Комментарии 336
Настоящие мечи-кладенцы баз данных — глобалы — давно известны, но до сих пор немногие умеют эффективно ими пользоваться или вовсе не владеют этим супероружием.
Очень заинтересовали что за глобалы такие, начал искать в инете. Поправьте меня если я ошибаюсь но разве это не синоним обычного key-value или nosql хранилища? Учитывая популярность всяких nosql баз и хранилищ, мне кажется это давно уже не супероружие, а один из самых распостраненных инструментов наряду с sql базами данных. Или в идеи глобалов есть все-таки что-то ещё кроме key-value или nosql хранилища? Чем глобал отличается от обычного nosql хранилища, построенного на основе бинарного дерева? В каких nosql хранилищах используется эта концепция?
Это надмножество key-value. В следующей статье об этом будет подробно.
В 2-х словах — глобалы — это иерархический key-value. Где под одним key можно хранить целое дерево значений и ключей.
Поскольку глобалы появились давно, то это невероятно отлаженная и вылизанная технология, очень скорострельная.
Как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки.
Как правило к глобалам идёт специальный язык на котором можно писать хранимые процедуры (в терминах SQL) и полноценные программы.
Программы на этом языке можно компилировать — и это даёт огромную скорость обработки данных в БД по сравнению с интерпретируемым SQL.
В 2-х словах — глобалы — это иерархический key-value. Где под одним key можно хранить целое дерево значений и ключей.
Поскольку глобалы появились давно, то это невероятно отлаженная и вылизанная технология, очень скорострельная.
Как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки.
Как правило к глобалам идёт специальный язык на котором можно писать хранимые процедуры (в терминах SQL) и полноценные программы.
Программы на этом языке можно компилировать — и это даёт огромную скорость обработки данных в БД по сравнению с интерпретируемым SQL.
Как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки.
А можно поподробнее, как это достигается?
Когда я смотрел исходный код GT.M я был поражён — не менее 50% кода написано на ассемблере (причём под все архитектуры), а остальное на Си. Исходный код Caché закрыт, но я думаю там таже история. Они недавно писали, что оптимизируют всё даже под конкретные модели процессоров.
Оптимизация на ассемблере — это хорошо, но скорость работы с диском имеет банальные физические ограничения (и поэтому заведомо медленнее работы с памятью). Как это ограничение обойдено?
Есть 3 вопроса в вашем: при вставке, обновлении, выборке.
Я изложу свои догадки, поскольку я не разработчик.
При случайной выборке из объёмов многократно превосходящих ОЗУ мы упираемся в IOPS диска (тестировал сам), но сама структура хранения глобалов такова, что дерево хранится очень компактно, и поэтому за один IOPS считывается кусок дерева.
То же при обновлении: я подозреваю, что за 1 IOPS обновляется сразу несколько значений узлов.
При записи происходит сортировка и определённая буферизация, очень оттюнингованная. За один IOPS записывается сразу много значений узлов.
Также нужно учитывать, что современные in-memory БД появились недавно и поэтому не до конца оптимизированы. Авторы вот этой статьи утверждают, что GlobalsDB рвёт по тестам Redis. Можно у них попросить данные тестирований.
Также, я думаю, если скидывать значения на диск раз в несколько секунд, то одних ассемблерных и алгоритмических оптимизаций будет достаточно, чтобы выигрывать у тех in-memory продуктов, которые полностью написаны на высокоуровневых языках.
Я изложу свои догадки, поскольку я не разработчик.
При случайной выборке из объёмов многократно превосходящих ОЗУ мы упираемся в IOPS диска (тестировал сам), но сама структура хранения глобалов такова, что дерево хранится очень компактно, и поэтому за один IOPS считывается кусок дерева.
То же при обновлении: я подозреваю, что за 1 IOPS обновляется сразу несколько значений узлов.
При записи происходит сортировка и определённая буферизация, очень оттюнингованная. За один IOPS записывается сразу много значений узлов.
Также нужно учитывать, что современные in-memory БД появились недавно и поэтому не до конца оптимизированы. Авторы вот этой статьи утверждают, что GlobalsDB рвёт по тестам Redis. Можно у них попросить данные тестирований.
Также, я думаю, если скидывать значения на диск раз в несколько секунд, то одних ассемблерных и алгоритмических оптимизаций будет достаточно, чтобы выигрывать у тех in-memory продуктов, которые полностью написаны на высокоуровневых языках.
При случайной выборке из объёмов многократно превосходящих ОЗУ мы упираемся в IOPS диска (тестировал сам),
То есть скорость, внезапно, не от in-memory, а упирается в диск.
То же при обновлении: я подозреваю, что за 1 IOPS обновляется сразу несколько значений узлов. При записи происходит сортировка и определённая буферизация, очень оттюнингованная. За один IOPS записывается сразу много значений узлов.
Буферизация? Т.е., пока буфер не наберется (ну или таймаут не случится), записи на диск не будет?
Можно изложить вот так. Если мы тестируем in-memory БД и БД на глобалах на одинаковом объёме ОЗУ, то ничего не мешает той же GlobalsDB держать всё в памяти. Это честное тестирование. На одной и тоже машине: одинаковый объём ОЗУ и винта для двух БД.
Если мы тестируем базу на 10ТБ на глобалах и in-memory базу на 20GB в ОЗУ — это нечестное тестирование. Разные объёмы.
При равных объёмах ОЗУ она выигрывает в скорости за счёт оптимизаций, которые десятками лет выдумывались. Делая синхронизацию когда нужно. Если на машине стоит рейд-контроллер с Write-back и батарейкой, то БД на глобалах может скидывать данные на диск хоть каждую десятую секунды. Write-back кэш будет проглатывать их мгновенно.
При последнем подходе иногда может получиться даже, что база 10ТБ на глобалах будет быстрее чем in-memory база на 20GB в ОЗУ.
Если мы тестируем базу на 10ТБ на глобалах и in-memory базу на 20GB в ОЗУ — это нечестное тестирование. Разные объёмы.
При равных объёмах ОЗУ она выигрывает в скорости за счёт оптимизаций, которые десятками лет выдумывались. Делая синхронизацию когда нужно. Если на машине стоит рейд-контроллер с Write-back и батарейкой, то БД на глобалах может скидывать данные на диск хоть каждую десятую секунды. Write-back кэш будет проглатывать их мгновенно.
При последнем подходе иногда может получиться даже, что база 10ТБ на глобалах будет быстрее чем in-memory база на 20GB в ОЗУ.
Можно изложить вот так. Если мы тестируем in-memory БД и БД на глобалах на одинаковом объёме ОЗУ, то ничего не мешает той же GlobalsDB держать всё в памяти. Это честное тестирование. Одинаковый объём ОЗУ и винта.
Это по определению не «честное» тестирование, потому что разные задачи и требования.
Если на машине стоит рейд-контроллер с Write-back и батарейкой, то БД на глобалах может скидывать данные на диск хоть каждую десятую секунды. Write-back кэш будет проглатывать их мгновенно.
Омг. Разница в скорости между памятью и диском как минимум на порядок (в идеальных условиях, в реальности память быстрее). Теперь представьте, что у меня идет непрерывный поток транзакций, полностью забивающий пропускную способность памяти. Что случится с кэшом?
Это по определению не «честное» тестирование, потому что разные задачи и требования.
А я думаю честное. И с чего вы взяли, что задачи разные? Может быть задача одна и та же, раз сравнивали с in-memory БД — скорость. Если на одинаковой ОЗУ, одинаковом размере памяти и одинаковом размере памяти база на глобалах скоростнее, то значит она скоростнее. В чём тут нечестность?
Твоя задача скорость — вот и получаешь скорость.
А я думаю честное. И с чего вы взяли, что задачи разные? Может быть задача одна и та же, раз сравнивали с in-memory БД — скорость. Если на одинаковой ОЗУ, одинаковом размере памяти и одинаковом размере памяти база на глобалах скоростнее, то значит она скоростнее. В чём тут нечестность?
В расходах на жесткий диск, которых у in-memory практически нет.
Ну так это только замедляет базы на глобалах. Так что HDD — это фора. Я, кстати, могу представить как делали такое тестирование — поставили время синхронизации с диском такое же как и у in-memory и прогнали тесты.
Ведь и in-memory БД тоже скидывают на диск когда-то.
А если данные в in-memory БД чисто на чтение, то можно в базе на глобалах выставить время синхронизации с диском раз в миллион лет.
Ведь и in-memory БД тоже скидывают на диск когда-то.
А если данные в in-memory БД чисто на чтение, то можно в базе на глобалах выставить время синхронизации с диском раз в миллион лет.
Ведь и in-memory БД тоже скидывают на диск когда-то.
Зачем?
Чтобы данные не пропали. Ведь далеко невсегда они используются только для кеширования чтения.
redis.io/topics/persistence
Loading and Saving In-Memory Databases www.sqlite.org/backup.html
redis.io/topics/persistence
Loading and Saving In-Memory Databases www.sqlite.org/backup.html
В этот момент они перестают быть in-memory, и становятся гибридными. И у них тоже появляется ограничение по пропускной способности, коррелирующее с диском.
Так и есть. Вы правы. Но всё-равно их называют in-memory. Так принято.
Кем принято? А главное, в этом случае сравнение «GlobalsDb выигрывает даже у in-memory» вводит в ожидаемое заблуждение: я весь этот тред думал, что GlobalsDb с полным ACID работает быстрее, чем «чистая» in-memory (которая в лучшем случае ACI, а чаще и того нет).
Так внимание, вопрос: расшифруйте, пожалуйста, вашу фразу «как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки»? Что подразумевается под «скоростью» — время отклика, пропускная способность, что-то еще? Какие гарантии обеспечивает «глобал», и какие — «in-memory БД»? На какие исследования вы опираетесь, делая это утверждение?
Так внимание, вопрос: расшифруйте, пожалуйста, вашу фразу «как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки»? Что подразумевается под «скоростью» — время отклика, пропускная способность, что-то еще? Какие гарантии обеспечивает «глобал», и какие — «in-memory БД»? На какие исследования вы опираетесь, делая это утверждение?
А какие гарантии обеспечивает in-memory БД? Если не сбрасывать дамп на диск — никаких.
Под скоростью принимается частота запросов типа SET и/или GET.
В особенности хорошо глобалы работают с массированной вставкой. С гарантией, что могут потеряться данные только за последние 1-2 секунды без использования транзакций. Цифры озвучивал.
Очевидно, что такой уровень целостности in-memory БД предоставить не может. А если сбрасывать дампы in-memory БД на диск каждые 1-2 секунды, то это убьёт её производительность.
Специально для вас только что я провёл тест на вставку, где каждая вставка была обёрнута в транзакцию, и получил скорость 572 082 вставок/секунду. Вставлял 100М значений на обычные винты в RAID5, write-back включён.
У меня нет развёрнутого дистрибутива GlobalsDB, поэтому тестировал на GT.M.
Это очень приличные цифры — примерно такие же как у Redis на hi-end сервере. Проверьте сами. Код M-программы:
Под скоростью принимается частота запросов типа SET и/или GET.
В особенности хорошо глобалы работают с массированной вставкой. С гарантией, что могут потеряться данные только за последние 1-2 секунды без использования транзакций. Цифры озвучивал.
Очевидно, что такой уровень целостности in-memory БД предоставить не может. А если сбрасывать дампы in-memory БД на диск каждые 1-2 секунды, то это убьёт её производительность.
Специально для вас только что я провёл тест на вставку, где каждая вставка была обёрнута в транзакцию, и получил скорость 572 082 вставок/секунду. Вставлял 100М значений на обычные винты в RAID5, write-back включён.
У меня нет развёрнутого дистрибутива GlobalsDB, поэтому тестировал на GT.M.
Это очень приличные цифры — примерно такие же как у Redis на hi-end сервере. Проверьте сами. Код M-программы:
mytest
for i=0:1:50000000 do
. TSTART
. Set ^a(i)=i
. TCOMMIT
Но о чём говорит такой тест?
Гарантированной фиксации транзакций – нет.
Никаких запросов с клиентского приложения – нет, база варится внутри самой себя.
Чтобы адекватно сравнивать с другими СУБД – нужно делать bulk load транзакциями по 1-2 сек. Сделайте такой тест, тогда будет о чём говорить.
А то у вас тест из серии «положим газету в серную кислоту, а журнал – в дистиллированую воду». В Redis кидаем отдельные SET/GET запросы из клиентского приложения, а GT.M варится внутри себя. Это не серьёзно!
Гарантированной фиксации транзакций – нет.
Никаких запросов с клиентского приложения – нет, база варится внутри самой себя.
Чтобы адекватно сравнивать с другими СУБД – нужно делать bulk load транзакциями по 1-2 сек. Сделайте такой тест, тогда будет о чём говорить.
А то у вас тест из серии «положим газету в серную кислоту, а журнал – в дистиллированую воду». В Redis кидаем отдельные SET/GET запросы из клиентского приложения, а GT.M варится внутри себя. Это не серьёзно!
Каждый коммит гарантирует фиксацию транзакций.
Так устроено. Если коммит не проходит, то выкидывается ошибка.
Я просто не писал их обработку.
В Redis кидались запросы не из клиентского приложения, а из тестовой программки, которая идёт вместе с ним. Которая тоже тестирует хитро, чтобы показать максимальную производительность.
Так устроено. Если коммит не проходит, то выкидывается ошибка.
Я просто не писал их обработку.
В Redis кидались запросы не из клиентского приложения, а из тестовой программки, которая идёт вместе с ним. Которая тоже тестирует хитро, чтобы показать максимальную производительность.
Каждый коммит гарантирует фиксацию транзакций.
Так устроено. Если коммит не проходит, то выкидывается ошибка.
Я просто не писал их обработку.
Для того, чтобы так было, у вас «на обычные винты в RAID5» должны были бы выдать 572 082 IOPS'ов минимум.
В Redis кидались запросы не из клиентского приложения, а из тестовой программки, которая идёт вместе с ним. Которая тоже тестирует хитро, чтобы показать максимальную производительность.
Хитро или не хитро, но даже гонять данные между тестовой программкой и СУБД – это не тоже самое что когда СУБД пишет сама в себя.
Для того, чтобы так было, у вас «на обычные винты в RAID5» должны были бы выдать 572 082 IOPS'ов минимум
Достаточно иметь write-back кеш с батарейкой, который и даёт такую производительность.
Достаточно иметь write-back кеш с батарейкой, который и даёт такую производительность.
Ок. Но это не отменяет того, что в таких тестах всё, как правило упирается в коммуникацию с приложением, которую вы искусственно выключили.
Я просто не стал её создавать. Это же всё хобби. Мне за создание тестов не платят.
Да, результаты были бы другими. Какими?
Я не знаю. Сетевые задержки снизили бы скорость, а использованная многоядерность повысила.
Да, результаты были бы другими. Какими?
Я не знаю. Сетевые задержки снизили бы скорость, а использованная многоядерность повысила.
Нашёл данные своего однопоточного тестирования вставки из PHP через Pipe. Удалось получить 51 398 вставок в секунду. Глобалы при этом предварительно обнулялись.
Всего вставок делалось 1 000 000.
Вообще такой результат (51K/сек) для очень и очень многих обычных баз недостижим.
Предположу, что если организовать 6 потоков, по числу ядер в моём проце, то будет более 300 000 инсертов/сек.
Так как внутри базы в одном потоке скорость более 500 000 инсертов/секунду.
Всего вставок делалось 1 000 000.
Вообще такой результат (51K/сек) для очень и очень многих обычных баз недостижим.
Предположу, что если организовать 6 потоков, по числу ядер в моём проце, то будет более 300 000 инсертов/сек.
Так как внутри базы в одном потоке скорость более 500 000 инсертов/секунду.
Вообще такой результат (51K/сек) для очень и очень многих обычных баз недостижим.
Из чистого любопытства провел тест на рабочем компьютере (SSD, 8Gb RAM, i5-4460). MS SQL Server (без дополнительных оптимизаций, только преаллокация БД) вставляет миллион записей (одной транзакцией) за ~7,5 с, что дает ориентировочно 133К/сек.
Понятное дело, что тест нереалистичный (все записи идут скриптом в цикле, скрипт выполняется прямо на сервере — зато без какой-либо компиляции, все записи в одной транзакции), но «о чем-то говорит».
Там же тест на чтение — 4,3M записей читается 14 секунд, это порядка 300К/сек. Причем мой опыт показывает, что львиная доля этого времени уходит на передачу данных между клиентом и сервером, в реальности первый ответ приходит намного быстрее, и если делать потоковую обработку, то получается еще выиграть.
Опять-таки, никаких оптимизаций.
Опять-таки, никаких оптимизаций.
51K — это я получил когда из другого процесса через pipe давал в интерпретаторном режиме команды.
Так что сделайте тест по моей методике: цикл идёт в PHP, посылайте команды через pipe по одной.
Если хотите сравнивать по вашей методике, то сравнивать нужно со значением 750K/ секунду, которое у меня в цикле получается.
Так что сделайте тест по моей методике: цикл идёт в PHP, посылайте команды через pipe по одной.
Если хотите сравнивать по вашей методике, то сравнивать нужно со значением 750K/ секунду, которое у меня в цикле получается.
А там, в общем-то, такая же разница, что и внутри сервера — ориентировочно в пять раз (т.е. порядка 10К/сек). Только это «честная» RDBMS с полной транзакционностью, гарантией фиксации и так далее. Если я, скажем, возьму EventStore, то цифры будут «немножко» другие.
Я делал тест в цикле с честной полной транзакционностью — что-то около 300K/сек. Цифры я приводил.
И я бы так уверенно на вашем месте насчёт честности MS SQL не говорил — они используют буфер на запись, судя по поиску в сети.
Сделайте тест. Цикл на запись с параллельной записью в сокет/или файл, отрубите жёстко питание, чтобы буфера не успели сброситься и сравните максимальный id после перезагрузки в файле и таблице.
И я бы так уверенно на вашем месте насчёт честности MS SQL не говорил — они используют буфер на запись, судя по поиску в сети.
Сделайте тест. Цикл на запись с параллельной записью в сокет/или файл, отрубите жёстко питание, чтобы буфера не успели сброситься и сравните максимальный id после перезагрузки в файле и таблице.
Я делал тест в цикле с честной полной транзакционностью
Мы уже как-то выясняли, что не очень понятно, что у глобалов с изоляцией.
Сделайте тест. Цикл на запись с параллельной записью в сокет/или файл, отрубите жёстко питание, чтобы буфера не успели сброситься и сравните максимальный id после перезагрузки в файле и таблице.
Спасибо, но нет. Я достаточно хорошо отношусь к своему рабочему компьютеру, чтобы так над ним измываться. Коммит транзакции в MS SQL (а он происходит либо по команде, либо, если открытой транзакции нет, по умолчанию после каждой DML-операции) явно дожидается подтверждения от нижележащей системы о фиксации I/O-операции.
явно дожидается подтверждения от нижележащей системы о фиксации I/O-операции
Вы говорите как верующий. А с чего вы взяли, что явно? В интернет полно упоминаний о буферах в MsSQL.
И что это за гарантии целостности, если вы боитесь разрушения базы или ОС от выключения компа?
Вы говорите как верующий. А с чего вы взяли, что явно? В интернет полно упоминаний о буферах в MsSQL.
Эти упоминания есть прямо в документации. Вместе с рассказом про то, как работает WAL.
И что это за гарантии целостности, если вы боитесь разрушения базы или ОС от выключения компа?
Эмм, а в Windows, внезапно, полностью транзакционная файловая система (я сейчас не про MS SQL, а про другие процессы, которые на этой машине запущены)? И это я не говорю про то, какую нагрузку прямой power cycle дает на диск.
Меня совершенно не радует мысль о том, что тестовая БД, на которой я гоняю нагрузку, выживет, а системный раздел — умрет.
Поскольку MS SQL работает в среде Windows, тем самым вы признаёте, что реальных гарантий целостности нет вообще.
Вы правда не понимаете, что гарантия целостности обеспечивается не только системой, но и приложением?
В частности, если у вас append-only поток, то сохранение его целостности — тривиальная задача, каждая запись либо завершена, либо нет. Соответственно, если у нас операция записи оборвалась, то откат такого файла прост, как две копейки. При этом, обратный сигнал о том, что запись завершена, означает, что она реально завершена. Надо ли говорить, что в логах транзакций используются аналогичные подходы?
А теперь сравните это с ситуацией, когда какое-то неумное приложение перезаписывает структурированный файл целиком. В этом случае обрыв записи посередине даст нам нечитаемый файл.
В частности, если у вас append-only поток, то сохранение его целостности — тривиальная задача, каждая запись либо завершена, либо нет. Соответственно, если у нас операция записи оборвалась, то откат такого файла прост, как две копейки. При этом, обратный сигнал о том, что запись завершена, означает, что она реально завершена. Надо ли говорить, что в логах транзакций используются аналогичные подходы?
А теперь сравните это с ситуацией, когда какое-то неумное приложение перезаписывает структурированный файл целиком. В этом случае обрыв записи посередине даст нам нечитаемый файл.
Как раз речь об этом. В MUMPS ты имеешь возможность работать напрямую с базой и там же развернуть сервер данных, а в других базах нет. Это и есть преимущество.
При желании кеш всегда можно забить. Понятно, что в этом случае производительность упадёт. На объёмах данных, когда забьётся ОЗУ, забьётся кеш сравнивать нужно уже с БД, которые хранят данные на диске.
Конечно у СУБД на глобалах задачи несколько другие. Более универсальные.
Я не пытаюсь доказать, что диск быстрее памяти )))
Конечно у СУБД на глобалах задачи несколько другие. Более универсальные.
Я не пытаюсь доказать, что диск быстрее памяти )))
Я не пытаюсь доказать, что диск быстрее памяти
Тем не менее, вы утверждаете, что система, хранящая данные на диске, работает со скоростью системы, работающей только с памятью. В моем опыте, это достижимо только отказом от гарантий персистентности. Мне интересно, каких еще способов я не знаю.
Вообще-то я ссылался на статью, где GlobalsDB превзошла Redis, а не была равной.
Чудес не бывает. Хорошая оптимизация кода, алгоритмов кеширования, продуманное и экономичное использование памяти. Преимущества долгого развития.
При гигантском размере базы никакое самое мудрое кеширование не спасёт и упрёмся в IOPS. Кстати говоря, не все БД умеют работать со скоростью большей чем IOPSы SSD.
Чудес не бывает. Хорошая оптимизация кода, алгоритмов кеширования, продуманное и экономичное использование памяти. Преимущества долгого развития.
При гигантском размере базы никакое самое мудрое кеширование не спасёт и упрёмся в IOPS. Кстати говоря, не все БД умеют работать со скоростью большей чем IOPSы SSD.
Вообще-то я ссылался на статью, где GlobalsDB превзошла Redis, а не была равной.
Можете еще раз привести ссылку? Как я уже писал, та, которую я вижу — битая.
У меня открывается
habrahabr.ru/company/intersystems/blog/194818
habrahabr.ru/company/intersystems/blog/194818
Там есть только утверждение «для сравнения Globals по тестам работает быстрее, чем Redis», никакими, собственно, тестами не подтвержденное.
Для тех кто будет читать этот тред. В этом комменте можно увидеть результаты Redis vs GlobalsDB
Что интересно, Rob Tweed, когда делал сравнительное тестирование не подкручивал буферизацию в GlobalsDB. Он использовал дефолтные настройки. А по дефолту там сброс буферов не реже, чем раз в секунду.
Globals database, standard default install with no performance tweaking.
Вы уже весь его код просмотрели?
Нет. Я прочитал его отчёт о тестировании. Код, кстати, на github. Я так понимаю в папке examples. Как я понял, он написал специальный менеджер запросов, который их перенаправляет к GlobalsDB, а с ней работает через пул.
— GlobalsDB превзошла Redis,
а Redis об этих тестах знает? А то вполне может что специально сконструриванная база под сравнение, как это уже не раз было в истории.
а Redis об этих тестах знает? А то вполне может что специально сконструриванная база под сравнение, как это уже не раз было в истории.
Не знаю.
Если Redis-база помещается в памяти, то как можно её сконструировать, чтобы ухудшить работу?
В самих тестах написано, что Redis тестировалась отдельно на куче SET операций, а потом отдельно на куче GET. Т.е. наиболее выгодный для Redis вариант.
А GlobalsDB на смешанном потоке, что для базы, которая в итоге данные сбрасывает на диск, явно более проигрышный вариант.
GlobalsDB в секунду делала
read: 92,000 / sec И write: 50,571 /sec
А Redis SET: 88,105 /sec ИЛИ GET: 88,573 /sec
Ссылка
Если Redis-база помещается в памяти, то как можно её сконструировать, чтобы ухудшить работу?
В самих тестах написано, что Redis тестировалась отдельно на куче SET операций, а потом отдельно на куче GET. Т.е. наиболее выгодный для Redis вариант.
