
Мы уже успели поговорить про сверточные операторы на графах, а теперь посмотрим на реальные архитектуры.
В этой заметке мы сравним между собой модели глубокого обучения, направленные на решение задачи семантической сегментации облака точек, и попытаемся выяснить, какие из существующих моделей наиболее пригодны для встраивания в реальную систему сканирования пространства.
Серия 3D ML на Хабре:
- Формы представления 3D данных
- Функции потерь в 3D ML
- Датасеты и фреймворки в 3D ML
- Дифференциальный рендеринг
- Сверточные операторы на графах
- Обзор алгоритмов семантической сегментации облака точек
Репозиторий на GitHub для данной серии заметок.
Заметка от партнера IT-центра МАИ и организатора магистерской программы “VR/AR & AI” — компании PHYGITALISM.
Введение
Если рассматривать обработку трехмерных данных классическими методами машинного обучения, то можно обнаружить, что в этом направлении проделана значительная работа, и для всех, кто хочет ознакомиться с примерами таких алгоритмов, мы рекомендуем обзорную статью [5]. В частности, в статье рассматриваются различные этапы препроцессинга и способы извлечения информативных признаков из ковариационной матрицы разброса ближайших соседей для каждой точки.
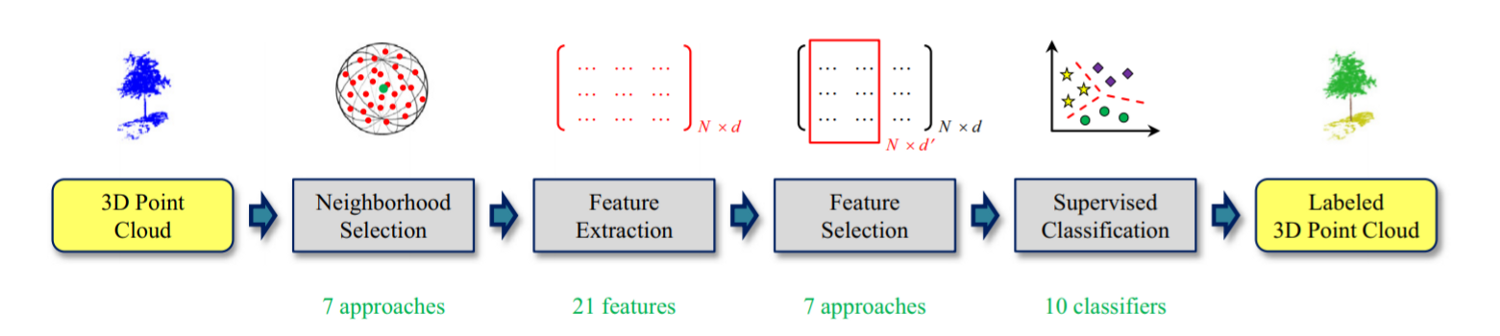
Рис. 1. Этапы извлечение признаков и классификации для облака точек [5].
Так как задача классификации 3D объектов достаточно сложная и выделение информативных признаков из 3D данных — задача крайне нетривиальная, то в качестве алгоритма классификации видится более перспективным применение глубоких нейронных сетей, которые извлекают признаки автоматически. На данный момент существующие глубокие архитектуры позволяют достичь хороших результатов в различных задачах обработки 3D данных, от классификации единичных объектов до генерации новых объектов, по их наброскам. Можно провести аналогию с тем каких успехов удалось достичь в обработке 2D изображений и видео с массовым распространением нейронных сетей. С другой стороны более традиционные методы также остаются полезными при решении некоторых задач.
Исследователями в области 3D machine learning было предложено достаточно много идей (см. обзоры [3,4]), основанных на разных базовых принципах и формах представлений объектов, для решения задачи классификации объектов в форме облака точек. Так, например, это были методы, использующие последовательность 2D изображений (снимки сцены с разных ракурсов / multi view methods), к которым применялись сверточные нейронные сети (CNN), после чего результат разметки обратно проецировался в трехмерное пространство (поэтому эти методы также называют проекционными методами анализа облаков точек).
Другим же подходом, является использование вокселей (voxel based methods) и применение операторов свёрток к ним. Однако, самым лучшим подходом видимо является использование в качестве входа для нейронной сети самого облака точек (т. н. прямой подход).
Посмотреть про актуальные задачи в области 3D ML можно на соответствующих страницах сайта paperswithcode: про задачи 3D в машинном зрении в общем, и про семантическую сегментацию облака точек в частности.
Мы собрали таблицу с разными методами и подходами, упомянутыми в обзорной работе [4], вместе со значениями метрик на разных наборах данных для оценки текущего состояния прогресса в решении задачи семантической сегментации облака точек. Ниже мы дадим краткий анализ основных подходов и их особенностей (там где нам удалось найти реализацию модели в коде, мы приложили ссылку на GitHub страницу проекта).
Кстати, на хабре на подобную тему удалось разыскать только такую заметку.
В будущем году мы актуализируем таблицу как только пройдут конференции посвященные обработке лидарных данных и компьютерному зрению.
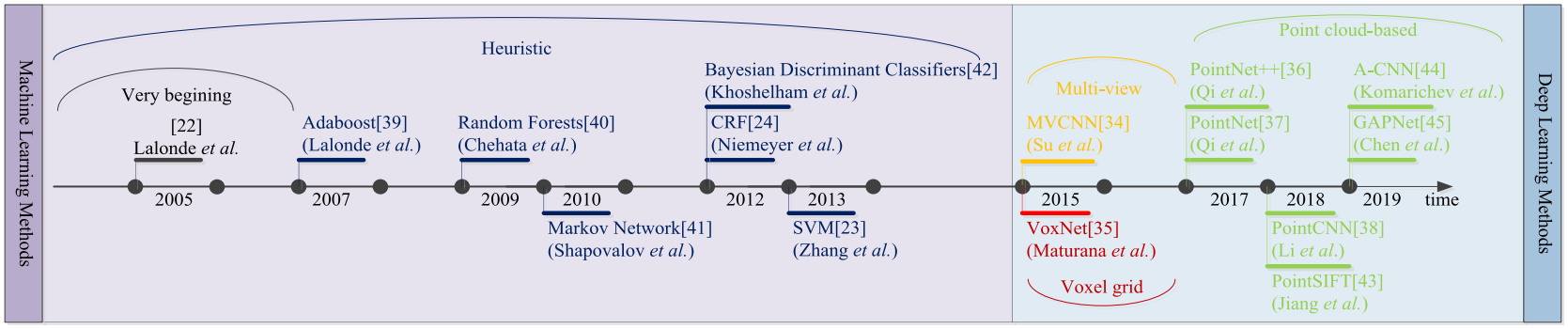
Рис. 1.1 Краткая хронология развития алгоритмов семантической сегментации облака точек из обзора [4].
Обзор моделей глубокого обучения
Архитектуры глубокого обучения, предназначенные для обработки облаков точек, можно разделить, аналогично тому как это сделано в обзоре [4], на две большие группы: прямые (direct) и непрямые (indirect). Прямые методы в качестве входных данных для нейронной сети непосредственно используют облако точек, а для использования непрямых методов, необходимо предварительно перевести облако точек в иную форму представления данных.
