
В прошлом посте я начала говорить о решении IBM Maximo Visual Inspection от IBM, позволяющем использовать технологию компьютерного зрения без команды дата-сайнтистов и внушительных затрат на разработку. Сейчас я расскажу подробнее о том, как это решение применять.
У Maximo Visual Inspection отличные обучающие уроки, которые выкладывает сама компания (например, можно начать с рассказа о применении этого инструмента для анализа снимков легких в начале пандемии covid-19), и я не думаю, что стоит демонстрировать подробности. Но хочется хотя бы поверхностно показать, почему стоит обратить внимание на этот инструмент для упрощения вхождения в область, так что дальше будет несколько примеров, как происходит предобработка данных (ну и вы проверите истинность моих слов про «уровень кружка базовой компьютерной грамотности»!).
В качестве датасета для примера ручной разметки и сегментации изображений я взяла датасет с Kaggle — это соревнование от «Северстали» по детекции дефектов с фотографии съемки листов, проходящих по конвейеру. Когда-то мы много обсуждали с коллегами эту задачу, так как наша команда участвовала в этом соревновании. Это была интересная задача, и в итоге «Северсталь» интересно ее реализовала — об этом можно почитать на Kaggle.

Итак, разметка по контуру. У нас есть лист стали, а на нем — дефекты разного класса. Датасет предоставлялся уже размеченным специалистами «Северстали», но в данном случае я представила, что никакой разметки нет, а я — специалист по оценке дефектов или хорошо разбирающийся в металлургии менеджер проекта.
Разметка может производиться в режиме обычной мышки с помощью боксов-прямоугольников, если нам нужно определить место с дефектом на изображении, или с помощью полигона, если нам нужно четко очертить зону нахождения дефекта.
Если вы работаете с обычной мышкой, то в разметке для сегментации изображения по пикселям будут некоторые элементы «пиксель-хантинга». Но возможно, что и эта задача будет упрощена в следующих релизах инструментом, похожим на «волшебную палочку» из визуальных редакторов.

В Maximo Visual Inspection есть возможность накладывать фильтры по тому, как мы размечали изображения. Если бы я уже подготовила разметку по значимой части изображений, то я могла бы пометить листы, которые имеют какой-то дефект, и листы, которые не имеют никакого дефекта.
Все это подсвечивается, и можно сразу, без дополнительных инструментов, получать изображения, пригодные для демонстрации в презентациях. Классы подписаны удобным образом, можно выделять полигоны.

После разметки первых пяти изображений можно попробовать применить к вашему датасету модель, которая в несколько итераций постарается сделать авторазметку. Насколько хорошо она будет работать конкретно на ваших данных, предсказать сложно. Документация рекомендует попробовать прогнать четыре итерации авторазметки, довольно часто можно добиться вполне приемлемого качества на уровне более 90 %. Очевидно, что для хорошей точности авторазметки может потребоваться больше пяти изображений и некоторое разнообразие, если объекты как-то значимо друг от друга отличаются.
Аналогично устроена маркировка видео. В Maximo Visual Inspection можно загрузить видео для того, чтобы отметить, где на нем расположены те или иные объекты и как они перемещаются по изображению. С точки зрения компьютера, видео — это просто последовательность изображений, которая получила развитие во времени. Временной аспект делает задачу сложнее, разные кадры требуется соотносить друг с другом. На стоп-кадрах из видео точно также в режиме ручной разметки можно отметить определенные действия.
В число обычных для подготовки изображений к обучению нейросети входит «аугментация» — небольшое изменение исходных изображений, используемое для того, чтобы повысить разнообразие в данных (и избежать нелепых случайностей, когда искомый объект был всегда в правом углу и нейросеть решила, что это правило, и ищет всегда теперь только там). В Maximo Visual Inspection основные из этих технологий встроены: преобразование по цвету, обрезка (как раз для того, чтобы модель не переобучалась под абсолютные координаты в изображениях), ротация изображений в разные стороны.
В целом, все эти техники очень полезны, но подумайте о том, могут ли имеющиеся у вас входные изображения в естественной среде получиться такими, какими они стали в результате аугментации? На примере кейса с «Северсталью» понятно, что лист можно вертеть как угодно в силу специфики расположения камеры над станом, по которому он проезжает, но при этом ротация не имеет смысла, потому что изображения с этой камеры всегда приходят в одинаковой ориентации. Имеет ли смысл размывать изображение — большой вопрос, если камера одна и та же, как и уровень запыленности в цеху. В общем, все вопросы о применимости конкретного вида аугментации к конкретному датасету нужно решать самостоятельно по мере необходимости.
Maximo Visual Inspection предлагает обучение модели на основе автоматически подобранных параметров и показывает кривые обучения в режиме реального времени. Даже неспециалист знает, что если ошибка идет вверх, то что-то пошло не так. Возможно использование разных архитектур нейросетей моделей, но в качестве моделей первого выбора предлагаются R-SNN, которые сегодня являются наиболее популярными.
С точки зрения анализа результатов модели Maximo Visual Inspection предлагает все те же инструменты, которые будет использовать дата-сайнтист; в случае задач по классификации речь идет о метриках, связанных с точностью определения объектов. Вопрос баланса точности и полноты (precision&recall), и того, насколько общая правильность (accuracy) ценна для вас — решается исходя из бизнес-задач. Метрика accuracy используется в объектах классификации, но она очень чувствительна к сбалансированности классов: если у вас есть одно изображение класса А, а все остальные изображения относятся к классу В, то возможны проблемы (при выделении всех объектов класса В accuracy пострадает несильно). Баланс точности (precision) и полноты (recall) зависит от вашей задачи. Нужно ли вам найти наибольшее число объектов определенного класса (пусть и за счет большого числа ложных срабатывания)? Или вам важно, чтобы, когда модель говорит, что нашла что-то — это точно было то, про что она сообщает?