А GlobalsDB на смешанном потоке, что для базы, которая в итоге данные сбрасывает на диск, явно более проигрышный вариант.
GlobalsDB в секунду делала
read: 92,000 / sec И write: 50,571 /sec
А Redis SET: 88,105 /sec ИЛИ GET: 88,573 /sec
Ссылка
Буферизация? Т.е., пока буфер не наберется (ну или таймаут не случится), записи на диск не будет?
Да.
Однако насколько я знаю: буферизация записи вещь настраиваемая. Можно её вообще выставить в ноль. А можно раздуть, если нужно для задачи.
Причём она может происходить автоматически как на уровне ОС, так и на уровне БД. Можно на уровне БД вообще отключить.
Буферизация? Т.е., пока буфер не наберется (ну или таймаут не случится), записи на диск не будет?
Да.
А как же D из ACID-транзакций? Или транзакции в глобалах, про которые вы выше писали — не durable?
Ну а как вы думаете обеспечивают D — Oracle, MySql и MSSQL? У них у всех есть буфера.
D — обеспечивается тем, что при отключении питания не должны повредиться уже проведённые транзакции.
Когда выдаётся команда COMMIT происходит запись на диск, а всё что до COMMIT может храниться в буфере.
D — обеспечивается тем, что при отключении питания не должны повредиться уже проведённые транзакции.
Когда выдаётся команда COMMIT происходит запись на диск, а всё что до COMMIT может храниться в буфере.
Ну а как вы думаете обеспечивают D — Oracle, MySql и MSSQL? У них у всех есть буфера.
За всех не знаю, но насколько мне известно, транзакция не считается проведенной, пока нет подтверждения о ее фиксации хранилищем.
Когда выдаётся команда COMMIT происходит запись на диск, а всё что до COMMIT может храниться в буфере.
Если вы о commit в терминах ANSI SQL, то представьте себе систему, которая пишет большой поток атомарных событий, каждое из которых является неявной транзакцией (и, как следствие, должно быть зафиксировано на диск). Где здесь место буферу?
При таком раскладе:
1) когда каждая транзакция принципиальна важна
2) их очень много
место для буфера остаётся только в плате рейд-контроллера с батарейкой и Write-back cache.
Видимо для таких случаев и оставлена возможность установки буфера в ноль.
Хотя с другой стороны, если мы для надёжности пишем сразу на 2 сервера, то можем спокойно буферизировать запись. Если один из них сломается — запишется на втором.
1) когда каждая транзакция принципиальна важна
2) их очень много
место для буфера остаётся только в плате рейд-контроллера с батарейкой и Write-back cache.
Видимо для таких случаев и оставлена возможность установки буфера в ноль.
Хотя с другой стороны, если мы для надёжности пишем сразу на 2 сервера, то можем спокойно буферизировать запись. Если один из них сломается — запишется на втором.
место для буфера остаётся только в плате рейд-контроллера с батарейкой и Write-back cache.
И в этом случае упрется в скорость IO сразу после окончания буфера контроллера, а они не такие и большие.
Хотя с другой стороны, если мы для надёжности пишем сразу на 2 сервера, то можем спокойно буферизировать запись. Если один из них сломается — запишется на втором.
Вы это серьезно? А то, что распределенная гарантия записи в реальности дороже локальной, вы знаете?
А то, что распределенная гарантия записи в реальности дороже локальной, вы знаете?
В каком отношении дороже? Поскольку мы говорим о скорости, рискну предположить, что вы утверждаете, что нельзя организовать распределённую запись со скоростью того же порядка, что и нераспределённую.
Распределённая будет медленнее, конечно, но не на порядок.
Собственно в другом комменте я написал, что если оборачивать в транзакции, то у глобалов примерно на треть замедляется время вставки.
Авторы вот этой статьи утверждают, что GlobalsDB рвёт по тестам Redis.
У вас нет ссылки на статью, только ссылка на этот же блог на хабре. Можно, все-таки, ссылку на сам тест? Гугль дает только битую ссылку на форум самого GlobalsDB.
Вообще-то я дал ссылку на статью. А в статье говорилось о тестировании.
Есть проблема. Человек писавший ту статью умер. Я не могу попросить его выложить результаты тестов.
Однако в недрах wayback machine я нашёл инфу о другом тестировании GlobalsDB vs Redis.
Его проводил Rob Tweed. У него можно узнать детали.
Есть проблема. Человек писавший ту статью умер. Я не могу попросить его выложить результаты тестов.
Однако в недрах wayback machine я нашёл инфу о другом тестировании GlobalsDB vs Redis.
Его проводил Rob Tweed. У него можно узнать детали.
http://web.archive.org/web/20120126105627/http://globalsdb.org/forum/topic/70
OK here's a comparison with Redis on the exact same machine — latest version of Redis (2.2.13), standard install.
Started up the Redis server and then ran src/redis-benchmark -n 100000.
In summary:
SET: 88,105 /sec
GET: 88,573 /sec
Bear in mind that this benchmark runs a bunch of SETs, then a bunch of GETs, rather than a combination together, and is presumably optimised to show off Redis in as good a light as possible.
Compare with the results for Node.js + Globals, where both Sets and Gets were happening together:
read: 92,000 / sec
write: 50,571 /sec
Or, in terms of total database hits: 142,571 /sec
** Looks like Globals is giving Redis (supposedly the fastest thing on the planet) a serious spanking! **
=======================
Here's the full Redis-benchmark trace for anyone interested:
rob@rob-ProLiant-ML115-G5:~/redis-2.2.13$ src/redis-benchmark -n 100000
====== PING (inline) ======
100000 requests completed in 1.22 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.87% <= 1 milliseconds
100.00% <= 1 milliseconds
82169.27 requests per second
====== PING ======
100000 requests completed in 1.22 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.81% <= 1 milliseconds
100.00% <= 1 milliseconds
82034.45 requests per second
====== MSET (10 keys) ======
100000 requests completed in 2.21 seconds
50 parallel clients
3 bytes payload
keep alive: 1
67.53% <= 1 milliseconds
99.93% <= 2 milliseconds
99.99% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 5 milliseconds
100.00% <= 6 milliseconds
100.00% <= 7 milliseconds
100.00% <= 8 milliseconds
45248.87 requests per second
====== SET ======
100000 requests completed in 1.13 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.90% <= 1 milliseconds
100.00% <= 1 milliseconds
88105.73 requests per second
====== GET ======
100000 requests completed in 1.14 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
87412.59 requests per second
====== INCR ======
100000 requests completed in 1.12 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.98% <= 1 milliseconds
100.00% <= 1 milliseconds
88967.98 requests per second
====== LPUSH ======
100000 requests completed in 1.13 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.98% <= 1 milliseconds
99.99% <= 2 milliseconds
100.00% <= 3 milliseconds
100.00% <= 3 milliseconds
88573.96 requests per second
====== LPOP ======
100000 requests completed in 1.14 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
87796.30 requests per second
====== SADD ======
100000 requests completed in 1.20 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.95% <= 10 milliseconds
99.96% <= 11 milliseconds
99.96% <= 12 milliseconds
99.97% <= 13 milliseconds
99.97% <= 14 milliseconds
99.98% <= 15 milliseconds
99.98% <= 16 milliseconds
99.99% <= 17 milliseconds
99.99% <= 18 milliseconds
100.00% <= 18 milliseconds
83612.04 requests per second
====== SPOP ======
100000 requests completed in 1.17 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.97% <= 1 milliseconds
99.99% <= 2 milliseconds
100.00% <= 3 milliseconds
100.00% <= 4 milliseconds
100.00% <= 4 milliseconds
85763.29 requests per second
====== LPUSH (again, in order to bench LRANGE) ======
100000 requests completed in 1.12 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
88888.89 requests per second
====== LRANGE (first 100 elements) ======
100000 requests completed in 2.41 seconds
50 parallel clients
3 bytes payload
keep alive: 1
48.07% <= 1 milliseconds
99.31% <= 2 milliseconds
99.99% <= 3 milliseconds
100.00% <= 3 milliseconds
41476.57 requests per second
====== LRANGE (first 300 elements) ======
100000 requests completed in 4.80 seconds
50 parallel clients
3 bytes payload
keep alive: 1
1.26% <= 1 milliseconds
66.13% <= 2 milliseconds
95.34% <= 3 milliseconds
99.88% <= 4 milliseconds
99.95% <= 5 milliseconds
99.98% <= 7 milliseconds
99.98% <= 8 milliseconds
99.98% <= 10 milliseconds
99.99% <= 11 milliseconds
99.99% <= 13 milliseconds
99.99% <= 14 milliseconds
99.99% <= 16 milliseconds
99.99% <= 17 milliseconds
99.99% <= 19 milliseconds
99.99% <= 20 milliseconds
99.99% <= 23 milliseconds
99.99% <= 24 milliseconds
99.99% <= 26 milliseconds
100.00% <= 28 milliseconds
100.00% <= 30 milliseconds
100.00% <= 32 milliseconds
100.00% <= 34 milliseconds
100.00% <= 36 milliseconds
100.00% <= 38 milliseconds
20842.02 requests per second
====== LRANGE (first 450 elements) ======
100000 requests completed in 6.68 seconds
50 parallel clients
3 bytes payload
keep alive: 1
0.64% <= 1 milliseconds
29.63% <= 2 milliseconds
74.15% <= 3 milliseconds
91.33% <= 4 milliseconds
99.79% <= 5 milliseconds
99.89% <= 6 milliseconds
99.92% <= 7 milliseconds
99.96% <= 8 milliseconds
100.00% <= 8 milliseconds
14974.54 requests per second
====== LRANGE (first 600 elements) ======
100000 requests completed in 8.34 seconds
50 parallel clients
3 bytes payload
keep alive: 1
1.31% <= 1 milliseconds
29.83% <= 2 milliseconds
59.73% <= 3 milliseconds
83.49% <= 4 milliseconds
95.88% <= 5 milliseconds
99.78% <= 6 milliseconds
99.91% <= 7 milliseconds
99.95% <= 8 milliseconds
99.95% <= 9 milliseconds
99.98% <= 10 milliseconds
100.00% <= 10 milliseconds
11996.16 requests per second
rob@rob-ProLiant-ML115-G5:~/redis-2.2.13$
Started up the Redis server and then ran src/redis-benchmark -n 100000.
In summary:
SET: 88,105 /sec
GET: 88,573 /sec
Bear in mind that this benchmark runs a bunch of SETs, then a bunch of GETs, rather than a combination together, and is presumably optimised to show off Redis in as good a light as possible.
Compare with the results for Node.js + Globals, where both Sets and Gets were happening together:
read: 92,000 / sec
write: 50,571 /sec
Or, in terms of total database hits: 142,571 /sec
** Looks like Globals is giving Redis (supposedly the fastest thing on the planet) a serious spanking! **
=======================
Here's the full Redis-benchmark trace for anyone interested:
rob@rob-ProLiant-ML115-G5:~/redis-2.2.13$ src/redis-benchmark -n 100000
====== PING (inline) ======
100000 requests completed in 1.22 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.87% <= 1 milliseconds
100.00% <= 1 milliseconds
82169.27 requests per second
====== PING ======
100000 requests completed in 1.22 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.81% <= 1 milliseconds
100.00% <= 1 milliseconds
82034.45 requests per second
====== MSET (10 keys) ======
100000 requests completed in 2.21 seconds
50 parallel clients
3 bytes payload
keep alive: 1
67.53% <= 1 milliseconds
99.93% <= 2 milliseconds
99.99% <= 3 milliseconds
99.99% <= 4 milliseconds
100.00% <= 5 milliseconds
100.00% <= 6 milliseconds
100.00% <= 7 milliseconds
100.00% <= 8 milliseconds
45248.87 requests per second
====== SET ======
100000 requests completed in 1.13 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.90% <= 1 milliseconds
100.00% <= 1 milliseconds
88105.73 requests per second
====== GET ======
100000 requests completed in 1.14 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
87412.59 requests per second
====== INCR ======
100000 requests completed in 1.12 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.98% <= 1 milliseconds
100.00% <= 1 milliseconds
88967.98 requests per second
====== LPUSH ======
100000 requests completed in 1.13 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.98% <= 1 milliseconds
99.99% <= 2 milliseconds
100.00% <= 3 milliseconds
100.00% <= 3 milliseconds
88573.96 requests per second
====== LPOP ======
100000 requests completed in 1.14 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
87796.30 requests per second
====== SADD ======
100000 requests completed in 1.20 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.95% <= 10 milliseconds
99.96% <= 11 milliseconds
99.96% <= 12 milliseconds
99.97% <= 13 milliseconds
99.97% <= 14 milliseconds
99.98% <= 15 milliseconds
99.98% <= 16 milliseconds
99.99% <= 17 milliseconds
99.99% <= 18 milliseconds
100.00% <= 18 milliseconds
83612.04 requests per second
====== SPOP ======
100000 requests completed in 1.17 seconds
50 parallel clients
3 bytes payload
keep alive: 1
99.97% <= 1 milliseconds
99.99% <= 2 milliseconds
100.00% <= 3 milliseconds
100.00% <= 4 milliseconds
100.00% <= 4 milliseconds
85763.29 requests per second
====== LPUSH (again, in order to bench LRANGE) ======
100000 requests completed in 1.12 seconds
50 parallel clients
3 bytes payload
keep alive: 1
100.00% <= 0 milliseconds
88888.89 requests per second
====== LRANGE (first 100 elements) ======
100000 requests completed in 2.41 seconds
50 parallel clients
3 bytes payload
keep alive: 1
48.07% <= 1 milliseconds
99.31% <= 2 milliseconds
99.99% <= 3 milliseconds
100.00% <= 3 milliseconds
41476.57 requests per second
====== LRANGE (first 300 elements) ======
100000 requests completed in 4.80 seconds
50 parallel clients
3 bytes payload
keep alive: 1
1.26% <= 1 milliseconds
66.13% <= 2 milliseconds
95.34% <= 3 milliseconds
99.88% <= 4 milliseconds
99.95% <= 5 milliseconds
99.98% <= 7 milliseconds
99.98% <= 8 milliseconds
99.98% <= 10 milliseconds
99.99% <= 11 milliseconds
99.99% <= 13 milliseconds
99.99% <= 14 milliseconds
99.99% <= 16 milliseconds
99.99% <= 17 milliseconds
99.99% <= 19 milliseconds
99.99% <= 20 milliseconds
99.99% <= 23 milliseconds
99.99% <= 24 milliseconds
99.99% <= 26 milliseconds
100.00% <= 28 milliseconds
100.00% <= 30 milliseconds
100.00% <= 32 milliseconds
100.00% <= 34 milliseconds
100.00% <= 36 milliseconds
100.00% <= 38 milliseconds
20842.02 requests per second
====== LRANGE (first 450 elements) ======
100000 requests completed in 6.68 seconds
50 parallel clients
3 bytes payload
keep alive: 1
0.64% <= 1 milliseconds
29.63% <= 2 milliseconds
74.15% <= 3 milliseconds
91.33% <= 4 milliseconds
99.79% <= 5 milliseconds
99.89% <= 6 milliseconds
99.92% <= 7 milliseconds
99.96% <= 8 milliseconds
100.00% <= 8 milliseconds
14974.54 requests per second
====== LRANGE (first 600 elements) ======
100000 requests completed in 8.34 seconds
50 parallel clients
3 bytes payload
keep alive: 1
1.31% <= 1 milliseconds
29.83% <= 2 milliseconds
59.73% <= 3 milliseconds
83.49% <= 4 milliseconds
95.88% <= 5 milliseconds
99.78% <= 6 milliseconds
99.91% <= 7 milliseconds
99.95% <= 8 milliseconds
99.95% <= 9 milliseconds
99.98% <= 10 milliseconds
100.00% <= 10 milliseconds
11996.16 requests per second
rob@rob-ProLiant-ML115-G5:~/redis-2.2.13$
А в статье говорилось о тестировании.
Я цитату выше уже привел, это весьма смехотворно.
А тестирование, на которое вы ссылаетесь сейчас, во-первых, было четыре года назад, с тех пор новая мажорная версия редиса успела выйти, во-вторых, оно методологически странно — сравниваются разные операции, не описаны требования к персистентности и консистентности, и так далее.
Это было тестирование на скорость. Какие могут быть требования к Redis в области персистентности и консистентности?
Любой сбой питания и база потеряна.
4 года назад Redis тоже была базой in-memory.
Сам факт, что база с автоматическим сохранением на диск + индексация + сортировка смогла опередить in-memory базу удивителен.
Если бы вы лично потестировали глобалы в работе, то знали бы, что они невероятно быстры.
Настолько, что программист, который с ними никогда не работал, не может поверить.
Хорошо я привёл данные своего собственного тестирования GT.M — если тестировать чисто вставку получал 750 000 вставок/секунду для миллиона вставок (с использованием буферов по дефолту) и 422 000 вставок/сек для 300М вставок (с постоянным скидыванием инфы на диск, кеш забит).
По этой более новой ссылке мужик получал, тестируя Redis, на Macbook Pro 37 000 вставок/сек и 550 000 вставок/секунду на hi-end сервере.
Скачайте Cache (тестовую версвию) или GlobalsDB или GT.M, напишите программу на COS/M из трёх строчек и вы убедитесь в скорости глобалов сами.
Конечно, это очень разные базы данных и для разных задач.
Любой сбой питания и база потеряна.
4 года назад Redis тоже была базой in-memory.
Сам факт, что база с автоматическим сохранением на диск + индексация + сортировка смогла опередить in-memory базу удивителен.
Если бы вы лично потестировали глобалы в работе, то знали бы, что они невероятно быстры.
Настолько, что программист, который с ними никогда не работал, не может поверить.
Хорошо я привёл данные своего собственного тестирования GT.M — если тестировать чисто вставку получал 750 000 вставок/секунду для миллиона вставок (с использованием буферов по дефолту) и 422 000 вставок/сек для 300М вставок (с постоянным скидыванием инфы на диск, кеш забит).
По этой более новой ссылке мужик получал, тестируя Redis, на Macbook Pro 37 000 вставок/сек и 550 000 вставок/секунду на hi-end сервере.
Скачайте Cache (тестовую версвию) или GlobalsDB или GT.M, напишите программу на COS/M из трёх строчек и вы убедитесь в скорости глобалов сами.
Конечно, это очень разные базы данных и для разных задач.
Это было тестирование на скорость. Какие могут быть требования к Redis в области персистентности и консистентности?
Если их не было, то это тоже надо озвучивать.
Сам факт, что база с автоматическим сохранением на диск + индексация + сортировка смогла опередить in-memory базу удивителен.
Он «удивителен» только в общих словах. А в реальности нам нужно не удивление, а конкретные данные — какой сценарий, что происходит, какие гарантии дают обе базы.
Скачайте Cache (тестовую версвию) или GlobalsDB или GT.M, напишите программу на COS/M из трёх строчек и вы убедитесь в скорости глобалов сами.
Простой вопрос: как COS/M коммуницирует с СУБД? Он находится в ее процессе или отдельно? Если отдельно, то инструкция вставки передается каждая отдельно, или все сразу?
Я тестировал, когда COS/M находился в одном процессе.
Rob Tweed делал обёртку из отдельной программы и обгонял Redis при тестировании по HTTP. У него, естественно, были в разных процессах.
Rob Tweed делал обёртку из отдельной программы и обгонял Redis при тестировании по HTTP. У него, естественно, были в разных процессах.
Я тестировал, когда COS/M находился в одном процессе.
Эээ, а вас не смущает, что на таких объемах затраты на коммуникацию обходятся дороже общения с памятью?
Сложный вопрос. Стандартная утилитка Redis'а тестирует в 50 потоков, используя многоядерность. А я на одном ядре, в одном потоке.
Вообще цель моего тестирования была показать скорость глобалов. Redis просто попал под руку для сравнения.
Скорости получаются одного порядка. И это делает честь и хвалу программистам Caché и GT.M.
Вообще цель моего тестирования была показать скорость глобалов. Redis просто попал под руку для сравнения.
Скорости получаются одного порядка. И это делает честь и хвалу программистам Caché и GT.M.
Скорости получаются одного порядка. И это делает честь и хвалу программистам Caché и GT.M.
Я не могу считать скорости «внутри процесса» и «по одному объекту между процессами» одним порядком, вы меня простите.
Ну посмотрите у Роба. У него даже получилось побить Redis. Хотя он вообще прослойку использовал. У него база + менеджер запросов + Node.JS. Три процесса, как минимум.
Если для вас это принципиальный момент использовать последний Redis — повторите тесты.
Я вообще ссылку приводил, что на hi-end машине с SSD при тестировании бизнес транзакций через сеть была достигнута скорость 22 миллиона транзакции/сек на Caché. Причём они тестировали очень тяжёлое приложение.
Если для вас это принципиальный момент использовать последний Redis — повторите тесты.
Я вообще ссылку приводил, что на hi-end машине с SSD при тестировании бизнес транзакций через сеть была достигнута скорость 22 миллиона транзакции/сек на Caché. Причём они тестировали очень тяжёлое приложение.
Ну посмотрите у Роба. У него даже получилось побить Redis.
Четыре года назад. С неизвестной методикой.
Вообще-то методику он описал. Я её просто в коммент не скопировал. Нужно перейти по ссылке и читать с самого верхнего поста.
Вот ссылка на мой тест, когда доступ был извне процесса.
В одном потоке при вставках по 20 штук скорость была около 299 000 инсертов/сек.
В одном потоке при вставках по 20 штук скорость была около 299 000 инсертов/сек.
Rob Tweed делал обёртку из отдельной программы
А с чего вы решили, что данные у него были в разных процессах?
Вот цитата из вашего же перевода статьи того же Роба (выделение мое):
Одним из интересных свойств GlobalsDB является то, можно широко использовать синхронное программирование без вреда для производительности, что упрощает работу с ней и позволяет использовать ОО-синтаксис в полном объёме внутри JavaScript. Это возможно из-за уникальной производительности GlobalsDB: она работает в связке c NodeJS как подлинкованный процесс в оперативной памяти (в отличие от многих других NoSQL-баз, которые работают через различные сетевые сокеты).
Это еще одна иллюстрация к тому, что методологию тестирования надо описывать.
С того, что запросы подавались по http.
Приложение делающее запросы + Менеджер http-запросов + несколько тредов [Node.js + GlobalsDB].
Только то, что в квадратных скобках было в одном процессе.
Приложение делающее запросы + Менеджер http-запросов + несколько тредов [Node.js + GlobalsDB].
Только то, что в квадратных скобках было в одном процессе.
Где вы нашли, что запросы подавались по http? Где код приложения, делающего запросы?
Сама архитектура его приложения показывает, что он принимал запросы по http. Иначе зачем ему менеджер http-запросов, который перенаправляет запросы к пулу тредов, где запущены БД?
Во-первых, если «архитектура приложения показывает», но самого источника запросов нет — это плохой тест. Но лично мне эта архитектура показывает совсем другое.
Окей, покажите, где там менеджер http-запросов.
Окей, покажите, где там менеджер http-запросов.
По ссылке, что я приводил указан:
https://github.com/robtweed/Q-Oper8
https://github.com/robtweed/Q-Oper8
Омг, Q-Oper8 — это не менеджер http-запросов. Ладно, вот вам код теста, взятый по вашей же ссылке:
Где здесь прием и обработка http-запросов?
Main Node.js server process:
var scheduler = require('qoper8'); var params = {poolSize: 4, trace: true, childProcessPath: '/home/rob/gdbwork/gmpChildProc1.js'}; scheduler.start(params, function(queue) { console.log("started!!!"); var startTime = new Date().getTime(); var total = 0; var handler = function(actionObj, response, pid) { total++; if (total % 100 === 0) { var now = new Date().getTime(); console.log(total + ": Total elapsed time: " + (now - startTime)/1000 + ": queue length " + queue.length); console.log("response was " + JSON.stringify(response)); console.log("original action was: " + JSON.stringify(actionObj.action)); console.log("pid = " + pid); } }; for (var i = 1; i < 1100; i++) { scheduler.addToQueue({action: {domNo: i}}, handler); } });
Child process logic:
var childProcess = require('qoper8').childProcess; var ewdDOM = require('ewdDOM'); var params = { path:'/home/rob/globals111/mgr', trace: false }; ewdDOM.start(params,function(db) { var actionMethod = function(action) { ewdDOM.counters.set = 0; ewdDOM.counters.get = 0; ewdDOM.counters.data = 0; ewdDOM.counters.retrieve = 0; ewdDOM.counters.kill = 0; ewdDOM.counters.order = 0; var docName = 'test' + action.domNo; ewdDOM.removeDocument(docName); var document = ewdDOM.createDocument(docName); var node1 = document.createElement("testElement"); var documentNode = document.getDocumentNode(); documentNode.appendChild(node1); node1.setAttribute("name","rob"); node1.setAttribute("town","Reigate"); var newNode = { tagName: "div", attributes: {id: "myNewNode", abc: 123, def: "this will be removed!"}, text: "This is a new div" }; var node2 = node1.addElement(newNode); newNode = { tagName: "div", attributes: {id: "secondDiv", abc: 'hkjhjkhjk'}, }; var node3 = node1.addElement(newNode); var imNode = node1.insertIntermediateElement("intermediateTag"); var pNode = imNode.insertParentElement("newParentTag"); node2.modifyElementText("New replacement text for myNewNode"); var response = {docName: docName, counters: ewdDOM.counters}; return response; }; childProcess.handler(actionMethod); });
Где здесь прием и обработка http-запросов?