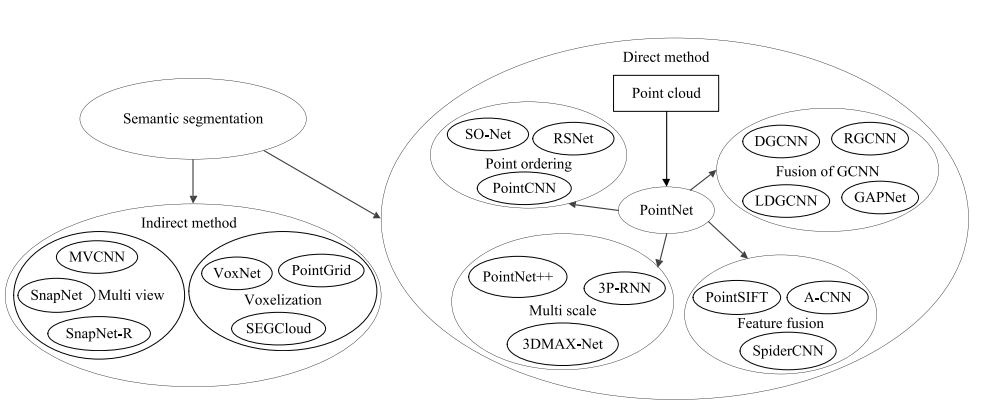
Рис. 2. Таксономия моделей глубокого обучения, предназначенных для семантической сегментации облака точек [4].
Непрямые методы
Для начала, рассмотрим непрямые методы двух видов: multi view methods и voxel based methods.
Multi-view based methods
Первая группа таких методов, основана на получении множества “снимков” (двумерных срезов) исходного облака точек с разных ракурсов (multi view methods). Такой подход, позволяет использовать всю мощь методов обработки изображений, которой обладает современное компьютерное зрение в целом, и использующиеся там модели глубокого обучения в частности.
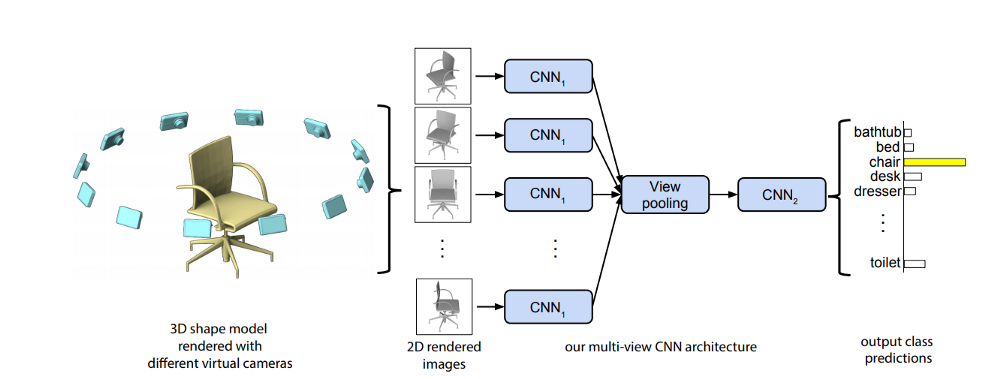
Рис. 3. Схема работы сети MVCNN [6].
Входные данные: Одно или несколько изображений (RGB) 3D объекта.
Выходные данные: Класс формы объекта.
Особенности:
- Одна из первых работ, посвященная multi-view подходу. Базируется на использовании 2D дескрипторов изображений для определения 3D характеристик.
- Сеть предназначена для классификации единичных моделей и не приспособлена под сцены или облака точек.
- В статье можно найти алгоритм настройки камер на сцене для получения двумерных срезов.
- В заметки упоминается SOTA дескрипторы для изображений векторы Фишера.
- Есть возможность приспособить сеть под другие задачи, такие как распознавание двумерных скетчей трехмерных объектов (3D visual search на основе скетч запроса).
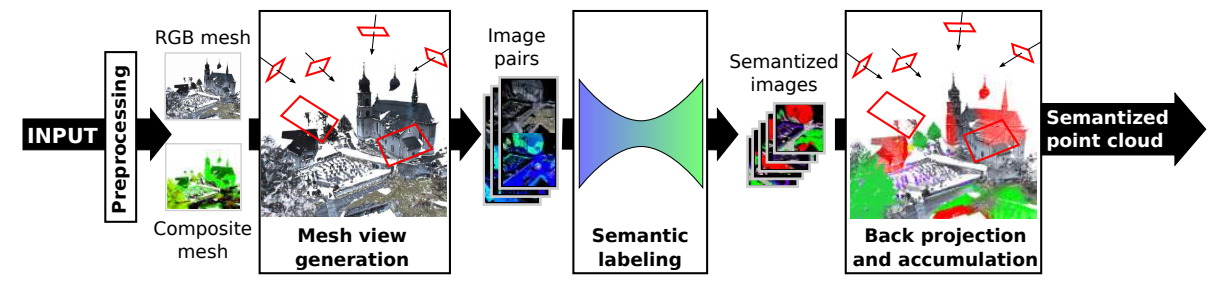
Рис.4 Схема работы сети SnapNet [7].
Входные данные: Облако точек.
Выходные данные: Семантическая разметка облака точек.
Особенности:
- В статье предложен подход, использующий генерацию ряда пар RGB и Depth изображений — проекций с различных ракурсов для исходного облака точек. Предварительно строится полигональная модель участков. Семантическая разметка происходит для плоских изображений (рис.4).
- Предложена техника быстрого проецирования из 2D в 3D после семантической сегментации изображений.
- В работе исследованы различные подходы к 2D семантической сегментации, в частности, был рассмотрен вопрос совмещение RGB-D данных в одной или нескольких сетях (fusion networks).
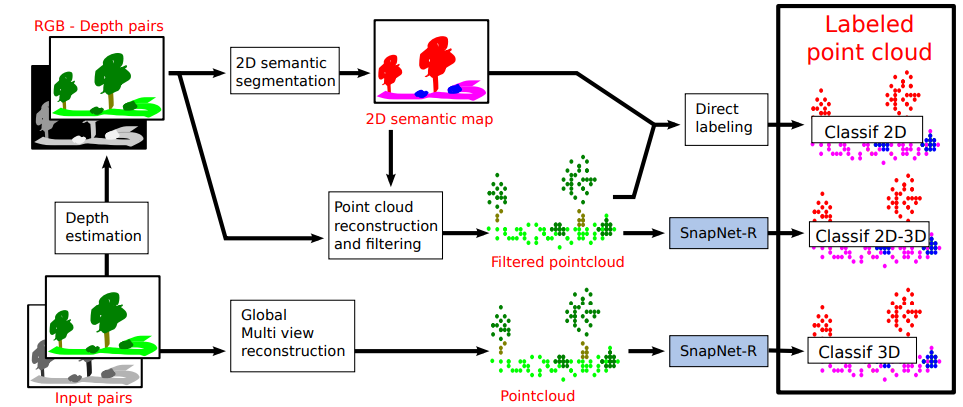
Рис. 5. Схема работы сети SnapNet-R [8].
Входные данные: Облако точек.
Выходные данные: Семантическая разметка облака точек.
Особенности:
- Сеть использует в качестве базового подхода архитектуру SnapNet, но имеет улучшенный алгоритм расстановки камер на сцене и генерации изображений (рис.5) за счет чего, превосходит свою предшественницу по показателям качества.
- В работе, авторы исходили из предположения, что в реальной жизни камеры не могут быть расставлены на сцене случайным образом, а скорее всего подчинены определенной логике (например это может быть стереопара на беспилотном транспорте). В этих предположениях сконструирован фреймворк для разметки облаков точек на основе RGB-D снимков и реконструированного из этих снимков облака точек.
Volumetric methods
Вторая группа непрямых методов использует воксельное представление 3D моделей (voxel based methods). Поскольку воксельные сетки имеют регулярную структуру (аналогично пиксельным изображениям), то для них несложно обобщаются понятия сверток и многие другие приемы, применимые для анализа изображений.
