
На определенном этапе зрелости ИБ многие компании начинают задумываться о том, как получить и использовать сведения об актуальных для них киберугрозах. В зависимости от отраслевой специфики организации, интерес могут вызывать разные типы угроз. Подход к применению таких сведений был сформирован ещё компанией Lockheed Martin в материале Intelligence Driven Defence.
Благо сейчас у служб ИБ есть масса источников для их получения и даже отдельный класс решений – Threat Intelligence Platform (TIP), который позволяет управлять процессами их получения, генерации и интеграции в средства защиты.
Для нас как центра мониторинга и реагирования на инциденты ИБ крайне важно, чтобы сведения о киберугрозах, которые мы получаем и генерируем, были актуальными, применимыми и, что немаловажно, управляемыми. Ведь от этого зависит безопасность организаций, вверивших нам защиту своей инфраструктуры.
Мы решили поделиться своим видением TI в Jet CSIRT и рассказать о попытках адаптации различных потенциально полезных подходов к управлению сведениями о киберугрозах.
В сфере кибербезопасности мало что работает по принципу set'n'forget. Межсетевой экран не будет блокировать пакеты, пока не настроены фильтры, IPS не найдет признаки вредоносной активности в трафике, пока на него не загрузят сигнатуры, а SIEM не начнет самостоятельно писать правила корреляции и определять ложноположительные срабатывания. Threat Intelligence в этом плане не исключение.
Сложность реализации решения, которое действительно отражало бы концепцию Threat Intelligence, заключается уже в самом ее определении.
Threat Intelligence – это процесс исследования и анализа определенных источников информации для получения и накопления сведений об актуальных киберугрозах с целью проведения мер по усилению кибербезопасности и повышению ИБ-осведомленности определенного ИБ-сообщества.
Определенными источниками могут являться:
- Открытые источники информации. Все то, что можно найти c помощью Google, Yandex, Bing и более специализированных средств, таких как Shodan, Censys, nmap. Процесс анализа данных источников так и называется – Open Source Intelligence (OSINT). Нужно отметить, что сведения, получаемые в рамках OSINT, идут из открытых (несекретных) источников. Если источник платный, это может и не делать его секретным, а значит, анализ такого источника – тоже OSINT.
- Средства массовой информации. Все то, что можно найти в СМИ и на социальных площадках Sосial Media Intelligence (SOCMINT). Этот тип получения данных, по сути, является составной частью OSINT.
- Закрытые площадки и форумы, на которых обсуждаются детали предстоящих киберпреступлений (deepweb, darknet). В основном на теневых площадках можно добыть сведения о DDoS-атаках или о создании нового ВПО, которое хакеры пытаются там продать.
- Люди, имеющие доступ к информации. «Коллеги по цеху» и люди, поддающиеся на методы социнженерии, – тоже источники, которые могут поделиться информацией.
Есть и более серьезные методы, доступные только специализированным службам. В этом случае данные могут поступать либо от агентов, работающих под прикрытием в киберпреступной среде, либо от людей, причастных к киберпреступлениям и сотрудничающих со следствием. Одним словом, все это называется HUMan Intelligence (HUMINT). В Jet CSIRT мы, конечно же, HUMINT не практикуем.
Поместить все эти процессы в «коробку», которая будет работать автономно, невозможно. Поэтому, когда речь заходит о решении TI, то, скорее всего, его основное потребительское ценностное предложение – это те самые сведения о киберугрозах и способы управления ими, доступ к которым в том или ином виде получает ИБ-сообщество.
Сведения о киберугрозах
В 2015 году компания MWR Infosecurity совместно с CERT и Центром национальной защиты инфраструктуры Великобритании опубликовали информационную брошюру, в которой было выделено 4 категории сведений, являющихся результатом процесса TI. Эта классификация теперь применяется повсеместно:
- Операционные. Сведения о готовящихся и текущих кибератаках, получаемые, как правило, спецслужбами в результате процесса HUMINT или с помощью прослушки каналов общения злоумышленников.
- Стратегические. Сведения, завязанные на оценке рисков для организации стать жертвой кибератаки. Не содержат никакой технической информации и никак не могут быть применены на средствах защиты.
- Тактические. Сведения о техниках, тактиках, процедурах (TTP) и инструментах, которые используют злоумышленники в рамках вредоносной кампании.
Показательный пример – недавно открытый LockerGoga- Инструмент: cmd.exe.
- Техника: запускается криптолокер, который шифрует все файлы на компьютере жертвы (включая файлы ядра ОС Windows) с помощью алгоритма AES в режиме блочного (CTR) шифрования c длиной ключа 128 бит. Ключ файла и вектор инициализации (IV) шифруются по алгоритму RSA-1024 с использованием функции генерации маски MGF1(SHA-1). В свою очередь для повышения криптостойкости данной функции применяется схема заполнения OAEP. Зашифрованные ключи файла и IV затем сохраняются в заголовке самого зашифрованного файла.
- Процедура: далее вредонос запускает несколько параллельно работающих дочерних процессов, шифруя только каждые 80.000 байт каждого файла, пропуская следующие 80.000 байт для ускорения шифрования.
- Тактика: затем требует выкуп в биткоинах за ключ для расшифровки файлов обратно.
Подробнее можно почитать тут.