А я вам другой кусок кода покажу:
qoper8.asyncHandler();
var responseHandler = function(requestObj, results, pid) {
//console.log("This is the response handler: ");
//console.log("** action: " + JSON.stringify(requestObj.action));
//console.log("results = " + JSON.stringify(results));
var response = requestObj.response;
var html = "<html>";
html = html + "<head><title>Q-Oper8 action response</title></head>";
html = html + "<body>";
html = html + "<p>Action was processed !</p><p>Results: " + results + "</p>";
html = html + "</body>";
html = html + "</html>";
response.writeHead(200, {"Content-Type": "text/html"});
response.write(html);
response.end();
qoper8.makeProcessAvailable(pid);
};Какое отношение этот кусок кода имеет к тесту? В каком месте теста он вызывается?
Нет, серьезно. Я вам показал реальный код теста, опубликованный автором. Это тот самый код, который создает нагрузку. Если вы ему не верите — значит, вы не верите и результатам теста, и весь разговор бессмысленнен. А если верите — то где в нем http?
Нет, серьезно. Я вам показал реальный код теста, опубликованный автором. Это тот самый код, который создает нагрузку. Если вы ему не верите — значит, вы не верите и результатам теста, и весь разговор бессмысленнен. А если верите — то где в нем http?
Это не тест создающий нагрузку. Это библиотека, которая сохраняет DOM в глобалах.
У него есть 2 проекта по ссылке:
github.com/robtweed/Q-Oper8 — менеджер запросов
github.com/robtweed/ewdDOM — библиотека, которая сохраняет DOM в глобалах.
У него есть 2 проекта по ссылке:
github.com/robtweed/Q-Oper8 — менеджер запросов
github.com/robtweed/ewdDOM — библиотека, которая сохраняет DOM в глобалах.
Так. Еще раз.
Открываем приведенную вами ссылку, второй пост сверху (Sept. 20, 2011 04:12:02):
И дальше идет приведенный мной код. В котором, кстати, хорошо видно использование Q-Oper8 для разделения двух процессов и вызов ewdDom в дочернем процессе (собственно,
Вы серьезно хотите оспорить утверждение о том, что это не код теста? Я его могу практически построчно откомментировать же.
Открываем приведенную вами ссылку, второй пост сверху (Sept. 20, 2011 04:12:02):
Here's the details of the DOM benchmark test. [...] All the DOM creation is defined in the child process logic. The main server process just puts 1000 requests on the Q-Oper8 queue and receives the results.
И дальше идет приведенный мной код. В котором, кстати, хорошо видно использование Q-Oper8 для разделения двух процессов и вызов ewdDom в дочернем процессе (собственно,
var ewdDOM = require('ewdDOM');).Вы серьезно хотите оспорить утверждение о том, что это не код теста? Я его могу практически построчно откомментировать же.
Ну вот вы и сами признали, что процессы разделены, а не являются одним.
Да, я ошибся, когда думал, что он использовал свой менеджер http-запросов совместно с http-клиентом.
Однако не вижу проблемы, в том, каким образом он напихал в очередь запросы.
Node.JS на хорошей машине позволяет держать миллион соединений. Так что напихать 1000 запросов в очередь не проблема.
Если вы хотите оспорить результаты его теста, то должны сказать что его менеджер запросов не способен принять и поместить в очередь 1000 запросов за 3.5 секунды (длина его теста).
Признаю — тестирование у него не является строгим доказательством. Он сравнивал сохранение узлов DOM-документов с SET и GET в Redis. Причём он ещё не учёл, что GlobalsDB выполняла дополнительные команды kill (удаления узлов) и data(проверки существования узла), что снижало производительность. Вообще не понимаю зачем он там kill использовал — наверное, удалял деревья.
Да, я ошибся, когда думал, что он использовал свой менеджер http-запросов совместно с http-клиентом.
Однако не вижу проблемы, в том, каким образом он напихал в очередь запросы.
Node.JS на хорошей машине позволяет держать миллион соединений. Так что напихать 1000 запросов в очередь не проблема.
Если вы хотите оспорить результаты его теста, то должны сказать что его менеджер запросов не способен принять и поместить в очередь 1000 запросов за 3.5 секунды (длина его теста).
Признаю — тестирование у него не является строгим доказательством. Он сравнивал сохранение узлов DOM-документов с SET и GET в Redis. Причём он ещё не учёл, что GlobalsDB выполняла дополнительные команды kill (удаления узлов) и data(проверки существования узла), что снижало производительность. Вообще не понимаю зачем он там kill использовал — наверное, удалял деревья.
Ну вот вы и сами признали, что процессы разделены, а не являются одним.
Это «дочерние процессы» в терминах Node, у них другая коммуникация, нежели между изолированными процессами ОС (и тем более — приложениями на разных машинах).
Так что напихать 1000 запросов в очередь не проблема.
Конечно, не проблема. Только потом каждый из этих запросов порождает порядка пятисот обращений к GlobalsDB, и вот эти обращения по какому транспорту идут?
А обращения к Redis каждое проходит по TCP/IP loopback, со всеми накладными расходами.
Вот хорошая статья о том, что такое redis-benchmark, и почему ее применение в данном случае вообще ни о чем не говорит.
тестирование у него не является строгим доказательством.
Воообще никаким доказательством, к сожалению.
Вот хорошая статья о некорректности подобных тестирований.
Спасибо за обсуждение. Я думаю мы нашли истину. Я склоняюсь к тому, что по возможности сделаю подобное тестирование, но более строгое. Нужно будет сделать абсолютно такой же интерфейс как и у Redis. И потестировать бенчмарковской утилитой redis.
Если у вас есть желание самому провести — я буду рад. Скажите тогда мне, чтобы мы не дублировали друг друга.
Если у вас есть желание самому провести — я буду рад. Скажите тогда мне, чтобы мы не дублировали друг друга.
Судя по скорости ответа, статьи вы в лучшем случае проглядели по диагонали.
GET/SET Benchmarks are not a great way to compare different database systems.
Ответ был написан до того, как вы привели свои ссылки. Не нужно предполагать в людях худшее.
Предложите другую КОНКРЕТНУЮ методику тестирования. Только без общих слов.
Предложите другую КОНКРЕТНУЮ методику тестирования. Только без общих слов.
Ответ был написан до того, как вы привели свои ссылки. Не нужно предполагать в людях худшее.
Извините, был невнимателен, не посмотрел, на что вы отвечаете.
Предложите другую КОНКРЕТНУЮ методику тестирования. Только без общих слов.
Да в той же статье написано все — выбираем конкретный сценарий использования, дальше реализуем его под обе БД, смотрим, какую нагрузку выдерживает. В качестве сценария можно выбрать, например, shopping cart — создали, запихали k строчек, вывели всю целиком. Соответственно, потом берем и смотрим, сколько параллельных сценариев система выдержит (и что является ограничивающим фактором). Естественно, обе БД должны быть сконфигурированы под одинаковые гарантии durability (если это возможно). Для пущего счастья надо тестировать два разных типа распределения: когда бд на той же машине, что апп, и когда на разных.
if (uri.indexOf('/test/') !== -1) {
var action = {query: urlObj.query};
var requestObj = {action: action, request: request, response: response, urlObj: urlObj};
qoper8.addToQueue(requestObj, handler);
}А тут пришедший http-запрос помещается в очередь.
Мне вот непонятна ваша мотивация: зачем вы спорите?
Вопрос не в том http или нет, а в том что передача данных между двумя процессами одной системы и передача данных через сокеты — две большие разницы. Например, на Java я легко с помощью обычных хештаблиц достигал сохранение и получение десятков миллионов элементов в секунду на обычном компе (не сервере), потому что не было накладных расходов на сеть. Даже если при этом переодически делать серилизацию данных в файлы раз в секунду, все равно работало бы куда быстрее посылать данные через сеть в стороннею систему. Естественно, при сравнении работы одной системы через сеть даже в пределах одной машины, второй передающий данные напрямую через память можно получить даже десятикратное превосходство.
По этой более новой ссылке мужик получал, тестируя Redis, на Macbook Pro 37 000 вставок/сек и 550 000 вставок/секунду на hi-end сервере.
Из комментария там же:
I was able to achieve this, without any optimizations, on a 512MB VM I made on my server:
redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -s /tmp/redis.sock -P 16 -q
SET: 838926.19 requests per second
GET: 375093.78 requests per second
LPUSH: 844951.44 requests per second
LPOP: 973709.81 requests per second
Программы на этом языке можно компилировать — и это даёт огромную скорость обработки данных в БД
Наверно, всё-таки не это. А наверно, те свойства глобалов, которые вы перечислили выше.
Если быть точнее, то можно ответить так:
Скорость глобалов = Простая архитектура * Ассемблер * Отточенность алгоритмов * Компиляция COS/M * Продуманные алгоритмы кеширования
Каждый множитель важен. И, наверное, есть ещё какие-то множители, которые только разработчики знают.
Меня лично изумила скорость вставки при первом знакомстве с глобалами.
Скорость глобалов = Простая архитектура * Ассемблер * Отточенность алгоритмов * Компиляция COS/M * Продуманные алгоритмы кеширования
Каждый множитель важен. И, наверное, есть ещё какие-то множители, которые только разработчики знают.
Меня лично изумила скорость вставки при первом знакомстве с глобалами.
На сколько я помню в MUMPS АCID достигается ручным программированием каждой ситуации. Он вроде бы есть, но на самом его нет.
Bы уже сумели победить это проблему?
www.computerworld.com/article/2548231/it-project-management/problems-abound-for-kaiser-e-health-records-management-system.html
В общем, было примерно так: Epic политическими маневрами (читай откат) добилась внедрения ее софта, написанного на MUMPS, который имеет проблемы с масштабируемостью и секьюрити данных. Для борьбы с этим используются Citrix сервера, которым объемы тоже не под силу. Ай, маладцы, здорово продумали архитектуру! CIO поплатился головой.
Bы уже сумели победить это проблему?
www.computerworld.com/article/2548231/it-project-management/problems-abound-for-kaiser-e-health-records-management-system.html
В общем, было примерно так: Epic политическими маневрами (читай откат) добилась внедрения ее софта, написанного на MUMPS, который имеет проблемы с масштабируемостью и секьюрити данных. Для борьбы с этим используются Citrix сервера, которым объемы тоже не под силу. Ай, маладцы, здорово продумали архитектуру! CIO поплатился головой.
Есть стандартные команды TSTART, TCOMMIT, TROLLBACK.
Если их использовать, то всё будет ACID.
Из статьи я понял, что Citrix и Epic бодаются на тему из-за кого глючит система.
И Epic говорит, что там где они не использовали CItrix проблем не было.
Ну, если у системы более 100 тыс. пользователей, то неудивительно, что есть жалобы. тем более, что там медперсонал пользуется, а не компьютерщики.
Если даже комп у юзера зависнет — он скажет, что система глючит.
Если их использовать, то всё будет ACID.
Из статьи я понял, что Citrix и Epic бодаются на тему из-за кого глючит система.
И Epic говорит, что там где они не использовали CItrix проблем не было.
Ну, если у системы более 100 тыс. пользователей, то неудивительно, что есть жалобы. тем более, что там медперсонал пользуется, а не компьютерщики.
Если даже комп у юзера зависнет — он скажет, что система глючит.
А можно про I из ACID по подробнее?
На уровне SQL в Caché, даже полноценного READ COMMITTED, когда я смотрел, не было.
Как обстоит дело с глобалами?
На уровне SQL в Caché, даже полноценного READ COMMITTED, когда я смотрел, не было.
Как обстоит дело с глобалами?
Я на домашнем компе запустил транзакцию
TSTART
Set ^ff=5
В другом потоке глобал ^ff был неопределён.
Из чего вывод — Isolated.
TSTART
Set ^ff=5
В другом потоке глобал ^ff был неопределён.
Из чего вывод — Isolated.
Из чего вывод — Isolated.
Мягко говоря, основание для вывода недостаточно.
Ваш пример кода или идея для проверки?
Пример кода уже не раскопаю. Но в SQL изоляция не работала на 2009 год.
Идея простая – иметь таблицу с числами. Гонять на ней много параллельных транзакций, которые уменьшают одно число и увеличивают другое так, чтобы сумма не изменялась. А-ля перевод денег со счёта на счёт. В параллельной транзакции постоянно считать сумму и проверять, что она действительно неизменна.
Идея простая – иметь таблицу с числами. Гонять на ней много параллельных транзакций, которые уменьшают одно число и увеличивают другое так, чтобы сумма не изменялась. А-ля перевод денег со счёта на счёт. В параллельной транзакции постоянно считать сумму и проверять, что она действительно неизменна.
Я попробовал вашу идею. В первом потоке:
Во втором параллельном потоке
Работает.
Set ^f1=5,^f2=5
TSTART
Set ^f1=4,^f2=6
Set ^f1=3,^f2=7
Set ^f1=2,^f2=8Во втором параллельном потоке
TSTART
Write ^f1+^f2
10
Write ^f1+^f2
10
Write ^f1+^f2
10
Write ^f1+^f2
10Работает.
Я не совсем это имел ввиду, а вернее совсем не это…
Нужно намного много данных и много параллельных транзакций.
Идея простая, на самом деле.
Чтобы организовать изоляцию, нужны либо блокировки, либо MVCC.
На блокировках при большом объёме данных и большом потоке транзакций оно неизбежно начнёт тормозить.
MVCC в Caché нет. Значит оно либо будет тормозить, либо будет нарушать изоляцию. Хотелось понять, какой из вариантов в каких случаях реализуется.
Нужно намного много данных и много параллельных транзакций.
Идея простая, на самом деле.
Чтобы организовать изоляцию, нужны либо блокировки, либо MVCC.
На блокировках при большом объёме данных и большом потоке транзакций оно неизбежно начнёт тормозить.
MVCC в Caché нет. Значит оно либо будет тормозить, либо будет нарушать изоляцию. Хотелось понять, какой из вариантов в каких случаях реализуется.
Ну либо я не прав на счёт MVCC. Анализа хочется, а не просто вердикта, что всё круто, но не понятно как и почему.
Вот что я нашёл:
Caché SQL, относится не к глобалам, а к таблицам на глобалах.
ISOLATION LEVEL READ UNCOMMITTED (the default)
ISOLATION LEVEL READ COMMITTED
GT.M (а вот про SERIALIZE в TSTART)
Caché SQL, относится не к глобалам, а к таблицам на глобалах.
ISOLATION LEVEL READ UNCOMMITTED (the default)
ISOLATION LEVEL READ COMMITTED
GT.M (а вот про SERIALIZE в TSTART)
Each block has a transaction number that GT.M sets to the current database transaction number when updating a block.— очень похоже на описание MVCC.
Вот что я нашёл:
Caché SQL, относится не к глобалам, а к таблицам на глобалах.
ISOLATION LEVEL READ UNCOMMITTED (the default)
ISOLATION LEVEL READ COMMITTED
Да, но READ COMMITTED работает с нарушениями. Проще сказать, что его нет.
GT.M (а вот про SERIALIZE в TSTART)
Each block has a transaction number that GT.M sets to the current database transaction number when updating a block.
— очень похоже на описание MVCC.
Не похоже, пока больше похоже на блокировочника.
Как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки.
Можно, пожалуйста, ссылку на конкретные тесты?
Правильно ли я понимаю, что github.com/Yomguithereal/baobab частный случай глоала?
Ещё на глобалы можно посмотреть как на многомерный key->value. Многомерный ключ, скалярное value. На след. неделе, надеюсь, напишу статью об этом.
Лучше смотреть на них как на key->value с составным ключом, это куда ближе к реальности. Потому что фактически все ключи пакуются в один составной ключ для B-tree. Это было описано в документации к старым версиям Кашэ. docs.intersystems.com/cache41/prg/prgglobalstorage.html
В более новых версия Кашэ этот раздел документации выпилили, но внутри, скорее всего, ничего не поменялось. Во всяком случае ограничение на длину так и осталось на все ключи вместе, а не по отдельности.
В более новых версия Кашэ этот раздел документации выпилили, но внутри, скорее всего, ничего не поменялось. Во всяком случае ограничение на длину так и осталось на все ключи вместе, а не по отдельности.
Есть сходство с составным ключом в SQL, но это не то. В SQL составной ключ идёт по жёстко заданному набору колонок, а в глобалах абсолютно по всем наборам всех свойств. И его не надо никак определять в схеме данных.
Запросто на обычном key-value хранилище глобал не получится эмулировать. В глобалах ^a(«b»,«b») != ^a(«bb»). Я проверял. Придётся исхитряться. В индексах числа хранятся как числа, строки как строки.
Всякие полезные функции обхода дерева, удаления поддерева, копирования поддерева тоже придётся писать.
Ну а эмулировать транзакции и вовсе не получится. Поэтому лучше не пытаться сделать глобалы на key-value, а использовать готовые.
Запросто на обычном key-value хранилище глобал не получится эмулировать. В глобалах ^a(«b»,«b») != ^a(«bb»). Я проверял. Придётся исхитряться. В индексах числа хранятся как числа, строки как строки.
Всякие полезные функции обхода дерева, удаления поддерева, копирования поддерева тоже придётся писать.
Ну а эмулировать транзакции и вовсе не получится. Поэтому лучше не пытаться сделать глобалы на key-value, а использовать готовые.
Если не вникать, что как устроено, то индекс в глобали именно набор ключей. А за остальное отвечает реализация. Глобалы можно построить на любой УПОРЯДОЧЕННОЙ базе ключ-значение. Нужны только операции доступа к первому, последнему, следующему и предыдущему ключам. На ХЕШ таблицах и неупорядоченных базах ключ-значение глобал не построишь. Вопрос только в эффективности такого решения. Реализация глобалов по крайней мере в CACHE по моему опыту очень эффективна.
При поиске в интернете можно обратить внимание на порядок появления терминов:
глобал - 1970, nosql - 2009
А я то думал тут расскажут конкретно о структурах данных которые можно использовать для индексации: ну там R-tree X-tree Quad-tree MVP-tree B*-tree, хэш-таблицах, различных cache oblivious и sync oblivious решениях, ну и как это всё вяжется в контексте упомянутых «глобалов». О тех вещах, которые действительно влияют на производительность.
> Удаление поддеревьев — ещё одна сильная сторона глобалов. Для этого не нужна рекурсия. Это происходит невероятно быстро.
На уровне абстракции это звучит мега-круто, но как такое удаление происходит на практике, в физической реализации? Сдаётся мне, помечается только верхний узел, а реальное удаление откладывается до момента компактирования базы, сборки мусора или какого-то эквивалента. Чудес не бывает, чтобы физически удалить информацию, нужно пройти всё поддерево.
На уровне абстракции это звучит мега-круто, но как такое удаление происходит на практике, в физической реализации? Сдаётся мне, помечается только верхний узел, а реальное удаление откладывается до момента компактирования базы, сборки мусора или какого-то эквивалента. Чудес не бывает, чтобы физически удалить информацию, нужно пройти всё поддерево.
Вот у меня к вам только одно острое пожелание. Пишите про структуры данных — отлично! Но зачем при этом гнобить файловые системы?
Простейшая операция, которая вам все ваши структуры данных поставит в неприличную позу:
Дописывает в каждый файл один байт по смещению 1000000000, если файл меньше такого размера, увеличивает файл до соотв. размера.
Моя домашнаяя файловая система на зашифрованном томе справляется с этой задачей для 56 первых попавшихся файлов (бедная репа с github'а) за душераздирающие 23с (привет, иноды!), то есть примерно 0.5с на файл.
А ведь это не самый сложный пример. Кому-то может захотеться, например, сделать программу, которая будет в миллион файлов записывать по-очереди по байту за раз. И если ваша «фс» должна такое переживать. А потом кто-то захочет эти файлы прочитать подряд, и будет крайне недоволен, если у вас будет большая фрагментация (привет, экстенты).
Не надо гнать на ФС. Это очень сложные и специализированные базы данных, и у них не то, чтобы всё хорошо, но там очень и очень много думали.
Простейшая операция, которая вам все ваши структуры данных поставит в неприличную позу:
find . -type f |xargs -I dd if=/dev/random of=I oflag=direct bs=1 count=1 seek=1000000000
Дописывает в каждый файл один байт по смещению 1000000000, если файл меньше такого размера, увеличивает файл до соотв. размера.
Моя домашнаяя файловая система на зашифрованном томе справляется с этой задачей для 56 первых попавшихся файлов (бедная репа с github'а) за душераздирающие 23с (привет, иноды!), то есть примерно 0.5с на файл.
А ведь это не самый сложный пример. Кому-то может захотеться, например, сделать программу, которая будет в миллион файлов записывать по-очереди по байту за раз. И если ваша «фс» должна такое переживать. А потом кто-то захочет эти файлы прочитать подряд, и будет крайне недоволен, если у вас будет большая фрагментация (привет, экстенты).
Не надо гнать на ФС. Это очень сложные и специализированные базы данных, и у них не то, чтобы всё хорошо, но там очень и очень много думали.
Спасибо за комментарий. Конечно, такие хитрости типа seek=1000000000 сложно (а скорее всего и невозможно) сделать на глобалах. Фрагментация — отдельный вопрос, который мало где вообще решается в автоматическом режиме.
Однако создание псевдофайловой системы для хранения маленьких файлов на глобалах выглядит хорошей идеей. Записать в миллион узлов по байту — очень быстрая операция для глобалов.
Над глобалами с 66 года тоже очень много думали.
Однако создание псевдофайловой системы для хранения маленьких файлов на глобалах выглядит хорошей идеей. Записать в миллион узлов по байту — очень быстрая операция для глобалов.
там очень и очень много думали.
Над глобалами с 66 года тоже очень много думали.
Вы думаете, что вы первый, кто придумал предложить object storage в качестве файловой системы?
Три простые вещи, в которых ваша файловая система должна быть быстрой, чтобы её вообще восприняли в качестве «файловой системы».
1) random IO (включая запись). Простейший тест: перенесите mysql/postgres с ext4 на вашу файловую систему и посмотрите «сколько транзакций в секунду» будет выполняться.
2) Трафик виртуальных машин. Положите на вашу файловую систему виртуалку и посмотрите, сколько там будет выполняться что-то невинное (например, debootstrap).
3) Положите туда почтовую базу любого более-менее приличного почтового клиента (сервера). На выбор: thunderbird, microsoft exchange, evolution.
Дополнительные условия для того, чтобы быть приличной FS:
Поддержка partial blocks, поддержка метаинформации (расширенные атрибуты)
Понимаете, воспринимать файловую систему как 'object storage' можно, только пользы от неё будет — как от object storage'а.
Я верю, что «над глобалами думали с 66 года». Но это всего лишь структура данных, и делать из неё серебрянную пулю для решения всех проблем файловых систем — мягко говоря, ошибка.
Три простые вещи, в которых ваша файловая система должна быть быстрой, чтобы её вообще восприняли в качестве «файловой системы».
1) random IO (включая запись). Простейший тест: перенесите mysql/postgres с ext4 на вашу файловую систему и посмотрите «сколько транзакций в секунду» будет выполняться.
2) Трафик виртуальных машин. Положите на вашу файловую систему виртуалку и посмотрите, сколько там будет выполняться что-то невинное (например, debootstrap).
3) Положите туда почтовую базу любого более-менее приличного почтового клиента (сервера). На выбор: thunderbird, microsoft exchange, evolution.
Дополнительные условия для того, чтобы быть приличной FS:
Поддержка partial blocks, поддержка метаинформации (расширенные атрибуты)
Понимаете, воспринимать файловую систему как 'object storage' можно, только пользы от неё будет — как от object storage'а.
Я верю, что «над глобалами думали с 66 года». Но это всего лишь структура данных, и делать из неё серебрянную пулю для решения всех проблем файловых систем — мягко говоря, ошибка.
Я верю, что «над глобалами думали с 66 года». Но это всего лишь структура данных, и делать из неё серебрянную пулю для решения всех проблем файловых систем — мягко говоря, ошибка.
Глобалы – это даже не структура данных, а всего лишь красивая обёртка над B-tree.
Глобалы – это даже не структура данных, а всего лишь красивая обёртка над B-tree.
Глобалы — это структура данных и способ хранения данных, где в глубине скорее всего зарыто B-tree.
Впрочем и в реляционных базах тоже зарыто B-tree и где оно только не зарыто…
Глобалы — это структура данных и способ хранения данных, где в глубине скорее всего зарыто B-tree.
