
Несмотря на то, что большая часть ИТ-индустрии внедряет инфраструктурные решения на базе контейнеров и облачных решений, необходимо понимать и ограничения этих технологий. Традиционно Docker, Linux Containers (LXC) и Rocket (rkt) не являются по-настоящему изолированными, поскольку в своей работе они совместно используют ядро родительской операционной системы. Да, они эффективны с точки зрения ресурсов, но общее количество предполагаемых векторов атаки и потенциальные потери от взлома все еще велики, особенно в случае мультиарендной облачной среды, в которой размещаются контейнеры.

Корень нашей проблемы заключается в слабом разграничении контейнеров в моменте, когда операционная система хоста создает виртуальную область пользователя для каждого из них. Да, были проведены исследования и разработки, направленные на создание настоящих «контейнеров» с полноценной «песочницей». И большинство полученных решений ведут к перестройке границ между контейнерами для усиления их изоляции. В этой статье мы рассмотрим четыре уникальных проекта от IBM, Google, Amazon и OpenStack соответственно, в которых используются разные методы для достижения одной и той же цели: создания надежной изоляции. Так, IBM Nabla разворачивает контейнеры поверх Unikernel, Google gVisor создает специализированное гостевое ядро, Amazon Firecracker использует чрезвычайно легкий гипервизор для приложений песочницы, а OpenStack помещает контейнеры в специализированную виртуальную машину, оптимизированную для инструментов оркестрации.
Контейнеры — это современный способ упаковки, совместного использования и развертывания приложения. В отличие от монолитного приложения, в котором все функции упакованы в одну программу, контейнерные приложения или микросервисы предназначены для целенаправленного узкого использования и специализируются только на одной задаче.
Контейнер включает в себя все зависимости (например, пакеты, библиотеки и двоичные файлы), которые необходимы приложению для выполнения своей конкретной задачи. В результате, контейнеризованные приложения не зависят от платформы и могут работать в любой операционной системе независимо от ее версии или установленных пакетов. Это удобство избавляет разработчиков от огромного куска работы по адаптации разных версий программного обеспечения для разных платформ или клиентов. Хотя концептуально это не совсем точно, многим людям нравится думать о контейнерах как об «облегченных виртуальных машинах».
Когда контейнер развертывается на хосте, ресурсы каждого контейнера, такие как его файловая система, процесс и сетевой стек, помещаются в фактически изолированную среду, к которой другие контейнеры не могут получить доступ. Эта архитектура позволяет одновременно запускать сотни и тысячи контейнеров в одном кластере, а каждое приложение (или микросервис) можно потом легко масштабировать путем репликации бо́льшего количества экземпляров.
При этом разверстка контейнера основывается на двух ключевых «строительных блоках»: пространстве имен Linux и контрольных группах Linux (cgroups).
Пространство имен создает практически изолированное пользовательское пространство и предоставляет приложению выделенные системные ресурсы, такие как файловая система, сетевой стек, идентификатор процесса и идентификатор пользователя. В этом изолированном пользовательском пространстве приложение контролирует корневой каталог файловой системы и может запускаться от имени root. Это абстрактное пространство позволяет каждому приложению работать независимо, не мешая при этом жить другим приложениям на том же хосте. Сейчас доступно шесть пространств имен: mount, inter-process communication (ipc), UNIX time-sharing system (uts), process id (pid), network и user. Этот список предлагается дополнить еще двумя дополнительными пространствами имен: time и syslog, но сообщество Linux все еще не определилось с окончательными спецификациями.
Cgroups обеспечивают ограничение аппаратных ресурсов, расстановку приоритетов, мониторинг и контроль приложения. В качестве примера аппаратных ресурсов, которыми они могут управлять, можно назвать процессор, память, устройство и сеть. При объединении пространства имен и cgroups, мы можем безопасно запускать несколько приложений на одном хосте, причем каждое приложение находится в своей изолированной среде — что есть фундаментальное свойство контейнера.
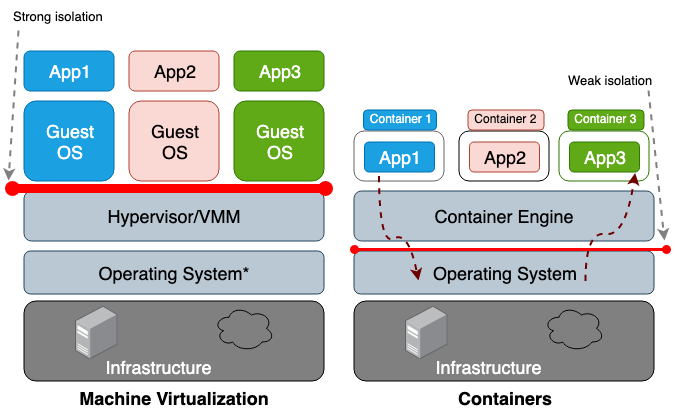
Основное же различие между виртуальной машиной (ВМ) и контейнером заключается в том, что виртуальная машина — это виртуализация на аппаратном уровне, а контейнер — виртуализация на уровне операционной системы. Гипервизор ВМ эмулирует аппаратную среду для каждой машины, где уже среда выполнения контейнера в свою очередь эмулирует операционную систему для каждого объекта. Виртуальные машины совместно используют физическое оборудование хоста, а контейнеры — как оборудование, так и ядро ОС. Поскольку контейнеры в целом разделяют с хостом большее количество ресурсов, их работа с хранилищем, памятью и циклами ЦП намного эффективнее, чем у виртуальной машины. Однако недостатком такого общего доступа является проблемы в плоскости информационной безопасноти, так как между контейнерами и хостом устанавливается слишком большое доверие. Рисунок 1 иллюстрирует архитектурную разницу между контейнером и виртуальной машиной.
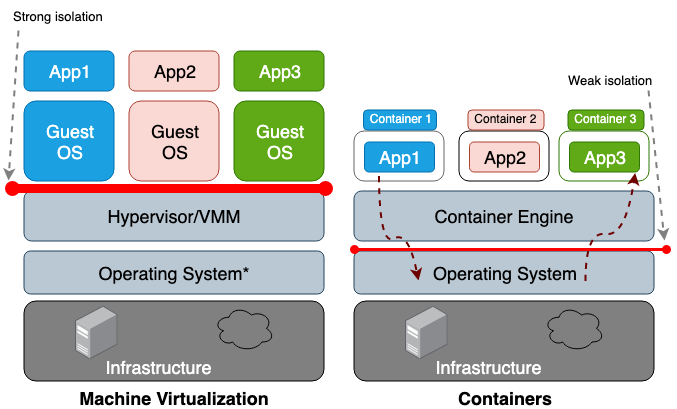
В целом, изоляция виртуализированного оборудования создает гораздо более прочный периметр безопасности, нежели просто изоляция именного пространства. Риск того, что злоумышленник успешно покинет изолированный процесс, намного выше, чем шанс успешного выхода за пределы виртуальной машины. Причиной более высокого риска выхода за пределы ограниченной среды контейнеров является слабая изоляция, создаваемая пространством имен и cgroups. Linux реализует их, связывая новые поля свойств с каждым процессом. Эти поля в файловой системе
Большинство эксплойтов ядра создают вектор для успешной атаки, поскольку обычно они выливаются в повышение привилегий и позволяют скомпрометированному процессу получить контроль за пределами своего предполагаемого именного пространства. Помимо векторов атак в контексте уязвимостей программного обеспечения, свою роль может сыграть и неправильная конфигурация. Например развертывание образов с чрезмерными привилегиями (CAP_SYS_ADMIN, привилегированный доступ) или критические точки монтирования (
Эти проблемы мотивируют исследователей создавать более прочные периметры безопасности. Идея состоит в том, чтобы создать настоящий sandbox-контейнер, максимально изолированный от основной ОС. Большинство подобных решений включают в себя разработку гибридной архитектуры, которая использует строгое разграничение приложения и виртуальной машины, и фокусируется на повышении эффективности контейнерных решений.
На момент написания статьи не было ни одного проекта, который можно было бы назвать достаточно зрелым, чтобы его можно было принять за стандарт, но в будущем разработчики несомненно, примут некоторые из этих концепций в качестве основных.
Начнем свой обзор с Unikernel, самой старой узкоспециализированной системы, которая упаковывает приложение в один образ с использованием минимального набора библиотек ОС. Сама концепция Unikernel оказалась фундаментальной для множества проектов, целью которых было создание безопасных, компактных и оптимизированных образов. После мы перейдем к рассмотрению IBM Nabla — проекта по запуску приложений Unikernel, в том числе контейнеров. Кроме этого у нас есть Google gVisor — проект для запуска контейнеров в пространстве пользовательского ядра. Далее мы переключимся на контейнерные решения на основе виртуальных машин — Amazon Firecracker и OpenStack Kata. Подытожим этот пост сравнением всех вышеупомянутых решений.