Такие сведения появляются в результате тщательного расследования вредоносной кампании, которое может идти достаточно длительное время. Результатом этих исследований являются бюллетени и отчёты от коммерческих компаний, таких как Cisco Talos, FireEye, Symantec, Group-IB, Kaspersky GREAT, государственных организаций и регуляторов (ФинЦЕРТ, НКЦКИ, US-CERT, FS-ISAC), а также независимых исследователей.
Тактические сведения можно и нужно применять на средствах защиты и при построении архитектуры сети.
- Технические. Сведения о признаках и сущностях вредоносной активности или же о способах их выявления.
Например, при анализе вредоносного ПО было обнаружено, что оно распространяется в виде .pdf файла со следующими параметрами:
- именем прайс_декабрь.pdf,
- запускающим процесс pureevil.exe,
- имеющим MD5 хеш-сумму 81a284a2b84dde3230ff339415b0112a,
- который пытается установить соединения с С&C-сервером по адресу 123.45.67.89 на TCP порт 1337.
В этом примере сущностями являются названия файла и процесса, значение хеш-суммы, адрес сервера и номер порта. Признаки – это взаимодействие данных сущностей между собой и компонентами инфраструктуры: запуск процесса, исходящее сетевое взаимодействие с сервером, изменение ключей реестра и т.п.
Эти сведения тесно связаны с понятием «индикаторов компрометации» (Indicator of Compromise — IoC). Технически, пока сущность не обнаружена в инфраструктуре, она еще ни о чем не говорит. А вот если, скажем, обнаружить в сети факт попыток подключения хоста к С&C-серверу по адресу 123.45.67.89:1337 или запуск процесса pureevil.exe, да ещё с MD5-суммой 81a284a2b84dde3230ff339415b0112a, то это уже индикатор компрометации.
То есть индикатор компрометации – это совокупность определённых сущностей, признаков вредоносной активности и контекстной информации, которая требует реагирования со стороны служб ИБ.
При этом в сфере ИБ индикаторами компрометации принято называть как раз сущности, которые были кем-то замечены во вредоносной активности (IP-адреса, доменные имена, хеш-суммы, URL, имена файлов, ключи реестра и т.п.).
Обнаружение индикатора компрометации лишь сигнализирует о том, что на этот факт следует обратить внимание и проанализировать для определения дальнейших действий. Категорически не рекомендуется мгновенно блокировать индикатор на СЗИ без выяснения всех обстоятельств. Но об этом мы еще поговорим далее.
Индикаторы компрометации также удобно разделять на:
- Атомарные. В них содержится всего один признак, который невозможно поделить дальше, например:
- IP-адрес С&C-сервера – 123.45.67.89
- Хеш-сумма – 81a284a2b84dde3230ff339415b0112a
- Композитные. В них содержатся две или более сущностей, замеченных во вредоносной активности, например:
- Сокет – 123.45.67.89:5900
- Файл прайс_декабрь.pdf спавнит процесс pureevil.exe с хеш-суммой 81a284a2b84dde3230ff339415b0112a
Очевидно, что детектирование композитного индикатора будет с большей долей вероятности свидетельствовать о компрометации системы.
К техническим сведениям можно также отнести различные сущности для детектирования и блокирования индикаторов компрометации, например, Yara-правила, корреляционные правила для SIEM, различного рода сигнатуры для выявления атак и ВПО. Таким образом, технические сведения можно однозначно применять на средствах защиты.
Проблемы эффективного использования сведений технических TI
Быстрее всего поставщики TI-услуг могут получить именно технические сведения о киберугрозах, а уж как их применять – вопрос полностью к потребителю. Тут-то и кроется большинство проблем.
Например, индикаторы компрометации можно применить на нескольких этапах реагирования на инцидент ИБ:
- на этапе подготовки (Preparation), превентивно блокируя индикатор на СЗИ (разумеется, после исключения false-positive);
- на этапе детектирования, отслеживая срабатывания правил по выявлению индикатора в реальном времени средствами мониторинга (SIEM, SIM, LM);
- на этапе расследования инцидента, используя индикатор в ретроспективных проверках;
- на этапе более углубленного анализа пораженных активов, например, при анализе исходного кода вредоносного образца.
Чем больше ручной работы задействовано на том или ином этапе, тем больше аналитики (обогащения сущности индикатора контекстной информацией) необходимо будет от поставщиков индикаторов компрометации. В этом случае речь идет именно о внешней контекстной информации, то есть о том, что уже известно другим о данном индикаторе.
Обычно индикаторы компрометации поставляются в виде так называемых потоков или фидов угроз (threat feed). Это такой структурированный список данных об угрозах в различных форматах.
Например, ниже представлен фид вредоносных хешей в формате json:

Это пример хорошего фида, обогащенного контекстом:
- содержится ссылка на анализ угрозы;
- название, тип и категория угрозы;
- временная метка публикации.
Всё это позволяет управлять индикаторами компрометации из данного фида при загрузке на средства защиты информации и мониторинга, а также сокращает время на анализ инцидентов, сработавших по ним.
Но существуют фиды и другого качества (как правило, open source). Например, ниже приведён пример адресов якобы C&C-серверов из одного открытого источника:

Как видно, здесь полностью отсутствует контекстная информация. Любой из этих IP-адресов может хостить легитимный сервис, какие-то могут быть кроулерами Yandex или Google, индексирующими сайты. Мы ничего не можем сказать о данном списке.
