«Собственно, б***ь, вот…», думал я, пока в телефонной трубке звучали длинные гудки. Я звонил своему боссу — не сомневаюсь, этим ясным пятничным утром он только и мечтал услышать, как его старший разработчик только что своими руками, не нарочно, удалил базу данных бэк-офиса.
Гудки напомнили мне писк больничной аппаратуры — когда монитор отмеряет последние пульсы умирающего больного. В данном случае, речь шла о моей карьере. Наконец, трубку на том конце кто-то снял. Мне оставалось уповать лишь на мудрость моего начальника. В глубине души я верил, что, выслушав меня, он произнесет какую-нибудь вдохновляющую речь, после которой я найду в себе силы всё исправить. Но он сказал: «Как это, мать твою, вообще случилось?!».
Что ж, сейчас я расскажу вам, как.

Немного контекста
Описанная история произошла несколько лет назад, я работал тогда в молодой e-commerce компании. В мои обязанности входило руководство двумя группами разработчиков, ответственных за поддержку нескольких важных инструментов для нужд бэк-офиса. Сам бэк-офис управлял потоками информации, доступной пользователям через фронтэнд приложения. Поддержку фронта при этом вели совершенно другие команды. К тому же, несмотря на свою молодость, компания уже могла похвастаться сотнями тысяч пользователей изо всех уголков мира.
Одна из моих команд занималась поддержкой основного каталога продуктов, от работы которого зависела большая часть потоков и служб, от управления информацией о продуктах до осуществления заказов. Можно сказать, это была критически важная платформа, поскольку все службы, процессы и приложения бэк-офиса так или иначе к нему обращались. Чтобы вам стало понятнее, вот упрощенная схема:
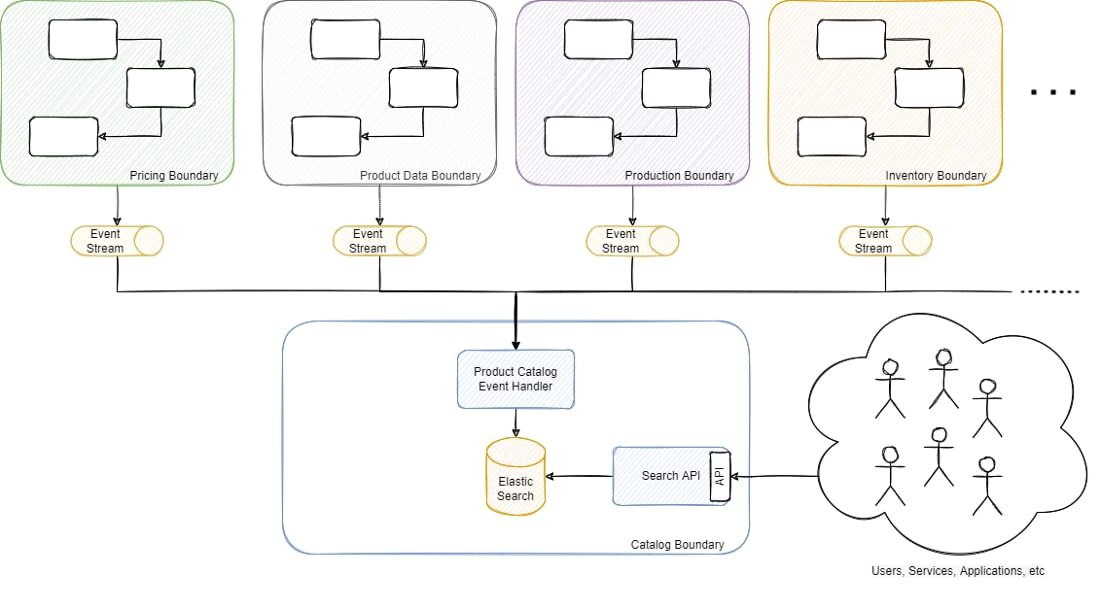
Платформа была построена на основе микросервисной архитектуры, каталог продуктов представлял собой модель для чтения с денормализованной информацией, полученной из потоков событий из нескольких разных доменов, управляемых другими микросервисами. Каталог продуктов поддерживался базой данных ElasticSearch, она хранила порядка 17 миллионов продуктов, включая метаданные, информацию о запасах, производстве, наличии, ценах и т.д., которые предоставлялись через REST API. Мы выбрали ElasticSearch в основном из-за большого разнообразия фильтров (более 50 штук, включая фильтры с поиском по тексту).
