
Швейцарский стартап DeepCode разрабатывает систему автоматического код-ревью на базе глубинного обучения, сообщает venturebeat. На днях компания закрыла первый инвестиционный раунд и получила на свое развитие $4 млн.
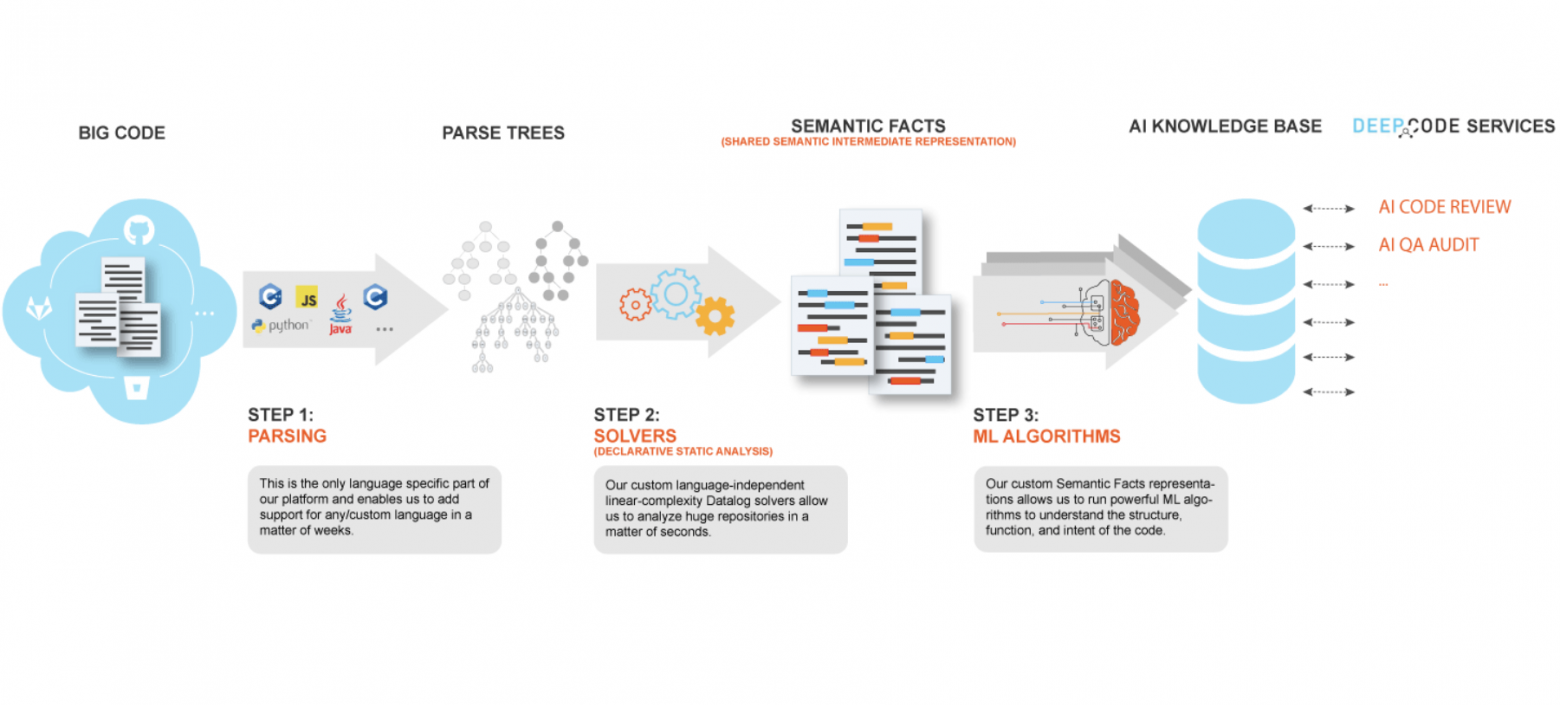
В основе технологии, предлагаемой командой DeepCode, лежит семантический анализ кода вкупе с обучением нейросети с помощью Big Data. Самое интересное в этой разработке то, что в качестве базы данных для обучения сети будет использоваться код публичных репозиториев GitHub.