Вы не знаете точно?
Я не могу отвечать за все СУБД на глобалах. Я всего с тремя так или иначе имел дело. В GT.M зарыто B-tree.
В Caché зарыто B*-tree + ещё какая-то технология.
В Caché зарыто B*-tree + ещё какая-то технология.
Очень ждём во второй части детального описания что и как реализовано. Хочется мяса, а манной каши уже достаточно на эту тему было.
Вообще-то я могу дать ссылки на внутреннее устройство сразу, так как не буду в статьях его рассматривать:
Caché 1 — свежее, 2 — несколько устаревшее
GT.M
Что написано, то написано. Подробнее можно только в исходном коде посмотреть.
Caché 1 — свежее, 2 — несколько устаревшее
GT.M
Что написано, то написано. Подробнее можно только в исходном коде посмотреть.
Скажу по-другому. Не интересна статья, где говориться как круто обращаться к данным вот с таким синтаксисом, а там внутри ядро, которое развивается с 1966 года, поэтому всё быстро и надёжно. А хочется анализ увидеть: реальные решения, их плюсы и минусы.
Насколько реальные? Конкретные сданные проекты или теоретические примеры решений типовых проблем?
Какие решения заложены в реализации глобалов (хотя бы одну, например Open Source GT.M)? Сравнить это с решениями, заложенными в основу других NoSQL СУБД.
Я настолько задолбал вопросами главного разработчика GT.M, что он мне сказал:
А там 50% исходного кода на ассемблере.
С InterSystems примерно та же история. Я очень много вопросов задаю.
Если разберусь с деталями внутреннего устройства — напишу, конечно.
Пока просто хочу рассказать об основах. Внутреннее устройство БД интересно немногим…
Let me refer you to the ultimate source of information, the source code.
А там 50% исходного кода на ассемблере.
С InterSystems примерно та же история. Я очень много вопросов задаю.
Если разберусь с деталями внутреннего устройства — напишу, конечно.
Пока просто хочу рассказать об основах. Внутреннее устройство БД интересно немногим…
Сам факт, что база с автоматическим сохранением на диск + индексация + сортировка смогла опередить in-memory базу удивителен.
Когда заявляете такие вещи, которые удивляют вас самих, будьте готовы, что объяснение заинтересует многих. Весь исходный код знать не обязательно, нужно понять алгоритмы и структуры данных.
Вот +1. Из статьи мало что понятно — откуда плюшки-то. Ощущение, что рекламный агент пытается впарить чудо-технологию.
«Внутре у ней… эта… неонка!»
Господа, ну во-первых, длительность разработки кода никак не говорит о его качестве. Он мог 100500 раз быть переписан.
Во-вторых, не стоит махать ассемблером, как чудо-палкой. Современные процессоры могут кучу различных оптимизаций кода, которые человеку сложно учесть. Поэтому этим занимаются компиляторы, а не люди. Если код не совершенно элементарный, то переписывание его на asm не гарантирует вам автоматически бОльшую скорость, увы. Я не говорю, что компилятор всегда сделает лучше, но и обратное тоже не верно.
Остальные аргументы — «отточенные алгоритмы», «вылизанная архитектура» — простите меня за прямоту, это рекламный bullshit.
А что persistent db обгоняет in memory — это объективно абсурд, говорит лишь о том, что тестирование проведено не корректно.
Но автор заинтриговал! =) Посмотрим, что это за зверь. Хотя никаких иллюзий не питаю, если бы это решение было таким офигительно крутым на протяжении десятков лет — о нем бы на любом заборе было написано. Однако этого не наблюдается.
«Внутре у ней… эта… неонка!»
Господа, ну во-первых, длительность разработки кода никак не говорит о его качестве. Он мог 100500 раз быть переписан.
Во-вторых, не стоит махать ассемблером, как чудо-палкой. Современные процессоры могут кучу различных оптимизаций кода, которые человеку сложно учесть. Поэтому этим занимаются компиляторы, а не люди. Если код не совершенно элементарный, то переписывание его на asm не гарантирует вам автоматически бОльшую скорость, увы. Я не говорю, что компилятор всегда сделает лучше, но и обратное тоже не верно.
Остальные аргументы — «отточенные алгоритмы», «вылизанная архитектура» — простите меня за прямоту, это рекламный bullshit.
А что persistent db обгоняет in memory — это объективно абсурд, говорит лишь о том, что тестирование проведено не корректно.
Но автор заинтриговал! =) Посмотрим, что это за зверь. Хотя никаких иллюзий не питаю, если бы это решение было таким офигительно крутым на протяжении десятков лет — о нем бы на любом заборе было написано. Однако этого не наблюдается.
Спасибо за отзыв! Рад, что получилось написать интересно.
В США базы данных на глобалах — это многомиллиардный бизнес.
Вы будете удивлены, наверное, но банки с десятками миллионов пользователей используют глобалы в продакшене для ATM уже десятки лет.
На западе практически любая транзакция проходит через иерахическую БД: или на глобалах или на подобии глобалов от IBM
В своё время в СССР не стали копировать эту технологию, а когда уже решили, то СССР пошёл вразнос.
Как я объяснял выше такое может легко получиться при условии одинакового объёма базы. Вся база закешируется в памяти и будет время от времени синхронизироваться. Любой объём данных, которая in-memory БД может держать в памяти, абсолютно также может держать в памяти и персистентная БД.
Если трафик на запись не является колоссальным, а in-memory БД как правило на чтение используется + на сервере есть рейд с write-back, то при условии чрезвычайной оптимизированности кода персистентной БД она может легко обгонять in-memory БД.
Ссылки я приводил. Репозиторий на github для повторения тестирования тоже.
В США базы данных на глобалах — это многомиллиардный бизнес.
Вы будете удивлены, наверное, но банки с десятками миллионов пользователей используют глобалы в продакшене для ATM уже десятки лет.
На западе практически любая транзакция проходит через иерахическую БД: или на глобалах или на подобии глобалов от IBM
В своё время в СССР не стали копировать эту технологию, а когда уже решили, то СССР пошёл вразнос.
А что persistent db обгоняет in memory — это объективно абсурд
Как я объяснял выше такое может легко получиться при условии одинакового объёма базы. Вся база закешируется в памяти и будет время от времени синхронизироваться. Любой объём данных, которая in-memory БД может держать в памяти, абсолютно также может держать в памяти и персистентная БД.
Если трафик на запись не является колоссальным, а in-memory БД как правило на чтение используется + на сервере есть рейд с write-back, то при условии чрезвычайной оптимизированности кода персистентной БД она может легко обгонять in-memory БД.
Ссылки я приводил. Репозиторий на github для повторения тестирования тоже.
Но это всего лишь структура данных
Это не только структура данных, но и очень отлаженная и вылизанная программная реализация.
Я собственно утверждаю, что только для хранения огромного количества маленьких файлов глобалы могли бы подойти.
Вообще пример с ФС был дан, чтобы лучше объяснить идею глобалов.
Файловая система стандартная деревянная структура данных далекая от совершенства. В Linuxe постоянно появляются новые файловые системы. Что говорит, что она далека от совершенства. Только в качестве данных в ФС используется пространство устройства которым она управляет. И за пределы теории структур данных ФС не выходят. И реализовать ФС можно на любой деревянной базе.
Дисклеймер: статья и комментарии являются личным мнением автора и не являются официальной позицией корпорации InterSystems.
Но в случае глобалов мы получаем на выходе структуризованное проиндексированное хранилище, с которым можно в дальнейшем просто и быстро работать. [...] Данные в глобале всегда проиндексированы. Их обход как на одном уровне, так и вглубь дерева, всегда быстр.
Кстати, об индексах. В «традиционных», как вы выражаетесь, БД под индексированием обычно понимают добавление дополнительных структур данных обеспечивающих более высокую скорость поиска (и иногда чтения). Судя по статье, вы под этим понимаете другое.
Предположим, у нас есть представленная вашей же картинкой структура, хранящая данные о пользователях:
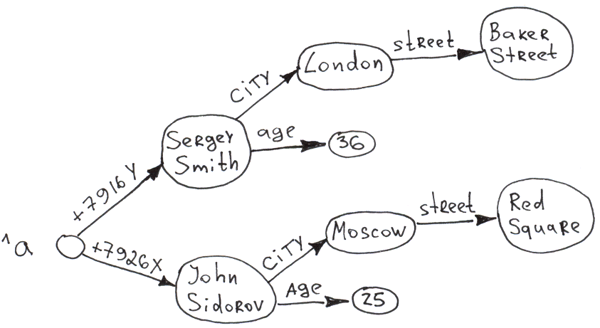
Вы утверждаете, что:
Данные сортируются по ключу. В дальнейшем при обходе массива первым элементом станет «Sergey Smith», а вторым «John Sidorov». При получении списка пользователей из глобала база не тратит времени на сортировку.
А теперь давайте рассмотрим два сценария.
- Нам надо вывести список пользователей в порядке возрастания их возраста
- Нам надо вывести список пользователей, живущих в Москве
Какие в глобалах есть технологические решения для оптимизации таких запросов?
Хорошой вопрос.
Я уточню: в глобалах любой запрос, в котором используются индексы а-ля индексы массива, является одновременно и индексированным в терминах обычных БД.
То есть запрос значения глобала ^q(x,y,z) будет одновременно выдавать соотвествующее значение массива, которое будет искаться в базе по ранее автоматически созданному индексу на B-tree (x,y,z).
Касательно второй части вопроса. Для поиска по городу и возрасту нам придётся создать вторичные индексы. Иначе это будет делаться перебором и долго.
Я бы написал процедуру для сохранения пользователя, обернул бы её в транзакцию. Примерно так:
Когда нам потребовалось бы вывести список пользователей по возрасту, то с помощью функции $Order(^a(«i_age»)) я бы получил список id пользователей отсортированных по возрасту.
Далее по id вывел бы его с подгрузкой остальных полей.
Для вывода москвичей я бы вызвал функцию $Order(^a(«i_city»,«Moscow»)). Эта функция нашла бы моментально первого москвича, а далее я бы вызывал в цикле $Order(^a(«i_city»,«Moscow», предыдущий_id)), а потом также по id выводил бы сопутствующие поля.
Глобалы похожи на Си — это низкоуровневая вещь, однако работает быстро. Над ними в Caché есть объектная и SQL-надстройки, которые позволяют упростить работу.
Я уточню: в глобалах любой запрос, в котором используются индексы а-ля индексы массива, является одновременно и индексированным в терминах обычных БД.
То есть запрос значения глобала ^q(x,y,z) будет одновременно выдавать соотвествующее значение массива, которое будет искаться в базе по ранее автоматически созданному индексу на B-tree (x,y,z).
Касательно второй части вопроса. Для поиска по городу и возрасту нам придётся создать вторичные индексы. Иначе это будет делаться перебором и долго.
Я бы написал процедуру для сохранения пользователя, обернул бы её в транзакцию. Примерно так:
insert_user(id, name, age, city)
TSTART
Set ^a(id)=name
Set ^a(id, "city")=city, ^a(id, "age")=age
Set ^a("i_city",city, id)=1
Set ^a("i_age",age, id)=1
TCOMMITКогда нам потребовалось бы вывести список пользователей по возрасту, то с помощью функции $Order(^a(«i_age»)) я бы получил список id пользователей отсортированных по возрасту.
Далее по id вывел бы его с подгрузкой остальных полей.
Для вывода москвичей я бы вызвал функцию $Order(^a(«i_city»,«Moscow»)). Эта функция нашла бы моментально первого москвича, а далее я бы вызывал в цикле $Order(^a(«i_city»,«Moscow», предыдущий_id)), а потом также по id выводил бы сопутствующие поля.
Глобалы похожи на Си — это низкоуровневая вещь, однако работает быстро. Над ними в Caché есть объектная и SQL-надстройки, которые позволяют упростить работу.
Я уточню: в глобалах любой запрос, в котором используются индексы а-ля индексы массива, является одновременно и индексированным в терминах обычных БД.
Я боюсь, что у нас с вами фундаментально разное понимание «индексации». В моем понимании, проход по «индексам» глобала эквивалентен индексам традиционных БД только тогда, когда эти «индексы» являются значениями. Иными словами,
^a("+7926X") — это индекс (потому что он имеет семантику «найди такой элемент, идентификатор которого равен „+7926X“), но ^a("city") — не индекс, потому что его семантика — »найди таблицу City".Давайте попробуем зайти с другой стороны. Какова алгоритмическая сложность вставки элемента в глобал (пока рассмотрим только один уровень) и его получения оттуда?
Для поиска по городу и возрасту нам придётся создать вторичные индексы.
И сами глобалы этого никак не умеют?
Я бы написал процедуру для сохранения пользователя, обернул бы её в транзакцию.
Тем самым мы (а) увеличили количество операций записи приблизительно вдвое, увеличили время блокировки системы настолько же и, что интереснее, (б) теперь должны поддерживать связность этих «вторичных индексов» все последующие разы.
С моей точки зрения это означает, что глобалы — не индексированы; потому что характеристика «доступ по ключу в дереве» характерна дереву, а не индексам, а собственно индексов в понимании «традиционных БД», т.е. возможности автоматически оптимизировать доступ по не-ключам, мы пока не нашли.
Насчёт ^a(«city»). Представьте, что подобных свойств миллион. В глобале не будет перебора, будет использование дерева. Очень быстро узел ^a(«city») будет найден. Внутри глобалов, как правило, та или иная разновидность B-tree.
Индексы в реляционных БД сами по себе деревья. И глобалы деревья. Поэтому можно сказать, что любой проход по дереву к определённому узлу эквивалентен тому, что мы использовали индекс в реляционных БД.
Нужно различать глобалы и то, что можно на них сделать. В том же Caché можно работать с глобалами через SQL (или объектный доступ) — в этом случае все эти низкоуровневые операции создания вторичных индексов, поиска по ним, поддержания целостности будут делаться невидимо для программиста.
В этой статье я рассказываю именно о глобалах. Из них можно собрать реляционную базу, можно документную, можно графовую.
Возможность убыстрить доступ к произвольным полям есть. Она не будет автоматической, если её не запрограммировать. Опять таки всё это касается работы с глобалами напрямую.
Глобалы — это не замена SQL. Это возможность делать скоростные NoSQL приложения, специализированные БД и многое другое. Это низкоуровневая вещь. Поэтому основные операции с ними можно выучить за час, чего не скажешь об операторах SQL.
Индексы в реляционных БД сами по себе деревья. И глобалы деревья. Поэтому можно сказать, что любой проход по дереву к определённому узлу эквивалентен тому, что мы использовали индекс в реляционных БД.
И сами глобалы этого никак не умеют?
Нужно различать глобалы и то, что можно на них сделать. В том же Caché можно работать с глобалами через SQL (или объектный доступ) — в этом случае все эти низкоуровневые операции создания вторичных индексов, поиска по ним, поддержания целостности будут делаться невидимо для программиста.
В этой статье я рассказываю именно о глобалах. Из них можно собрать реляционную базу, можно документную, можно графовую.
Возможность убыстрить доступ к произвольным полям есть. Она не будет автоматической, если её не запрограммировать. Опять таки всё это касается работы с глобалами напрямую.
Глобалы — это не замена SQL. Это возможность делать скоростные NoSQL приложения, специализированные БД и многое другое. Это низкоуровневая вещь. Поэтому основные операции с ними можно выучить за час, чего не скажешь об операторах SQL.
Насчёт ^a(«city»). Представьте, что подобных свойств миллион. В глобале не будет перебора, будет использование дерева.
А вы считаете, что обращение к нужно таблице в «традиционных» БД делается перебором? Я сейчас говорю о семантике, а не о скорости, в любом случае.
Поэтому можно сказать, что любой проход по дереву к определённому узлу эквивалентен тому, что мы использовали индекс в реляционных БД.
Технологически, но не семантически. И, как следствие, результаты получаются различными.
Именно поэтому я призываю вас не писать, что «глобалы дают проиндексированное хранилище». Глобалы дают дерево, с характерными для него особенностями (включая время доступа). Индексы — это другая сущность, ее глобалы не дают.
Кстати, вы так и не ответили про алгоритмическую сложность операций на глобалах.
^a(«city») — это не таблица.
Чтобы вам было проще используйте аналогию, что глобал — это таблица — ^a.
В глобалах семантика своя. Я пытаюсь найти аналогии для людей из известных терминов.
Какие именно результаты различны?
Когда я запрашиваю ветви узла (команда $Order) ^a(5, «city») это эквивалентно тому что я делаю:
Select city from a where id=5 Order by city
(Допустим в таблице содержатся маршруты коммивояжера)
Если мне нужно только значение ^a(5, «city») это эквивалентно
Select city from a where id=5
(Таблица с личными данными)
Алгоритмическая сложность — точно не знаю. Учитывая, что всё построено на разновидностях B-tree примерно O(log(N)).
На практике при вставке 300M значений я не замечал никакого торможения, кроме как из-за забивающегося кеша на запись. Когда европейское космическое агентство тестировало вставку на протяжении нескольких дней, то тоже не заметили торможения вызванного разбуханием глобала.
Чтобы вам было проще используйте аналогию, что глобал — это таблица — ^a.
В глобалах семантика своя. Я пытаюсь найти аналогии для людей из известных терминов.
И, как следствие, результаты получаются различными.
Какие именно результаты различны?
Когда я запрашиваю ветви узла (команда $Order) ^a(5, «city») это эквивалентно тому что я делаю:
Select city from a where id=5 Order by city
(Допустим в таблице содержатся маршруты коммивояжера)
Если мне нужно только значение ^a(5, «city») это эквивалентно
Select city from a where id=5
(Таблица с личными данными)
Алгоритмическая сложность — точно не знаю. Учитывая, что всё построено на разновидностях B-tree примерно O(log(N)).
На практике при вставке 300M значений я не замечал никакого торможения, кроме как из-за забивающегося кеша на запись. Когда европейское космическое агентство тестировало вставку на протяжении нескольких дней, то тоже не заметили торможения вызванного разбуханием глобала.
В глобалах семантика своя. Я пытаюсь найти аналогии для людей из известных терминов.
Вот я вам и показываю ошибку в вашей аналогии.
Какие именно результаты различны?
Семантика индекса и основного ключа — разные вещи. И семантика доступа к данным и метаданным — разные вещи.
Вот возьмем, казалось бы, банальную вещь: словарь (построенный на хэш-таблице), значениями которого являются объекты (скажем, пользователи), а ключом — идентификаторы объектов (скажем, UID пользователя). Доступ к конкретному объекту стоит нам O(1) (это свойство хэш-таблицы). Доступ к конкретному свойству конкретного объекта — тоже O(1), потому что доступ к свойству объекта является элементарной операцией языка. Итого мы имеем структуру, болезненно похожую на ваш двухуровневый глобал, и со стоимостью операций O(1). Является ли она «индексированной»? Нет. Точнее, является — только по «первичному ключу», что в БД эквивалентно кластерному индексу по первичному ключу. Вы не можете за те же O(1) получить пользователя с заданным емейлом. Аналогично и глобалы (в вашем описании) не являются индексированной структурой. Они являются структурой, которая дает быстрый доступ по (строго одному для каждого значения) ключу, но никак не индексирует сами значения.
Поэтому еще раз вас прошу — не вводите в заблуждение, не пишите, что глобалы, помимо основных своих качеств, еще и дают индексированное хранилище. Оно не индексированное. Оно просто дерево, с характерными для дерева O(log n).
Хорошо. Вы фокусируете меня на том, что индекс — это более общее понятие, чем первичный ключ.
Я согласен.
Индекс работает O(log(N)) и дерево работает O(log(N)). Потому что индексы внутри тоже деревья. Отличие семантическое очень тонкое.
Если при первоначальной вставке я подобрал правильную структуру дерева и сразу делаю несколько вспомогательных деревьев, то, фактически, материальная база для нужных мне быстрых поисков по нужным полям также будет создана.
По смыслу это эквивалентно, что заполнил таблицу с основным и вторичными ключами с разницей в том, что мне нужно будет самому писать процедуры для правильного осуществления этого поиска (если я не использую SQL-доступ).
А ведь я могу заполнить все нужные деревья, а потом обращаться к ним вообще из SQL. И интерпретатор SQL в Caché автоматически будет использовать мои вспомогательные деревья и использовать их как вторичные индексы.
Вопрос: чем это отличается от индексированного хранилища?
Я вижу лишь отличие на уровне глобалов — там мне действительно придётся писать доп. процедуры для выборок с использованием вторичных индексов и там нет той высокоуровневой работы с индексами, свойственной SQL.
Я согласен.
Индекс работает O(log(N)) и дерево работает O(log(N)). Потому что индексы внутри тоже деревья. Отличие семантическое очень тонкое.
Если при первоначальной вставке я подобрал правильную структуру дерева и сразу делаю несколько вспомогательных деревьев, то, фактически, материальная база для нужных мне быстрых поисков по нужным полям также будет создана.
По смыслу это эквивалентно, что заполнил таблицу с основным и вторичными ключами с разницей в том, что мне нужно будет самому писать процедуры для правильного осуществления этого поиска (если я не использую SQL-доступ).
А ведь я могу заполнить все нужные деревья, а потом обращаться к ним вообще из SQL. И интерпретатор SQL в Caché автоматически будет использовать мои вспомогательные деревья и использовать их как вторичные индексы.
Вопрос: чем это отличается от индексированного хранилища?
Я вижу лишь отличие на уровне глобалов — там мне действительно придётся писать доп. процедуры для выборок с использованием вторичных индексов и там нет той высокоуровневой работы с индексами, свойственной SQL.
Индекс работает O(log(N)) и дерево работает O(log(N)). Потому что индексы внутри тоже деревья. Отличие семантическое очень тонкое.
Да ничего тонкого. Дерево — это структура данных. Индекс — это инструмент в БД. Второе может быть построено на первом (а может и не быть).
Вопрос: чем это отличается от индексированного хранилища?
Тем, что вы поддерживаете целостность самостоятельно (и потери на этом в ваших тестах не учтены). Поэтому писать, что глобалы дают индексированное хранилище — неверно. Вы его делаете поверх глобалов, как дополнительную структуру.
Я вижу лишь отличие на уровне глобалов
А мы глобалы и обсуждаем в этой статье.
Я согласен с тем, что без использования вспомогательных деревьев не получится сделать быстрый поиск по другим полям.
В MUMPS используется несколько другая терминология, чем в традиционных БД. Индексом называется то, что обычно называется первичным ключем. Если использовать традиционную терминологию то индексов в глобалях нет, и более того в общем случае их быть не может. Глобаль и реляционная база это не изоморфные структуры. Любую реляционную таблицу можно представить в виде дерева, но не наоборот. Реляционная таблица это частный случай дерева с одинаковым количеством индексов и данными только на последнем уровне. А если есть данные на промежуточных уровнях, то для такого дерева никакие индексы не построишь. И требование наличия индексов для глобали некорректны.
Любую реляционную таблицу можно представить в виде дерева, но не наоборот.
Если не брать в расчет эффективность доступа, то все-таки любое дерево можно в таблицу завернуть. EAV в помощь. Только не подумайте, что это хорошо.
Если использовать традиционную терминологию то индексов в глобалях нет, и более того в общем случае их быть не может.
Что мы с некоторым успехом и доказали inetstar.
Собственно, это проблема сравнения нескольких различных технологий — когда даже терминология различается, сложно провести аккуратные терминологии.
Любую реляционную таблицу можно представить в виде дерева, но не наоборот.
Все-таки, нет. Под каждое дерево можно подобрать реляционную структуру для хранения.
когда даже терминология различается, сложно провести аккуратные терминологии.
Что-то я явно не проснулся еще. «когда даже терминология различается, сложно провести аккуратные аналогии».
Мне кажется вы преувеличиваете роль индексов в базах данных. Насколько я знаю NoSql базы не имеют индексов и прекрасно существуют. Это изобретение SQL баз и достаточно сомнительное. Индексация базы как любое дублирование порождает кучу плохо разрешимых проблем. Если индексировать первичную информацию, то никогда нельзя быть уверенным в достоверности индекса. Критические к достоверности данные индексировать фактически нельзя. Не критические требуют проверки индекса и его обслуживания. Использовать индексы на временных данных вообще бессмыслица. С таким же успехом можно построить необходимые глобали, что тоже мало полезно. Поэтому я не считаю индексацию базы великим преимуществом.
Насколько я знаю NoSql базы не имеют индексов и прекрасно существуют.
Вы знаете неправильно. Индексы в MongoDB, индексы в RavenDB.
Если индексировать первичную информацию, то никогда нельзя быть уверенным в достоверности индекса.
Ну так транзакции же.
Это изобретение SQL баз и достаточно сомнительное
Прекрасно. Предложите другой способ выбирать всех клиентов, живущих в Пенсильвании, без прямого перебора их записей.
Другого способа нет. В подобном случае пользуюсь прямым перебором.