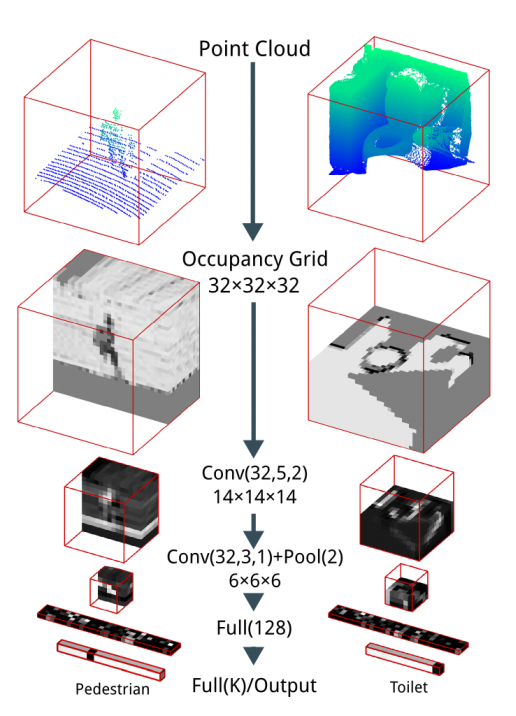
Рис.6 Схема работы сети VoxNet [9].
Входные данные: Вокселизированная модель исходного облака точек.
Выходные данные: Семантически сегментированное облако и воксельная маска распознанного объекта.
Особенности:
- Главным инструментом подхода являются свертки на трехмерных матрицах.
- В целом, данный подход можно считать устаревшим, так как есть более оптимизированные подходы, основанные на воксельных представлениях.
- Из интересного, в статье описаны различные типы сверток на вокселях и процедура вокселизации облака точек.
- Сеть способна обрабатывать сцены с несколькими объектами, но больше приспособлена на отделение шумового фона от центрального объекта (рис. 6).
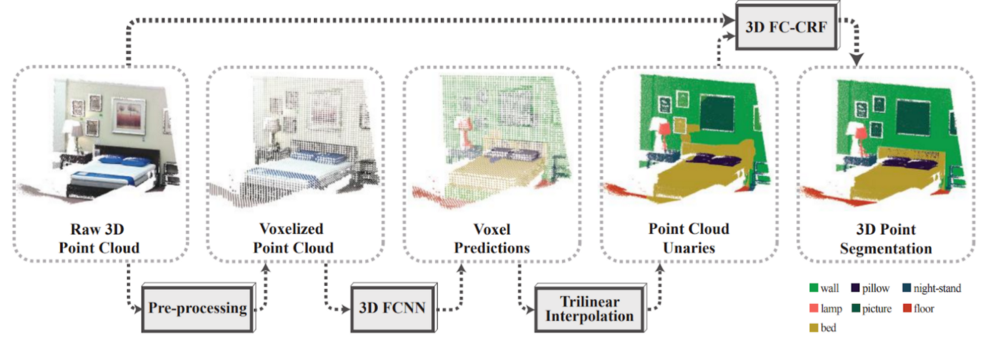
Рис. 7. Схема работы сети SEGCloud [10].
- Github page (код отсутсвует)
- Paper
Входные данные: Вокселизированная модель исходного облака точек.
Выходные данные: Семантически сегментированное облако и воксельная маска распознанного объекта.
Особенности:
- Комбинированный подход методов классического машинного обучения и глубоких архитектур.
- Для оптимизации использования памяти и оптимизации по скорости воксельную разреженную сеть сегментируют трехмерными матричными свертками (3D-FCNN), после чего, результат подается на вход трилинейному интерполятору (схема работы сети на рис. 7) для того, чтобы заполнить свободное пространство на основе полученной маски.
- Дополнительно используется conditional random field (CRF), для комбинирования информативных признаков из исходного облака точек и интерполированной воксельной сетки.
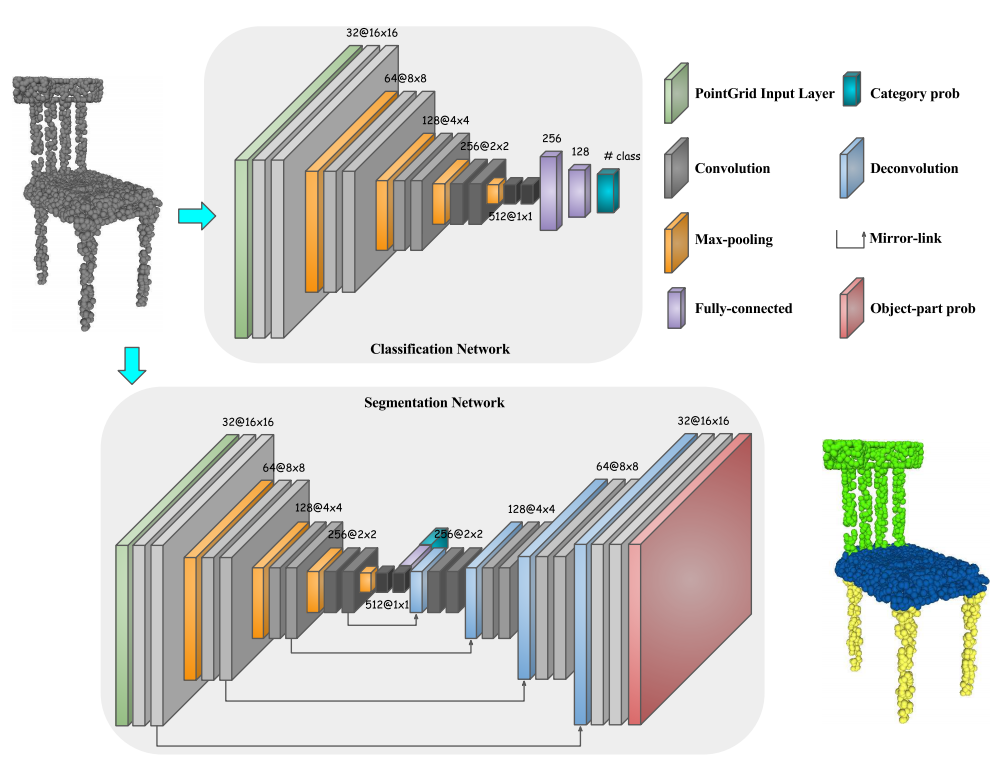
Рис. 8. Схема работы сети PointGrid [11].
Входные данные: Вокселизированная модель исходного облака точек.
Выходные данные: Семантически сегментированное облако и воксельная маска распознанного объекта.
Особенности:
- Подход аналогичен VoxNet.
- Можно выделить процедуру семплирования точек в пространстве, которая дополняет исходное облако так, что в каждом вокселе содержится одинаковое количество точек.
- Используется энкодер-декодер архитектура и свертки на воксельной сетке (рис. 8).
- По сравнению с другими воксельными моделями работает быстрее и использует меньшее количество памяти.
Прямые методы
Если говорить о прямых методах, то авторы обзора [4] разделили их на несколько групп в зависимости от особенности использованной глубокой архитектуры или в зависимости от того, какую из основных проблем работы с неструктурированными данными решает архитектура.
Methods of point ordering
Первая группа методов направлена на то, чтобы справиться с неупорядоченностью трехмерных данных (methods of point ordering).
