Привет, друзья!
Прошлой осенью мне по работе понадобилось протестировать решения для защиты сред контейнеризации (я работаю ИБ-инженером), но готового стенда с микросервисной архитектурой для этого не оказалось. Мотор-то мы купили, да трактор… у нас украли. Почувствовался резкий дефицит систем оркестрации контейнеров, и в воздухе запахло приключением!

Так как мои Ops коллеги всегда на острие интеграций и внедрений, денно и нощно разворачивают сложнейшие системы и вычислительные комплексы, просить их «по-быстренькому запилить кластер OpenShift» совсем не укладывалось в концепт инженерной солидарности. Поэтому я принял волевое решение — делать самому! Не без советов коллег, разумеется, ибо с Sec’ом да прибудет мудрость Ops’а.
Забегая вперед, скажу, что в итоге стенд удался и даже вполне себе работает по сей день, а мне хочется поделиться с вами полученным опытом.
Итак, речь пойдет о платформе оркестрации Red Hat OKD 3.11. Сразу оговорюсь, что, хотя уже вышла ее новая, четвертая мажорная версия, предыдущие все еще широко используются для работы микросервисных приложений в контейнерах. Даже там, где в test уже пробуют 4.x, в prod по-прежнему частенько задействуют 3.x.
Решение Red Hat OKD 3.11 весьма любопытное, однако общественное мнение о нем противоречивое.
Одни говорят:
Бабка ставит самовар, да начнется холивар…
Но мы тут не ради холивара. Давайте вместе попробуем с нуля развернуть платформу, позапускать ручки внутрь OKD 3.11 <отрегулируем жиклеры и настроим зажигание>, а затем сами во всем убедимся. А еще поговорим немного о безопасности — тема обширная, и ей иногда пренебрегают (да-да, и у «них» тоже). Надеюсь, что если вы не сталкивались с Red Hat OpenShift / OKD, то эта статья послужит для вас обзорным гайдом и поможет не наступать на мои грабли. Если же вы работали с платформой — you know kung fu.
И, как вы уже успели заметить, комментарии моего альтер эго могут проскакивать по тексту в скобочках <> — не пугайтесь.
Дисклеймер: мнение автора может не совпадать с мнением редакции, маркетингового департамента Red Hat, президента Уругвая и кошки автора!
Не будем погружаться в историю и выяснять, кто первым придумал концепцию контейнеров, Google или Red Hat. Посмотрим, что платформа предлагает нам сейчас. Для этого попробуем развернуть систему на своих мощностях, а именно: подготовим инфраструктуру, сконфигурируем окружение, запустим установку и попытаемся поправить возникающие по ходу дела проблемы <они будут, уверяю>, после чего подготовим систему к работе. Что-то типа «Cold & Dark to Ready for Taxi».

Так вышло, что хорошие инженеры и славные ребята <кстати, в Google есть такая позиция > начинают с чтения документации. На портале Red Hat нас встречают «дружелюбный» интерфейс и большое количество разделов документации. Правда, хронология сходу может показаться не совсем понятной. В документации есть ответы практически на все вопросы <но читать ее бывает больно>. Здесь вы найдете описание архитектуры, компонентов системы и множество гайдов по настройке, траблшутингу и действиям на случай большинства возможных ситуаций.
Посмотрев на требования платформы к вычислительной системе, вы увидите слова «additional are strongly recommended». Это значит, что если ресурсов у вас не много, то взлетит оно с трудом <ну как Crysis на некропека>, так как все указанное — необходимый минимум. В остальном, сколько вычислительных ресурсов вы системе дадите, столько она и сожрет, и это вполне нормально, так как система заточена на быструю и легкую масштабируемость. Платформа достаточно требовательна к ресурсам, и в самой простой инсталляции ей необходимы одна master нода, две worker ноды и одна infra нода. Что это, почему так, и для чего они нужны?
Master — это управляющие серверы, на которых работает ядро системы. Они управляют развертыванием контейнеров, хранят в себе конфигурации системы, на них шуршит API, через который все компоненты системы общаются между собой. Короче говоря, мозги. Минимальное количество — один.
Worker — рабочий сервер, в первом приближении — «ведро» контейнеров. По сути это вычислительная среда, предоставляющая мощности для работы контейнеров. Управляются, как и следовало ожидать, мастерами. Минимальное количество — два.
Infra — тоже воркер, но служебный. На нем развернуты сервисные контейнеры внутреннего реестра образов (где хранятся образы), роутер (контейнерный маршрутизатор, об этом позже) и контейнеры системы мониторинга (сбор и отображение метрик о состоянии системы). Контейнеры с другими приложениями на нем не поднимаются. Минимальное количество — один.
Вся система представляет собой набор контейнеров, а в нашей инсталляции будет еще отдельный сервер под NFS и DNS, на нем же развернем Ansible, с помощью которого выполним установку. Ну, и простим платформе ее жирноту в угоду удобству и отказоустойчивости.
Мой on-premise стенд обладает следующими характеристиками:

Развернул я все это добро в облаке vCloud, где создал виртуальные машины с указанными характеристиками. На каждой из них установил CentOS 7.4-1708 в паке web-server (оптимальный вариант, т.к. занимает не слишком много места, и большинство нужных пакетов уже есть), создал привилегированных пользователей и через network manager прописал сетевые настройки. Так что все серверы доступны друг для друга.
Все долгосрочное хранение данных контейнеризированных сервисов в моем случае будет расположено на NFS (сервер Bastion) в каталогах persistent volume’ов, поэтому можно обойтись без большой дисковой емкости непосредственно на самих нодах. Контейнеры хранят данные внутри себя в течение жизненного цикла, то есть, пока не будут остановлены. Если требуется постоянное хранение данных, не зависящее от удаления и перезапуска контейнеров, то оно происходит в сущности под названием persistent volume. Это своего рода каталог с данными, доступными определенным контейнерам в соответствии с настроенными политиками доступа. Грубо говоря, приложение в контейнере записывает данные в persistent volume, под которым по факту находится каталог NFS, куда попадут эти данные. После перезапуска контейнера или, например, добавления второй реплики контейнера с приложением оба приложения из обоих контейнеров все равно будут иметь доступ к этим данным.
OpenShift поддерживает ряд плагинов для подсистем хранения данных: NFS, GlusterFS, Ceph RBD, OpenStack Cinder, AWS Elastic Block Store (EBS), GCE Persistent Disks и iSCSI. Выбор плагина зависит от конкретной инсталляции и требуемых задач, и я не возьмусь сказать, какой лучше использовать <поджигать реактивные струи в комментариях — ну уж нет>.
Я выбрал NFS, потому что его просто и быстро развернуть, благо в интернете полно инструкций и гайдов. Однако вендор не рекомендует использовать такой вариант в prod. Для тестов, демо и всего такого его вполне достаточно, но в prod могут возникнуть сложности. Например, OpenShift не создает каталоги на NFS для хранения данных, их придется создать и экспортировать заранее. Для сотен и тысяч контейнеров в сотнях проектов создавать каталоги руками будет не гуд.
Давайте вернемся к платформе. В идеальном мире конфигурация платформы будет примерно такой, как на рисунке ниже. Это полная рекомендуемая инсталляция — дальше можно масштабировать добавлением worker’ов, сколько влезет.
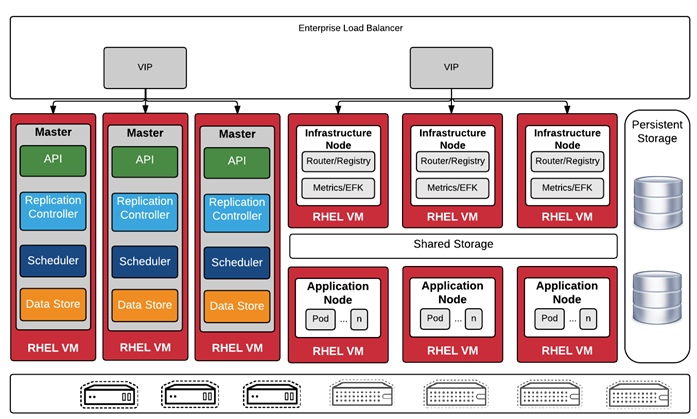
Три Master ноды — обеспечивают отказоустойчивость для зачач хранения конфигураций (etcd datastore), управления репликами контейнеров (Replication controller) и планирования развертывания новых контейнеров (scheduler), а также служат для управления системой.
Три Worker ноды (они же Application Node) — по ним равномерно размазываются контейнеры с приложениями (если не настроено иначе), причем в случае отказа какой-то ноды они перетекут на другие.
Три Infra ноды — тут все происходит по аналогии с worker, только со служебными контейнерами.
Load Balancer — условно говоря, это как бы NAT для виртуальной внутренней сети, к которой подключены контейнеры и роутер для трафика между ними. Детально рассматривать не буду, потому как непосредственно его настраивать не стану. Скажу только, что это виртуальный маршрутизатор, умеющий разруливать сетевой трафик и раскидывать его по нужным контейнерным сервисам.
Ansible Master — этот компонент не является частью непосредственно платформы, но стоит упоминания. Если вы сталкиваетесь с ним впервые, вот пара слов о том, что это и зачем:
Попробую объяснить на пальцах, как это работает: мастер-хост Ansible подключается по сети к целевым хостам и может автоматически их настраивать. Чтобы это работало, у него есть первое — файл inventory, в котором прописаны параметры доступа к целевым хостам: их IP-адреса, пользователь, под которым нужно подключаться, и его пароль (это минимум). И второе — playbook, то есть перечень заданных значений параметров для настройки. Ansible проверяет значение конкретного параметра и задает необходимый. Грубо говоря, система проверяет systemctl is-enabled docker и ожидаемое значение, например enabled, если значение от целевого хоста возвращается disabled, соответственно, выполняет systemctl enable docker, задав таким образом требуемое значение параметра. Пример деревянный, но суть приблизительно такая.
В сложных системах применяются переменные для значений параметров конфигураций, SSH-ключи для авторизации, дочерние группы хостов для группировок целевых хостов по различным типам и много других крутых штук, которые очень полезны, но тянут на отдельную статью. Когда столкнемся с ними по ходу установки, посмотрим чуть детальнее.
Пока нам достаточно понимать, что это сервер, который умеет настраивать другие серверы. Очень полезная вещь, если на целевом сервере нужно много всего настроить, и таких серверов большое количество. Делать он это может отправкой команд на целевые хосты либо заливкой конфигурации из файла. Естественно, при условии сетевой связности машин.
Но вернемся к OpenShift. В нашем случае инсталляция будет проще: 1 master, 1 infra и 2 worker’a (рисунок ниже). Исходя из опыта использования в тестовой среде около полугода, работать это будет, но до первой проблемы с master. Как только он упадет <никогда такого не было, и вот опять>, например, произойдет программный сбой в ОС, отвалится сеть, криво обновится какой-нибудь Python 2.7 или еще что-то подобное, платформа станет неработоспособной (во избежание как раз этого, мастеров рекомендуется три штуки). Справедливости ради, должен заметить, что после устранения проблем и нормальной загрузки ноды все само поднимается, подключается назад и работает дальше, как будто ничего не было.

