Представляем исчерпывающую шпаргалку, где мы простыми словами рассказываем, из чего «делают» искусственный интеллект и как это все работает.
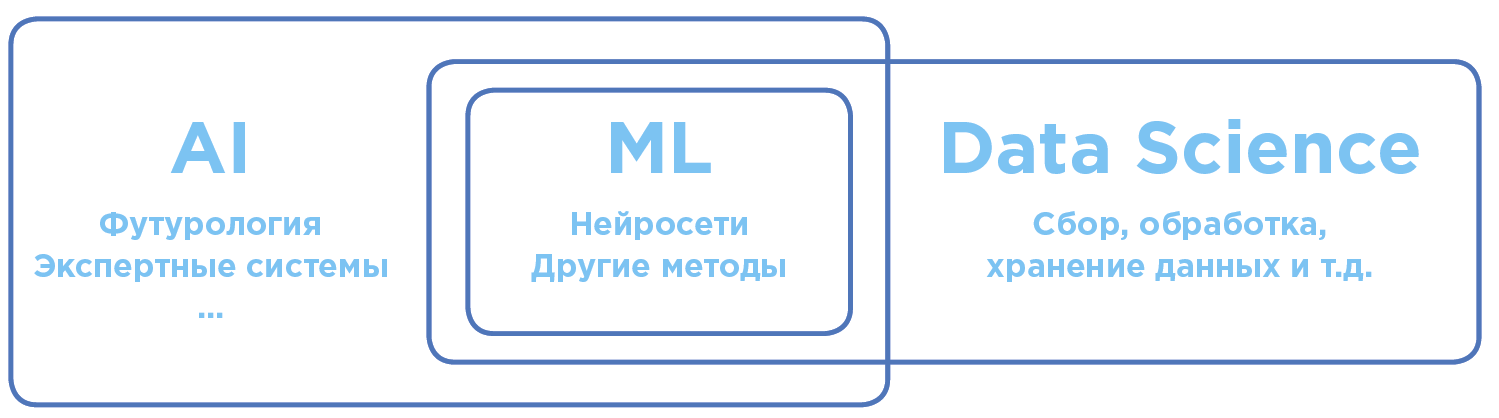
Разграничение понятий в области искусственного интеллекта и анализа данных.
В глобальном общечеловеческом смысле ИИ — термин максимально широкий. Он включает в себя как научные теории, так и конкретные технологические практики по созданию программ, приближенных к интеллекту человека.
Раздел AI, активно применяющийся на практике. Сегодня, когда речь заходит об использовании AI в бизнесе или на производстве, чаще всего имеется в виду именно Machine Learning.
ML-алгоритмы, как правило, работают по принципу обучающейся математической модели, которая производит анализ на основе большого объема данных, при этом выводы делаются без следования жестко заданным правилам.
Наиболее частый тип задач в машинном обучении — это обучение с учителем. Для решения такого рода задач используется обучение на массиве данных, по которым ответ заранее известен (см.ниже).
Наука и практика анализа больших объемов данных с помощью всевозможных математических методов, в том числе машинного обучения, а также решение смежных задач, связанных со сбором, хранением и обработкой массивов данных.
Data Scientists — специалисты по работе с данными, в частности, проводящие анализ при помощи machine learning.

Рассмотрим работу ML на примере задачи банковского скоринга. Банк располагает данными о существующих клиентах. Ему известно, есть ли у кого-то просроченные платежи по кредитам. Задача — определить, будет ли новый потенциальный клиент вовремя вносить платежи. По каждому клиенту банк обладает совокупностью определенных черт/признаков: пол, возраст, ежемесячный доход, профессия, место проживания, образование и пр. В числе характеристик могут быть и слабоструктурированные параметры, такие как данные из соцсетей или история покупок. Кроме того, данные можно обогатить информацией из внешних источников: курсы валют, данные кредитных бюро и т. п.