Очень краткий экскурс в ElasticSearch
Никто не имел прямого доступа на запись ни к одной базе данных, ни в одной технологии БД (мы использовали несколько технологий в зависимости от сценария использования, от SQL Server до MongoDB и Cassandra). Однако ElasticSearch был исключением, так как традиционно им управляли инженерные команды, а не Infra или DBA.
В отличие от других технологий баз данных, доступ к ElasticSearch осуществляется через REST-интерфейс. Как правило, URL-адреса имеют следующий формат (в то время мы использовали ElasticSearch версии 5):
{cluster_endpoint}/{index_name}/{type}/{document_id}
(Например: elastic.com/productIndex/product/152474145)
*В более свежих версиях type был упразднен.
Все операции с БД выполнялись через HTTP-запросы: если другие СУБД требовали написать SQL-скрипт, то ElasticSearch достаточно было HTTP-запроса. Например, следуя принципам REST, если у вас есть индекс каталога продуктов (индекс в ElasticSearch является чем-то вроде аналога SQL-таблицы), и вы хотите получить конкретный продукт, вы должны выполнить GET elastic.com/productIndex/product/152474145. Тот же эндпоинт будет использоваться для обновления этого продукта с помощью PUT или PATCH, удаления с помощью DELETE или создания с помощью POST или PUT. То же самое применимо к остальным компонентам URL: GET-запрос к elastic.com/productIndex/product поможет получить информацию о типе product. То же касается и elastic.com/productIndex — можно получить информацию об индексе, обновить или удалить ее.
Мой подвиг
Это была самая обычная пятница — как и в другие дни, мы бегали с одного совещания на другое. В мимолетных перерывах между встречами я обычно занимаюсь ситуативными задачами, например, помогаю в решении сложных вопросов или проблем, с которыми команды не справляются самостоятельно. В тот раз поступил бизнес-запрос на экспорт данных с учетом фильтров, которые не были доступны через API. Это не самая простая операция, но, учитывая срочность и важность вопроса для бизнеса, мы решили помочь.
За пятнадцать минут, которые у меня были до следующего совещания, я скооперировался с одним из старших членов команды, чтобы быстро получить доступ к среде и выполнить запрос. Поскольку прямой доступ к ElasticSearch — это, по сути, обращение к REST API, для этих целей мы использовали Postman.
Мой коллега ассистировал мне через удаленный совместный доступ к экрану. Полезная практика, которая позволяет проверять код перед выполнением операции в режиме реального времени. Сначала я хотел протестировать подключение и убедиться, что у меня правильный URL, поэтому я скопировал эндпоинт и имя индекса (что-то похожее на то, что мы обсуждали выше cluster_endpoint/index_name) и отправил GET-запрос. Если вы знакомы с интерфейсом Postman, то, возможно, помните, что HTTP-действие выбирается из выпадающего списка:

К сожалению и моему великому ужасу, сразу после отправки запроса я увидел, что вместо GET было выбрано DELETE. И вместо того, чтобы извлечь информацию об индексе, я просто удалил его.
Запрос занял всего несколько секунд, сразу подтверждения выполнения я нажал отмену. Она успешно выполнилась. Во мне забрезжил огонек надежды, совсем слабый, похожий на последний лист умирающего дерева. Возможно, я отменил запрос как раз вовремя, наивно подумал я.

Однако этот чахлый листик тут же сдуло порывом ветра рационального мышления: я понял, что запрос всё ещё продолжает выполняться на стороне сервера (в ElasticSearch) несмотря на то, что он отменён на клиенте (Postman). Я выполнил стандартный поиск без фильтров по индексу, чтобы уточнить общее количество строк. Запрос, который обычно возвращает 17 миллионов результатов, на сей раз принес только несколько сотен (сервис обрабатывает около 70 событий в секунду, эти несколько сотен были продуктами, которые создавались/редактировались в это самое время).
И вот так просто основной каталог продуктов бэк-офиса, включающий денормализованное представление 17 миллионов продуктов с информацией от десятков микросервисов со всей платформы, навеки сгинул — и унес с собой мою самооценку.
В чем нам все-таки повезло
Я позвонил своему боссу, и мы быстро организовали военный штаб, так как с каждой площадки начали поступать сообщения о проблемах. Поскольку это была, по сути, модель для чтения, она не была источником истины для какой-либо конкретной информации, поэтому нам «всего лишь» пришлось сводить информацию со всех других служб.
