменту допустимы. К несчастью, комбинации листов с подлистами имеют специфическую логику. С момента введения команды объём вывода CPUID (т.е. число допустимых комбинаций листов и подлистов) был расширен во много раз.
CPUID достаточно интересна, чтобы посвятить ей отдельную статью. Здесь скажу лишь, что по её выводу можно понять, сколько ядер есть у процессора, как устроены его кэши, какие инструкции в нём присутствуют, ну и, конечно же, кто его произвёл.
Вывод CPUID для Intel Xeon CPU E5-2690, полученное с помощью ggg-cpuid [2]:
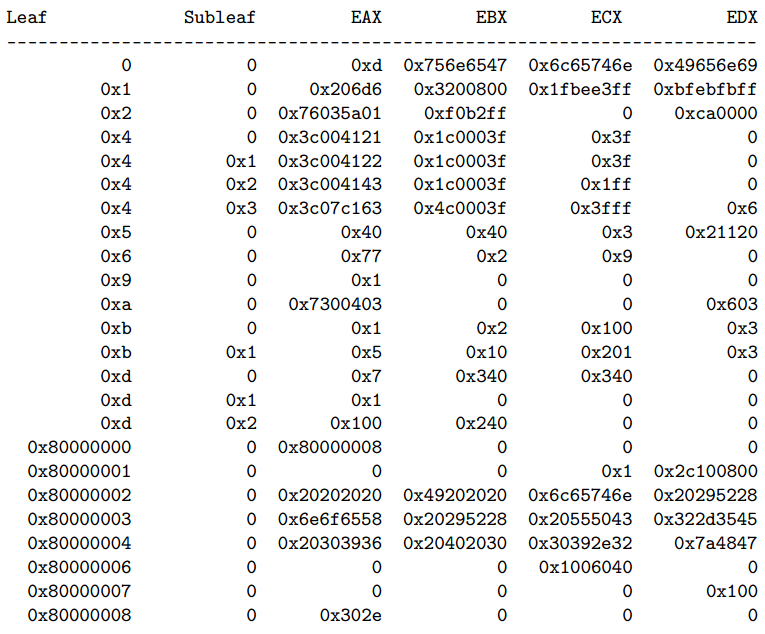
В текущем своём состоянии CPUID способно закодировать около 3 кбит данных.
Сравнение средств идентификации
Настоящего сравнения, увы, тут не будет. Уж слишком различными по составу заявляемых расширений оказываются разные процессоры. Но общее всё-таки есть. Все рассмотренные системы позволяют выяснить как минимум два параметра: производителя и некоторый номер «ревизии» процессора. Действительно, это представляется минимальным необходимым набором для идентификации. Если хранить в программном приложении таблицу соответствия «вендор» → «продукт» → «список расширений», то оно сможет однозначно идентифицировать свойства конкретной железки, на которой его запустили. Именно такой подход, кстати, я обнаружил в исходниках операционных систем: один или два (вложенных) больших switch'а.
Нельзя сказать, что минимализм этот удобен. Во-первых, надо как-то сформировать и хранить такую таблицу, а для этого придётся перерыть изрядное количество документации и провести натурных экспериментов. Во-вторых, налицо крайняя негибкость получаемого кода по отношению к будущим системам. Достаточно новому вендору выйти на рынок или уже присутствующему выпустить совместимый вроде бы ЦПУ с новым номером ревизии, и такая программа не сможет распознать его без обновления таблицы с последующей перекомпиляцией. Использование битовых масок для кодирования доступных расширений позволяет «старому» коду игнорировать новые расширения, но узнавать известные, что полезно для обратной совместимости.
Что действительно разнится у всех архитектур, так это объём предоставляемых данных идентификации. В этом графике я собрал вместе приблизительные значения ёмкости связанного с этим архитектурного состояния в битах для всех описанных выше процессоров.