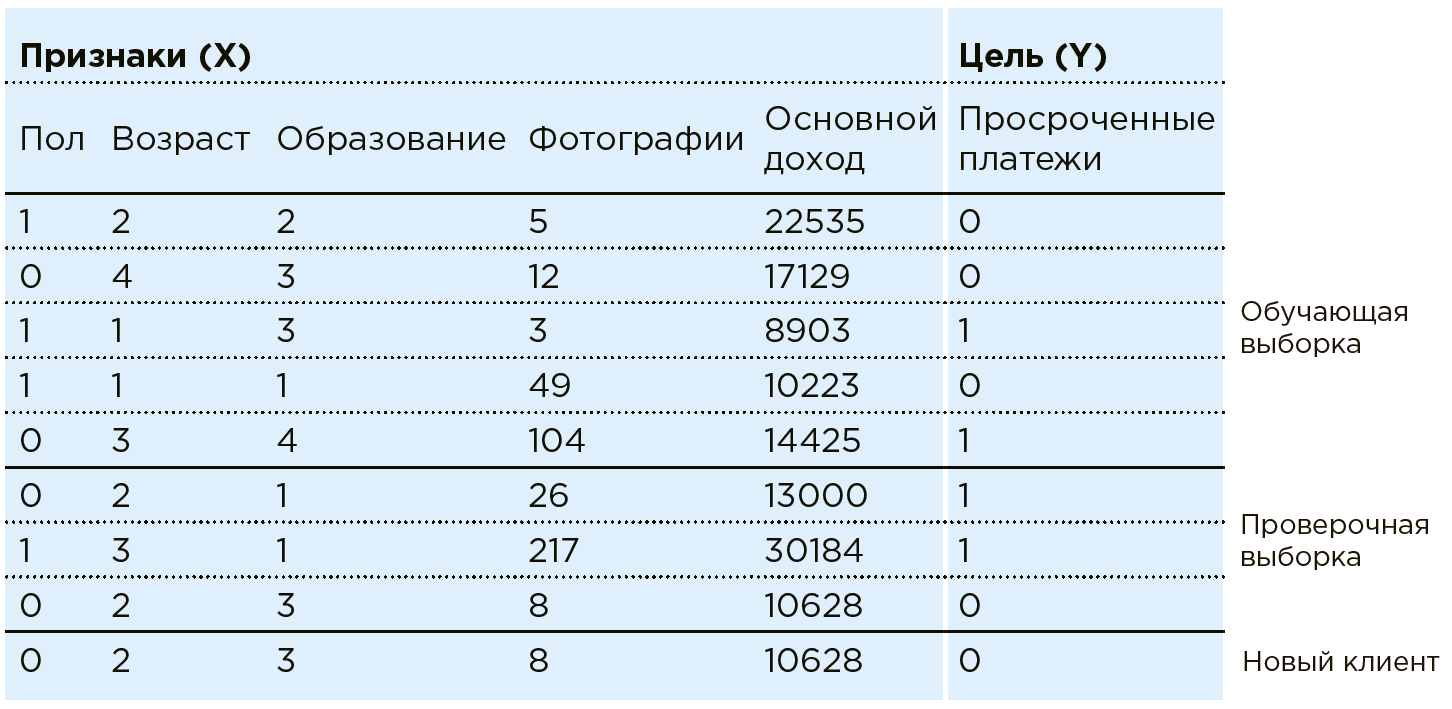
Машина видит любого клиента как совокупность признаков: . Где, например,
. Где, например,  — возраст,
— возраст,  — доход, а
— доход, а  — количество фотографий дорогих покупок в месяц (на практике в рамках подобной задачи Data Scientist работает с более чем сотней признаков). Каждому клиенту соответствует еще одна переменная —
— количество фотографий дорогих покупок в месяц (на практике в рамках подобной задачи Data Scientist работает с более чем сотней признаков). Каждому клиенту соответствует еще одна переменная —  с двумя возможными исходами: 1 (есть просроченные платежи) или 0 (нет просроченных платежей).
с двумя возможными исходами: 1 (есть просроченные платежи) или 0 (нет просроченных платежей).
Совокупность всех данных и — есть Data Set. Используя эти данные, Data Scientist создает модель
и — есть Data Set. Используя эти данные, Data Scientist создает модель  , подбирая и дорабатывая алгоритм машинного обучения.
, подбирая и дорабатывая алгоритм машинного обучения.
В этом случае модель анализа выглядит так:
Алгоритмы машинного обучения подразумевают поэтапное приближение ответов модели к истинным ответам (которые в обучающем Data Set известны заранее). Это и есть обучение с учителем на определенной выборке.
На практике чаще всего машина обучается лишь на части массива (80 %), применяя остаток (20 %) для проверки правильности выбранного алгоритма. Например, система может обучаться на массиве, из которого исключены данные пары регионов, на которых сверяется точность модели после.
Теперь, когда в банк приходит новый клиент, по которому еще не известен банку, система подскажет надежность плательщика, основываясь на известных о нем данных  .
.
Однако, обучение с учителем — не единственный класс задач, которые способна решать ML.
Другой спектр задач — кластеризация, способная разделять объекты по признакам, например, выявлять разные категории клиентов для составления им индивидуальных предложений.
Также с помощью ML-алгоритмов решаются такие задачи, как моделирование общения специалиста поддержки или создание художественных произведений, неотличимых от сотворенных человеком (например, нейросети рисуют картины).
Новый и популярный класс задач — обучение с подкреплением, которое проходит в ограниченной среде, оценивающей действия агентов (например, с помощью такого алгоритма удалось создать AlphaGo, победившую человека в Го).

Один из методов Machine Learning. Алгоритм, вдохновленный структурой человеческого мозга, в основе которой лежат нейроны и связи между ними. В процессе обучения происходит подстройка связей между нейронами таким образом, чтобы минимизировать ошибки всей сети.