У нас было несколько вариантов:
ElasticSearch не имеет возможности менять схему при возникновении деструктивных изменений. По сути, вся стратегия сводится к переиндексации всей информации в новый индекс. Для обработки таких ситуаций у нас был компонент, который создавал каждый продукт с нуля, получая данные от кучи разных микросервисов через синхронные REST API. Также это помогало решить любую проблему с целостностью из-за ошибки или любого инцидента в вышестоящих сервисах. Однако на сбор всех данных по всем 17 миллионам продуктов ушло 6 дней. Так или иначе, мы сразу же приступили к работе.
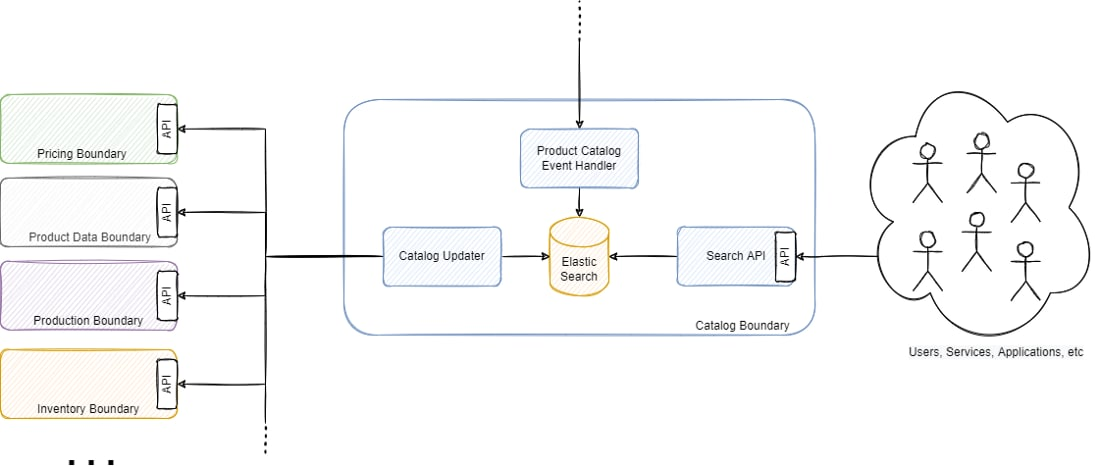
Вторым вариантом сгладить возникшую проблему было использование потоков событий. Большинство сервисов имеют функциональность для повторной публикации событий, если это необходимо, поэтому мы также попросили наиболее критичные площадки начать воспроизведение данных, которые бы применялись вместе с изменениями, сопутствующими обычному использованию.
Однако в чём нам действительно повезло, так это в том, что несколько дней назад нам пришлось сделать радикальное изменение схемы. Как я написал выше, нам потребовалось создать новую версию индекса и переиндексировать всю информацию. Длительный процесс, во время которого обе версии обновляются с учетом последних изменений. Мы дескопировали старый индекс, и новая функциональность, которой и требовалось пресловутое изменение, была не столь критична, поэтому мы просто откатились на старую версию. Данные устарели на несколько дней, но это было не так критично, как их полное отсутствие. Вкупе со всем вышеописанным, нам удалось успешно восстановить БД.
Чему мы научились
Резервные копии против скорости восстановления
Вечный спор по поводу необходимости резервного копирования разгорелся с новой силой. У нас были резервные копии большинства баз данных, кроме ElasticSearch. Кроме того, эта база данных была моделью для чтения и по определению не являлась источником истины. В теории, модели для чтения не должны иметь резервных копий, они должны оперативно перестраиваться, чтобы не вызывать проблем в случае крупного инцидента. Поскольку модели для чтения чаще всего хранят информацию, выведенную откуда-то еще, возникает вопрос, рационально ли их бэкапить с экономической точки зрения. Но на практике быстро восстановить модель и при этом не навредить бизнес-процессам весьма непросто. Если в модели хранится несколько сотен или тысяч записей, это не проблема. Однако модель с несколькими миллионами записей из десятков различных источников — совершенно другое дело.
В итоге у нас получилась некая смесь из этих двух вариантов. Мы переработали процесс восстановления до такой степени, что он сократился с 6 дней до всего нескольких часов. Однако из-за критичности компонента даже несколько часов даунтайма мы себе позволить не можем, особенно в сезоны продаж. Было несколько вариантов дальнейшего сокращения времени простоя, но по итогу мы отвергли их из-за чрезмерной сложности или дороговизны инфраструктуры. Мы приняли решение ограничиться включением резервного копирования только в самые критические периоды работы бизнеса.