Порядок действий по установке системы есть в инструкции на портале вендора, но отдельно обращу внимание на некоторые моменты, где есть нюансы:
Ладно, погнали уже!
С помощью network manager’а задаю конфигурацию сети, сразу указываю свой будущий DNS — ничего необычного. Мне удобнее через nmtui.
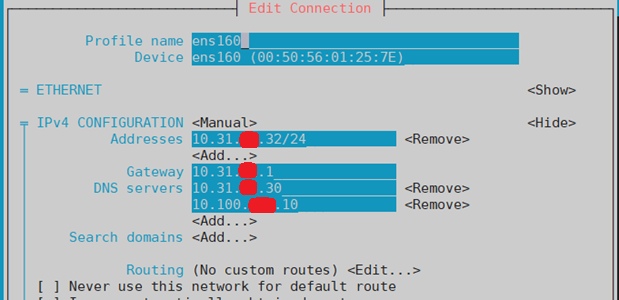
Назначаю hostname:
для master,
для worker-1 и так далее.
Домен okd.local у меня будет локальным, для него я создам отдельную DNS-зону. Вы можете придумать домен по своему вкусу. Cпокуха, мы сейчас до этого дойдем. Выполнить эту настройку, соответственно, нужно для всех master, worker и infra нод.
В моем случае — просто Bind. Нужен для отработки запросов в кластерном домене. Приложения внутри кластера могут общаться между собой в том числе через доменные имена. Все эти доменные имена будут расположены в кластерной зоне, которую DNS и обслуживает.
Вкратце, зачем это нужно. Приложения работают в контейнерах, которые крутятся внутри кластера в виртуальной сети. Они постоянно запускаются, уничтожаются, реплицируются <и, вообще, движуха с ними похожа на азиатские перекрестки>, поэтому для маршрутизации сетевого трафика использовать IP-адреса контейнеров бессмысленно — они постоянно меняются. Для этого можно привязаться к доменным именам, и всю маршрутизацию выполнять по ним. Именно это в OpenShift и делает роутер. А чтобы FQDN-адреса сервисов можно было отрезолвить, необходим пресловутый DNS-сервер.
Устанавливаю пакеты:
Запускаю и включаю автозагрузку сервиса:
Открываю и привожу файл конфигурации bind /var/named/chroot/etc/named.conf к следующему виду (убрал под спойлер):
Что я сделал? <сотворил монстра>
Я задал такие параметры:
Если совсем лень, можете все оставить по умолчанию — работать будет. Идем дальше.
Для начала, собственно, нужно создать эту зону. Я описываю файл зоны в named.conf (т.е. говорю named’у: «Параметры зоны ищи там-то») и указываю файл зоны в конце файла. Вот так:
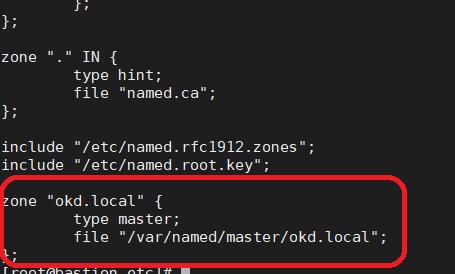
А теперь создаю этот самый файл зоны <я люблю пользоваться Nano, хотя со временем почувствовал странное ощущение при использовании Vim… не то щекотка, не то зуд>.
И содержимое файла (под спойлером):
И сохраняю (в nano ctrl+x).
Пара слов о том, что я сделал: создал новую зону, которую будет резолвить DNS-сервер, и указал в ней необходимые хосты. Я сказал DNS’у, что все запросы на master, api, infra и т.д. будут попадать на соответствующие хосты, и указал их IP-адреса. Тут ничего сложного, но что за API?
Это — API-сервер самого OpenShift (сиречь — Kubernetes), с помощью которого пользователь и компоненты системы могут общаться с ее ядром, а также компоненты между собой. Например, программы oc и kubectl (пользовательские консольные оболочки) производят ввод-вывод как раз через этот API. Если вы говорите системе oc get nodes (команда показать статус нод кластера), oc под капотом делает запрос в API, а он в свою очередь возвращает ответ, который oc переводит в понятный человеку вид… <в доме, который построил Джек>
Такой записью я в явном виде указал, что этот API работает на master.
Запись с вайлдкардой *.okd.local означает, что все адреса в домене okd.local (а это будут приложения в контейнерах, типа app1.okd.local, app2.okd.local и т.д.) работают за адресом 10.31.хх.31, которым является моя infra нода с роутером. Некисло так уровней абстракции, да? DNS на внешний запрос отвечает, что, например, приложение app1.okd.local находится на 10.31.хх.31, где роутер, который сам работает в контейнере, смаршрутизирует пакет и отправит его в другой контейнер, на ту ноду, где крутится приложение <я уже сам не очень уверен, что написал верно>.
Короче говоря, файл зоны я создал, сохранил и скормил Named’у. Теперь давайте перезапустим DNS и посмотрим, чтобы не было ошибок:
Команда должна выполниться и ничего не писать в ответ. Если получилось иначе, посмотрите сообщение об ошибке: она подскажет, где проверить, что именно пошло не так. Обычно для этого нужно обратиться в /var/log/messages или journalctl. Что именно там смотреть, вы также узнаете из сообщения об ошибке.
Обязательно проверьте, что все работает! Ошибка здесь чревата тем, что кластер не поднимется на этапе развертывания. Когда завершится установка API, и далее по плейбуку пойдут проверки healthcheck с его использованием, он может тупо не отвечать, т.к. будет недоступен, если DNS не отрезолвит его адрес. И тогда придется очень-очень долго ломать голову и искать ошибку <и готовиться к разводу с женой из-за того, что ночами пропадаешь на работе >, у меня было именно так, благо обошлось <жена — женщина чуткая и понимающая>. А виной всему была просто опечатка в конфигурации зоны.
Для этого проверьте настройку DNS в /etc/resolv.conf, конфигурацию hostname, и отвечают ли серверы по именам. Например, так:
В /etc/resolve.conf убедитесь, что прописан верный DNS.

Проверьте на нодах hostname.

Проверьте, что ноды пингуются по имени.