Особенностью нейронных сетей является наличие архитектур, подходящих практически под любой формат данных: сверточные нейросети для анализа картинок, рекуррентные нейросети для анализа текстов и последовательностей, автоэнкодеры для сжатия данных, генеративные нейросети для создания новых объектов и т. д.
В то же время практически все нейросети обладают существенным ограничением — для их обучения нужно большое количество данных (на порядки большее, чем число связей между нейронами в этой сети). Благодаря тому, что в последнее время объемы готовых для анализа данных значительно выросли, растет и сфера применения. С помощью нейросетей сегодня, например, решаются задачи распознавания изображений, такие как определение по видео возраста и пола человека, или наличие каски на рабочем.
Раздел Data Science, позволяющий понять причины выбора ML-моделью того или иного решения.
Существует два основных направления исследований:
Например, при прогнозировании брака на производстве признаки объектов — это данные настроек станков, химический состав сырья, показатели датчиков, видео с конвейера и т. д. А ответы – это ответы на вопрос, будет ли брак или нет.
Естественно, производство интересует не только прогноз самого брака, но и интерпретация результата, т. е. причины брака для их последующего устранения. Это может быть долгое отсутствие тех.обслуживания станка, качество сырья, или просто аномальные показания некоторых датчиков, на которые технологу стоит обратить внимание.
Потому в рамках проекта прогноза брака на производстве должна быть не просто создана ML-модель, но и проделана работа по её интерпретации, т. е. по выявлению факторов, влияющих на брак.

Когда есть большой набор статистических данных, но найти в них зависимости экспертными или классическими математическими методами невозможно или очень трудоемко. Так, если на входе есть более тысячи параметров (среди которых как числовые, так и текстовые, а также видео, аудио и картинки), то найти зависимость результата от них без машины невозможно.
Например, на химическую реакцию кроме самих вступающих во взаимодействие веществ влияет множество параметров: температура, влажность, материал емкости, в которой она происходит, и т. д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
Для построения моделей машинного обучения требуются в разных случаях числовые, текстовые, фото, видео, аудио и иные данные. Для того чтобы эту информацию хранить и анализировать существует целая область технологий — Big Data. Для оптимального накопления данных и их анализа создают «озера данных» (Data Lake) — специальные распределенные хранилища для больших объемов слабоструктированной информации на базе технологий Big Data.
Цифровой двойник — виртуальная копия реального материального объекта, процесса или организации, которая позволяет моделировать поведение изучаемого объекта/процесса. Например, можно предварительно увидеть результаты изменения химического состава на производстве после изменений настроек производственных линий, изменений продаж после проведения рекламной кампании с теми или иными характеристиками и т. д. При этом прогнозы строятся цифровым двойником на основе накопленных данных, а сценарии и будущие ситуации моделируются в том числе методами машинного обучения.
Data Scientiest’ы! Именно они создают алгоритм прогноза: изучают имеющиеся данные, выдвигают гипотезы, строят модели на основе Data Set. Они должны обладать тремя основными группами навыков: IT-грамотностью, математическими и статистическими знаниями и содержательным опытом в конкретной области.
Получение данных
Могут быть использованы данные из смежных систем: график работ, план продаж. Данные могут быть также обогащены внешними источниками: курсы валют, погода, календарь праздников и т. д. Необходимо разработать методику работы с каждым типом данных и продумать конвейер их преобразования в формат модели машинного обучения (набор чисел).
Построение признаков
Проводится вместе с экспертами из необходимой области. Это помогает вычислить данные, которые хорошо подходят для прогнозирования целей: статистика и изменение количества продаж за последний месяц для прогноза рынка.
Модель машинного обучения
Метод решения поставленной бизнес-задачи выбирает data scientist самостоятельно на основании своего опыта и возможностей различных моделей. Под каждую конкретную задачу необходимо подобрать отдельный алгоритм. От выбранного метода напрямую зависят скорость и точность результата обработки исходных данных.
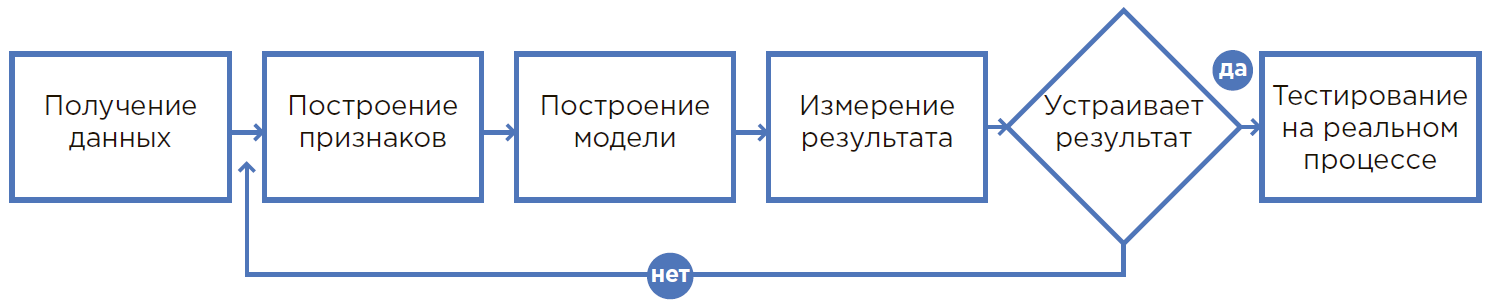
Процесс создания ML-модели.