Я так понимаю, что производительность вас в этом случае не волнует.
Мне кажется, что misha_shar53 ошибается. Как и любая другая NoSQL система, глобалы подразумевают, что данные организовываются с учётом последующих выборок. Т.е. естественно, что если есть необходимость «выбирать всех клиентов, живущих в Пенсильвании», будет как вариант, напрограммирован соответствующий индексный глобал, или в городах будет ссылка на его жителей, или будет индекс в глобале, или ещё как-то. Но и «полный перебор», в некоторых случаях может быть не так уж и затратен.
Тут как и с индексами в SQL системах, не все они одинаково полезны.
А что бы не допустить такого, есть и упомянутые вами транзакции и полезная вещь — блокировки lock.
Тут как и с индексами в SQL системах, не все они одинаково полезны.
Если индексировать первичную информацию, то никогда нельзя быть уверенным в достоверности индекса.
А что бы не допустить такого, есть и упомянутые вами транзакции и полезная вещь — блокировки lock.
Мне тоже кажется, что он ошибается, но поскольку я не работаю с глобалами, я не могу это ни доказать, ни опровергнуть.
## Если использовать традиционную терминологию то индексов в глобалях нет, и более того в общем случае их быть не может.
в мампсе и индекс есть и перебирают все — последовательно, каждая строка имеет индекс (глобал) у нее связка со следующей строкой этого глобала и того же уровня… нужна пенсильвания пиши:
^v[«USA»,«Пенсильвании»,«user_1»] = _
^v[«USA»,«Пенсильвании»,«user_2»] = _
^v[«USA»,«Пенсильвании»,«user_3»] = _
^v[«USA»,«Пенсильвании»,«user_4»] = _
My_Global = ^v[«USA»,«Пенсильвании»]
и фор цикл по глобалу My_Global
в мампсе и индекс есть и перебирают все — последовательно, каждая строка имеет индекс (глобал) у нее связка со следующей строкой этого глобала и того же уровня… нужна пенсильвания пиши:
^v[«USA»,«Пенсильвании»,«user_1»] = _
^v[«USA»,«Пенсильвании»,«user_2»] = _
^v[«USA»,«Пенсильвании»,«user_3»] = _
^v[«USA»,«Пенсильвании»,«user_4»] = _
My_Global = ^v[«USA»,«Пенсильвании»]
и фор цикл по глобалу My_Global
Безусловно волнует. Но из 2-х зол я всегда выбираю меньшее. А в моих случаях всегда корректность данных была важнее скорости. Но возможны варианты.
А в чем ваши проблемы с корректностью данных? В глобалах нет транзакционной целостности?
В глобалах есть транзакции. Теоретически все должно оставаться корректным. На практике это не так. Редко но бывает нарушение целостности данных, при этом это никак не проявляется внешне кроме как проверкой специальными утилитами или противоречий в выходных документах. А так как приложение работает у заказчика и нами постоянно не администрируется, обнаружиться нарушение целостности данных может поздно. Это проблема не только индексов, а любого дублирования первичных данных.
В глобалах есть транзакции. Теоретически все должно оставаться корректным. На практике это не так.
Я правильно вас понял: в глобалах есть транзакции, но они не гарантируют целостность данных?
Именно так. Транзакции есть, но они не всегда гарантируют корректность результатов. С подобной проблемой я сталкивался и в SQL базах при использовании индексов. Мир к сожалению не идеален и очень сложен. Сказать точно в какие моменты это происходит и почему я не могу, но с подобными явлениями я переодически сталкиваюсь.
Транзакции есть, но они не всегда гарантируют корректность результатов.
Просто… вау. Нет, серьезно. А inetstar так долго доказывал нам, что в глобалах есть «честные» ACID-транзакции…
С подобной проблемой я сталкивался и в SQL базах при использовании индексов.
Вы, конечно же, можете привести конкретный пример с указанием СУБД?
Конечно InterBase. А вы что верите сказкам, что такого не бывает в природе?
А вы что верите сказкам, что такого не бывает в природе?
Я верю своему опыту, который говорит, что при отсутствии аппаратных проблем СУБД, с которыми я работал (MS SQL в основном, немного Oracle и DB/2), никогда такого не допускали.
Каждый — каждый — раз, когда мы расследовали ошибку «у нас тут кривая транзакция», выяснялось, что ошибка в прикладном коде.
Ну значит у нас разный опыт. А насчет отсутствия аппаратных проблем ничего сказать не могу в обоих случаях они могли иметь место. Что происходит у заказчика мы постоянно не контролировали. Возможно после выключения питания при повторном пуске шло какое то восстановление из журналов. Может еще что. Обычная дворцовая жизнь. Но системы в обоих случаях продолжали работать и ничего криминального не сообщали.
Но системы в обоих случаях продолжали работать и ничего криминального не сообщали.
Значит, система не предоставляет гарантий по консистентности/персистентности. Не надо с такими работать безотносительно того, есть там индексы, или нет.
(конечно, если вам важна консистентность данных, а не то, что вы систему в качестве кэша используете)
Конечно не предоставляет. Но других систем у рядовых заказчиков нет. Обычные китайские компы. А вы наверно обитаете в стране чудес? Мне бы к вам. Тогда и буду использовать индексы и зависимые глобали. А пока приходится как то выкручиваться. Так и живем.
Но других систем у рядовых заказчиков нет.
Ну не знаю, мы как-то находили.
Понимаете ли, в чем дело, если ваша система не предоставляет гарантий по консистентности/персистентности данных, то не важно, используете вы дополнительные данные или нет. Во-первых, рано или поздно вы получите нарушение консистентности на двух взаимосвязанных операциях (приход и расход в двойной записи). Во-вторых, рано или поздно вы получите нарушение персистентности внутри одной операции (т.е., вы сказали системе записать такое-то значение, она отрапортовала, что записала, вы, исходя из этого, действуете дальше, но в реальности записано другое значение (или не записано ничего вообще).
Если вы работаете, как вы выражаетесь, с «критическими» данными, для них такие системы использовать просто нельзя.
В идеальном мире свет в городе не отключают. УПС держит скачки напряжений, а базы корректно восстанавливаются из журналов. Увы у меня все не так. В городе и особенно в области отключение света банальная ситуация да и стабильного напряжения никто не гарантирует. Хочешь работай, не хочешь не работай.
Вот «базы корректно восстанавливаются из журналов» — это как раз зависит от того, как СУБД спроектирована.
А на отключение света и скачки напряжения нормальной персистентной БД пофиг, уже обсуждали это. Любая проведенная транзакция должна быть зафиксирована в персистентном хранилище. Если ваша СУБД так не делает — значит, либо она не дает гарантий персистентности (а зачем вы ее тогда используете для «критических данных»), либо вы не умеете ее готовить, либо в ней критический баг (и тогда тоже лучше не иметь с ней дела).
А на отключение света и скачки напряжения нормальной персистентной БД пофиг, уже обсуждали это. Любая проведенная транзакция должна быть зафиксирована в персистентном хранилище. Если ваша СУБД так не делает — значит, либо она не дает гарантий персистентности (а зачем вы ее тогда используете для «критических данных»), либо вы не умеете ее готовить, либо в ней критический баг (и тогда тоже лучше не иметь с ней дела).
А на отключение света и скачки напряжения нормальной персистентной БД пофиг, уже обсуждали это.
В ходе обсуждения вы побоялись отключать питание у своего компа во время работы БД (1, 2).
Далее вы не привели никаких исследований и тестов, доказывающих что пофиг базам отключение питания.
Так что заканчивайте с фантазиями. Моё утверждение, что пофиг только в теории.
Дайте ссылки на тесты применительно к любимому вами MS SQL, что «А на отключение света и скачки напряжения нормальной персистентной БД пофиг»
Чайник Рассела. Нет, спасибо.
Чайник Рассела — это про религиозные утверждения. Мимо кассы. Мы же говорим о практике и реальной жизни.
Тем более в отличае от микроскопического чайника между Землёй и Марсом, необнаружимого в телескопы, выдергнуть шнур из розетки — это очень повторимый и элементарный опыт.
Тем более в отличае от микроскопического чайника между Землёй и Марсом, необнаружимого в телескопы, выдергнуть шнур из розетки — это очень повторимый и элементарный опыт.
Чайник Рассела — он про то, что доказать отсутствие чего-то невозможно. Как уже неоднократно говорилось, тот факт, что после выдергивания шнура из розетки с компьютером ничего не произошло, никак не доказывает, что с ним ничего не может произойти.
Лично ваш опыт говорит, что одного такого эксперимента может оказаться достаточно для разрушения винды или ФС, поэтому вы и не хотите его проводить. Зачем вы отрицаете свой опыт?
Мне даже не нужно 100% доказательство, которое действительно невозможно.
Меня устроит тестирование, в котором статистически значимое число раз выдёргивался шнур питания во время работы MS SQL и консистентность подтверждалась c доверительным интервалом 99,99%.
Мне даже не нужно 100% доказательство, которое действительно невозможно.
Меня устроит тестирование, в котором статистически значимое число раз выдёргивался шнур питания во время работы MS SQL и консистентность подтверждалась c доверительным интервалом 99,99%.
Лично ваш опыт говорит, что одного такого эксперимента может оказаться достаточно для разрушения винды или ФС, поэтому вы и не хотите его проводить. Зачем вы отрицаете свой опыт?
Затем, что отдаю себе отчет, что разрушение винды или файловой системы не имеет отношения к разрушению данных MS SQL.
Меня устроит тестирование, в котором статистически значимое число раз выдёргивался шнур питания во время работы MS SQL и консистентность подтверждалась c доверительным интервалом 99,99%.
Проводите его самостоятельно или запрашивайте результаты такого тестирования у MS. Мой личный (а тем более — рабочий) компьютер — не полигон для ваших статистических испытаний.
MS SQL, с которым я в той или иной мере работаю
Для правильных тестов нужно отключать питание именно во время массовых транзакций. Понятно, что если он не пишет во время сбоя питания, то может обойтись. Ну и вы, явно, не конечный заказчик, у которого базы под постоянной нагрузкой.
Проводите его самостоятельно
Это вы утверждаете что MS SQL, как «любой нормальной персистентной базе пофиг сбои питания», а не я.
Поэтому приведите результаты тестирований персистентности MS SQL при отключениях питания.
Ну и вы, явно, не конечный заказчик, у которого базы под постоянной нагрузкой.
У конечного заказчика и система — не десктопный компьютер без ИБП.
Это вы утверждаете что MS SQL, как «любой нормальной персистентной базе пофиг сбои питания», а не я. Поэтому приведите результаты тестирований персистентности MS SQL при отключениях питания.
Не, извините, не буду. Мне достаточно моего опыта и заявлений MS (можно в обратном порядке). Вам недостаточно? Окей, можете считать, что в MS SQL нет durable транзакций.
С интересом послушаю, а где же они есть.
Да, о моем опыте. На моем рабочем компьютере последние лет восемь стоит MS SQL, с которым я в той или иной мере работаю. А еще на этом компьютере никогда нет бесперебойника, так что power cycle с ним за эти годы случался далеко не единожды без какой-либо моей помощи.
Так вот, за все это время я ни разу не столкнулся с повреждением баз MS SQL, зато как минимум единожды видел умерший SSD.
Так вот, за все это время я ни разу не столкнулся с повреждением баз MS SQL, зато как минимум единожды видел умерший SSD.
А можно подробнее?
Это ссылочная целостность? Или физическая целостность данных?
Ошибка приходит из транзакции?
Можно примеры с глобалами?
Это ссылочная целостность? Или физическая целостность данных?
Ошибка приходит из транзакции?
Можно примеры с глобалами?
А можете развёрнуто с примерами пояснить?
Что пояснить? Что индекс в SQL базе может стать некорректным? Что дополнительная глобаль с индексацией может перестать соответствовать первичной глобали?
Что индекс в SQL базе может стать некорректным?
Ну SQL меня тут не интересут. Мне интересно про глобалы.
Что дополнительная глобаль с индексацией может перестать соответствовать первичной глобали?
Да, мне интересно как это может произойти.
Мне тоже.
Да, мне интересно как это может произойти.
Это может произойти, когда, например,
- вставка в индексный глобал не объединена транзакцией с вставкой в основной глобал.
- обновление индексированного поля не ведёт к удалению элемента из индексного глобала и к вставке нового значения в индексный глобал (всё это тоже д.б. в одной транзакции)
- делает удаление из основного глобала, а из индексного глобала забывается удалить. И/или это тоже сделано без транзакции
- когда выполняются 2 операции обновления над одними и теми же данными, в некоторых СУБД на глобалах нужна локировка. Её, в принципе, лучше всегда использовать, так как она работает быстрее и понятнее, чем механизм обеспечивающий корректность при параллельных транзакциях.
Вы перечислили варианты, когда ошибка у программиста. А misha_shar53 убеждает что в коде все правильно.
А в инструкции к gt.m вроде было написано, что лучше lock не использовать, а правильно применять транзакции.
Её, в принципе, лучше всегда использовать, так как она работает быстрее и понятнее, чем механизм обеспечивающий корректность при параллельных транзакциях.
А в инструкции к gt.m вроде было написано, что лучше lock не использовать, а правильно применять транзакции.
А misha_shar53 убеждает что в коде все правильно.
Как можно это гарантировать? Практика говорит, что ошибки, которые на исправляются по 15 лет, есть даже в notepad.
А в инструкции к gt.m вроде было написано, что лучше lock не использовать, а правильно применять транзакции.
Согласен. Вы наверное имелии ввиду LOCK vs TSTART.
Я говорю о TSTART vs LOCK+TSTART
Однако транзакции в GT.M работают очень хитро. При коммите измененённых данных в параллельном потоке транзакции в других потоках автоматически перезапускаются. Это делается до 4-х раз.
И если в транзакциях используются операции ввода-вывода, неоткатываемая работа с локальными переменными — будет ошибка.
Иными словами, если программист досконально не понимает как работают транзакции в GT.M, то лучше ему использовать LOCK в сочетании с TSTART.
На прикладном уровне в CACHE есть средство называемое Куб. Там на специфических деревьях строится индексация по всем ключам. Но это конечно частный случай.
Вводных статей про глобалы было уже несколько.
Эту выделяют отличные рисунки. Тот, на котором изображено дерево из одних груш, — мастерский, как раз из-за аналогии.
Эту выделяют отличные рисунки. Тот, на котором изображено дерево из одних груш, — мастерский, как раз из-за аналогии.
В 1987-90 годах я работал и преподавал систему ДИАМС, построенную на глобалах.
Я досконально изучал структуру физических блоков хранения глобал на диске.
Вся фишка огромной скорости выборки и записи на диск заключается в чтении или изменении и записи отдельных 512 байтовых блоков. ЛЮБАЯ информация по индексам из базы десятки гигабайт извлекается чтением максимум пяти фрагментов с диска. При записи происходит отложенная запись на диск ТОЛЬКО изменённых блоков.
Есть блоки разной иерархии. В них есть ссылки на линейные блоки или на следующий уровень, если база большая. Корневой блок глобалы может ссылаться на вторичные, те на третий уровень и т.д. до 5. Индексы и значения лежат линейно в блоке в текстовом виде, но они отсортированы. Если не хватает места для данных в одном блоке, берётся другой свободный и в нём прописывается тот, который был следующим. При интенсивной вставке/удалении данных база становится рыхлой. Блоки могут быть полупустыми, но есть специальные механизмы, которые дефрагментируют базу во время простоя или по заданию. При приведённом выше тестовом задании все операции произошли в буфере в ОЗУ и один раз записались на диск, поэтому такая скорость. Если бы индексы формировались случайные, скорость была бы ниже, но незначительно.
Я досконально изучал структуру физических блоков хранения глобал на диске.
Вся фишка огромной скорости выборки и записи на диск заключается в чтении или изменении и записи отдельных 512 байтовых блоков. ЛЮБАЯ информация по индексам из базы десятки гигабайт извлекается чтением максимум пяти фрагментов с диска. При записи происходит отложенная запись на диск ТОЛЬКО изменённых блоков.
Есть блоки разной иерархии. В них есть ссылки на линейные блоки или на следующий уровень, если база большая. Корневой блок глобалы может ссылаться на вторичные, те на третий уровень и т.д. до 5. Индексы и значения лежат линейно в блоке в текстовом виде, но они отсортированы. Если не хватает места для данных в одном блоке, берётся другой свободный и в нём прописывается тот, который был следующим. При интенсивной вставке/удалении данных база становится рыхлой. Блоки могут быть полупустыми, но есть специальные механизмы, которые дефрагментируют базу во время простоя или по заданию. При приведённом выше тестовом задании все операции произошли в буфере в ОЗУ и один раз записались на диск, поэтому такая скорость. Если бы индексы формировались случайные, скорость была бы ниже, но незначительно.
Вся фишка огромной скорости выборки и записи на диск заключается в чтении или изменении и записи отдельных 512 байтовых блоков.
Почти все более-менее развитые СУБД работают с блоками. Правда, сейчас, они, как правило, большего размера.
ЛЮБАЯ информация по индексам из базы десятки гигабайт извлекается чтением максимум пяти фрагментов с диска.
Имеется ввиду доступ к одному значению? Если требуется много информации, то непонятно как она помещается в пять фрагментов. Это совершенно обычная ситуация для сбалансированных древовидных структур: даже очень большое дерево обладает небольшой глубиной (логарифмическая зависимость). И это есть практически в любой СУБД.
При записи происходит отложенная запись на диск ТОЛЬКО изменённых блоков.
Это тоже совершенно обычный механизм для СУБД.
Есть блоки разной иерархии. В них есть ссылки на линейные блоки или на следующий уровень, если база большая. Корневой блок глобалы может ссылаться на вторичные, те на третий уровень и т.д. до 5.
Вот про это можно было бы по-подробнее.
Индексы и значения лежат линейно в блоке в текстовом виде, но они отсортированы. Если не хватает места для данных в одном блоке, берётся другой свободный и в нём прописывается тот, который был следующим. При интенсивной вставке/удалении данных база становится рыхлой. Блоки могут быть полупустыми, но есть специальные механизмы, которые дефрагментируют базу во время простоя или по заданию. При приведённом выше тестовом задании все операции произошли в буфере в ОЗУ и один раз записались на диск, поэтому такая скорость. Если бы индексы формировались случайные, скорость была бы ниже, но незначительно.
Это тоже всё стандартные приёмы в реализации СУБД на сегодняший день.
Для 1987-90 годов, может быть, это всё было круто и инновационно. Но сейчас эти методы применяются повсеместно. Поэтому когда нам говорят о небывалой производительности, то хочется понять, а в чём собственно дело?
Несколько причин:
- SQL — интерпретируемый язык, COS/M компилируемый.
- В реляционных БД минимальный блок — это одна строка. Даже если меняется одно значение, то по концепции MVCC делается копия всей строки, а в глобале только одного блока, где значение узла.
- SQL как правило работает через сокеты, а базы на глобалах предпочитают работать из пространства процесса. (Через сокеты тоже, конечно, могут)
- Преимущества долгого развития
- Ассемблерные оптимизации
- Очень грамотное использование буферов и кеширования
SQL — интерпретируемый язык, COS/M компилируемый.
Это далеко не всегда так. Почему SQL – интерпретируемый? Для него есть различные реализации. Да и потом вы заявляете о преимуществах над NoSQL базами тоже.
В реляционных БД минимальный блок — это одна строка. Даже если меняется одно значение, то по концепции MVCC делается копия всей строки, а в глобале только одного блока, где значение узла. Опять же, не сбрасываем со счетов NoSQL базы.
В разных база сделано по-разному. Есть реляционные базы с MVCC и без MVCC. В зависимости от способа реализации, запись в таблицу тоже может быть обновлением только одного блока.
SQL как правило работает через сокеты, а базы на глобалах предпочитают работать из пространства процесса. (Через сокеты тоже, конечно, могут)
Хранимые процедуры, в том числе и компилируемые, есть в большинстве СУБД.
Преимущества долгого развития
Это далеко не всегда преимущества.
Ассемблерные оптимизации
Про них уже написали. При современных процессорах и компиляторах, они далеко не всегда уместны. Особенно те, которые появились в результате долгого развития.
Очень грамотное использование буферов и кеширования
Не понятно, что такое «очень грамотное». В этой области есть много исследований, но они, как правило, касаются того как и когда делать eviction. Когда вся база помещается в буфера, то не понятно, о чём речь.
Я предлагаю вам повторить самостоятельно какие-то из моих или тестов Роба Твида, поскольку только так вы можете сами убедиться.
Очевидно, что вы like Фома Неверующий, который может с чем-то согласиться только проведя самостоятельные тесты. Поэтому спор бесполезен. Буду рад почитать вашу статью с результатами тестирования.
Напишите хранимку для инсерта случайных данных на SQL и на COS/M. И сравните скорость. Я делал сравнение с MySQL и для хранимок, и для интерпретаторного режима. В обоих случая глобалы были быстрее, как минимум, на порядок. Вот результаты одного из моих тестов. В нём я тестировал интерпретаторный режим GT.M (без компиляции) и MySql (без хранимок).
Теоретически компилятор может написать код лучше человека, а долгая работа над кодом талантливых программистов не приводить к его улучшению, а в программах можно использовать только хранимые процедуры, отказавшись от SQL. Но на практике это бывает редко.
Когда база помещается в буфера — это только когда делается сравнительное тестирование с in-memory БД, которые не могут работать с базами большего объёма.
Я многократно использовал в тестах 100-300M вставок, которые НЕ помещаются ни в какие буфера и винты хрустят как бешеные. И при этом получал всё равно сотни тысяч инсертов в секунду.
Очевидно, что вы like Фома Неверующий, который может с чем-то согласиться только проведя самостоятельные тесты. Поэтому спор бесполезен. Буду рад почитать вашу статью с результатами тестирования.
Напишите хранимку для инсерта случайных данных на SQL и на COS/M. И сравните скорость. Я делал сравнение с MySQL и для хранимок, и для интерпретаторного режима. В обоих случая глобалы были быстрее, как минимум, на порядок. Вот результаты одного из моих тестов. В нём я тестировал интерпретаторный режим GT.M (без компиляции) и MySql (без хранимок).
Теоретически компилятор может написать код лучше человека, а долгая работа над кодом талантливых программистов не приводить к его улучшению, а в программах можно использовать только хранимые процедуры, отказавшись от SQL. Но на практике это бывает редко.
Когда база помещается в буфера — это только когда делается сравнительное тестирование с in-memory БД, которые не могут работать с базами большего объёма.
Я многократно использовал в тестах 100-300M вставок, которые НЕ помещаются ни в какие буфера и винты хрустят как бешеные. И при этом получал всё равно сотни тысяч инсертов в секунду.
Очевидно, что вы like Фома Неверующий, который может с чем-то согласиться только проведя самостоятельные тесты. Поэтому спор бесполезен. Буду рад почитать вашу статью с результатами тестирования.
Понимаете, тут не религия, а наука, принято полагаться не на веру, а на анализ. Поэтому речь не о том, верю я результатам тестирования или нет. Речь о том, можете ли вы предоставить этим тестам убедительное объяснение. А предоставить вы его не можете.
Фома Неверующий — наименее верующий из всех апостолов. По легендам он лично проверял раны Христа, не поверив другим.
Если продолжать аналогию с Фомой, то если бы вы были на месте Фомы, то сказали бы: нет, Иисус, руки в раны вкладывать не стану. Я поверю только тогда, когда ты мне объяснишь Теорию воскресения, сотворения мира и Триединства)))
Вот вы можете мне доказать, что ассемблерные ручные оптимизации ВСЕГДА хуже по быстродействию, чем код который создают компиляторы? Нет?
Тогда факт, что более 50% кода написано на ассемблере достаточен.
А доказать, что долгая работа над кодом ВСЕГДА не приводит к улучшению продукта? Тоже нет?
Значит объяснение я вам предоставил.
Ваша аргументы откровенно слабы: в каких-то случаях компилятор так же хорош как человек, в каких-то случаях долгое развитие фигня. Где-то иногда можно не использовать интерпретатор SQL, а написать много хранимок, которые в некоторых БД окажутся хорошо откомпилированными, а не тупо сохранёнными как текст.
Для того, чтобы быть уверенным, что кирпич падает с такой же скоростью как гиря, необязательно знать квантовую механику и теорию гравитации. Достаточно провести тесты.
Нужно более глубокое и детализированное знание — спросите у разработчиков. Или почитайте исходные коды. Благо они есть. Напишите статью с выводами. Все вам будут благодарны.
Если продолжать аналогию с Фомой, то если бы вы были на месте Фомы, то сказали бы: нет, Иисус, руки в раны вкладывать не стану. Я поверю только тогда, когда ты мне объяснишь Теорию воскресения, сотворения мира и Триединства)))
Вот вы можете мне доказать, что ассемблерные ручные оптимизации ВСЕГДА хуже по быстродействию, чем код который создают компиляторы? Нет?
