Эта статья — переработанная версия доклада Отказоустойчивая работа с Redis с прошедшего 17 октября 2020 митапа PHP-разработчиков Йошкар-Олы.
Мы поговорим о подводных камнях использования Redis в системе, где важна отказоустойчивость — на примере хранения сессий в условном веб-сервисе, написанном на PHP, но многие замечания будут справедливы и для других платформ — например для микросервисов на Go. Статья будет полезна, если вы проектируете микросервисы или монолитные приложения с достаточно большой нагрузкой и интенсивно работаете с Redis либо столкнулись с потребностью в перепроектировании механизмов аутентификации и сессий.
Немного о Redis
Redis — это NoSQL СУБД с открытым исходным кодом, работающая с данными вида «ключ — значение». Если вы захотите узнать о преимуществах Redis, вы наверняка найдёте примерно такой список:
Redis хранит все данные в оперативной памяти, что повышает производительность
В Redis нет SQL и схемы хранилища, что опять же повышает производительность (нет интерпретатора SQL) и даёт гибкость
Нет никаких ACID транзакций, изменения просто сохраняются на диск в фоне, что тоже повышает производительность
см. Redis Persistence в документации
Иначе говоря, Redis может быть очень быстрым.
Но давайте взглянем на это с точки зрения надёжности и отказоустойчивости:
Redis хранит все данные в оперативной памяти, и при аварийном завершении процесса или выключении машины данные будут потеряны
Redis не ориентирован на ACID транзакции, и на практике значит:
даже при включённом сохранении на диск данные могут быть потеряны частично либо полностью
в данных может быть нарушена целостность с точки зрения приложения
фоновое сохранение данных на диск может нанести ущерб производительности и отказоустойчивости
Значит ли это, что Redis плох? Вовсе нет. Наша статья о том, что при внедрении Redis в проект нужно рассматривать разные варианты и принимать взвешенные решения, а не верить слепо, что всё уже предусмотрено умными дядьками и никаких проблем на production не возникнет.
Теперь поговорим про это подробнее.
Сценарии отказа Redis
Допустим, мы используем классический метод развёртывания веб-приложений, и у нас есть две машины — на одной развёрнуто PHP приложение, на другой — Redis.
Обычно в PHP приложении на каждый HTTP-запрос создаётся новый контекст PHP-интерпретатора, со своей памятью и ресурсами. Чтобы обратиться к Redis (например, для чтения/записи данных сессии), приложению придётся установить соединение с Redis, а потом отправить одну или несколько команд — например, SETEX key, value, ttl. С точки зрения Redis, есть 4 этапа обработки первой полученной команды:
Приём соединения
Приём команды
Ожидание в очереди
Обработка команды

Из этих шагов только последний работает с той фантастической скоростью, которую обещают разработчики Redis. Все остальные могут вызывать проблемы.
Во-первых, Redis может упасть:

В этом случае приложение попытается установить соединение, но не сможет (сразу либо после произвольного таймаута, установленного для библиотеки Predis). Будет создано исключение, к которому код может быть не готов.
Во-вторых, может нарушиться сетевая связность:
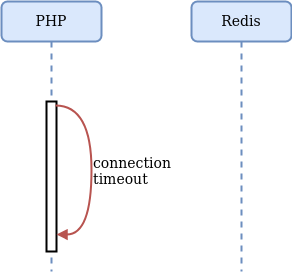
В этом случае бесполезное ожидание и отказ по таймауту неизбежны, что может привести к веерным отказам: сначала бесполезные таймауты под нагрузкой приведут к повышению числа активных процессов php-fpm и числа соединений с СУБД, а потом закончится либо одно, либо другое, клиенты начнут получать 500-е и 504-е коды ошибок — сервис перестанет их обслуживать.
В-третьих, под высокой нагрузкой Redis может не успеть обработать полученную команду:
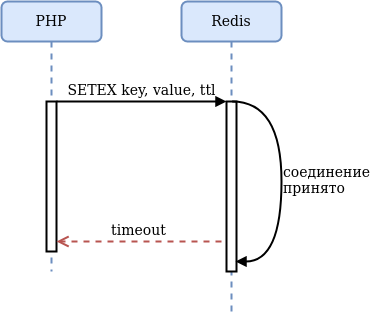
С точки зрения приложения произойдёт отказ по таймауту, с рисками веерного отказа. Что ещё хуже, веерные отказы могут произойти и без явных отказов Redis: приложение просто будет ждать дольше обычного и исчерпаются соединения с СУБД либо процессы php-fpm.
