Мы начинаем цикл статей, рассказывающих о различных ситуациях, в которых использование инструментов Intel для разработчиков позволило существенно повысить скорость работы программного обеспечения и улучшить его качество.
Наша первая история произошла в Новосибирском Университете, где исследователи разрабатывали программное средство для численного моделирования магнитогидродинамических проблем при ионизации водорода. Данная работа проводилась в рамках глобального проекта моделирования астрофизических объектов AstroPhi; в качестве аппаратной платформы использовались процессоры Intel Xeon Phi. В результате использования Intel Advisor и Intel Trace Analyzer and Collector производительность вычислений увеличилась в 3 раза, а скорость решения одной задачи сократилась с недели до двух дней.
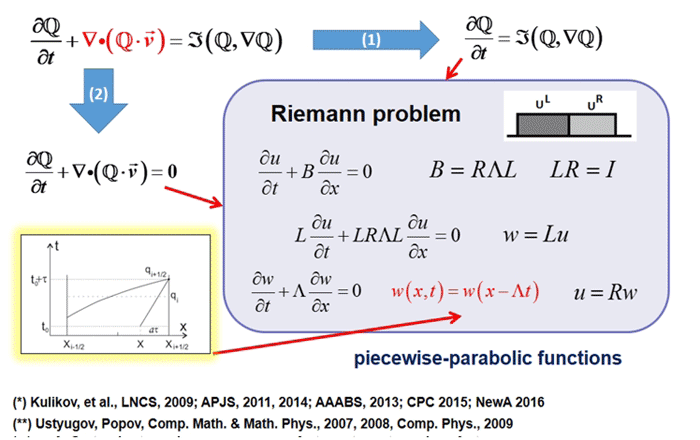
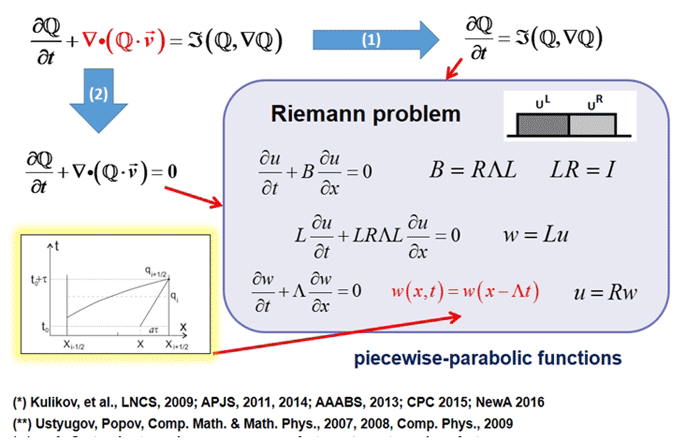
Математическое моделирование играет важную роль в современной астрофизике, как и в любой науке; это универсальное средство исследования нелинейных эволюционных процессов во вселенной. Моделирование сложных астрофизических процессов в высоком разрешении требует огромных вычислительных ресурсов. Проект AstroPhi НГУ занимается разработкой астрофизического программного кода для суперкомпьютеров на базе процессоров Intel Xeon Phi. Студенты учатся писать программы моделирования для чрезвычайно параллелизированной среды исполнения, получая важные знания, которые далее понадобятся им при работе с другими суперкомпьютерами.
Используемый в проекте численный метод моделирования имел ряд важных преимуществ:
Первые три фактора — ключевые для реалистичного моделирования значительных физических эффектов в астрофизических задачах.
Команда исследователей создала новое средство моделирования для многопараллельных архитектур на базе Intel Xeon Phi. Его главной задачей было избежать узких мест в обмене данными между узлами и максимально упростить доработку кода. Средство решения для параллелизации использует MPI, а для векторизации — инструкции Intel Advanced Vector Extensions 512 (Intel AVX-512), добавляющие поддержку 512-бит SIMD и позволяющие программе упаковать 8 чисел с плавающей точкой двойной точности или 16 чисел одинарной точности (32-битных) в векторы длиной 512 бит. Таким образом, за одну инструкцию обрабатывается вдвое больше элементов данных, чем при использовании AVX/AVX2 и вчетверо больше, чем при SSE.
