Недавно мы рассказывали о последнем релизе СУБД InterSystems Caché 2015.1, в котором существенно улучшена производительность, реализована поддержка второй версии языка преобразования XML-документов XSL Transformations (XSLT) Version 2.0 и использование семафоров для синхронизации процессов в Caché и организации их взаимодействия между собой. Кроме того, в новом релизе Caché расширены возможности использования сценариев высокой доступности и поддерживается применение внешнего web-сервера NGINX для сервера приложений Caché. В этой статье мы поговорим о первом из перечисленных усовершенствований нашей СУБД, а именно о том, насколько после выхода нового релиза улучшается производительность Caché при работе на многопроцессорных серверах, оборудованных процессорами Intel Xeon E7 v2 (кодовое название Ivy Bridge-EX).
Эти процессоры, являющиеся самыми мощными в линейке Intel Xeon и рассчитанные на четырёх- и более процессорные системы, вышли около года назад. По сравнению с первым поколением Xeon E7 у них вдвое улучшена производительность, на 25% увеличен объём встроенного кэша, втрое максимальный объём поддерживаемой оперативной памяти и в четыре раза пропускная способность каналов ввода/вывода. Кроме того, благодаря использованию технологий защиты от сбоев, разработанных для процессоров Intel Itanium, серверы на базе Xeon E7 v2 обеспечивают доступность на уровне пяти девяток (99,999%). Процессор Xeon E7 содержит до 15 процессорных ядер, которые поддерживают по два потока команд и используют общую кэш-память третьего уровня (L3) объёмом до 37,5 Мбайт и до трёх линков QuickPath Interconnect (QPI). Четырехпроцессорные серверы, оборудованные этим процессором, масштабируются до 6 Тбайт оперативной памяти, а восьмипроцессорные – до 12 Тбайт оперативной памяти.
Для того чтобы оценить масштабируемость Caché 2015.1 при использовании процессоров Xeon E7 v2, компания InterSystems провела тестирование базы данных при обслуживании системы управления медицинскими записями (Electronic Medical Records, EMR) фирмы EPIC, которая используется в ряде крупнейших американских медицинских учреждений. Тесты показали, что Caché 2015.1 в сочетании с технологией Enterprise Cache Protocol (ECP) на серверах на базе Xeon E7 v2 способна обслуживать в секунду более 21 млн. запросов конечных пользователей к базе данных (мы называем этот показатель производительности Global References per Second или GREF). При этом более чем в три раза был улучшен результат, которого удалось добиться на Caché 2013.1 в сочетании с Xeon E5. Выбор для тестирования системы EMR объясняется тем, что медицинские учреждения наряду с финансовыми институтами, розничной торговлей и государственным сектором являются основными заказчиками InterSystems.
Трёхкратный рост производительности был получен благодаря следующим усовершенствованиям масштабируемости Caché 2015.1:
Тесты проводились с помощью копии реальной многотерабайтной базы данных, которую использует система EPIC EMR, обслуживающая сеть больниц Sanford Health. Sanford Health – одна из крупнейших медицинских организаций в США, которой принадлежит 43 госпиталя с 1400 врачами, и обеспечивающая лечение более 26 тысяч пациентов.
Эксперты по производительности Intersystems и Epic выполнили на многотерабайтной копии базы Sanford Health серию тестов для определения измеряемой в GREF производительности Caché 2015.1, а также протестировали работу той же базы данных с предыдущим релизом Caché 2013.1. Для генерации нагрузки, создаваемой запросами к базе данных от конечных пользователей, применялись специальные инструменты моделирования, разработанные Epic. При этом постепенно увеличивалось число конечных пользователей, обращающихся к базе данных. В тестах замерялись как показатели производительности GREF, так и величина задержки, т.е. насколько быстро база данных может обрабатывать серию сложных запросов.
 Для тестирования Caché 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Caché 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.
Для тестирования Caché 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Caché 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.