nslookup или dig’ом проверьте, что ноды резолвятся с правильным доменным именем.
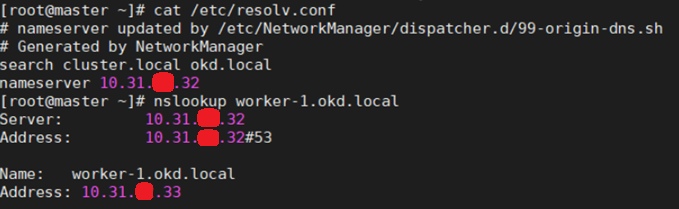
Соответственно, все это надо проверить на всех нодах кластера, включая сервер с DNS. Важно, чтобы настройки были идентичны на всех серверах, и для каждого были соответствующие. Например, hostname для master был master.okd.local, для infra — infra.okd.local и так далее. Если все верно — отлично, если нет — приведите к правильному виду. Лучше перепроверьте все сейчас, чем потом будете долго и муторно выискивать ошибку. Поехали дальше…
Настроим беспарольное подключение по SSH для выполнения Ansible плейбуков. С этого момента можно считать, что мы приступили к установке OpenShift. Отключать пароли я не буду — просто сгенерирую ключи и импортирую их на хост Ansible master.
На каждом хосте сгенерируйте SSH-ключи. Как я уже говорил, они понадобятся для того, чтобы Ansible master мог подключиться под привилегированным пользователем и выполнять команды настройки хостов так, чтобы при этом приходилось вручную вводить пароли пользователей. Для этого на всех целевых хостах выполните:
И на все вопросы протыкайте Enter. В итоге сервер покажет директорию, в которой сохранен ключ, его отпечаток и рандомарт.
После этого, собственно, беспарольное подключение. Если вы хоть раз пользовались Ansible, вам все должно быть понятно. Если такого опыта у вас не было, поясню: Ansible выполняет команды на целевых хостах, будучи залогиненым на них указанным пользователем и подключенным по SSH. Чтобы плейбук (или простая ad-hoc команда) мог отрабатывать, ему нужно указать адрес хоста назначения, пользователя, под которым Ansible должен подключаться, и в самом простом случае — пароль. Чтобы каждый раз не подтверждать подключение и не вводить пароль, импортируйте публичные SSH-ключи с целевых машин на Ansible master. Разумеется, ключи должны быть уже сгенерированы (см. выше). Для этого на Bastion (который Ansible master) выполняем:
Теперь в каталоге ~/.ssh/id_rsa.pub должны появиться скопированные ключи. Проверить, что все в порядке, можно путем подключения с Bastion к каждому хосту. Категорически рекомендую и жалостливо умоляю это сделать:
На запрос подтверждения нужно ответить yes. Сервер должен залогиниться на каждый хост без ввода пароля, а благодаря тому, что мы приняли предложение подключиться, больше оно появляться не будет. Для отработки плейбуков это хорошо: не надо будет каждый раз при их запуске жмакать yes.
Все там же, на хосте Bastion.
Тут есть нюанс. Указанный порядок работает для CentOS, а для RHEL процедура выглядит несколько иначе. Например, в RHEL нужно активировать подписку на обновления через subcribition manager, зарегистрировать на портале Red Hat свои хосты, выбрать необходимые репозитории и производить установку с них. В моем же случае, т.к. CentOS на портале не зарегистрировать, выполняю простую установку при помощи RPM-пакетов. Результат будет одинаковый, так что это не принципиально.
Подробнее об этом можно посмотреть в инструкции.
В принципе, не все из указанного может понадобиться, но это полный пак утилит для настройки и траблшутинга возможных проблем. Поэтому лучше не ломаться, а поставить все:
Устанавливаю репозиторий epel, с него загружу Ansible.
Глобально выключаю репозиторий, чтобы в дальнейшем по умолчанию пакеты грузились и обновлялись с дефолтных репо.
И наконец выполняю установку ansible rpm из репозитория epel:
<Да какого черта так много? Где просто кнопка INSTALL?????>
Тут каточка на изи: я сходил в домашний каталог, склонировал в него с Гитхаба архив с плейбуками и всеми нужными файлами и убедился, что взял нужную версию.
Это делаю на нодах master, infra и обоих worker! Там, где платформа будет крутиться.
Что я сделал? Установил Docker в качестве контейнерного движка и включил его хранилище. Но помните, что это сторадж для хранения загруженных образов и вообще для самого докера. Это не сторадж для приложений в контейнере, его нужно будет создать в самой платформе позже. Вообще, на этом этапе можно не останавливаться подробно, потому что конфигурацию хранилища, ее безопасность и прочие нужные штуки возьмет на себя OpenShift. Docker будет тупо запускать контейнеры так, как скажет платформа.
Хранение тут я оставил по самому дефолтному дефолту, и дополнительных настроек обычно не требуется. Однако в некоторых случаях может появиться надобность что-то сконфигурировать. Я использую простой драйвер device-mapper, а для хранилища — простые блочные устройства, диски /sda, /sdb и так далее.
<А ведь еще даже не запустили установку>
Первым делом приведу ссылку на документацию по этому разделу. Она понадобится… I know that feel bro…
Тут остановлюсь чуть подробнее, так как здесь большой кусочек боли и бессонницы — верных спутников первой установки OpenShift 3.x. Inventory файл описывает установку платформы, типы и роли ее нод, конфигурацию дополнительных модулей и много всего прочего. Он хранит в себе переменные, используемые плейбуком при выполнении, и их целевые значения. В самом простом случае inventory файл мог бы выглядеть как-то так (это пример с тестового стенда, Openshift тут ни при чем — просто для наглядности):

Тут можно увидеть группы серверов (RHEL, DEBIAN, windows), называются они Children — дочерние как бы. Например, если надо установить на все серверы net-tools, то для RHEL based операционных систем хостов команда в плейбуке будет yum install net-tools, а для Debian based Ubuntu — apt-get install net-tools. Вот для того, чтобы один плейбук, пытающийся выполнить две эти команды, не валил сразу на все серверы в логи ошибку о том, что он не может выполнить yum на Ubuntu и apt-get на RHEL, целевые хосты можно разбить на группы. Для группы RHEL выполнять плейбук с yum, а для Ubuntu — с apt-get. Очень топорный пример, но суть, думаю, понятна.
Соответственно, в каждой группе указан хост с придуманным именем (-=CentOS-1=- / 2 и так далее), отображаться он будет только при выполнении плейбука. Это нужно для того, чтобы пользователь понимал, на каком хосте что происходит, и где случилась ошибка. Присутствует IP-адрес этого хоста, пользователь для подключения и его пароль.
Да, кстати, Windows Ansible тоже умеет конфигурировать, он делает это по-другому, и, пожалуйста, давайте не будем об этом, мы здесь сейчас не за этим.
Так вот, в inventory файле для развертывания OpenShift все хосты также разделены на группы по их ролям (master, worker, infra и все такое), а еще сразу добавлены переменные конфигурации самой системы. То есть сначала, при выполнении, Ansible подгоняет конфигурации хостов к целевым (это плейбук prerequisites.yml), а далее, когда он начинает разворачивать систему (плейбук deploy-cluster.yml) и задавать параметры ее конфигурации, то берет эти самые параметры из указанных в inventory переменных.
Возвращаясь к тому, как выглядит invetory файл: спрятал под спойлер мой inventory от OpenShift — там чад кутежа, например.
Пф-ф-ф, да все понятно, ваще изи…
Детально файл описан в документации <но я не хочу делать никому больно>, обращу внимание на то, что надо поменять следующие переменные Ansible Inventory (напоминаю, это все находится Bastion):
ansible_ssh_user=root — здесь вам нужно задать пользователя, под которым Ansible может залогиниться на ноду (чей ключ скопировали для доступа SSH по ключу). Я сделал под root <исключительно для того, чтобы лишний раз напомнить, что никогда-никогда нельзя работать из под root, а не потому что ленивый, мамой клянус>.
openshift_master_default_subdomain=apps.okd.local — здесь и далее укажите домен из созданной зоны, у меня это okd.local.
openshift_master_cluster_hostname=api.okd.local
openshift_master_cluster_public_hostname=console.okd.local
openshift_console_hostname=console.apps.okd.local
openshift_metrics_storage_volume_size=40Gi — тут можете указать размер хранилища метрик мониторинга.
openshift_logging_storage_volume_size=50Gi — здесь можете указать размер хранилища логов.
openshift_hosted_etcd_storage_volume_size=5G — можете указать размер хранилища etcd, это хранилище конфигураций.
Дальше те самые Children группы. В данном случае они привязаны к роли ноды:
# host group for masters
[masters]
master — тут хостнейм мастера.
# host group for etcd
[etcd]
master — тут тоже hostname мастера, потому что конфига хранится на нем.
[nfs]
bastion — хостнейм NFS-сервера (если разворачивали). У меня это Bastion с Ansible, DNS и NFS.
[nodes]
master openshift_node_group_name=«node-config-master» — мастеру указываем роль node-config-master. Trust me, просто указываем.
worker-1 openshift_node_group_name=«node-config-compute» — рабочим нодам указываем роль node-config-compute.
worker-2 openshift_node_group_name=«node-config-compute»
infra openshift_node_group_name=«node-config-infra» — инфра нодам указываем роль node-config-infra.
После всех подготовительных мероприятий требуется запустить плейбук из скачанного пака. Плейбуков там много, и многие из них предназачены для дальнейшего обслуживания, например, расширения хранилища логов и мониторинга, добавления нод в кластер, ротации сертификатов шифрования и т. д.
Хочется сказать пару слов про всю эту установку, поделиться сугубо моими ощущениями. Автоматизация с помощью Ansible — в целом клевая тема, однако для такой сложной штуки, как OpenShift, процесс инсталляции требует огромного количества проверок и конфигураций целевых хостов. В результате вполне возможен <и ваш покорный слуга подвергался подобному насилию целую неделю> сбой по ходу отработки плейбука, что приведет к остановке инсталляции.
Безусловно, Ansible покажет этап, на котором произошла ошибка, некоторое ее описание и так далее. Однако полагать, что причина ошибки будет понятна из отчета выполнения плейбука, к сожалению, очень наивно. Так что, скорее всего, вам придется лезть во всевозможные логи и журналы и анализировать, где произошла ошибка и в чем она заключается. Sad but true…
Однако Red Hat в корне поменял свой подход, и уже в мажорных 4-ых версиях используется операционная система CoreOS, которую можно развернуть на нодах одновременно с инсталляцией платфморы. Очень круто, но об этом в другой раз.
После запуска выполнение плейбука займет минут 15 <это, если сразу не грохнется с ошибкой, лол>.
По завершении Ansible выводит краткую сводку по выполнению. Типа такой, только цифры будут больше:
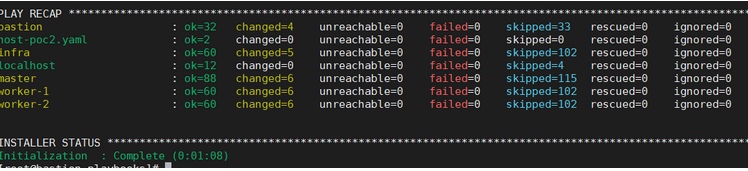
К каждому хосту из файла inventory приведено количество задач (TASK) из групп плейбуков. Иными словами, это действия по настройке.
В случае неудачи в сводку добавится информация о задаче и переменной, с которой произошла ошибка.
В случае неудачного выполнения плейбука в Ansible предусмотрен режим отладки выполнения. Запустить его можно путем выполнения плейбука с ключом -v. Например:
В таком случае Ansible будет показывать детали выполнения каждой задачи. Чтобы повысить детализацию, добавьте дополнительный ключ -v. Для максимальной детализации укажите 5 ключей (-vvvvv).
Когда выполнение плейбука закончится, убедиться в том, что все получилось <или нет>, поможет вывод команды статуса нод кластера (на master.okd.local):
И-и-и-и…

Наконец-то!
При успешной установке кластера для доступа на веб-интерфейс надо указать IP-адрес мастер ноды. Я просто прописал в hosts master.okd.local:
10.31.хх.32 console.okd.local
После этого будет доступен веб-интерфейс консоли по адресу https://console.okd.local:8443.
ВАБА – ЛАБА – ДАБ – ДАБ! Кластер проинсталлирован!

