

Какое отношение к легаси-коду имеют «Звёздные войны», группа «Тату» и сочетание «Ctrl-Alt-Del»? Как быть, когда приходишь в большой проект и сталкиваешься с пропастью непонятного старого кода? И как эффективнее донести до начальства, что трудозатраты на ликвидацию технического долга оправдывают себя?
Доклады Дилана Битти не обходятся без шуток, но эти шутки сопровождают вполне серьёзные рассуждения о главных вопросах разработки. Такое хорошо подходит для завершения конференции: когда зрители уже услышали много хардкора и больше не могут воспринимать слайды с кодом, самое время для более общих вопросов и яркой подачи. И когда нашу .NET-конференцию DotNext 2018 Moscow завершало выступление Дилана про легаси-код, зрителям оно понравилось сильнее всего.
Поэтому теперь для Хабра мы сделали переведённую текстовую версию этого выступления: и для дотнетчиков, и для всех остальных. Помимо текста, под катом есть и оригинальная англоязычная видеозапись.
Здравствуйте, меня зовут Дилан Битти. Тема разговора очень близка мне и, по-моему, крайне важна для всех, кто занимается разработкой софта: речь пойдёт о легаси-коде.
Вначале скажу пару слов о себе. Я начал разрабатывать веб-сайты ещё в 1992-м, по меркам нашей отрасли — в доисторические времена. Сейчас я CTO лондонской компании SkillsMatter. Начал там работать в этом году, тем самым унаследовав кодовую базу: моей ответственностью стали 75 тысяч строк кода, написанного не мной. Отчасти мой доклад основан на этом опыте. Кроме того, я Microsoft MVP и руководитель лондонской юзер-группы .NET.

Что общего у «Доктора Кто», современных «Звёздных войн», «Шерлока» и «Пэддингтона»? При работе над ними был использован легаси-код. Мне это известно, поскольку в течение 15 лет я работал в Spotlight. Это лондонская компания, которая предоставляет онлайн-инструмент для профессиональных актёров, снимающихся в фильмах и на телевидении. Софт, написанный мной и моей командой, использовался в работе над всеми упомянутыми проектами и многими другими.
В новых «Звёздных войнах» кому-то не понравились актёры, другим не понравился сюжет. Но никто не вышел из кинотеатра со словами «мне не нравится, что при создании был использован классический ASP»!
Потому что это не имеет никакого значения. Эта кодовая база в продакшне очень давно, и да, там присутствует классический ASP — код, который старше, чем весь .NET — который по-прежнему используется сегодня в кастинге для фильмов и сериалов. Надо правильно ставить акценты: важны именно эти фильмы и сериалы, а код существует только для того, чтобы решать проблемы. Пока вы его не запустили, код сам по себе ничего не значит. Ценность у него возникает только тогда, когда вы его запускаете, и с его помощью что-то делаете. Вот за что люди платят — за Netflix или DVD. Проблема в том, что об этом очень легко забыть.
В общем, сегодня я хочу, помимо прочего, поделиться с вами моим опытом работы с одной и той же кодовой базой на протяжении многих лет. Я наблюдал, как она эволюционировала, и как другие люди знакомились с ней и учились её использовать. А другая сторона этого уравнения — моя новая работа, позволившая мне увидеть тот же процесс с другой стороны, когда мне самому пришлось знакомиться с чужим кодом.
Но вначале давайте поговорим о том, насколько быстро всё меняется в IT.