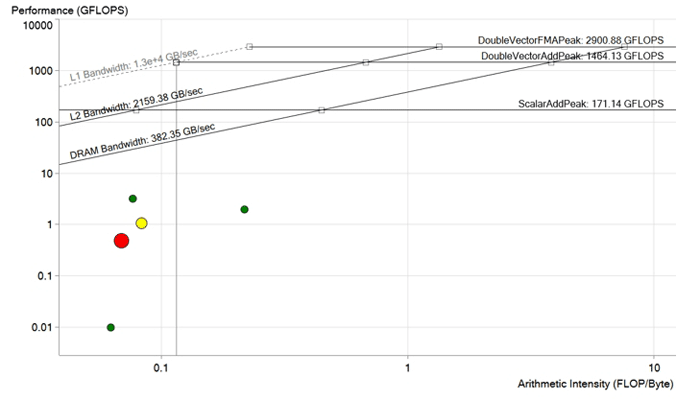
Картина до оптимизации. Каждая точка — это цикл обработки. Чем точка больше и краснее, тем больше времени продолжается цикл и тем заметнее оказывается эффект от его оптимизации. Красная точка лежит много ниже предела пропускной способности DRAM и обсчитывается с производительностью менее 1 GFLOP. Она имеет очень большой потенциал для улучшения
До оптимизации код имел определенные проблемы с зависимостями и размерами векторов. Целью оптимизации являлось удаление зависимостей векторов и улучшение операций загрузки данных в память, используя оптимальный для Xeon Phi размер векторов и массивов. Для оптимизации использовались Intel Advisor и Intel Trace Analyzer and Collector, два средства из состава Intel Parallel Studio XE.
Intel Advisor — это, как следует из его названия, советник — программное средство, оценивающее степень оптимизации — векторизации (с помощью инструкций AVX или SIMD) и параллелизации для достижения максимальной производительности. С использованием этого инструмента команда смогла сделать обзорный анализ циклов, выделяя работающие с низкой производительностью, указывая потенциал улучшения и определяя, что может быть улучшено и стоит ли овчинка выделки. Intel Advisor отсортировал циклы по потенциалу, добавил в исходники сообщения для лучшей читаемости отчета компилятора. Он также предоставил такую важную информацию, как число повторений циклов, зависимости данных и шаблоны доступа к памяти для безопасной и эффективной векторизации.
Intel Trace Analyzer and Collector — еще одно средство для оптимизации кода. Оно включает в себя профилирование MPI коммуникаций и функционал анализа для улучшения слабого и сильного масштабирования. Этот графический инструмент помог команде разобраться в MPI поведении приложения, быстро найти узкие места и, самое главное, увеличить производительность на архитектуре Intel.
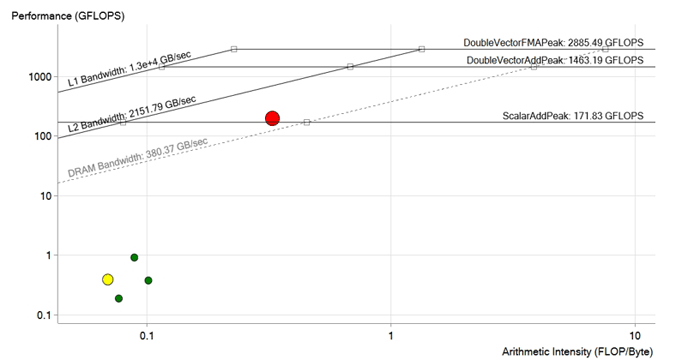
Картина после оптимизации. Во время оптимизации красного цикла были удалены зависимости векторизации, оптимизированы операции загрузки в память, размеры векторов и массивов адаптированы для Intel Xeon Phi и инструкций AVX-512. Производительность увеличилась до 190 GFLOPS, то есть примерно в 200 раз. Теперь она выше предела DRAM и, скорее всего, лимитируется характеристиками L2 кеша
Итак, после всех улучшений и оптимизаций команда достигла производительности 190 GFLOPS при арифметической интенсивности 0.3 FLOP/б, 100% утилизации и пропускной способности памяти 573 ГБ/с.

Фрагмент оптимизированного кода
Наша первая история произошла в Новосибирском Университете, где исследователи разрабатывали программное средство для численного моделирования магнитогидродинамических проблем при ионизации водорода. Данная работа проводилась в рамках глобального проекта моделирования астрофизических объектов AstroPhi; в качестве аппаратной платформы использовались процессоры Intel Xeon Phi. В результате использования Intel Advisor и Intel Trace Analyzer and Collector производительность вычислений увеличилась в 3 раза, а скорость решения одной задачи сократилась с недели до двух дней.
Описание задачи
Математическое моделирование играет важную роль в современной астрофизике, как и в любой науке; это универсальное средство исследования нелинейных эволюционных процессов во вселенной. Моделирование сложных астрофизических процессов в высоком разрешении требует огромных вычислительных ресурсов. Проект AstroPhi НГУ занимается разработкой астрофизического программного кода для суперкомпьютеров на базе процессоров Intel Xeon Phi. Студенты учатся писать программы моделирования для чрезвычайно параллелизированной среды исполнения, получая важные знания, которые далее понадобятся им при работе с другими суперкомпьютерами.
Используемый в проекте численный метод моделирования имел ряд важных преимуществ:
- отсутствие искусственной вязкости,
- галилеева инвариантность,
- гарантия неуменьшения энтропии,
- простая параллелизация,
- потенциально бесконечная расширяемость.
Первые три фактора — ключевые для реалистичного моделирования значительных физических эффектов в астрофизических задачах.