Наконец, у Redis может кончиться память, и тогда всё зависит от настроек maxmemory и maxmemory-policy. По умолчанию maxmemory-policy имеет значение noeviction, и это означает, что при нехватке памяти Redis перейдёт в режим readonly:
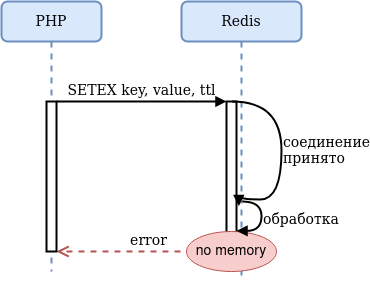
Даже если поменять maxmemory-policy, вы можете получить ситуацию, когда при нехватке памяти Redis выкидывает ключи, значительно сокращая время жизни сессий, токенов и других полезных данных. Будет ли ваше приложение работать нормально, если контракт на время жизни данных не выполняется?
Сценарии отказа Redis в Kubernetes
Давайте сгустим краски ещё больше: добавим Kubernetes и засунем в него Redis.
Kubernetes — это система управления кластером. Он запускает N приложений в контейнерах на меньшем числе машин, распределяя нагрузку такими сложными путями, что для сопровождения проекта в Kubernetes вам потребуется отдельная команда (если у вас всё кросс-функциональное, тогда её размажет ровным слоем по остальным командам).
Допустим, у нас есть кластер из 4 worker'ов, управляемых Kubernetes. Допустим, Kubernetes раскидал экземпляры PHP-приложения и Redis так, как показано на картинке:
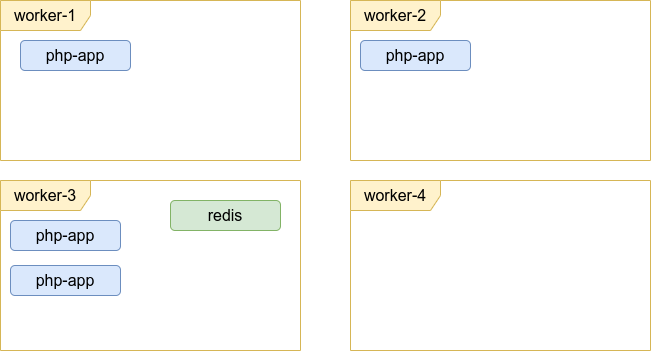
После этого worker #3 вывели на обслуживание, в результате мы теряем единственный экземпляр Redis и 2 из 4 экземпляров приложения и получаем кратковременный отказ. Если Redis прислал свои данные не на сетевой диск, то получаем ещё и потерю всех его данных. Если же он писал на сетевой диск, то делал это медленно, поскрипывая винчестерами на весь дата-центр и мешая дежурным спать.
Как бы развернуть Redis, чтобы потеря одной worker-машины не создавала проблем?
У Redis предусмотрено два способа организации отказоустойчивости: Redis Sentinel и Redis Cluster. Прочитав документацию и собрав факты, вы увидите следующее:
Обе реализации являются скорее кирпичиками для построения отказоустойчивости с автоматическим failover
Redis Cluster имеет некоторую автоматизацию, но эта разница нивелируется в Kubernetes за счёт Redis Operator (например, spotahome/redis-operator), который основан на Redis Sentinel
Redis Cluster даёт шардирование, Redis Sentinel его не даст
Если вы хотите производительность выше той космической, что можно выжать из одного инстанса, подумайте о Redis Cluster вне Kubernetes. Если вы хотите засунуть Redis в Kuberntes, используйте Redis + Sentinel + Redis Operator.