Взгляните на самый первый iPhone — сегодня он выглядит совершенно древним и громоздким. А этой модели всего 11 лет, она появилась в 2007 году, и стоила она тогда 800 долларов. Если бы в 2007 году вы купили стиральную машину, гитару или велосипед, сегодня вы по-прежнему могли бы ими пользоваться. А вот первый iPhone уже не работает — даже если вам удастся найти экземпляр с батареей и зарядником, в нём не будет работать все те вещи, которые сделали смартфон таким удивительным устройством.
Вы не сможете открыть карту, поскольку сервера карт больше не существуют. Вы не сможете выйти в Twitter, поскольку последние версии приложения Twitter требуют версии iOS, которую нельзя установить на iPhone 1. Клиент Twitter просто ответит вам: «endpoint not found». В сущности, у вас в руках будет ископаемое. А единственное, что в нём будет работать — это функция обычного телефона, по нему всё ещё можно звонить. Потому что в этой области, в отличие от IT, стандарты за 11 лет не поменялись.
Давайте совершим небольшое путешествие во времени. Помните вот это?
А помните, в каком году это было? «Тату» выступали на «Евровидении» в 2003-м. А я в 2003-м писал ASP-код, который сейчас по-прежнему используется в продакшне.
Нам кажется, что это было очень давно, но этот код всё ещё работает. Производителям мобильных телефонов удалось заставить людей покупать новый телефон каждые два года, поэтому они могут себе позволить избавляться от старых наработок, отключать API, конечные точки, сервисы. Но у многих компаний нет такой возможности, и поэтому они продолжают поддерживать код, написанный, когда «Тату» выступали на «Евровидении». Этот код важен, потому что он по-прежнему выполняет важные функции, он приносит доход — то есть это легаси-код.
И хотя мы все согласны, что легаси существует, остаётся вопрос: что именно является им? Вот пример кода:

Посмотрите, подумайте: это легаси или нет? Как вы считаете?
Я изобрёл устройство, хочу в следующем году продавать. Вы вставляете его в USB-разъём, выделяете кусок кода, и прибор говорит вам, это легаси или нет!

Тот код, который вы только что видели — не легаси. Его написал Андрей Акиньшин (DreamWalker) четыре дня назад. Это взято из BenchmarkDotNet.
В том-то и дело, что нельзя определить, является ли код легаси, просто взглянув на него. Больше того — сам код здесь вообще не при чём. Важно то, что происходит вокруг него: люди, культура, процессы, тесты и так далее.
Если открыть статью «Legacy code» в англоязычной Википедии, то там можно прочитать следующее: «Это исходный код, относящийся к операционной системе или какой-либо иной компьютерной технологии, поддержка или производство которой прекращены». Мы такие: «ну окей». А дальше написано: «Этот термин был впервые использован Джорджем Оливетти применительно к коду, поддержкой которого занимался администратор, сам этот код не писавший».

В конце этого предложения находится ссылка на блог некоего Самюэля Маллена. Мы думаем: «Интересно, посмотрим». Но если мы откроем пост, то увидим, что этот Маллен, в свою очередь, ссылается на Википедию!

И, кажется, больше никому не известно, кем вообще был этот самый Джордж Оливетти. Так что, похоже, нам стоит поискать определение получше.
Одно из самых популярных определений в индустрии дал Майкл Фэзерс: «Легаси — это попросту код без тестов». А Майкл по этому вопросу написал целую книгу, так что он определённо знает, о чём говорит. Но всё же я не до конца согласен с его определением.
Поэтому я уже несколько лет пользуюсь своим определением: «Унаследованный код — это код, который слишком страшен, чтобы его обновлять, но слишком прибылен, чтобы его удалить».

Позже оказалось, что очень похожее определение уже давали независимо от меня: «очень прибыльный код, который мы боимся менять». Мне интересно, откуда берётся этот страх. Что есть такого в тестах, что превращает код без них в легаси?
Один из старейших инструментов бизнеса во всём мире — это система двойной записи бухгалтерского учёта. Ей много сотен лет, и в ней каждая сделка банка или компании учитывается дважды: в одном столбце я записываю, сколько денег я заплатил, а в другом — стоимость, которую я за них получил. При этом суммы обоих столбцов должны быть равны, если же есть расхождение — где-то совершена ошибка.