Горизонтальная масштабируемость оказалась пустышкой
Одним из самых разрекламированных преимуществ наличия микросервисов является возможность горизонтального масштабирования. Часто незаметная деталь — полагаясь исключительно на синхронные API (как изображено на рисунке 4), горизонтальная масштабируемость быстро превращается в тыкву. Компонент, отвечающий за перестройку модели чтения, работал почти 6 дней, но теоретически мы могли бы кратно сократить это время, горизонтально масштабировав его. Дело в том, что для получения информации он полагался на синхронные REST API. Он запрашивал данные у каждого следующего микросервиса через REST-запросы, строил денормализованное представление и сохранял состояние. Его масштабирование вызвало бы большое количество запросов к другим сервисам, которые могли бы не справиться со значительной дополнительной нагрузкой и сами нуждались бы в масштабировании. Это вызвало бы цепную реакцию, которая в конечном итоге поставила бы под угрозу всю платформу. Добавим к этому тот факт, что большинство из них очень зависимы от баз данных, и их базы данных также нуждались бы в масштабировании.
Мы провели масштабирование, весьма скромное, однако даже тогда начались последствия в виде перегрузки других сервисов. Оглядываясь назад, можно сказать, что все это стало больше походить на монолит, чем на действительно распределенную архитектуру...
Доступ на основе ролей
Возможно, одним из самых очевидных шагов, которые мы предприняли, было внедрение ролевого управления доступом. Мы использовали старую версию ElasticSearch, которая обеспечивала лишь самую базовую аутентификацию пользователей, поэтому мы воспользовались тогда еще платной версией XPack. В более поздних версиях ElasticSearch XPack уже включен в бесплатную лицензию.
Мы всё-таки перешли на более новую версию ElasticSearch (седьмую) и реализовали разные роли для чтения и записи. В конечном итоге, только приложения должны иметь возможность регулярно писать напрямую в базу данных, пользователи могут иметь возможность (максимум) читать.
Виноваты процессы, а не люди
Я всегда повторяю своим командам, когда что-то идет не так, одну популярную пословицу. Ее смысл состоит в том, что виноваты процессы, а не люди. Мы должны понять, какая часть процесса дала сбой, и найти способы изменить ее, чтобы мы или кто-либо другой, новый сотрудник или опытный специалист, никогда больше не совершил ту же ошибку.
Это то, во что я искренне верю, и это заложено в мой стиль руководства и разбора инцидентов. Несмотря на то, что это не помешало мне ощутить себя полным идиотом, и сегодня, спустя годы после случившегося, мне до сих пор кажется, что я оправдываюсь, но в глубине души за этим стоит здравый смысл. Мы изменили способы доступа к живым данным, поскольку никто не должен был иметь прямой доступ на запись. Даже для доступа на чтение его стали избегать, так как несанкционированный запрос может оказать серьезное влияние на ресурсы, особенно в ElasticSearch, где сложные запросы (например, с высокой глубиной пагинации) могут привести к сбою кластера (например, закончится память на клиентских узлах). Это предназначено не для того, чтобы сузить автономию команд, а чтобы защитить людей от неправильных действий.
Специальные запросы передавались действующим инженерным командам, которые управляли такого рода запросами, в идеале без прямого доступа к базе данных. Ручные повторяющиеся задачи были интегрированы в функциональность соответствующих сервисов и должным образом валидированы через прикладной уровень, что предотвращало нежелательные удаления или перегруженные запросы. В целом, главный вывод — гарантировать, что у людей есть надежные и безопасные средства для выполнения своей работы и реагирования на запросы бизнеса.
Заключительное слово
Я много раз читал о подобных ситуациях, но всегда был уверен, что они никогда не произойдут со мной. «У меня есть выстроенный процесс» — наивно думал я, — «Я не отношусь к подобным действиям легкомысленно». Иногда достаточно лишь одного мгновения, доли секунды рассеянности, чтобы оставить после себя непоправимый ущерб. Я был навсегда смирен этим опытом, это поучительная история, которую я иногда рассказываю своим командам, чтобы показать, что иногда их босс тоже может совершить ужасную ошибку.
А процессы в конечном итоге существуют для того, чтобы защитить нас от нас самих и нашей неизбывной глупости.