Гипотеза рождается при анализе проблемного процесса, опыта сотрудников или при свежем взгляде на производство. Как правило, гипотеза затрагивает такой процесс, где человек физически не может учесть множество факторов и пользуется округлениями, допущениями или просто делает так, как всегда делал.
В таком процессе применение машинного обучения позволяет использовать существенно больше информации при принятии решений, поэтому, возможно, удается достичь существенно лучших результатов. Плюс ко всему, автоматизация процессов с помощью ML и снижение зависимости от конкретного человека существенно минимизируют человеческий фактор (болезнь, низкая концентрация и т. д.).
На основании сформулированной гипотезы выбираются данные, необходимые для разработки модели машинного обучения. Осуществляется поиск соответствующих данных и оценка их пригодности для встраивания модели в текущие процессы, определяется, кто будет ее пользователями и за счет чего достигается эффект. При необходимости вносятся организационные и любые другие изменения.
Оценка экономического эффекта внедряемого решения производится специалистами совместно с соответствующими департаментами: эффективности, финансов и т. д. На данном этапе необходимо понять, что именно является метрикой (количество верно выявленных клиентов / увеличение выпуска продукции / экономия расходных материалов и т. п.) и четко сформулировать измеряемую цель.
После понимания бизнес-результата его необходимо переложить в математическую плоскость — определить метрики измерений и ограничения, которые нельзя нарушать. Данные этапы data
scientist выполняет совместно с бизнес-заказчиком.
Необходимо собрать данные в одном месте, проанализировать их, рассматривая различные статистики, понять структуру и скрытые взаимосвязи этих данных для формирования признаков.
Является, по сути, проверкой гипотезы. Это возможность построения модели на текущих данных и первичной проверки результатов ее работы. Обычно прототип делается на имеющихся данных без разработки интеграций и работы с потоком в реальном времени.
Создание прототипа — быстрый и недорогой способ проверить, решаема ли задача. Это весьма полезно в том случае, когда невозможно заранее понять, получится ли достичь нужного экономического эффекта. К тому же процесс создания прототипа позволяет лучше оценить объем и подробности проекта по внедрению решения, подготовить экономическое обоснование такого внедрения.
В тот момент, когда результаты работы прототипа демонстрируют уверенное достижение показателей, создается полноценное решение, где модель машинного обучения является лишь составляющей изучаемых процессов. Далее производится интеграция, установка необходимого оборудования, обучение персонала, изменение процессов принятия решений и т. Д.
Во время опытной эксплуатации система работает в режиме советов, в то время как специалист еще повторяет привычные действия, каждый раз давая обратную связь о необходимых улучшениях системы и увеличении точности прогнозов.
Финальная часть — промышленная эксплуатация, когда налаженные процессы переходят на полностью автоматическое обслуживание.
Шпаргалку можно скачать по ссылке.
Завтра на форуме по системам искусственного интеллекта RAIF 2019 в 09:30 — 10:45 состоится панельная дискуссия: «AI для людей: разбираемся простыми словами».
В этой секции в формате дебатов спикеры объяснят простыми словами на жизненных примерах сложные технологии. А также подискутируют на следующие темы:
В дискуссии принимают участие:
Николай Марин, директор по технологиям, IBM в России и СНГ
Алексей Натекин, основатель, Open Data Science x Data Souls
Алексей Хахунов, технический директор, Dbrain
Евгений Колесников, директор Центра машинного обучения, Инфосистемы Джет
Павел Доронин, CEO, AI Today
Дискуссия будет доступна на канале YouTube «Инфосистемы Джет» в конце октября.
В чем разница между Artificial Intelligence, Machine Learning и Data Science?
