ИДЕЯ
Идея проекта — попробовать реализовать базовые функции MongoDB API для поиска, сохранения, обновления и удаления документов так, чтобы можно было бы не меняя клиентский код вместо MongoDB использовать InterSystems Caché.
МОТИВАЦИЯ
Возможно, если взять интерфейс MongoDB и в качестве хранилища данных использовать InterSystems Caché, то можно получить некоторый выигрыш в производительности.
Ну, а почему бы и нет?! ¯\_(ツ)_/¯
ОГРАНИЧЕНИЯ
В рамках исследовательского проекта было сделано несколько упрощений:
— используются только примитивные типы данных:
— null, boolean, number, string, array, object, ObjectId;
— клиентский код работает с MongoDB посредством MongoDB драйвера;
— клиентский код использует MongoDB Node.js driver;
— клиентский код использует только базовые функции MongoDB API:
— find, findOne — поиск документов;
— save, insert — сохранение документов;
— update — обновление документов;
— remove — удаление документов;
— count — подсчет документов.
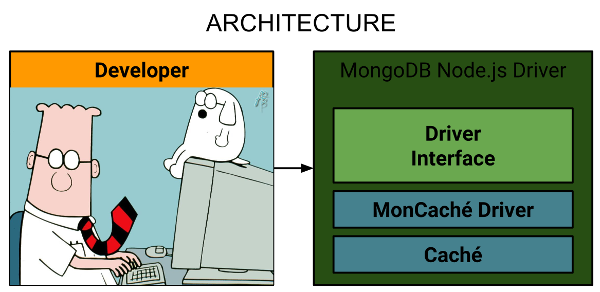
РЕАЛИЗАЦИЯ
В итоге задача разбилась на следующие подзадачи:
— воспроизвести интерфейс MongoDB Node.js driver по выбранным базовым функциям;
— реализовать этот интерфейс, используя в качестве хранилища данных — InterSystems Caché:
— разработать схему представления базы данных в Caché;
— разработать схему представления коллекций в Caché;
— разработать схему представления документов в Caché;
— разработать схему взаимодействия с Caché, используя Node.js;
— реализовать разработанные схемы и немножко потестить. :)
ДЕТАЛИ РЕАЛИЗАЦИИ
С первой подзадачей никаких особых трудностей не было, поэтому перейду сразу к подзадаче реализации интерфейса.
MongoDB определяет базу данных как физический контейнер для коллекций. А коллекцию как набор документов. И, наконец, документ, как набор данных. Документ подобен JSON документу, но с большим количеством допустимых типов — BSON.
В InterSystems Caché все данные хранятся в глобалах. Упрощенно, можно думать о глобалах как о иерархических структурах данных.
В этом проекте все данные будут храниться в одном глобале — ^MonCache.
Таким образом, требуется разработать схему представления базы данных, коллекций и документов, используя иерархические структуры данных.
Схема представления базы данных в Caché
В MongoDB на одном инстансе может быть несколько баз данных, а значит требуется разработать такую схему представления, которая позволит хранить несколько баз данных, которые были бы изолированы друг от друга. Важно также отметить, что MongoDB поддерживает базы данных не содержащие коллекций (далее «пустые» базы данных).
Я выбрал самый простой и очевидный способ решения поставленной задачи. Базы данных представляются узлом первого уровня в глобале ^MonCache. Кроме этого такому узлу приписывается значение "", для того, чтобы реализовать поддержку «пустых» баз данных. Всё дело в том, что если этого не делать и просто добавлять дочерние узлы, то как только все дочерние узлы будут удалены, родительский узел также будет удален (особенности глобалов).