Развитие технологий виртуализации позволило нам перейти к облачным вычислениям. Гипервизоры типа Xen и KVM заложили фундамент того, что мы сейчас знаем как Amazon Web Services (AWS) и Google Cloud Platform (GCP). И хотя современные гипервизоры способны работать с сотней виртуальных машин, объединенных в единый кластер, традиционные операционные системы общего назначения не слишком приспособлены и оптимизированы для работы в подобном окружении. ОС общего назначения предназначена, в первую очередь, для поддержки и работы с как можно большим числом разнообразных приложений, поэтому их ядра включают в себя все виды драйверов, библиотек, протоколов, планировщиков и так далее. Однако большинство виртуальных машин, развернутых сейчас где-то в облаке, используются для работы какого-то одного приложения, например, для обеспечения работы DNS, прокси или какой-то базы данных. Поскольку такое отдельно взятое приложение опирается в своей работе только на конкретный и небольшой участок ядра ОС, все остальные его «обвесы» просто вхолостую тратят системные ресурсы, а самим фактом своего существования увеличивают количество векторов для потенциальной атаки. Ведь чем больше кодовая база, тем сложнее устранить все недостатки, и тем больше потенциальных уязвимостей, ошибок и прочих слабых мест. Эта проблема побуждает специалистов к разработке узкоспециализированных ОС с минимальным набором функциональных возможностей ядра, то есть к созданию инструментов для поддержки одного конкретного приложения.
Впервые идея Unikernel родилась еще в 90-х годах. Тогда же он оформился как специализированный образ машины с единым адресным пространством, который может работать непосредственно на гипервизорах. Он упаковывает основное и зависящие от него приложения и функции ядра в единый образ. Nemesis и Exokernel — две самые ранние исследовательские версии проекта Unikernel. Процесс упаковки и развертывания показан на рисунке 2.
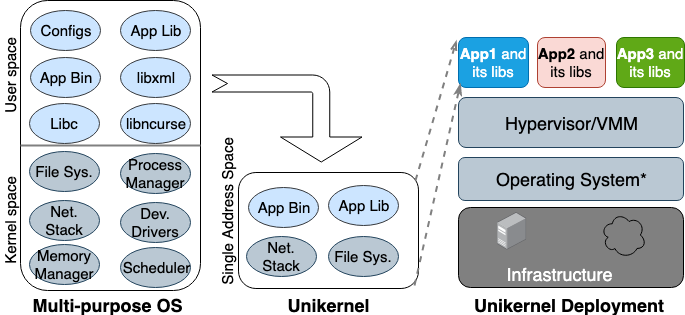
Рисунок 2. Многоцелевые операционные системы созданы для поддержки всех типов приложений, поэтому многие библиотеки и драйверы загружены в них заранее. Unikernels — это узкоспециализированные ОС, которые созданы для поддержки одного конкретного приложения.
Unikernel разбивает ядро на несколько библиотек и помещает в образ только необходимые компоненты. Как и обычные виртуальные машины, unikernel развертывается и работает на гипервизоре ВМ. Благодаря небольшим размерам он может быстро загружаться и также быстро масштабироваться. Наиболее важные свойства Unikernel — это повышенная безопасность, небольшой занимаемый объем, высокая степень оптимизации и быстрая загрузка. Поскольку эти образы содержат только зависимые от приложения библиотеки, и оболочка ОС недоступна, если она не была подключена целенаправленно, то и количество векторов атаки, которую могут использовать злоумышленники на них минимально.
То есть, атакующим не только трудно закрепиться в этих уникальных ядрах, но и их влияние также ограничивается одним экземпляром ядра. Поскольку размер образов Unikernel составляет всего несколько мегабайт, они загружаются за десятки миллисекунд, а на одном хосте могут запускаться буквально сотни его экземпляров. Используя выделение памяти в одном адресном пространстве вместо многоуровневой таблицы страниц, как это происходит в большинстве современных ОС, приложения unikernel имеют меньшую задержку доступа к памяти по сравнению с тем же приложением, работающем на обычной виртуальной машине. Поскольку приложения собираются вместе с ядром при построении образа, компиляторы могут выполнять просто статическую проверку типов для оптимизации двоичных файлов.
Сайт Unikernel.org ведет список проектов unikernel. Но со всеми своими отличительными особенностями и свойствами unikernel не получил большого распространения. Когда в 2016 году Docker приобрел Unikernel Systems, сообщество решило, что теперь компания будет упаковывать контейнеры в них. Но прошло уже три года, а признаков интеграции все еще нет. Одна из основных причин такого медленного внедрения заключается в том, что до сих пор нет зрелого инструмента для создания приложений Unikernel, а большинство таких приложений могут работать только на определенных гипервизорах. Кроме того, портирование приложения в unikernel может потребовать ручного переписывания кода на других языках, включая переписывание зависимых библиотек ядра. Важно и то, что мониторинг или отладка в unikernels либо невозможны, либо оказывают значительное влияние на производительность.
Все эти ограничения удерживают разработчиков от перехода на данную технологию. Следует отметить, что unikernel и контейнеры имеют много похожих свойств. И первые, и вторые являются узконаправленными неизменяемыми образами, а это означает, что компоненты внутри них не могут быть обновлены или исправлены, то есть для патча приложения всегда приходится создавать новый образ. Сегодня Unikernel похож на предка Docker: тогда среда выполнения контейнера была недоступна, и разработчикам приходилось использовать базовые инструменты построения изолированной среды приложения (chroot, unshare и cgroups).
Когда-то исследователи из IBM предложили концепцию «Unikernel как процесс» — то есть приложение unikernel, которое бы исполнялось как процесс на специализированном гипервизоре. Проект IBM «Nabla containers» усилял периметр безопасности unikernel, заменив универсальный гипервизор (к примеру, QEMU) на собственную разработку под названием Nabla Tender. Обоснование подобного подхода заключается в том, что вызовы между unikernel и гипервизором по-прежнему предоставляют наибольшее количество векторов для атаки. Именно поэтому использование выделенного для unikernel гипервизора с меньшим количеством разрешенных системных вызовов может значительно укрепить периметр безопасности. Nabla Tender перехватывает вызовы, которые unikernel направляет в гипервизор, и уже самостоятельно переводит их в системные запросы. При этом политика seccomp Linux блокирует все прочие системные вызовы, которые не нужны для работы Tender. Таким образом, Unikernel в связке с Nabla Tender запускается в качестве процесса в пользовательском пространстве хоста. Ниже, на рисунке №3, отражено, как Nabla создает тонкий интерфейс между unikernel и хостом.
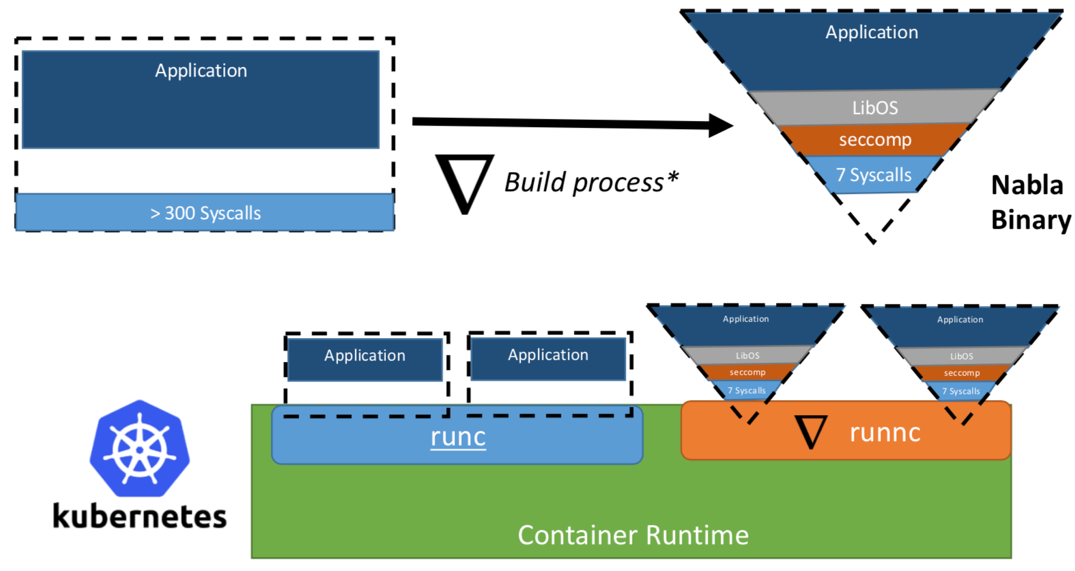
Рисунок 3. Чтобы увязать Nabla с существующими платформами среды выполнения контейнеров, Nabla использует среду, совместимую с OCI, которую в свою очередь можно подключить к Docker или Kubernetes.
Разработчики утверждают, что Nabla Tender использует в своей работе менее семи системных вызовов для взаимодействия с хостом. Так как системные вызовы служат своеобразным мостом между процессами в пользовательском пространстве и ядром операционной системы, то чем меньше нам доступно системных вызовов, тем меньше и количество доступных векторов для атаки на ядро. Еще одно преимущество запуска unikernel как процесса заключается в том, что отладку подобных приложений можно проводить с помощью большого количества инструментов, например, с помощью gdb.
Для работы с платформами оркестрации контейнеров Nabla предоставляет выделенную среду выполнения
Google gVisor — это технология «песочницы», использующая механизм приложений Google Cloud Platform (GCP), облачные функции и CloudML. В какой-то момент компания Google осознала риск запуска ненадежных приложений в инфраструктуре публичного облака и неэффективность приложений песочницы с использованием виртуальных машин. В итоге было разработано ядро пользовательского пространства для изолированной среды таких ненадежных приложений. gVisor помещает эти приложения в песочницу, перехватывая все системные вызовы от них к ядру хоста и обрабатывая их в пользовательской среде с помощью ядра gVisor Sentry. По сути, он функционирует как комбинация гостевого ядра и гипервизора. На рисунке 4 показана архитектура gVisor.