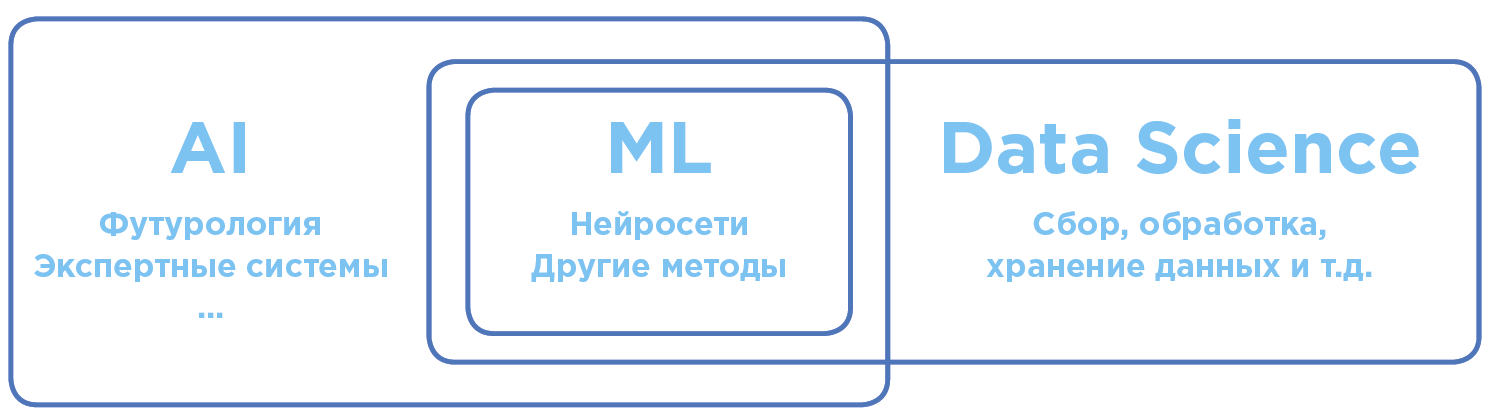
Разграничение понятий в области искусственного интеллекта и анализа данных.
Artificial Intelligence — AI (Искусственный Интеллект)
В глобальном общечеловеческом смысле ИИ — термин максимально широкий. Он включает в себя как научные теории, так и конкретные технологические практики по созданию программ, приближенных к интеллекту человека.
Machine Learning — ML (Машинное обучение)
Раздел AI, активно применяющийся на практике. Сегодня, когда речь заходит об использовании AI в бизнесе или на производстве, чаще всего имеется в виду именно Machine Learning.
ML-алгоритмы, как правило, работают по принципу обучающейся математической модели, которая производит анализ на основе большого объема данных, при этом выводы делаются без следования жестко заданным правилам.
Наиболее частый тип задач в машинном обучении — это обучение с учителем. Для решения такого рода задач используется обучение на массиве данных, по которым ответ заранее известен (см.ниже).
Data Science — DS (Наука о данных)
Наука и практика анализа больших объемов данных с помощью всевозможных математических методов, в том числе машинного обучения, а также решение смежных задач, связанных со сбором, хранением и обработкой массивов данных.
Data Scientists — специалисты по работе с данными, в частности, проводящие анализ при помощи machine learning.

Как работает Machine Learning?
Рассмотрим работу ML на примере задачи банковского скоринга. Банк располагает данными о существующих клиентах. Ему известно, есть ли у кого-то просроченные платежи по кредитам. Задача — определить, будет ли новый потенциальный клиент вовремя вносить платежи. По каждому клиенту банк обладает совокупностью определенных черт/признаков: пол, возраст, ежемесячный доход, профессия, место проживания, образование и пр. В числе характеристик могут быть и слабоструктурированные параметры, такие как данные из соцсетей или история покупок. Кроме того, данные можно обогатить информацией из внешних источников: курсы валют, данные кредитных бюро и т. п.
Машина видит любого клиента как совокупность признаков:
. Где, например, — возраст, — доход, а — количество фотографий дорогих покупок в месяц (на практике в рамках подобной задачи Data Scientist работает с более чем сотней признаков). Каждому клиенту соответствует еще одна переменная — с двумя возможными исходами: 1 (есть просроченные платежи) или 0 (нет просроченных платежей).Совокупность всех данных
и — есть Data Set. Используя эти данные, Data Scientist создает модель , подбирая и дорабатывая алгоритм машинного обучения.В этом случае модель анализа выглядит так:
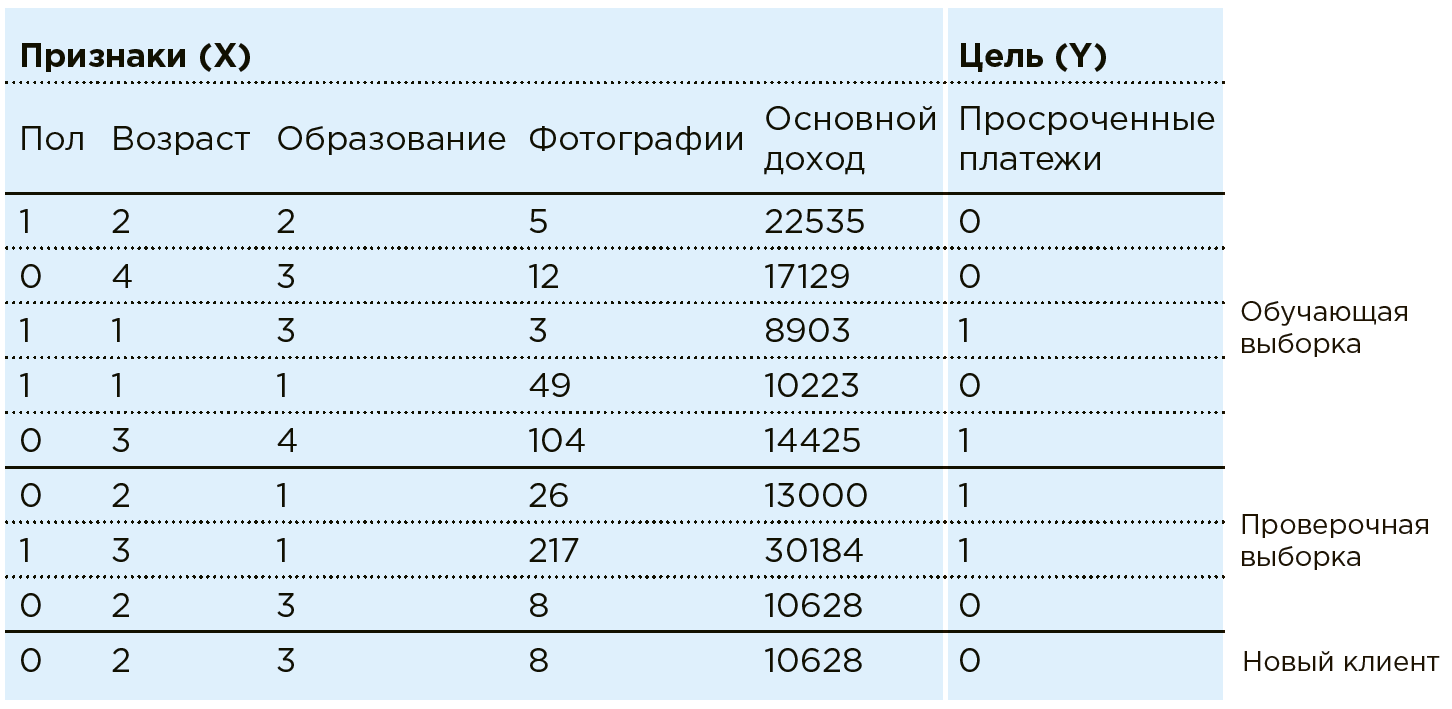
Алгоритмы машинного обучения подразумевают поэтапное приближение ответов модели