Отказоустойчивость Sentinel и Cluster имеет свою цену:
Оба варианта меняют протокол взаимодействия с Redis, и клиент должен поддерживать новый вариант
Как минимум 3 экземпляра Redis Sentinel нужно, чтобы достигнуть кворума при выборке master
Сам Redis Sentinel нового мастера не назначит, его надо попросить, что и делает Redis Operator
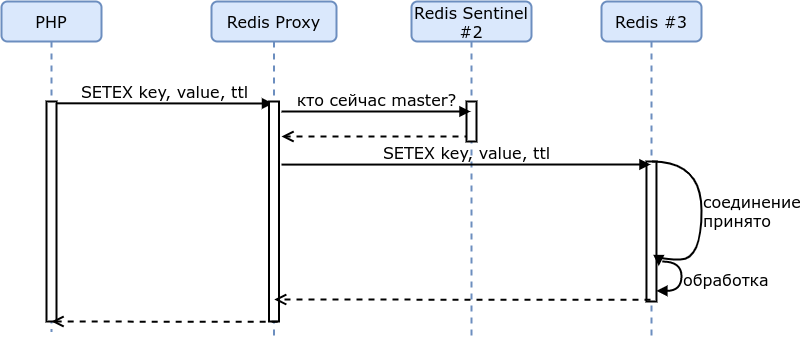
Взаимодействие PHP-приложения с Redis Sentinel показано на схеме:

Сначала приложение обращается к Redis Sentinel и узнаёт, какой из экземпляров Redis является мастером. Затем приложение обращается к нужному экземпляру Redis.
Допустим, в нашем кластере распределено 3 redis и 3 redis-sentinel, причём redis master и один из sentinel оказались на одной машине #3:

После этого worker #3 вывели на обслуживание, в результате мы теряем redis master и один из redis-sentinel. Пока redis-sentinel не перезапустится на другой машине, а redis operator не попросит всех троих выбрать нового master, redis останется недоступен (по крайней мере на запись).
Чтобы PHP-приложение (или, например, NGINX/Lua) не обращалось к redis-sentinel на каждый запрос, можно ввести ещё одного игрока: redis-proxy (например, ifwe/twemproxy). Этот proxy является stateless, он может быть запущен внутри контейнера PHP-приложения либо как sidecar-контейнер, чтобы минимизировать задержки сети.
Взаимодействие PHP-приложения с Redis Proxy показано на схеме:
Возможен ещё один вариант отказа из статьи Одна история с оператором Redis в K8s и мини-обзор утилит для анализа данных этой БД
Worker, на котором находится redis master, выводится на обслуживание
Запускается новый redis
Посовещавшись, тройка redis sentinel выбирает новый redis мастером
Новый и абсолютно пустой redis в роли мастера просит реплики удалить все данные
Баг, приводящий к такому сценарию, исправили в spotahome/redis-operator, но кто даст гарантию, что это был последний баг?
Избежать проблемы можно путём добавления сетевого диска — например, NFS. Тогда NFS станет ещё одной точкой отказа.
Так что же делать?
Если вы на этапе проектирования, подумайте:
Так ли вам нужен Redis в этом классе/модуле/сервисе? избегайте хранения в Redis важных данные или данных, требующих контроля целостности
Так ли вам нужен Redis в Kubernetes, или подойдёт Redis на отдельной машине?
В целом стоит насторожиться, когда кто-то предлагает засунуть хранилища данных в Kubernetes. Если это предлагает коллега, расскажите ему анекдот про мужика, сено и скафандр.
Вы можете столкнутся с несколькими доводами в пользу применения Redis:
В проекте уже используют Redis
возражение: важно понимать, для чего именно использован Redis и на какие компромиссы при этом согласились
Данные имеют time to life
возражение: это не мешает хранить их в SQL СУБД
Redis быстрее SQL СУБД
возражение: перегруженный redis работает медленее, кроме того, взаимодействие с двумя хранилищами вместо одного добавляет сетевые задержки и точки отказа
Достойная причина использовать Redis — высокие нагрузки и данные, которые не так страшно потерять.
Как улучшить отказоустойчивость
Сложная система порождает новые сценарии катастроф. Что ещё хуже, вы не можете заранее предсказать все риски. Но можно практиковать избыточность, нагрузочное тестирование и тестирование тех сценариев отказа, которые вы можете предсказать.
Избыточность может проявляться по-разному:
В дополнительных сущностях: redis-sentinel, redis-operator, redis-proxy
В распределении redis по разным машинам или даже разным дата-центрам
В дополнительной отказоустойчивости со стороны приложения, а не инфраструктуры
Последний пункт почти не упоминается в статьях об отказоустойчивом Redis, а мы поговорим об этом подробнее.