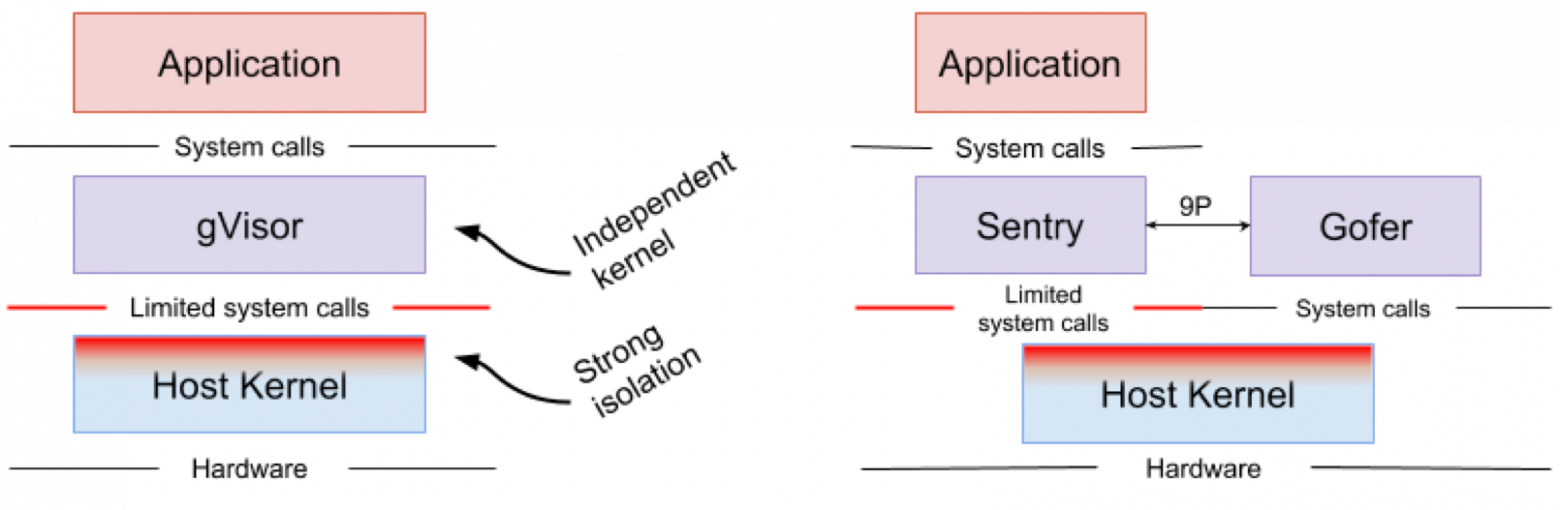
Рисунок 4. Реализация ядра gVisor // Файловые системы Sentry и gVisor Gofer используют небольшое количество системных вызовов для взаимодействия с хостом
gVisor создает прочный периметр безопасности между приложением и его хостом. Он ограничивает системные вызовы, которые могут использовать приложения в пользовательском пространстве. Не полагаясь на виртуализацию, gVisor работает в качестве хост-процесса, который взаимодействует между изолированным приложением и хостом. Sentry поддерживает большинство системных вызовов Linux и основные функции ядра, такие как доставка сигнала, управление памятью, сетевой стек и потоковая модель. В Sentry реализовано более 70% из 319 системных вызовов Linux для поддержки изолированных приложений. При этом для взаимодействия с ядром хоста Sentry использует менее 20 системных вызовов Linux. Стоит отметить, что у gVisor и Nabla очень похожая стратегия: защита хостовой ОС и оба этих решения используют менее 10% системных вызовов Linux для взаимодействия с ядром. Но нужно понимать, что gVisor создает многоцелевое ядро, а, например, Nabla полагается на уникальные ядра. При этом оба решения запускают специализированное гостевое ядро в пользовательском пространстве для поддержки доверенных им изолированных приложений.
Кто-то может задаться вопросом, зачем gVisor необходимо собственное ядро, когда ядро Linux и так обладает открытым исходным кодом и легкодоступно. Так вот, Ядро gVisor, написанное на Golang, более безопасно, чем ядро Linux, написанное на C. Все благодаря мощным функциям безопасности типов и управления памятью в Golang. Еще один важный момент касательно gVisor — тесная интеграция с Docker, Kubernetes и стандартом OCI. Большинство образов Docker можно просто извлечь и запустить с помощью gVisor, изменив среду выполнения на gVisor runsc. В случае Kubernetes вместо «песочницы» для каждого отдельно взятого контейнера в gVisor можно запустить целую «песочницу»-модуль.
Поскольку gVisor все еще находится в зачаточном состоянии, у него существуют некоторые ограничения. Когда gVisor перехватывает и обрабатывает системный вызов, созданный приложением из песочницы, всегда возникают издержки, поэтому он не подходит для тяжелых приложений. (Обратите внимание, что в Nabla нет таких проблем, поскольку приложения unikernel не создают системные вызовы. Nabla использует семь системных вызовов только для обработки hypercall). У gVisor нет прямого аппаратного доступа (passthrough), поэтому приложения, которым он требуется, например, к GPU, не могут работать в нем. Наконец, поскольку gVisor поддерживает только 70% системных вызов Linux, приложения, использующие вызовы не вошедшие в список поддержки, не могут запускаться в gVisor.
Amazon Firecracker — это технология, которая сегодня используется в AWS Lambda и AWS Fargate. Это гипервизор, который создает «легкие виртуальные машины» (MicroVM) специально для multi-tenant контейнеров и бессерверных операционных моделей. До появления Firecracker функции Lambda и Fargate для каждого клиента работали внутри выделенных виртуальных машин EC2 для того, чтобы обеспечить надежную изоляцию. Хотя виртуальные машины и обеспечивают достаточную изоляцию для контейнеров в общедоступном облаке, использование и виртуальных машин общего назначения, и виртуальных машин для приложений с изолированными средами не очень эффективно с точки зрения потребляемых ресурсов. Firecracker решает проблемы как безопасности, так и производительности, будучи предназначенным специально для облачных приложений. Гипервизор Firecracker предоставляет каждой гостевой виртуальной машине минимальные функциональные возможности ОС и эмулируемые устройства для повышения как безопасности, так и производительности. Пользователи с помощью двоичного файла ядра Linux и образа файловой системы ext4 могут легко создавать образы виртуальных машин. Amazon начал разработку Firecracker в 2017 году, а в 2018 году открыл исходный код проекта сообществу.
Подобно концепции unikernel, Firecracker предоставляет только небольшое подмножество функций для обеспечения работоспособности контейнерных операций. По сравнению с традиционными виртуальными машинами micro-VM имеют гораздо меньшее количество потенциальных уязвимостей, а также потребляемый объем памяти и время запуска. Практика показывает, что micro-VM от Firecracker потребляет около 5 Мб памяти и загружается за ~125 мс при работе на хосте с конфигурацией 2 CPU + 256 Гб RAM. На рисунке 5 показана архитектура Firecracker и ее периметр безопасности.
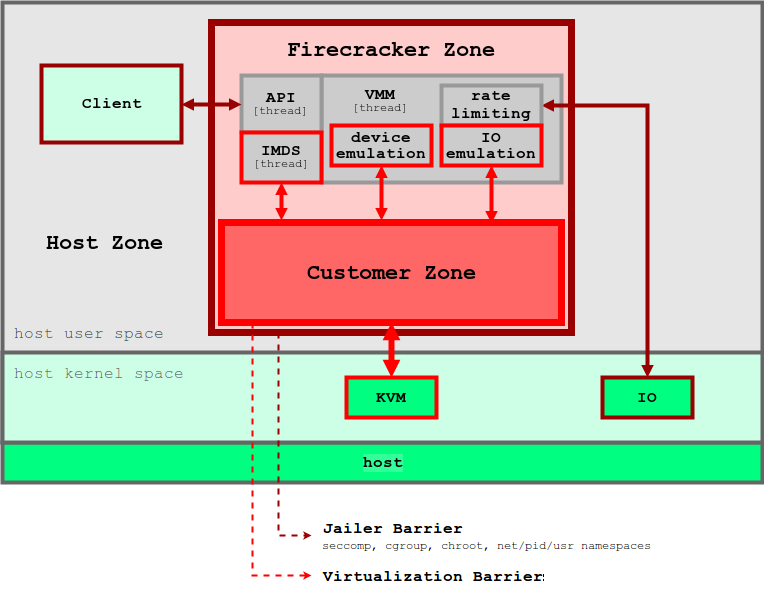
Рисунок 5. Гипервизор Firecracker использует уровни безопасности для изоляции приложений каждого отдельного пользователя
Firecracker основан на KVM, и каждый экземпляр запускается как процесс в пользовательском пространстве. Каждый процесс Firecracker заблокирован политиками seccomp, cgroups и namespaces, поэтому системные вызовы, аппаратные ресурсы, файловая система и сетевые действия для него строго ограничены. Внутри каждого процесса Firecracker есть несколько потоков. Так, поток API дает возможность управления между клиентами на хосте и microVM. Поток гипервизора предоставляет собой минимальный набор устройств virtIO (сеть и блок). Firecracker дает только четыре эмулируемых устройства для каждого microVM: virtio-block, virtio-net, serial console и 1-button контроллер клавиатуры, предназначенный только для остановки microVM. В целях все той же безопасности виртуальные машины не имеют механизма обмена файлами с хостом. Данные на хосте, например образы контейнеров, взаимодействуют с microVM через File Block Devices, а сетевые интерфейсы поддерживаются через сетевой мост. Все исходящие пакеты копируются на выделенное устройство, а их скорость ограничивается политикой cgroups. Все эти меры предосторожности и обеспечения информационной безопасности гарантируют, что вероятность влияния одного приложения на прочие будет сведена к минимуму.