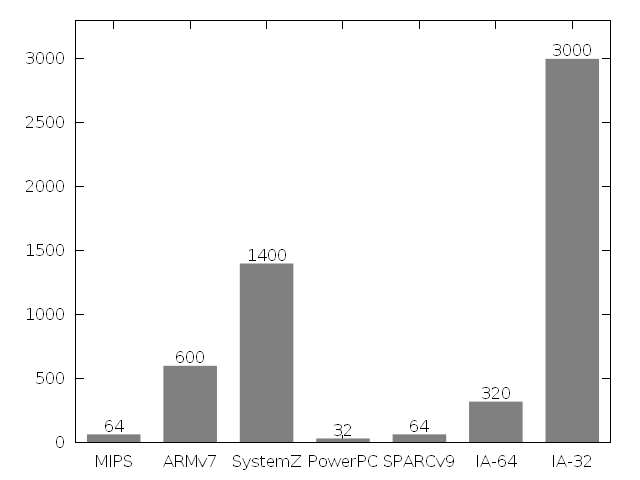
Затем я попытался найти какую-то корреляцию значений от особенностей каждой архитектуры, но не очень преуспел. Например, «возраст» системы не влияет на объём данных. Вообще довольно сложно определить возраст архитектуры, так как одна часто растёт из другой. Сначала я хотел написать, что system z была объявлена в 2005 году, но вспомнил, что происходит она от System/360, которая появилась в 1960-x. Та же история с Intel IA-32. Идентификация для неё в современном виде появилась в 1993 году (что было до этого, я напишу во второй части); но 8086-то родом из 1970-х! Intel IA-64 (объявленный в начале двухтысячных) просто не успел вобрать в себя несчётные расширения, чтобы суметь «блеснуть» запутанным содержимым cpuid. MIPS и ARM тоже нельзя назвать молодыми системами, они уже существовали как минимум в 1980-х, но вот надёжной идентификацией как-то не прирасли.
Что мне показалось на самом деле наблюдаемым, так это факт зависимости количества и качества средств идентификации расширений от свойства «встраиваемости» архитектуры. Если система изначально была предназначена для рынка встраиваемых систем, в которых переносимость двоичного кода не является продающим фактором, то средства идентификации у неё относительно скромны. Наоборот, рынок ПК, ЦПУ для которых в своё время производили чуть ли не десять компаний (с удивлением вчера узнал, что клон 8086 был даже у Siemens!), а диапазон применений архитектуры варьируется от IoT до суперкомпьютеров со специализированными ускорителями, продиктовал необходимость в чёткой дифференциации одновременно с переносимостью двоичного кода, что привело к «разбуханию» IA-32 CPUID до невероятных размеров.
Заключение
В этом небольшом обзоре мне не удалось достаточно подробно расписать детали идентификации конкретных моделей ЦПУ с примерами. Также некоторые менее популярные семейства процессоров вообще не были упомянуты: ARC, Alpha, AVR, Z80, 68000, 6502, Cell, Эльбрус… И, если для Intel IA-32 я ещё могу попробовать сделать подробное описание, то по другим архитектурам, увы, мои знания достаточно скудны. Однако, я надеюсь постепенно добраться и до них. Поэтому я буду признателен, если в комментариях читатели поделятся ссылками на документацию или просто расскажут о своём опыте работы с кодом, требующим идентификации расширений процессора.
Спасибо за внимание!
Литература
- Intel Corporation. Intel 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Grigory Rechistov. A set of CPU identification tools for Intel IA-32, IA-64 and other systems. github.com/grigory-rechistov/ggg-cpuid
- Advanced Micro Devices. AMD64 Architecture Programmer’s Manual Volume 1: Application Programming, 2012. support.amd.com/us/Processor_TechDocs/24592_APM_v1.pdf
- Per Fremstad, Wolfgang Fries, Marian Gasparovic, Parwez Hamid, Brian Hatfield, Dick Jorna, Fernando Nogal, and Karl-Erik Stenfors. IBM System z10 Enterprise Class Technical Guide. IBM, November 2009.
- IBM. PowerPC Microprocessor Family: The Programming Environments Manual for 64-bit Microprocessors Version 3.0, July 2005.
- Imagination Technologies. MIPS32 Architecture, 2014. www.imgtec.com/mips/mips32-architecture.asp
- MIPS Technologies, Inc. MIPS Architecture For Programmers Volume I-A: Introduction to the MIPS32 Architecture, March 2011.
- Intel Corporation. Intel Itanium Architecture Software Developer’s Manual. Volumes 1–4, 2010. www.intel.com/content/dam/doc/manual/itanium-architecture-vol-1-2-3-4-reference-set-manual.pdf
- D.L. Weaver, T. Germond, and SPARC International. The SPARC architecture manual: version 9. PTR Prentice Hall, 1994. books.google.ru/books?id=JNVQAAAAMAAJ
- ARM Limited. CPUID Base Register. Cortex-M1 FPGA Development Kit Cortex-M1 User Guide. infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0395b/CIHCAGHH.html