Отсутствие или недостаточность контекста в фидах угроз является одной из основных проблем для потребителей технических сведений. Без контекста сущность из фида не применима и, по сути, не является индикатором компрометации. Иными словами, блокирование любого IP-адреса на СЗИ, равно как и загрузка этого фида на средства мониторинга, скорее всего, приведет к большому количеству ложноположительных срабатываний (false positive — FP).
Если рассматривать использование индикаторов компрометации с точки зрения детектирования на средствах мониторинга, то упрощенно этот процесс представляет собой последовательность:
- интеграция индикатора в средства мониторинга;
- срабатывание правила выявления индикатора;
- анализ срабатывания службой ИБ.
Из-за наличия в этой последовательности человеческого ресурса мы заинтересованы в том, чтобы анализировались только те случаи выявления индикаторов, которые действительно свидетельствуют об угрозе организации, и сокращать число FP.
В основном ложноположительные срабатывания вызывает детектирование сущности популярных ресурсов (Google, Microsoft, Yandex, Adobe и др.) как потенциально вредоносных.
Простой пример: исследуется ВПО, которое попало на хост. Обнаруживается, что оно проверяет наличие доступа в Интернет, опрашивая update.googleapis.com. Ресурс update.googleapis.com заносится в фид угроз как индикатор компрометации и вызывает FP. Точно также в фид может попасть хеш-сумма легитимной библиотеки или файла, которую использует ВПО, адреса публичных DNS, адреса различных кроулеров и спайдеров, ресурсы проверки отозванных сертификатов CRL (Certificate Revocation List) и «сокращатели» URL (bit.ly, goo.gl и т.д.).
Проверка подобного рода срабатываний, не обогащенных внешним контекстом, может занимать достаточно большое количество времени аналитика, в течение которого может быть упущен реальный инцидент.
Кстати, фиды индикаторов, которые могут вызвать FP, тоже есть. Одним из таких примеров является ресурс misp-warninglist.
Приоритизация индикаторов компрометации
Ещё одна проблема – приоритизация срабатываний. Условно говоря, какой у нас будет SLA при детектировании того или иного индикатора компрометации. Ведь поставщики фидов угроз не выставляют приоритет сущностям, которые в них содержатся. Чтобы помочь потребителю, они могут добавить степень уверенности во вредоносности той или иной сущности, как это сделано в фидах от «Лаборатории Касперского»:

Однако выставление приоритета событий выявления индикаторов – это задача потребителя.
Для решения этого вопроса в Jet CSIRT мы адаптировали подход, изложенный Райаном Казансьяном (Ryan Kazanciyan) на COUNTERMEASURE 2016. Его суть заключается в том, что все индикаторы компрометации, которые можно обнаружить в инфраструктуре, рассматриваются с точки зрения принадлежности к доменам систем и доменам данных.
Домены данных находятся в 3 категориях:
- Real-Time-активность на источнике (то, что он в данный момент хранит в памяти; обнаруживается средствами анализа событий ИБ в реальном времени):
- запускаемые процессы, изменение ключей реестра, создание файлов;
- сетевая активность, активные подключения;
- другие события, сгенерированные только что.
При обнаружении индикатора данной категории время на реакцию со стороны служб ИБ – минимально.
- Историческая активность (то, что уже случилось; обнаруживается при ретроспективных проверках):
- исторические логи;
- телеметрия;
- сработавшие алерты.
При обнаружении индикатора данной категории время на реакцию со стороны служб ИБ – допустимо ограничено.
- Данные, находящиеся в покое (то, что уже было прежде, чем мы подключили источник на мониторинг; обнаруживается в рамках ретроспективных проверок давно неиспользуемых источников):
- файлы, которые давно хранятся на источнике;
- ключи реестра;
- другие неиспользующиеся объекты.
При обнаружении индикатора данной категории время на реакцию со сторон служб ИБ ограничивается длительностью проведения полного расследования инцидента.
Обычно по факту таких расследований составляются подробные отчеты и бюллетени с разбором действий злоумышленников, но актуальность таких данных сравнительно небольшая.
То есть домены данных – это то состояние анализируемых данных, при которых был обнаружен индикатор компрометации.
Домены систем – это принадлежность источника индикатора компрометации к одной из подсистем инфраструктуры:
- Рабочие станции. Источники, используемые непосредственно пользователем для выполнения повседневной работы: АРМ, ноутбуки, планшеты, смартфоны, терминалы (VoIP, ВКС, IM), прикладные программы (CRM, ERP, etc.).
- Серверы. Здесь имеются в виду остальные устройства, обслуживающие (serve) инфраструктуру, т.е. устройства, обеспечивающие работу ИТ-комплекса: СЗИ (FW, IDS/IPS, AV, EDR, DLP), сетевые устройства, файловые/веб/прокси-серверы, системы СХД, СКУД, контроль окр. среды и т.д.