Итого, каждая база данных представляется в Caché в следующем виде:
^MonCache(<db>) = ""
Например, представление базы данных «my_database» будет таким:
^MonCache("my_database") = ""
Схема представления коллекций в Caché
MongoDB определяет коллекцию как элемент базы данных. Все коллекции в одной базе данных имеют уникальное имя, а значит имя может использоваться для однозначной идентификации коллекции. Этот факт позволил мне найти простой способ представления коллекций в глобале, а именно использовать узлы второго уровня. Теперь нужно решить две небольшие задачи. Первая, заключается в том, что подобно базам данных, коллекции тоже могут быть пустыми. Вторая, заключается в том, что коллекция — это набор документов. И все документы должны быть изолированы друг от друга. Честно скажу, мне не пришло в голову ничего лучше чем хранить счетчик, что-то типа автоинкрементного значения, в качестве значения узла коллекции. Все документы имеют свой уникальный номер. При вставке нового документа в коллекцию, создается узел с именем равным текущему значению счетчика, а после этого значение счетчика увеличивается на 1.
Итого, каждая коллекция представляется в Caché в следующем виде:
^MonCache(<db>) = ""
^MonCache(<db>, <collection>) = 0
Например, представление коллекции «my_collection» в базе данных «my_database» будет таким:
^MonCache("my_database") = ""
^MonCache("my_database", "my_collection") = 0
Схема представления документов в Caché
Документ, в этом проекте, это JSON документ, расширенный дополнительным типом — ObjectId. Нужно было разработать схему представления документов на иерархических структурах данных. Здесь меня ждало несколько сюрпризов. Во-первых, нет возможности использовать «родной» null в Caché, так как Caché не поддерживает null. Второй интересный момент в том, что boolean значения реализованы константами 0 и 1. Т.е., грубо говоря, true — 1, false — 0. Самым ожидаемым проблемным моментом стало то, что нужно придумать как хранить ObjectId. В общем, все эти проблемы были успешно решены в самой, как мне казалось, простой форме. Далее, я рассмотрю каждый тип данных и его представление.
Схемы представления
Для более лаконичной записи я буду использовать специальное обозначение — @.
Вместо ^MonCache(<db>,<collection>,<document id>, ...) я буду просто писать
@(...).
Пусть есть поле f типа «null».
Определим для него следующее представление:
Пусть есть поле f типа «boolean» (значение true).
Определим для него следующее представление:
Пусть есть поле f типа «boolean» (значение false).
Определим для него следующее представление:
Пусть есть поле f типа «number».
Определим для него следующее представление:
Пусть есть поле f типа «string».
Определим для него следующее представление:
Пусть есть поле f типа «ObjectId».
Определим для него следующее представление:
Осталось два типа: «object» и «array». По своей сути эти типы являются «контейнерами» для значений более «простых» типов. Поэтому можно просто рекурсивно применить уже описанные правила и получить представления для элементов этих контейнеров. Единственный тонкий момент — нужно придумать способ сохранения порядка элементов в контейнере типа «array». Это решается тривиально — все элементы нумеруются в порядке обхода, и в том же порядке производится представление.
Пусть есть поле f типа «object» (пустой).
Определим для него следующее представление:
Пусть есть поле f типа «object».
Определим для него следующее представление:
Пусть есть поле f типа «array» (пустой).
Определим для него следующее представление:
Пусть есть поле f типа «array».
Определим для него следующее представление:
Вместо ^MonCache(<db>,<collection>,<document id>, ...) я буду просто писать
@(...).
Пусть есть поле f типа «null».
f: nullОпределим для него следующее представление:
@("f", "t") = "null"
Пусть есть поле f типа «boolean» (значение true).
f: trueОпределим для него следующее представление:
@("f", "t") = "boolean"
@("f", "v") = 1
Пусть есть поле f типа «boolean» (значение false).
f: falseОпределим для него следующее представление:
@("f", "t") = "boolean"
@("f", "v") = 0
Пусть есть поле f типа «number».
f: 3.14Определим для него следующее представление:
@("f", "t") = "number"
@("f", "v") = 3.14
Пусть есть поле f типа «string».
f: 'Habrahabr.ru'Определим для него следующее представление:
@("f", "t") = "string"
@("f", "v") = "Habrahabr.ru"
Пусть есть поле f типа «ObjectId».