к истинным ответам (которые в обучающем Data Set известны заранее). Это и есть обучение с учителем на определенной выборке.На практике чаще всего машина обучается лишь на части массива (80 %), применяя остаток (20 %) для проверки правильности выбранного алгоритма. Например, система может обучаться на массиве, из которого исключены данные пары регионов, на которых сверяется точность модели после.
Теперь, когда в банк приходит новый клиент, по которому
еще не известен банку, система подскажет надежность плательщика, основываясь на известных о нем данных .Однако, обучение с учителем — не единственный класс задач, которые способна решать ML.
Другой спектр задач — кластеризация, способная разделять объекты по признакам, например, выявлять разные категории клиентов для составления им индивидуальных предложений.
Также с помощью ML-алгоритмов решаются такие задачи, как моделирование общения специалиста поддержки или создание художественных произведений, неотличимых от сотворенных человеком (например, нейросети рисуют картины).
Новый и популярный класс задач — обучение с подкреплением, которое проходит в ограниченной среде, оценивающей действия агентов (например, с помощью такого алгоритма удалось создать AlphaGo, победившую человека в Го).

Нейронная сеть
Один из методов Machine Learning. Алгоритм, вдохновленный структурой человеческого мозга, в основе которой лежат нейроны и связи между ними. В процессе обучения происходит подстройка связей между нейронами таким образом, чтобы минимизировать ошибки всей сети.
Особенностью нейронных сетей является наличие архитектур, подходящих практически под любой формат данных: сверточные нейросети для анализа картинок, рекуррентные нейросети для анализа текстов и последовательностей, автоэнкодеры для сжатия данных, генеративные нейросети для создания новых объектов и т. д.
В то же время практически все нейросети обладают существенным ограничением — для их обучения нужно большое количество данных (на порядки большее, чем число связей между нейронами в этой сети). Благодаря тому, что в последнее время объемы готовых для анализа данных значительно выросли, растет и сфера применения. С помощью нейросетей сегодня, например, решаются задачи распознавания изображений, такие как определение по видео возраста и пола человека, или наличие каски на рабочем.
Интерпретация результата
Раздел Data Science, позволяющий понять причины выбора ML-моделью того или иного решения.
Существует два основных направления исследований:
- Изучение модели как «черного ящика». Анализируя загруженные в него примеры, алгоритм сравнивает признаки этих примеров и выводы алгоритма, делая выводы о приоритете каких-либо из них. В случае с нейросетями обычно применяют именно черный ящик.
- Изучение свойств самой модели. Изучение признаков, которые использует модель, для определения степени их важности. Чаще всего применяется к алгоритмам, основанным на методе решающих деревьев.