На момент написания этого поста Firecracker еще не до конца прошел процесс интеграции с Docker и Kubernetes. Firecracker не поддерживает сквозное подключение аппаратного обеспечения, поэтому приложения, которым необходим графический процессор или любой ускоритель доступа к устройствам, несовместимы с ним. Он также имеет ограниченные возможности по обмену файлами между виртуальными машинами и примитивную сетевую модель. Тем не менее, поскольку проект разрабатывается крупным сообществом, скоро он должен быть подведен под стандарт OCI и начать поддерживать больше приложений.
Видя проблемы безопасности традиционных контейнеров, в 2015 году компания Intel представила технологию собственной разработки на базе виртуальных машин Clear Containers. Clear Containers основываются на аппаратной технологии виртуализации Intel VT и сильно модифицированном гипервизоре QEMU-KVM
Kata полностью интегрирован с OCI, интерфейсом выполнения контейнера (CRI) и сетевым интерфейсом (CNI). Он поддерживает различные типы сетевых моделей (например, passthrough, MacVTap, bridge, tc mirroring) и настраиваемые гостевые ядра, так что на нем могут работать все приложения, требующие специальных сетевых моделей или версий ядра. На рисунке 6 показано, как контейнеры внутри виртуальных машин Kata взаимодействуют с существующими платформами оркестрации.
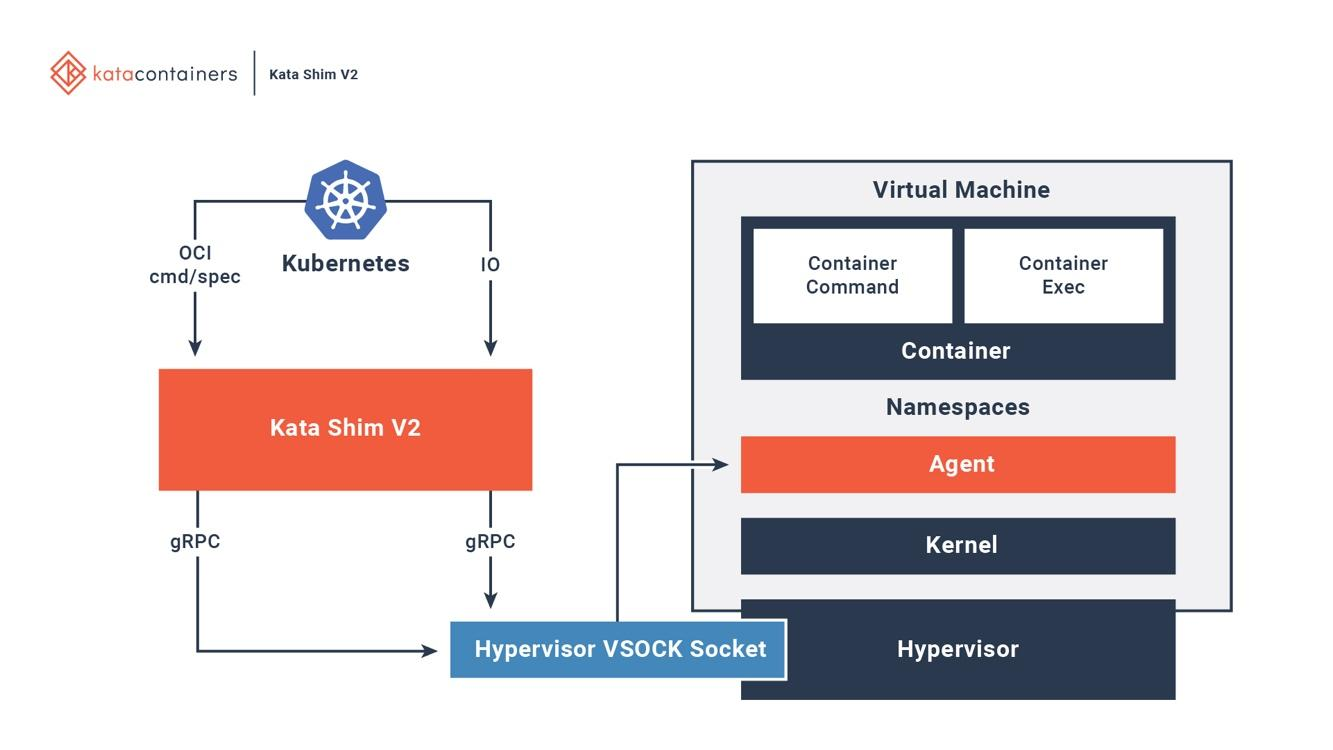
Рисунок 6. Полная интеграция контейнеров Kata с Docker и Kubernetes
На хосте Kata есть среда запуска и настройки. Для каждого контейнера в виртуальной машине Kata на хосте есть соответствующий Kata Shim, который получает запросы API от клиентов (например, docker или kubectl) и направляет запросы агенту внутри виртуальной машины через VSock. Дополнительно Kata оптимизирует время загрузки. NEMU — это облегченная версия QEMU из которой удалено ~80% устройств и пакетов. VM-Templating создает клон запущенного экземпляра Kata VM и делится им с другими только что созданными ВМ. Это значительно сокращает время загрузки и потребление памяти гостевой машиной, но может привести к уязвимости для атак по побочным каналам, к примеру, по CVE-2015-2877. Возможность подключения «на горячую» позволяет ВМ загружаться с минимальным количеством ресурсов (например, ЦП, памятью, блоком virtio), а позже добавлять недостающее по запросу.
Контейнеры Kata и Firecracker — это технология «песочницы» на основе виртуальной машины, разработанная для облачных приложений. У них одна цель, но разные подходы. Firecracker — это специализированный гипервизор, который создает безопасную среду виртуализации для гостевых ОС, в то время как контейнеры Kata — это легкие виртуальные машины, которые хорошо оптимизированы под свои задачи. Были и попытки запустить контейнеры Kata на Firecracker. Хотя эта идея все еще находится в стадии эксперимента, потенциально она может объединить лучшие черты двух проектов.
Мы рассмотрели несколько решений, цель которых — помочь с проблемой слабой изоляции современных контейнерных технологий.
IBM Nabla — это решение на основе unikernel, которое упаковывает приложения в специализированную виртуальную машину.
Google gVisor — это объединение специализированного ядра гипервизора и гостевой ОС, которое создает безопасный интерфейс между приложениями и их хостом.
Amazon Firecracker — это специализированный гипервизор, который предоставляет каждой гостевой ОС минимальный набор аппаратных и ядерных ресурсов.
OpenStack Kata — это высокооптимизированная виртуальная машина со встроенным контейнерным движком, которая может работать на различных гипервизорах.
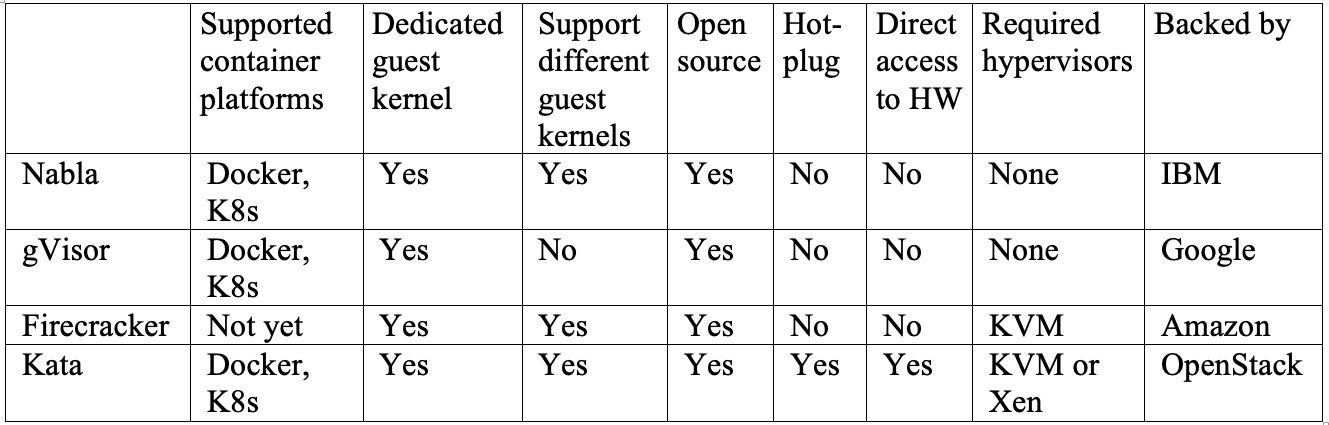
Трудно сказать, какое из этих решений работает лучше всего, так как все они обладают своими плюсами и минусами. Таблица в конце статьи проводит параллельное сравнение некоторых важных функций всех четырех проектов. Nabla будет лучшим выбором, если у вас есть приложения, работающие в unikernel-системах, таких как MirageOS или IncludeOS. gVisor сейчас лучше всего интегрируется с Docker и Kubernetes, но из-за неполного покрытия системных вызовов некоторые приложения с ним несовместимы. Firecracker поддерживает настраиваемые образы гостевой ОС и это хороший выбор, если ваши приложения должны запускаться в настроенной виртуальной машине. Контейнеры Kata полностью соответствуют стандарту OCI и могут работать как на KVM, так и на гипервизоре Xen. Это может упростить развертывание микросервисов на гибридных платформах.