Тогда факт, что более 50% кода написано на ассемблере достаточен.
А доказать, что долгая работа над кодом ВСЕГДА не приводит к улучшению продукта? Тоже нет?
Значит объяснение я вам предоставил.
Ваша аргументы откровенно слабы: в каких-то случаях компилятор так же хорош как человек, в каких-то случаях долгое развитие фигня. Где-то иногда можно не использовать интерпретатор SQL, а написать много хранимок, которые в некоторых БД окажутся хорошо откомпилированными, а не тупо сохранёнными как текст.
Для того, чтобы быть уверенным, что кирпич падает с такой же скоростью как гиря, необязательно знать квантовую механику и теорию гравитации. Достаточно провести тесты.
Нужно более глубокое и детализированное знание — спросите у разработчиков. Или почитайте исходные коды. Благо они есть. Напишите статью с выводами. Все вам будут благодарны.
Вот вы можете мне доказать, что ассемблерные ручные оптимизации ВСЕГДА хуже по быстродействию, чем код который создают компиляторы? Нет? Тогда факт, что более 50% кода написано на ассемблере достаточен.
Я не очень понимаю, какое логическое построение привело вас к этому выводу.
Тот факт, что вы не засчитали мой аргумент об ассемблере, сославшись на коммент, где говорится что иногда компиляторы создают машинный код не хуже человека.
(ну вы бы хоть следили, с кем вы общаетесь)
Факт не может быть логическим построением. Факт может быть основанием для логического построения.
Так что мой вопрос остается актуальным.
Факт не может быть логическим построением. Факт может быть основанием для логического построения.
Так что мой вопрос остается актуальным.
Про свои построения можете сами рассказать. Я вижу, что вы не приняли аргумент про ассемблер. Это и есть факт.
А раз вы его не приняли, тогда докажите мне, что ассемблерные оптимизации вовсе не дают никогда выигрышей.
А раз вы его не приняли, тогда докажите мне, что ассемблерные оптимизации вовсе не дают никогда выигрышей.
Я вижу, что вы не приняли аргумент про ассемблер.
… а где вы это видите?
А раз вы его не приняли, тогда докажите мне, что ассемблерные оптимизации вовсе не дают никогда выигрышей.
Бремя доказательства лежит на утверждающем. Это вы утверждаете, что глобалы быстрее потому, что применен ассемблер. Известен факт (надеюсь, что вы не будете его оспаривать), что не всякое применение ассемблера ускоряет приложение. Как следствие, на основании чего вы утверждаете, что в данном случае применение ассемблера приложение ускорило?
То что глобалы быстрее, я уже доказал тестами.
Вы принимаете факт быстроты глобалов? Да или нет.
Вы принимаете факт быстроты глобалов? Да или нет.
«Быстрота» — понятее относительное само по себе. На данный момент я готов признать, что есть тесты, которые показывают, что в определенных условиях конкретная реализация глобалов выдает больше абстрактных операций, чем некоторые другие хранилища.
Прекрасно. Поскольку я не разработчик баз на глобалах, то я ответил в меру своего понимания о том, что помогло получить такие результаты.
Для кого-то это уже полезная информация. Поскольку я хотя бы бегло уже смотрел исходный код и потратил приличное время на изучение экокультуры глобалов.
Доказательство каждого конкретного пункта из этого списка не входит в мои планы.
Это то, как я сам для себя объясняю полученные результаты.
Информация о существовании протестированной технологии с высоким потенциалом — уже ценная вещь.
Для кого-то это уже полезная информация. Поскольку я хотя бы бегло уже смотрел исходный код и потратил приличное время на изучение экокультуры глобалов.
Доказательство каждого конкретного пункта из этого списка не входит в мои планы.
Это то, как я сам для себя объясняю полученные результаты.
Информация о существовании протестированной технологии с высоким потенциалом — уже ценная вещь.
Информация о существовании протестированной технологии с высоким потенциалом — уже ценная вещь.
Ценно было бы, если бы эта информация была непротиворечивой, бесспорной и подтвержденной конкретными фактами.
Где я сам себе противоречил?
Требование бесспорности — это максимализм и субъективизм, есть люди которые всегда спорят. Я лично считаю, что наиболее ценна спорная информация, так как она может дать фору (пока остальные тормозят) и привести к взрывному прогрессу.
Факты я предоставил. Конкретные и с цифрами.
Требование бесспорности — это максимализм и субъективизм, есть люди которые всегда спорят. Я лично считаю, что наиболее ценна спорная информация, так как она может дать фору (пока остальные тормозят) и привести к взрывному прогрессу.
Факты я предоставил. Конкретные и с цифрами.
Факты я предоставил. Конкретные и с цифрами.
Например, в части индексов и сортировок. Или в части транзакций.
Я даже сделал тесты на скорость именно транзакций и выложил их прямо в комменты.
Поиск по слову «TSTART» на странице.
Насчёт индексов и сортировок я выкладывал ссылки на внутреннее устройство баз, на детали технической реализации.
Какие факты вам нужны насчёт индексов и сортировок?
Поиск по слову «TSTART» на странице.
Насчёт индексов и сортировок я выкладывал ссылки на внутреннее устройство баз, на детали технической реализации.
Какие факты вам нужны насчёт индексов и сортировок?
Я даже сделал тесты на скорость именно транзакций и выложил их прямо в комменты.
Дело не в тестах на скорость транзакций, а в том, какие транзакционные гарантии дают глобалы (кстати, формально, вообще никаких — гарантии дает реализация, а не структура данных).
Какие факты вам нужны насчёт индексов и сортировок?
Ну например, мы выяснили, что в терминах традиционных БД глобалы не индексированы.
Я думаю, что если бы изначально я написал, что данные в глобале проиндексированы (т.е. обеспечивают быстрый доступ) по всем ветвям, то это бы вас устроило.
Вас смутила фраза про индексированное хранилище. У глобалов я должен вручную строить индексы, а в реляционных БД это происходит автоматически.
Небольшая разница в смысле, которая накладывает на разработчика систем на глобалах несколько больше работы.
Я всё правильно понял?
Вас смутила фраза про индексированное хранилище. У глобалов я должен вручную строить индексы, а в реляционных БД это происходит автоматически.
Небольшая разница в смысле, которая накладывает на разработчика систем на глобалах несколько больше работы.
Я всё правильно понял?
Я думаю, что если бы изначально я написал, что данные в глобале проиндексированы (т.е. обеспечивают быстрый доступ) по всем ветвям, то это бы вас устроило.
Нет, это фраза избыточна, потому что она вытекает из свойств дерева, на котором (по вашему утверждению) построен глобал. Мы же не говорим, что хэш-таблица проиндексирована?
У глобалов я должен вручную строить индексы, а в реляционных БД это происходит автоматически.
У глобалов просто нет такой вещи, как «индексы» в понимании реляционных БД. То, что вы строите — это дополнительный глобал.
Поэтому, собственно, я и указываю, что — до тех пор, пока вы ведете сравнение с «традиционными» БД — говорить, что глобалы дают индексированное хранилище, терминологически некорректно.
Дело в том, что дерево глобала, которое я рисую оно не совпадает с внутренним B-tree. Логически из одного узла может выходить 1000 ветвей, но внутри только 2 и гораздо больше уровней.
Если считать дерево на рисунках отображающем реальную логику работы глобала, то получается, что мы будем искать одну ветвь из 1000 перебором, что неверно.
Ваше мнение: как следовало сказать правильно?
Если считать дерево на рисунках отображающем реальную логику работы глобала, то получается, что мы будем искать одну ветвь из 1000 перебором, что неверно.
Ваше мнение: как следовало сказать правильно?
Я вижу, что вы не приняли аргумент про ассемблер.
… а где вы это видите?
Преимущества долгого развития
Это далеко не всегда преимущества.
Ассемблерные оптимизации
Про них уже написали. При современных процессорах и компиляторах, они далеко не всегда уместны. Особенно те, которые появились в результате долгого развития.
То что у кого-то ассемблерные оптимизации не работают и долгое развитие не развивает — это не доказательство того, что в глобалах это бесполезно.
Простите, вы сейчас с кем разговаривали и что пытались озвучить?
Но верно и обратное: нет доказательств того, что «быстрота» глобалов проистекает из ассемблерной оптимизации и долгого развития, а не, скажем, из удачно выбранного алгоритма.
То что у кого-то ассемблерные оптимизации не работают и долгое развитие не развивает — это не доказательство того, что в глобалах это бесполезно.
Но верно и обратное: нет доказательств того, что «быстрота» глобалов проистекает из ассемблерной оптимизации и долгого развития, а не, скажем, из удачно выбранного алгоритма.
Фома Неверующий — наименее верующий из всех апостолов. По легендам он лично проверял раны Христа, не поверив другим.
Вы действительно считаете все эти аналогии уместными? Может быть я говорю с апостолом от InterSystems?
Вот вы можете мне доказать, что ассемблерные ручные оптимизации ВСЕГДА хуже по быстродействию, чем код который создают компиляторы? Нет?
Тогда факт, что более 50% кода написано на ассемблере достаточен.
А доказать, что долгая работа над кодом ВСЕГДА не приводит к улучшению продукта? Тоже нет?
Значит объяснение я вам предоставил.
Ваша аргументы откровенно слабы: в каких-то случаях компилятор так же хорош как человек, в каких-то случаях долгое развитие фигня. Где-то иногда можно не использовать интерпретатор SQL, а написать много хранимок, которые в некоторых БД окажутся хорошо откомпилированными, а не тупо сохранёнными как текст.
Напротив, это ваша аргументация в течении всего обсуждения не отличалась силой. Ассемблерные оптимизации – это, пожалуй, единственное что осталось от всей вашей многословной аргументации. В остальном же вы перечисляли стандартные подходы, повсеместно применяющиеся в большинстве других СУБД. И я не говорил, что ассемблерные оптимизации – фигня. Но если вы объясняете ими разницу на порядок – это вызывает совершенно законные вопросы.
Для того, чтобы быть уверенным, что кирпич падает с такой же скоростью как гиря, необязательно знать квантовую механику и теорию гравитации. Достаточно провести тесты.
На мой взгляд, не самая удачная аналогия. В случае с кирпичом и гирей – мы ставим простой эксперимент, чтобы установить простой закон. А в случае с СУБД – каждый продукт индивидуален. Чтобы сравнить две СУБД в условиях, близких в равным, нужны глубокие знания в каждой из СУБД. А чтобы результаты правильно интерпретировать – тем более. Именно поэтому интернет кишит безграмотными сравнениями: у проводящего тесты есть достаточные знания в лучшем случае только по одной из сравниваемых СУБД.
Нужно более глубокое и детализированное знание — спросите у разработчиков. Или почитайте исходные коды. Благо они есть. Напишите статью с выводами. Все вам будут благодарны.
Пожалуй, в данной ситуации, это единственное, что остаётся.
Вы действительно считаете все эти аналогии уместными? Может быть я говорю с апостолом от InterSystems?
Аналогия абсолютна уместна, так как вы не желаете проводить собственные эксперименты и не признаёте ссылки на проведённые. Для вас критерий истинности — это не практика, а чтобы вам теоретически нечто доказали. Что может быть принципиально невозможным, так как явно у вас есть какой-то негатив, связанный с этой технологией.
И в конце статьи жирным шрифтом есть Disclaimer. Почитайте и узнаете являюсь ли я «апостолом».
Но если вы объясняете ими разницу на порядок – это вызывает совершенно законные вопросы.
На Хабре полно статей, когда программу переписывали на Си или ассемблере и получали выигрыш на несколько порядков.. Читайте, просвещайтесь.
Это очень удобная позиция — не принимать чужие аргументы. Вот вы не принимаете аргумент долгого развития, а я в качестве примера приведу вам, что php 1.0 в десятки тысяч раз медленнее современной реализации. Php 4.0 медленнее php 5.0 в разы. А базы на глобалах это, образно говоря, технология 90.0.
Докажите мне, что долгое развитие ничего не даёт, а потом говорите это этот аргумент ничтожен.
Аналогия абсолютна уместна, так как вы не желаете проводить собственные эксперименты и не признаёте ссылки на проведённые.
Я не говорил, что я их не признаю. Много вопросов есть к их интерпретации.
Для вас критерий истинности — это не практика, а чтобы вам теоретически нечто доказали.
Дело в том, что в данном случае вся практика свелась к очень примитивным бенчмаркам, которые никак не могут претендавать на полноценное практическое исследование. Поэтому вопрос правильной интерпретации не менее важен чем сами бенчмарки.
Что может быть принципиально невозможным, так как явно у вас есть какой-то негатив, связанный с этой технологией.
Негатива к глобалам у меня нет. Проблема в том, что это N+1 статья, рассказывающая о том, как круты глобалы. И как всегда не написано ничего толкового о том, почему они же круты.
На Хабре полно статей, когда программу переписывали на Си или ассемблере и получали выигрыш на несколько порядков..
Когда переписывали на Си или ассемблере с интерпретируемого языка – да. Но вот, чтобы переписать с Си на ассемблер и получить выигрыш на порядок – это скорее исключение, чем правило. Поэтому я не понимаю, какое отношение это имеет к дискуссии.
Читайте, просвещайтесь.
А просвещаться нужно в первую очередь вам. Вы написали рекламную статью про глобалы, но при этом слабо ориентируетесь в современных технологиях СУБД, что продемонстрировали в ходе дискуссии.
Это очень удобная позиция — не принимать чужие аргументы. Вот вы не принимаете аргумент долгого развития, а я в качестве примера приведу вам, что php 1.0 в десятки тысяч раз медленнее современной реализации. Php 4.0 медленнее php 5.0 в разы. А базы на глобалах это, образно говоря, технология 90.0.
php 5.0 быстрее php 4.0 не потому что у него номер версии такой, а потому что в нём были проделаны вполне конкретные оптимизации, которые этот выигрыш дали. Причём перечисление этих оптимизаций можно найти в release notes. А также можно найти статьи, описывающие эти оптимизации. А приводить аргументы долгого развития и оптимизаций на ассемблере – это просто такая ширма, чтобы прикрыть собственное незнание.
Поэтому я не понимаю, какое отношение это имеет к дискуссии.
Такое что современные БД почти не пишут на Си. В лучшем случае C++, а в некоторых вообще Erlang (CouchDB например).
А раз вы этого не знаете, то я делаю вывод, что слабые знания современных СУБД именно у вас.
Итак, вы утверждаете, что невозможно получить выигрыш на порядок переписав программу с C++ на ассемблере?
А приводить аргументы долгого развития и оптимизаций на ассемблере – это просто такая ширма, чтобы прикрыть собственное незнание.
Это то, что можно сказать 10 словами вместо 100 000 строк release notes за последние 40 лет.
> Такое что современные БД почти не пишут на Си. В лучшем случае C++
Простите, но вот это уже откровенная ложь или подтасовка. Либо расскройте ваше понимание «современные БД».
Простите, но вот это уже откровенная ложь или подтасовка. Либо расскройте ваше понимание «современные БД».
Современные — это значит существующие в настоящее время и активно развивающиеся.
Вы влезли в дискуссию, не заметив фразу smagen
А отношение такое, что многие современные БД написаны на интерпретируемых языках. При чём если язык, компилируется в байт-код, то он всё равно интерпретируемый (википедия). Таких баз много. Я сразу привёл наиболее яркий пример — CouchDB. Баз на Java огромное количество.
То что smagen не понял как это относится к дискуссии означает, что он этого не знал.
Современная БД — существующая в настоящее время и активно развивающаяся.
Вы влезли в дискуссию, не заметив фразу smagen
Когда переписывали на Си или ассемблере с интерпретируемого языка – да.
…
Поэтому я не понимаю, какое отношение это имеет к дискуссии.
А отношение такое, что многие современные БД написаны на интерпретируемых языках. При чём если язык, компилируется в байт-код, то он всё равно интерпретируемый (википедия). Таких баз много. Я сразу привёл наиболее яркий пример — CouchDB. Баз на Java огромное количество.
То что smagen не понял как это относится к дискуссии означает, что он этого не знал.
Современная БД — существующая в настоящее время и активно развивающаяся.
Таких баз много.
Список баз, написанных на интерпретируемом языке, пусть даже компилирующего типа напишите. В особенности те которые делают ставку на максимальную производительность. Если вы говорите Много значит должны знать хотя бы десяток.
А это уже ваша придумка и незаконное требование — «в особенности те, которые делают ставку на максимальную производительность»
Речь шла просто о современных БД.
Список (жирным отмечены базы, которые рассчитаны на высокую производительность):
Apache Cassandra — java
HBase — java
CouchDB — java
Neo4j — java
CouchDB — erlang
Mnesia — erlang
Riak — erlang
Voldemort — java
Terrastore — java
OrientDB — java. «It's written in Java and it's amazing fast»
InfoGrid — java. Явного указания на суперскорость нет, но позиционируются для обслуживания веб графов (соц. сети, например)
Производительности такие базы достигают в первую очередь за счёт использования кластеров и шардинга, а не за счёт безумной производительности самого кода.
Однако сам автор CouchDB собирается переписать её на C++, но сообщество CouchDB с ним не согласно.
Речь шла просто о современных БД.
Список (жирным отмечены базы, которые рассчитаны на высокую производительность):
Apache Cassandra — java
HBase — java
CouchDB — java
Neo4j — java
CouchDB — erlang
Mnesia — erlang
Riak — erlang
Voldemort — java
Terrastore — java
OrientDB — java. «It's written in Java and it's amazing fast»
InfoGrid — java. Явного указания на суперскорость нет, но позиционируются для обслуживания веб графов (соц. сети, например)
Производительности такие базы достигают в первую очередь за счёт использования кластеров и шардинга, а не за счёт безумной производительности самого кода.
Однако сам автор CouchDB собирается переписать её на C++, но сообщество CouchDB с ним не согласно.
То что smagen не понял как это относится к дискуссии означает, что он этого не знал.
1. На момент написания моего предыдущего комментария, из СУБД не основанных на глобалах, упоминались только Redis (написан на C), PostgreSQL (написан на C) и MySQL (написан на C и C++).
2. Я нигде не использовал понятие «современная СУБД». я упоминал «современные технологии СУБД», что далеко не тоже самое.
3. Дискуссия уже явно исчерпала себя. Я уже понял, что то, что меня интересует, мне автор сообщить либо не может, либо не хочет.
Вот про это можно было бы по-подробнее.
Адрес первого блока глобалы и её имя хранятся в главной системной глобале. В первом блоке записываются Значение глобалы, первичные (затем вторичные и т.д.) индексы и значения первичных (вторичных) индексов. В конце блока ссылка на продолжение текущего блока. Индексация производится во время записи нового индекса. Ищется место вставки и записывается новое значение. Блоки разбиты на страницы (насколько помню, по 400 блоков). Длина линейной записи ограничена. Когда заканчивается место, строится второй слой первичных индексов. Для этого в качестве первого блока берётся блок-указатель первого уровня. В него помещаются первый индекс из уже заполненного и вводится ссылка на его расположение в исходной записи. Блок первого уровня может ссылаться на Х (~ 50-100 точно не помню) блоков нулевого уровня. Они продолжают создаваться. Когда заполняется второй блок нулевого уровня, в блоке первого создаётся индекс и ссылка на следующий. Когда полностью заполнится запись первого уровня, создаётся запись второго уровня, которая ссылается уже на записи первого уровня и так далее. Таким образом строится сбалансированное индексированное дерево. Поиск в нём очень быстрый как для чтения, так и для вставки новых индексов. Начинается с блока самого высокого уровня. Адресуется на блок нижнего уровня и до конца. Часто читаемые блоки хранятся в кэше дольше и их не надо повторно считывать с диска.
Данные в базе упакованы плотно, длина записей всегда равна длине данных. Не хранятся лишние пробелы, выравнивающие записи как в других базах. Это тоже увеличивает скорость чтения с диска.
Вообще вся структура ДИАМСа (MSM) иерархична и итерационна. Всё ядро ОС занимало 256 килобайт вместе с драйверами. Графики там не было.
Данные в базе упакованы плотно, длина записей всегда равна длине данных.
А что происходит, когда размер существующих данных увеличивается?
Я писал об этом выше.
При вставке индекса или увеличении размеров данных существующего, если данные не помещаются в имеющийся блок, то в цепочку блоков вставляется свободный. Затрагивается минимум блоков и ссылок на них. При интенсивной вставке база становится рыхлой, но на производительность это почти не влияет.
При вставке индекса или увеличении размеров данных существующего, если данные не помещаются в имеющийся блок, то в цепочку блоков вставляется свободный. Затрагивается минимум блоков и ссылок на них. При интенсивной вставке база становится рыхлой, но на производительность это почти не влияет.
А сам язык программирования удивительно гибок и компактен. Программа экранного редактора программ (в комплекте не было) занимала у меня 15-20 строк текста с возможностью запоминать и вставлять фрагменты, сохранять и загружать текст программы.
Механизм Т9 в ДИАМСе работал мгновенно, тогда как попытка реализации подобного механизма в FOXPRO при базе в 800 человек на каждое изменение вводимого текста мог тормозить на 2 сек. — полный циклический перебор всех индексов.
Механизм Т9 в ДИАМСе работал мгновенно, тогда как попытка реализации подобного механизма в FOXPRO при базе в 800 человек на каждое изменение вводимого текста мог тормозить на 2 сек. — полный циклический перебор всех индексов.
Хочу задать вам несколько вопросов.
1. Вы говорили, что многопоточная вставка ускоряет процесс. По моему опыту еще не существует эффективных не блокирующих деревьев. Даже если все делать с CAS, в итоге 4 потока работают так же как с блокировками на мониторе. Получается что у вас действительно чудесное дерево, что аж не верится. Так какие методики синхронизации потоков все таки были использованы?
2. >> Массив, который автоматически сохраняется на диск.
Любое дерево требует балансировки. Если ваши деревья находятся в массивах, как же вы делаете балансировки?
3. А что если мне требуется еще 3-4 индекса на одни и те же данные. Например сортировка по цене, по названию, фильтрация по имени, группировка по каталогу. Данные в дереве дублируются или индексы строятся во время запросов? Меня немного в ступор вводит ваша фраза, про то что данные в дереве уже проиндексированы.
1. Вы говорили, что многопоточная вставка ускоряет процесс. По моему опыту еще не существует эффективных не блокирующих деревьев. Даже если все делать с CAS, в итоге 4 потока работают так же как с блокировками на мониторе. Получается что у вас действительно чудесное дерево, что аж не верится. Так какие методики синхронизации потоков все таки были использованы?
2. >> Массив, который автоматически сохраняется на диск.
Любое дерево требует балансировки. Если ваши деревья находятся в массивах, как же вы делаете балансировки?
3. А что если мне требуется еще 3-4 индекса на одни и те же данные. Например сортировка по цене, по названию, фильтрация по имени, группировка по каталогу. Данные в дереве дублируются или индексы строятся во время запросов? Меня немного в ступор вводит ваша фраза, про то что данные в дереве уже проиндексированы.
1. Я говорил, что вставка в несколько потоков может ускорить процесс. Контекст этой фразы такой, что я вставлял данные в базу через медленный pipe из PHP, со скоростью 51К вставок/сек. При том, что максимум внутри COS/M у меня был 750К вставок/сек. Очевидно, что даже, если блокировки замедлят процесс, то у него есть потенциал как минимум до 350К вставок/сек.
Если же говорить об увеличении скорости вставок, достигнутых мною в одном потоке (750K/сек), то и это возможно. Внутри баз на глобалах есть эффективное партиционирование. Разные ветви глобала (по диапазонам индексов) база может хранить в разных файлах. Таким образом число локировок уменьшается пропорционально числу партиций глобала. Настраивается оно элементарно. Таким образом есть возможность использовать все ядра, если например мы храним базу с предсказуемым интервалом главного ключа. Например, мы используем мобильный номер как id.
2. Массив это форма работы с глобалом. Абстракция. Ближе всего глобал именно к дереву. Все балансировки происходят при вставке/удалении автоматически.
3. Данные в основном дереве проиндексированы по путям до любых узлов. Тут я рассказал про вторичные индексы. Это фактически вспомогательные деревтья. Если нужен индекс, которого нет, то несложно написать универсальную процедуру, с помощью которой можно индексы построить в любой момент. Либо можно использовать SQL- или объектный доступ к глобалам.
На глобалах можно конструировать новые БД. По словам Rob Tweed они сделали клон SimpleDB (Amazon) на глобалах за месяц.
Если же говорить об увеличении скорости вставок, достигнутых мною в одном потоке (750K/сек), то и это возможно. Внутри баз на глобалах есть эффективное партиционирование. Разные ветви глобала (по диапазонам индексов) база может хранить в разных файлах. Таким образом число локировок уменьшается пропорционально числу партиций глобала. Настраивается оно элементарно. Таким образом есть возможность использовать все ядра, если например мы храним базу с предсказуемым интервалом главного ключа. Например, мы используем мобильный номер как id.