Комбинируя эти сведения с составом признаков индикатора компрометации (атом, композит), в зависимости от допустимого времени реакции, можно сформировать приоритет инцидента при его детектировании:
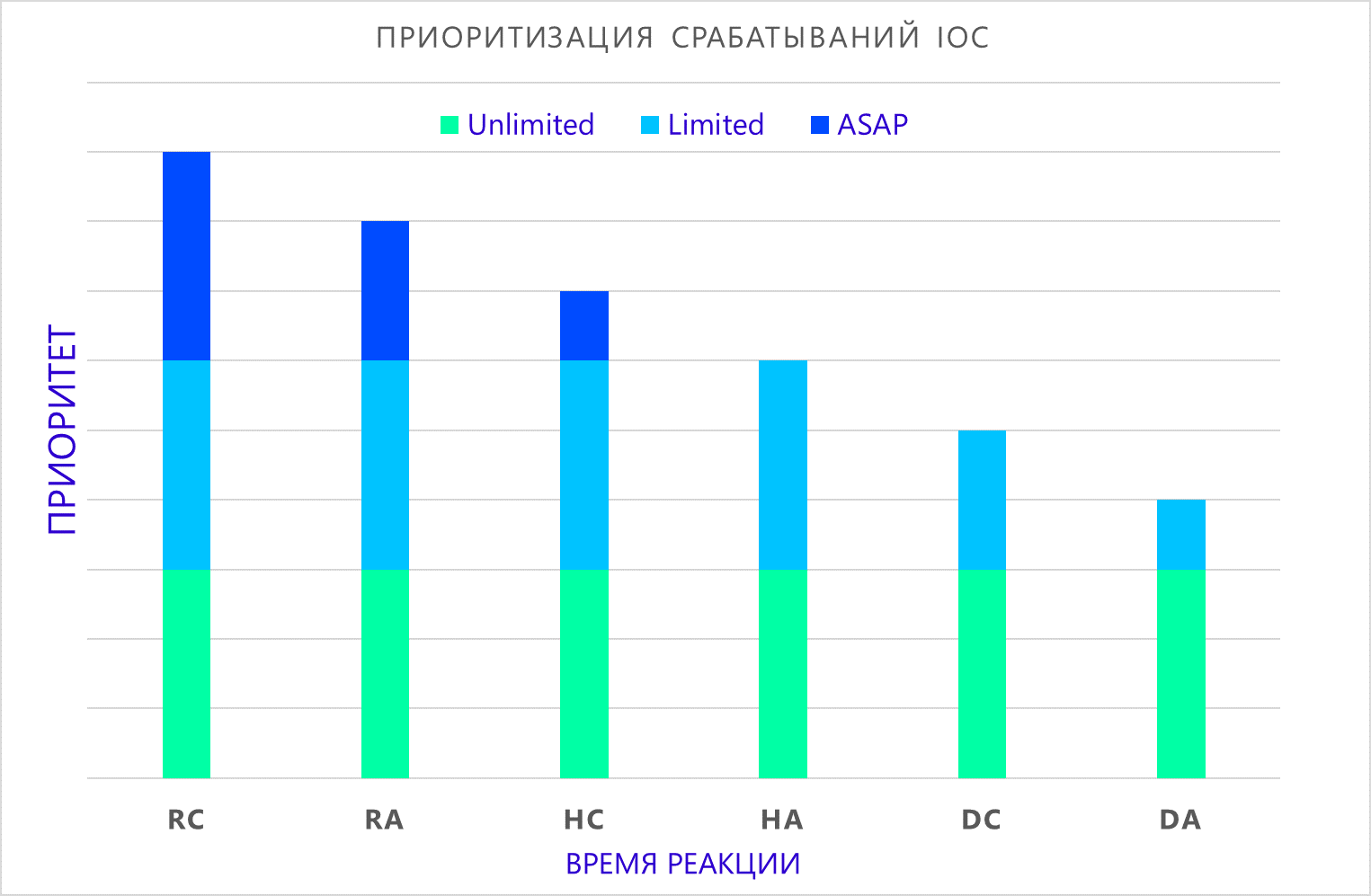
- ASAP. Обнаружение индикатора требует немедленной реакции со стороны группы реагирования.
- Limited. Обнаружение индикатора требует дополнительного анализа для выяснения обстоятельств произошедшего и принятия решения о дальнейших действиях.
- Unlimited. Обнаружение индикатора требует проведения тщательного расследования и подготовки отчёта о деятельности злоумышленников. Обычно такие находки исследуются в рамках форензики, которая может длиться годами.
Где:
- RC – обнаружение композитного индикатора в реальном времени;
- RA – обнаружение атомарного индикатора в реальном времени;
- HC – обнаружение композитного индикатора в рамках ретроспективной проверки;
- HA – обнаружение атомарного индикатора в рамках ретроспективной проверки;
- DC – обнаружение композитного индикатора в давно неиспользуемых источниках;
- DA – обнаружение атомарного индикатора в давно неиспользуемых источниках.
Нужно сказать, что приоритет не умаляет важности обнаружения индикатора, а скорее показывает примерное время, которое у нас есть для предотвращения возможной компрометации инфраструктуры.
Справедливо также заметить, что такой подход не может использоваться в отрыве от наблюдаемой инфраструктуры, к этому мы еще вернемся.
Контроль срока жизни индикаторов компрометации
Существует часть вредоносных сущностей, которые оставляют индикатор компрометации навсегда. Удалять такие сведения, даже спустя длительный промежуток времени, не рекомендуется. Это часто становится актуальным при ретроспективных проверках (НС/HA) и при проверке давно неиспользуемых источников (DC/DA).
Некоторые центры мониторинга и поставщики индикаторов компрометации считают необязательным контролировать срок жизни вообще для всех индикаторов. Однако на практике такой подход становится неэффективным.