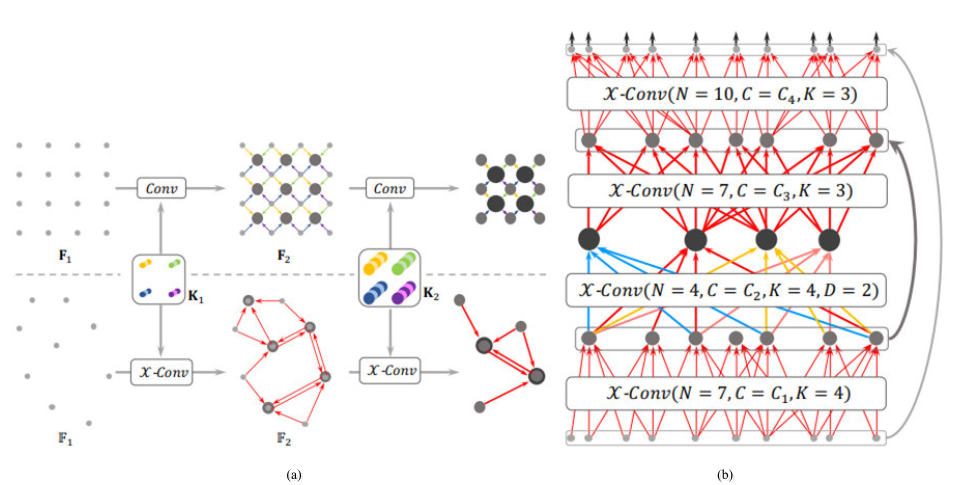
Рис. 9. Иерархические свертки (а) и архитектура (b) для сети PointCNN [12].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Основным нововведением является использование
 -transformed operator — оператора, преобразующего исходное облако точек в информативные признаки (взвешенное облако точек) и представляющего из себя многослойный персептрон (рис. 9).
-transformed operator — оператора, преобразующего исходное облако точек в информативные признаки (взвешенное облако точек) и представляющего из себя многослойный персептрон (рис. 9). - Признаками, на основе которых производится разметка, являются выходы -персептронов, так как они инвариантны к перестановкам точек.
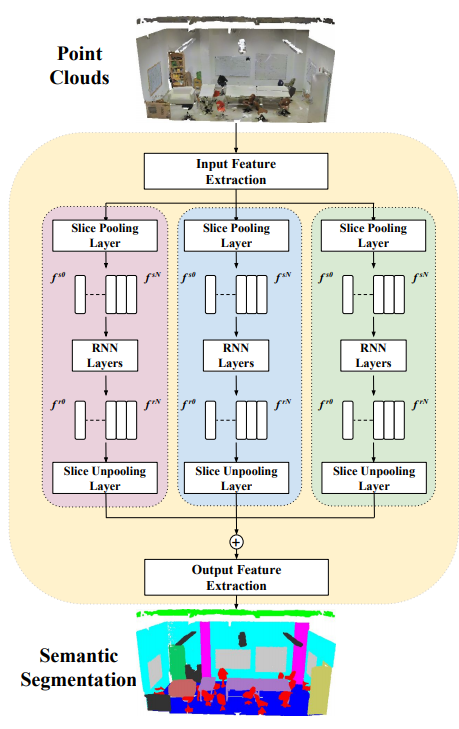
Рис. 10 Схема работы сети RSNet [13].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Предложен специальный слой, который позволяет упорядочивать точки (Slice pooling layer).
- Объект делится на слои по трем координатным направлениям (все точки проецируются на координатные оси из пространства меньшей размерности). Из каждого слоя извлекаются признаки путем применения рекурентной архитектуры (RNN), после чего применяется оператор обратного проецирования (Slice Unpooling) (рис. 10).
- Добавление цвета помогает улучшить результаты.
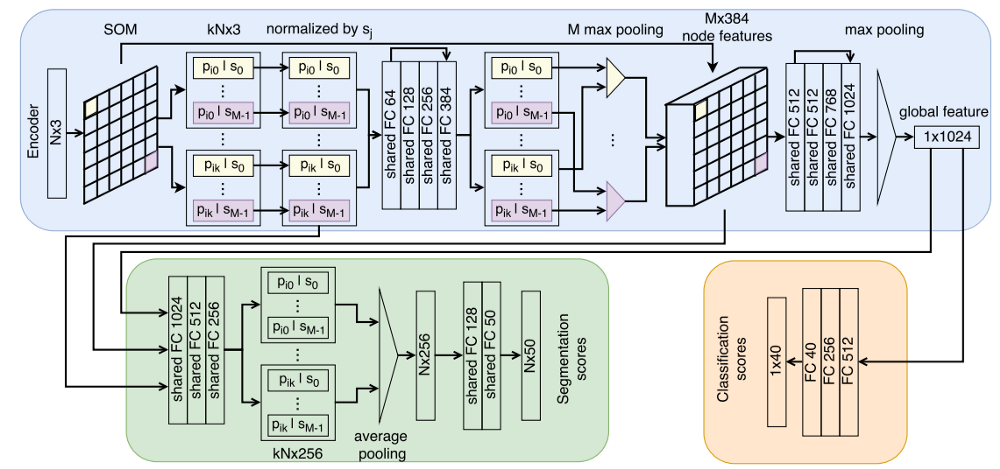
Рис.11 Архитектура сети SO-Net [14].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Главная особенность: предварительно из облака точек извлекаются признаки с помощью метода Карт Кохонена.
- Сеть предназначена для решения широко спектра задач: классификация, кластеризация, дополнение формы и многие другие. Разнообразие задач является следствием использования архитектуры автокодировщика (AE) (рис. 11).
- Из минусов можно отметить сложность модели, плохое качество работы с мелкими деталями и невозможность обрабатывать сцены состоящие из нескольких объектов.
Methods based on multi-scale
Следующая группа методов решает проблему масштабирования: часто, для решения задач классификации исследователи успешно применяют различные сверточные операторы. В зависимости от масштаба облака точек, одна и та же свертка может покрывать как большую область данных, делая выводы о крупных деталях и масштабных признаках, так и приспособится под локальные признаки на мелких деталях. Модели данной группы методов приспособлены под то, чтобы извлекать признаки на разных масштабах.
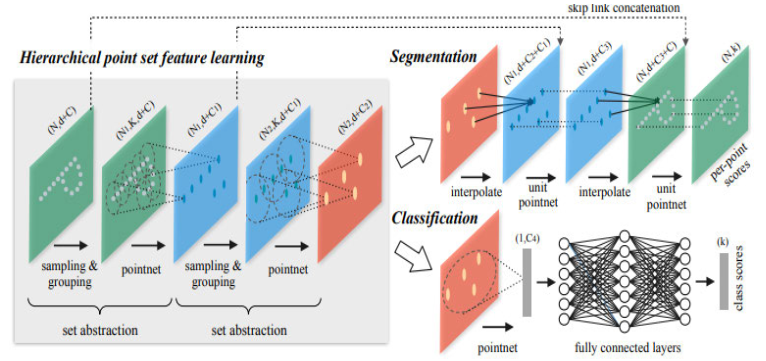
Рис. 12 Архитектура сети PointNet++ [15].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Используется повторное применение PointNet [27] к уменьшающемуся подмножеству точек (рис. 12).
- Используется farthest point sampling (FPS) algorithm для изначального разбиения.
- Рассматриваются случаи, когда специальная структура метрического пространства помогает намного улучшить результат, по сравнению с Евклидовым пространством.
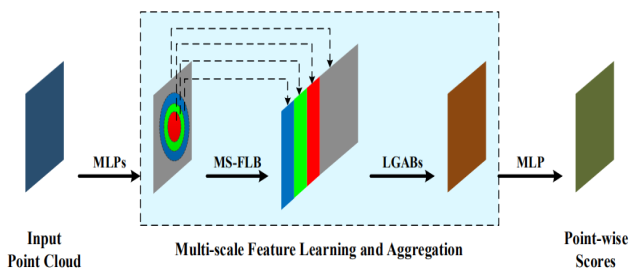
Рис. 13 Схема работы сети 3DMAX-Net [16].
- Github page (код отсутствует)
- Paper
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Архитектура состоит из двух подархитектур: multi-scale feature learning block (MS-FLB) и Local and Global feature Aggregation Block (LGAB) (рис. 13).
- Первая подархитеткура извлекает информативные признаки инвариантные к трансформации, а вторая агрегирует локальные и глобальные признаки.