Касательно инсталляции при помощи плейбуков: предполагается запустить первый плейбук, перекурить, налить чай и после его успешного выполнения, минут так через десять—пятнадцать, запустить второй, кластерный деплой. Само собой, этот уже будет пожирнее, и можно даже успеть перекусить: я в этот момент в десятом часу вечера вторника успел дойти от офиса до кафешки с шаурмой, заскочить в ларек за газировкой и вернуться в офис, схомячив шаурму.
И вот, по завершении второго плейбука, вывод команды oc get nodes должен показать все ноды в статусе ready, и веб-консоль оказалась доступна…
И-и-и-и… Нет.
По ходу выполнения есть вероятность неявных проблем, например:
1. В файле inventory есть такой параметр:
openshift_disable_check
В моем случае он имеет значение:
=memory_availability,disk_availability,package_availability,docker_image_availability,docker_storage,package_version
В него я добавил выделенный жирным параметр.
Как это было в жизни
При выполнении плейбука prerequisites есть этап Check Docker image availability с хэндлером, он циклично повторяется некоторое количество раз, пока заданный параметр не получит ожидаемое значение — это в контексте Ansible. В реальности же происходило то, что демон Docker искал в публичном реестре некоторый образ, который по какой-то причине был недоступен. Из-за запутанности переменными и ссылками плейбуков на плейбуки найти концы в тот момент мне так и не удалось.
Что оказалось
Это был образ консоли внутреннего реестра образов. В OpenShift есть сам реестр образов, в котором можно хранить свои образы, а есть консоль — веб-интерфейс для этого реестра для удобного просмотра содержимого. Образ этой консоли как раз и оказался недоступен, и сама она не работала.
А когда понадобилась, мне пришлось найти новый образ, заменить им старый в конфигурации деплоймента консоли и пересоздать эту консоль. Потому как на момент инсталляции я этого не знал, то решил попробовать добавить проверку в исключение и посмотреть, на чем зафейлится выполнение плейбука дальше.
Это только один из примеров, демонстрирующих неожиданные векторы проблем, которые могут возникнуть при раскатывании OpenShift из плейбуков. Хотя, безусловно, о самой идее попытаться автоматизировать установку так, чтобы после запуска двух плейбуков все само стало ОК, ничего плохого сказать нельзя.
С горем пополам выполнение prerequisites плейбука завершилось успешно, я закинулся валокордином и поставил на выполнение плейбук deploy-cluster. Тут все также гладко не прошло.
2. Возникла ошибка о том, что сетевой плагин SDN не работает.
Главная сложность деплоя посредством набора плейбуков, битком набитых переменными и ссылками на другие плейбуки, заключалась в проблематичности поиска причин ошибок. Например, на этапе установки плагина SDN (внутренней виртуальной сети платформы) Ansible отрапортовал ошибкой. В логах машины будущего мастера оказалось множество ошибок о сетевой недоступности. Как выяснилось сильно позже, проблема была в опечатке в конфиге DNS-зоны. В плейбуке происходила проверка доступности API-сервера по его доменному имени, которое было задано из inventory. В конфигурации DNS-зоны FQDN-имя было написано неправильно, и DNS его не резолвил. В результате API-сервер на master был недоступен, что плейбук интерпретировал как ошибку сетевого плагина.
Знаю-знаю, сам криворукий, но выловить ошибку удалось, только глубоко погрузившись в логи DNS, master ноды и ручную проверку доступности хостов между собой…

Я не говорю, что способ развертывания плохой. Я лишь утверждаю, что отловить ошибку при инсталляции, да еще на нескольких машинах, тем более на нескольких уровнях абстракции, когда к тому же не понимаешь, что делаешь, очень проблематично.
И вот ошибки отловлены и исправлены, процесс инсталляции завершен, и мы можем пользоваться платформой. Взглянем, что она может нам предложить.
Слышал такое мнение:
Что ж, звучит вполне складно.
Из коробки мы имеем:
Кстати, на правах оффтопа, не могу не отметить кое-какие изменения в Red Hat OpenShift 4-ой версии (подробный обзор от моих Ops-коллег можно почитать тут).
Отличий на самом деле много, но первое, с которым вам придется столкнуться, — это процесс инсталляции. Тут вендор кардинально изменил подход, отказавшись от идеи использования Ansible. Вместо этого теперь используется метод инсталляции на хосты образов CoreOS. Это операционная система от Red Hat, позиционируемая вендором как легковесная, специально заточенная под развертывание кластеров, имеющая минимальную необходимую функциональность, в которой приложения работают в контейнерах. Система заливается при помощи PxE-сервера, оттуда же в процессе развертывания подтягиваются все конфигурации, и в целом процесс установки состоит по сути из этапа подготовки всех конфигураций и этапа ожидания, пока все само развернется.
Сам кластер OpenShift 4.x, кстати, работает практически весь в контейнерах и обладает новой сущностью — operator, контейнерами, которые умеют разворачивать другие контейнеры с приложениями и всегда следить за их работоспособностью. Но об этом есть статьи от самого Red Hat :)
Собственно, друзья мои, вот мы с вами вместе и установили систему. Теперь можно выдохнуть и похвалить себя. В другой статье мы позанимаемся так называемыми «day 2 operations» — вещами, которые стоит сконфигурировать после инсталляции. И конечно же, не обделим вниманием средства безопасности: я расскажу, что такое Security Context Constraints, Network Policies, и объясню, зачем надо мыть руки перед деплоем приложения!
Продолжение следует.
P.S. Всех желающих поговорить о DevSecOps приглашаю на канал«DevSecOps Talks»: tlgg.ru/devsecops_weekly. Там мы с командой делимся интересными обзорами по теме, полезными ссылками и вносим посильный вклад в развитие культуры безопасной разработки.
Прошлой осенью мне по работе понадобилось протестировать решения для защиты сред контейнеризации (я работаю ИБ-инженером), но готового стенда с микросервисной архитектурой для этого не оказалось. Мотор-то мы купили, да трактор… у нас украли. Почувствовался резкий дефицит систем оркестрации контейнеров, и в воздухе запахло приключением!

Так как мои Ops коллеги всегда на острие интеграций и внедрений, денно и нощно разворачивают сложнейшие системы и вычислительные комплексы, просить их «по-быстренькому запилить кластер OpenShift» совсем не укладывалось в концепт инженерной солидарности. Поэтому я принял волевое решение — делать самому! Не без советов коллег, разумеется, ибо с Sec’ом да прибудет мудрость Ops’а.
Забегая вперед, скажу, что в итоге стенд удался и даже вполне себе работает по сей день, а мне хочется поделиться с вами полученным опытом.
Итак, речь пойдет о платформе оркестрации Red Hat OKD 3.11. Сразу оговорюсь, что, хотя уже вышла ее новая, четвертая мажорная версия, предыдущие все еще широко используются для работы микросервисных приложений в контейнерах. Даже там, где в test уже пробуют 4.x, в prod по-прежнему частенько задействуют 3.x.
Решение Red Hat OKD 3.11 весьма любопытное, однако общественное мнение о нем противоречивое.
Одни говорят:
— Смузи и подвороты! Навесили свистелок на Vanilla Kubernetes и толкают как энтерпрайз. Proof me wrong!Другие противостоят:
— А еще раньше на корове деревянным плугом пахали. Если собрали все в кучу и заставили работать хорошо, да еще вдогонку дали вендорскую поддержку, почему бы и нет?
Бабка ставит самовар, да начнется холивар…
Но мы тут не ради холивара. Давайте вместе попробуем с нуля развернуть платформу, позапускать ручки внутрь OKD 3.11 <отрегулируем жиклеры и настроим зажигание>, а затем сами во всем убедимся. А еще поговорим немного о безопасности — тема обширная, и ей иногда пренебрегают (да-да, и у «них» тоже). Надеюсь, что если вы не сталкивались с Red Hat OpenShift / OKD, то эта статья послужит для вас обзорным гайдом и поможет не наступать на мои грабли. Если же вы работали с платформой — you know kung fu.
И, как вы уже успели заметить, комментарии моего альтер эго могут проскакивать по тексту в скобочках <> — не пугайтесь.
Дисклеймер: мнение автора может не совпадать с мнением редакции, маркетингового департамента Red Hat, президента Уругвая и кошки автора!
Не будем погружаться в историю и выяснять, кто первым придумал концепцию контейнеров, Google или Red Hat. Посмотрим, что платформа предлагает нам сейчас. Для этого попробуем развернуть систему на своих мощностях, а именно: подготовим инфраструктуру, сконфигурируем окружение, запустим установку и попытаемся поправить возникающие по ходу дела проблемы <они будут, уверяю>, после чего подготовим систему к работе. Что-то типа «Cold & Dark to Ready for Taxi».