Действительно, такие индикаторы компрометации, как, например, хеш-суммы вредоносных файлов, ключи реестра, создаваемые вредоносом, и URL, через которые происходит заражение узла, уже никогда не станут легитимными сущностями, т.е. срок их действия не ограничен.
Наглядный пример: анализ SHA-256 суммы файла RAT Vermin с инкапсулированным SOAP-протоколом для обмена данными с C&C-сервером. Анализ показывает, что файл был создан в 2015 году. Недавно мы нашли его на одном из файловых серверов одного нашего заказчика.
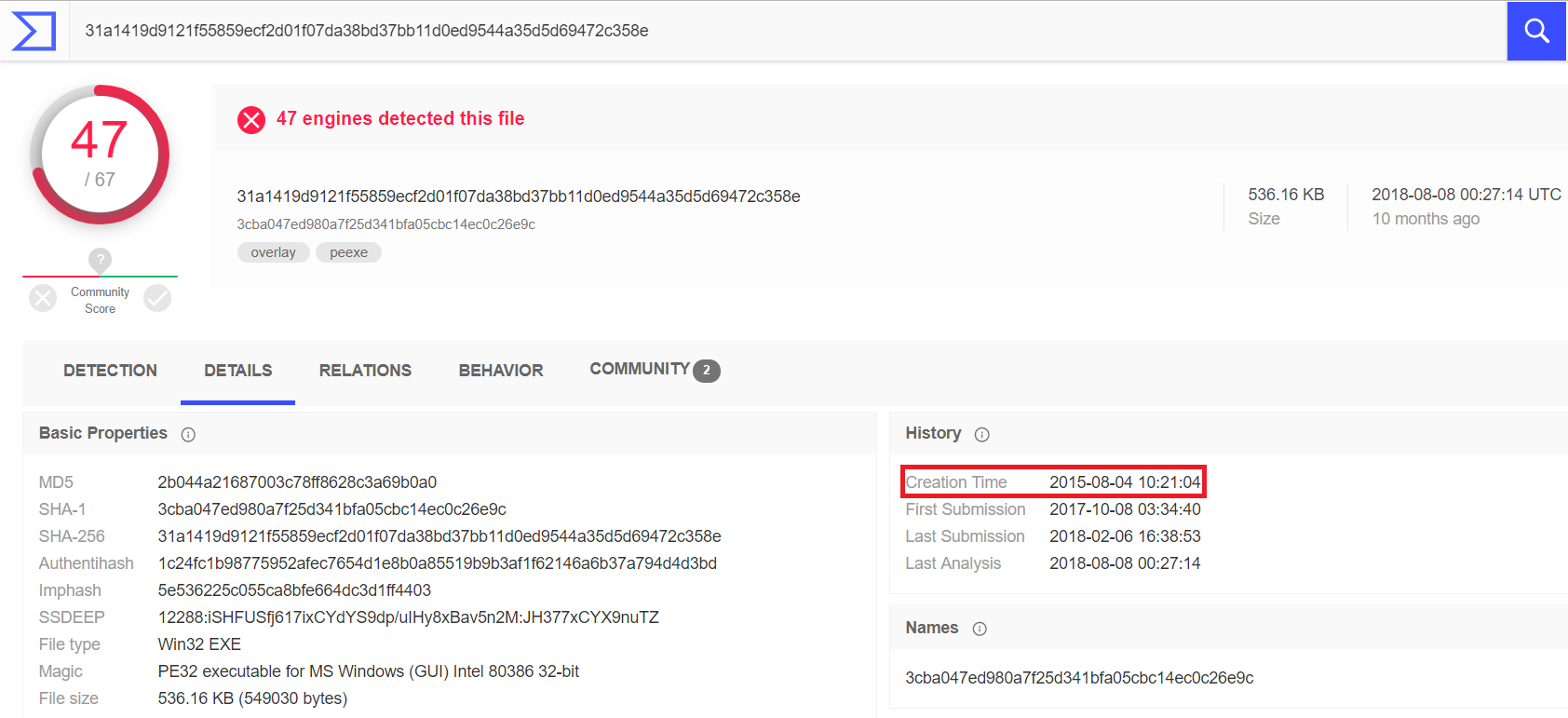
Однако совсем иная картина будет с типом сущностей, которые были созданы или «позаимствованы» на время для вредоносной кампании. То есть, по сути, являющихся эндпоинтами под управлением злоумышленников.
Такие сущности могут вновь стать легитимными после того, как их владельцы очистят скомпрометированные узлы, или когда злоумышленники перестанут использовать очередную инфраструктуру.
