
Хотите ли вы в джавке треды, которые не жрут память как не в себя и не тормозят? Хорошее похвальное желание, и на данный вопрос отвечает этот выпуск.
Объясняем работу Project Loom на коробках с пиццей! Налетай!
Всё это снимается и пишется специально для Хабра.
Позывные
Часто ли вы видите у себя на веб-сервисе вот такую картинку: вначале все было хорошо, потом к вам пришёл миллион китайцев, сервис наделал миллион тредов и захлебнулся к чертям собачьим?
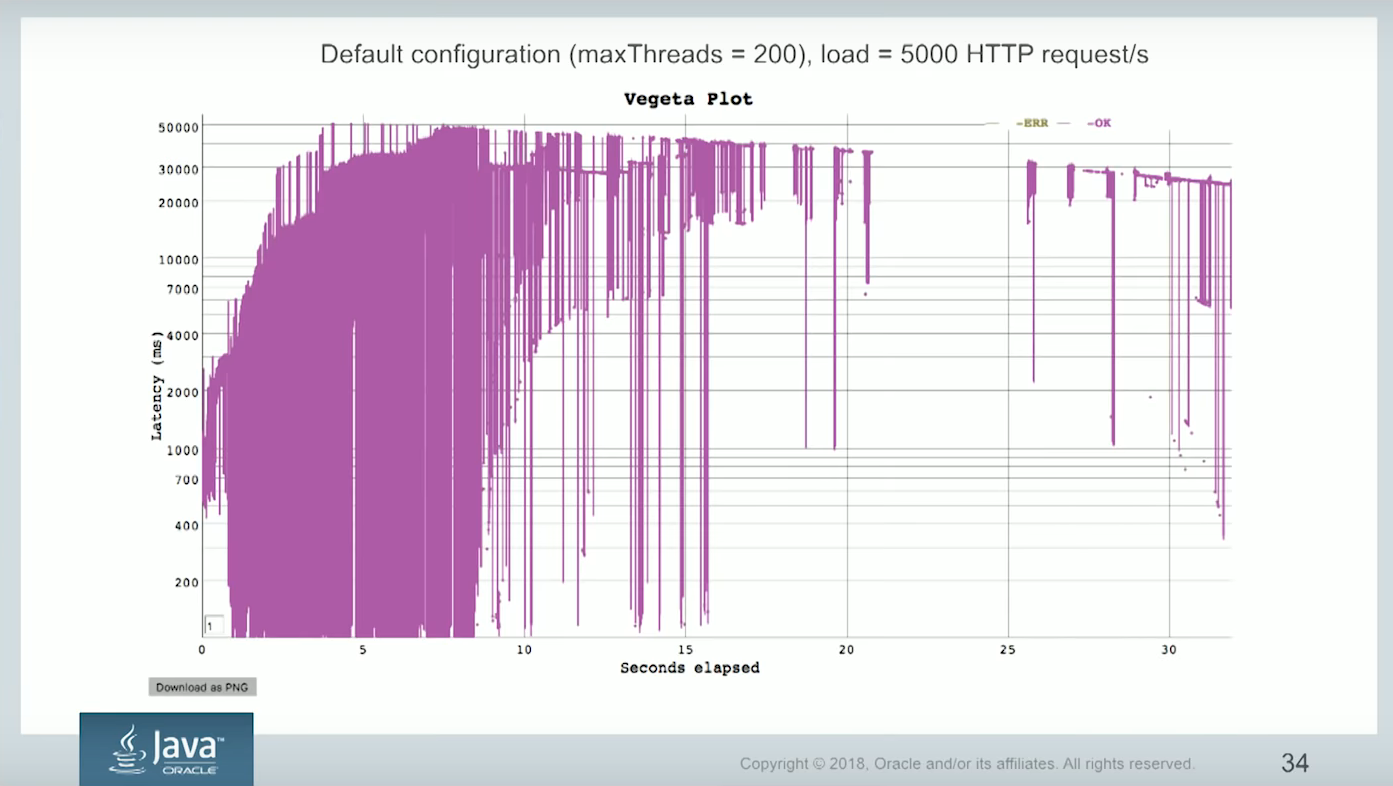
Хотите ли вы вот такую няшную картинку?

Иначе говоря, хотите ли вы в джавке треды, которые не жрут память как не в себя и не тормозят? Хорошее похвальное желание, и на данный вопрос отвечает этот выпуск.
Мы будем заниматься, по сути, распаковкой нового фреймворка. Помните, как Wylsacom распаковывал айфоны? Кое-кто уже и не помнит старых обзорщиков, а всё почему? Потому что Хабр — оплот мейнстрима, а проплаченные видосы — это, извините, лучи поноса. В этом посте мы будем заниматься исключительно техническим хардкором.
Сначала две минуты на завязку, отказ от ответственности и прочую фигню, которую надо сказать. Можно ее пропустить, если вам лень.
Во-первых, всё сказанное в ролике — это мои личные мысли, и никакого отношения к работодателю или славной корпорации Oracle, мировому правительству ящериков и черту в ступе они не имеют. Я даже пишу это в три часа ночи, чтобы ну вот точно было ясно, что это моя личная инициатива, моя личная фигня. Все совпадения чисто случайны.
Но есть еще одна бонусная цель. Мы постоянно разговариваем о корутинах в Kotlin. Вот недавно были интервью с Ромой Елизаровым, богом корутин, и с Пашей Финкельштейном, который на них собирается писать бэкенды. Скоро будет интервью с Андреем Бреславом — который отец Kotlin. И везде так или иначе упоминается проект Loom, потому что это аналог корутин. И если вы не знаете, что такое Loom, вам при чтении этих интервью вам может стать стрёмно. Вот есть какие-то клевые чуваки, они обсуждают крутые вещи. А есть ты, и ты не с ними, ты чмо. Это очень тупо.
Не делайте так, прочитайте, что такое Loom, в этой статье, или дальше смотрите это видео, я все объясню.
Итак, в чем завязка. Есть такой чувак, Рон Пресслер.

В прошлом году он пошел в рассылку, заявил, что треды в джаве — отстой, и предложил похачить рантайм и починить это. И все бы над ним посмеялись и закидали камнями, говном, если бы не тот факт, что ранее он написал Quasar, и это вообще-то очень круто. Можно долго ругаться на Квазар, но он как бы есть и работает, и в большой картине всего это, скорее, достижение.
Есть чертово количество говнокодеров, которые ничего не делают, просто говорят. Ну и поймите правильно, я такой же. Или вот есть люди, которые вроде бы клевые инженеры, но вообще в несознанке, они такие говорят: «В джаве надо улучшить треды». Что улучшить? Что — треды?
Людям вообще лень думать.
Как там в анекдоте:
Летят в самолете Петька и Василий Иванович.
Василий Иванович спрашивает: — Петька, приборы?
Петька отвечает: — 200!
Василий Иванович: — А что 200?
Петька: — А что приборы?
Расскажу историю. Я был этой весной на Украине, мы летели из Беларуси (вы понимаете, почему напрямую из Питера нельзя). И на таможне мы сидели что-то часа два, не меньше. Таможенники весьма приятные, на полном серьезе спрашивали, является ли Java устаревшей технологией. Рядом сидели люди, которые летят на ту же конфу. И я же типа докладчик, должен понтануться, стою и, как положено, бесстыже рассказываю о вещах, которые вообще не использую. И по пути рассказал о дистрибутиве JDK под названием Liberica, это такой JDK для Raspberry Pi.
И что вы думаете. Не проходит и полгода, как ко мне в телегу стучится чел и говорит, что вот, гляди, мы запилили на Либерике решение в прод, и у меня уже есть доклад про это на белорусскую конфу jfuture.by. Вот это подход. Это не евангелист какой-то паршивый, а норм чувак, норм инженер.
Кстати, у нас скоро будет конференция Joker 2018, на которой будут и Андрей Бреслав (очевидно, шарящий в корутинах), и Паша Финкельштейн, а о поддержке Loom в Spring можно будет спросить у Джоша Лонга. Ну и ещё куча крутых видных экспертов, налетай!
И вот, возвращаясь к тредам. Люди пытаются сквозь свои деграднувшие два нейрона мысль провести, такие наматывают сопли на кулак, и бормочут: "В джаве треды не так, в джаве треды не так". Приборы! Что приборы? Это вообще ад.
И вот приходит Пресслер, нормальный не деграднувший чувак, и вначале делает вменяемое описание. А через год пилит рабочую демку. Все это я говорил, чтобы вы поняли, что нормальное описание проблем, нормальная документация — это такой героизм особого рода. А демка — это вообще космос. Это первый человек, который вообще что-то сделал в этом направлении. Ему больше всего надо.
Вместе с демкой Пресслер выступил на конференции и выпустил вот такое видео:
По сути, вся эта статья — это некий обзор на сказанное там. Я совершенно не претендую на уникальность этого материала, всё, что есть в этой статье, придумал Рон.
Обсуждение идёт по поводу трех болезненных тем:
- Continations
- Fibers
- Tail-calls
Вероятно, его так задолбало пилить Квазар и бороться с его глюками, что вот сил нет — надо пихать это в рантайм.
Было это год назад, и с тех пор они пилили прототип. Некоторые уже потеряли надежду, что мы когда-то увидим демку, но месяц назад её-таки родили и показали, что видно по этому твиту.
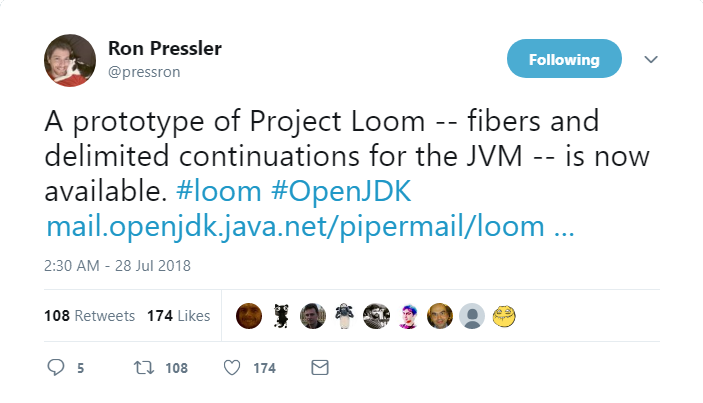
Все три болезненные темы в этой демке имеются или прямо в коде, или хотя бы присутствуют морально. Ну да, tail calls они пока не осилили, но хотят.
Проблематика
Несчастные пользователи, прикладные разработчики, когда делают API, принуждены выбирать между двумя стульями. На одном стуле встроены пики, на другом — растут цветы. И ни то, ни другое нам не подходит.

Например, если ты пишешь сервис, который работает синхронно, он отлично работает с легаси-кодом, его легко дебажить и мониторить перформанс. Проблемы возникнут с пропускной способностью и масштабируемостью. Просто потому, что количество тредов, которые сейчас можно запустить на простой железяке, на commodity hardware — ну допустим, две тысячи. Это сильно меньше, чем количество соединений, которые можно бы открыть к этому серверу. Коих с точки зрения неткода может быть чуть ли не бесконечно.
(Ну и да, это как-то связано с тем, что сокеты в джаве устроены дебильно, но это тема другого разговора)
Представьте, вы пишете какую-нибудь MMO.
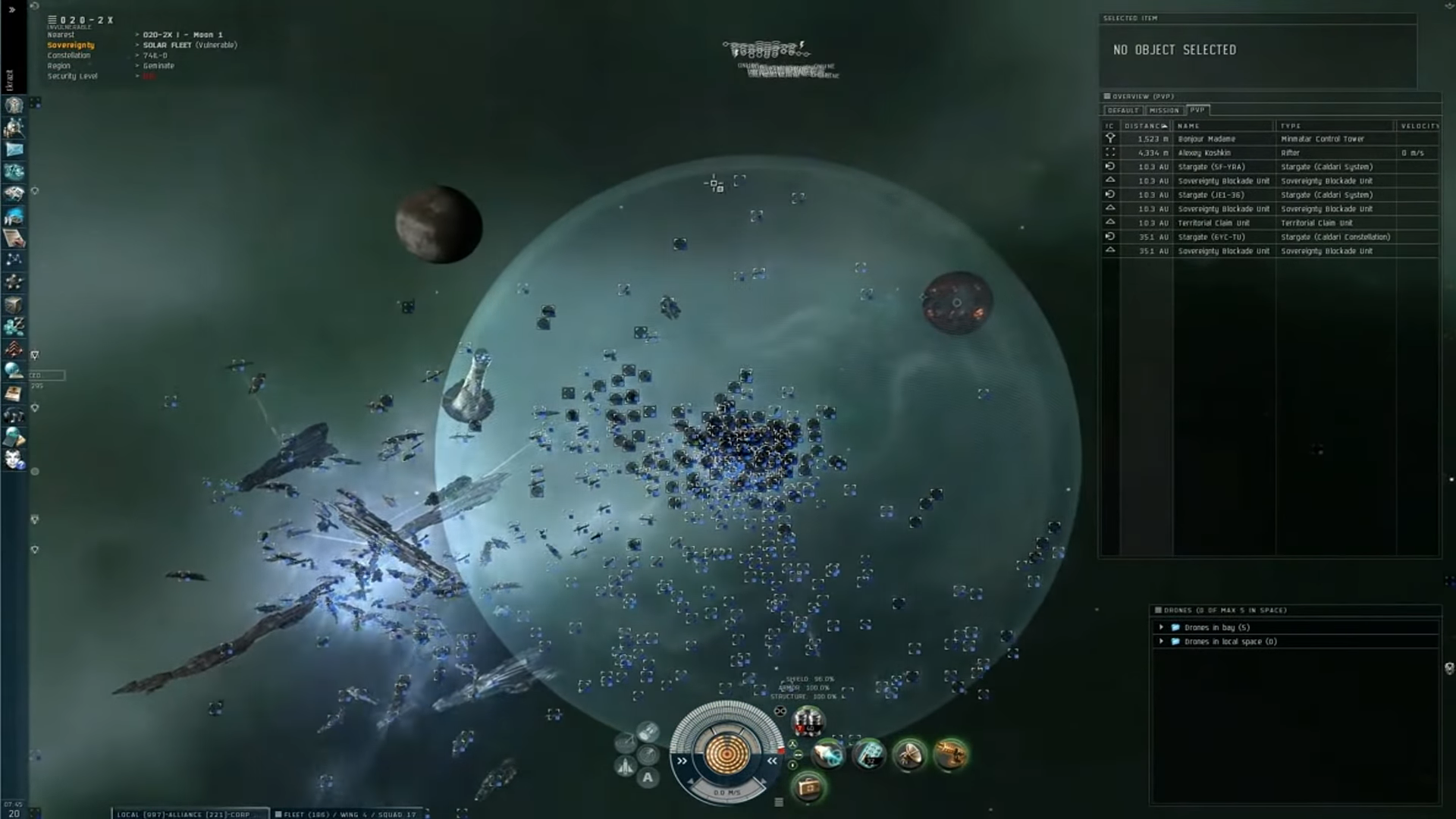
Например, во время Северной Войны в EVE Online в одной точке пространства собрались две тысячи четыреста пилотов, каждый из которых — условно, будь это написано на Java, — был бы не один тред, а несколько. И пилот, понятно, — это сложная бизнес-логика, а не выдача какого-нибудь HTML, который можно руками поразлинеивать в лупе.
Время отклика в той битве было настолько большим, что ждать выстрела игроку приходилось несколько минут. Насколько знаю, CCP специально под ту битву бросило огромные аппаратные ресурсы своего кластера.
Хотя, я, наверное, зря привожу в пример именно EVE, потому что, насколько понимаю, у них всё написано на Python, а в Python с многопоточностью всё ещё хуже, чем у нас — и можно считать плохой конкарренси фичей языка. Но зато пример наглядный и с картинками.
Если вас заинтересовала тематика ММО вообще и история «Северной Войны» в частности, недавно на канале БУЛДЖАТь (что бы ни значило это название) появился очень хороший ролик на эту тему, смотреть с моей временной метки.
Возвращаемся к теме.
С другой стороны, можно использовать какой-нибудь асинхронный фреймворк. Он масштабируется. Но мы тут же попадём на очень сложную отладку, сложное профилирование перформанса, мы не сможем бесшовно это интегрировать с легаси, придётся очень много чего переписать, обернуть в мерзотные обертки, и вообще ощущать себя, как будто нас только что изнасиловали. Несколько раз подряд. Целыми днями, на самом деле, всё время, пока мы это пишем, так придется себя чувствовать.
Я поинтересовался у эксперта, известного академика Эскобара, что он думает по этому поводу:

Что же делать? На помощь спешат так называемые файберы.
В общем случае, файберы — это такие легкие треды, которые тоже шарят адресное пространство (потому что чудес не бывает, вы понимаете). Но в отличие от обычных тредов используют не вытесняющую многозадачность, а кооперативную многозадачность. Подробней стоит почитать на Википедии.
Файберы могут на себе реализовать плюсы как синхронного, так и асинхронного программирования. В результате повышается утилизация железа, и мы используем меньше серверов в кластере на ту же самую задачу. Ну и в карман за это получаем лавандосики. Бабосы. Лавэ. Денежки. Ну, вы поняли. За сэкономленные сервера.
На распутье
Первое, что хочется обсудить. Люди не понимают разницы между континуациями и файберами.
Сейчас будет Культпросвет!
Огласим факт: Continuation и Fiber — это разные вещи.
Continuations
Файберы построены поверх механики под названием Continuations.
Continuations (если точнее, delimited continuations) — это некое вычисление, исполнение, кусок программы, который может заснуть, потом проснуться и продолжить выполнение с того места, как заснул. Его иногда можно даже склонировать или сериализовать, даже в тот момент, пока он спит.
Я буду использовать слово «континуация», а не «продолжение» (как это написано на Википедии), потому что все мы общаемся на рунглише. Используя нормальную русскую терминологию, можно легко прийти к ситуации, когда разница между русским и английским термином становится слишком большой и никто больше не понимает смысла сказанного.
Ещё я иногда буду использовать слово «вытеснение» вместо английского варианта «yield». Просто слово «yield» — оно какое-то уж совсем мерзковатое. Поэтому будет «вытеснение».
Так вот. Очень важно, что никакого конкарренси внутри континуации не должно быть. Она сама по себе — минимальный примитив этого процесса.
Можно думать о континуации как о Runnable, у которого внутри можно вызвать метод pause(). Именно внутри и напрямую, потому что многозадачность у нас кооперативная. И потом можно запустить его ещё раз, и вместо того, чтобы всё считать заново, он продолжит с места, где остановился. Такая магия. К магии мы еще вернемся.
Где взять демку с работающими континуациями — мы обсудим в самом конце. Сейчас поговорим о том, что там есть.
Сам класс континуации лежит по адресу в java.base, все ссылки будут в описании. (src/java.base/share/classes/java/lang/Continuation.java). Но этот класс очень большой, объемный, поэтому имеет смысл посмотреть только на какую-то выжимку из него.
public class Continuation implements Runnable {
public Continuation(ContinuationScope scope, Runnable body);
public final void run();
public static void yield(ContinuationScope scope);
public boolean isDone();
protected void onPinned(Reason reason) {
throw new IllegalStateException("Pinned: " + reason);
}
}Заметьте, что на самом деле файл этот постоянно меняется. Например, по состоянию на предыдущий день континуация не реализовывала интерфейс Runnable. Относитесь к этому как к некой зарисовке.
Взгляните на конструктор. body — это код, который вы пытаетесь запускать, а scope — это некий скоп, позволяющий вкладывать континуации в континуации.
Соответственно, можно или заранить этот код до конца методом run, или вытеснить его с каким-то конкретным скопом с помощью метода yield (скоп тут нужен для чего-то типа пробрасывания эксепшенов по вложенным обработчикам, но нам это неважно как пользователям). Можно спросить с помощью метода isDone, завершилось ли всё до конца.
И по причинам, продиктованным исключительно нуждами текущей реализации (но скорей всего, в релиз тоже попадёт), совершенно не всегда можно сделать yield. Например, если внутри континуации у нас случился переход в нативный код и на стеке появился нативный фрейм, то зайилдить нельзя. Ещё так произойдет, если попытаться вытесниться, пока внутри тела континуации взят нативный монитор, типа синхронизованного метода. По умолчанию, при попытке зайилдить такое, выбрасывается исключение… но файберы, построенные поверх континуаций, перегружают этот метод и делают кое-что другое. Об этом будет чуть позже.
Использовать это можно примерно следующим образом:
Continuation cont = new Continuation(SCOPE, () -> {
while (true) {
System.out.println("before");
Continuation.yield(SCOPE);
System.out.println("after");
}
});
while (!cont.isDone()) {
cont.run();
}Это пример из презентации Пресслера. Опять, это не «всамделишный» код, это какая-то зарисовка.
Это зарисовка о том, что мы делаем континуацию, в середине этой континуации вытесняемся и потом в бесконечном цикле спрашиваем — отработала ли континуация до конца и надо ли её продолжить.
Но вообще, не предполагается, что обычные прикладные программисты будут касаться этого API. Оно предназначено для создателей системных фреймворков. Системообразующие фреймворки вроде Spring Framework сразу же заадоптят этот фичу, как только она выйдет. Вот увидите. Считайте это за предсказание. Такое, лайтовое предсказание, потому что здесь всё довольно очевидно. Все данные для предсказания есть. Это слишком важная фича, чтобы ее не заадоптить. Поэтому не нужно заранее беспокоиться, что кто-то вас будет истязать кодированием вот в таком виде. Ну а если вы — разработчик Spring, то знали, на что шли.
И вот уже поверх континуаций построены файберы.
Fibers
Итак, что в нашем случае означают файберы.
Это некая абстракция, представляющая из себя:
- Легкие треды, обрабатываемые в самой JVM, а не в операционной системе;
- С крайне низкими оверхедами на создание, поддержание жизни, переключение задач;
- Которые можно запускать миллионы раз.
Многие технологии пытаются сделать файберы тем или иным образом. Например, в Kotlin есть корутины, реализованные на очень умной генерации байткода. ОЧЕНЬ УМНОЙ. Но рантайм — более правильное место для реализации подобных вещей.
Как минимум, JVM уже умеет хорошо справляться с тредами, а всё, что нам нужно — это упростить процесс кодирования многопоточности. Можно использовать асинхронные API, но это вряд ли стоит называть «упрощением»: даже использование таких штук, как Reactor, Spring Project Reactor, позволяющих писать вроде-бы-линейный код, не особо поможет при необходимости отладки сложных проблем.
Итак, файбер.
Файбер состоит из двух компонентов. Это:
- Continuation (континуейшен)
- Scheduler (скедьюлер)
То есть:
- Континуация
- Планировщик

Можете сами решить, кто здесь планировщик. Я думаю, планировщик тут именно Джей.
- Файбер оборачивает код, который вы хотите исполнить, в континуации
- Планировщик запускает их на пуле из carrier threads
Буду называть их тредами-носителями.

В текущем прототипе используется java.util.concurrent.Executor, а встроенный планировщик — ForkJoinPool. Всё у нас есть. В будущем там может появиться что-то поумней, но пока вот так.
Как ведет себя континуация:
- Вытесняется (yield), когда происходит блокировка (например, на IO);
- Продолжается, когда готова продолжиться (например, IO-операция завершилась и можно двигаться дальше).
Текущий статус работ:
- Основной фокус на философии, концепциях;
- API не зафиксировано, оно есть «для галочки». Это исследовательский прототип;
- Есть готовый закодированный работающий прототип класса
java.lang.Fiber.
О нем пойдет речь.
Что уже запилили в файбер:
- В нем работает запуск задач;
- Паркинг-анпаркинг на тред-носитель;
- Ожидание завершения файбера.
Принципиальная схема
mount();
try {
cont.run();
} finally () {
unmount();
}- Мы можем смонтировать файбер на тред-носитель;
- Потом запустить континуацию;
- И ждать, пока она не вытеснится или честно не остановится;
- В конце концов, мы всегда уходим с треда.
Этот псевдокод выполнится на планировщике ForkJoinPool или на каком-то другом (который в конце концов окажется в финальной версии).
Использование в реальности
Fiber f = Fiber.execute( () -> {
System.out.println("Good Morning!");
readLock.lock();
try {
System.out.println("Good Afternoon");
} finally {
readLock.unlock();
}
System.out.println("Good Night");
});Глядите, мы создаем файбер, в котором:
- приветствуем всех;
- блочимся на РЕЕНТРАНТ ЛОКЕ;
- по возвращении поздравляем с обедом;
- в конце концов отпускаем лок;
- и прощаемся.
Всё очень просто.
Мы не вызываем вытеснение напрямую. Сам Project Loom знает, что при срабатывании readLock.lock(); ему стоит вмешаться и неявно сделать вытеснение. Пользователь этого не видит, но оно там происходит.
Стеки, повсюду стеки!
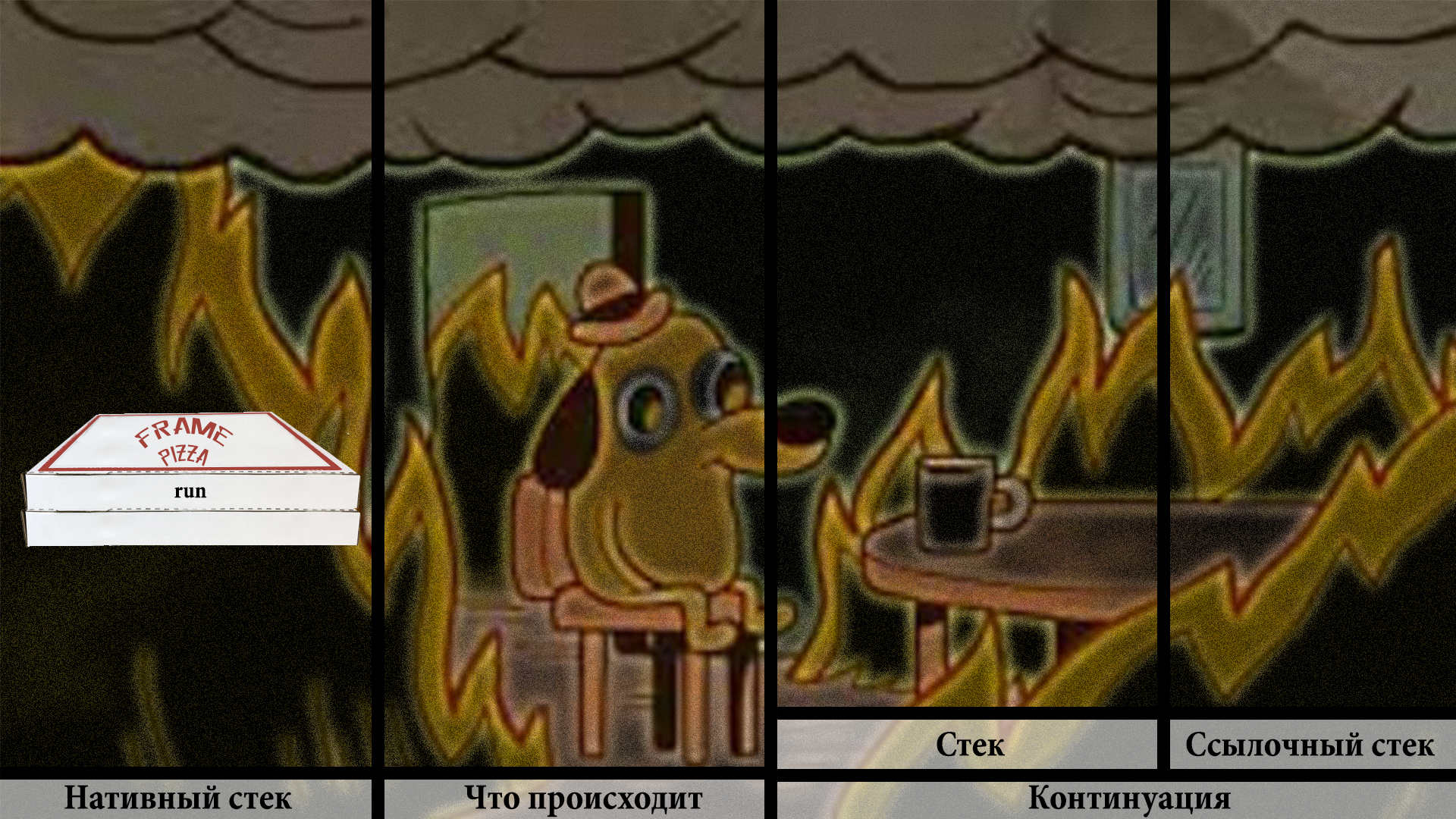
Давайте на примере стека с пиццей продемонстрируем, что происходит.
Вначале тред-носитель находится в состоянии ожидания, и ничего не происходит.