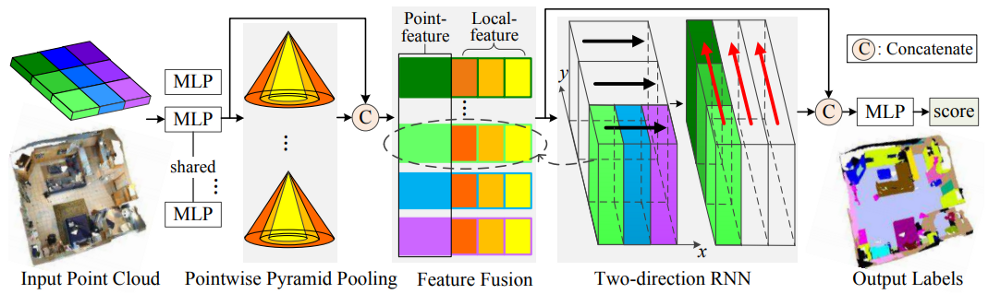
Рис. 14 Схема работы сети 3P-RNN [17].
- Github page (код отсутствует)
- Paper
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Применяются двунаправленные рекуррентные нейронные сети в пространстве признаков (рис. 14).
- Предложен поточечный пирамидальный pooling (3P) для выделение скрытых признаков.
- Нужно знать плоскость (условно пол) т. к.происходит деление облака точек на блоки определенного размера вдоль оси x и y.
- В отличие от предыдущих методов, эта архитектура показывает приемлемый результат как на облаках точек внутренних помещений, так и на облаках точек открытого пространства.
Methods of feature fusion
Для анализа больших сцен, состоящих из множества разнообразных объектов необходимо уметь извлекать информативные признаки, относящиеся ко всей сцене в общем, и признаки, относящиеся к конкретным объектам и их частям в частности. Для того, чтобы не искать универсальную модель для извлечения всех признаков сразу, применяют подход синтеза нескольких моделей, каждая из которых направлена на выявления той или иной категории признаков.
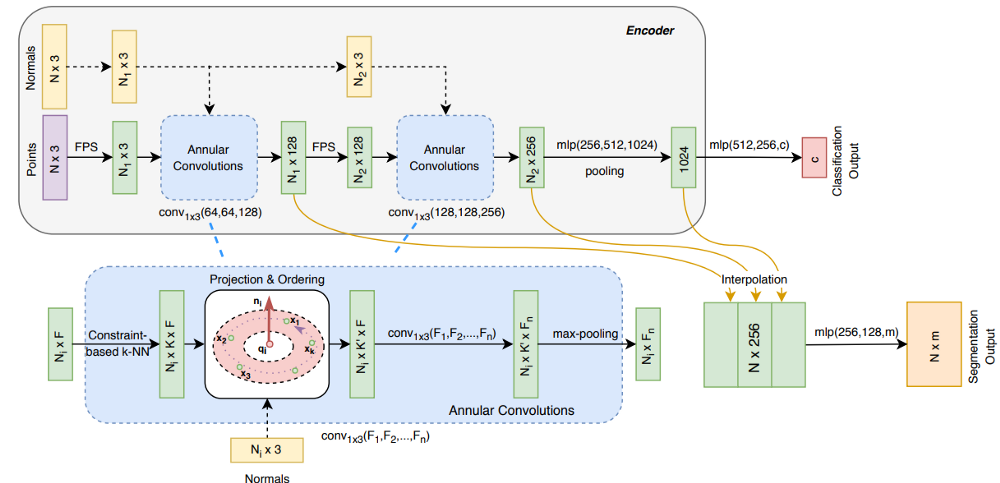
Рис. 16 Архитектура сети A-CNN [19].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Предложены кольцевые свертки (архитектура сети на рис. 16).
- Нужно оценить или иметь нормали для облака точек, т. к. они используются в процессе вычислений.
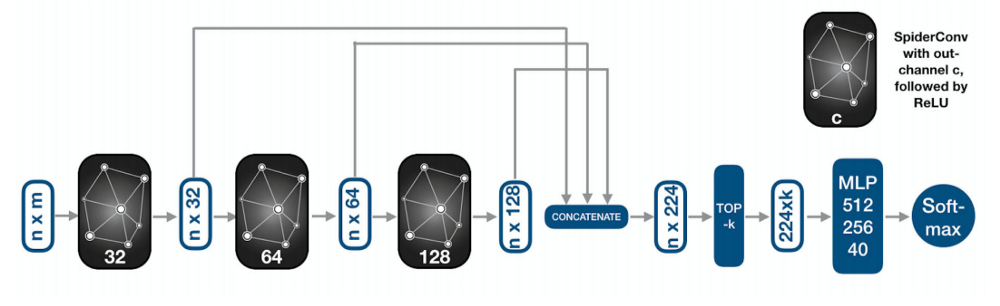
Рис. 17 Архитектура сети SpiderCNN [20].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Предложен новый сверточный оператор SpiderConv (архитектура сети на рис. 17).
- Новый оператор конструируется как произведение двух операторов: кусочно-постоянного и полиномиального, полученных из разложения в ряд Тейлора сверточного фильтра общего вида.
- Порядок разложения следует из некоторых результатов трилинейной интерполяции на регулярной сетке в 3D.
Methods of fusing GCNN
Если есть возможность восстановить информацию о поверхности объекта (например в случаи, когда мы работаем с полигональной моделью), то можно попытаться применить специфические свойства пространственных графов для решения задачи классификации и сегментации. Следующая группа методов основана на использовании операций сверток на графах, и все модели, так или иначе, базируются на архитектуре Graph Convolutional Neural Networks (GCNN) [28].
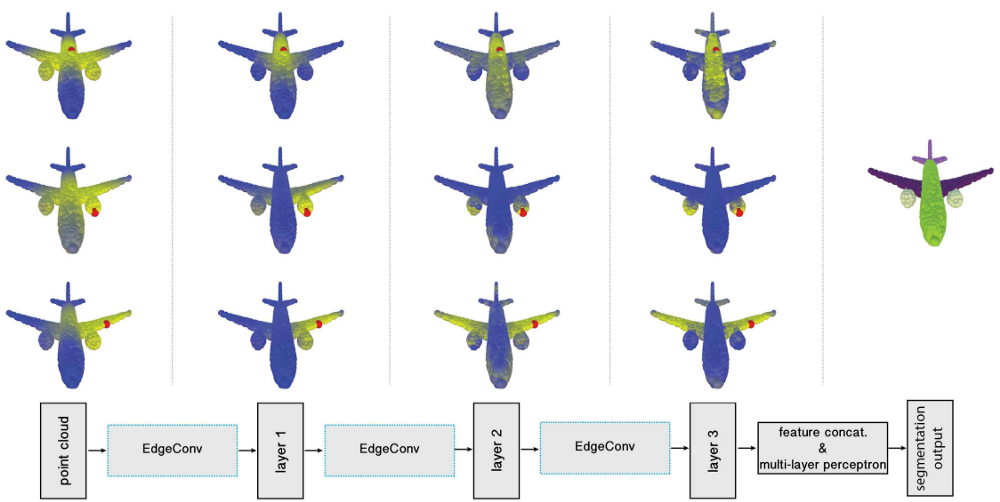
Рис. 18 Схема сети DGCNN [2].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- В отличие от базового GCNN, в данной архитектуре, граф динамически перестраивается в процессе применения после прохождения информации через каждый последующий слой сети (рис. 18).
- В качестве операторов в скрытых слоях используются графовые свертки, которые позволяют находить для каждой точки ближайших соседей не только в исходном Евклидовом пространстве, но и в пространстве скрытых признаков.
- Архитектура почти аналогична PointNet [27], но вместо полносвязных перцептронов, в ней используются графовые свертки.