Принимая во внимание эти факторы, можно построить примерную таблицу индикаторов компрометации с привязкой к доменам данных, сроку их актуальности и необходимости контроля их жизненного цикла:
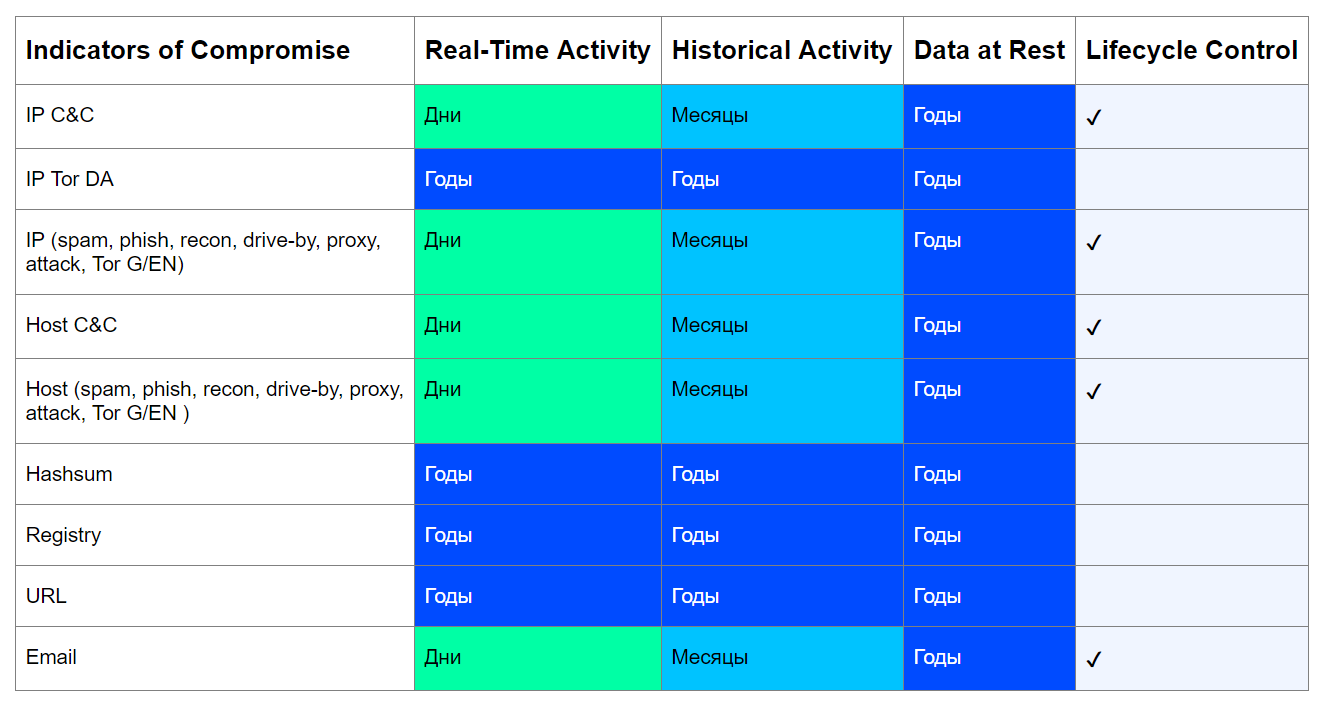
Задача данной таблицы – ответить на три вопроса:
- Может ли данный индикатор стать легитимным со временем?
- Каков минимальный срок актуальности индикатора в зависимости от состояния анализируемых данных?
- Нужно ли контролировать срок жизни данного индикатора?
Рассмотрим данный подход на примере IP C&C-сервера. Сегодня злоумышленники предпочитают поднимать распределенную инфраструктуру, часто меняя адреса, чтобы оставаться незамеченными и избежать возможных блокировок от провайдера. При этом C&C часто разворачиваются на взломанных узлах, как, например, в случае с Emotet. Однако ботнеты ликвидируются, негодяев ловят, поэтому такой индикатор, как IP-адрес C&C-сервера, точно может стать легитимной сущностью, а значит, срок его жизни можно контролировать.
Если мы обнаружим обращения к IP C&C-сервера в реальном времени (RA/RC), то срок его актуальности для нас будет исчисляться днями. Ведь вряд ли на следующий день после обнаружения этот адрес уже не будет хостить C&C.
Обнаружение такого индикатора в ретроспективных проверках (HA/HC), которые обычно имеют более длительные интервалы (раз в несколько недель/месяцев), обозначит и минимальный срок актуальности, равный соответствующему интервалу. При этом сам C&C может быть уже не активен, но если мы найдем у себя в инфраструктуре факт обращения, то индикатор для нас будет актуальным.
Такая же логика применяется к остальным типам индикаторов. Исключение составляют хеш-суммы, ключи реестра, Directory Authority (DA) ноды сети Tor и URL.
С хешами и значениями реестра все просто – их нельзя удалить из природы, поэтому и срок их жизни контролировать не имеет смысла. А вот вредоносные URL удалить можно, легитимными они, конечно, не станут, но зато будут неактивными. Тем не менее, они тоже уникальны и создаются специально под вредоносную кампанию, поэтому легитимными стать не могут.
IP-адреса DA нод сети Tor общеизвестны и неизменны, срок их жизни ограничен лишь сроком жизни самой сети Tor, поэтому такие индикаторы всегда актуальны.
Как видно, для большинства типов индикаторов из таблицы необходим контроль времени их жизни.
Мы в Jet CSIRT выступаем за такой подход по следующим причинам.
- Сущности, когда-то представлявшие собой индикаторы компрометации, могут со временем начать хостить какой-нибудь сервис, с которым, возможно, нужно будет работать.
Например, компания Microsoft через суд добилась контроля над 99 доменами, которые ранее использовала группировка APT35. Через какое-то время Microsoft может начать использовать эти доменные имена в легальных целях.
Еще одним примером могут служить письма с IP-адресов компаний, которые были взломаны и использованы в спам-рассылках. Последствия взлома могут быть давно ликвидированы, но поскольку их IP-адрес занесен с в списки «спамеров», письма сотрудников такой компании будут автоматически отправляться в папки, где могут остаться незамеченными. - Контроль времени жизни индикаторов компрометации помогает снизить нагрузку на СЗИ, которое осуществляет блокировку.