Например, при прогнозировании брака на производстве признаки объектов
— это данные настроек станков, химический состав сырья, показатели датчиков, видео с конвейера и т. д. А ответы – это ответы на вопрос, будет ли брак или нет.Естественно, производство интересует не только прогноз самого брака, но и интерпретация результата, т. е. причины брака для их последующего устранения. Это может быть долгое отсутствие тех.обслуживания станка, качество сырья, или просто аномальные показания некоторых датчиков, на которые технологу стоит обратить внимание.
Потому в рамках проекта прогноза брака на производстве должна быть не просто создана ML-модель, но и проделана работа по её интерпретации, т. е. по выявлению факторов, влияющих на брак.

Когда эффективно применение машинного обучения?
Когда есть большой набор статистических данных, но найти в них зависимости экспертными или классическими математическими методами невозможно или очень трудоемко. Так, если на входе есть более тысячи параметров (среди которых как числовые, так и текстовые, а также видео, аудио и картинки), то найти зависимость результата от них без машины невозможно.
Например, на химическую реакцию кроме самих вступающих во взаимодействие веществ влияет множество параметров: температура, влажность, материал емкости, в которой она происходит, и т. д. Химику сложно учесть все эти признаки, чтобы точно рассчитать время реакции. Скорее всего, он учтет несколько ключевых параметров и будет основываться на своем опыте. В то же время на основании данных предыдущих реакций машинное обучение сможет учесть все признаки и дать более точный прогноз.
Как связаны Big Data и машинное обучение?
Для построения моделей машинного обучения требуются в разных случаях числовые, текстовые, фото, видео, аудио и иные данные. Для того чтобы эту информацию хранить и анализировать существует целая область технологий — Big Data. Для оптимального накопления данных и их анализа создают «озера данных» (Data Lake) — специальные распределенные хранилища для больших объемов слабоструктированной информации на базе технологий Big Data.
Цифровой двойник как электронный паспорт
Цифровой двойник — виртуальная копия реального материального объекта, процесса или организации, которая позволяет моделировать поведение изучаемого объекта/процесса. Например, можно предварительно увидеть результаты изменения химического состава на производстве после изменений настроек производственных линий, изменений продаж после проведения рекламной кампании с теми или иными характеристиками и т. д. При этом прогнозы строятся цифровым двойником на основе накопленных данных, а сценарии и будущие ситуации моделируются в том числе методами машинного обучения.
Что нужно для качественного машинного обучения?
Data Scientiest’ы! Именно они создают алгоритм прогноза: изучают имеющиеся данные, выдвигают гипотезы, строят модели на основе Data Set. Они должны обладать тремя основными группами навыков: IT-грамотностью, математическими и статистическими знаниями и содержательным опытом в конкретной области.
Машинное обучение стоит на трех китах
Получение данных
Могут быть использованы данные из смежных систем: график работ, план продаж. Данные могут быть также обогащены внешними источниками: курсы валют, погода, календарь праздников и т. д. Необходимо разработать методику работы с каждым типом данных и продумать конвейер их преобразования в формат модели машинного обучения (набор чисел).
Построение признаков
Проводится вместе с экспертами из необходимой области. Это помогает вычислить данные, которые хорошо подходят для прогнозирования целей: статистика и изменение количества продаж за последний месяц для прогноза рынка.
Модель машинного обучения
Метод решения поставленной бизнес-задачи выбирает data scientist самостоятельно на основании своего опыта и возможностей различных моделей. Под каждую конкретную задачу необходимо подобрать отдельный алгоритм. От выбранного метода напрямую зависят скорость и точность результата обработки исходных данных.
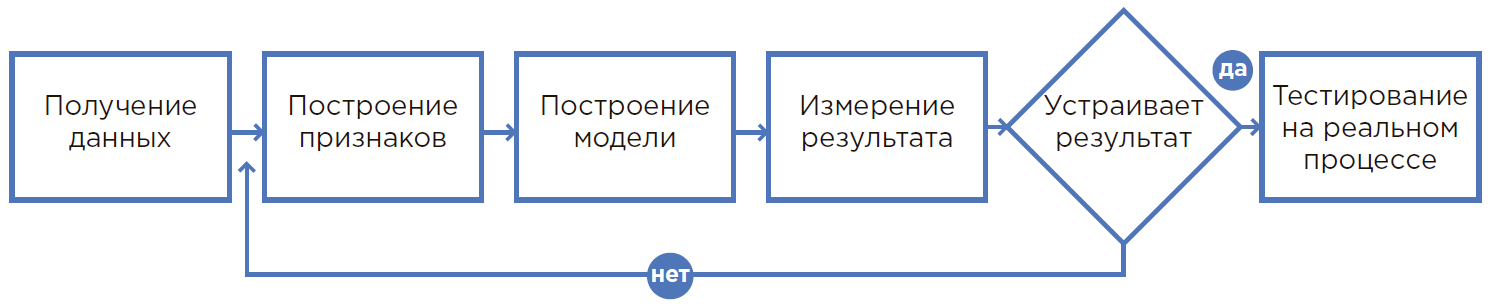
Процесс создания ML-модели.