Делаем кэширование необязательным
Допустим, наше приложение на PHP использует Redis как кэш. В таком случае мы должны:
При записи сохранять данные и в Redis, и в основную БД
При чтении читать сначала из Redis, а при ошибке — читать из БД
Сохранить небольшой timeout для клиента Redis — например, 100 или 300 миллисекунд
Рассмотрим схему классов для хранения данных сессии:
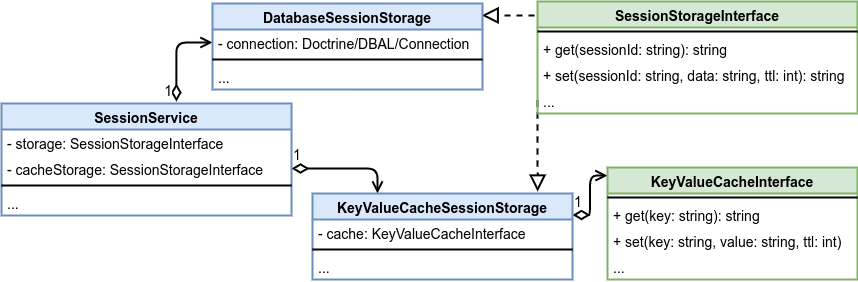
Интерфейс
KeyValueCacheInterfaceобъявляет обобщённый API для работы с кэшем, за которым скрыт RedisИнтерфейс
SessionStorageInterfaceобъявляет хранилище данных сессииреализация
DatabaseSessionStorageхранит сессии в таблице в БДреализация
KeyValueCacheSessionStorageхранит сессии в кэше
SessionServiceиспользует оба варианта хранилища, но работает с ними по-разному
При чтении данных в SessionService сначала пытаемся читать из Redis, в случае ошибки — читаем из БД:
private function doRead(callable $job)
{
try
{
return $job($this->cacheStorage);
}
catch (KeyValueCacheNotAvailableException $e)
{
$this->loggerService->error(
'failed to read from session cache',
['exception' => $e]
);
return $job($this->storage);
}
}
Для обновления данных записываем и Redis, и в БД:
private function doUpdate(callable $job): void
{
try
{
$job($this->cacheStorage);
}
catch (KeyValueCacheNotAvailableException $e)
{
$this->loggerService->error(
'failed to write into session cache',
['exception' => $e]
);
}
$job($this->storage);
}
Такое решение имеет свои ограничения:
Возрастёт нагрузка на БД — в сравнении с хранением данных только в Redis
После отказа и восстановления кэша в нём появляются неактуальные данные, записанные в БД в период отказа
Усовершенствование в хранении сессий
На примере всё тех же сессий посмотрим, как можно усовершенствовать механизм отказоустойчивости.
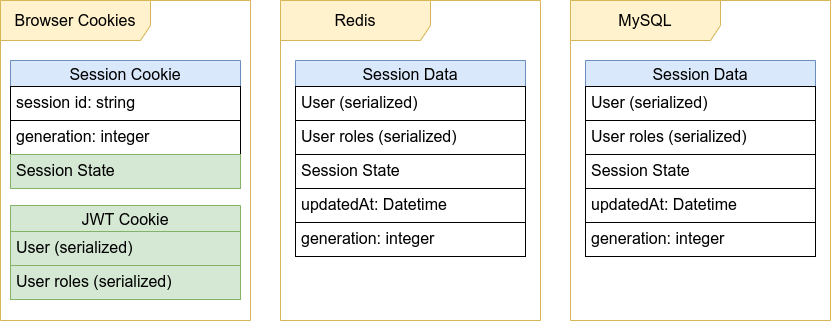
Допустим, у нас есть сессии, которые хранятся в трёх хранилищах: session id хранится в Cookie, а данные сессии хранятся одновременно и в Redis, и в MySQL:
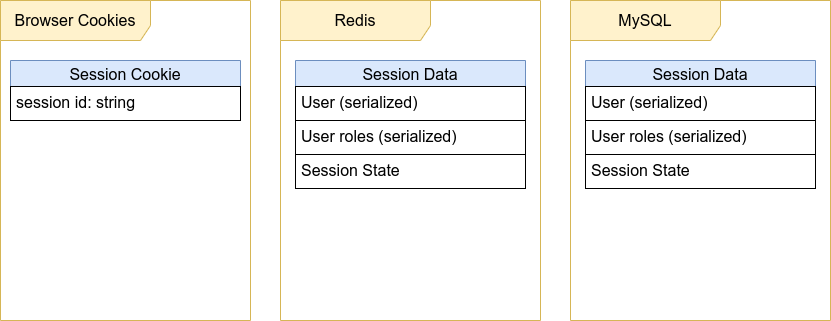
Сессию надо периодически обновлять, чтобы при активном использовании TTL (time to life) не истёк и сессия не закончилась. Чтобы уменьшить частоту обновления сессий, мы можем добавить в данные сессии дату последнего обновления, и обновлять сессию в обработчике запроса только в том случае, если с последнего обновления прошло больше определённого числа секунд (например, 60 секунд).