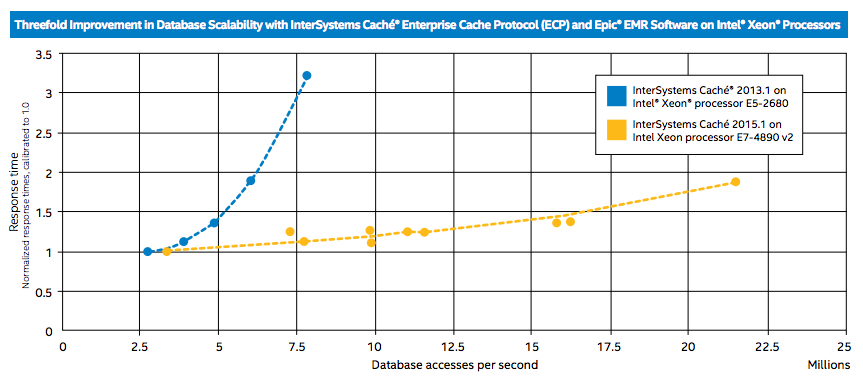
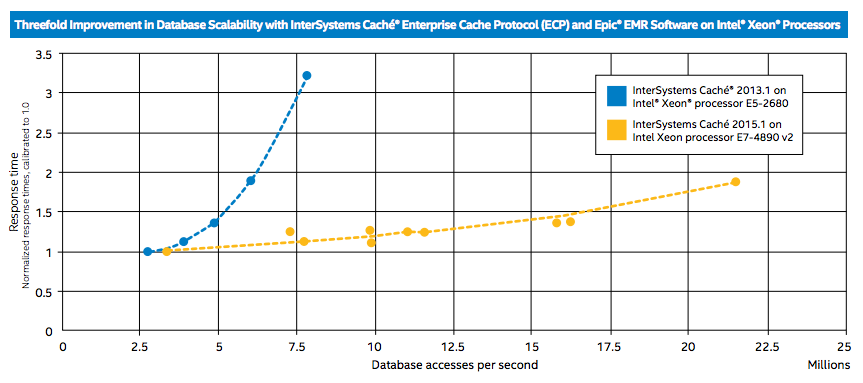
Как видно из графика, Caché 2015.1 на сервере с Intel Xeon E7-4890 v2 в тестах показала в три раза более высокую производительность, чем Caché 2013.1 на сервере с Intel Xeon E5-2680. Также график наглядно демонстрирует, что при росте числа запросов к базе данных задержки при использовании нового релиза Caché растут намного медленнее. Стоит отметить, что тестирование при более 22 млн. GREF не проводилось из-за ограничений аппаратной конфигурации сервера, а не достижения потолка производительности самой Caché 2015.1.
Тестирование продемонстрировало существенно улучшенную масштабируемость нового релиза Caché, обеспеченную как усовершенствованиями механизма распараллеливания самой базы данных, так и использованием преимуществ новой многоядерной архитектуры процессоров Intel Xeon E7 v2.
Спасибо за внимание, готовы ответить на ваши вопросы.
Эти процессоры, являющиеся самыми мощными в линейке Intel Xeon и рассчитанные на четырёх- и более процессорные системы, вышли около года назад. По сравнению с первым поколением Xeon E7 у них вдвое улучшена производительность, на 25% увеличен объём встроенного кэша, втрое максимальный объём поддерживаемой оперативной памяти и в четыре раза пропускная способность каналов ввода/вывода. Кроме того, благодаря использованию технологий защиты от сбоев, разработанных для процессоров Intel Itanium, серверы на базе Xeon E7 v2 обеспечивают доступность на уровне пяти девяток (99,999%). Процессор Xeon E7 содержит до 15 процессорных ядер, которые поддерживают по два потока команд и используют общую кэш-память третьего уровня (L3) объёмом до 37,5 Мбайт и до трёх линков QuickPath Interconnect (QPI). Четырехпроцессорные серверы, оборудованные этим процессором, масштабируются до 6 Тбайт оперативной памяти, а восьмипроцессорные – до 12 Тбайт оперативной памяти.