Для того, чтобы одно из решений стало стандартом, может потребоваться время, но уже сейчас хорошо и то, что большинство крупных облачных провайдеров начали искать пути решения существующих проблем.

Корень нашей проблемы заключается в слабом разграничении контейнеров в моменте, когда операционная система хоста создает виртуальную область пользователя для каждого из них. Да, были проведены исследования и разработки, направленные на создание настоящих «контейнеров» с полноценной «песочницей». И большинство полученных решений ведут к перестройке границ между контейнерами для усиления их изоляции. В этой статье мы рассмотрим четыре уникальных проекта от IBM, Google, Amazon и OpenStack соответственно, в которых используются разные методы для достижения одной и той же цели: создания надежной изоляции. Так, IBM Nabla разворачивает контейнеры поверх Unikernel, Google gVisor создает специализированное гостевое ядро, Amazon Firecracker использует чрезвычайно легкий гипервизор для приложений песочницы, а OpenStack помещает контейнеры в специализированную виртуальную машину, оптимизированную для инструментов оркестрации.
Обзор современной контейнерной технологии
Контейнеры — это современный способ упаковки, совместного использования и развертывания приложения. В отличие от монолитного приложения, в котором все функции упакованы в одну программу, контейнерные приложения или микросервисы предназначены для целенаправленного узкого использования и специализируются только на одной задаче.
Контейнер включает в себя все зависимости (например, пакеты, библиотеки и двоичные файлы), которые необходимы приложению для выполнения своей конкретной задачи. В результате, контейнеризованные приложения не зависят от платформы и могут работать в любой операционной системе независимо от ее версии или установленных пакетов. Это удобство избавляет разработчиков от огромного куска работы по адаптации разных версий программного обеспечения для разных платформ или клиентов. Хотя концептуально это не совсем точно, многим людям нравится думать о контейнерах как об «облегченных виртуальных машинах».
Когда контейнер развертывается на хосте, ресурсы каждого контейнера, такие как его файловая система, процесс и сетевой стек, помещаются в фактически изолированную среду, к которой другие контейнеры не могут получить доступ. Эта архитектура позволяет одновременно запускать сотни и тысячи контейнеров в одном кластере, а каждое приложение (или микросервис) можно потом легко масштабировать путем репликации бо́льшего количества экземпляров.
При этом разверстка контейнера основывается на двух ключевых «строительных блоках»: пространстве имен Linux и контрольных группах Linux (cgroups).
Пространство имен создает практически изолированное пользовательское пространство и предоставляет приложению выделенные системные ресурсы, такие как файловая система, сетевой стек, идентификатор процесса и идентификатор пользователя. В этом изолированном пользовательском пространстве приложение контролирует корневой каталог файловой системы и может запускаться от имени root. Это абстрактное пространство позволяет каждому приложению работать независимо, не мешая при этом жить другим приложениям на том же хосте. Сейчас доступно шесть пространств имен: mount, inter-process communication (ipc), UNIX time-sharing system (uts), process id (pid), network и user. Этот список предлагается дополнить еще двумя дополнительными пространствами имен: time и syslog, но сообщество Linux все еще не определилось с окончательными спецификациями.
Cgroups обеспечивают ограничение аппаратных ресурсов, расстановку приоритетов, мониторинг и контроль приложения. В качестве примера аппаратных ресурсов, которыми они могут управлять, можно назвать процессор, память, устройство и сеть. При объединении пространства имен и cgroups, мы можем безопасно запускать несколько приложений на одном хосте, причем каждое приложение находится в своей изолированной среде — что есть фундаментальное свойство контейнера.
Основное же различие между виртуальной машиной (ВМ) и контейнером заключается в том, что виртуальная машина — это виртуализация на аппаратном уровне, а контейнер — виртуализация на уровне операционной системы. Гипервизор ВМ эмулирует аппаратную среду для каждой машины, где уже среда выполнения контейнера в свою очередь эмулирует операционную систему для каждого объекта. Виртуальные машины совместно используют физическое оборудование хоста, а контейнеры — как оборудование, так и ядро ОС. Поскольку контейнеры в целом разделяют с хостом большее количество ресурсов, их работа с хранилищем, памятью и циклами ЦП намного эффективнее, чем у виртуальной машины. Однако недостатком такого общего доступа является проблемы в плоскости информационной безопасноти, так как между контейнерами и хостом устанавливается слишком большое доверие. Рисунок 1 иллюстрирует архитектурную разницу между контейнером и виртуальной машиной.
В целом, изоляция виртуализированного оборудования создает гораздо более прочный периметр безопасности, нежели просто изоляция именного пространства. Риск того, что злоумышленник успешно покинет изолированный процесс, намного выше, чем шанс успешного выхода за пределы виртуальной машины. Причиной более высокого риска выхода за пределы ограниченной среды контейнеров является слабая изоляция, создаваемая пространством имен и cgroups. Linux реализует их, связывая новые поля свойств с каждым процессом. Эти поля в файловой системе
/proc указывают операционной системе хоста, может ли один процесс видеть другой, или сколько ресурсов процессора/памяти может использовать какой-то конкретный процесс. При просмотре запущенных процессов и потоков из родительской ОС (например, команды top или ps) контейнерный процесс выглядит так же, как любой другой. Как правило, традиционные решения, такие как LXC или Docker, не считаются полноценно изолированными, поскольку они используют одно и то же ядро в рамках одного хоста. Поэтому, не удивительно, что у контейнеров имеется достаточное количество уязвимостей. Например, CVE-2014-3519, CVE-2016-5195, CVE-2016-9962, CVE-2017-5123 и CVE-2019-5736 могут привести получению злоумышленником доступа к данным за пределами контейнера. Большинство эксплойтов ядра создают вектор для успешной атаки, поскольку обычно они выливаются в повышение привилегий и позволяют скомпрометированному процессу получить контроль за пределами своего предполагаемого именного пространства. Помимо векторов атак в контексте уязвимостей программного обеспечения, свою роль может сыграть и неправильная конфигурация. Например развертывание образов с чрезмерными привилегиями (CAP_SYS_ADMIN, привилегированный доступ) или критические точки монтирования (
/var/run/docker.sock), могут привести к утечке. Учитывая эти потенциально катастрофические последствия, следует понимать риск, на который вы идете при развертывании системы в мультиарендном пространстве или при использовании контейнеров для хранения конфиденциальных данных.Эти проблемы мотивируют исследователей создавать более прочные периметры безопасности. Идея состоит в том, чтобы создать настоящий sandbox-контейнер, максимально изолированный от основной ОС. Большинство подобных решений включают в себя разработку гибридной архитектуры, которая использует строгое разграничение приложения и виртуальной машины, и фокусируется на повышении эффективности контейнерных решений.
На момент написания статьи не было ни одного проекта, который можно было бы назвать достаточно зрелым, чтобы его можно было принять за стандарт, но в будущем разработчики несомненно, примут некоторые из этих концепций в качестве основных.
Начнем свой обзор с Unikernel, самой старой узкоспециализированной системы, которая упаковывает приложение в один образ с использованием минимального набора библиотек ОС. Сама концепция Unikernel оказалась фундаментальной для множества проектов, целью которых было создание безопасных, компактных и оптимизированных образов. После мы перейдем к рассмотрению IBM Nabla — проекта по запуску приложений Unikernel, в том числе контейнеров. Кроме этого у нас есть Google gVisor — проект для запуска контейнеров в пространстве пользовательского ядра. Далее мы переключимся на контейнерные решения на основе виртуальных машин — Amazon Firecracker и OpenStack Kata. Подытожим этот пост сравнением всех вышеупомянутых решений.
Unikernel
Развитие технологий виртуализации позволило нам перейти к облачным вычислениям. Гипервизоры типа Xen и KVM заложили фундамент того, что мы сейчас знаем как Amazon Web Services (AWS) и Google Cloud Platform (GCP). И хотя современные гипервизоры способны работать с сотней виртуальных машин, объединенных в единый кластер, традиционные операционные системы общего назначения не слишком приспособлены и оптимизированы для работы в подобном окружении. ОС общего назначения предназначена, в первую очередь, для поддержки и работы с как можно большим числом разнообразных приложений, поэтому их ядра включают в себя все виды драйверов, библиотек, протоколов, планировщиков и так далее. Однако большинство виртуальных машин, развернутых сейчас где-то в облаке, используются для работы какого-то одного приложения, например, для обеспечения работы DNS, прокси или какой-то базы данных. Поскольку такое отдельно взятое приложение опирается в своей работе только на конкретный и небольшой участок ядра ОС, все остальные его «обвесы» просто вхолостую тратят системные ресурсы, а самим фактом своего существования увеличивают количество векторов для потенциальной атаки. Ведь чем больше кодовая база, тем сложнее устранить все недостатки, и тем больше потенциальных уязвимостей, ошибок и прочих слабых мест. Эта проблема побуждает специалистов к разработке узкоспециализированных ОС с минимальным набором функциональных возможностей ядра, то есть к созданию инструментов для поддержки одного конкретного приложения.