Мне кажется очень важной основополагающая мысль этого подхода: все решения, которые мы принимаем, оказывают своё влияние дважды, и если вы поменяли что-то одно, то где-либо в другом месте обязательно также произойдут изменения, за которыми нужно следить. Этот двойной подход можно применить к коду и тестам, или к коду и системе мониторинга, или к коду и документации.
Многие системы, которые мы считаем легаси, тоже существуют в двух версиях, но это версии «в коде и в чьей-то голове». И здесь, на мой взгляд, кроется одна из главных наших трудностей.
Вспоминается одностраничный комикс «This is why you shouldn't interrupt a programmer». Разработчик смотрит на простую строчку кода, и в голове тут же начинает думать о том, что нужно теперь переписать в меню навигации, как это повлияет на отладчик, что затем надо будет поменять в коде. Кто-то подходит к нему и спрашивает: «ты получил моё письмо?», и тут же всё это сложное дерево правок вылетает из головы.
Когда мы работаем, мы входим в изменённое состояние сознания, наш мозг строит сложные модели, объясняющие работу кода. Когда код пишет один человек (например, в стартапе или опенсорсном проекте), зачастую, кроме модели в голове и модели в коде, ничего нет. Это позволяет работать очень быстро — вы просто транслируете то, что у вас в голове, в код. Правильной является та модель, которая в голове, так что если в коде что-то не так, достаточно взглянуть на него, сравнить с тем, что в голове, и ошибка сразу будет видна. А когда вы находите баг, зачастую это показывает вам, что вы какой-то аспект недостаточно продумали, и вы обновляете вначале модель в голове, а потом код.
Есть замечательный пост Джессики Керр, где она среди прочего говорит, что изобретение — это как бежать вниз с горы, а анализ — как подниматься в гору. Нам нравится писать код, это интересно и легко: вы начинаете с нуля и изобретаете нечто новое, решаете проблемы, пишете алгоритмы, методы и классы. А вот читать код тяжело — перед вами с самого начала огромный массив чужого кода, и это работа совершенно другого характера.

Поэтому во многих организациях можно наблюдать явление, которое Альберто Брандолини назвал «хозяин подземелья» (dungeon master): это человек, написавший первую версию системы. Я был этим человеком в Spotlight — в одиночку написал значительную часть первой версии, причём написал на классическом ASP, без документации и без юнит-тестов. С этим инструментом стали снимать фильмы, сделали «Звёздные войны», у нас появились деньги и всё было замечательно. Но затем мы начали нанимать новых сотрудников, которые поначалу не могли разобраться, как это всё работает, и в течение двух-трёх месяцев им приходилось знакомиться с системой.
Вскоре начались разговоры о том, что нужно портировать систему на .NET, поскольку классический ASP недостаточно надёжный и недостаточно быстрый. Такие разговоры будут всегда — какой бы код вы ни написали, кто-нибудь обязательно будет настаивать, что его надо переписать. Происходит это потому, что этот человек не понимает ваш код, а новый код писать интереснее, чем вникать в старый. Программирование — такая работа, которая приносит удовольствие, нам она очень нравится. Поэтому вполне естественно, что, будучи представлены перед выбором, мы будем склоняться в пользу того варианта, который более увлекательный.
Хозяин подземелья — это человек, который знает все подводные камни в коде. Он знает про ту кнопку, на которую нельзя нажимать, иначе приложение упадёт; ту самую, на которой висит TODO из 2014 года, до которого ни у кого не дошли руки. Мы в нашей отрасли научились больше не создавать таких систем. Это то, за что я люблю мероприятия вроде DotNext, юзер-группы, сообщества и StackOverflow: когда вы начинаете новый проект, вам обязательно объяснят, что нужно писать тесты, делать specification by example, интеграции, мониторинг. Так что наше будущее — это бессерверные микросервисы на F# со стопроцентным покрытием кода тестами.
Но проблема не в том софте, который нам предстоит написать: в нашем мире уже полно софта. И, если представить этот софт в виде пирамиды, то бессерверный F# будет занимать лишь самую вершину. Чуть больше будет ASP.NET, кое-как покрытого тестами. Ещё больше — Visual Basic на Windows XP. Но самая популярная в истории платформа для разработки коммерческих продуктов — таблицы Excel.