Матрица смешения (Confusion Matrix) — очень полезный инструмент, который позволяет оценить, какие классы чаще принимают за что-то другое. Представим теоретически, что у вас есть сотрудники, которые должны надеть косынку, и сотрудники, которые должны надеть хирургическую шапочку. Вы обучили модель и выяснили, что при хороших прочих метриках модель часто принимает шапочку за косынку, а это недопустимо, поскольку люди, которые обязаны надевать шапочку, должны надевать именно ее. Ответы на такого рода вопросы вы увидите с помощью Confusion Matrix.
У наших коллег из IBM есть несколько решений, связанных с внедрением предобученных моделей с помощью Maximo Visual Inspection, в частности, есть коробочное решение для производства, которое позволяет сразу использовать детекцию некоторых деталей, в том числе, с помощью мобильных устройств. Кроме того, IBM традиционно предлагает обученные под конкретные задачи решения.
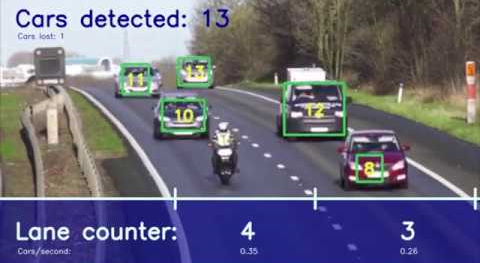
Если вам интересно, как выглядит весь pipeline работы с Maximo Visual Inspection на реальных данных, я рекомендую сходить в этот репозиторий: https://github.com/IBM/powerai-counting-cars — в нем показан весь процесс от разметки до обучения модели. Работа модели реализована в Jupyter Notebook. Там даны более подробные скриншоты для каждого шага, понятно, как происходила разметка данных. В этом примере присутствует счетчик для видео, но для изображений задача родственная, с небольшими отличиями.
По решениям машинного зрения и видеоаналитики мы активно взаимодействуем с Клиентским центром IBM в Москве. Это помогает разбираться в деталях и особенностях данных решений, находить эффективные конфигурации технологий для выполнения задач, связанных с распознаванием объектов и видеоаналитикой.
Надеюсь, этот обзор поможет тем, кто хотел бы попробовать внедрить у себя решение на базе компьютерного зрения, но переживает, что команда датасайнтистов, облаченных в украшенные тайными математическими символами робы, потратит весь бюджет проекта и не добьется результатов. Такие коробочные решения, как Maximo Visual Inspection, помогут оценить реальность задачи и научиться говорить близкими терминами, когда придет пора все-таки позвать этих ребят и делать что-то по-настоящему сложное и кастомное.
Царева Александра, ведущий специалист по машинному обучению «Инфосистемы Джет».