Впервые идея Unikernel родилась еще в 90-х годах. Тогда же он оформился как специализированный образ машины с единым адресным пространством, который может работать непосредственно на гипервизорах. Он упаковывает основное и зависящие от него приложения и функции ядра в единый образ. Nemesis и Exokernel — две самые ранние исследовательские версии проекта Unikernel. Процесс упаковки и развертывания показан на рисунке 2.
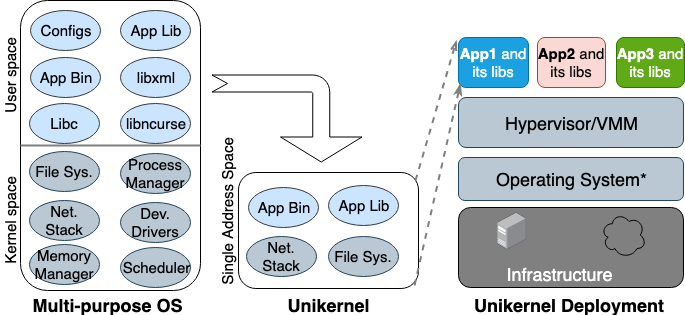
Рисунок 2. Многоцелевые операционные системы созданы для поддержки всех типов приложений, поэтому многие библиотеки и драйверы загружены в них заранее. Unikernels — это узкоспециализированные ОС, которые созданы для поддержки одного конкретного приложения.
Unikernel разбивает ядро на несколько библиотек и помещает в образ только необходимые компоненты. Как и обычные виртуальные машины, unikernel развертывается и работает на гипервизоре ВМ. Благодаря небольшим размерам он может быстро загружаться и также быстро масштабироваться. Наиболее важные свойства Unikernel — это повышенная безопасность, небольшой занимаемый объем, высокая степень оптимизации и быстрая загрузка. Поскольку эти образы содержат только зависимые от приложения библиотеки, и оболочка ОС недоступна, если она не была подключена целенаправленно, то и количество векторов атаки, которую могут использовать злоумышленники на них минимально.
То есть, атакующим не только трудно закрепиться в этих уникальных ядрах, но и их влияние также ограничивается одним экземпляром ядра. Поскольку размер образов Unikernel составляет всего несколько мегабайт, они загружаются за десятки миллисекунд, а на одном хосте могут запускаться буквально сотни его экземпляров. Используя выделение памяти в одном адресном пространстве вместо многоуровневой таблицы страниц, как это происходит в большинстве современных ОС, приложения unikernel имеют меньшую задержку доступа к памяти по сравнению с тем же приложением, работающем на обычной виртуальной машине. Поскольку приложения собираются вместе с ядром при построении образа, компиляторы могут выполнять просто статическую проверку типов для оптимизации двоичных файлов.
Сайт Unikernel.org ведет список проектов unikernel. Но со всеми своими отличительными особенностями и свойствами unikernel не получил большого распространения. Когда в 2016 году Docker приобрел Unikernel Systems, сообщество решило, что теперь компания будет упаковывать контейнеры в них. Но прошло уже три года, а признаков интеграции все еще нет. Одна из основных причин такого медленного внедрения заключается в том, что до сих пор нет зрелого инструмента для создания приложений Unikernel, а большинство таких приложений могут работать только на определенных гипервизорах. Кроме того, портирование приложения в unikernel может потребовать ручного переписывания кода на других языках, включая переписывание зависимых библиотек ядра. Важно и то, что мониторинг или отладка в unikernels либо невозможны, либо оказывают значительное влияние на производительность.
Все эти ограничения удерживают разработчиков от перехода на данную технологию. Следует отметить, что unikernel и контейнеры имеют много похожих свойств. И первые, и вторые являются узконаправленными неизменяемыми образами, а это означает, что компоненты внутри них не могут быть обновлены или исправлены, то есть для патча приложения всегда приходится создавать новый образ. Сегодня Unikernel похож на предка Docker: тогда среда выполнения контейнера была недоступна, и разработчикам приходилось использовать базовые инструменты построения изолированной среды приложения (chroot, unshare и cgroups).
IBM Nabla
Когда-то исследователи из IBM предложили концепцию «Unikernel как процесс» — то есть приложение unikernel, которое бы исполнялось как процесс на специализированном гипервизоре. Проект IBM «Nabla containers» усилял периметр безопасности unikernel, заменив универсальный гипервизор (к примеру, QEMU) на собственную разработку под названием Nabla Tender. Обоснование подобного подхода заключается в том, что вызовы между unikernel и гипервизором по-прежнему предоставляют наибольшее количество векторов для атаки. Именно поэтому использование выделенного для unikernel гипервизора с меньшим количеством разрешенных системных вызовов может значительно укрепить периметр безопасности. Nabla Tender перехватывает вызовы, которые unikernel направляет в гипервизор, и уже самостоятельно переводит их в системные запросы. При этом политика seccomp Linux блокирует все прочие системные вызовы, которые не нужны для работы Tender. Таким образом, Unikernel в связке с Nabla Tender запускается в качестве процесса в пользовательском пространстве хоста. Ниже, на рисунке №3, отражено, как Nabla создает тонкий интерфейс между unikernel и хостом.
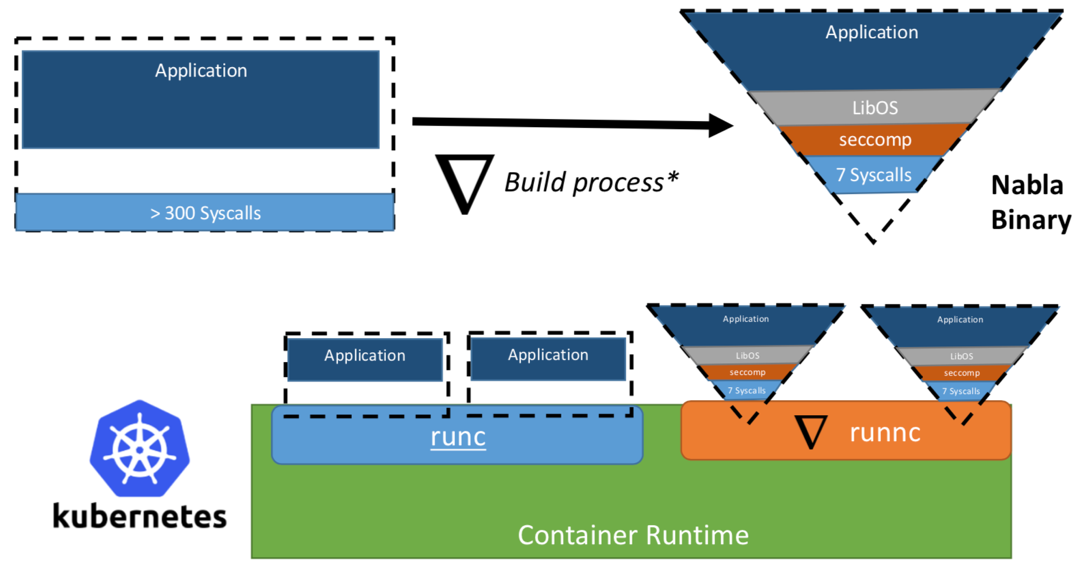
Рисунок 3. Чтобы увязать Nabla с существующими платформами среды выполнения контейнеров, Nabla использует среду, совместимую с OCI, которую в свою очередь можно подключить к Docker или Kubernetes.
Разработчики утверждают, что Nabla Tender использует в своей работе менее семи системных вызовов для взаимодействия с хостом. Так как системные вызовы служат своеобразным мостом между процессами в пользовательском пространстве и ядром операционной системы, то чем меньше нам доступно системных вызовов, тем меньше и количество доступных векторов для атаки на ядро. Еще одно преимущество запуска unikernel как процесса заключается в том, что отладку подобных приложений можно проводить с помощью большого количества инструментов, например, с помощью gdb.