Я готов биться об заклад, что каждый раз, когда вы покупаете билет на самолёт или останавливаетесь в отеле, так или иначе ваше имя оказывается в какой-нибудь таблице Excel. Разработка через тестирование не принимает во внимание этот огромный багаж уже написанного кода.
Но почему нужно настаивать на том, чтобы переписывать старый код? Вначале людям не нравится классический ASP и они хотят переписать всё на .NET. Потом выясняется, что нужно всё переписать на версии 4.5, потом 4.6, потом .NET Core. JQuery никуда не годится, поэтому нужно обязательно перейти на Angular, после чего настанет очередь React, затем Vue.
Я подозреваю, что по меньшей мере одна из причин здесь кроется в погоне за модой. Мы все общаемся друг с другом, и значительная часть самой качественной работы в нашей отрасли сделана потому, что авторам хотелось добиться признания и уважения людей их профессии. Мне кажется, что у нас в отрасли есть чрезмерное пристрастие ко всему новому и глянцевому, и языки программирования подвержены веяниям моды. Но ведь те, на которые мода проходит, сами по себе никак не изменились, все их преимущества остались теми же, что и были.
Представьте, что перед вами лежит два резюме:

Для меня не представляет сомнений, с кем из них мне будет лучше работать над действительно важными проблемами. Но если вы поговорите с людьми из HR, или с теми, кто только что закончил курс программирования, то увидите, что на навыках первого программиста, по их мнению, можно неплохо заработать, а навыки второго они считают устаревшими. Но ведь они вовсе не устарели — по-прежнему существует много проблем, над которыми этот человек может работать.
Я думаю, одна из причин такого отношения в том, что людям страшно. Некоторые из моих коллег ушли из нашей команды потому, что они хотели работать на Angular или на NodeJS. Когда я спросил их, зачем им это нужно, они ответили, что если они будут продолжать работать только на .NET, то через два года не смогут найти работу. Я отвечаю им: ребята, мы со своим .NET только что помогли сделать «Звёздные войны»! А они говорят: да, но это всё равно не Angular.
Поймите меня правильно, я уважаю их решение. Здесь не может быть речи о какой-либо продажности, просто люди беспокоятся о своём будущем и будущем своей семьи в случае, если придётся искать работу. А в нашей отрасли этот вопрос безопасности обычно интерпретируется в том ключе, что нужно каждые полтора года всё изучать заново с нуля, иначе потеряешь конкурентоспособность. Очень часто нас значительно больше интересует технология сама по себе, чем наша способность решать проблемы.
Помимо страха отстать и устареть здесь, на мой взгляд, большую роль играет страх менять систему, которую ты не понимаешь. Вам дают код, о котором вы ничего не знаете, но если в нём что-то сломается, это будет на вашей ответственности, и если он упадёт посреди ночи, будить будут вас. Отсюда возникает страх.

Как мы знаем из тех же «Звёздных войн», страх ведёт к злости, злость ведёт к ненависти, ненависть ведёт к страданиям, страдания ведут к JavaScript. Как нам работать со своим страхом и со страхом наших коллег? На мой взгляд, здесь три основных аспекта: понимание, доверие и контроль.
Доверие — одновременно самое простое и самое сложное из этих трёх. Я доверяю этому ноутбуку, потому что он ещё ни разу не крэшнулся во время презентации. Как только это произойдёт, моё доверие к нему исчезнет. В английском языке есть поговорка «доверие завоёвывают по каплям, а теряют вёдрами». После месяца работы с человеком вы будете готовы признать, что он, возможно, разбирается в своём деле, через два вы скажете, что он разбирается неплохо, через три вы согласитесь, что он знает своё дело очень хорошо. А через три месяца и один день в его коде обнаружится уязвимость к SQL-инъекциям, и вы скажете «А, я всегда говорил, что от него никакого толка».
Доверять другим людям всегда тяжело, поскольку это всегда значит отказываться от какой-то степени контроля. Доверие к коду — тоже важная тема. После того, как вы поработали с системой определённое время, вам хочется верить, что она будет работать в соответствии с вашими ожиданиями. Ваши операционные системы стабильные и надёжные, и вы надеетесь, что они не упадут. Вы доверяете базам данных вашу информацию и ожидаете, что они её не потеряют. Вы рассчитываете, что провайдеры облака обеспечат постоянную работу вашего сайта и не продадут информацию ваших клиентов на чёрном рынке.
Нет быстрого способа добиться доверия. Правда, доверие транзитивно: если я доверяю вам, а вы доверяете кому-то другому, то, скорее всего, я этому человеку тоже могу доверять. Если я прислушиваюсь к вашему мнению, а вы считаете, что можно доверять Amazon, AWS, Azure или Google App Engine, то я буду готов поверить, что это хорошие сервисы. Но быстрого способа добиться доверия нет.
Давайте перейдём к пониманию. В университете я три года изучал computer science. Если бы принципу, лежащему в основе нашего образования, следовали инженеры-строители, то на первом курсе они строили бы деревянные сараи, на втором — металлические, а на третьем, продвинутом — стеклянные.

