
Недавно заказчик попросил нас реализовать систему учета дисковых мощностей. Стояла задача объединить информацию с более семидесяти дисковых массивов разных вендоров, от свичей SAN и ESX-хостов VMware. Затем данные нужно было систематизировать, проанализировать и иметь возможность выводить на дашборд и различные отчеты, например, о свободном и занятом объеме дискового пространства во всех или отдельно взятых массивах.
Мы решили реализовать проект с помощью системы анализа операционной деятельности — Splunk.
Почему Splunk?
Splunk силен своей визуализацией собранных данных. Он позволяет создавать интерактивные отчеты — дашборды, — обновляемые в режиме реального времени. На них мы вывели информацию об общем дисковом пространстве, отобразили сразу все массивы с возможностью сортировки по разным фильтрам, например, по емкости. Кликнув на массив, мы сразу получаем информацию обо всех подключениях. В отдельной панели можно ввести имя виртуальной машины и увидеть, на каком ESX-хосте она живет, с каких массивов получает данные и другие параметры.
По моему мнению, пока что у Splunk нет аналогов, которые бы из коробки работали с любыми СХД. Несколько лет назад появился платный CommandCentral, но он не обладает нужной гибкостью, не умеет генерировать произвольные отчеты (в первых версиях отчетов вообще не было) и с хромающей визуализацией. В общем, это инструмент не для инвентаризации, а для мониторинга и контроля состояния систем. Чтобы выполнить поставленную заказчиком задачу, его нужно было бы долго и дорого дорабатывать.
В то же время у Splunk впечатляющие возможности отображения информации: графики можно свободно компоновать между собой, отслеживать состояния всех систем в режиме одного окна и, таким образом, упрощать их обслуживания. Ко всему прочему — для нашей задачи мы воспользовались бесплатной версией.

Что делали?
До этого момента у нашей команды не было опыта работы со Splunk. К счастью, система оказалась дружелюбной и интуитивно понятной, а решения возникающих проблем легко находились с помощью штатного хэлпа или в поисковике.
В Splunk оказался встроен ряд нужных нам инструментов. Например, система позволяет объединять данные из разных источников по какому-либо полю через так называемые Lookup’ы (справочники). Так, в одной таблице ESX-хосты отображались в виде IP, в другой — в виде DNS-имён. Сначала мы хотели создать самодельный Lookup и с помощью утилиты nslookup выбирать DNS-записи и собирать таблицы, но оказалось, что в Splunk есть справочник, который сам сопоставляет DNS по IP и наоборот. Этот встроенный Lookup не приходится настраивать, он сам извлекает данные о DNS-серверах из системных настроек, и ему не важно, Windows это или Linux, и данные о DNS-записях всегда актуальны.

Один из интересных сценариев, реализованных с помощью Splunk — контроль изменений (RFC) в системе. К примеру, менеджер RFC получает от инженера запрос на обслуживание одного из свичей SAN. Он вводит в Splunk имя свича и видит, какие хранилища к нему подключены и какие серверы получают данные из этих хранилищ. Одновременно менеджер видит план работ, который написал инженер, и может оценить, как отключение данного свича при проведении обслуживания отразится на производительности массивов и серверов.
Мы настроили ежесуточную загрузку в Splunk информации о подключении всех свичей и массивов. Заказчика устраивает такая частота обновления. У него уже был мониторинговый инструмент Stor2RRD, но тот не умеет объединять данные из разных источников и визуализировать их. Поэтому системe сбора данных в Splunk мы настроили так:
- Получаем от Stor2RRD информацию по хранилищам;
- От свичей получаем информацию по SAN;
- Через vCenter с помощью PowerCLI-скриптов собираем данные от ESX-хостов.
Полученные данные автоматически приводятся в единый вид, обрабатываются и выводятся в виде любых необходимых отчетах.
С чем пришлось бороться?
Splunk — мощная система, но есть задачи, которые из коробки решить не получается, и для решения некоторых задач нужны глубокие знания VMware.