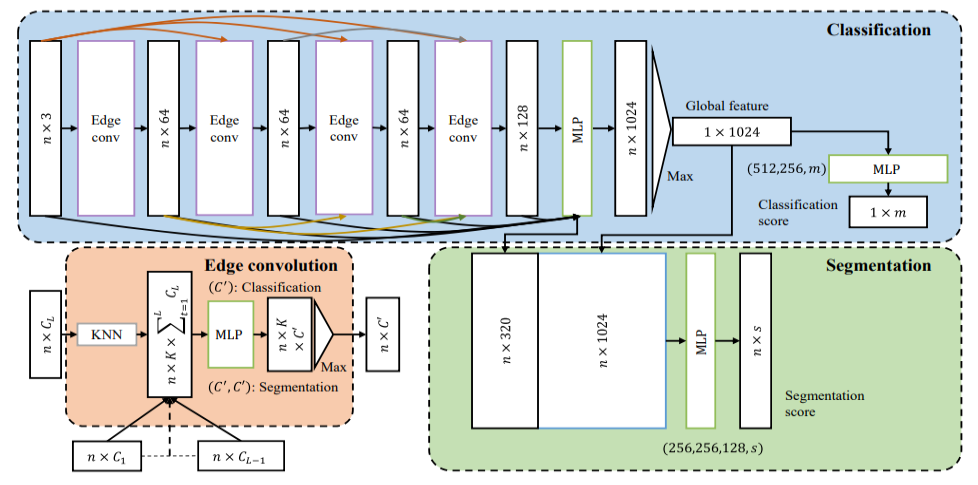
Рис. 19 Архитектура сети LDGCNN [21].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Модификация архитектуры DGCNN [2]: отказались от сети для преобразования координат и адаптировали идеи из работы DenseNet [29].
- Обучение делится на два этапа: обучение модели, которая извлекает признаки, и обучение классификатора при фиксированной модели для извлечения признаков (рис. 19).
- Модель лучше сходится в процессе обучения и имеет меньшее число параметров по сравнению с DGCNN.
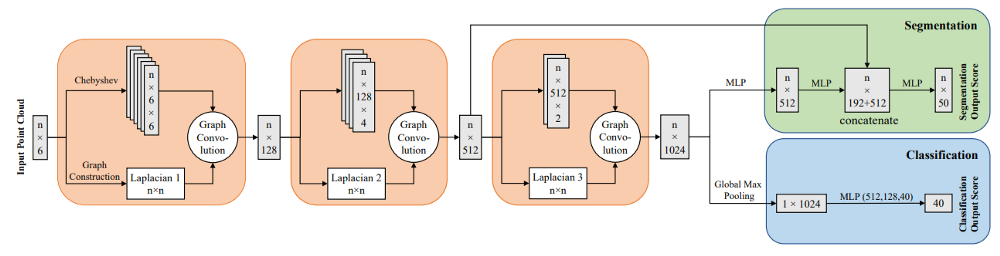
Рис. 20 Архитектура сети RGCNN [22].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Сеть строится из блоков, в каждом из которых используются три оператора: построение графа, свертка на графе, отбор признаков (рис. 20).
- Для лучшего распознавания структуры динамически изменяющегося от слоя к слою графа, авторы используют матрицу Лапласа заданного графа (graph Laplacian matrix), которая описывает взаимосвязь признаков полученных в разных скрытых слоях.
- Модель устойчива к выбросам в данных.
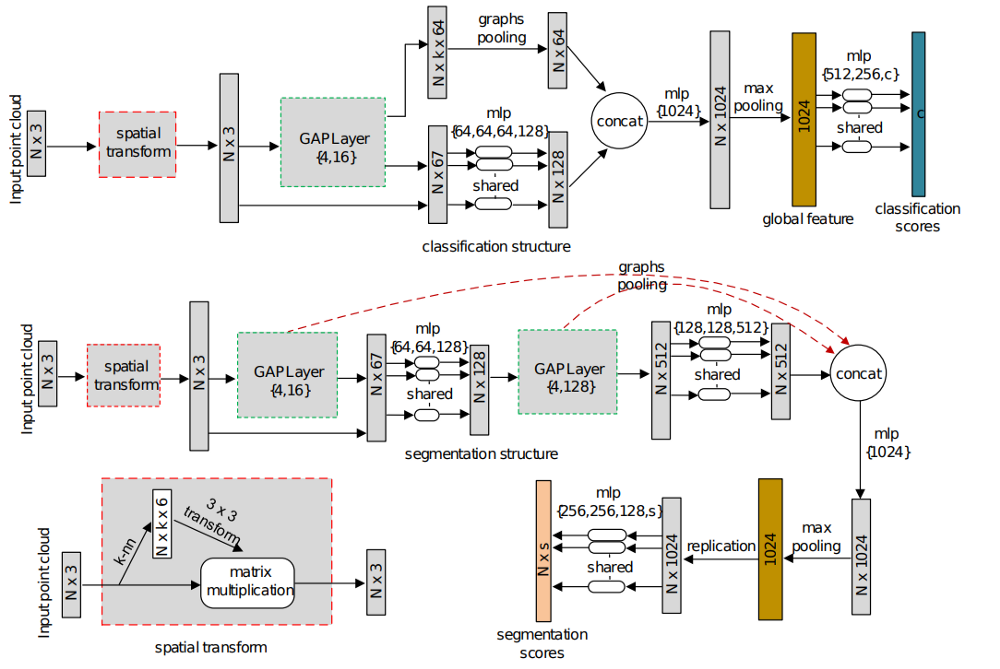
Рис. 21 Архитектура сети GAPNet [23].
Входные данные: Облако точек.
Выходные данные: Семантически сегментированное облако.
Особенности:
- Основная особенность — использование механизма внимания, состоящего из двух частей: самовнимание (self attention) для текущей точки и механизма внимания для поиска региона интереса в данных (рис. 21).
- Архитектура похожа на PointNet [27].
Анализ качества работы глубоких архитектур
Для каждого алгоритма можно определить две группы метрик, для оценки качества их работы:
- Внутренние метрики, показывающие насколько хорошо алгоритм справился с поставленной перед ним задачей (классификация, кластеризация, ранжированная выдача, генерация и многое другое);
- Внешние метрики качества, показывающие то, насколько алгоритм хорошо встраиваться в общую систему, составной частью которой он является (скорость работы, потребляемая память, безопасность данных и другие).
С точки зрения внешних метрик качества для алгоритмов для алгоритмов глубокого обучения обычно выделяют время выполнения (т.н. время прямого распространения сигнала) и количество параметров сети, которое напрямую влияет на количество памяти, необходимое для хранения модели.
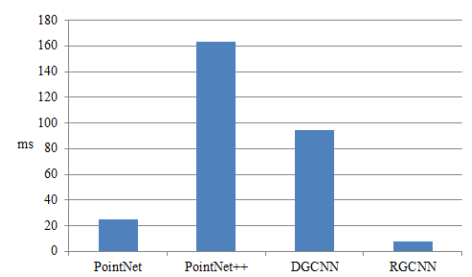
Рис. 22 Время прямого распространения сигнала через нейронную сеть в миллисекундах (ms) [4].
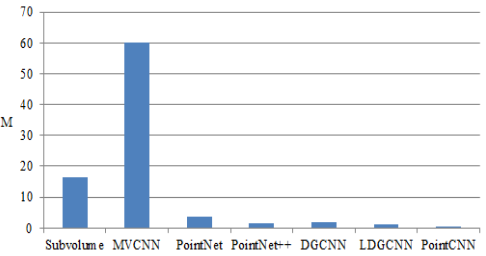
Рис. 23 Количество параметров нейронной сети в миллионах (М) [4].
Ниже приведены сравнения работы описанных алгоритмов с помощью метрик качества классификации и семантической сегментации для различных наборов данных (большее количество информации и конкретные данные для сравнения вы можете найти в обзорной статье [4] или в этом github репозитории).