2. Массив это форма работы с глобалом. Абстракция. Ближе всего глобал именно к дереву. Все балансировки происходят при вставке/удалении автоматически.
3. Данные в основном дереве проиндексированы по путям до любых узлов. Тут я рассказал про вторичные индексы. Это фактически вспомогательные деревтья. Если нужен индекс, которого нет, то несложно написать универсальную процедуру, с помощью которой можно индексы построить в любой момент. Либо можно использовать SQL- или объектный доступ к глобалам.
На глобалах можно конструировать новые БД. По словам Rob Tweed они сделали клон SimpleDB (Amazon) на глобалах за месяц.
1. Вы говорили, что многопоточная вставка ускоряет процесс. По моему опыту еще не существует эффективных не блокирующих деревьев. Даже если все делать с CAS, в итоге 4 потока работают так же как с блокировками на мониторе. Получается что у вас действительно чудесное дерево, что аж не верится. Так какие методики синхронизации потоков все таки были использованы?
Если дерево большое, а вставки осуществляются в разные его части, то блокируются разные страницы. В этом случае потоки не мешают друг другу и достигается ускорение. Конечно, когда потоки конкурируют за одни и те же страницы, то ускорения нет, а может быть даже замедление.
Весьма поэтически про глобалы.
Мне понравилось сравнение глобалов с файловой системой, в которой директории не могут существовать без файлов, если в самой «глубокой» директории не осталось ни одного файла. Очень точная найдена метафора.
Чтобы лучше понять работу глобалов представим, что было бы, если создатели файловых систем использовали для хранения информации подход аналогичный глобалам?
Мне понравилось сравнение глобалов с файловой системой, в которой директории не могут существовать без файлов, если в самой «глубокой» директории не осталось ни одного файла. Очень точная найдена метафора.
Если глобалы так быстры, это очень круто! Нужно потестировать эту технологию.
Зарегистрирован:
03 декабря 2010 в 11:42 по приглашению пользователя inetstar
Что-то с глобалами не то, если им нужна накрутка.
Так всё понятно…
Globals DB is a FREE NoSQL Database offering by InterSystems
inetstar — Работаю: InterSystems
morisson — Работаю: InterSystems
adaptun — Работаю: InterSystems
vsekruto — Зарегистрирован: по приглашению пользователя inetstar
Ох, реклама, она такая реклама. :( А ведь я почти поверил в серебрянную пулю nosql. :(
inetstar — Работаю: InterSystems
Все эти операции происходят невероятно быстро. На домашнем компьютере я получал значения до 750 000 вставок/сек в одном процессе. На многоядерных процессорах значения могут достигать десятков миллионов вставок/сек.
morisson — Работаю: InterSystems
«Весьма поэтически про глобалы.Мне понравилось сравнение глобалов с файловой системой, в которой директории не могут существовать без файлов, если в самой «глубокой» директории не осталось ни одного файла. Очень точная найдена метафора.»
adaptun — Работаю: InterSystems
«Вводных статей про глобалы было уже несколько. Эту выделяют отличные рисунки. Тот, на котором изображено дерево из одних груш, — мастерский, как раз из-за аналогии.»
vsekruto — Зарегистрирован: по приглашению пользователя inetstar
«Если глобалы так быстры, это очень круто! Нужно потестировать эту технологию.»
Ох, реклама, она такая реклама. :( А ведь я почти поверил в серебрянную пулю nosql. :(
А ведь я почти поверил в серебрянную пулю nosql.
Ненене, не путайте NoSql в общем и конкретно взятые глобалы. У NoSql есть свои очень разумные применения. А вот где стоят глобалы, как часть NoSql — это весьма интересный вопрос.
Где используются глобалы
… is widely used in financial applications.
MUMPS gained an early following in the financial sector,
and MUMPS applications are in use at many banks and
credit unions. It is used by Ameritrade, the largest online
trading service in the US with over 12 billion transactions
per day, as well as by the Bank of England and Barclays
Bank, among others.*
…
Large companies currently using MUMPS include
AmeriPath (part of Quest Diagnostics), Care Centric,
Epic, Coventry Healthcare, EMIS, Partners HealthCare
(including Massachusetts General Hospital),
MEDITECH, GE Healthcare (formerly IDX Systems
and Centricity), and Sunquest Information Systems
(formerly Misys Healthcare*[8]). Many reference
laboratories, such as DASA, Quest Diagnostics,
[9] and Dynacare, use MUMPS software written by or based
on Antrim Corporation code. Antrim was purchased by
Misys Healthcare (now Sunquest Information Systems)
in 2001.*
…
The U.S. Department of Veterans Affairs (formerly the
Veterans Administration) was one of the earliest major
adopters of the MUMPS language. Their development
work (and subsequent contributions to the free
MUMPS application codebase) was an influence on
many medical users worldwide. In 1995, the Veterans
Affairs' patient Admission/Tracking/Discharge system,
Decentralized Hospital Computer Program (DHCP) was
the recipient of the Computerworld Smithsonian Award
for best use of Information Technology in Medicine. In
July 2006, the Department of Veterans Affairs (VA) /
Veterans Health Administration (VHA) was the recipient
of the Innovations in American Government Award presented
by the Ash Institute of the John F. Kennedy School
of Government at Harvard University for its extension of
DHCP into the Veterans Health Information Systems and
Technology Architecture (VistA). Nearly the entire VA
hospital system in the United States, the Indian Health
Service, and major parts of the Department of Defense
CHCS hospital system use MUMPS databases for clinical
data tracking.
MUMPS gained an early following in the financial sector,
and MUMPS applications are in use at many banks and
credit unions. It is used by Ameritrade, the largest online
trading service in the US with over 12 billion transactions
per day, as well as by the Bank of England and Barclays
Bank, among others.*
…
Large companies currently using MUMPS include
AmeriPath (part of Quest Diagnostics), Care Centric,
Epic, Coventry Healthcare, EMIS, Partners HealthCare
(including Massachusetts General Hospital),
MEDITECH, GE Healthcare (formerly IDX Systems
and Centricity), and Sunquest Information Systems
(formerly Misys Healthcare*[8]). Many reference
laboratories, such as DASA, Quest Diagnostics,
[9] and Dynacare, use MUMPS software written by or based
on Antrim Corporation code. Antrim was purchased by
Misys Healthcare (now Sunquest Information Systems)
in 2001.*
…
The U.S. Department of Veterans Affairs (formerly the
Veterans Administration) was one of the earliest major
adopters of the MUMPS language. Their development
work (and subsequent contributions to the free
MUMPS application codebase) was an influence on
many medical users worldwide. In 1995, the Veterans
Affairs' patient Admission/Tracking/Discharge system,
Decentralized Hospital Computer Program (DHCP) was
the recipient of the Computerworld Smithsonian Award
for best use of Information Technology in Medicine. In
July 2006, the Department of Veterans Affairs (VA) /
Veterans Health Administration (VHA) was the recipient
of the Innovations in American Government Award presented
by the Ash Institute of the John F. Kennedy School
of Government at Harvard University for its extension of
DHCP into the Veterans Health Information Systems and
Technology Architecture (VistA). Nearly the entire VA
hospital system in the United States, the Indian Health
Service, and major parts of the Department of Defense
CHCS hospital system use MUMPS databases for clinical
data tracking.
Ссылка, страница 359
Это ничего не говорит нам о месте глобалов в экосистеме (и классификации) NoSql-решений, а мой вопрос был именно об этом.
(Ну и да, каждый раз, когда я вижу список мест использования MUMPS, я задаюсь вопросом — когда же была первая инсталляция подобного решения у этого заказчика. Но это не тема для дискуссии в этом посте.)
(Ну и да, каждый раз, когда я вижу список мест использования MUMPS, я задаюсь вопросом — когда же была первая инсталляция подобного решения у этого заказчика. Но это не тема для дискуссии в этом посте.)
Предложите место, куда поместили бы вы.
Я специально рассматриваю глобалы, а не MUMPS, так как новые приложения лучше разрабатывать на COS.
А сами глобалы можно использовать как структуры хранения данных из других языков.
Мне более всего импонируют глобалы для сохранения информации нуждающейся в первичной структуризации, замены EAV, а также для конструирования новых специализированных типов БД.
Я специально рассматриваю глобалы, а не MUMPS, так как новые приложения лучше разрабатывать на COS.
А сами глобалы можно использовать как структуры хранения данных из других языков.
Мне более всего импонируют глобалы для сохранения информации нуждающейся в первичной структуризации, замены EAV, а также для конструирования новых специализированных типов БД.
Предложите место, куда поместили бы вы.
Я же сказал — это интересный вопрос. Пока что это ближе всего к key/value (я помню про иерархичность), дальше вопрос, как реально соотносятся возможности, гарантии и производительность.
Мне более всего импонируют глобалы для сохранения информации нуждающейся в первичной структуризации, замены EAV,
EAV в мире NoSQL, по факту, не существует. А для «сохранения информации, нуждающейся в первичной структуризации» много что подходит — и key-value, и document-oriented, и даже event storage.
также для конструирования новых специализированных типов БД.
Может все-таки не стоит строить одну БД поверх другой? Можно нарваться на тот же impedance mismatch, что преследует ORM.
Может все-таки не стоит строить одну БД поверх другой?
Стоит. Это очень просто и дешево. Как прототип — точно стоит. А потом может оказаться, что и прототипа достаточно.
А потом может оказаться, что и прототипа достаточно.
Эээ… МакКоннелл не для вас писал, видимо. Или вы имеете в виду «прототипа достаточно, чтобы понять, что систему разрабатывать не стоит»?
Приводите точную ссылку, пожалуйста. И на нужную страницу. Или цитату. Думаю, МакКоннелл много чего написал.
Я имею ввиду, что если прототип выполняет всё что требуется с нужной скоростью и гарантиями сохранности, то создавать базу с нуля не потребуется.
Я имею ввиду, что если прототип выполняет всё что требуется с нужной скоростью и гарантиями сохранности, то создавать базу с нуля не потребуется.
Приводите точную ссылку, пожалуйста. И на нужную страницу. Или цитату. Думаю, МакКоннелл много чего написал.
Steve McConnell, Code Complete, 2 ed, Microsoft Press, 2004, p. 114:
The word “prototyping” means lots of different things to different people (McConnell 1996). In this context, prototyping means writing the absolute minimum amount of throwaway code that’s needed to answer a specific design question. [...] Prototyping works poorly when developers aren’t disciplined about writing the absolute minimum of code needed to answer a question.
Я имею ввиду, что если прототип выполняет всё что требуется с нужной скоростью и гарантиями сохранности, то создавать базу с нуля не потребуется.
Тогда это не прототип.
Бывают удачные прототипы.
Или кто-то пишет код. Говорит альфа.
Время проходит, глюков не находят. И становится stable.
Или кто-то пишет код. Говорит альфа.
Время проходит, глюков не находят. И становится stable.
Удачный прототип — это прототип, который ответил на заданный вопрос за минимальное время. Ну или у вас свое понимание слова «прототип», отличающееся от МакКоннелловского (ну и, скромно говоря, моего).
У меня понимание ближе к техническим словарям русского языка. Реально работающая предварительная версия продукта.
Окей, не вижу смысла спорить о терминологии. Поясните, пожалуйста, чем эта предварительная версия отличается от финальной? На каком этапе разработки она появляется?
В тот момент, когда руководитель проекта говорит: «Всё! Уже не глючит. Выкладываем первый релиз (отправляем в серию)»
Вы говорите о proof of concept, а я о том, что для решения какой-то проблемы смастерили прибор, а он так хорошо работает, что оказалось что прототипной версией можно полноценно пользоваться без значимых недостатков.
Вы говорите о proof of concept, а я о том, что для решения какой-то проблемы смастерили прибор, а он так хорошо работает, что оказалось что прототипной версией можно полноценно пользоваться без значимых недостатков.
В тот момент, когда руководитель проекта говорит: «Всё! Уже не глючит. Выкладываем первый релиз (отправляем в серию)»
Это вы о предварительной версии или финальной? Я спрашивал о предварительной. Ну и чем они отличаются, меня все еще интересует.
Они отличаются только решением руководителя. Этот фазовый переход происходит у него в голове. Он может отправить полное глючило в продажи или продакшен.
Таким образом, ваша «предварительная рабочая версия» появляется на финальной стадии разработки, когда реализованы вся (или хотя бы подавляющее большинство) функциональность, запланированная к релизу, архитектура и дизайн приложения/системы определены, ну и так далее — проще говоря, большая часть работы проведена и завершена?
Так или нет?
Так или нет?
Совершенно необязательно. Я же говорил о фазовом переходе в голове босса.
Когда босс принимает решение о переходе прототипа в релиз, тогда оно и происходит.
Полно примеров, когда недоделки и глючила шли в серию.
Или когда продавали бесконечно виснущие ОС.
Главный критерий перехода — это субъективно оцененная целесообразность оного ответственным лицом.
Когда босс принимает решение о переходе прототипа в релиз, тогда оно и происходит.
Полно примеров, когда недоделки и глючила шли в серию.
Или когда продавали бесконечно виснущие ОС.
Главный критерий перехода — это субъективно оцененная целесообразность оного ответственным лицом.
Понятно. У нас с вами принципиально разные представления о подходе к разработке (впрочем, это и по терминологии видно).
В моем понимании, существует некий набор решений, которые надо принимать раньше, а не позже (здесь я согласен с Сальтарелло и Эспозито в их определении, что архитектурное решение — это такое решение, последствия ошибочного выбора в котором будут дороже потом, нежели сейчас). И выбор хранилища относится как раз к таким решениям: смена хранилища/технологии доступа к данным на живом проекта — это едва ли не самое дорогое изменение (не считая смены архитектуры в целом), которое я видел.
Соответственно, идея брать «какое-нибудь» хранилище на этапе дизайна с мыслью «ну подойдет — так и запустим в релиз» меня приводит в некоторое, скажем так, непонимание. Обычно хранилище (как и другие инфраструктурные вещи) выбираются по совокупности критериев, включая как функциональные и нефункциональные требования заказчика, так и собственно опыт команды разработки.
Использовать одну БД при разработке другой? Только для каких-то очень странных случаев, обычно выгоднее писать с нуля, чтобы не натыкаться на семантические различия.
А для общих случаев — я и вовсе не вижу, чем глобалы выгоднее в разработке (не быстром прототипировании на выброс), чем любая другая подходящая для задачи БД. That, как говорится, remains to be seen.
В моем понимании, существует некий набор решений, которые надо принимать раньше, а не позже (здесь я согласен с Сальтарелло и Эспозито в их определении, что архитектурное решение — это такое решение, последствия ошибочного выбора в котором будут дороже потом, нежели сейчас). И выбор хранилища относится как раз к таким решениям: смена хранилища/технологии доступа к данным на живом проекта — это едва ли не самое дорогое изменение (не считая смены архитектуры в целом), которое я видел.
Соответственно, идея брать «какое-нибудь» хранилище на этапе дизайна с мыслью «ну подойдет — так и запустим в релиз» меня приводит в некоторое, скажем так, непонимание. Обычно хранилище (как и другие инфраструктурные вещи) выбираются по совокупности критериев, включая как функциональные и нефункциональные требования заказчика, так и собственно опыт команды разработки.
Использовать одну БД при разработке другой? Только для каких-то очень странных случаев, обычно выгоднее писать с нуля, чтобы не натыкаться на семантические различия.
А для общих случаев — я и вовсе не вижу, чем глобалы выгоднее в разработке (не быстром прототипировании на выброс), чем любая другая подходящая для задачи БД. That, как говорится, remains to be seen.
Нет-нет. Вы не поняли того, что я сказал.
Моя идея не в том, чтобы брать какое-нибудь хранилище на этапе разработки. А в том, что на глобалах можно легко сконструировать специализированную БД, если таковой нет в природе. И с приличной вероятностью переписывать потом её не придётся. Десятки лет глобалы работают в трейдинге и медицине.
Вы же предлагаете писать с нуля, что долго, дорого и глючно.
С нуля писать базу данных почти никогда не является более выгодным, в проектах где она не главное. Редчайшие случаи.
На темы того, чем глобалы выгодны в разработке скоро будет другая статья.
Моя идея не в том, чтобы брать какое-нибудь хранилище на этапе разработки. А в том, что на глобалах можно легко сконструировать специализированную БД, если таковой нет в природе. И с приличной вероятностью переписывать потом её не придётся. Десятки лет глобалы работают в трейдинге и медицине.
Вы же предлагаете писать с нуля, что долго, дорого и глючно.
С нуля писать базу данных почти никогда не является более выгодным, в проектах где она не главное. Редчайшие случаи.
На темы того, чем глобалы выгодны в разработке скоро будет другая статья.
А в том, что на глобалах можно легко сконструировать специализированную БД, если таковой нет в природе.
Например?
С нуля писать базу данных почти никогда не является более выгодным, в проектах где она не главное.
Как база данных может быть не главным, когда речь идет о специализированной БД?
Ну или у нас еще и понятие «специализированной БД» расходится.
Например?
База болезней со специфическими следствиями, симптомами и т.д.
Как база данных может быть не главным, когда речь идет о специализированной БД?
Элементарно. Например, в социальной сети мне нужно проанализировать некий граф. Это не главное. Главное — сама социальная сеть. А специальная БД может понадобиться.
здесь я согласен с Сальтарелло и Эспозито в их определении, что архитектурное решение — это такое решение, последствия ошибочного выбора в котором будут дороже потом, нежели сейчас
Звучи, конечно, круто. Но практически любую ошибку проще исправить сразу, чем потом. Начиная от кофейного пятна и опечатки, заканчивая выбором СУБД.
База болезней со специфическими следствиями, симптомами и т.д.
Это не «специализированная БД», это обычная прикладная БД. Которая может быть построена на той или иной технологии.
Элементарно. Например, в социальной сети мне нужно проанализировать некий граф. Это не главное. Главное — сама социальная сеть. А специальная БД может понадобиться.
В этом случае вполне можно взять существующую БД для работы с графами.
Звучи, конечно, круто. Но практически любую ошибку проще исправить сразу, чем потом.
Вопрос стоимости. Для архитектурных решений она выше, чем для не-архитектурных. Грубо говоря, есть разница между выбором БД и годом в копирайте в нижнем колонтитуле сайта.
Серебряной пули нет, кто бы где не работал.
Именно!
На всякий случай помещу тут ссылку — en.wikipedia.org/wiki/No_Silver_Bullet.
На всякий случай помещу тут ссылку — en.wikipedia.org/wiki/No_Silver_Bullet.
Если бы вы читали внимательно, то увидели бы что лично я тестировал на скорость GT.M — бесплатную и опенсорсную БД на глобалах.
И несколько ссылок на неё тоже давал.
GlobalsDB и Caché работают также очень и очень быстро, что подтверждают другие источники.
И несколько ссылок на неё тоже давал.
GlobalsDB и Caché работают также очень и очень быстро, что подтверждают другие источники.
Неважно. В статье скрытая реклама GlobalsDB и Caché, в комментах работники вашей компании изображают «просто прохожих» с хвалебными отзывами и скрытой рекламой. Должны ли мы верить в объективность и корректность вашего анализа и тестов? :)
Позволю себе ответить, хоть вы и не мне написали. inetstar, если захочет, тоже, наверное, ответит.
1) В статье реклама явная. Как может быть _скрытая_ реклама в блоге компании InterSystems. Конечно явная.
2) Как мы можем изображать просто прохожих, если у нас в профилях написано «работаю в InterSystems». (см также)
3) У меня в комментарии (не буду говорить за других) моё личное мнение. Я до сих пор не понимаю, чем он рекламный.
4) Вы ни в коем случае верить не должны! Должны убедиться сами.
1) В статье реклама явная. Как может быть _скрытая_ реклама в блоге компании InterSystems. Конечно явная.
2) Как мы можем изображать просто прохожих, если у нас в профилях написано «работаю в InterSystems». (см также)
3) У меня в комментарии (не буду говорить за других) моё личное мнение. Я до сих пор не понимаю, чем он рекламный.
4) Вы ни в коем случае верить не должны! Должны убедиться сами.
adaptun всё правильно сказал.
Что удивительного в том, что те, кому нравится какая-то технология хорошего о ней мнения?
Лучший критерий истины — практика.
Лично я решил писать статьи о глобалах именно потому, что был впечатлён их скорострельностью и универсальностью.
Провёл тесты и понял, что об этой технологии нужно рассказать.
Что удивительного в том, что те, кому нравится какая-то технология хорошего о ней мнения?
Лучший критерий истины — практика.
Лично я решил писать статьи о глобалах именно потому, что был впечатлён их скорострельностью и универсальностью.
Провёл тесты и понял, что об этой технологии нужно рассказать.
Все эти операции происходят невероятно быстро. На домашнем компьютере я получал значения до 750 000 вставок/сек в одном процессе. На многоядерных процессорах значения могут достигать десятков миллионов вставок/сек.
На самом деле в этой цифре нет ничего такого уж фантастического. Я на домашнем компьютере в PostgreSQL с помощью команды COPY могу делать 400 000 вставок/сек. Но вот только PostgreSQL вставка осуществляется сразу в два места – в heap и в индекс. Также PostgreSQL обременён MVCC с тяжёлыми tuple header'ами, абстракцией от типов данных и т.д.
Т.е., в принципе, скорость вставки в глобалы, с моей точки зрения, не фантастическая. Такая, какая и должна быть при добротной реализации журналируемого дерева даже без мечей-кладенцов, технологий 90.0 и ассемблерной оптимизации 50% кода :)
Мне только непонятно одно – неужели это действительно рекорд среди NoSQL, да ещё с отрывом чуть ли не на порядок? В это не очень верится, но если это так, то это было бы довольно забавно.
Спасибо! :)
Извини. Redis — это in-memory БД. А 750 000 это вставка на моём домашнем компе с записью на винт.
Если говорить о рекордах сравнивать нужно тогда с 22M/вставок в секунду, которые даёт Caché на хорошем железе.
И сравнивать с другой NoSQL базой, которая сохраняет на винт.
Если говорить о рекордах сравнивать нужно тогда с 22M/вставок в секунду, которые даёт Caché на хорошем железе.
И сравнивать с другой NoSQL базой, которая сохраняет на винт.
сравнивать нужно тогда с 22M/вставок в секунду, которые даёт Caché на хорошем железе.
SRSLY?
Цитирую еще раз: «I was able to achieve this, without any optimizations, on a 512MB VM I made on my server»
И сравнивать с другой NoSQL базой, которая сохраняет на винт.
А кто недавно утверждал, что in-memory тоже сбрасывает на диск?
Ну а что непонятного? Человек запустил маленькую базу на маленькой виртуальной машине. Причём скорее всего 512MB это объём свободной памяти. А VM что-то типа OpenVZ, которая считает объём памяти для скриптов пользователя и не считает остальное.
А какой размер базы? 10 строк?
И где вы увидели указание, что памяти для Redis не хватило и он постоянно свопился на диск?
А какой размер базы? 10 строк?
И где вы увидели указание, что памяти для Redis не хватило и он постоянно свопился на диск?
А какой размер базы?
А какая разница, какой «размер базы», если в нее было сделано два миллиона записей из одного миллиона случайных ключей? После выполнения первой части теста там все равно ~миллион записей.
И где вы увидели указание, что памяти для Redis не хватило и он постоянно свопился на диск?
А это вообще отношения к персистентности не имеет.
Не нравятся эти результаты? Вот вам другие. Напоминаю, что все эти цифры — это обмен либо через tcp/ip, либо через юникc-сокет, поэтому сравнивать надо не с 750К/сек, а с 58К/сек (цифра из вашего теста), либо с 200К/сек (в случае 16х-пайплайнинга в редисе).
Собственно, это еще одна иллюстрация к тому, что методику тестирования надо описывать детально и аккуратно, а сами по себе цифры не значат ни-че-го (и в статье про redis-benchmark это неоднократно повторено).
И где вы увидели указание, что памяти для Redis не хватило и он постоянно свопился на диск?
А это вообще отношения к персистентности не имеет.
smagen явно имел ввиду NoSQL базы с записью на диск, так как он сравнивал с PgSql, а вы ему подсунули цифру от in-memory базы.
smagen явно имел ввиду NoSQL базы с записью на диск, так как он сравнивал с PgSql, а вы ему подсунули цифру от in-memory базы.
Я думаю, что smagen сам способен сказать, что он имел в виду. И, повторюсь, чтобы аргументированно спорить «in-memory vs on-disk», необходимо определяться с требуемыми и предоставляемыми гарантиями.
PS Как быстро забылся тезис «глобалы работают быстрее in-memory».
Не нужно искажать мои слова! Вот первоначальная фраза:
Я не говорил, что как правило быстрее. В конкретном тесте Rob'а Tweed быстрее, но, мы выяснили, что методика у него не даёт строгой доказательной базы.
Как правило глобалы работают со скоростью in-memory БД при этом обеспечивая хранение на диске, транзакции и другие плюшки.