Вершина стека наверху, напоминаю.
Потом файбер запланировали к исполнению, и таск файбера начал запускаться

Внутри себя он, очевидно, запускает континуацию, в которой уже находится настоящий код.
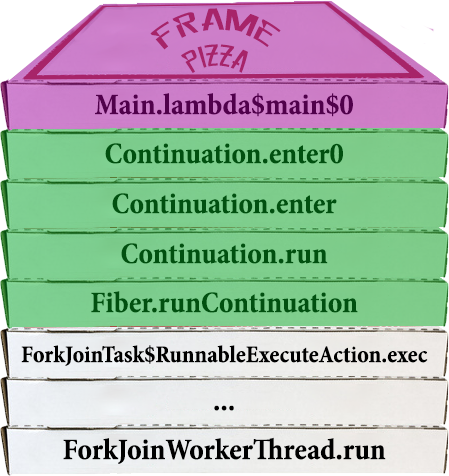
С точки зрения пользователя, мы здесь еще ничего не запустили.
Вот только первый фрейм юзерского кода появился на стеке, и он отмечен фиолетовым.
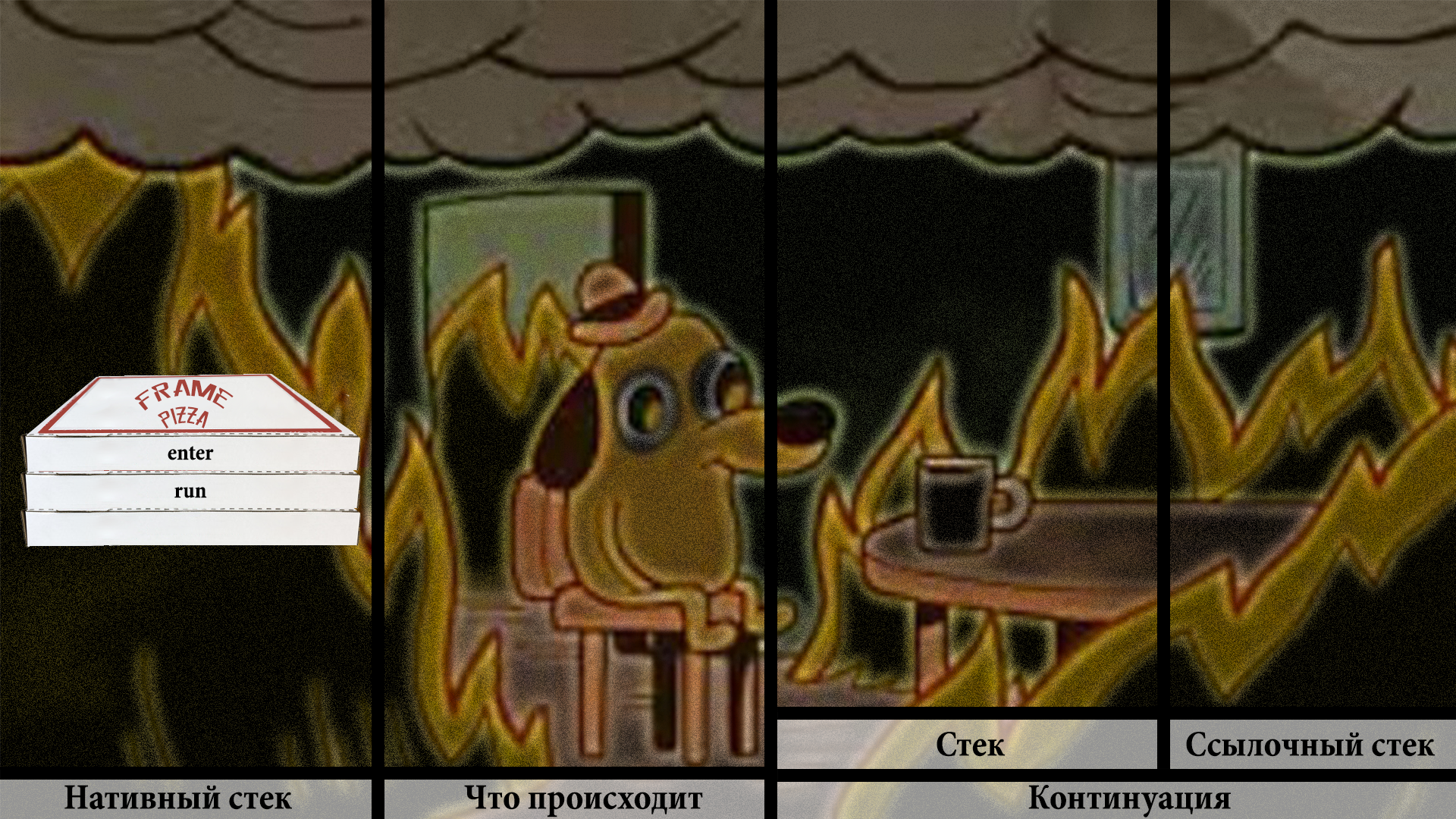
Дальше код выполняется-выполняется, в какой-то момент таск пытается захватить лок и заблочиться на нем, что приводит к автоматическому вытеснению.

Всё, что есть на стеке континуации, сохраняется в некое магическое место. И исчезает.

Как видим, поток возвращается в файбер, на инструкцию, которая идет следом за Continuation.run. А это — окончание кода файбера.
Таск файбера заканчивается, тред-носитель ждет новой работы.

Файбер запаркован, где-то лежит, континуация полностью вытеснена.
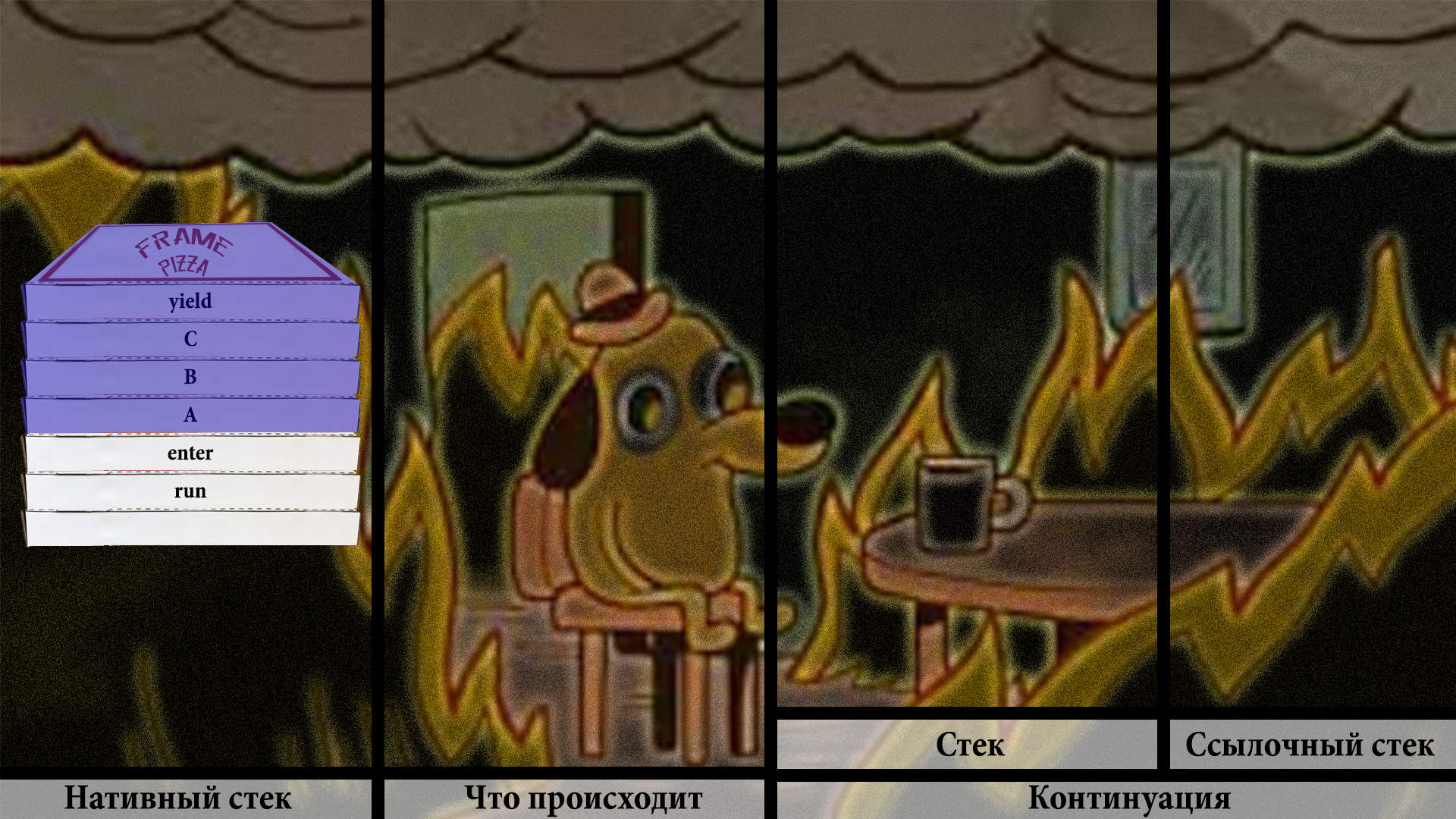
Рано или поздно наступает момент, когда тот, кто владеет локом, отпускает его.
Это приводит к тому, что файбер, который ждал отпускания лока, анпаркится. Таск этого файбера запускается снова.
- ReentrantLock.unlock
- LockSupport.unpark
- Fiber.unpark
- ForkJoinPool.execute
И мы быстро возвращаемся к стеку, который был недавно.
Причем тред-носитель может быть совершенно другой. И в этом смысл!
Снова запускаем континуацию.

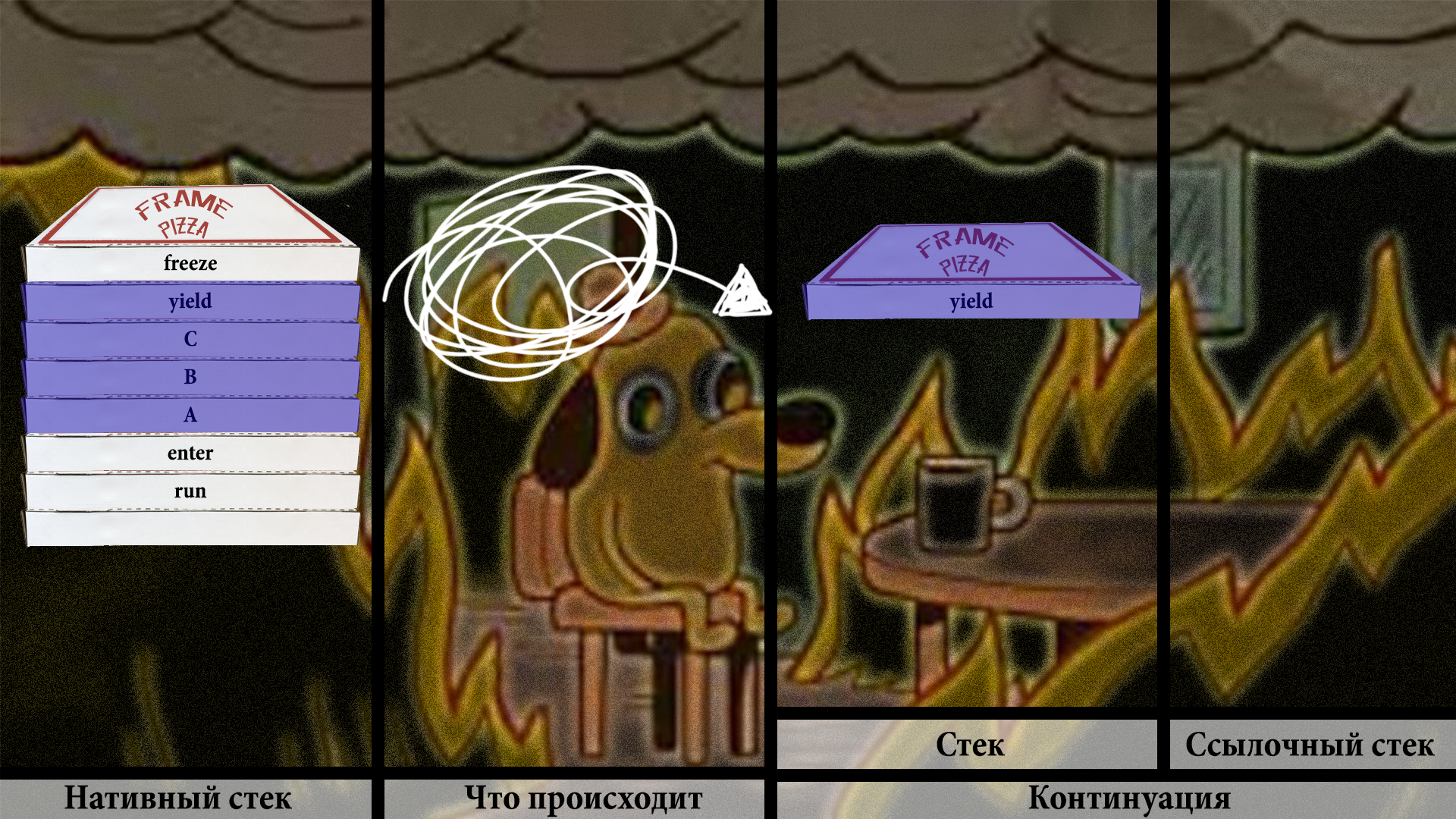
И тут происходит МАГИЯ!!! Стек восстанавливается, и выполнение продолжается с инструкции после Continuation.yield.