С чего начать?
Так вышло, что хорошие инженеры и славные ребята <кстати, в Google есть такая позиция > начинают с чтения документации. На портале Red Hat нас встречают «дружелюбный» интерфейс и большое количество разделов документации. Правда, хронология сходу может показаться не совсем понятной. В документации есть ответы практически на все вопросы <но читать ее бывает больно>. Здесь вы найдете описание архитектуры, компонентов системы и множество гайдов по настройке, траблшутингу и действиям на случай большинства возможных ситуаций.
Посмотрев на требования платформы к вычислительной системе, вы увидите слова «additional are strongly recommended». Это значит, что если ресурсов у вас не много, то взлетит оно с трудом <ну как Crysis на некропека>, так как все указанное — необходимый минимум. В остальном, сколько вычислительных ресурсов вы системе дадите, столько она и сожрет, и это вполне нормально, так как система заточена на быструю и легкую масштабируемость. Платформа достаточно требовательна к ресурсам, и в самой простой инсталляции ей необходимы одна master нода, две worker ноды и одна infra нода. Что это, почему так, и для чего они нужны?
Master — это управляющие серверы, на которых работает ядро системы. Они управляют развертыванием контейнеров, хранят в себе конфигурации системы, на них шуршит API, через который все компоненты системы общаются между собой. Короче говоря, мозги. Минимальное количество — один.
Worker — рабочий сервер, в первом приближении — «ведро» контейнеров. По сути это вычислительная среда, предоставляющая мощности для работы контейнеров. Управляются, как и следовало ожидать, мастерами. Минимальное количество — два.
Infra — тоже воркер, но служебный. На нем развернуты сервисные контейнеры внутреннего реестра образов (где хранятся образы), роутер (контейнерный маршрутизатор, об этом позже) и контейнеры системы мониторинга (сбор и отображение метрик о состоянии системы). Контейнеры с другими приложениями на нем не поднимаются. Минимальное количество — один.
Вся система представляет собой набор контейнеров, а в нашей инсталляции будет еще отдельный сервер под NFS и DNS, на нем же развернем Ansible, с помощью которого выполним установку. Ну, и простим платформе ее жирноту в угоду удобству и отказоустойчивости.
Разберемся, что к чему
Мой on-premise стенд обладает следующими характеристиками:

Развернул я все это добро в облаке vCloud, где создал виртуальные машины с указанными характеристиками. На каждой из них установил CentOS 7.4-1708 в паке web-server (оптимальный вариант, т.к. занимает не слишком много места, и большинство нужных пакетов уже есть), создал привилегированных пользователей и через network manager прописал сетевые настройки. Так что все серверы доступны друг для друга.
Хранение данных
Все долгосрочное хранение данных контейнеризированных сервисов в моем случае будет расположено на NFS (сервер Bastion) в каталогах persistent volume’ов, поэтому можно обойтись без большой дисковой емкости непосредственно на самих нодах. Контейнеры хранят данные внутри себя в течение жизненного цикла, то есть, пока не будут остановлены. Если требуется постоянное хранение данных, не зависящее от удаления и перезапуска контейнеров, то оно происходит в сущности под названием persistent volume. Это своего рода каталог с данными, доступными определенным контейнерам в соответствии с настроенными политиками доступа. Грубо говоря, приложение в контейнере записывает данные в persistent volume, под которым по факту находится каталог NFS, куда попадут эти данные. После перезапуска контейнера или, например, добавления второй реплики контейнера с приложением оба приложения из обоих контейнеров все равно будут иметь доступ к этим данным.
OpenShift поддерживает ряд плагинов для подсистем хранения данных: NFS, GlusterFS, Ceph RBD, OpenStack Cinder, AWS Elastic Block Store (EBS), GCE Persistent Disks и iSCSI. Выбор плагина зависит от конкретной инсталляции и требуемых задач, и я не возьмусь сказать, какой лучше использовать <поджигать реактивные струи в комментариях — ну уж нет>.
Я выбрал NFS, потому что его просто и быстро развернуть, благо в интернете полно инструкций и гайдов. Однако вендор не рекомендует использовать такой вариант в prod. Для тестов, демо и всего такого его вполне достаточно, но в prod могут возникнуть сложности. Например, OpenShift не создает каталоги на NFS для хранения данных, их придется создать и экспортировать заранее. Для сотен и тысяч контейнеров в сотнях проектов создавать каталоги руками будет не гуд.
Давайте вернемся к платформе. В идеальном мире конфигурация платформы будет примерно такой, как на рисунке ниже. Это полная рекомендуемая инсталляция — дальше можно масштабировать добавлением worker’ов, сколько влезет.

Три Master ноды — обеспечивают отказоустойчивость для зачач хранения конфигураций (etcd datastore), управления репликами контейнеров (Replication controller) и планирования развертывания новых контейнеров (scheduler), а также служат для управления системой.
Три Worker ноды (они же Application Node) — по ним равномерно размазываются контейнеры с приложениями (если не настроено иначе), причем в случае отказа какой-то ноды они перетекут на другие.
Три Infra ноды — тут все происходит по аналогии с worker, только со служебными контейнерами.
Load Balancer — условно говоря, это как бы NAT для виртуальной внутренней сети, к которой подключены контейнеры и роутер для трафика между ними. Детально рассматривать не буду, потому как непосредственно его настраивать не стану. Скажу только, что это виртуальный маршрутизатор, умеющий разруливать сетевой трафик и раскидывать его по нужным контейнерным сервисам.
Ansible Master — этот компонент не является частью непосредственно платформы, но стоит упоминания. Если вы сталкиваетесь с ним впервые, вот пара слов о том, что это и зачем:
«Ansible — система управления конфигурациями, написанная на языке программирования Python, с использованием декларативного языка разметки для описания конфигураций. Используется для автоматизации настройки и развертывания программного обеспечения». Wiki
Попробую объяснить на пальцах, как это работает: мастер-хост Ansible подключается по сети к целевым хостам и может автоматически их настраивать. Чтобы это работало, у него есть первое — файл inventory, в котором прописаны параметры доступа к целевым хостам: их IP-адреса, пользователь, под которым нужно подключаться, и его пароль (это минимум). И второе — playbook, то есть перечень заданных значений параметров для настройки. Ansible проверяет значение конкретного параметра и задает необходимый. Грубо говоря, система проверяет systemctl is-enabled docker и ожидаемое значение, например enabled, если значение от целевого хоста возвращается disabled, соответственно, выполняет systemctl enable docker, задав таким образом требуемое значение параметра. Пример деревянный, но суть приблизительно такая.
В сложных системах применяются переменные для значений параметров конфигураций, SSH-ключи для авторизации, дочерние группы хостов для группировок целевых хостов по различным типам и много других крутых штук, которые очень полезны, но тянут на отдельную статью. Когда столкнемся с ними по ходу установки, посмотрим чуть детальнее.
Пока нам достаточно понимать, что это сервер, который умеет настраивать другие серверы. Очень полезная вещь, если на целевом сервере нужно много всего настроить, и таких серверов большое количество. Делать он это может отправкой команд на целевые хосты либо заливкой конфигурации из файла. Естественно, при условии сетевой связности машин.
Но вернемся к OpenShift. В нашем случае инсталляция будет проще: 1 master, 1 infra и 2 worker’a (рисунок ниже). Исходя из опыта использования в тестовой среде около полугода, работать это будет, но до первой проблемы с master. Как только он упадет <никогда такого не было, и вот опять>, например, произойдет программный сбой в ОС, отвалится сеть, криво обновится какой-нибудь Python 2.7 или еще что-то подобное, платформа станет неработоспособной (во избежание как раз этого, мастеров рекомендуется три штуки). Справедливости ради, должен заметить, что после устранения проблем и нормальной загрузки ноды все само поднимается, подключается назад и работает дальше, как будто ничего не было.

Порядок действий по установке системы есть в инструкции на портале вендора, но отдельно обращу внимание на некоторые моменты, где есть нюансы:
- Настроить сетевые адаптеры и hostname на хостах.
- Установить и запустить DNS-сервер.
- Настроить локальную зону DNS.
- Настроить хосты для использования локального DNS.
- Настроить беспарольное подключение по SSH для выполнения Ansible плейбуков.
- Установить и обновить необходимые RPM-пакеты.
- Установить требуемые репозитории.
- Скачать архив плейбуков.
- Установить Docker, создать docker storage.
- Отредактировать inventory файл.
- Выполнить плейбук prerequisites.yml.
- Выполнить плейбук deploy_cluster.yml.
Ладно, погнали уже!
1. Настроить сетевые адаптеры и hostname на хостах
С помощью network manager’а задаю конфигурацию сети, сразу указываю свой будущий DNS — ничего необычного. Мне удобнее через nmtui.