Я не говорил, что как правило быстрее. В конкретном тесте Rob'а Tweed быстрее, но, мы выяснили, что методика у него не даёт строгой доказательной базы.
Для in-memory баз сбрасывание на диск происходит редко. Если его специально настроить.
А в базах на глобалах каждую 1-2 секунды (в зависимости от реализации, можно и в 0 поставить).
Некорректно сравнивать. Для корректного сравнения нужна NoSQL-база, которая сохраняет не реже, чем 1 раз в секунду.
А в базах на глобалах каждую 1-2 секунды (в зависимости от реализации, можно и в 0 поставить).
Некорректно сравнивать. Для корректного сравнения нужна NoSQL-база, которая сохраняет не реже, чем 1 раз в секунду.
Я на домашнем компьютере в PostgreSQL с помощью команды COPY
Так это же некорректное сравнение. В моём тесте я не предсоздавал запрос. Он генерировался динамически.
Если уж жульничать как вы, то я могу использовать bulk-функции для загрузки дампов глобалов. И результат повышу до миллионов.
Первый вопрос: сколько вставок конкретно вы делали? Я миллион. Вставка 778 361 вставок/секунду.
Вставим 300 миллионов значений. 422 141 вставок/секунду
Попробуйте 300M.
Я на домашнем компьютере
Второй вопрос: А не SSD ли вы использовали? Я в некоторых комментах говорил, что использовал обычные винты.
какая и должна быть при добротной реализации журналируемого дерева
Это не просто журналируемое дерево. Оно ещё поддерживает ACID-транзакции с многоверсионностью.
Оно ещё поддерживает ACID-транзакции с многоверсионностью.
В любом глобале или в конкретной реализации? Можно увидеть либо тесты, подтверждающие это заявление, либо хотя бы утверждение в официальной документации?
(напомню, что в комментариях к этому посту мы пока не видели ни одного фактического — или хотя бы выданного производителем — подтверждения ни D, ни I в транзакциях)
Агу.
Caché:
Внимание, вопрос: это функции Caché или глобалов? Иными словами, какая их часть доступна в GlobalsDB? Опять-таки, обратите внимание на «by using locking operations». Где можно посмотреть, какие уровни изоляции гарантируют транзакции в Caché?
GT.M:
Так что «поддерживает» — это хорошо, но вопрос, какой ценой. Это про D. А про I — какие уровни изоляции гарантирует GT.M? Я этой информации в документации не нашел.
Caché:
Caché provides commands that define transaction boundaries; you can start, commit, or rollback a transaction. In the event of a rollback, all modifications made to globals within the transaction are undone; the contents of the database are restored to their pre-transaction state. By using the various Caché locking operations in conjunction with transactions, you can perform traditional ACID transactions using globals.
Внимание, вопрос: это функции Caché или глобалов? Иными словами, какая их часть доступна в GlobalsDB? Опять-таки, обратите внимание на «by using locking operations». Где можно посмотреть, какие уровни изоляции гарантируют транзакции в Caché?
GT.M:
The four key properties of transaction processing systems, the so called «ACID» properties are: Atomicity, Consistency, Isolation, and Durability. GT.M transaction processing provides the first three through the use of the TStart and TCommit commands. Durability is provided through the use of journaling. [...] GT.M's extensive journaling capabilities are optional. [...] Journaling requires additional CPU cycles, memory, and disk access. This can impact application performance.
Так что «поддерживает» — это хорошо, но вопрос, какой ценой. Это про D. А про I — какие уровни изоляции гарантирует GT.M? Я этой информации в документации не нашел.
Вы бы поиск по комментариям сделали. На этот вопрос я уже отвечал.
GlobalsDB через java-интерфейс имеет возможность работать с транзакциями.
GlobalsDB через java-интерфейс имеет возможность работать с транзакциями.
Вы бы поиск по комментариям сделали. На этот вопрос я уже отвечал.
Так и вам там уже ответили. Половина (Caché) вообще к глобалам не относится. А то, что реализовано в GT.M («If one or more blocks have changed, the process reverts its state to the TSTART and re-executes the application code for the transaction.») — это звучит страшненько. И все равно из этого описания не очевидно, дает ли GT.M повторяемое чтение.
GlobalsDB через java-интерфейс имеет возможность работать с транзакциями.
C какими гарантиями изоляции и персистентности?
Понимаете, мы, собственно, ходим по кругу. Вопрос, на самом деле, не в том, какие «фишки» других БД есть в глобалах, а в том, насколько они совпадают семантически (а не только по названию), и как их применение отражается на других характеристиках глобалов (например, скорости).
Я дал ссылки на доки. Глобалы — это фундамент в Caché. На них всё держится.
Вы мне тоже на несколько вопросов не ответили. Пропустили неудобные.
Например, чего стоят гарантии D, если операционная система только в которой работает база, совсем не D.
А перед этим расписывали насколько честен и какие твёрдые гарантии даёт MS SQL.
Вы мне тоже на несколько вопросов не ответили. Пропустили неудобные.
Например, чего стоят гарантии D, если операционная система только в которой работает база, совсем не D.
А перед этим расписывали насколько честен и какие твёрдые гарантии даёт MS SQL.
Я дал ссылки на доки. Глобалы — это фундамент в Caché. На них всё держится.
А еще ниже все держится на байтиках, только это не значит, что байтики транзакционны. Каждый уровень добавляет абстракции и возможностей.
(Все, вопрос повторяемого чтения в GT.M закрыт за отсутствием подтверждаемой информации?)
Например, чего стоят гарантии D, если операционная система только в которой работает база, совсем не D.
Ответил.
Если не понятно — отвечу еще раз: в Windows (как и в других системах) есть возможность получить от подсистемы IO информацию «операция записи признана успешной». Сейчас не важно, как IO-подсистема ее отдаст, это уже вопрос железа и драйверов. Соответственно, если мы отдали транзакцию в запись, и получили в ответ такую отмашку, то все, с этой транзакцией уже ничего не может случиться (не считая аппаратных проблем, но они не зависят от ОС). MS SQL, в свою очередь, гарантирует, что команда COMMIT не завершится, пока не будет получена отмашка. Соответственно, гарантии по durability выполнимы настолько, насколько их выполняет нижележащее железо.
Какие-то еще вопросы по этой теме?
Ну не ответили. Ответ был не по существу.
Правильный ответ был бы такой — ничего не стоят.
Это произведение D(OS)*D(базы), если один множитель 0, то и в целом получим ноль.
Я вот, например, не боюсь делать эксперименты с отключением питания на журналируемых ФС линукса, а вот вы по вашему признанию боитесь.
И вообще нет никакой гарантии, что выживет ваша тестовая БД, а упадёт именно системный раздел. БД также, запросто, может не подняться.
Вывод: ваш собственный опыт не позволяет вам признать мою правоту, но эго требует что-нибудь сказать.
Правильный ответ был бы такой — ничего не стоят.
Это произведение D(OS)*D(базы), если один множитель 0, то и в целом получим ноль.
Я вот, например, не боюсь делать эксперименты с отключением питания на журналируемых ФС линукса, а вот вы по вашему признанию боитесь.
И вообще нет никакой гарантии, что выживет ваша тестовая БД, а упадёт именно системный раздел. БД также, запросто, может не подняться.
Вывод: ваш собственный опыт не позволяет вам признать мою правоту, но эго требует что-нибудь сказать.
Ну не ответили. Ответ был не по существу.
Правильный ответ был бы такой — ничего не стоят.
Это произведение D(OS)*D(базы), если один множитель 0, то и в целом получим ноль.
Окей, а с чего вы взяли, что у Windows нулевая гарантия D?
Я вот, например, не боюсь делать эксперименты с отключением питания на журналируемых ФС линукса, а вот вы по вашему признанию боитесь.
Посмотрите выше на вашу же формулу. Не все процессы, работающие на моем компьютере, обеспечивают корректную персистентность на своем уровне. Ну и само железо жалко.
И вообще нет никакой гарантии, что выживет ваша тестовая БД, а упадёт именно системный раздел. БД также, запросто, может не подняться.
Конечно, нет. Если упадет железо — то упадет, что угодно. Только от этого никакое ПО не застраховано.
Окей, а с чего вы взяли, что у Windows нулевая гарантия D?
Из ваших страхов. Мой прошлый опыт тоже говорит, что десятка отключений питания в разгаре операций записи Windows может не пережить. А может хватить и одного. По моему опыту вообще 50 на 50.
А железу-то как раз ничего не будет. Просто разрушится может файловая система.
Простите, а как вы вообще понимаете гарантию durability применительно к транзакции? Потому что то, что вы описали, с ней никак не связано.
Так и понимаю. Если после подтверждения фиксации отключить ток, то после перезагрузки записанная информация нормально считается с винта.
Ключевое слово — записанная информация. Понимаете, записанная. Гарантия durability ничего не говорит о той информации, которая была в процессе записи в момент выключения питания.
Соответственно, чтобы доказать, что у Windows нулевая гарантия D, нужно доказать, что для правильно заданной (т.е., с явным сбросом буфера или с явным отключением оного) операции записи после подтверждения этой операции информация — записанная в рамках этой операции — с диска не читается. Естественно, сбойное железо и железо, игнорирующее стандарты, мы не рассматриваем.
Приводимые вами примеры этого никак не показывают.
Соответственно, чтобы доказать, что у Windows нулевая гарантия D, нужно доказать, что для правильно заданной (т.е., с явным сбросом буфера или с явным отключением оного) операции записи после подтверждения этой операции информация — записанная в рамках этой операции — с диска не читается. Естественно, сбойное железо и железо, игнорирующее стандарты, мы не рассматриваем.
Приводимые вами примеры этого никак не показывают.
Если было подтверждение — значит записана, а не в процессе. А иначе это нечестное D.
Несомненно. А что, вы считаете, что Windows дает подтверждение записи (естественно, в оговоренных выше условиях) до того, как операция подтверждена железом?
Ну вот мы и вернулись к началу.
Если винда всё делает правильно и MS SQL тоже, то проведите означенный мною эксперимент.
Вы скажете — жалко железа. А я скажу гарантии D низкие и про произведение. И про итоговый результат оного.
И в качестве вывода про «честность» ваших транзакций.
Если винда всё делает правильно и MS SQL тоже, то проведите означенный мною эксперимент.
Вы скажете — жалко железа. А я скажу гарантии D низкие и про произведение. И про итоговый результат оного.
И в качестве вывода про «честность» ваших транзакций.
Ну вот проведу я этот эксперимент. У меня (предположим) радостно навернется SSD (как на моей памяти было дважды). Что это докажет? Правильно, ничего.
Или проведу я этот эксперимент, а у меня перестанет загружаться система (хотя вот этого на моей памяти не было ни разу). При этом если я достану диск из компа и скопирую файлы БД на другую систему, то данные будут полностью восстановлены. И что это докажет? Тоже ничего.
В обоих случаях я потеряю кучу времени (а в первом — еще и денег), но, как ни странно, ничего не докажу, потому что согласитесь, что даже при отсутствии в винде каких-либо гарантий, отказ — это вероятностная характеристика, а не, простите за каламбур, гарантированная.
При этом, что интересно, привести каких-либо логических аргументов, которые бы указывали, что эта вероятность отлична от нуля, вы не можете.
Или проведу я этот эксперимент, а у меня перестанет загружаться система (хотя вот этого на моей памяти не было ни разу). При этом если я достану диск из компа и скопирую файлы БД на другую систему, то данные будут полностью восстановлены. И что это докажет? Тоже ничего.
В обоих случаях я потеряю кучу времени (а в первом — еще и денег), но, как ни странно, ничего не докажу, потому что согласитесь, что даже при отсутствии в винде каких-либо гарантий, отказ — это вероятностная характеристика, а не, простите за каламбур, гарантированная.
При этом, что интересно, привести каких-либо логических аргументов, которые бы указывали, что эта вероятность отлична от нуля, вы не можете.
Практика сильней теории. Если практика противоречит теории — меняем теорию.
Нет никаких гарантий, что если вы скопируете файлы БД, то они запустятся, а не будут из нулей, например.
В идеале производители БД должны были бы хотя бы 1000 таких тестов провести, а потом говорить о честности.
Но это будет какой-то хреноватый маркетинг: «Ребята, у нас в 50% случаев получилось запустить базу и сохранить инфу! Слава нашей Durability!»
Нет никаких гарантий, что если вы скопируете файлы БД, то они запустятся, а не будут из нулей, например.
В идеале производители БД должны были бы хотя бы 1000 таких тестов провести, а потом говорить о честности.
Но это будет какой-то хреноватый маркетинг: «Ребята, у нас в 50% случаев получилось запустить базу и сохранить инфу! Слава нашей Durability!»
Практика сильней теории. Если практика противоречит теории — меняем теорию.
Я пока не вижу никаких практических наблюдений, противоречащих практике.
Нет никаких гарантий, что если вы скопируете файлы БД, то они запустятся, а не будут из нулей, например.
Я с равным успехом могу сказать, что нет никаких гарантий, что БД вернет обратно те же данные, которые в нее были записаны. Любая БД, я имею в виду.
MS утверждает, что система ведет себя так. Контрпримеров я не видел ни одного (а падавших серверов я видел достаточно). Не вижу, почему я должен верить вам, а не МС.
В идеале производители БД должны были бы хотя бы 1000 таких тестов провести, а потом говорить о честности.
Два вопроса.
(а) почему вы думаете, что производители MS SQL таких тестов не проводили?
(б) а есть такие же тесты на глобалсы?
а) не хотят рушить свою репутацию
б) не знаю.
Но из-за чего этот тред? Вы распиарили честность и гарантированность транзакций MS SQL. А я вам доказываю, что это несколько преувеличено.
У БД на глобалах есть журналы для D. У GT.M и Caché точно.
Производитель заявляет поддержку полного ACID, много крупных пользователей — банки, трейдеры, здравохранение используют. В вики об этом написано, как и в доках. Эксперименты можно поставить. Я ставил.
Есть ACID.
б) не знаю.
Но из-за чего этот тред? Вы распиарили честность и гарантированность транзакций MS SQL. А я вам доказываю, что это несколько преувеличено.
У БД на глобалах есть журналы для D. У GT.M и Caché точно.
Производитель заявляет поддержку полного ACID, много крупных пользователей — банки, трейдеры, здравохранение используют. В вики об этом написано, как и в доках. Эксперименты можно поставить. Я ставил.
Есть ACID.
Вы распиарили честность и гарантированность транзакций MS SQL. А я вам доказываю, что это несколько преувеличено.
Доказательства так и нет. Есть ваши предположения, которые не основаны ни на чем.
Производитель заявляет поддержку полного ACID,
Для транзакции? Можно, пожалуйста, цитату, в которой это будет сказано (да-да, что именно для транзакции и именно полного).
Понимаете, то, что много пользователей используют, не означает, что есть ACID — означает лишь то, что эти пользователи нашли такой способ построить систему, при которой конкретные гарантии, предоставляемые используемым им ПО, их устраивают. Сейчас вообще много не-ACID систем, если что, это само по себе вполне нормально, если понимать, с чем имеешь дело, и как его готовить.
Есть ACID.
Повторюсь, вопрос не в том, есть ли в глобалсах ACID. Вопрос в том, какой именно (т.е., как он семантически соотносится с ACID в других БД), и, если он не обязателен (а это, как мы знаем, так), то как он влияет на скорость. Проще говоря, когда мы сравниваем скорость записи глобалсов со скоростью записи в (любая другая система), чтобы сравнение было честным, надо, чтобы гарантии durability были одинаковыми. А когда мы начинаем тестировать систему под параллельной нагрузкой — чтобы еще и были одинаковыми гарантии изоляции (потому что на их поддержание уходят ресурсы).
Хорошо, докажите мне, что MS SQL имеет 100% честность транкзаций. Слушаю.
Вы говорили про честность. Ноша доказательств ложится на утверждающего.
По моим тестам скорость у глобалов примерно в 2 раза замедляется в транкзационном режиме.
Вы говорили про честность. Ноша доказательств ложится на утверждающего.
По моим тестам скорость у глобалов примерно в 2 раза замедляется в транкзационном режиме.
Хорошо, докажите мне, что MS SQL имеет 100% честность транкзаций.
Пожалуйста:
A transaction is a sequence of operations performed as a single logical unit of work. A logical unit of work must exhibit four properties, called the atomicity, consistency, isolation, and durability (ACID) properties, to qualify as a transaction.
Atomicity: A transaction must be an atomic unit of work; either all of its data modifications are performed, or none of them is performed.
Consistency: When completed, a transaction must leave all data in a consistent state. In a relational database, all rules must be applied to the transaction's modifications to maintain all data integrity. All internal data structures, such as B-tree indexes or doubly-linked lists, must be correct at the end of the transaction.
Isolation: Modifications made by concurrent transactions must be isolated from the modifications made by any other concurrent transactions. A transaction either recognizes data in the state it was in before another concurrent transaction modified it, or it recognizes the data after the second transaction has completed, but it does not recognize an intermediate state. This is referred to as serializability because it results in the ability to reload the starting data and replay a series of transactions to end up with the data in the same state it was in after the original transactions were performed.
Durability: After a transaction has completed, its effects are permanently in place in the system. The modifications persist even in the event of a system failure.
А теперь немножко деталей, они нам понадобятся дальше.
Изоляция:
The ISO standard defines the following isolation levels, all of which are supported by the SQL Server Database Engine:
- Read uncommitted (the lowest level where transactions are isolated only enough to ensure that physically corrupt data is not read)
- Read committed (Database Engine default level)
- Repeatable read
- Serializable (the highest level, where transactions are completely isolated from one another)
[...]
- The snapshot isolation level uses row versioning to provide transaction-level read consistency. Read operations acquire no page or row locks; only SCH-S table locks are acquired. When reading rows modified by another transaction, they retrieve the version of the row that existed when the transaction started.
Персистентность:
COMMIT TRANSACTION
A Commit log record is generated. The log records associated with the transaction (and all previous log records) must be written to stable storage. The transaction is not considered committed until the log records are correctly flushed to stable media. (Log is hardened.)
(там же есть вся необходимая информация про Forced Unit Access)
Альтернативное описание (не из официального источника, но это сотрудник MS):
A COMMIT does the following
- adds a new log record describing the COMMIT to the log, in memory
- all log records not flushed to disk, up to and including the one generated above, are flushed (written to disk)
- thread blocks waits until the OS reports the above write as durable (IO completes)
- COMMIT statement (or DML statement with implicit commit) completes
По моим тестам скорость у глобалов примерно в 2 раза замедляется в транкзационном режиме.
С какими именно гарантиями (хотя бы в части изоляции и персистентности)? Обратите внимание, что гарантии, предоставляемые MS, озвучены вполне явно.
А теперь переходим к вашему следующему комменту.
GT.M transaction processing provides the first three [Atomicity, Consistency, Isolation] through the use of the TStart and TCommit commands. Durability is provided through the use of journaling.
Во-первых, обратите внимание на разделение: ACI предоставляются через
TStart/TCommit, D предоставляется через журналирование. Спрашивается, как это понимать? Здравый смысл говорит нам, что, наверное, это означает, что если включить журналирование, то в момент TCommit журнал будет сбрасываться (а если не включить, то транзакция будет ACI, без D). В принципе, вот здесь написано: «By default, when a process commits a transaction, it does not return control to the application code until the transaction has reached the journal file», что подтверждает мое предположение, поэтому давайте, for the sake of argument, считать, что это так, и что при включенном журналировании D-компонента ACID в GT.M семантически эквивалентна D-компоненте ACID в MS SQL (и давайте закроем глаза на
TRANSACTIONID="BATCH").Теперь более занятный вопрос: а какую же изоляцию предоставляет GT.M внутри транзакции?
Пойдем в уже упомянутуе выше документацию:
optimistic concurrency control. Each block has a transaction number that GT.M sets to the current database transaction number when updating a block. [...] Once inside a transaction, a GT.M process tracks each database block that it reads [...] and in process private memory keeps a list of updates that it intends to apply — application logic within the process views the database with the updates; application logic in other processes does not see states internal to the transaction. At TCOMMIT time, the process checks whether any blocks have changed since it read them, and if none have changed, it commits the transaction, [...] If one or more blocks have changed, the process reverts its state to the TSTART and re-executes the application code for the transaction.
Ага. Выглядит как снепшот, но, большое «но»: что произойдет, если нетранзакционный код за пределами транзакции изменит значение, которое уже было прочитано кодом внутри транзакции? При повторном чтении оно будет старым или новым? А если удалить?
(Я, заметим не говорю о том, сработает ли механизм версионного контроля в таких случаях — скорее всего, сработает. Меня интересует именно повторяемость чтений внутри транзакции.)
Интересная информация от сотрудника MS.
О гарантиях Durability. Их нет вообще. То есть нет указаний на то, в скольких процентах случаев при последующем отключении питания данные сохранятся. Нет указания на материальные компенсации при потерях данных и их условиях. Озвучены не гарантии, а последовательность действий базы при коммите.
А если реальных гарантий нет вообще, то как можно утверждать, что база честная? Код-то закрытый. Доказать честность можно только через массовые power-fail тесты с проверкой файлов БД на последующее чтение. Но их никто не проводил.
Отвечаю на вопрос. Специально протестировал данную конфигурацию, когда нетранзакционный код меняет данные в параллельном потоке. В транзакции изменения не видны.
Если нетранзакционный код удаляет глобал, то в транзакции глобал существует. Тоже протестировал.
О гарантиях Durability. Их нет вообще. То есть нет указаний на то, в скольких процентах случаев при последующем отключении питания данные сохранятся. Нет указания на материальные компенсации при потерях данных и их условиях. Озвучены не гарантии, а последовательность действий базы при коммите.
А если реальных гарантий нет вообще, то как можно утверждать, что база честная? Код-то закрытый. Доказать честность можно только через массовые power-fail тесты с проверкой файлов БД на последующее чтение. Но их никто не проводил.
Отвечаю на вопрос. Специально протестировал данную конфигурацию, когда нетранзакционный код меняет данные в параллельном потоке. В транзакции изменения не видны.
Если нетранзакционный код удаляет глобал, то в транзакции глобал существует. Тоже протестировал.
То есть нет указаний на то, в скольких процентах случаев при последующем отключении питания данные сохранятся. Нет указания на материальные компенсации при потерях данных и их условиях.
А это вы получите только если будете заключать контракт, причем не на покупку ПО.
А если реальных гарантий нет вообще, то как можно утверждать, что база честная?
На основании утверждений поставщика. Здесь мы с вами на равных — публично доступная (не контрактная) документация всех обсуждаемых систем приблизительно одинакова.
Специально протестировал данную конфигурацию, когда нетранзакционный код меняет данные в параллельном потоке. В транзакции изменения не видны. Если нетранзакционный код удаляет глобал, то в транзакции глобал существует. Тоже протестировал.
Значит, в этой реализации при выставленных вами настройках изоляция семантически эквивалентна снепшоту. Ура.
The four key properties of transaction processing systems, the so called «ACID» properties are: Atomicity, Consistency, Isolation, and Durability.
GT.M transaction processing provides the first three through the use of the TStart and TCommit commands. Durability is provided through the use of journaling.
В статье и комментариях умоминались несколько СУБД на глобалах, как минимум: GT.M, GlobalsDB, Caché. Хотелось бы понять следующее:
- Какие из СУБД на глобалах обеспечат мне наилучшую производительность при выполнении ACID транзакций в несколько потоков?
- Содержат ли лицензии этих СУБД ограничения на публикацию бенчмарков, сравнений с другими СУБД?
Наилучшую производительность получите в Caché в самых последних версиях, насчет многопоточных транзакций непонял. Изменения в рамках одной транзакции могут быть выполнены только в одном потоке, каждый поток должен работать со своей транзакцией.
Таких ограничений нету, а смысл, порой довольно сложно правильно сравнить разные СУБД.
Таких ограничений нету, а смысл, порой довольно сложно правильно сравнить разные СУБД.
Спасибо! Я имел ввиду много потоков, которые параллельно выполняют транзакции, каждый – свою. У Caché trial license на 12 процессов, насколько я понял. Но для того, чтобы нагрузить небольшой сервер этого может быть достаточно.
Смысла сравнивать разные СУБД, как всегда, особого нет. Разве что такой :)

Смысла сравнивать разные СУБД, как всегда, особого нет. Разве что такой :)
Версия без лицензий, имеет ограничение в одну лиценизию, а вот в рамках одной лицензии есть возможность создать до 25 процессов (12 это было раньше). Только вот, одна лицензия может расходоваться как на подключение студией, терминалом, так и запуск веб приложения. По поводу лицензий, насколько я знаю InterSystems охотно выдает временные лицензии, а так же есть различные программы, при которых можно получить лицензию и даже выделенный сервер с установленным Caché и лицензией.
Глобалы — мечи-кладенцы для хранения данных. Деревья. Часть 1