f: ObjectId('56b43c20af9c4f3fe2cc2908')Определим для него следующее представление:
@("f", "t") = "objectid"
@("f", "v") = "56b43c20af9c4f3fe2cc2908"
Осталось два типа: «object» и «array». По своей сути эти типы являются «контейнерами» для значений более «простых» типов. Поэтому можно просто рекурсивно применить уже описанные правила и получить представления для элементов этих контейнеров. Единственный тонкий момент — нужно придумать способ сохранения порядка элементов в контейнере типа «array». Это решается тривиально — все элементы нумеруются в порядке обхода, и в том же порядке производится представление.
Пусть есть поле f типа «object» (пустой).
f: {}Определим для него следующее представление:
@("f", "t") = "object"
Пусть есть поле f типа «object».
f: { site: 'Habrahabr.ru', topic: 276391 }Определим для него следующее представление:
@("f", "t") = "object"
@("f", "v", "site", "t") = "string"
@("f", "v", "site", "v") = "Habrahabr.ru"
@("f", "v", "topic", "t") = "number"
@("f", "v", "topic", "v") = 276391
Пусть есть поле f типа «array» (пустой).
f: []Определим для него следующее представление:
@("f", "t") = "array"
Пусть есть поле f типа «array».
f: [ 'Habrahabr.ru', 276391 ]Определим для него следующее представление:
@("f", "t") = "array"
@("f", "v", 0, "t") = "string"
@("f", "v", 0, "v") = "Habrahabr.ru"
@("f", "v", 1, "t") = "number"
@("f", "v", 1, "v") = 276391
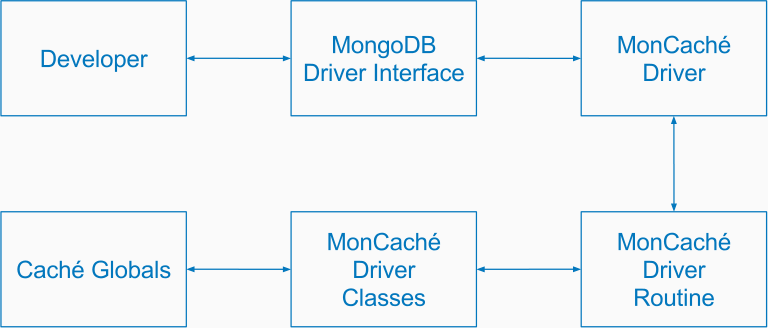
Схема взаимодействия с Caché
Логичным и простым выбором драйвера для работы с InterSystems Caché стал выбор Node.js драйвера (на сайте документации можно увидеть и другие драйверы для взаимодействия с Caché). Однако, сразу стоит отметить, что возможностей драйвера было недостаточно. Хотелось делать несколько вставок и всё это в рамках одной транзакции. Поэтому было принято решение разработать набор Caché ObjectScript классов, которые использовались для имитации MongoDB API, но на стороне Caché.
Caché Node.js драйвер не умел обращаться к классам в Caché, но зато умел делать вызовы программ в Caché. Этот факт привел к написанию небольшой программки — своеобразного мостика между драйвером и классами в Caché.
В итоге схема выглядела следующим образом:
В рамках работы над проектом был разработан специальный формат NSNJSON (Not So Normal JSON), который позволял «протаскивать» ObjectId, null, true, false через драйвер в Caché. С данным форматом можно ознакомиться на соответствующей странице на GitHub — NSNJSON. На Хабрахабр я выкладывал три статьи, посвященные этому формату:
— Усложнённый упрощённый JSON;
— JSON для любителей скобочек;
— NSNJSON. 道 (Заключительная статья).
ВОЗМОЖНОСТИ MONCACHÉ
При выполнении операции поиска документов поддерживаются следующие критерии:
— $eq — эквивалентность;
— $ne — не эквивалентно;
— $not — отрицание критерия;
— $lt — менее чем;
— $gt — более чем;
— $exists — существование.