Кликабельно
Весь процесс разработчики разделяют на несколько этапов. Первый — разметка базы, то есть парсинг самого GitHub и сортировка данных. В качестве главного параметра будет выступать язык программирования, на котором написан проект. Далее идет разметка данных и подготовка спаршенного кода к потреблению нейросетью. Ну и последний, третий этап — это обучение самого DeepCode.
На выходе мы получаем продукт, который способен анализировать загруженный код не только со стороны банального синтаксиса и наличия фактически ошибок, но и с точки зрения его полезности. Как пример приводится анализ пулл-реквестов в мастер на том же гитхабе.
DeepCode будет способен ответить не только на вопрос «сколько в коде ошибок», но и выдать информацию по количеству новых фич и потенциальных конфликтов с имеющейся кодовой базой. То есть разработка способна проводить как код-ревью, так и QA-аудит кода.
Разработчики уверяют, что в отличие от других популярных анализаторов кода DeepCode будет сосредоточен не просто на соблюдении синтаксиса и поиске ошибок форматирования, но сможет выявлять и серьезные проблемы. В пример приводится выявление XSS или SQL-инъекций.
Все это становится доступным именно из-за первоначального источника данных для обучения системы — благодаря open source проектам на GitHub. Именно благодаря открытому исходному коду разработчики могут тренировать сеть не только в разрезе того, как должен выглядеть правильный код, но и добавлять в процесс обучения анализ данных по вносимым изменениям по ходу развития проекта. То есть DeepCode учится не на статичных репозиториях, а анализирует весь когда-либо написанный в рамках проекта код. Таким образом, система может выработать для себя общие принципы анализа и изучить логику разработки, видеть в ходе обучения как сами ошибки, так и пути их исправления.
DeepCode доступен уже в тестовом режиме и опробовать его возможности можно тут после авторизации через GitHub или Bitbucket.
Для тех, кто использует локальные системы хранения кода, команда предлагает возможность интеграции через docker-контейнер, который предоставляется по запросу. Оформить запрос можно по этому адресу электронной почты.
С официальной документацией можно ознакомиться тут.
В основе технологии, предлагаемой командой DeepCode, лежит семантический анализ кода вкупе с обучением нейросети с помощью Big Data. Самое интересное в этой разработке то, что в качестве базы данных для обучения сети будет использоваться код публичных репозиториев GitHub.

Кликабельно
Весь процесс разработчики разделяют на несколько этапов. Первый — разметка базы, то есть парсинг самого GitHub и сортировка данных. В качестве главного параметра будет выступать язык программирования, на котором написан проект. Далее идет разметка данных и подготовка спаршенного кода к потреблению нейросетью. Ну и последний, третий этап — это обучение самого DeepCode.
На выходе мы получаем продукт, который способен анализировать загруженный код не только со стороны банального синтаксиса и наличия фактически ошибок, но и с точки зрения его полезности. Как пример приводится анализ пулл-реквестов в мастер на том же гитхабе.
DeepCode будет способен ответить не только на вопрос «сколько в коде ошибок», но и выдать информацию по количеству новых фич и потенциальных конфликтов с имеющейся кодовой базой. То есть разработка способна проводить как код-ревью, так и QA-аудит кода.
Разработчики уверяют, что в отличие от других популярных анализаторов кода DeepCode будет сосредоточен не просто на соблюдении синтаксиса и поиске ошибок форматирования, но сможет выявлять и серьезные проблемы. В пример приводится выявление XSS или SQL-инъекций.
Все это становится доступным именно из-за первоначального источника данных для обучения системы — благодаря open source проектам на GitHub. Именно благодаря открытому исходному коду разработчики могут тренировать сеть не только в разрезе того, как должен выглядеть правильный код, но и добавлять в процесс обучения анализ данных по вносимым изменениям по ходу развития проекта. То есть DeepCode учится не на статичных репозиториях, а анализирует весь когда-либо написанный в рамках проекта код. Таким образом, система может выработать для себя общие принципы анализа и изучить логику разработки, видеть в ходе обучения как сами ошибки, так и пути их исправления.
DeepCode доступен уже в тестовом режиме и опробовать его возможности можно тут после авторизации через GitHub или Bitbucket.
Для тех, кто использует локальные системы хранения кода, команда предлагает возможность интеграции через docker-контейнер, который предоставляется по запросу. Оформить запрос можно по этому адресу электронной почты.
С официальной документацией можно ознакомиться тут.
