 Настоящие мечи-кладенцы баз данных — глобалы — давно известны, но до сих пор немногие умеют эффективно ими пользоваться или вовсе не владеют этим супероружием.
Настоящие мечи-кладенцы баз данных — глобалы — давно известны, но до сих пор немногие умеют эффективно ими пользоваться или вовсе не владеют этим супероружием.Если использовать глобалы в решении тех задач, в которых они действительно хороши, то можно добиться выдающихся результатов. Либо в производительности, либо в упрощении решения задачи (1, 2).
Глобалы — это специальный способ хранения и обработки данных, совершенно другой, чем таблицы в SQL. Они появились в 1966 году в языке M(UMPS) (эволюционное развитие — Caché ObjectScript, далее COS) в медицинских БД и до сих пор там активно используются, а также проникли в некоторые другие области, где требуется надёжность и высокая производительность: финансы, трейдинг и т.д.
Глобалы в современных СУБД поддерживают транзакции, журналирование, репликацию, партиционирование. Т.е. на них можно строить современные, надёжные, распределённые и быстрые системы.
Глобалы не ограничивают вас пределами реляционной модели. Они дают свободу для разработки структур данных, оптимизированных под конкретные задачи. Для многих приложений разумное использование глобалов может быть поистине секретным оружием, обеспечивая производительность, о которой разработчики реляционных приложений могут только мечтать.
Глобалы как способ хранения данных можно использовать во многих современных языках программирования, как высокоуровневых, так и низкоуровневых. Поэтому в этой статье я сфокусируюсь именно на глобалах, а не на языке, из которого они когда-то вышли.
2. Как работают глобалы
Давайте вначале разберёмся, как работают глобалы, и в чём их сильные стороны. На глобалы можно смотреть с разных точек зрения. В этой части статьи мы будем смотреть на них как на деревья. Или как на иерархические хранилища данных.
Упрощённого говоря, глобал — это персистентный массив. Массив, который автоматически сохраняется на диск.
Трудно представить что-то более простое для хранения данных. В коде (на языках COS/M) от обычного ассоциативного массива он отличается только символом ^ перед именем.
Для сохранения данных в глобале не нужно изучать язык запросов SQL, команды для работы с ними очень просты. Их можно выучить за час.
Начнём с самого простого примера. Одноуровневое дерево с 2-мя ветвями. Примеры написаны на COS.

Set ^a("+7926X") = "John Sidorov"
Set ^a("+7916Y") = "Sergey Smith"При вставке информации в глобал (комaнда Set) автоматически происходят 3 вещи:
- Сохранение данных на диск.
- Индексация. То что в скобках выступает ключом (в англоязычной литературе — «subscript»), а справа от равно — значением («node value»).
- Сортировка. Данные сортируются по ключу. В дальнейшем при обходе массива первым элементом станет «Sergey Smith», а вторым «John Sidorov». При получении списка пользователей из глобала база не тратит времени на сортировку. Причём можно запросить вывод отсортированного списка, начиная с любого ключа, даже несуществующего (вывод начнётся с первого реального ключа, который идёт за несуществующим).
Все эти операции происходят невероятно быстро. На домашнем компьютере я получал значения до 750 000 вставок/сек в одном процессе. На многоядерных процессорах значения могут достигать десятков миллионов вставок/сек.
Конечно, сама по себе скорость вставки мало о чём говорит. Можно, например, очень быстро записывать информацию в текстовые файлы — так по слухам работает процессинг Visa. Но в случае глобалов мы получаем на выходе структуризованное проиндексированное хранилище, с которым можно в дальнейшем просто и быстро работать.

- Самая сильная сторона глобалов — это скорость вставки новых узлов.
- Данные в глобале всегда проиндексированы. Их обход как на одном уровне, так и вглубь дерева, всегда быстр.
Добавим в глобал ещё несколько ветвей второго и третьего уровня.
Set ^a("+7926X", "city") = "Moscow"
Set ^a("+7926X", "city", "street") = "Req Square"
Set ^a("+7926X", "age") = 25
Set ^a("+7916Y", "city") = "London"
Set ^a("+7916Y", "city", "street") = "Baker Street"
Set ^a("+7916Y", "age") = 36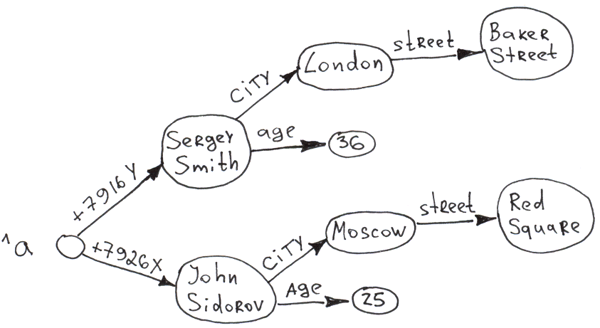
Очевидно, что на основе глобалов можно строить многоуровневые деревья. Причём доступ к любому узлу практически мгновенный из-за автоиндексирования при вставке. И на любом уровне дерева все ветви отсортированы по ключу.
Как видно информацию можно хранить как в ключе, так и значении. Общая длина ключа (сумма длин всех индексов) может достигать 511 байт, а значения 3.6 МБ для Caché. Число уровней в дереве (число измерений) — 31.
Ещё интересный момент. Можно построить дерево, не задавая значений узлов верхний уровней.