Мы вылезаем из только что отпаркованного лока и начинаем выполнять весь оставшийся в континуации код:

Таск пользователя завершается, и управление возвращается в таск файбера сразу же после инструкции continuation.run

При этом заканчивается и выполнение файбера, и мы снова оказываемся в режиме ожидания.
Следующий запуск файбера вновь инициирует весь описанный выше цикл перерождений.

Живые примеры
А кто вообще сказал, что все это работает? Это про пару микробенчмарков, написанных за вечер?
В качестве примера работы файберов оракловцы написали небольшой веб-сервер и накормили его запросами так, что он захлебнулся. Потом перевели на файберы. Сервер захлебываться перестал, и из этого сделали вывод, что файберы работают.
У меня нет точного кода этого сервера, но если этот пост наберет достаточно лайков и комментариев, я попробую самостоятельно написать пример и построить реальные графики.
Проблемы
Есть ли тут какие-то проблемы? Да, конечно! Вся история с файберами — это история о сплошных проблемах и трейдоффах.
Философские проблемы
- Нужно ли нам переизобрести треды?
- Должен ли весь существующий код нормально работать внутри файбера?
Текущий прототип выполняет с ограничениями. Которые, возможно, перейдут в релиз, хотя не хотелось бы. Всё-таки, OpenJDK — это штука, уважающая бесконечную совместимость.
В чем заключаются технические ограничения? Самых очевидных ограничений — 2 штуки.
Проблема раз — нельзя вытеснить нативные фреймы
PrivilegedAction<Void> pa = () -> {
readLock.lock(); // may park/yield
try {
//
} finally {
readLock.unlock();
}
return null;
}
AccessController.doPrivileged(pa); //native methodЗдесь doPrivileged зовет нативный метод.
Вы в файбере зовете doPrivileged, выпрыгиваете из VMки, у вас на стеке появляется нативный фрейм, после чего вы пытаетесь запарковаться на строчке readLock.lock(). И в этот момент тред-носитель окажется запиненным до того времени, пока его не распаркуют. То есть тред пропадает. В этом случае могут закончиться треды-носители, и вообще, это ломает всю идею файберов.
Способ это решить уже известен, и сейчас идут дискуссии по этому поводу.
Проблема два — synchronized-блоки
Это уже гораздо более серьезная фигня
synchronized (object) { //may park
object.wait(); //may park
}synchronized (object) { //may park
socket.getInputStream().read(); //may park
}В случае захвата монитора в файбере, треды-носители тоже пинятся.
Понятно, что в совершенно новом коде можно поменять мониторы на прямые блокировки, вместо wait+notify можно использовать condition objects, но что делать с легаси? Это проблема.
Thread API? Thread.currentThread()? Thread Locals?
В текущем прототипе для Thread и Fiber сделали один общий суперкласс под названием Strand.
Это позволяет перенести API в самом минимальном варианте.
Что делать дальше — как всегда в этом проекте, вопрос.
Что сейчас происходит с Thread API?
- Первое использование
Thread.currentThread()в файбере создает некий теневой тред, Shadow Thread; - с точки зрения системы, это "незапущенный" тред, и в нем нет никакой VMной метаинформации;
- ST старается эмулировать все, что может;
- но надо понимать, что в старом API куча мусора;
- более конкретно, Shadow Thread реализует Thread API для всего, кроме
stop,suspend,resumeи обработки непойманных исключений.
Что делать с Thread Locals?
- сейчас thread locals просто превращаются в fiber locals;
- с этим есть очень много проблем, все это обсуждается;
- особенно обсуждается набор способов использования;
- треды исторически использовали и правильно, и неправильно (те, кто используют неправильно, все равно на что-то надеются, и нельзя их совсем-то разочаровывать);
- в целом это создает целый спектр применений:
- Высокоуровневые: кэш коннекшенов или паролей в контейнере;
- Низкоуровневые: процессорные в системных библиотеках.
Сколько все это жрет

Thread:
- Стек: 1MB и 16KB на структуры данных ядра;
- На экземпляр треда: 2300 байтов, включая VMную метаинформацию.
Fiber:
- Стек континуации: от сотен байт до килобайт;
- На экземпляр файбера: 200-240 байтов.
Разница колоссальная!
И это именно то, что позволяет файберам запускаться миллионами.
Что может парковаться
Понятно, что самая магическая вещь — это автоматическая парковка при наступлении каких-то событий. Что сейчас поддерживается?
- Thread.sleep, join;
- java.util.concurrent и LockSupport.lock;
- IO: сетевое на сокетах (socket read, write, connect, accept), файлы, пайпы;
- Всё это недоделанное, но свет в туннеле виден.
Коммуникация между файберами
Еще один вопрос, который все задают: как конкуррентно обмениваться информацией между файберами.
- Текущий прототип запускает таски в
Runnable, можно переделать наCompletableFuture, если зачем-то нужно; - java.util.concurrent «просто работает». Можно шарить всё стандартным способом;
- возможно, появятся новые API для многопоточности, но это не точно;
- куча мелких вопросов вроде «должны ли файберы возвращать значения?»; всё обсуждается, их нет в прототипе.
Как реализованы континуации в прототипе?
На континуации накладываются очевидные требования: нужно использовать как можно меньше оперативной памяти, и нужно переключаться между ними как можно быстрей. Иначе не получится держать их миллионами. Основная задача тут — каким-то образом не делать полное копирование стека на каждый паркинг-анпаркинг. И такая схема есть! Попробуем объяснить это в картинках.
Самый крутой способ был бы, конечно, просто класть все стеки на джавовый хип и использовать их напрямую. Но это непонятно, как сейчас закодить, поэтому в прототипе используется копирование. Но копирование с небольшим, но важным хаком.
У нас есть два стула… в смысле, два стека. Два джавовых массива в хипе. Один — объектный массив, где мы будем хранить ссылки на объекты. Второй — примитивный (например, интовый), который будет обрабатывать всё остальное.
Сейчас мы находимся в состоянии, когда континуация собирается выполняться в самый первый раз.
run зовёт внутренний метод под названием enter:
И дальше выполняется пользовательский код, вплоть до первого вытеснения.
В этот момент выполняется вызов VM, который зовёт freeze. В этом прототипе это делается прямо физически — с помощью копирования.

Начинаем процесс последовательного копирования фреймов из нативного стека в джавовый хип.
Нужно обязательно проверить, держатся ли там мониторы или используется нативный код, или ещё что-то такое, что на самом деле не даст нам дальше работать.
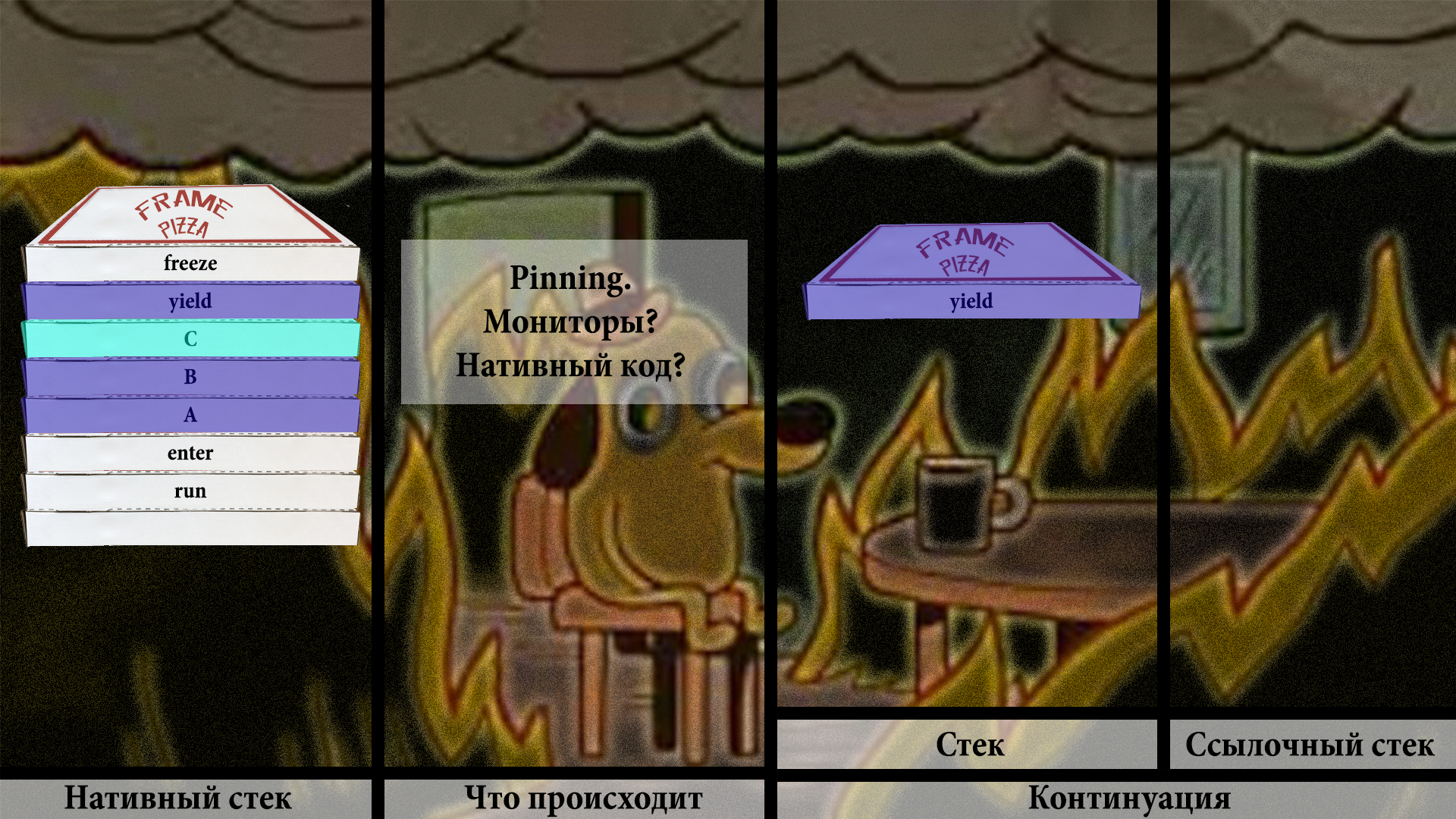
И если всё хорошо, мы копируем сначала в примитивный массив:

Потом вычленяем ссылки на объекты и сохраняем в объектный массив:
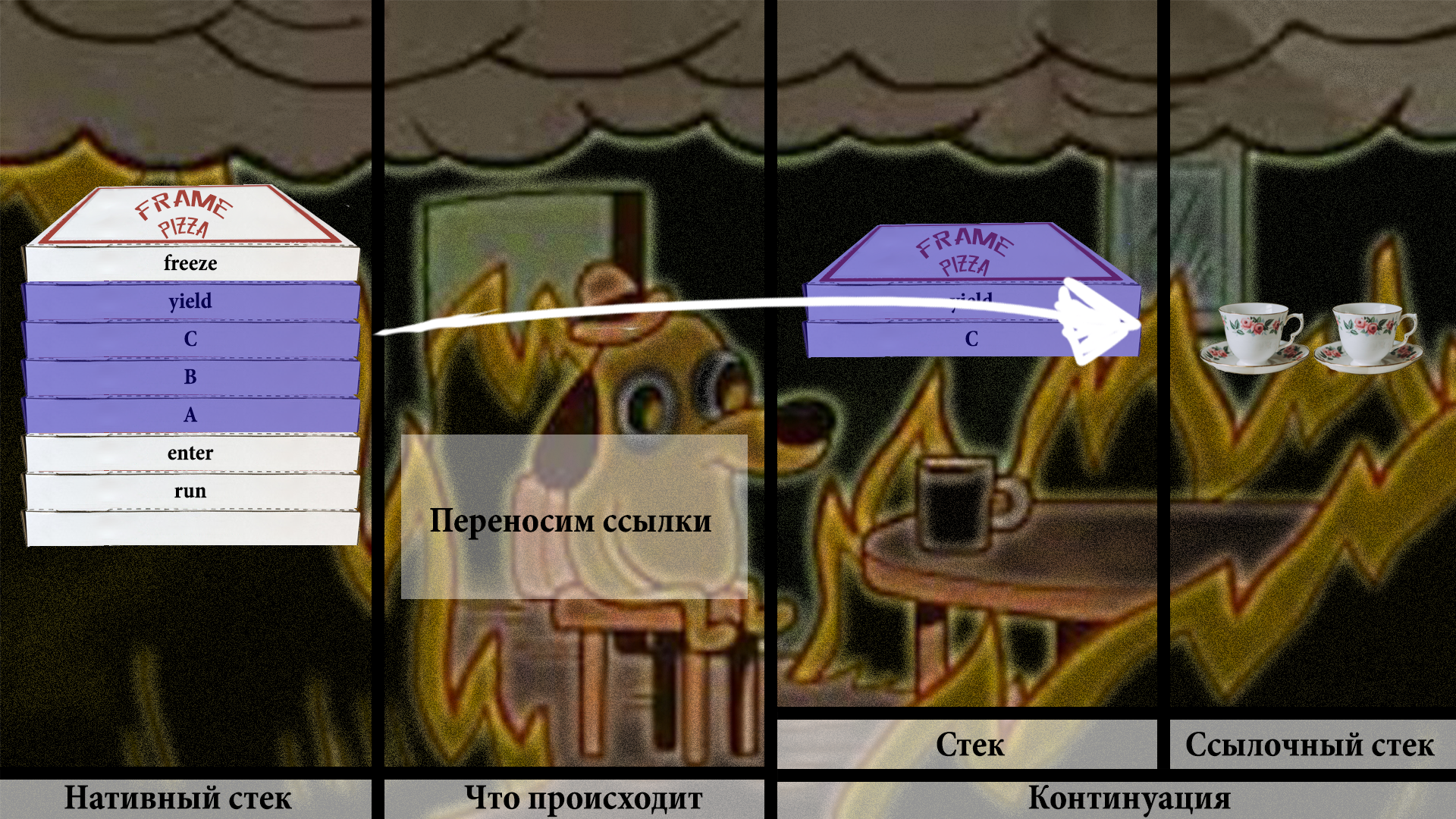
Собственно, два чая всем, кто дочитал до этого места!
Дальше мы продолжаем эту процедуру для всех остальных элементов нативного стека.