В качестве метрик используются следующие три:
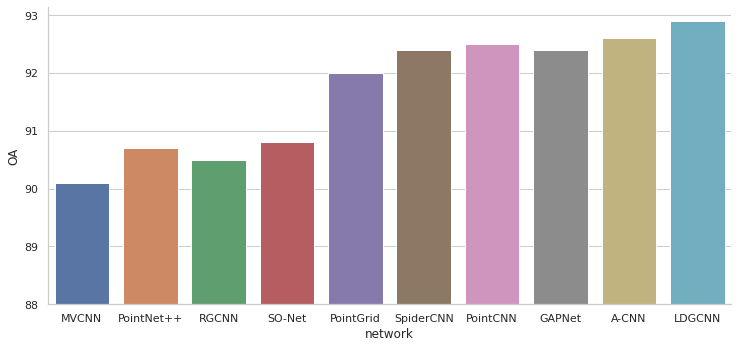
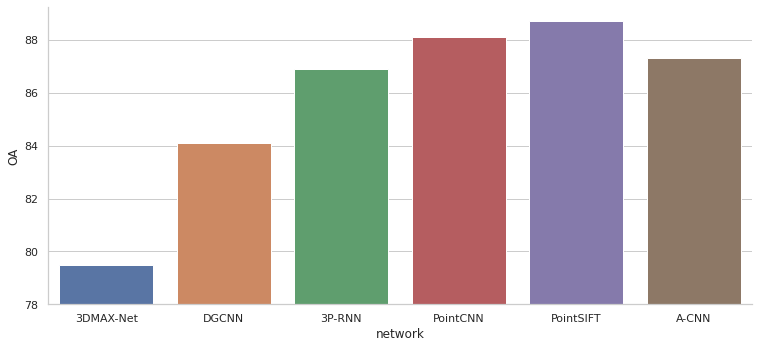
- Overall accuracy (OA) — доля правильных ответов на всех классах / для всех точек.
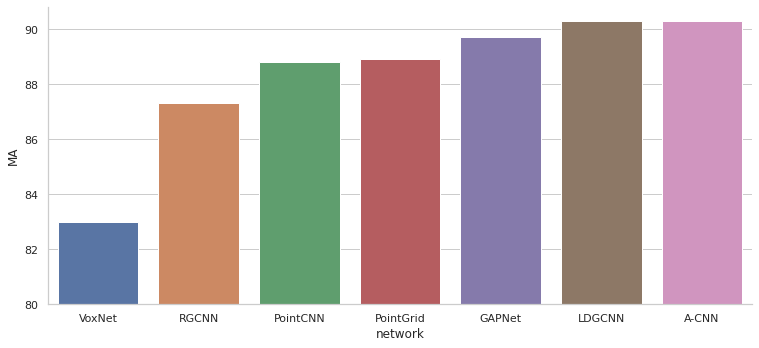
- Mean accuracy (MA) — среднее значение Overall Accuracy по классам / для всех точек.
- Mean intersection over union (mIoU) — среднее значение метрики IoU [4] на всех классах / для всех точек.
В качестве наборов данных, для рассмотрения на графиках ниже были использованы следующие датасеты:

Рис. 24 Пример помещений, отсканированных в формате цветного облака точек и семантической разметки из датасета S3DIS [24].
Состоит из 13 категорий, 224 отсканированных сцен для обучения и 48 сцен для валидирования. Все сцены — помещения, отсканированные с помощью лидара и размеченные вручную.
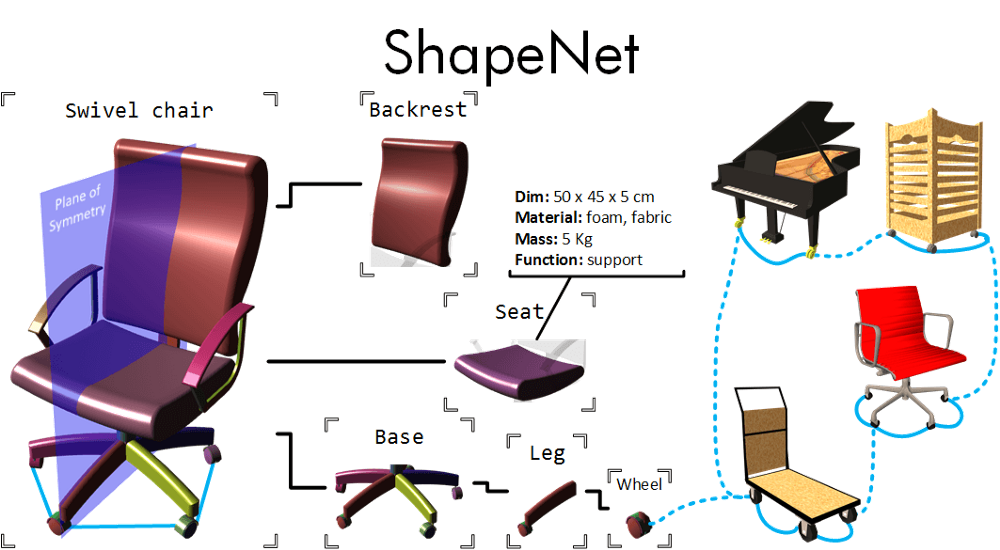
Рис. 25 Пример объектов и их разбиения на составные части из датасета ShapeNet part [25].
Состоит из 16 категорий, 12137 объектов в обучающей выборке, 2874 объектов для валидации. Датасет состоит из одиночных 3D моделей нарисованных художниками и разбитыми на составные части.

Рис. 26 Пример объектов класса “стул” их разбиений на составные части в формате облака точек из датасета ModelNet40 [1].
Состоит из 40 классов, 12311 3D СAD моделей в обучающей и валидационной выборке. Датасет состоит из одиночных 3D параметрических моделей (CAD форматы), для 10-и классов, есть информация об ориентации моделей. Нет разбиения на части, этот датасет используется только для задачи классификации отдельных объектов.

Рис. 27 Пример семантического разбиения отсканированного помещения из датасета ScanNet [26].
Состоит из 21 класса, 1201 сцены в обучающей выборке и 312 сцен в валидационной выборке. Датасет состоит из сцен помещений в виде набора RGB-D ракурсов + семантические размеченные облака точек без цвета.
Сравнения метрик
Далее приведены графики сравнения моделей по различным метрикам для определённого набора данных. Не все модели можно сравнить между собой т. к. для некоторых в статье не приведены результаты расчёта метрик. На графиках модели упорядочены по годам выпуска статей в которых они описаны.
На абсолютные значения метрик нужно смотреть с осторожностью. Схемы проверки могут отличаться в некоторых случаях, поэтому лучше смотреть на общую тенденцию, чем на конкретные значения, при сравнении моделей.