Назначаю hostname:
hostnamectl set-hostname master.okd.localдля master,
hostnamectl set-hostname worker-1.okd.localдля worker-1 и так далее.
Домен okd.local у меня будет локальным, для него я создам отдельную DNS-зону. Вы можете придумать домен по своему вкусу. Cпокуха, мы сейчас до этого дойдем. Выполнить эту настройку, соответственно, нужно для всех master, worker и infra нод.
2. Установить и запустить DNS-сервер
В моем случае — просто Bind. Нужен для отработки запросов в кластерном домене. Приложения внутри кластера могут общаться между собой в том числе через доменные имена. Все эти доменные имена будут расположены в кластерной зоне, которую DNS и обслуживает.
Вкратце, зачем это нужно. Приложения работают в контейнерах, которые крутятся внутри кластера в виртуальной сети. Они постоянно запускаются, уничтожаются, реплицируются <и, вообще, движуха с ними похожа на азиатские перекрестки>, поэтому для маршрутизации сетевого трафика использовать IP-адреса контейнеров бессмысленно — они постоянно меняются. Для этого можно привязаться к доменным именам, и всю маршрутизацию выполнять по ним. Именно это в OpenShift и делает роутер. А чтобы FQDN-адреса сервисов можно было отрезолвить, необходим пресловутый DNS-сервер.
Устанавливаю пакеты:
yum -y install bind bind-utils bind-chrootЗапускаю и включаю автозагрузку сервиса:
systemctl start named-chrootsystemctl enable named-chrootОткрываю и привожу файл конфигурации bind /var/named/chroot/etc/named.conf к следующему виду (убрал под спойлер):
/var/named/chroot/etc/named.conf
options {
listen-on port 53 { any; };
listen-on-v6 port 53 { none; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
allow-query { 127.0.0.1; 192.168.7.0/24; };
recursion yes;
allow-recursion { 127.0.0.1; 192.168.7.0/24; };
forwarders { 8.8.8.8; };
version «DNS Server»;
managed-keys-directory "/var/named/dynamic";
pid-file "/run/named/named.pid";
session-keyfile "/run/named/session.key";
dnssec-enable no;
dnssec-validation no;
};
zone "." IN {
type hint;
file «named.ca»;
};
include "/etc/named.rfc1912.zones";
include "/etc/named.root.key";
logging {
channel default_file {
file "/var/log/named/default.log" versions 3 size 5m;
severity dynamic;
print-time yes;
};
category default { default_file; };
};
listen-on port 53 { any; };
listen-on-v6 port 53 { none; };
directory "/var/named";
dump-file "/var/named/data/cache_dump.db";
allow-query { 127.0.0.1; 192.168.7.0/24; };
recursion yes;
allow-recursion { 127.0.0.1; 192.168.7.0/24; };
forwarders { 8.8.8.8; };
version «DNS Server»;
managed-keys-directory "/var/named/dynamic";
pid-file "/run/named/named.pid";
session-keyfile "/run/named/session.key";
dnssec-enable no;
dnssec-validation no;
};
zone "." IN {
type hint;
file «named.ca»;
};
include "/etc/named.rfc1912.zones";
include "/etc/named.root.key";
logging {
channel default_file {
file "/var/log/named/default.log" versions 3 size 5m;
severity dynamic;
print-time yes;
};
category default { default_file; };
};
Что я сделал? <сотворил монстра>
Я задал такие параметры:
listen-on-v6 port 53 { none; }; — отключил использование на интерфейсе ipv6, чтобы сервер не мусорил в логи о недоступности ipv6 адресов. forwarders { 8.8.8.8; }; — перенаправил запросы, которые сам не резолвлю, на DNS-сервер (тут лучше указать DNS-провайдера).Если совсем лень, можете все оставить по умолчанию — работать будет. Идем дальше.
3. Настроить локальную зону DNS
Для начала, собственно, нужно создать эту зону. Я описываю файл зоны в named.conf (т.е. говорю named’у: «Параметры зоны ищи там-то») и указываю файл зоны в конце файла. Вот так:

А теперь создаю этот самый файл зоны <я люблю пользоваться Nano, хотя со временем почувствовал странное ощущение при использовании Vim… не то щекотка, не то зуд>.
nano /var/named/master/okd.localИ содержимое файла (под спойлером):
okd.local
$TTL 86400
@ IN SOA okd. okd.local. (
1192648703
10800
3600
604800
38400
);
@ IN NS localhost.
console IN CNAME master
bastion IN A 10.31.хх.30
master IN A 10.31.хх.32
api IN A 10.31.хх.32
api-int IN A 10.31.хх.32
infra IN A 10.31.хх.31
worker-1 IN A 10.31.хх.33
worker-2 IN A 10.31.хх.34
*.okd.local IN A 10.31.хх.31
@ IN SOA okd. okd.local. (
1192648703
10800
3600
604800
38400
);
@ IN NS localhost.
console IN CNAME master
bastion IN A 10.31.хх.30
master IN A 10.31.хх.32
api IN A 10.31.хх.32
api-int IN A 10.31.хх.32
infra IN A 10.31.хх.31
worker-1 IN A 10.31.хх.33
worker-2 IN A 10.31.хх.34
*.okd.local IN A 10.31.хх.31
И сохраняю (в nano ctrl+x).
Пара слов о том, что я сделал: создал новую зону, которую будет резолвить DNS-сервер, и указал в ней необходимые хосты. Я сказал DNS’у, что все запросы на master, api, infra и т.д. будут попадать на соответствующие хосты, и указал их IP-адреса. Тут ничего сложного, но что за API?
Это — API-сервер самого OpenShift (сиречь — Kubernetes), с помощью которого пользователь и компоненты системы могут общаться с ее ядром, а также компоненты между собой. Например, программы oc и kubectl (пользовательские консольные оболочки) производят ввод-вывод как раз через этот API. Если вы говорите системе oc get nodes (команда показать статус нод кластера), oc под капотом делает запрос в API, а он в свою очередь возвращает ответ, который oc переводит в понятный человеку вид… <в доме, который построил Джек>
Такой записью я в явном виде указал, что этот API работает на master.
Запись с вайлдкардой *.okd.local означает, что все адреса в домене okd.local (а это будут приложения в контейнерах, типа app1.okd.local, app2.okd.local и т.д.) работают за адресом 10.31.хх.31, которым является моя infra нода с роутером. Некисло так уровней абстракции, да? DNS на внешний запрос отвечает, что, например, приложение app1.okd.local находится на 10.31.хх.31, где роутер, который сам работает в контейнере, смаршрутизирует пакет и отправит его в другой контейнер, на ту ноду, где крутится приложение <я уже сам не очень уверен, что написал верно>.
Короче говоря, файл зоны я создал, сохранил и скормил Named’у. Теперь давайте перезапустим DNS и посмотрим, чтобы не было ошибок:
# rndc reconfig
# systemctl restart named
Команда должна выполниться и ничего не писать в ответ. Если получилось иначе, посмотрите сообщение об ошибке: она подскажет, где проверить, что именно пошло не так. Обычно для этого нужно обратиться в /var/log/messages или journalctl. Что именно там смотреть, вы также узнаете из сообщения об ошибке.
Обязательно проверьте, что все работает! Ошибка здесь чревата тем, что кластер не поднимется на этапе развертывания. Когда завершится установка API, и далее по плейбуку пойдут проверки healthcheck с его использованием, он может тупо не отвечать, т.к. будет недоступен, если DNS не отрезолвит его адрес. И тогда придется очень-очень долго ломать голову и искать ошибку <и готовиться к разводу с женой из-за того, что ночами пропадаешь на работе >, у меня было именно так, благо обошлось <жена — женщина чуткая и понимающая>. А виной всему была просто опечатка в конфигурации зоны.
Для этого проверьте настройку DNS в /etc/resolv.conf, конфигурацию hostname, и отвечают ли серверы по именам. Например, так:
В /etc/resolve.conf убедитесь, что прописан верный DNS.

Проверьте на нодах hostname.

Проверьте, что ноды пингуются по имени.

nslookup или dig’ом проверьте, что ноды резолвятся с правильным доменным именем.

Соответственно, все это надо проверить на всех нодах кластера, включая сервер с DNS. Важно, чтобы настройки были идентичны на всех серверах, и для каждого были соответствующие. Например, hostname для master был master.okd.local, для infra — infra.okd.local и так далее. Если все верно — отлично, если нет — приведите к правильному виду. Лучше перепроверьте все сейчас, чем потом будете долго и муторно выискивать ошибку. Поехали дальше…
4. Теперь перейдем к подготовке Ansible master
Настроим беспарольное подключение по SSH для выполнения Ansible плейбуков. С этого момента можно считать, что мы приступили к установке OpenShift. Отключать пароли я не буду — просто сгенерирую ключи и импортирую их на хост Ansible master.
На каждом хосте сгенерируйте SSH-ключи. Как я уже говорил, они понадобятся для того, чтобы Ansible master мог подключиться под привилегированным пользователем и выполнять команды настройки хостов так, чтобы при этом приходилось вручную вводить пароли пользователей. Для этого на всех целевых хостах выполните:
# ssh key-genИ на все вопросы протыкайте Enter. В итоге сервер покажет директорию, в которой сохранен ключ, его отпечаток и рандомарт.
После этого, собственно, беспарольное подключение. Если вы хоть раз пользовались Ansible, вам все должно быть понятно. Если такого опыта у вас не было, поясню: Ansible выполняет команды на целевых хостах, будучи залогиненым на них указанным пользователем и подключенным по SSH. Чтобы плейбук (или простая ad-hoc команда) мог отрабатывать, ему нужно указать адрес хоста назначения, пользователя, под которым Ansible должен подключаться, и в самом простом случае — пароль. Чтобы каждый раз не подтверждать подключение и не вводить пароль, импортируйте публичные SSH-ключи с целевых машин на Ansible master. Разумеется, ключи должны быть уже сгенерированы (см. выше). Для этого на Bastion (который Ansible master) выполняем:
# for host in master.okd.local \
worker-1.okd.local \
worker-2.okd.local \
infra.okd.local; \
do ssh-copy-id -i ~/.ssh/id_rsa.pub $host; \
Done
Теперь в каталоге ~/.ssh/id_rsa.pub должны появиться скопированные ключи. Проверить, что все в порядке, можно путем подключения с Bastion к каждому хосту. Категорически рекомендую и жалостливо умоляю это сделать:
ssh master.okd.local
ssh worker-1.okd.local
...
На запрос подтверждения нужно ответить yes. Сервер должен залогиниться на каждый хост без ввода пароля, а благодаря тому, что мы приняли предложение подключиться, больше оно появляться не будет. Для отработки плейбуков это хорошо: не надо будет каждый раз при их запуске жмакать yes.
5. Установить и обновить требуемые пакеты
Все там же, на хосте Bastion.
Тут есть нюанс. Указанный порядок работает для CentOS, а для RHEL процедура выглядит несколько иначе. Например, в RHEL нужно активировать подписку на обновления через subcribition manager, зарегистрировать на портале Red Hat свои хосты, выбрать необходимые репозитории и производить установку с них. В моем же случае, т.к. CentOS на портале не зарегистрировать, выполняю простую установку при помощи RPM-пакетов. Результат будет одинаковый, так что это не принципиально.
Подробнее об этом можно посмотреть в инструкции.
В принципе, не все из указанного может понадобиться, но это полный пак утилит для настройки и траблшутинга возможных проблем. Поэтому лучше не ломаться, а поставить все:
# yum install –y wget git net-tools bind-utils yum-utils iptables-services bridge-utils bash-completion kexec-tools sos psacct6. Установить требуемые репозитории
Устанавливаю репозиторий epel, с него загружу Ansible.
# yum -y install \
https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpmГлобально выключаю репозиторий, чтобы в дальнейшем по умолчанию пакеты грузились и обновлялись с дефолтных репо.
# sed -i -e "s/^enabled=1/enabled=0/" /etc/yum.repos.d/epel.repoИ наконец выполняю установку ansible rpm из репозитория epel:
# yum -y --enablerepo=epel install ansible pyOpenSSL — тут у у меня пакет с самим Ansible, Python’ом и нужными утилитами. 7. Скачать архив плейбуков
<Да какого черта так много? Где просто кнопка INSTALL?????>
# cd ~
# git clone https://github.com/openshift/openshift-ansible
# cd openshift-ansible
# git checkout release-3.11
Тут каточка на изи: я сходил в домашний каталог, склонировал в него с Гитхаба архив с плейбуками и всеми нужными файлами и убедился, что взял нужную версию.
8. Установить Docker, создать docker storage
Это делаю на нодах master, infra и обоих worker! Там, где платформа будет крутиться.
# yum install docker-1.13.1
# systemctl enable docker
# systemctl start docker
# docker-storage-setup
# systemctl restart docker
Что я сделал? Установил Docker в качестве контейнерного движка и включил его хранилище. Но помните, что это сторадж для хранения загруженных образов и вообще для самого докера. Это не сторадж для приложений в контейнере, его нужно будет создать в самой платформе позже. Вообще, на этом этапе можно не останавливаться подробно, потому что конфигурацию хранилища, ее безопасность и прочие нужные штуки возьмет на себя OpenShift. Docker будет тупо запускать контейнеры так, как скажет платформа.
Хранение тут я оставил по самому дефолтному дефолту, и дополнительных настроек обычно не требуется. Однако в некоторых случаях может появиться надобность что-то сконфигурировать. Я использую простой драйвер device-mapper, а для хранилища — простые блочные устройства, диски /sda, /sdb и так далее.
9. Отредактировать inventory файл
<А ведь еще даже не запустили установку>
Первым делом приведу ссылку на документацию по этому разделу. Она понадобится… I know that feel bro…
Тут остановлюсь чуть подробнее, так как здесь большой кусочек боли и бессонницы — верных спутников первой установки OpenShift 3.x. Inventory файл описывает установку платформы, типы и роли ее нод, конфигурацию дополнительных модулей и много всего прочего. Он хранит в себе переменные, используемые плейбуком при выполнении, и их целевые значения. В самом простом случае inventory файл мог бы выглядеть как-то так (это пример с тестового стенда, Openshift тут ни при чем — просто для наглядности):