При выполнении операции обновления документов поддерживаются следующие операторы:
— $set — установка значения;
— $inc — инкрементирование значения на заданную величину;
— $mul — умножение значения на заданную величину;
— $unset — удаление значения;
— $rename — переименование значения.
ПРИМЕР
Я взял этот код со страницы официального драйвера и немного переделал его.
var insertDocuments = function(db, callback) {
var collection = db.collection('documents');
collection.insertOne({ site: 'Habrahabr.ru', topic: 276391 }, function(err, result) {
assert.equal(err, null);
console.log("Inserted 1 document into the document collection");
callback(result);
});
}
var MongoClient = require('mongodb').MongoClient
, assert = require('assert');
var url = 'mongodb://localhost:27017/myproject';
MongoClient.connect(url, function(err, db) {
assert.equal(null, err);
console.log("Connected correctly to server");
insertDocument(db, function() {
db.close();
});
});Этот код можно легко переделать чтобы он работал с MonCaché!
Надо просто сменить драйвер!
// var MongoClient = require('mongodb').MongoClient
var MongoClient = require('moncache-driver').MongoClientПосле выполнения этого кода глобал ^MonCache будет выглядеть следующим образом:
^MonCache("myproject","documents")=1
^MonCache("myproject","documents",1,"_id","t")="objectid"
^MonCache("myproject","documents",1,"_id","v")="b18cd934860c8b26be50ba34"
^MonCache("myproject","documents",1,"site","t")="string"
^MonCache("myproject","documents",1,"site","v")="Habrahabr.ru"
^MonCache("myproject","documents",1,"topic","t")="number"
^MonCache("myproject","documents",1,"topic","v")=267391ДЕМО
Кроме всего прочего было запущено небольшое демо приложение (исходники), также реализованное на Node.js для демонстрации смены драйвера с MongoDB Node.js на MonCaché Node.js без перезапуска сервера и изменения исходного кода. Приложение представляет собой крошечную демонстрационную площадку для выполнения CRUD операций над продуктами и офисами, а также интерфейс для смены конфигурации (смены драйвера).
Сервер позволяет создавать продукты и офисы, которые сохраняются в выбранное в конфигурации хранилище (Caché или MongoDB).
Вкладка «Заказы» выводит список заказов. Записи я создал, но форму не допилил, вы можете помочь проекту (исходники).
Вы можете сменить конфигурацию зайдя на страницу «Конфигурация». На странице есть две кнопки «MongoDB» и «MonCache». Нажимая на соответствующую кнопку вы выбираете нужную вам конфигурацию. При смене конфигурации клиентское приложение переподключается к источнику данных (абстракция, отделяющая приложение от реально используемого драйвера).
ЗАКЛЮЧЕНИЕ
В заключении отвечу на главный вопрос. Да! Действительно удалось получить некоторое увеличение производительности выполнения базовых операций.
Проект MonCaché опубликован на GitHub и доступен под лицензией MIT.
КРАТКАЯ ИНСТРУКЦИЯ
- Установите Caché
- Загрузите все необходимые компоненты MonCaché в Caché
- Создайте в Caché область MONCACHE
- Создайте в Caché пользователя moncache с паролем ehcacnom
- Создайте переменную окружения MONCACHE_USERNAME = moncache
- Создайте переменную окружения MONCACHE_PASSWORD = ehcacnom
- Создайте переменную окружения MONCACHE_NAMESPACE = MONCACHE
- Измените в вашем проекте зависимость от 'mongodb' на 'moncache-driver'
- Запускайте ваш проект! :-)
АКАДЕМИЧЕСКАЯ ПРОГРАММА INTERSYSTEMS
Если вам интересно реализовать собственный исследовательский проект на технологиях InterSystems, то вы можете посетить специализированный сайт, посвященный академическим программам InterSystems.