От гипотезы до результата
1. Всё начинается с гипотезы
Гипотеза рождается при анализе проблемного процесса, опыта сотрудников или при свежем взгляде на производство. Как правило, гипотеза затрагивает такой процесс, где человек физически не может учесть множество факторов и пользуется округлениями, допущениями или просто делает так, как всегда делал.
В таком процессе применение машинного обучения позволяет использовать существенно больше информации при принятии решений, поэтому, возможно, удается достичь существенно лучших результатов. Плюс ко всему, автоматизация процессов с помощью ML и снижение зависимости от конкретного человека существенно минимизируют человеческий фактор (болезнь, низкая концентрация и т. д.).
2. Оценка гипотезы
На основании сформулированной гипотезы выбираются данные, необходимые для разработки модели машинного обучения. Осуществляется поиск соответствующих данных и оценка их пригодности для встраивания модели в текущие процессы, определяется, кто будет ее пользователями и за счет чего достигается эффект. При необходимости вносятся организационные и любые другие изменения.
3. Расчет экономического эффекта и возврата инвестиций (ROI)
Оценка экономического эффекта внедряемого решения производится специалистами совместно с соответствующими департаментами: эффективности, финансов и т. д. На данном этапе необходимо понять, что именно является метрикой (количество верно выявленных клиентов / увеличение выпуска продукции / экономия расходных материалов и т. п.) и четко сформулировать измеряемую цель.
4. Математическая постановка задачи
После понимания бизнес-результата его необходимо переложить в математическую плоскость — определить метрики измерений и ограничения, которые нельзя нарушать. Данные этапы data
scientist выполняет совместно с бизнес-заказчиком.
5. Сбор и анализ данных
Необходимо собрать данные в одном месте, проанализировать их, рассматривая различные статистики, понять структуру и скрытые взаимосвязи этих данных для формирования признаков.
6. Создание прототипа
Является, по сути, проверкой гипотезы. Это возможность построения модели на текущих данных и первичной проверки результатов ее работы. Обычно прототип делается на имеющихся данных без разработки интеграций и работы с потоком в реальном времени.
Создание прототипа — быстрый и недорогой способ проверить, решаема ли задача. Это весьма полезно в том случае, когда невозможно заранее понять, получится ли достичь нужного экономического эффекта. К тому же процесс создания прототипа позволяет лучше оценить объем и подробности проекта по внедрению решения, подготовить экономическое обоснование такого внедрения.
DevOps и DataOps
В процессе эксплуатации может появится новый тип данных (например, появится ещё один датчик на станке или же на складе появится новый тип товаров) тогда модель нужно дообучить. DevOps и DataOps — методологии, которые помогают настроить совместную работу и сквозные процессы между командами Data Science, инженерами по подготовке данных, службами разработки и эксплуатации ИТ-систем, и помогают сделать такие дополнения частью текущего процесса быстро, без ошибок и без решения каждый раз уникальных проблем.
7. Создание решения
В тот момент, когда результаты работы прототипа демонстрируют уверенное достижение показателей, создается полноценное решение, где модель машинного обучения является лишь составляющей изучаемых процессов. Далее производится интеграция, установка необходимого оборудования, обучение персонала, изменение процессов принятия решений и т. Д.
8. Опытная и промышленная эксплуатация
Во время опытной эксплуатации система работает в режиме советов, в то время как специалист еще повторяет привычные действия, каждый раз давая обратную связь о необходимых улучшениях системы и увеличении точности прогнозов.
Финальная часть — промышленная эксплуатация, когда налаженные процессы переходят на полностью автоматическое обслуживание.
Шпаргалку можно скачать по ссылке.
Завтра на форуме по системам искусственного интеллекта RAIF 2019 в 09:30 — 10:45 состоится панельная дискуссия: «AI для людей: разбираемся простыми словами».
В этой секции в формате дебатов спикеры объяснят простыми словами на жизненных примерах сложные технологии. А также подискутируют на следующие темы:
- В чем разница между Artificial Intelligence, Machine Learning и Data Science?
- Как работает машинное обучение?
- Как работают нейронные сети?
- Что нужно для качественного машинного обучения?
- Что такое разметка, маркировка данных?
- Что такое цифровой двойник и как работать с виртуальными копиями реальных материальных объектов?
- В чем суть гипотезы? Как пройти путь от её постановки до оценки и интерпретации результата?
В дискуссии принимают участие:
Николай Марин, директор по технологиям, IBM в России и СНГ
Алексей Натекин, основатель, Open Data Science x Data Souls
Алексей Хахунов, технический директор, Dbrain
Евгений Колесников, директор Центра машинного обучения, Инфосистемы Джет
Павел Доронин, CEO, AI Today
Дискуссия будет доступна на канале YouTube «Инфосистемы Джет» в конце октября.