Мы на первом курсе писали маленькие программы на Lisp, на втором — маленькие программы на Java, на третьем — маленькие программы на Scheme и Prolog. Больших программ мы не писали, и, что ещё более важно, не пытались в них разобраться.
Но инженеров-строителей не учат на примере сараев, их заставляют разбираться в небоскрёбах, мостах, филармониях и зданиях вроде того, в котором мы с вами находимся сейчас. Эти студенты учатся на примере самых крупных и впечатляющих проектов своей отрасли. А если бы они учились по тому же принципу, по которому преподают computer science, то студенту, столкнувшись с реальным заказом на небоскрёб, не пришло бы в голову ничего, кроме как ставить друг на друга сараи, пока не получатся башни Петронас.

Именно в таком положении оказывается студент, закончивший курс computer science, и получивший задание написать распределённую коммерческую систему закупок. Значительная часть существующего сейчас софта примерно так и была написана. Люди, которые его писали, были не безответственными, а просто неопытными. У них очень хорошо получалось всё, что они делали в университете, и это создавало ложную уверенность в себе. Именно таким в своё время был я, и, я уверен, такими же в своё время были многие из вас. Мы действовали так: напишем веб-страницу, сделаем ссылку на ещё одну страницу, потом ещё одну, скопируем код и все будут рады — у клиентов продукт, у компании деньги, у нас премия. А через пять лет смотришь на этот кошмар и думаешь: как можно было такое написать?
Проблема отчасти в умении изучать софт. Инженеры-строители хорошо умеют изучать здания, авиаинженеры хорошо умеют изучать самолёты. Возьмём литературу: в «Войне и мире» может быть 45 тысяч строк (в зависимости от издания). Это одна из самых больших книг в мире, она требует очень серьёзного изучения со стороны людей, которые занимаются литературоведением. Другими словами, изучение такого крупного объекта — это работа. Размер самой длинной пьесы Шекспира, «Гамлета» — 6 тысяч строк. А теперь подумайте: ядро Linux в три раза длиннее «Войны и мира». Причём речь идёт о весьма компактном коде, хорошо организованном, с обширной документацией и многочисленным сообществом. И тем не менее разобраться в нём аналогично тому, чтобы трижды разобраться в «Войне и мире».

Посмотрите на этот график, на котором показано количество строк в книгах «Гамлет», «Моби Дик», «Братья Карамазовы», «Властелин Колец», «Атлант расправил плечи» и «Война и мир», а также в ядрах Linux и Mono.
Кажется ли вам это соотношение реалистичным? Прошу простить за то, что ввёл вас в заблуждение. Этот график на самом деле экспоненциальный.
А линейный график на следующем слайде:

Мысль здесь очень простая: софт огромен, просто сесть и прочитать его невозможно. Попросить кого-то познакомиться с ядром Linux аналогично тому, чтобы попросить человека прочитать «Войну и Мир», «Атлант расправил плечи», «Властелина колец» и всех «Гарри Поттеров» подряд. Представьте, что вы пришли в новую компанию, и вам с порога говорят, что надо изучить все эти книги, и только тогда вас допустят к коду. Конечно же, так не делают.
Чтение кода бывает очень полезным занятием — вы можете понять, как работают некоторые паттерны, изучить некоторые примеры. Но вы не сможете разобраться в крупной системе, если будете читать её так, как вы читаете книгу. Быть может, в этом подходе и есть что-то благородное, но он ни к чему не приводит, как мне кажется. Кода слишком много, а написан он хуже, чем эти книги.
Если просто читать код неэффективно, то как правильно его изучать? Вспомним Ричарда Фейнмана, нобелевского лауреата по физике. Для него огромную важность имел вопрос преподавания науки. Он считал, что нужно учить людей не науке, а тому, как правильно заниматься наукой. Его пригласили в университет Сан-Паулу в Бразилии, потому что в Бразилии студенты получали очень высокие оценки, но при этом наладить наукоёмкое производство никак не получалось. Фейнмана попросили помочь разобраться, в чём проблема.
В течение нескольких лет он каждый год приезжал в Бразилию на несколько недель, и общался со студентами. Он увидел, что бразильские студенты прекрасно знали, например, название феномена, возникающего при приложении давления к кристаллическому телу — триболюминесценция. Но никто из них не знал, что если дома в тёмном помещении раздавить кусок сахара плоскогубцами, то увидишь, как проскочат искры — а ведь это и есть триболюминесценция. Фейнман объяснил, что студентов только натаскивали по учебникам на сдачу экзаменов, но при этом они не ставили никаких экспериментов.
На мой взгляд, здесь содержится важный урок и для нашей отрасли. Чтение кода аналогично чтению учебника для экзамена, а нам нужно ставить эксперименты. Для этого давайте обратимся к основам научного метода, который лёг в основу современной физики, химии, медицины и так далее. Предположим, вы изучаете некоторый код.
Первый шаг — это наблюдение. Попытайтесь запустить систему, которую вы анализируете, и понаблюдать, как она себя будет вести.
Следующий шаг — формирование гипотезы. Вы предполагаете, что если внести некоторое изменение в код, то это вызовет определённые последствия. Например, если добавить индекс к некоторой таблице, то некоторая веб-страница будет отображаться быстрее.
Далее на основе гипотезы вы формулируете предсказание. Чтобы его проверить, вы ставите эксперимент. Результаты этого эксперимента вы анализируете. А затем сообщаете их своей команде или, если это опенсорсный проект, сообществу.
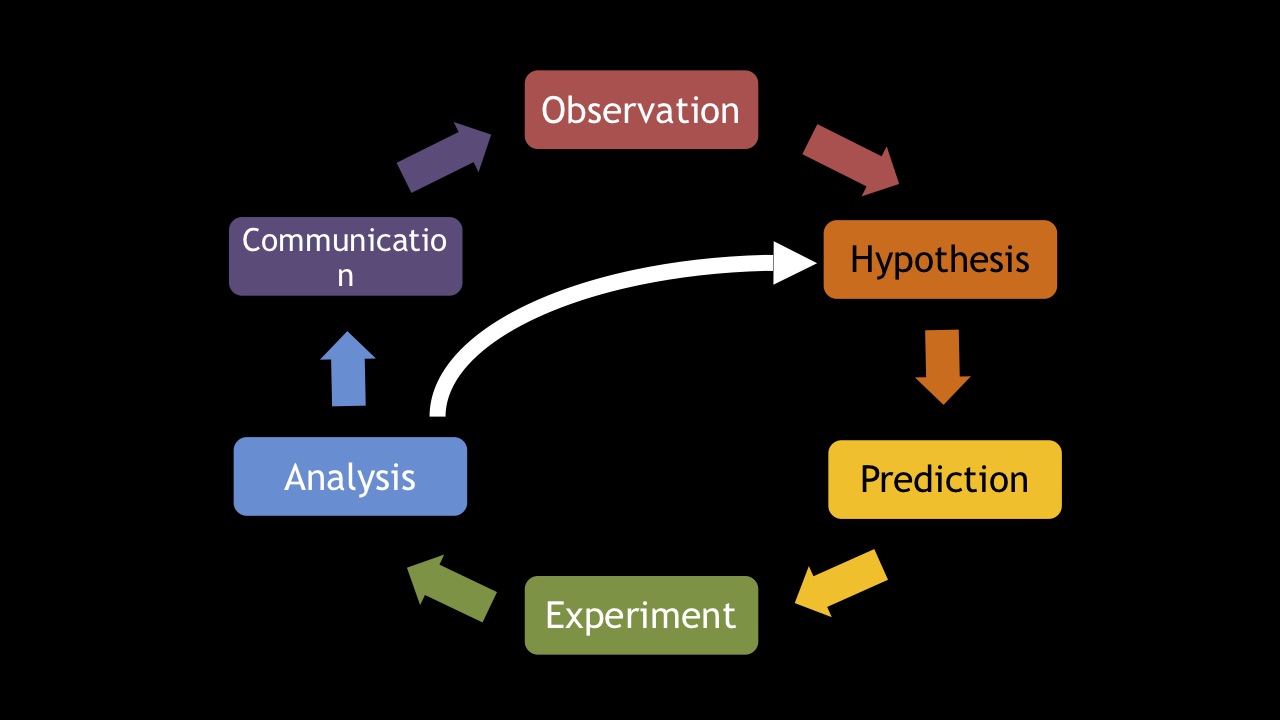
Очень часто в результате анализа вы понимаете, что ваша гипотеза была неверна — например, причиной медленного отображения страницы был не индекс базы данных, а сеть. Возможно, если перенастроить сеть так, чтобы между веб-сервером и сервером базы данных не было файерволла, всё будет работать быстрее? С новой гипотезой вы формулируете новое предсказание и ставите новый эксперимент.
Проблема таких экспериментов с легаси-кодом заключается в том, что в начале процесса вы действуете почти вслепую, поэтому легко можете что-то поломать. Эксперименты на работающих системах всегда сопряжены с риском.