Кстати, именно так ведут себя современные PHP фреймворки — например, Symfony.
Обновлённое расположение данных будет выглядеть так:
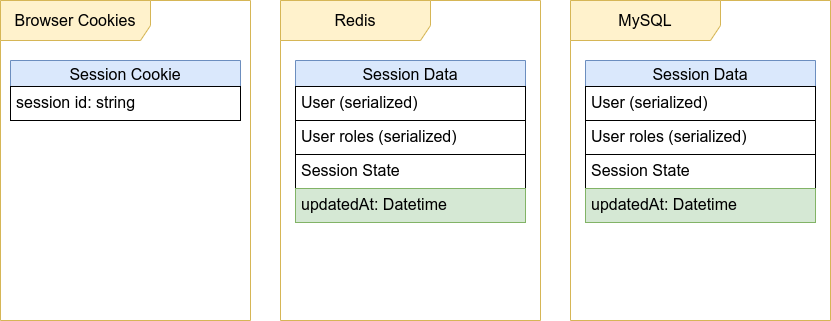
Чтобы решить проблему инвалидации кэша при его недоступности, мы можем добавить в Cookie ещё одно значение: целочисленный generation number данных сессии, который увеличивается на единицу при каждом изменении данных сессии, и предпочитать чтение данных из БД в случае, если generation number в Redis не совпадает с тем, что пришёл из Cookie:

Сессии в Signed Cookies
Идею хранения данных в Cookie можно развить, но для этого надо сделать Cookie надёжным хранилищем, в котором нельзя подменить данные. Этого можно достигнуть с помощью Signed Cookies — например, можно в качестве значения хранить JWT (JSON Web Token). В этом случае:
Секретный ключ для подписи JWT хранится на сервере, и пользователь не может подменить содержимое Cookie, не нарушив целостность подписи JWT.
Секретные данные в Signed Cookie хранить по-прежнему нельзя, т.к. полезная нагрузка в JWT хранится в открытом виде
С таким подходом основные данные сессии можно переместить в Cookie небольшого размера (не более 1-2 КБ), и до истечения JWT вообще не обращаться к Redis и MySQL. Короткое время жизни такой Cookie обеспечит баланс между временем инвалидации данных и снижением нагрузки на сервера.
Состояние сессии, влияющее только на просмотр, можно хранить в открытом виде в Cookie, а можно точно так же поместить в JWT.
После этих изменений схема расположения данных выглядит, как показано ниже. Можно убрать из схемы Redis, поскольку Signed Cookie снизит число обращений к данным сессии на сервере.
Подытожим
Отказоустойчивости в работе с Redis или с любым другим вспомогательным хранилищем можно достигнуть не только за счёт схемы развёртывания и инфраструктуры, но и за счёт пересмотра архитектуры или доработок приложения, обеспечивающих устойчивость к отказам.
Чтобы это сработало, надо:
Учесть разные сценарии отказа Redis, в том числе связанные с превышением таймаутов, превышением лимита памяти или сетевых соединений
Пересмотреть архитектуру и реализацию системы с точки зрения взаимодействия с Redis
Решить, куда вносить доработки: в схему развёртывания, в реализацию взаимодействия с Redis или даже в архитектуру хранения данных
Для большей устойчивости к отказам и нагрузкам потребуется применить все три метода
Кроме того, стоит решить, будет ли использование Redis, memcached или иного быстрого хранилища уместным:
Возможно, требования по нагрузке и отказоустойчивости позволяют не усложнять и хранить всё, включая сессии, в основной БД
Возможно, идея использовать Redis пришла из-за того, что данные временные; в этом случае данные можно так же хранить в БД, не забывая:
Добавить в таблицу и во все связанные SQL-запросы колонку expiration date
Реализовать механизм очистки старых данных фоновыми задачами, запускаемыми через cron или CronJob (в Kubernetes), например, каждую ночь
В микросервисной архитектуре можно выделить работу с сессиями, cookie и токенами в отдельный сервис (который также может взять на себя задачи аутентификации). В монолите можно скрыть работу с Redis за абстракцией, а в реализации этой абстракции Redis рассматривать как вспомогательный кэш, недоступность которого не приводит к отказу.
