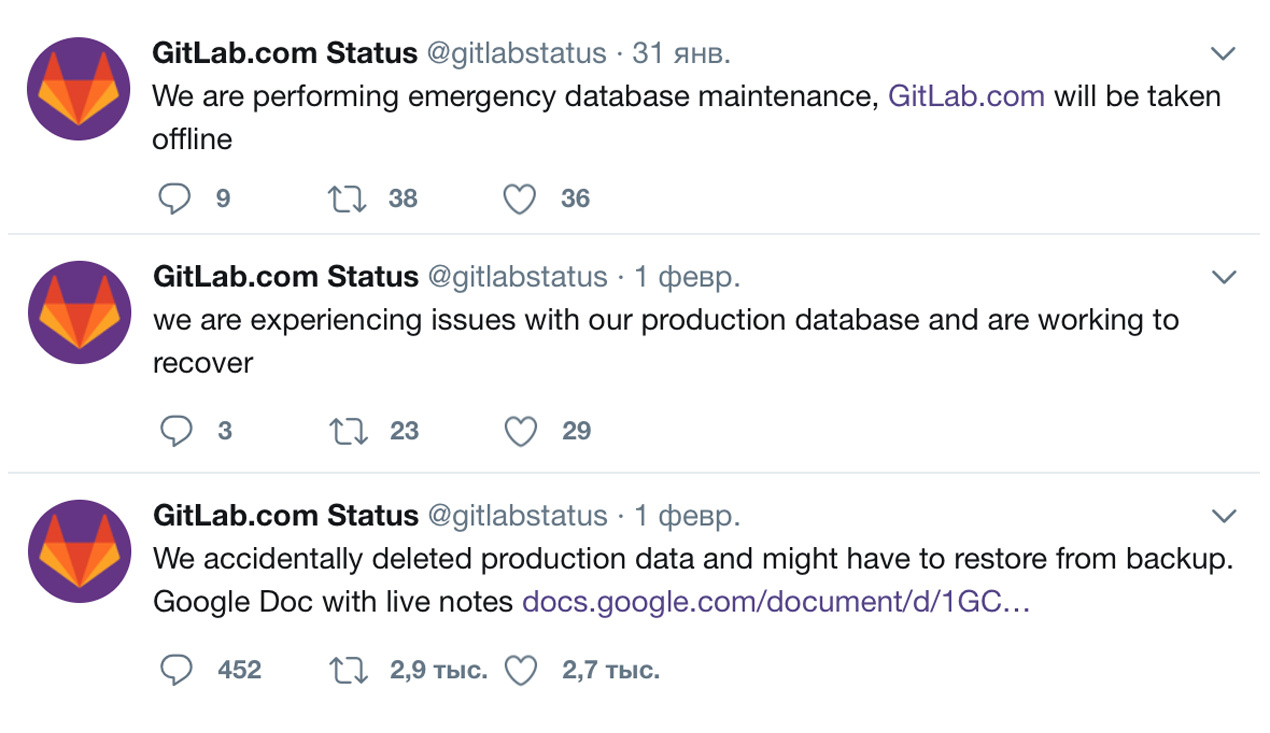
Рассуждать о том, что сайт должен быть доступен всегда — моветон и банальность, но 100% доступность, хотя и является обязательным требованием, чаще всего по-прежнему недоступный идеал. Сейчас на рынке существует масса решений, которые обещают максимальный uptime или предлагают решения для его увеличения, но их применение мало того, что не всегда помогает, в некоторых случаях даже может привести к увеличению рисков и снижению доступности проекта. В этой статье мы пройдемся по классическим ошибкам, которые с которыми мы постоянно сталкиваемся. Большинство проблем — элементарные, однако люди допускают их вновь и вновь.