Команда исследователей создала новое средство моделирования для многопараллельных архитектур на базе Intel Xeon Phi. Его главной задачей было избежать узких мест в обмене данными между узлами и максимально упростить доработку кода. Средство решения для параллелизации использует MPI, а для векторизации — инструкции Intel Advanced Vector Extensions 512 (Intel AVX-512), добавляющие поддержку 512-бит SIMD и позволяющие программе упаковать 8 чисел с плавающей точкой двойной точности или 16 чисел одинарной точности (32-битных) в векторы длиной 512 бит. Таким образом, за одну инструкцию обрабатывается вдвое больше элементов данных, чем при использовании AVX/AVX2 и вчетверо больше, чем при SSE.
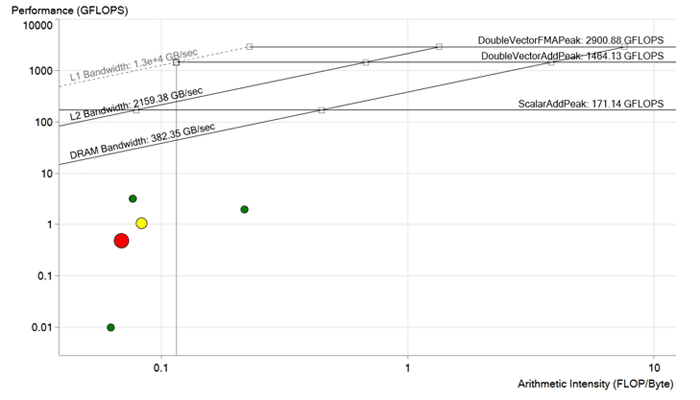
Картина до оптимизации. Каждая точка — это цикл обработки. Чем точка больше и краснее, тем больше времени продолжается цикл и тем заметнее оказывается эффект от его оптимизации. Красная точка лежит много ниже предела пропускной способности DRAM и обсчитывается с производительностью менее 1 GFLOP. Она имеет очень большой потенциал для улучшения
Оптимизация кода
До оптимизации код имел определенные проблемы с зависимостями и размерами векторов. Целью оптимизации являлось удаление зависимостей векторов и улучшение операций загрузки данных в память, используя оптимальный для Xeon Phi размер векторов и массивов. Для оптимизации использовались Intel Advisor и Intel Trace Analyzer and Collector, два средства из состава Intel Parallel Studio XE.
Intel Advisor — это, как следует из его названия, советник — программное средство, оценивающее степень оптимизации — векторизации (с помощью инструкций AVX или SIMD) и параллелизации для достижения максимальной производительности. С использованием этого инструмента команда смогла сделать обзорный анализ циклов, выделяя работающие с низкой производительностью, указывая потенциал улучшения и определяя, что может быть улучшено и стоит ли овчинка выделки. Intel Advisor отсортировал циклы по потенциалу, добавил в исходники сообщения для лучшей читаемости отчета компилятора. Он также предоставил такую важную информацию, как число повторений циклов, зависимости данных и шаблоны доступа к памяти для безопасной и эффективной векторизации.
Intel Trace Analyzer and Collector — еще одно средство для оптимизации кода. Оно включает в себя профилирование MPI коммуникаций и функционал анализа для улучшения слабого и сильного масштабирования. Этот графический инструмент помог команде разобраться в MPI поведении приложения, быстро найти узкие места и, самое главное, увеличить производительность на архитектуре Intel.
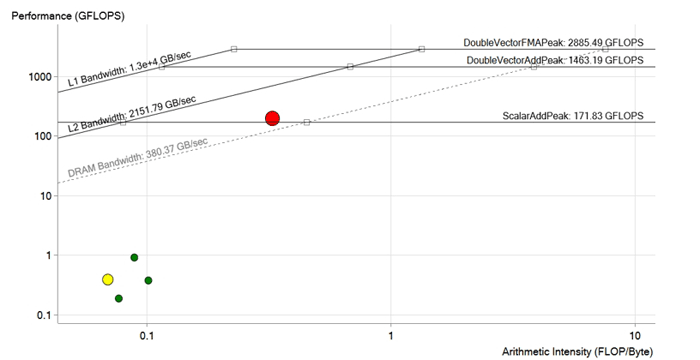
Картина после оптимизации. Во время оптимизации красного цикла были удалены зависимости векторизации, оптимизированы операции загрузки в память, размеры векторов и массивов адаптированы для Intel Xeon Phi и инструкций AVX-512. Производительность увеличилась до 190 GFLOPS, то есть примерно в 200 раз. Теперь она выше предела DRAM и, скорее всего, лимитируется характеристиками L2 кеша
Результат
Итак, после всех улучшений и оптимизаций команда достигла производительности 190 GFLOPS при арифметической интенсивности 0.3 FLOP/б, 100% утилизации и пропускной способности памяти 573 ГБ/с.

Фрагмент оптимизированного кода