Ура! Мы всё перекопировали в заначку в хипе. Можно спокойно прыгать в место вызова, не боясь, что мы чего-то потеряли. Всё в хипе.
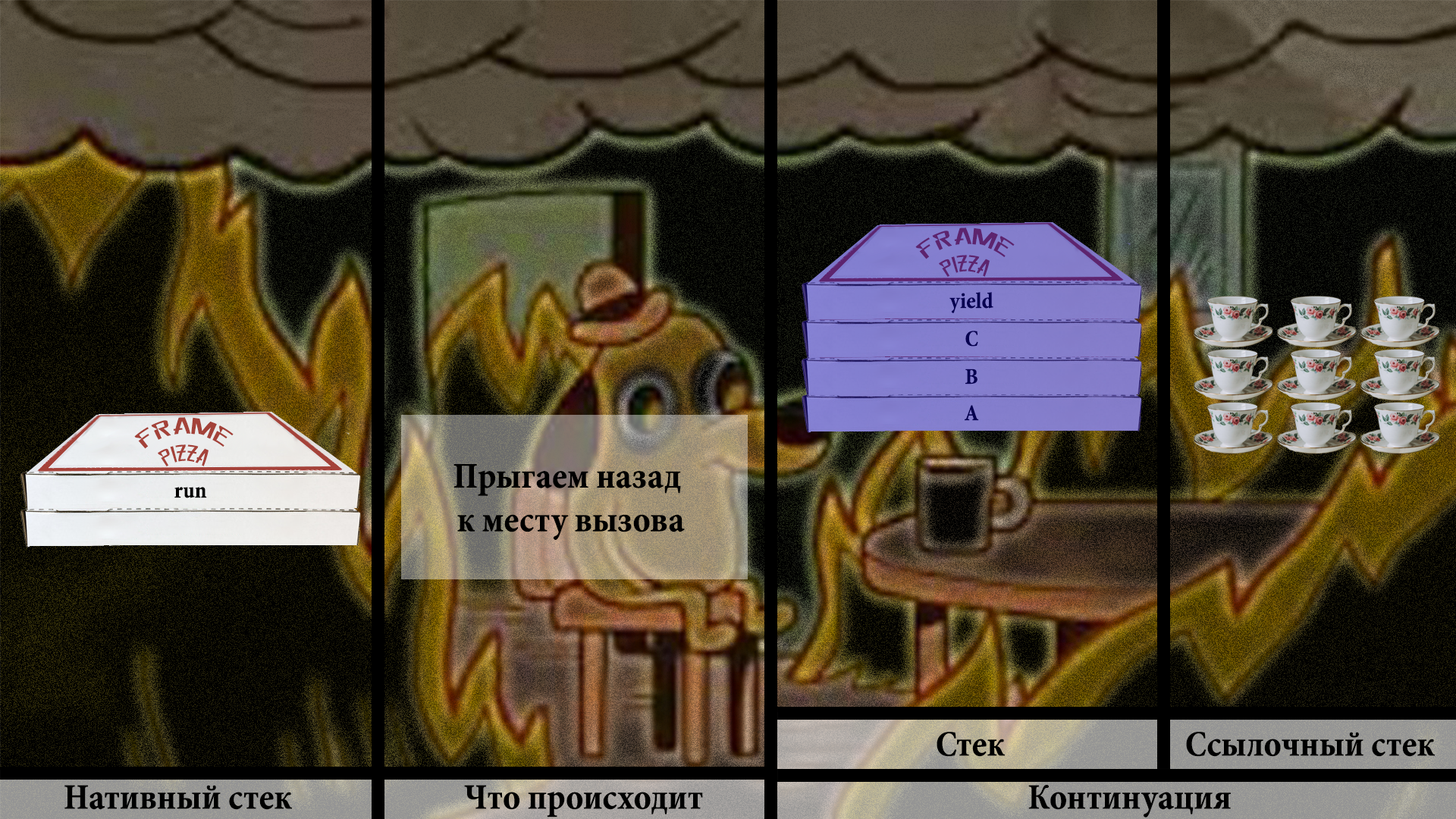
Теперь рано или поздно вызывающий код позовёт нашу континуацию снова. И она должна продолжиться с того места, где она была оставлена в прошлый раз. Это наша задача.
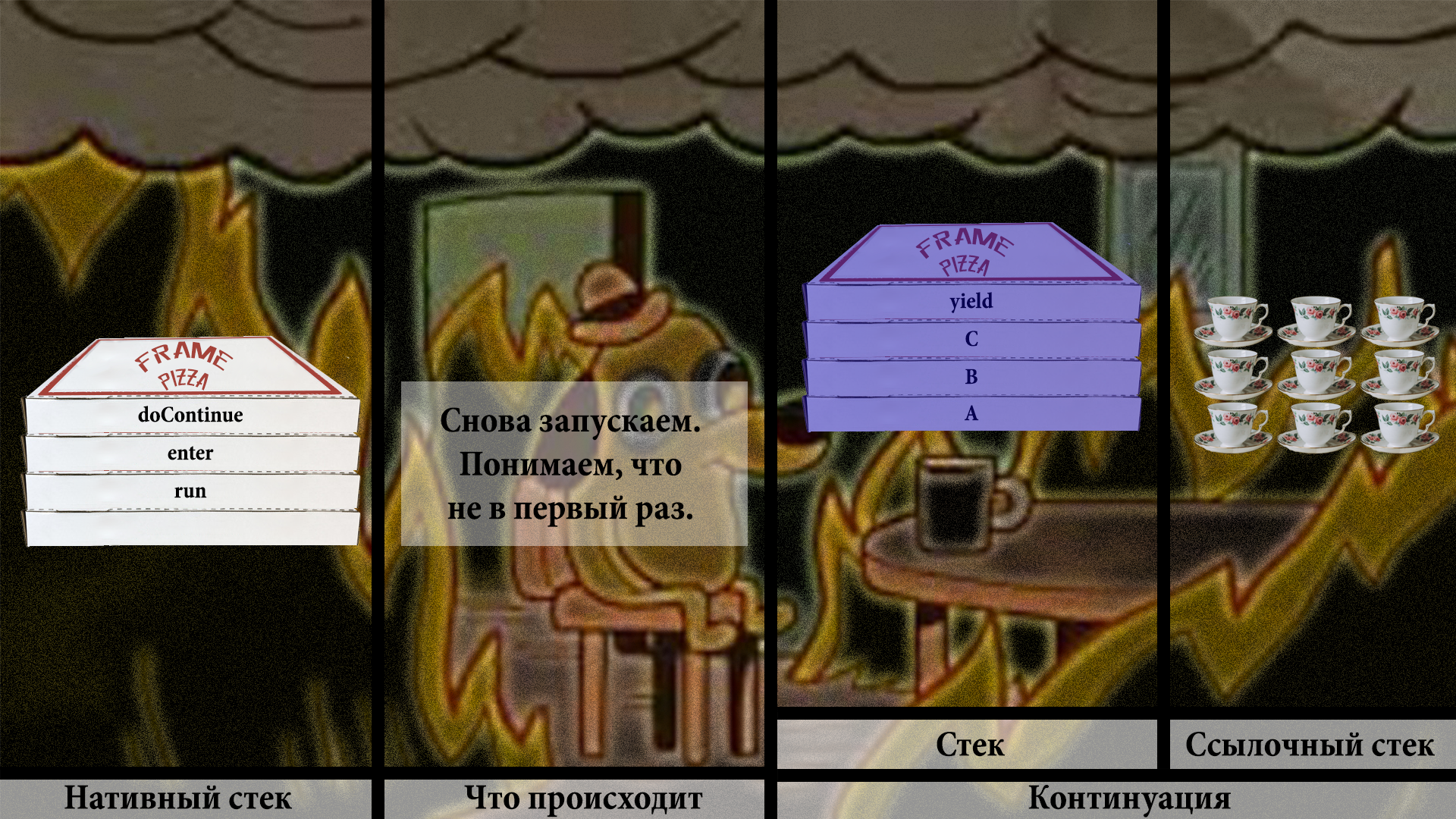
Проверка на то, запускалась ли континуация, говорит — да, запускалась. Значит, нужно позвать VM, почистить немного места на стеке и вызвать внутреннюю VM-ную функцию thaw. На русский «thaw» переводится как «оттаить», «разморозиться», что звучит вполне логично. Необходимо разморозить фреймы со стека континуации в наш основной нативный стек.
Не уверен, что разморозка чая выглядит достаточно наглядно. Плохая абстракция подобна котёнку с дверцей. Но нам и такая сгодится.
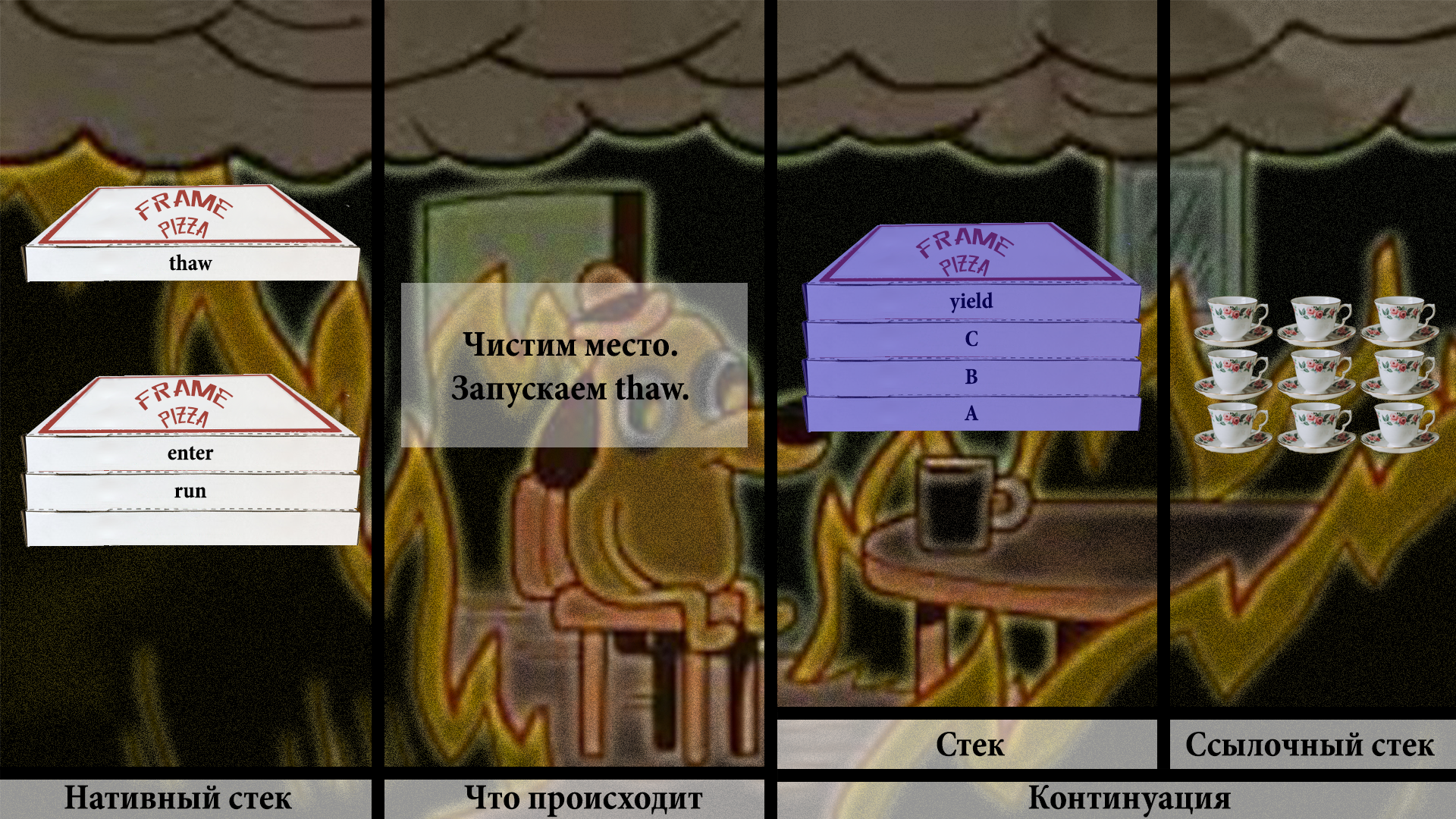
Производим вполне очевидные копирования.
Сначала с примитивного массива:
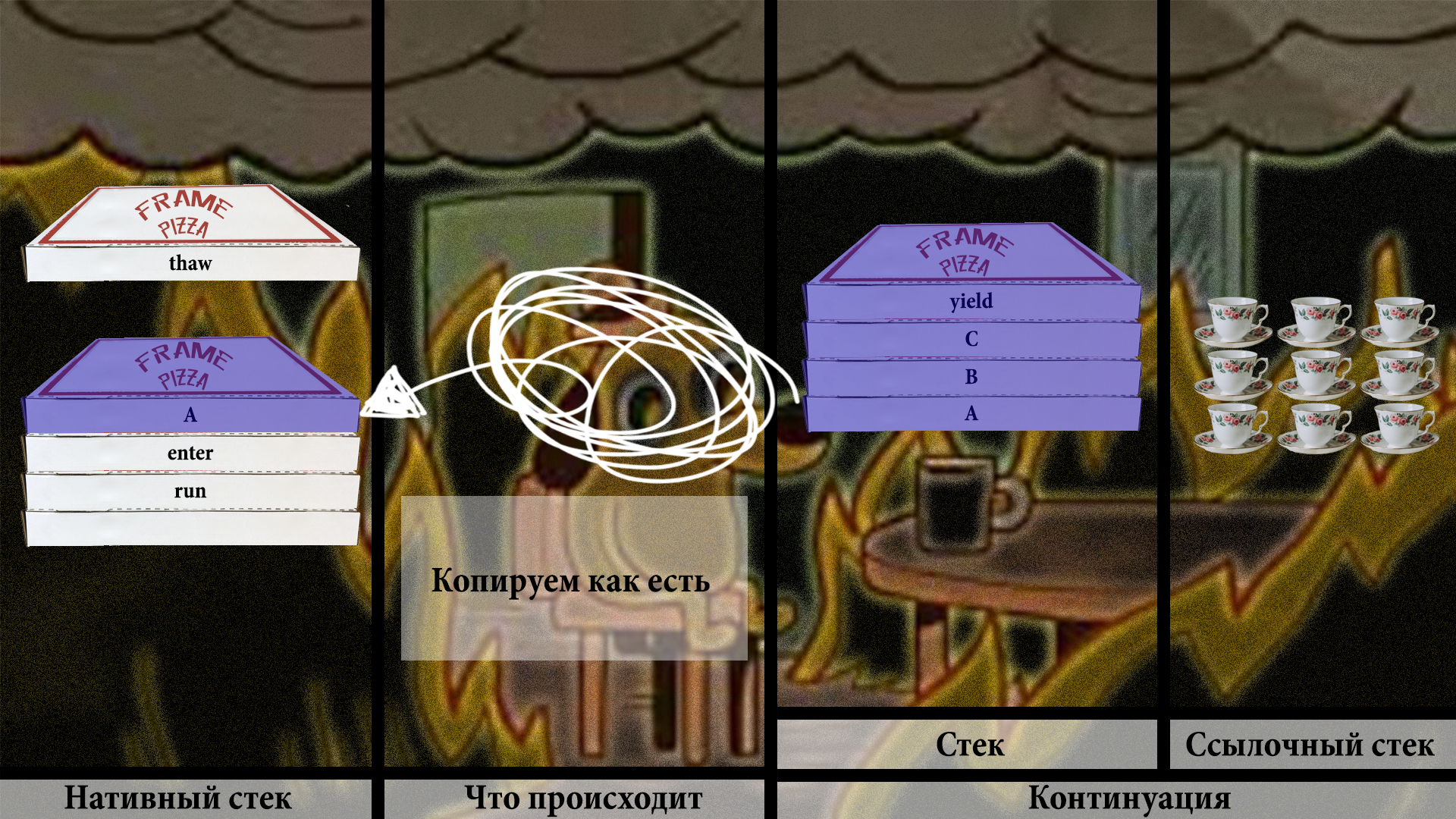
Потом со ссылочного:

Нужно немного попатчить скопированное, чтобы получить корректный стек:
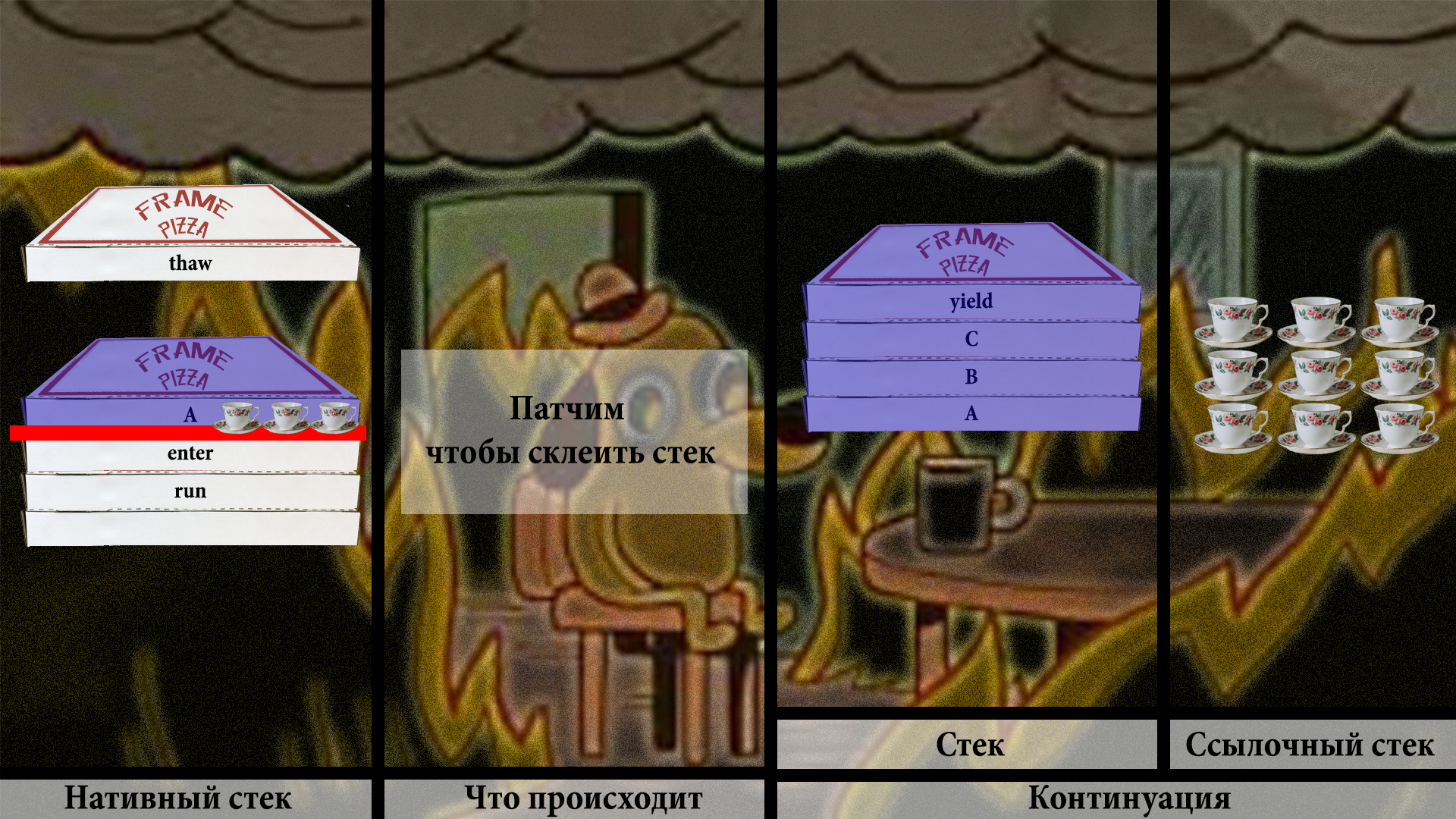
Повторяем непотребство для всех фреймов:
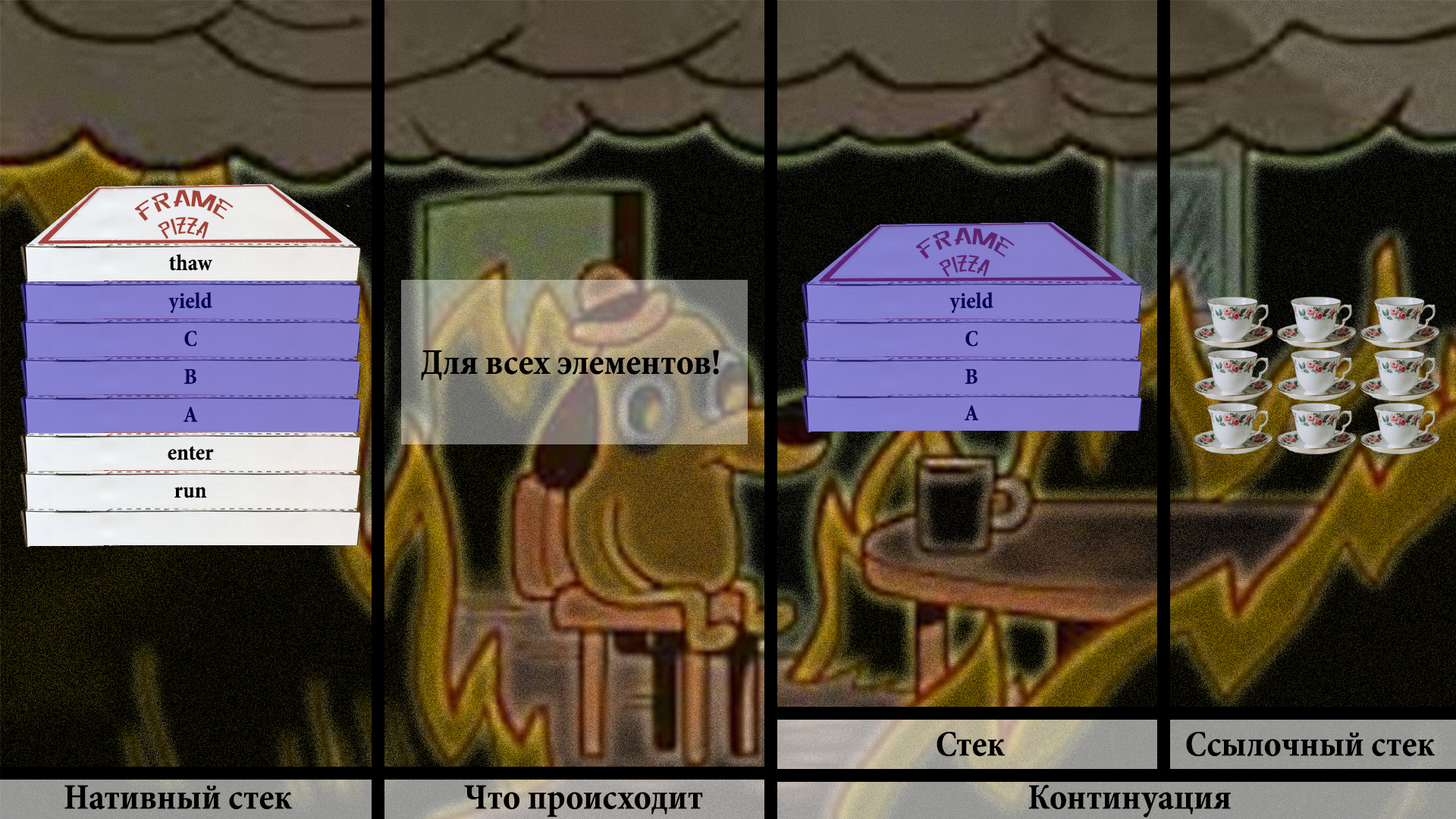
Теперь можно вернуться к yield и продолжить, как будто ничего и не происходило.

Проблема в том, что полное копирование стека — это совершенно не то, что нам хотелось бы иметь. Оно очень тормозное. Всё это вычленение ссылок, проверки для пиннинга, оно не быстрое. И главное — всё это линейно зависит от размера стека! Словом, ад. Не надо так делать.
Вместо этого у нас есть другая идея — ленивое копирование.
Давайте откатимся к тому месту, где у нас уже есть замороженная континуация.
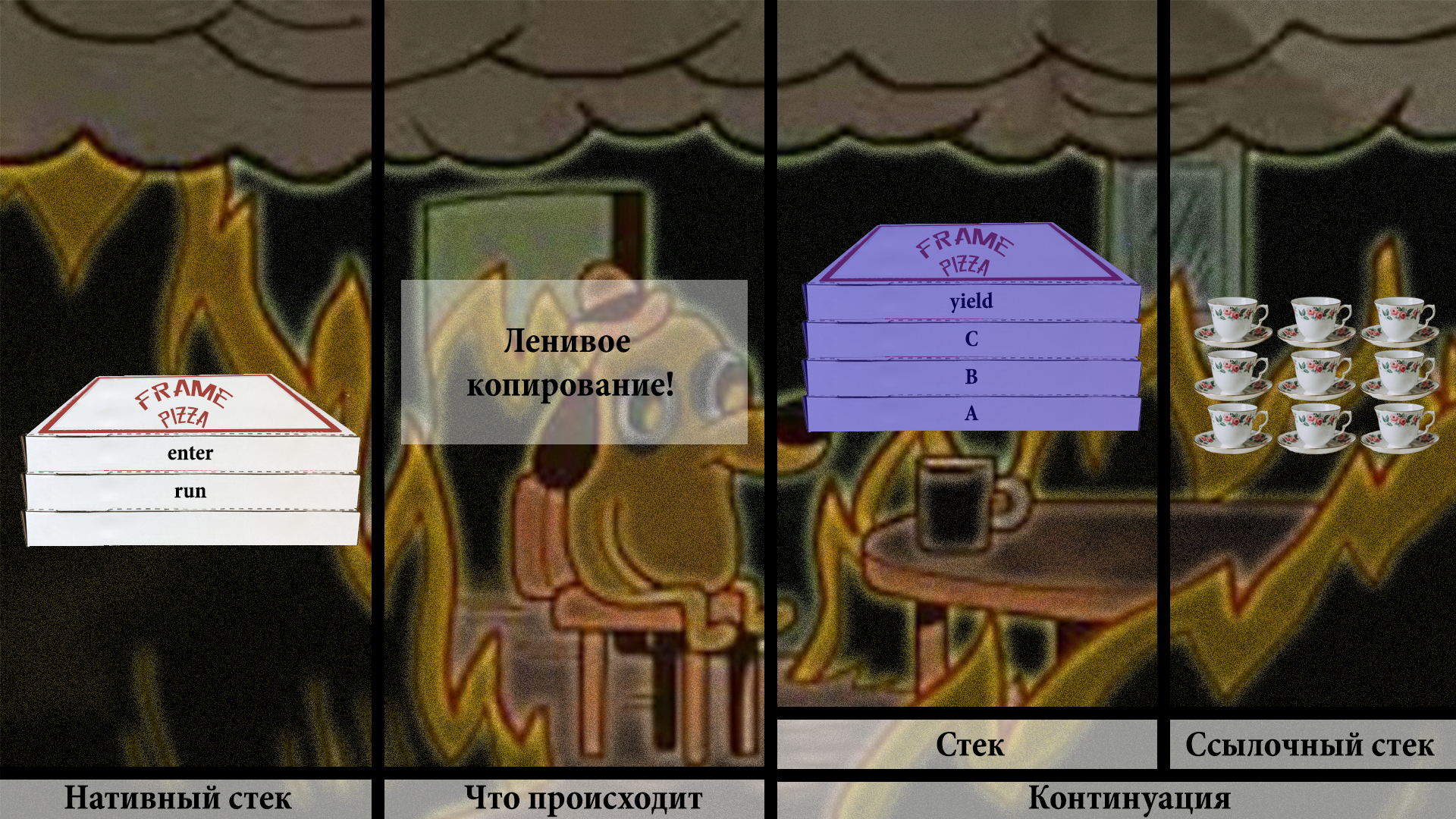
Мы продолжаем процесс так же, как и раньше:

Точно так же, как и раньше, чистим место на нативном стеке:
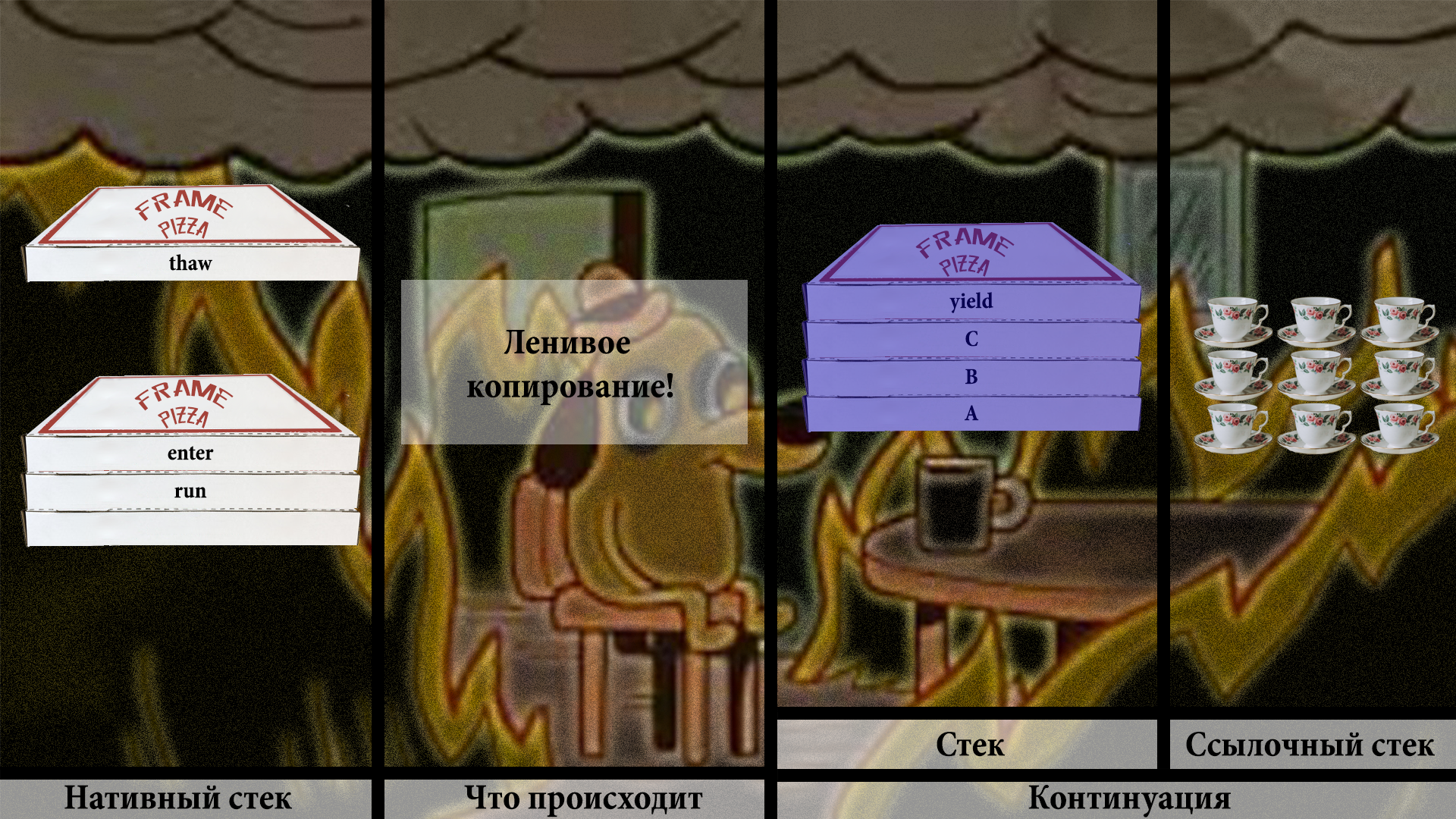
Но копируем не всё подряд, а только один или парочку фреймов:
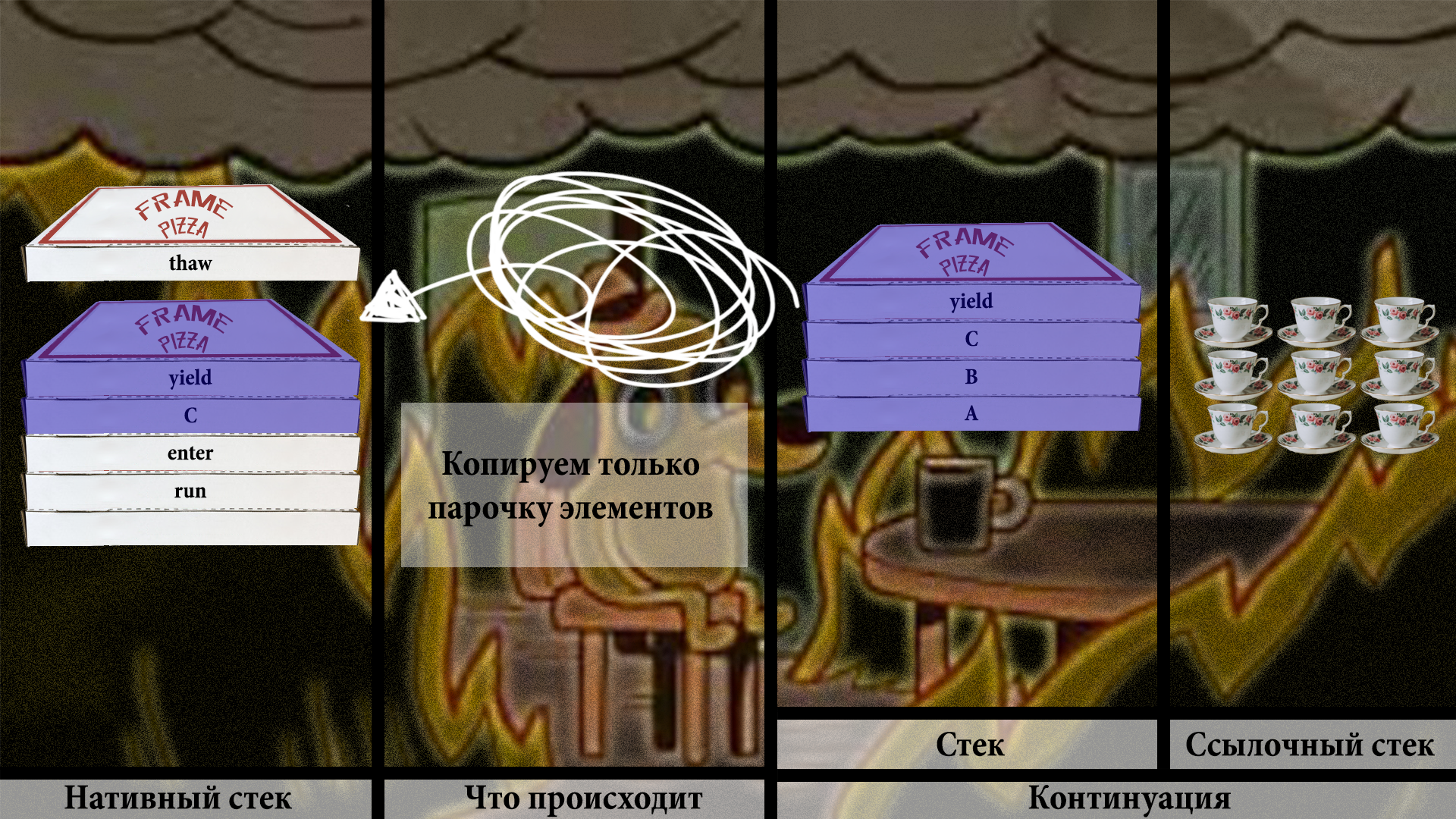
Теперь хак. Нужно пропатчить адрес возврата метода C, чтобы он указывал на некий return barrier:
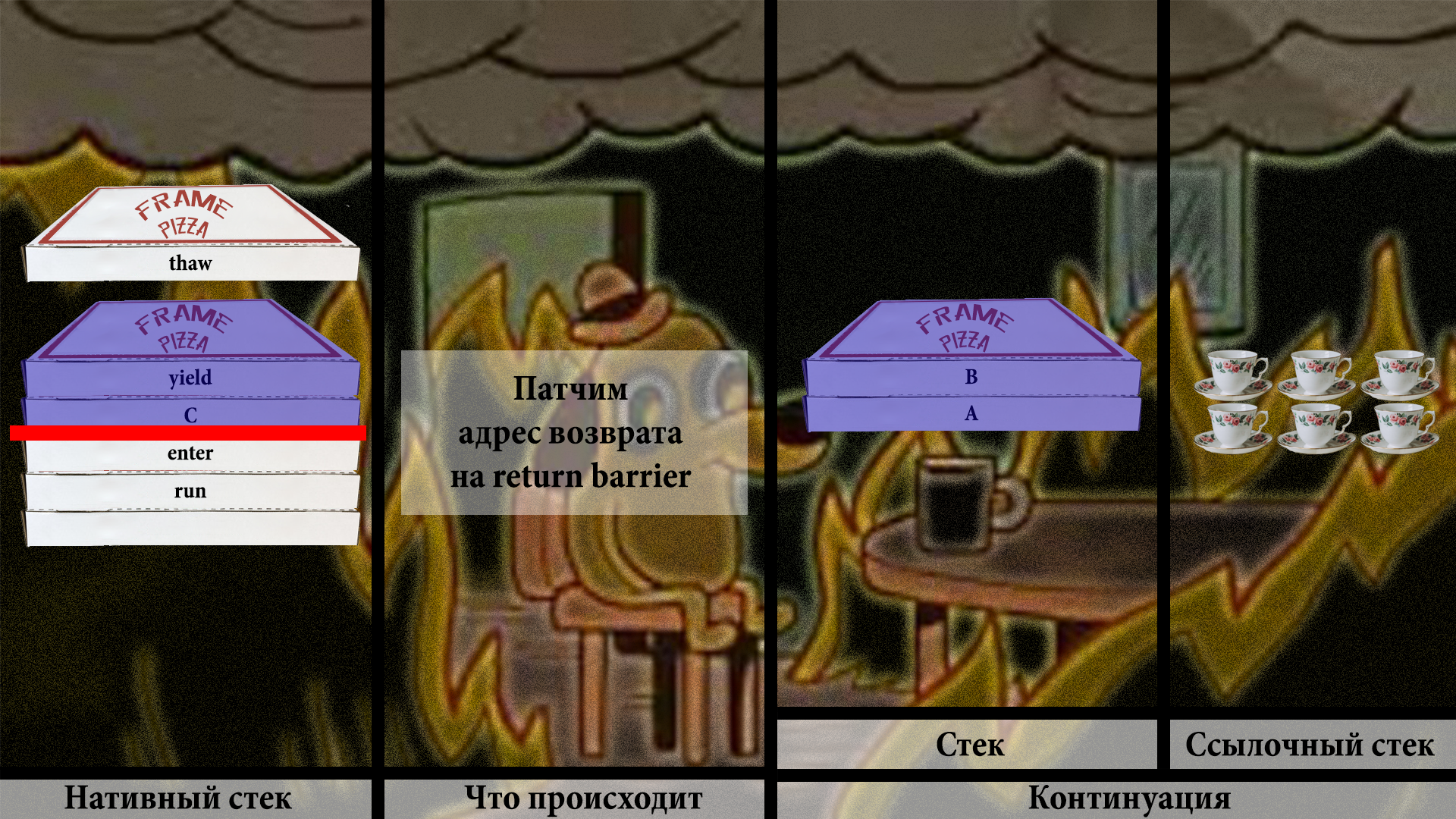
Теперь можно спокойно вернуться к yield:
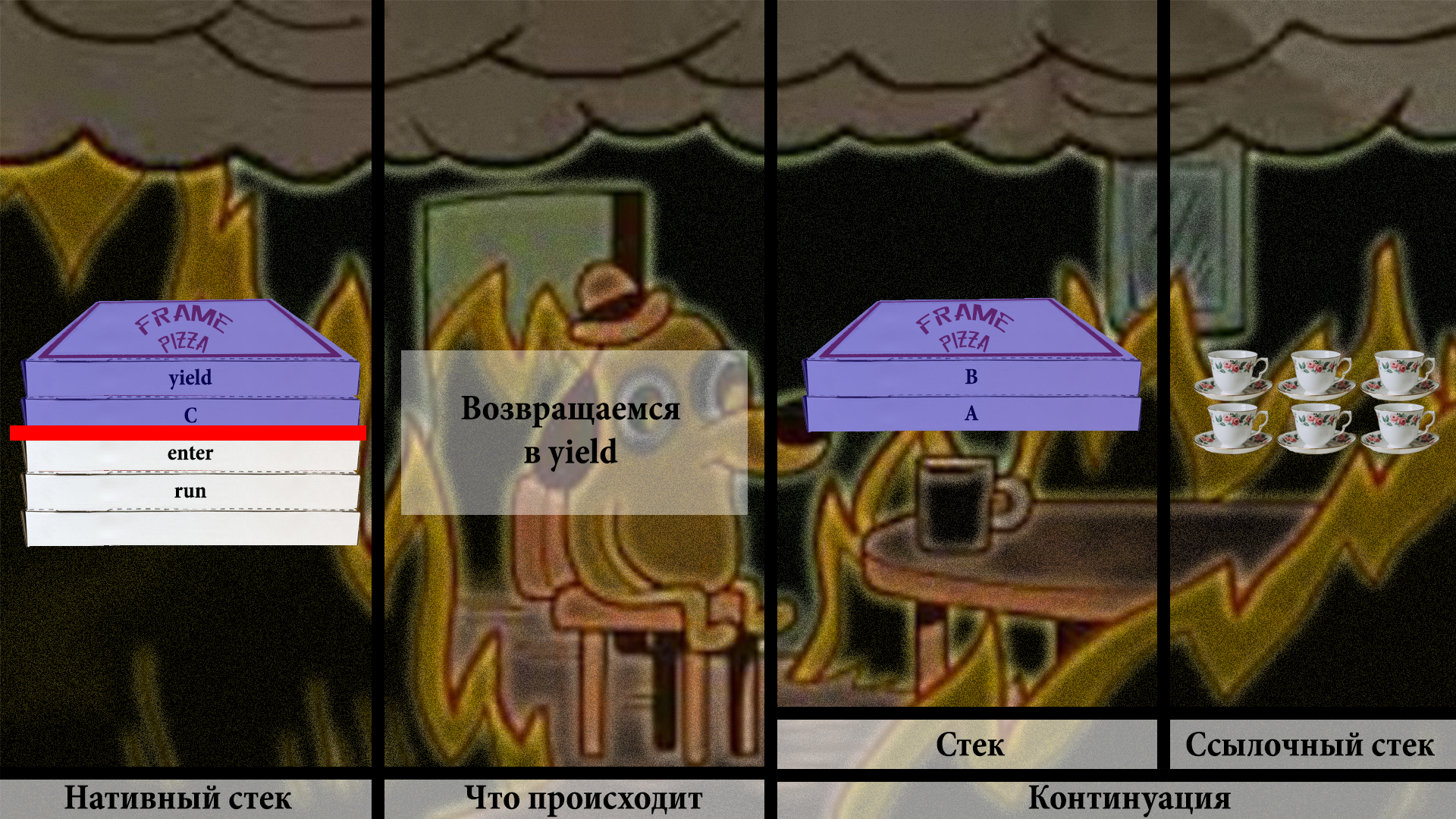
Что в свою очередь приведёт к вызову пользовательского кода в методе C:

Теперь представим, что C хочет вернуться к коду, который его вызвал. Но его вызывальщик — это B, и он не на стеке! Поэтому, когда он попытается вернуться, он пройдёт по адресу возврата, и этот адрес теперь — return barrier. И, ну вы понимаете, это снова потянет за собой вызов thaw:

А thaw нам разморозит следующий фрейм на стеке континуации, и это B:
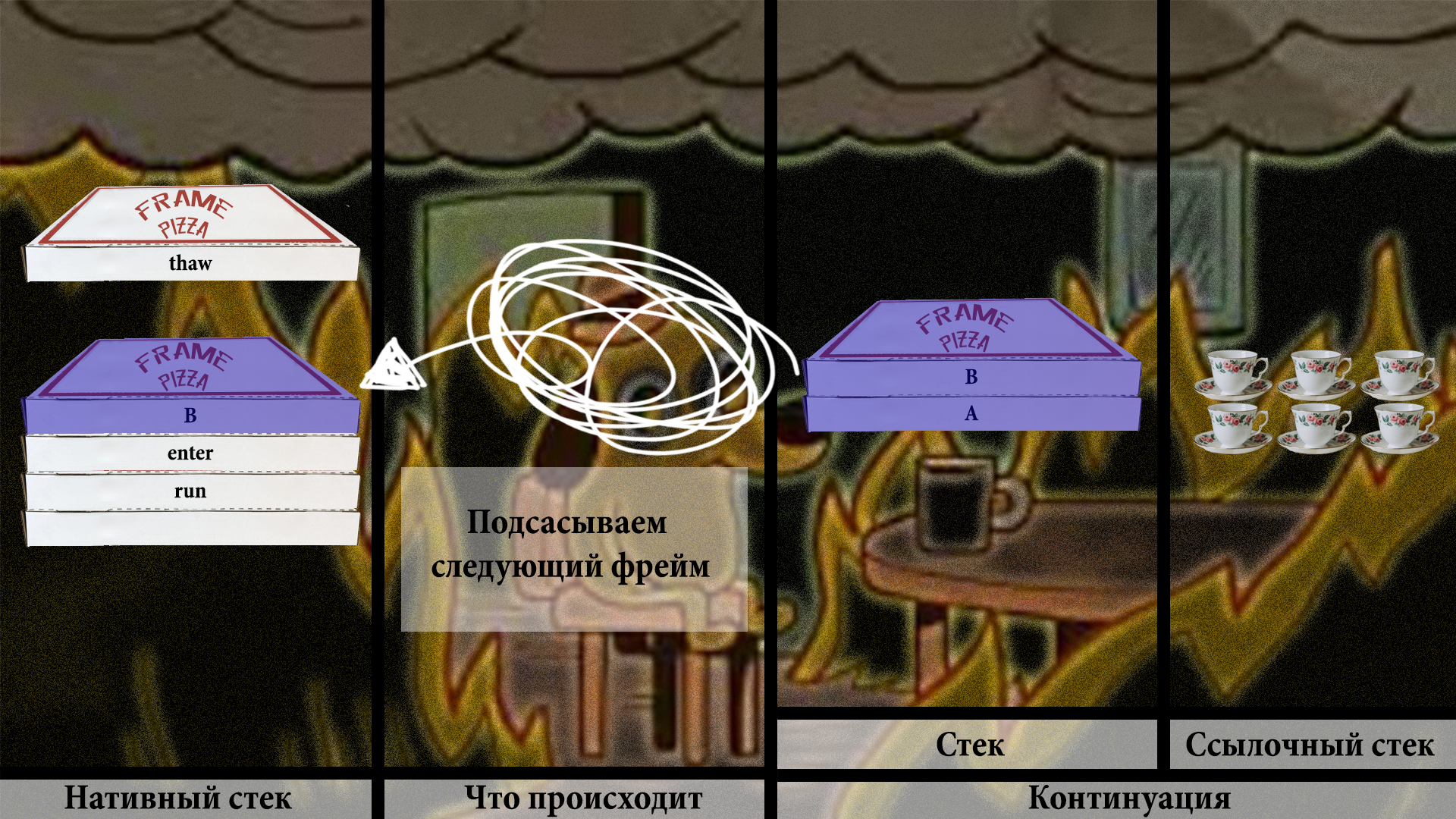
По сути, мы скопировали его лениво, по запросу.
Дальше мы сбрасываем B со стека континуации и снова устанавливаем барьер (барьер нужно ставить, потому что на стеке континуации кой-чего осталось). И так раз за разом.
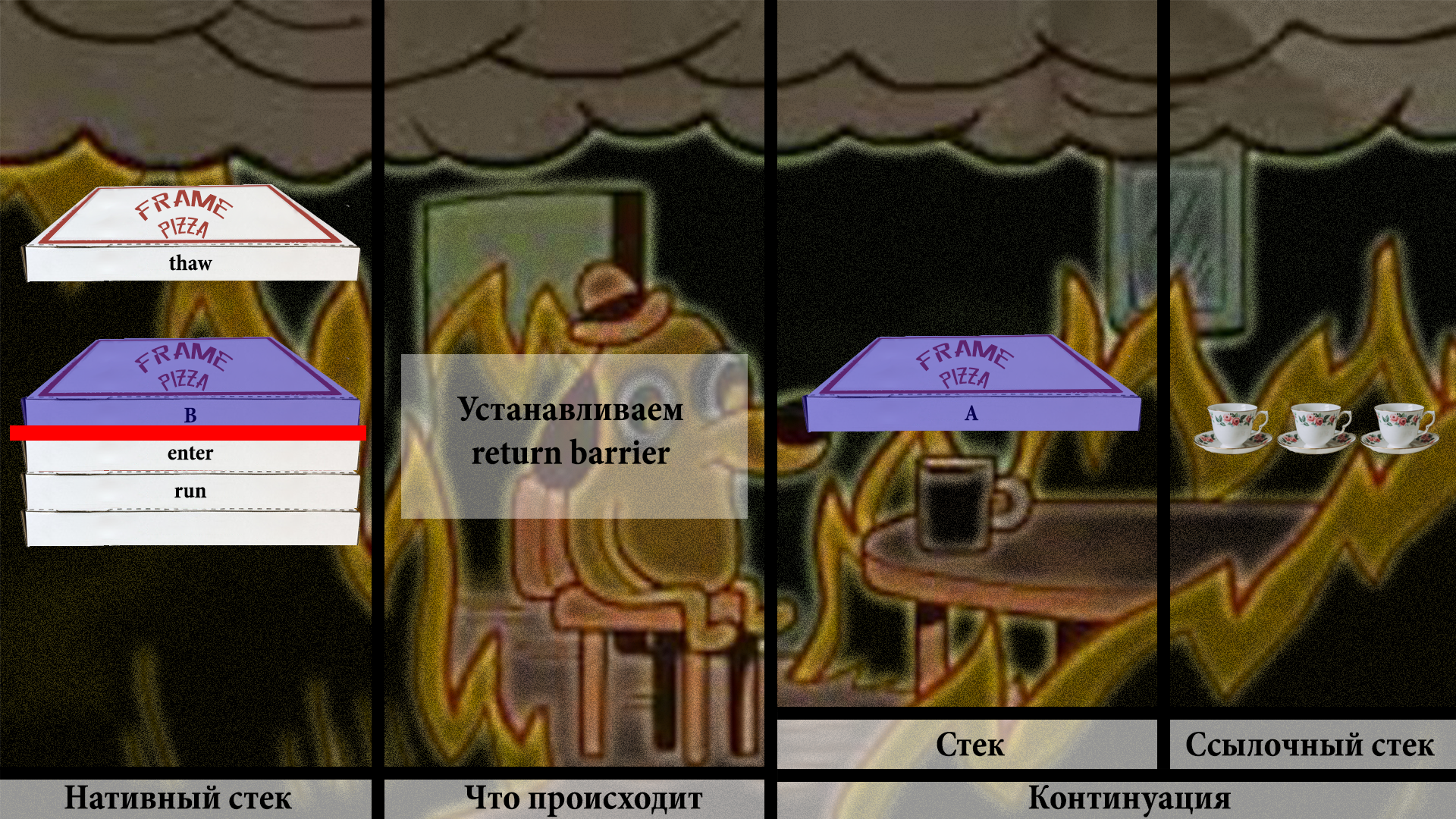
Но представим, что B не собирается возвращаться к вызывающему коду, а вначале зовёт какой-то другой метод D. И этот новый метод тоже хочет вытесниться.

В этом случае, когда придёт время делать freeze, нам нужно будет скопировать в стек континуации только верхушку нативного стека:

Таким образом, количество совершаемой работы не зависит линейно от размера стека. Оно линейно зависит только от количества тех фреймов, которые мы реально использовали в работе.
Что осталось?
Некоторые фичи разработчики держат в уме, но в прототип они не попали.
- Сериализация и клонирование. Возможность продолжить на другой машине, в другое время, и т.п.
- JVM TI и отладка, как будто бы они обычные треды. Если вы заблокировались на чтении сокета, то вы не увидите красивого прыжка из yield, в прототипе тред просто заблокируется, как и любой другой обычный тред.
- К хвостовой рекурсии даже не прикасались.
Следующие шаги:
- Сделать человеческий API;
- Добавить все недостающие фичи;
- Улучшить производительность.
Где взять
Прототип выполнен в виде бранча в репозитории OpenJDK. Cкачать прототип можно здесь, переключившись на бранч fibers.
Делается это так:
$ hg clone http://hg.openjdk.java.net/loom/loom
$ cd loom
$ hg update -r fibers
$ sh configure
$ make imagesКак вы понимаете, всё это запустит сборку всего чертового OpenJDK. Поэтому, во-первых, ближайшие полчаса вашей жизни придется заняться чем-то другим, пока всё это собирается.

Во-вторых, нужно иметь нормально настроенный компьютер с C++ тулчейном и GNUшными либами. Я намекаю, что всячески не рекомендуется делать это на Windows. Серьезно, даже со скачиванием VirtualBox и установкой новой Ubuntu туда вы потратите на порядки меньше времени, чем пытаясь осознать очередную негуманоидную ошибку при билде из Cygwin или msys64. Это тот момент, когда msys заходит даже хуже, чем Cygwin.
Хотя это, конечно, все ложь, я просто задолбался писать вам инструкции по сборке.
Если собираетесь чего-то менять в исходнике, рекомендую включить mercurial extension под названием fsmonitor. Прочитать, что это такое, можно командой hg help -e fsmonitor.
Для включения нужно добавить в ~/.hgrc такую строчку:
[fsmonitor]
mode = onМногие каким-то невообразимым образом умудряются испортить скачанный репозиторий в течение первых минут использования. Поэтому рекомендую на всякий случай сразу же после скачивания всю папочку скопировать куда-нибудь, cp -R ./loom ./loom-backup.
Как обычно, меняем место на жестком диске на возможные потерянные часы жизни. Думаю, что среднестатистический Java-разработчик получает достаточно много бабла, чтобы правильно расставить приоритеты в этом вопросе.
sh configure иногда будет просить что-то сделать. Например, если у вас свежеустановленная Ubuntu, то оно попросит установить Autoconf (sudo apt-get install autoconf). Это — одна из прелестей сборки OpenJDK на свежей Ubuntu, многие проблемы тебе уже рассказали, как решить. В Windows настолько же хороших подсказок не будет, если будут вообще.
Посмотреть, в чем разница между бранчами, можно командой hg diff --stat -r default:fibers.
В целом, подробный разбор увиденного в диффе заслуживает совершенно отдельной философской статьи, отдельного выпуска подкаста, и сейчас это обсуждать бессмысленно.
Заключение
Файбер в английском языке означает «волокно, нить». Отсюда слово «микрофибра», например. «Loom» — это «ткацкий станок». В Project Loom мы будем ткать свой код как полотно из файберов.
Но даже с этими нововведениями современное многопоточное программирование выглядит допотопно, потому что требует кучи дополнительных усилий и осознанности. То, что теперь мы можем запускать «треды» сразу миллионами, не означает, что думать вообще не надо — думать надо, но, к счастью, — сильно меньше.
Символично, что именно те, кто ткал на ручных ткацких станках в первой четверти XIX века бросились ломать автоматику, которая была тогда создана для дешевого производства чулок.

А у нас дешевое производство тредов. По-моему, аналогия прозрачна.
Надеюсь, однажды всё это будет заменено на ещё более простые и дешевые по отношению к мыслетопливу разработчиков механизмы. Всё это будет делать Искусственный Интеллект внутри IDE и так далее.
А в данный момент можно будет насладиться не только файберами, но и сочным бугуртом Свидетелей святой Конкарренси, которые расскажут нам, что всё это «не нужно», «тормозит», «вручную понятней» и так далее.
А что вы по этому поводу думаете? Напишите в комментариях. Порадуйте старого человека.
Спасибо.