Для работы с платформами оркестрации контейнеров Nabla предоставляет выделенную среду выполнения
runnc, которая реализована по стандарту Open Container Initiative (OCI). Последний определяет API между клиентами (например Docker, Kubectl) и средой времени выполнения (e.g., runc). С Nabla также поставляется конструктор образов, которые в последующем сможет запустить runnc. При этом из-за различий в файловой системе между unikernels и традиционными контейнерами, образы Nabla не соответствуют спецификациями образа OCI и, следовательно, образы Docker не совместимы с runnc. На момент написания статьи проект все еще находится в стадии ранней разработки. Существуют и другие ограничения, например, отсутствие поддержки для монтирования/доступа к файловым системам хоста, добавления нескольких сетевых интерфейсов (необходимых для Kubernetes) или использования образов из других образов unikernel (например, MirageOS).Google gVisor
Google gVisor — это технология «песочницы», использующая механизм приложений Google Cloud Platform (GCP), облачные функции и CloudML. В какой-то момент компания Google осознала риск запуска ненадежных приложений в инфраструктуре публичного облака и неэффективность приложений песочницы с использованием виртуальных машин. В итоге было разработано ядро пользовательского пространства для изолированной среды таких ненадежных приложений. gVisor помещает эти приложения в песочницу, перехватывая все системные вызовы от них к ядру хоста и обрабатывая их в пользовательской среде с помощью ядра gVisor Sentry. По сути, он функционирует как комбинация гостевого ядра и гипервизора. На рисунке 4 показана архитектура gVisor.
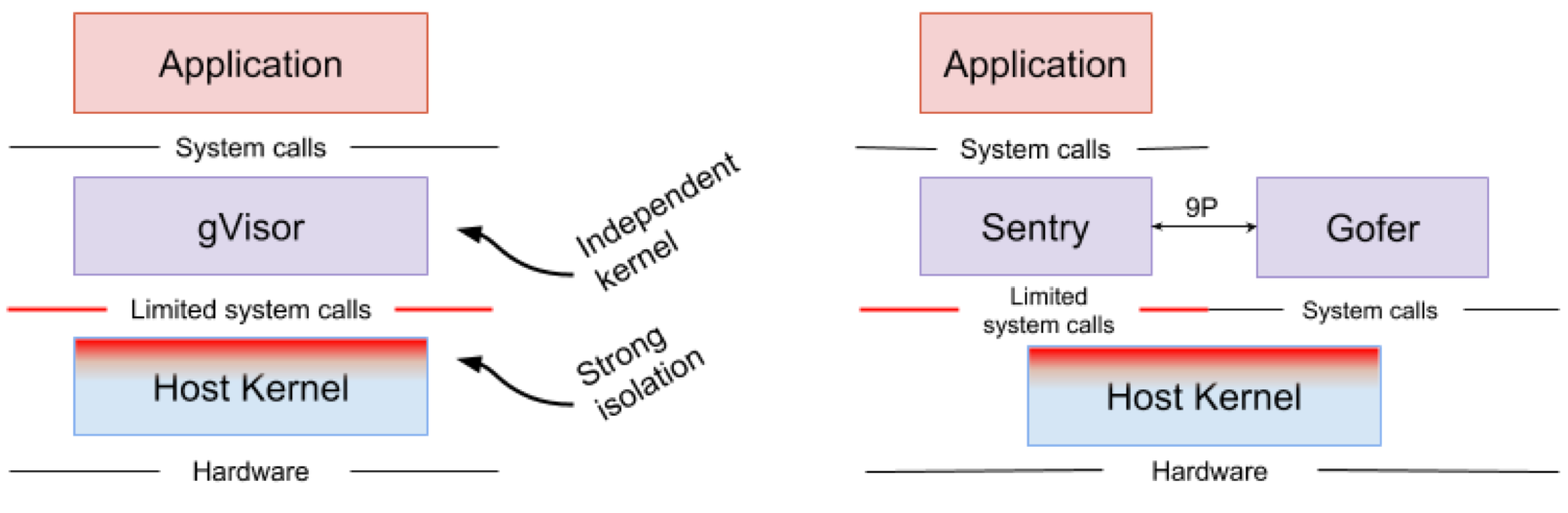
Рисунок 4. Реализация ядра gVisor // Файловые системы Sentry и gVisor Gofer используют небольшое количество системных вызовов для взаимодействия с хостом
gVisor создает прочный периметр безопасности между приложением и его хостом. Он ограничивает системные вызовы, которые могут использовать приложения в пользовательском пространстве. Не полагаясь на виртуализацию, gVisor работает в качестве хост-процесса, который взаимодействует между изолированным приложением и хостом. Sentry поддерживает большинство системных вызовов Linux и основные функции ядра, такие как доставка сигнала, управление памятью, сетевой стек и потоковая модель. В Sentry реализовано более 70% из 319 системных вызовов Linux для поддержки изолированных приложений. При этом для взаимодействия с ядром хоста Sentry использует менее 20 системных вызовов Linux. Стоит отметить, что у gVisor и Nabla очень похожая стратегия: защита хостовой ОС и оба этих решения используют менее 10% системных вызовов Linux для взаимодействия с ядром. Но нужно понимать, что gVisor создает многоцелевое ядро, а, например, Nabla полагается на уникальные ядра. При этом оба решения запускают специализированное гостевое ядро в пользовательском пространстве для поддержки доверенных им изолированных приложений.
Кто-то может задаться вопросом, зачем gVisor необходимо собственное ядро, когда ядро Linux и так обладает открытым исходным кодом и легкодоступно. Так вот, Ядро gVisor, написанное на Golang, более безопасно, чем ядро Linux, написанное на C. Все благодаря мощным функциям безопасности типов и управления памятью в Golang. Еще один важный момент касательно gVisor — тесная интеграция с Docker, Kubernetes и стандартом OCI. Большинство образов Docker можно просто извлечь и запустить с помощью gVisor, изменив среду выполнения на gVisor runsc. В случае Kubernetes вместо «песочницы» для каждого отдельно взятого контейнера в gVisor можно запустить целую «песочницу»-модуль.
Поскольку gVisor все еще находится в зачаточном состоянии, у него существуют некоторые ограничения. Когда gVisor перехватывает и обрабатывает системный вызов, созданный приложением из песочницы, всегда возникают издержки, поэтому он не подходит для тяжелых приложений. (Обратите внимание, что в Nabla нет таких проблем, поскольку приложения unikernel не создают системные вызовы. Nabla использует семь системных вызовов только для обработки hypercall). У gVisor нет прямого аппаратного доступа (passthrough), поэтому приложения, которым он требуется, например, к GPU, не могут работать в нем. Наконец, поскольку gVisor поддерживает только 70% системных вызов Linux, приложения, использующие вызовы не вошедшие в список поддержки, не могут запускаться в gVisor.
Amazon Firecracker
Amazon Firecracker — это технология, которая сегодня используется в AWS Lambda и AWS Fargate. Это гипервизор, который создает «легкие виртуальные машины» (MicroVM) специально для multi-tenant контейнеров и бессерверных операционных моделей. До появления Firecracker функции Lambda и Fargate для каждого клиента работали внутри выделенных виртуальных машин EC2 для того, чтобы обеспечить надежную изоляцию. Хотя виртуальные машины и обеспечивают достаточную изоляцию для контейнеров в общедоступном облаке, использование и виртуальных машин общего назначения, и виртуальных машин для приложений с изолированными средами не очень эффективно с точки зрения потребляемых ресурсов. Firecracker решает проблемы как безопасности, так и производительности, будучи предназначенным специально для облачных приложений. Гипервизор Firecracker предоставляет каждой гостевой виртуальной машине минимальные функциональные возможности ОС и эмулируемые устройства для повышения как безопасности, так и производительности. Пользователи с помощью двоичного файла ядра Linux и образа файловой системы ext4 могут легко создавать образы виртуальных машин. Amazon начал разработку Firecracker в 2017 году, а в 2018 году открыл исходный код проекта сообществу.
Подобно концепции unikernel, Firecracker предоставляет только небольшое подмножество функций для обеспечения работоспособности контейнерных операций. По сравнению с традиционными виртуальными машинами micro-VM имеют гораздо меньшее количество потенциальных уязвимостей, а также потребляемый объем памяти и время запуска. Практика показывает, что micro-VM от Firecracker потребляет около 5 Мб памяти и загружается за ~125 мс при работе на хосте с конфигурацией 2 CPU + 256 Гб RAM. На рисунке 5 показана архитектура Firecracker и ее периметр безопасности.
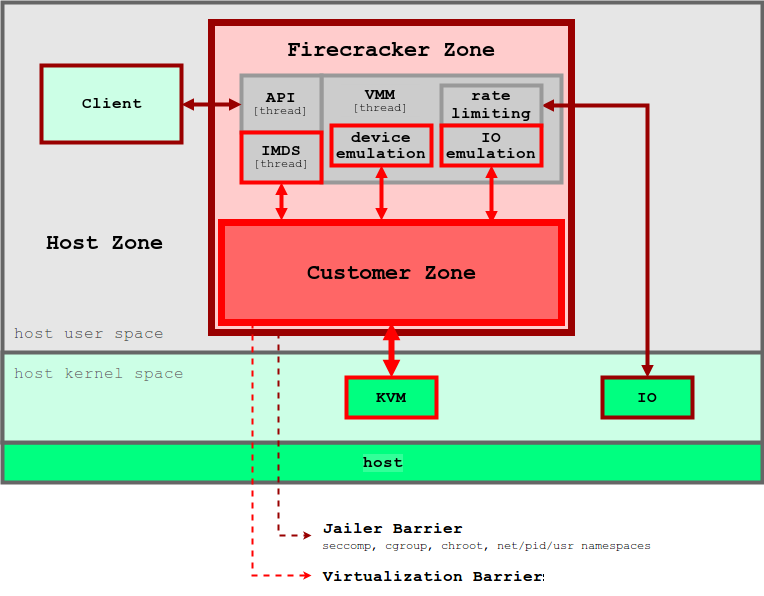
Рисунок 5. Гипервизор Firecracker использует уровни безопасности для изоляции приложений каждого отдельного пользователя
Firecracker основан на KVM, и каждый экземпляр запускается как процесс в пользовательском пространстве. Каждый процесс Firecracker заблокирован политиками seccomp, cgroups и namespaces, поэтому системные вызовы, аппаратные ресурсы, файловая система и сетевые действия для него строго ограничены. Внутри каждого процесса Firecracker есть несколько потоков. Так, поток API дает возможность управления между клиентами на хосте и microVM. Поток гипервизора предоставляет собой минимальный набор устройств virtIO (сеть и блок). Firecracker дает только четыре эмулируемых устройства для каждого microVM: virtio-block, virtio-net, serial console и 1-button контроллер клавиатуры, предназначенный только для остановки microVM. В целях все той же безопасности виртуальные машины не имеют механизма обмена файлами с хостом. Данные на хосте, например образы контейнеров, взаимодействуют с microVM через File Block Devices, а сетевые интерфейсы поддерживаются через сетевой мост. Все исходящие пакеты копируются на выделенное устройство, а их скорость ограничивается политикой cgroups. Все эти меры предосторожности и обеспечения информационной безопасности гарантируют, что вероятность влияния одного приложения на прочие будет сведена к минимуму.