Set ^b("a", "b", "c", "d") = 1
Set ^b("a", "b", "c", "e") = 2
Set ^b("a", "b", "f", "g") = 3Пустые кружки — это узлы, которым не присвоено значение.
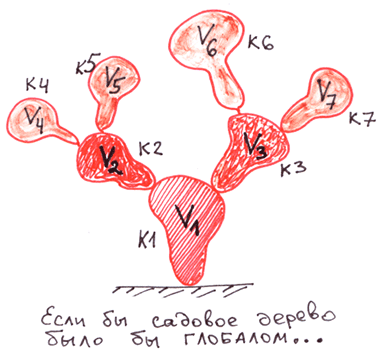
Для того, чтобы лучше понять глобалы, сравним их с другими деревьями: с садовыми и с деревьями имён файловых систем.
Сравним деревья на глобалах с наиболее знакомыми нам иерархическими структурами: с обычными деревьями, которые растут в садах и полях, а также с файловыми системами.
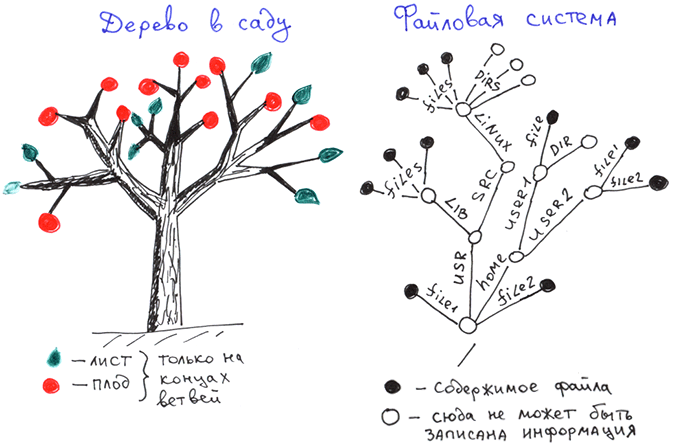
Как мы видим у садовых деревьев листья и плоды находятся только на концах ветвей.
Файловые системы — информация хранится только на концах ветвей, которые являются полными именами файлов.
А вот структура данных глобала.
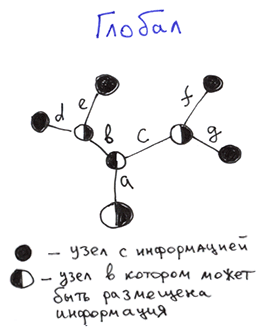 Отличия:
Отличия:- Внутренние узлы: информация в глобале может храниться в каждом узле, а не только на концах ветвей.
- Внешние узлы: у глобала обязательно должны быть определены значения на концах ветвей, у деревьев ФС и садовых — нет.
В части внутренних узлов, можно сказать, что структура глобала является надмножеством структуры деревьев имён в файловых системах и садовых деревьев. Т.е. более гибкой.
В общем случае глобал представляет собой упорядоченное дерево с возможностью хранения данных в каждом узле.
Чтобы лучше понять работу глобалов представим, что было бы, если создатели файловых систем использовали для хранения информации подход аналогичный глобалам?
- При удалении единственного файла в директории автоматически бы удалялась директория, а также все вышележащие директории содержащие только одну только что удалённую директорию.
- Надобность в директориях бы отпала. Просто были бы файлы с подфайлами и файлы без подфайлов. Если сравнить с обычным деревом, то каждая ветвь стала бы плодом.
- Такие вещи как файлы README.txt, возможно, отпали бы. Всё что нужно было сказать о содержимом директории можно было записать в сам файл директории. В пространстве путей имя файла неотличимо от имени директории, поэтому можно было обойтись одними файлами.
- Скорость удаления директорий с вложенными поддиректориям и файлами резко увеличилась бы. Много раз на хабре проскакивали статьи о том, как долго и трудно удалять миллионы мелких файлов (1, 2). Однако, если сделать псевдофайловую систему на глобале, то это будет занимать секунды или их доли. Когда я тестировал удаление поддеревьев на домашнем компьютере, то за 1 секунду удалялось 96-341 миллионов узлов из двухярусного дерева на HDD (не SSD). Причём речь идёт об удалении части дерева, а не просто всего файла с глобалами.
Удаление поддеревьев — ещё одна сильная сторона глобалов. Для этого не нужна рекурсия. Это происходит невероятно быстро.
В нашем дереве это можно было бы сделать командой Kill.
Kill ^a("+7926X")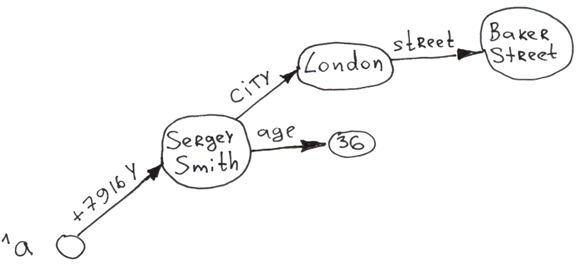
Для лучшего понимания того, какие действия нам доступны над глобалами, приведу краткую таблицу.
| Основные команды и функции по работе с глобалами в COS | |
|---|---|
| Set | Установка ветвей до узла (если ещё неопределены) и значения узла |
| Merge | Копирование поддерева |
| Kill | Удаление поддерева |
| ZKill | Удаление значения конкретного узла. Поддерево выходящее из узла не трогается |
| $Query | Полный обход дерева с заходом вглубь |
| $Order | Обход веток конкретного узла |
| $Data | Проверка определён ли узел |
| Атомарное инкрементирование значения узла. Чтобы не делать считывания и записи, для ACID. В последнее время рекомендуется менять на $Sequence | |
Disclaimer: данная статья и мои комментарии к ней является моим мнением и не имеют отношения к официальной позиции корпорации InterSystems.
Продолжение Глобалы — мечи-кладенцы для хранения данных. Деревья. Часть 2. Вы узнаете какие типы данных можно отобразить на глобалах и на каких задачах они дают максимальный выигрыш.