Постоянно увеличивающийся объем новых правил блокировки негативно сказывается на производительности СЗИ и, следовательно, несет угрозу критичному элементу, который должен защищать инфраструктуру. - Нарастающий объем угроз вынудит сообщество контролировать используемые индикаторы.
Ежегодно появляются миллионы новых угроз, которые оставляют индикаторы компрометации. Стоит добавить всего 1 символ в любой документ MS Office, и у него уже будет совершенно другая хеш-сумма, а мы можем больше никогда не встретить этот файл в других атаках. Увеличивающийся объем новых индикаторов в конечном счете заставит нас решать, какие индикаторы нужно продолжить эксплуатировать, а какие можно списать, и решающим фактором в этом станет их актуальность.
Именно поэтому мы считаем важным уже сейчас стремиться к адаптации процессов и выработке подходов к контролированию времени жизни индикаторов, которые интегрируются в средства защиты.
Один из таких подходов описан в материале Decaying Indicators of Compromise Центра реагирования на компьютерные инциденты Люксембурга (CIRCL), сотрудники которого создали платформу для обмена информацией об угрозах MISP. Именно в MISP и планируется применить идеи из данного материала. Для этого в основном репозитории проекта уже открыли соответствующую ветку, что лишний раз доказывает актуальность этой проблемы для ИБ-сообщества.
Этот подход предполагает, что время жизни некоторых индикаторов не является гомогенным и может меняться по мере того, как:
- злоумышленники перестают использовать свою инфраструктуру в кибератаках;
- о кибератаке узнает все большее ИБ-специалистов и вносит индикаторы в блок на СЗИ, вынуждая злоумышленников менять использующиеся элементы.
Таким образом, время жизни таких индикаторов можно описать в виде некой функции, характеризующей скорость выхода срока годности каждого индикатора со временем.
Коллеги из CIRCL строят свою модель с помощью условий, используемых в MISP, однако общая идея модели может быть использована и вне их продукта:
- индикатору компрометации (a) присваивается некая базовая оценка (
 ), которая лежит в пределах от 0 до 100;
), которая лежит в пределах от 0 до 100;
В материале CIRCL она учитывается надежностью/уверенностью в поставщике индикатора и связанными таксономиями. При этом при повторном обнаружении индикатора базовая оценка может меняться – повышаться или понижаться, в зависимости от алгоритмов поставщика.
- Вводится время
 , при котором его общая оценка должна = 0;
, при котором его общая оценка должна = 0; - Вводится понятие скорости выхода срока годности индикатора (decay_rate)
 , которое характеризует скорость снижения общей оценки индикатора со временем;
, которое характеризует скорость снижения общей оценки индикатора со временем; - Вводятся временные метки
 и
и  , характеризующие соответственно текущее время и время, когда индикатор был замечен последний раз.
, характеризующие соответственно текущее время и время, когда индикатор был замечен последний раз.
Учитывая все вышеперечисленные условия, коллеги из CIRCL приводят следующую формулу для расчета общей оценки (1):

Где,

Параметр
предлагается считать, как  ,
,Где,
 – время первого обнаружения индикатора;
– время первого обнаружения индикатора; – время последнего обнаружения индикатора;
– время последнего обнаружения индикатора; – максимальное время между двумя обнаружениями индикатора.
– максимальное время между двумя обнаружениями индикатора.Идея заключается в том, что когда оценка будет = 0, то соответствующий индикатор можно будет отозвать.
По нашим данным, некоторые поставщики фидов угроз реализуют другие методики для контроля актуальности и фильтрации индикаторов компрометации, применяемых на превентивном уровне. Однако большинство этих методик достаточно простые.
Мы постарались применить алгоритм из материала CIRCL для индикаторов, которые были обнаружены на этапе детектирования и применены в виде блокирующих правил на СЗИ в процессе реагирования и пост-инцидентной активности.
Очевидно, что такой подход может однозначно применяться только к тем типам индикаторов, для которых известно
. В материале CIRCL приводится в пример так называемое grace time – фиксированное время на исправление, которое провайдер дает владельцу ресурса, замеченного в подозрительной активности, прежде чем отключить ресурс. Но для большинства типов индикаторов все же неизвестно. К сожалению, мы не можем с точностью предсказать время, когда определенная сущность станет легитимной. Однако у нас почти всегда (от поставщика индикатора или из анализа открытых источников) есть сведения о том, когда эта сущность была обнаружена первый и последний раз, а также некое подобие базовой оценки. Таким образом, от того, чтобы выяснить, когда же можно будет списать индикатор согласно материалу CIRCL, нас отделяет лишь одна переменная – decay_rate. Однако мало просто сделать ее постоянной для всех индикаторов, а что более важно – для всех инфраструктур.
Поэтому мы попробовали привязать каждый тип индикатора, для которого возможен контроль жизненного цикла, к его скорости выхода срока годности (decay_rate), типу наблюдаемой инфраструктуры и ее уровню зрелости ИБ.