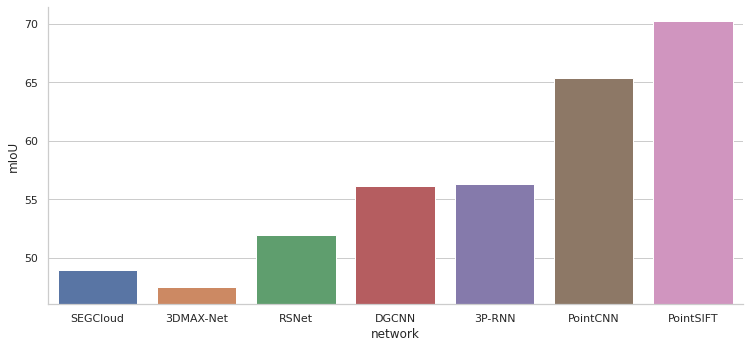
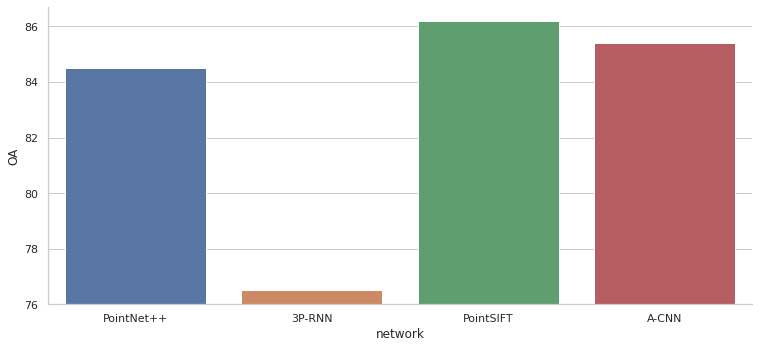
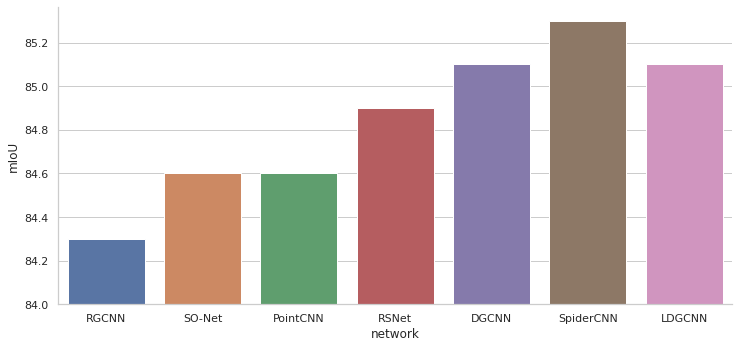
Выводы
Исходя из проведенного анализа, можно сделать вывод:
- прямые подходы предпочтительнее непрямых как с точки зрения внутренних, так и внешних метрик;
- в зависимости от задачи и типа данных, оптимальные подходы могут быть разными;
- в качестве потенциально применимых на практике подходов можно выделить: все сети основанные на GCNN, SpiderCNN и PointSIFT.
На наш вкус — LDGCNN наиболее универсальна и предпочтительна для применения в реальных задачах.
- Wu, Z., Song, S., Khosla, A., Yu, F., Zhang, L., Tang, X. and Xiao, J., 2015. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1912–1920). [paper]
- Wang, Y., Sun, Y., Liu, Z., Sarma, S.E., Bronstein, M.M. and Solomon, J.M., 2019. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (TOG), 38(5), pp.1–12. [paper]
- Xie Y., Tian J., Zhu X. X. A review of point cloud semantic segmentation //arXiv preprint arXiv:1908.08854. — 2019. [paper]
- Zhang J. et al. A Review of Deep Learning-based Semantic Segmentation for Point Cloud (November 2019) //IEEE Access. — 2019. [paper]
- Weinmann M. et al. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers //ISPRS Journal of Photogrammetry and Remote Sensing. — 2015. — Т. 105. — С. 286–304. [paper]
- H. Su, S. Maji, E. Kalogerakis, and E. Learned-Miller, ‘‘Multi-view convolutional neural networks for 3D shape recognition,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 945–953 [paper]
- A. Boulch, B. Le Saux, and N. Audebert, ‘‘Unstructured point cloud semantic labeling using deep segmentation networks,’’ in Proc. Eurograph. Workshop 3D Object Retr., vol. 2, 2017, pp. 17–24. [paper]
- J. Guerry, A. Boulch, B. Le Saux, J. Moras, A. Plyer, and D. Filliat, ‘‘SnapNet-R: Consistent 3D multi-view semantic labeling for robotics,’’ in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 669–678. [paper]
- D. Maturana and S. Scherer, ‘‘VoxNet: A 3D convolutional neural network for real-time object recognition,’’ in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst. (IROS), Dec. 2015, pp. 922–928. [paper]
- L. Tchapmi, C. Choy, I. Armeni, J. Gwak, and S. Savarese, ‘‘SEGCloud: Semantic segmentation of 3D point clouds,’’ in Proc. Int. Conf. 3D Vis. (3DV), Oct. 2017, pp. 537–547, doi: 10.1109/3DV.2017.00067. [paper]
- T. Le and Y. Duan, ‘‘PointGrid: A deep network for 3D shape understanding,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 9204–9214 [paper]
- Y. Li, R. Bu, M. Sun, W. Wu, X. Di and B. Chen, ‘‘PointCNN: Convolution On X-transformed points,’’ in Proc. Adv. Neural Inf. Process. Syst. (NIPS). Dec. 2018, pp. 828–838. [paper]
- Q. Huang, W. Wang, and U. Neumann, ‘‘Recurrent slice networks for 3D segmentation of point clouds,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 2626–2635. [paper]
- J. Li, B. M. Chen, and G. H. Lee, ‘‘SO-net: Self-organizing network for point cloud analysis,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2018, pp. 9397–9406 [paper]
- C. R. Qi, L. Yi, H. Su, and L. J. Guibas, ‘‘PointNet++: Deep hierarchical feature learning on point sets in a metric space,’’ in Proc. Adv. Neural Inf. Process. Syst. 30 (NIPS), 2017, pp. 5105–5114. [paper]
- Y. Ma, Y. Guo, Y. Lei, M. Lu, and J. Zhang, ‘‘3DMAX-net: A multi-scale spatial contextual network for 3D point cloud semantic segmentation,’’ in Proc. 24th Int. Conf. Pattern Recognit. (ICPR), Aug. 2018, pp. 1560–1566, doi: 10.1109/ICPR.2018.8546281. [paper]
- X. Ye, J. Li, H. Huang, L. Du, and X. Zhang, ‘‘3D recurrent neural networks with context fusion for point cloud semantic segmentation,’’ in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 403–417 [paper]
- M. Jiang, Y. Wu, T. Zhao, Z. Zhao, and C. Lu, ‘‘PointSIFT: A SIFTlike network module for 3D point cloud semantic segmentation,’’ 2018, arXiv:1807.00652. [paper]
- A. Komarichev, Z. Zhong, and J. Hua, ‘‘A-CNN: Annularly convolutional neural networks on point clouds,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2019, pp. 7421–7430 [paper]
- Y. Xu, T. Fan, M. Xu, L. Zeng, and Y. Qiao, ‘‘SpiderCNN: Deep learning on point sets with parameterized convolutional filters,’’ in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 87–102. [paper]
- K Zhang, M. Hao, J. Wang, C. W. de Silva, and C. Fu, ‘‘Linked dynamic graph CNN: Learning on point cloud via linking hierarchical features,’’ 2019, arXiv:1904.10014. [paper]
- G. Te, W. Hu, A. Zheng, and Z. Guo, ‘‘RGCNN: Regularized graph CNN for point cloud segmentation,’’ in Proc. 26th ACM Int. Conf. Multimedia, Oct. 2018, pp. 746–754. [paper]
- C. Chen, L. Z. Fragonara, and A. Tsourdos, ‘‘GAPNet: Graph attention based point neural network for exploiting local feature of point cloud,’’ 2019, arXiv:1905.08705. [paper]
- I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese, ‘‘3D semantic parsing of large-scale indoor spaces,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 1534–1543. [paper]
- L. Yi et al., ‘‘Large-scale 3D shape reconstruction and segmentation from ShapeNet core55,’’ 2017, arXiv:1710.06104. [paper]
- A. Dai, A. X. Chang, M. Savva, M. Halber, T. Funkhouser, and M. Nießner, ‘‘ScanNet: Richly-annotated 3D reconstructions of indoor scenes,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 5828–5839. [paper]
- Qi, C.R., Su, H., Mo, K. and Guibas, L.J., 2017. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 652-660). [paper]
- Zhang, Y. and Rabbat, M., 2018, April. A graph-cnn for 3d point cloud classification. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 6279-6283). IEEE. [paper]
- Huang, G., Liu, Z., Van Der Maaten, L. and Weinberger, K.Q., 2017. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4708). [paper]