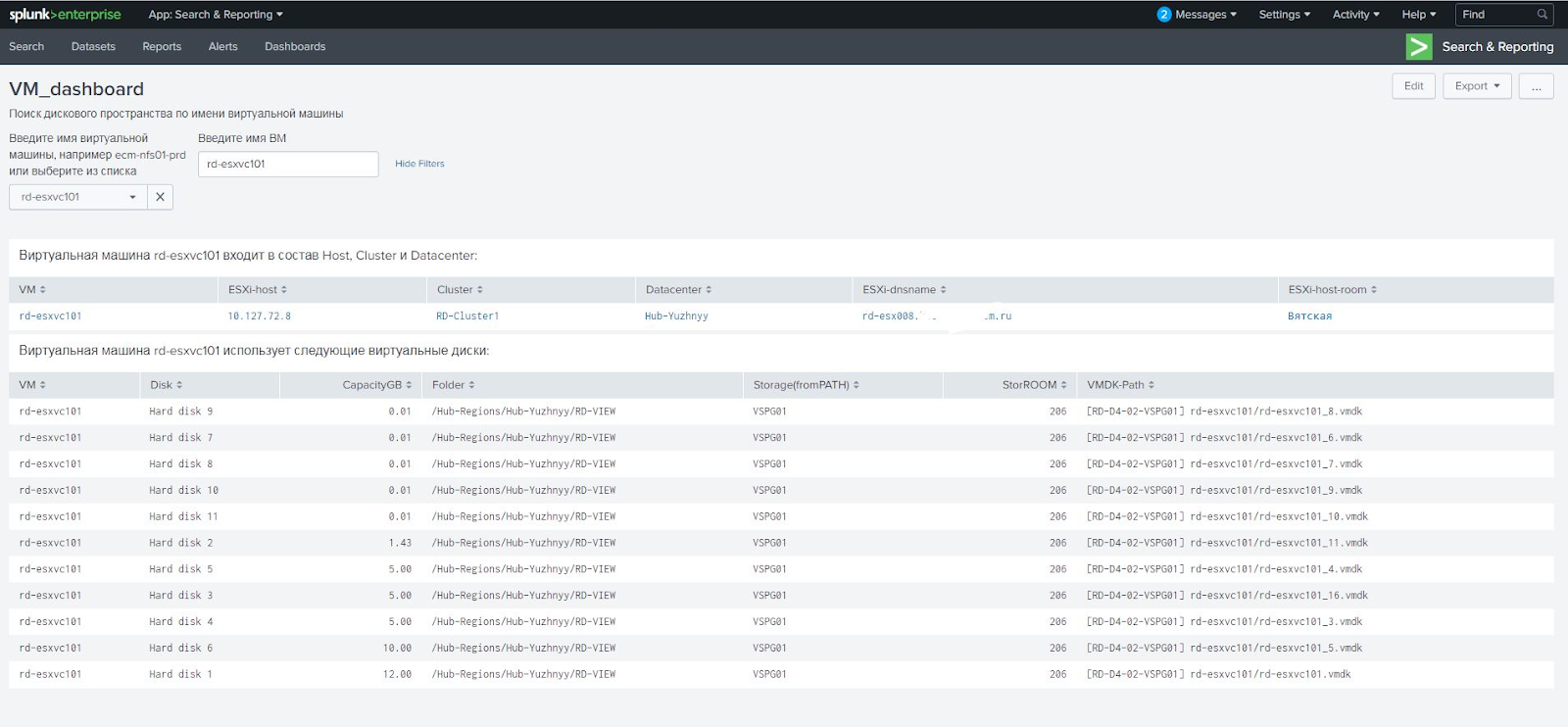
Например, заказчик использует для виртуальных машин и RDM-диски, выделяемые напрямую, и обычные виртуальные датасторы. С этими двумя типами дисков нужно работать по-разному. Сначала мы решили задачу своими силами, но потом столкнулись с ситуацией, когда виртуальная машина получала как RAW-диски, так и виртуальные. Оказалось, что мы получали неправильное поле Path в отчете от vCenter и неверную ссылку на дисковый массив RAW-диска. Схема работает с обычными датасторами, но не работает с RAW-дисками. Для них нужно использовать свойство диска RAW Disk ID, которое содержит признак дискового. Пришлось обратиться к специалистам по VMware, которые переделали скрипт так, чтобы он вычислял правильный массив через RAW Disk ID.
Также мы не сразу научились оптимально работать со скриптами PowerCLI, впоследствии алгоритмы пришлось дорабатывать. Изначально скрипты обрабатывали данные от нескольких тысяч виртуальных машин аж по три часа! После доработки длительность работы скриптов сократилось до сорока минут.
Что в итоге?
Не имея опыта работы со Splunk, мы оперативно реализовали на его основе систему учёта дисковых мощностей, которая получает информацию из многочисленных источников, консолидирует её и выдает широкий набор удобных и наглядных графиков. Если вам раньше не приходилось выбирать или создавать такую систему, то Splunk — удачный кандидат на эту роль. Быстро работает, легко и гибко настраивается и не требует каких-то специализированных знаний для решения подавляющего большинства задач.
Владислав Семенов, Руководитель группы системной архитектуры, Центр проектирования вычислительных комплексов «Инфосистемы Джет»