На момент написания этого поста Firecracker еще не до конца прошел процесс интеграции с Docker и Kubernetes. Firecracker не поддерживает сквозное подключение аппаратного обеспечения, поэтому приложения, которым необходим графический процессор или любой ускоритель доступа к устройствам, несовместимы с ним. Он также имеет ограниченные возможности по обмену файлами между виртуальными машинами и примитивную сетевую модель. Тем не менее, поскольку проект разрабатывается крупным сообществом, скоро он должен быть подведен под стандарт OCI и начать поддерживать больше приложений.
OpenStack Kata
Видя проблемы безопасности традиционных контейнеров, в 2015 году компания Intel представила технологию собственной разработки на базе виртуальных машин Clear Containers. Clear Containers основываются на аппаратной технологии виртуализации Intel VT и сильно модифицированном гипервизоре QEMU-KVM
qemu-lite. В конце 2017 года проект Clear Containers присоединился к Hyper RunV, основанной на гипервизоре для OCI, и начал разработку проекта Kata. Унаследовав все свойства Clear Containers, Kata теперь поддерживают более широкий спектр инфраструктур и спецификаций.Kata полностью интегрирован с OCI, интерфейсом выполнения контейнера (CRI) и сетевым интерфейсом (CNI). Он поддерживает различные типы сетевых моделей (например, passthrough, MacVTap, bridge, tc mirroring) и настраиваемые гостевые ядра, так что на нем могут работать все приложения, требующие специальных сетевых моделей или версий ядра. На рисунке 6 показано, как контейнеры внутри виртуальных машин Kata взаимодействуют с существующими платформами оркестрации.
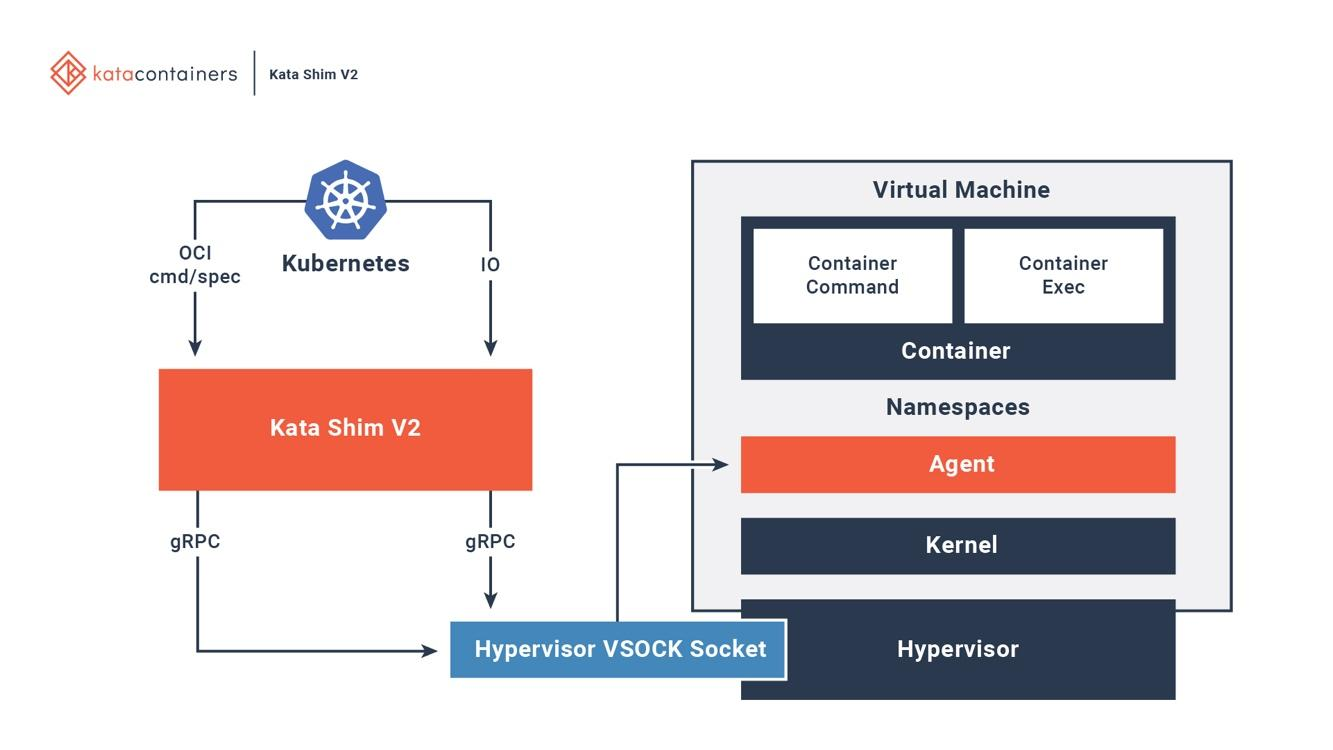
Рисунок 6. Полная интеграция контейнеров Kata с Docker и Kubernetes
На хосте Kata есть среда запуска и настройки. Для каждого контейнера в виртуальной машине Kata на хосте есть соответствующий Kata Shim, который получает запросы API от клиентов (например, docker или kubectl) и направляет запросы агенту внутри виртуальной машины через VSock. Дополнительно Kata оптимизирует время загрузки. NEMU — это облегченная версия QEMU из которой удалено ~80% устройств и пакетов. VM-Templating создает клон запущенного экземпляра Kata VM и делится им с другими только что созданными ВМ. Это значительно сокращает время загрузки и потребление памяти гостевой машиной, но может привести к уязвимости для атак по побочным каналам, к примеру, по CVE-2015-2877. Возможность подключения «на горячую» позволяет ВМ загружаться с минимальным количеством ресурсов (например, ЦП, памятью, блоком virtio), а позже добавлять недостающее по запросу.
Контейнеры Kata и Firecracker — это технология «песочницы» на основе виртуальной машины, разработанная для облачных приложений. У них одна цель, но разные подходы. Firecracker — это специализированный гипервизор, который создает безопасную среду виртуализации для гостевых ОС, в то время как контейнеры Kata — это легкие виртуальные машины, которые хорошо оптимизированы под свои задачи. Были и попытки запустить контейнеры Kata на Firecracker. Хотя эта идея все еще находится в стадии эксперимента, потенциально она может объединить лучшие черты двух проектов.
Заключение
Мы рассмотрели несколько решений, цель которых — помочь с проблемой слабой изоляции современных контейнерных технологий.
IBM Nabla — это решение на основе unikernel, которое упаковывает приложения в специализированную виртуальную машину.
Google gVisor — это объединение специализированного ядра гипервизора и гостевой ОС, которое создает безопасный интерфейс между приложениями и их хостом.
Amazon Firecracker — это специализированный гипервизор, который предоставляет каждой гостевой ОС минимальный набор аппаратных и ядерных ресурсов.
OpenStack Kata — это высокооптимизированная виртуальная машина со встроенным контейнерным движком, которая может работать на различных гипервизорах.
Трудно сказать, какое из этих решений работает лучше всего, так как все они обладают своими плюсами и минусами. Таблица в конце статьи проводит параллельное сравнение некоторых важных функций всех четырех проектов. Nabla будет лучшим выбором, если у вас есть приложения, работающие в unikernel-системах, таких как MirageOS или IncludeOS. gVisor сейчас лучше всего интегрируется с Docker и Kubernetes, но из-за неполного покрытия системных вызовов некоторые приложения с ним несовместимы. Firecracker поддерживает настраиваемые образы гостевой ОС и это хороший выбор, если ваши приложения должны запускаться в настроенной виртуальной машине. Контейнеры Kata полностью соответствуют стандарту OCI и могут работать как на KVM, так и на гипервизоре Xen. Это может упростить развертывание микросервисов на гибридных платформах.
Для того, чтобы одно из решений стало стандартом, может потребоваться время, но уже сейчас хорошо и то, что большинство крупных облачных провайдеров начали искать пути решения существующих проблем.