Проводя инвентаризацию конкретной защищаемой инфраструктуры, выясняя возраст ПО и оборудования, которое в ней используется, мы определяем decay_rate для каждого типа индикаторов компрометации. Примерный результат такой работы можно представить в виде таблицы:
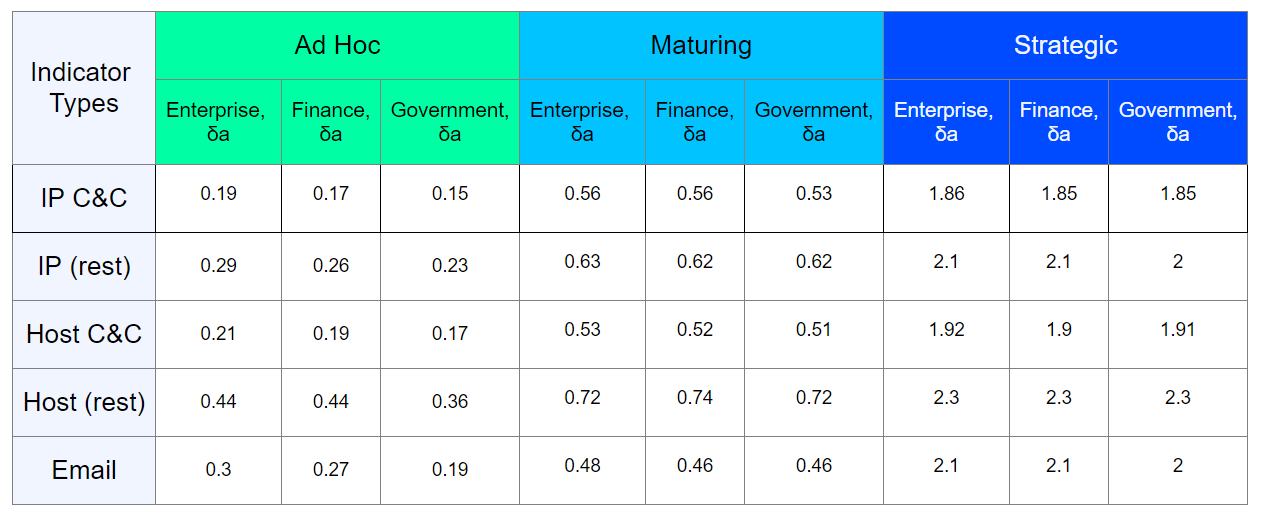
Еще раз подчеркну, что результат в таблице примерный, в реальности оценка должна проводиться индивидуально под конкретную инфраструктуру.
С появлением сроков годности каждого индикатора мы можем определить примерное время, когда их можно списать. Также стоит отметить, что расчет времени списания следует проводить только тогда, когда замечена тенденция к снижению базовой оценки индикатора.
Для примера рассмотрим индикатор с базовой оценкой 80, временем
= 120 и разным decay_rate ().
Как видно из графиков, определяя примерный предел критичности оценки (в нашем случае – 20, при начальной оценке 80), мы можем установить время для проверки данного индикатора на актуальность. Чем больше decay_rate, тем быстрее наступает это время. Например, при decay_rate = 3 и пределе оценки = 20 можно было бы проверить данный индикатор примерно на 50 день его эксплуатации на СЗИ.
Описанный подход достаточно сложно реализовать, но его прелесть в том, что мы можем проводить тестирование, не влияя на налаженные процессы информационной безопасности и инфраструктуру заказчиков. Сейчас мы обкатываем алгоритм контролирования времени жизни определенной выборки индикаторов, которые гипотетически могут попасть под списание. При этом на самом деле данные индикаторы остаются в эксплуатации на СЗИ. Условно говоря, мы берем выборку индикаторов, считаем для них
и, заметив тенденцию к снижению базовой оценки, помечаем их как «списанные», если проверка подтвердила их неактуальность. Пока рано говорить об эффективности данного подхода, но результаты тестирования помогут нам определиться с тем, стоит ли переводить его «в продакшен».
Такая методика потенциально может помочь контролировать не только те индикаторы, которые эксплуатируются на СЗИ вследствие реагирования на инцидент. Успешная адаптация этого подхода поставщиками сведений о киберугрозах позволит профилировать фиды угроз таким образом, чтобы они содержали индикаторы компрометации с определенным временем жизни для конкретных заказчиков и инфраструктур.
Заключение
Treat Intelligence – это, безусловно, нужная и полезная концепция в сфере ИБ, способная существенно усилить безопасность инфраструктуры компаний. Чтобы добиться эффективного использования TI, нужно понимать, как мы можем использовать различные сведения, получаемые в рамках данного процесса.
Говоря о технических сведениях Threat Intelligence, таких как фиды угроз и индикаторы компрометации, нужно помнить, что метод их использования не должен быть основан на слепом blacklisting. С виду простой алгоритм детектирования и последующего блокирования угрозы на самом деле имеет множество «подводных камней», поэтому для эффективного использования технических сведений необходимо правильно оценивать их качество, определять приоритет срабатываний, а также контролировать срок их жизни, чтобы снижать нагрузку на СЗИ.
Однако полагаться лишь на технические сведения Threat Intelligence не стоит. Куда более важно адаптировать в процессы защиты тактические сведения. Ведь злоумышленникам куда сложнее поменять тактику, техники и инструменты, нежели заставить нас гоняться за очередной порцией индикаторов компрометации, которая обнаружилась после хакерской атаки. Но об этом мы расскажем в наших следующих статьях.
Автор: Александр Ахремчик, эксперт Центра мониторинга и реагирования на инциденты ИБ Jet CSIRT компании «Инфосистемы Джет»