Для того чтобы оценить масштабируемость Caché 2015.1 при использовании процессоров Xeon E7 v2, компания InterSystems провела тестирование базы данных при обслуживании системы управления медицинскими записями (Electronic Medical Records, EMR) фирмы EPIC, которая используется в ряде крупнейших американских медицинских учреждений. Тесты показали, что Caché 2015.1 в сочетании с технологией Enterprise Cache Protocol (ECP) на серверах на базе Xeon E7 v2 способна обслуживать в секунду более 21 млн. запросов конечных пользователей к базе данных (мы называем этот показатель производительности Global References per Second или GREF). При этом более чем в три раза был улучшен результат, которого удалось добиться на Caché 2013.1 в сочетании с Xeon E5. Выбор для тестирования системы EMR объясняется тем, что медицинские учреждения наряду с финансовыми институтами, розничной торговлей и государственным сектором являются основными заказчиками InterSystems.
Трёхкратный рост производительности был получен благодаря следующим усовершенствованиям масштабируемости Caché 2015.1:
- Новый алгоритм распараллеливания для определённых приложений, благодаря которому при увеличении нагрузки и числа пользователей время реакции приложений остаётся на прежнем уровне;
- Caché 2015.1 использует специальные команды, минимизирующие задержки при работе приложений на многоядерных системах, связанные с неравномерным доступом к данным (NUMA, non-uniform memory access), поэтому при увеличении числа установленных в серверы процессоров время реакции приложений не увеличивается.
Как проводились тесты
Тесты проводились с помощью копии реальной многотерабайтной базы данных, которую использует система EPIC EMR, обслуживающая сеть больниц Sanford Health. Sanford Health – одна из крупнейших медицинских организаций в США, которой принадлежит 43 госпиталя с 1400 врачами, и обеспечивающая лечение более 26 тысяч пациентов.
Эксперты по производительности Intersystems и Epic выполнили на многотерабайтной копии базы Sanford Health серию тестов для определения измеряемой в GREF производительности Caché 2015.1, а также протестировали работу той же базы данных с предыдущим релизом Caché 2013.1. Для генерации нагрузки, создаваемой запросами к базе данных от конечных пользователей, применялись специальные инструменты моделирования, разработанные Epic. При этом постепенно увеличивалось число конечных пользователей, обращающихся к базе данных. В тестах замерялись как показатели производительности GREF, так и величина задержки, т.е. насколько быстро база данных может обрабатывать серию сложных запросов.
 Для тестирования Caché 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Caché 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.
Для тестирования Caché 2015.1 использовался четырехпроцессорный сервер с процессорами Intel Xeon E7-4890 v2 с тактовой частотой 2,8 ГГц, а Caché 2013.1 работал на двухсокетном сервере с Intel Xeon E5-2680 2,7 ГГц. На обоих серверах работали Red Hat Enterprise Linux и VMware vSphere; они обладали необходимыми ресурсами вычислительной мощности, оперативной памяти и дисков, чтобы эти показатели не ограничивали масштабируемость систем или не замедляли реагирование базы данных на запросы. В качестве системы хранения использовался твердотельный массив.Результаты
Как видно из графика, Caché 2015.1 на сервере с Intel Xeon E7-4890 v2 в тестах показала в три раза более высокую производительность, чем Caché 2013.1 на сервере с Intel Xeon E5-2680. Также график наглядно демонстрирует, что при росте числа запросов к базе данных задержки при использовании нового релиза Caché растут намного медленнее. Стоит отметить, что тестирование при более 22 млн. GREF не проводилось из-за ограничений аппаратной конфигурации сервера, а не достижения потолка производительности самой Caché 2015.1.
Выводы
Тестирование продемонстрировало существенно улучшенную масштабируемость нового релиза Caché, обеспеченную как усовершенствованиями механизма распараллеливания самой базы данных, так и использованием преимуществ новой многоядерной архитектуры процессоров Intel Xeon E7 v2.
Спасибо за внимание, готовы ответить на ваши вопросы.