Тут можно увидеть группы серверов (RHEL, DEBIAN, windows), называются они Children — дочерние как бы. Например, если надо установить на все серверы net-tools, то для RHEL based операционных систем хостов команда в плейбуке будет yum install net-tools, а для Debian based Ubuntu — apt-get install net-tools. Вот для того, чтобы один плейбук, пытающийся выполнить две эти команды, не валил сразу на все серверы в логи ошибку о том, что он не может выполнить yum на Ubuntu и apt-get на RHEL, целевые хосты можно разбить на группы. Для группы RHEL выполнять плейбук с yum, а для Ubuntu — с apt-get. Очень топорный пример, но суть, думаю, понятна.
Соответственно, в каждой группе указан хост с придуманным именем (-=CentOS-1=- / 2 и так далее), отображаться он будет только при выполнении плейбука. Это нужно для того, чтобы пользователь понимал, на каком хосте что происходит, и где случилась ошибка. Присутствует IP-адрес этого хоста, пользователь для подключения и его пароль.
Да, кстати, Windows Ansible тоже умеет конфигурировать, он делает это по-другому, и, пожалуйста, давайте не будем об этом, мы здесь сейчас не за этим.
Так вот, в inventory файле для развертывания OpenShift все хосты также разделены на группы по их ролям (master, worker, infra и все такое), а еще сразу добавлены переменные конфигурации самой системы. То есть сначала, при выполнении, Ansible подгоняет конфигурации хостов к целевым (это плейбук prerequisites.yml), а далее, когда он начинает разворачивать систему (плейбук deploy-cluster.yml) и задавать параметры ее конфигурации, то берет эти самые параметры из указанных в inventory переменных.
Возвращаясь к тому, как выглядит invetory файл: спрятал под спойлер мой inventory от OpenShift — там чад кутежа, например.
host-poc.yaml
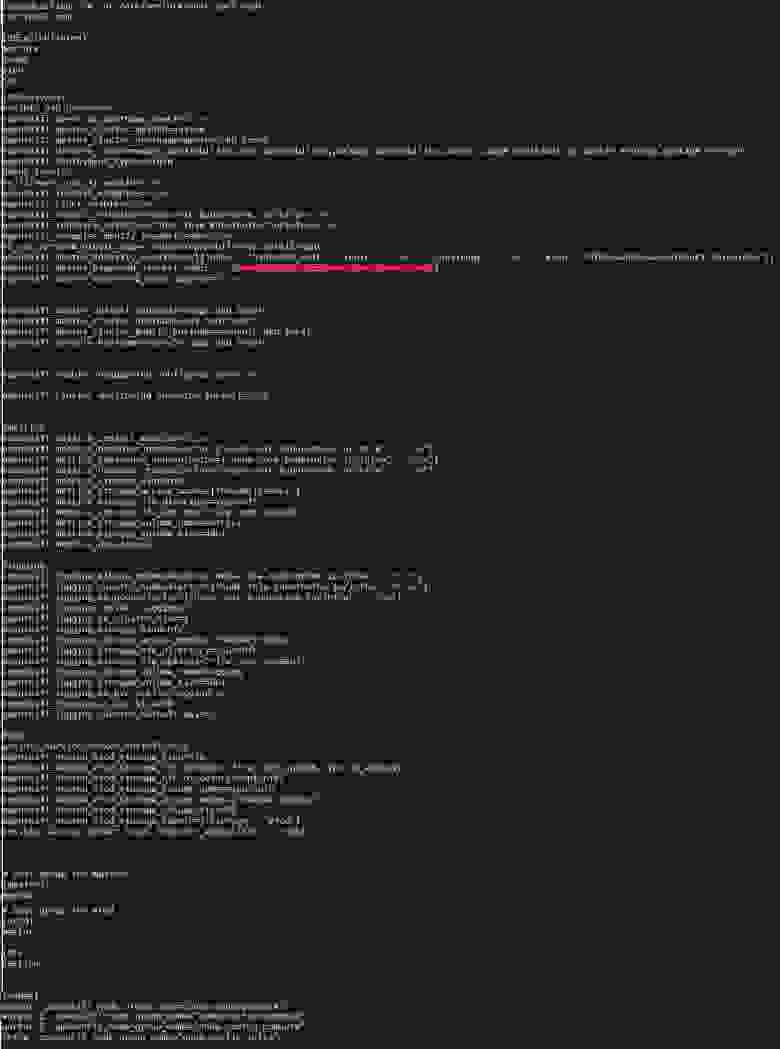

Пф-ф-ф, да все понятно, ваще изи…

Детально файл описан в документации <но я не хочу делать никому больно>, обращу внимание на то, что надо поменять следующие переменные Ansible Inventory (напоминаю, это все находится Bastion):
ansible_ssh_user=root — здесь вам нужно задать пользователя, под которым Ansible может залогиниться на ноду (чей ключ скопировали для доступа SSH по ключу). Я сделал под root <исключительно для того, чтобы лишний раз напомнить, что никогда-никогда нельзя работать из под root, а не потому что ленивый, мамой клянус>.
openshift_master_default_subdomain=apps.okd.local — здесь и далее укажите домен из созданной зоны, у меня это okd.local.
openshift_master_cluster_hostname=api.okd.local
openshift_master_cluster_public_hostname=console.okd.local
openshift_console_hostname=console.apps.okd.local
openshift_metrics_storage_volume_size=40Gi — тут можете указать размер хранилища метрик мониторинга.
openshift_logging_storage_volume_size=50Gi — здесь можете указать размер хранилища логов.
openshift_hosted_etcd_storage_volume_size=5G — можете указать размер хранилища etcd, это хранилище конфигураций.
Дальше те самые Children группы. В данном случае они привязаны к роли ноды:
# host group for masters
[masters]
master — тут хостнейм мастера.
# host group for etcd
[etcd]
master — тут тоже hostname мастера, потому что конфига хранится на нем.
[nfs]
bastion — хостнейм NFS-сервера (если разворачивали). У меня это Bastion с Ansible, DNS и NFS.
[nodes]
master openshift_node_group_name=«node-config-master» — мастеру указываем роль node-config-master. Trust me, просто указываем.
worker-1 openshift_node_group_name=«node-config-compute» — рабочим нодам указываем роль node-config-compute.
worker-2 openshift_node_group_name=«node-config-compute»
infra openshift_node_group_name=«node-config-infra» — инфра нодам указываем роль node-config-infra.
После всех подготовительных мероприятий требуется запустить плейбук из скачанного пака. Плейбуков там много, и многие из них предназачены для дальнейшего обслуживания, например, расширения хранилища логов и мониторинга, добавления нод в кластер, ротации сертификатов шифрования и т. д.
Хочется сказать пару слов про всю эту установку, поделиться сугубо моими ощущениями. Автоматизация с помощью Ansible — в целом клевая тема, однако для такой сложной штуки, как OpenShift, процесс инсталляции требует огромного количества проверок и конфигураций целевых хостов. В результате вполне возможен <и ваш покорный слуга подвергался подобному насилию целую неделю> сбой по ходу отработки плейбука, что приведет к остановке инсталляции.
Безусловно, Ansible покажет этап, на котором произошла ошибка, некоторое ее описание и так далее. Однако полагать, что причина ошибки будет понятна из отчета выполнения плейбука, к сожалению, очень наивно. Так что, скорее всего, вам придется лезть во всевозможные логи и журналы и анализировать, где произошла ошибка и в чем она заключается. Sad but true…
Однако Red Hat в корне поменял свой подход, и уже в мажорных 4-ых версиях используется операционная система CoreOS, которую можно развернуть на нодах одновременно с инсталляцией платфморы. Очень круто, но об этом в другой раз.
Да где же этот “Install”!?
# ansible-playbook -i host-poc.yaml /openshift-ansible/playbooks/prerequisites.ymlПосле запуска выполнение плейбука займет минут 15 <это, если сразу не грохнется с ошибкой, лол>.
По завершении Ansible выводит краткую сводку по выполнению. Типа такой, только цифры будут больше:

К каждому хосту из файла inventory приведено количество задач (TASK) из групп плейбуков. Иными словами, это действия по настройке.
- ok — значение заданной переменной на хосте совпадает со значением в плейбуке.
- changed — значение заданной переменной на хосте не совпадало со значением в плейбуке и было изменено.
- failed — изменение заданной переменной невозможно.
- skipped — проверка значения заданной переменной пропущена.
В случае неудачи в сводку добавится информация о задаче и переменной, с которой произошла ошибка.
11. Выполнить плейбук deploy_cluster.yml
# ansible-playbook -i host-poc.yaml /openshift-ansible/playbooks/deploy_cluster.ymlВ случае неудачного выполнения плейбука в Ansible предусмотрен режим отладки выполнения. Запустить его можно путем выполнения плейбука с ключом -v. Например:
# ansible-playbook -i host-poc.yaml /openshift-ansible/playbooks/deploy_cluster.yml –vВ таком случае Ansible будет показывать детали выполнения каждой задачи. Чтобы повысить детализацию, добавьте дополнительный ключ -v. Для максимальной детализации укажите 5 ключей (-vvvvv).
Когда выполнение плейбука закончится, убедиться в том, что все получилось <или нет>, поможет вывод команды статуса нод кластера (на master.okd.local):
# oc get nodesИ-и-и-и…

Наконец-то!
12. Доступ к веб-интерфейсу
При успешной установке кластера для доступа на веб-интерфейс надо указать IP-адрес мастер ноды. Я просто прописал в hosts master.okd.local:
10.31.хх.32 console.okd.local
После этого будет доступен веб-интерфейс консоли по адресу https://console.okd.local:8443.

ВАБА – ЛАБА – ДАБ – ДАБ! Кластер проинсталлирован!

Немного ретроспективы и возникшие проблемы
Касательно инсталляции при помощи плейбуков: предполагается запустить первый плейбук, перекурить, налить чай и после его успешного выполнения, минут так через десять—пятнадцать, запустить второй, кластерный деплой. Само собой, этот уже будет пожирнее, и можно даже успеть перекусить: я в этот момент в десятом часу вечера вторника успел дойти от офиса до кафешки с шаурмой, заскочить в ларек за газировкой и вернуться в офис, схомячив шаурму.
И вот, по завершении второго плейбука, вывод команды oc get nodes должен показать все ноды в статусе ready, и веб-консоль оказалась доступна…
И-и-и-и… Нет.
По ходу выполнения есть вероятность неявных проблем, например:
1. В файле inventory есть такой параметр:
openshift_disable_check
В моем случае он имеет значение:
=memory_availability,disk_availability,package_availability,docker_image_availability,docker_storage,package_version
В него я добавил выделенный жирным параметр.
Как это было в жизни
При выполнении плейбука prerequisites есть этап Check Docker image availability с хэндлером, он циклично повторяется некоторое количество раз, пока заданный параметр не получит ожидаемое значение — это в контексте Ansible. В реальности же происходило то, что демон Docker искал в публичном реестре некоторый образ, который по какой-то причине был недоступен. Из-за запутанности переменными и ссылками плейбуков на плейбуки найти концы в тот момент мне так и не удалось.
Что оказалось
Это был образ консоли внутреннего реестра образов. В OpenShift есть сам реестр образов, в котором можно хранить свои образы, а есть консоль — веб-интерфейс для этого реестра для удобного просмотра содержимого. Образ этой консоли как раз и оказался недоступен, и сама она не работала.
А когда понадобилась, мне пришлось найти новый образ, заменить им старый в конфигурации деплоймента консоли и пересоздать эту консоль. Потому как на момент инсталляции я этого не знал, то решил попробовать добавить проверку в исключение и посмотреть, на чем зафейлится выполнение плейбука дальше.
Это только один из примеров, демонстрирующих неожиданные векторы проблем, которые могут возникнуть при раскатывании OpenShift из плейбуков. Хотя, безусловно, о самой идее попытаться автоматизировать установку так, чтобы после запуска двух плейбуков все само стало ОК, ничего плохого сказать нельзя.
С горем пополам выполнение prerequisites плейбука завершилось успешно, я закинулся валокордином и поставил на выполнение плейбук deploy-cluster. Тут все также гладко не прошло.
2. Возникла ошибка о том, что сетевой плагин SDN не работает.
Главная сложность деплоя посредством набора плейбуков, битком набитых переменными и ссылками на другие плейбуки, заключалась в проблематичности поиска причин ошибок. Например, на этапе установки плагина SDN (внутренней виртуальной сети платформы) Ansible отрапортовал ошибкой. В логах машины будущего мастера оказалось множество ошибок о сетевой недоступности. Как выяснилось сильно позже, проблема была в опечатке в конфиге DNS-зоны. В плейбуке происходила проверка доступности API-сервера по его доменному имени, которое было задано из inventory. В конфигурации DNS-зоны FQDN-имя было написано неправильно, и DNS его не резолвил. В результате API-сервер на master был недоступен, что плейбук интерпретировал как ошибку сетевого плагина.
Знаю-знаю, сам криворукий, но выловить ошибку удалось, только глубоко погрузившись в логи DNS, master ноды и ручную проверку доступности хостов между собой…

Итого
Я не говорю, что способ развертывания плохой. Я лишь утверждаю, что отловить ошибку при инсталляции, да еще на нескольких машинах, тем более на нескольких уровнях абстракции, когда к тому же не понимаешь, что делаешь, очень проблематично.
И вот ошибки отловлены и исправлены, процесс инсталляции завершен, и мы можем пользоваться платформой. Взглянем, что она может нам предложить.
Слышал такое мнение:
«Вы можете взять голый Kubernetes, навесить на него средства сбора метрик и мониторинг, средства хранения артефактов, CI-систему и множество прочих плюшек, собрав таким образом систему, отвечающую всем требованиям разработки в вашей организации. Это вполне неплохо, пока не встает вопрос долговременного обслуживания всего этого добра. Red Hat OpenShift — это добро, компоненты которого отлажены и дружат между собой, а в придачу к нему есть вендорская поддержка. Если из-за обновления какого-то компонента стройная система рассыпется, вам не нужно лезть в его потроха, у вас есть вендор, который поможет вплоть до feature request’ов».
Что ж, звучит вполне складно.
Из коробки мы имеем:
- Саму платформу оркестрации. Оркестрирует, логирует, управляет секретами, имеет RBAC (Role Based Access Control) и в целом инструменты безопасности.
- Частный репозиторий для хранения образов с какой-никакой безопасностью: аутентификация/авторизация, возможность использования токенов, поддержка шифрования.
- CI-систему. Красивенькая, в меру удобный интерфейс, сборки выполняет, отчеты создает, этапы сборки редактируются из основного интерфейса.
- Систему мониторинга в связке Prometheus и Grafana. Присутствует, работает, кастомизируется.
- Интеграции с дополнительными системами, например, с анализаторами кода или системами сканирования образов также выполняются без особых сложностей.
Кстати, на правах оффтопа, не могу не отметить кое-какие изменения в Red Hat OpenShift 4-ой версии (подробный обзор от моих Ops-коллег можно почитать тут).
Отличий на самом деле много, но первое, с которым вам придется столкнуться, — это процесс инсталляции. Тут вендор кардинально изменил подход, отказавшись от идеи использования Ansible. Вместо этого теперь используется метод инсталляции на хосты образов CoreOS. Это операционная система от Red Hat, позиционируемая вендором как легковесная, специально заточенная под развертывание кластеров, имеющая минимальную необходимую функциональность, в которой приложения работают в контейнерах. Система заливается при помощи PxE-сервера, оттуда же в процессе развертывания подтягиваются все конфигурации, и в целом процесс установки состоит по сути из этапа подготовки всех конфигураций и этапа ожидания, пока все само развернется.
Сам кластер OpenShift 4.x, кстати, работает практически весь в контейнерах и обладает новой сущностью — operator, контейнерами, которые умеют разворачивать другие контейнеры с приложениями и всегда следить за их работоспособностью. Но об этом есть статьи от самого Red Hat :)
Собственно, друзья мои, вот мы с вами вместе и установили систему. Теперь можно выдохнуть и похвалить себя. В другой статье мы позанимаемся так называемыми «day 2 operations» — вещами, которые стоит сконфигурировать после инсталляции. И конечно же, не обделим вниманием средства безопасности: я расскажу, что такое Security Context Constraints, Network Policies, и объясню, зачем надо мыть руки перед деплоем приложения!
Продолжение следует.
P.S. Всех желающих поговорить о DevSecOps приглашаю на канал«DevSecOps Talks»: tlgg.ru/devsecops_weekly. Там мы с командой делимся интересными обзорами по теме, полезными ссылками и вносим посильный вклад в развитие культуры безопасной разработки.