Я как-то раз случайно заменил целый работающий сайт на одну страницу с надписью «I love LAMP», потому что думал, что у меня есть предохранитель при развёртывании, а он не сработал. Но закончилось всё хорошо — ошибка была настолько несуразной, что на нас никто не подумал, пользователи сочли, что проблема на их стороне. Мораль проста: если вы сломали систему, то чем масштабнее, тем лучше, тогда на вас не подумают.
Чтобы избежать такого рода происшествий, нам необходима безопасная среда, песочница, в которой можно будет ставить наши эксперименты. Для начала нужно убедиться, что у вас есть исходный код. Зачастую компании просят вас разобраться в системе, для которой есть только DLL. Это всё равно что приготовить пиццу по рецепту, выбросить его, а потом потребовать от человека приготовить точно такую же. Правда, даже из этой ситуации есть выход — можно провести декомпиляцию, или анализировать вызовы в модули. И всё же дальше я предполагаю, что у вас есть исходный код, в противном случае — мои соболезнования.
Следующий вопрос — можете ли вы собрать этот код? Компилируется ли он? Иногда код можно собрать только на билд-сервере, «мы просто что-то меняем и отправляем туда». Такую ситуацию надо исправить, нужно добиться, чтобы код можно было собрать локально. Затем собранный код необходимо запустить, и посмотреть, где он упадёт. На коде в продакшне можно ставить очень интересные наблюдения, если запустить его, выключив Wi-Fi. Без Wi-Fi ничего страшного, скорее всего, не произойдёт, потому что вы не общаетесь ни с какими внешними зависимостями. Дальше вы начинаете изучать ошибки: например, система упала, потому что не смогла найти базу данных — тогда как мне запустить её с базой данных? И так далее.
Во многих старых системах вы не найдёте файла конфигурации, в коде напрямую будет прописано, к чему системе обращаться. У меня были случаи, когда я просто копировал файл хоста и менял в нём все внешние зависимости, так, чтобы они указывали на мою машину.
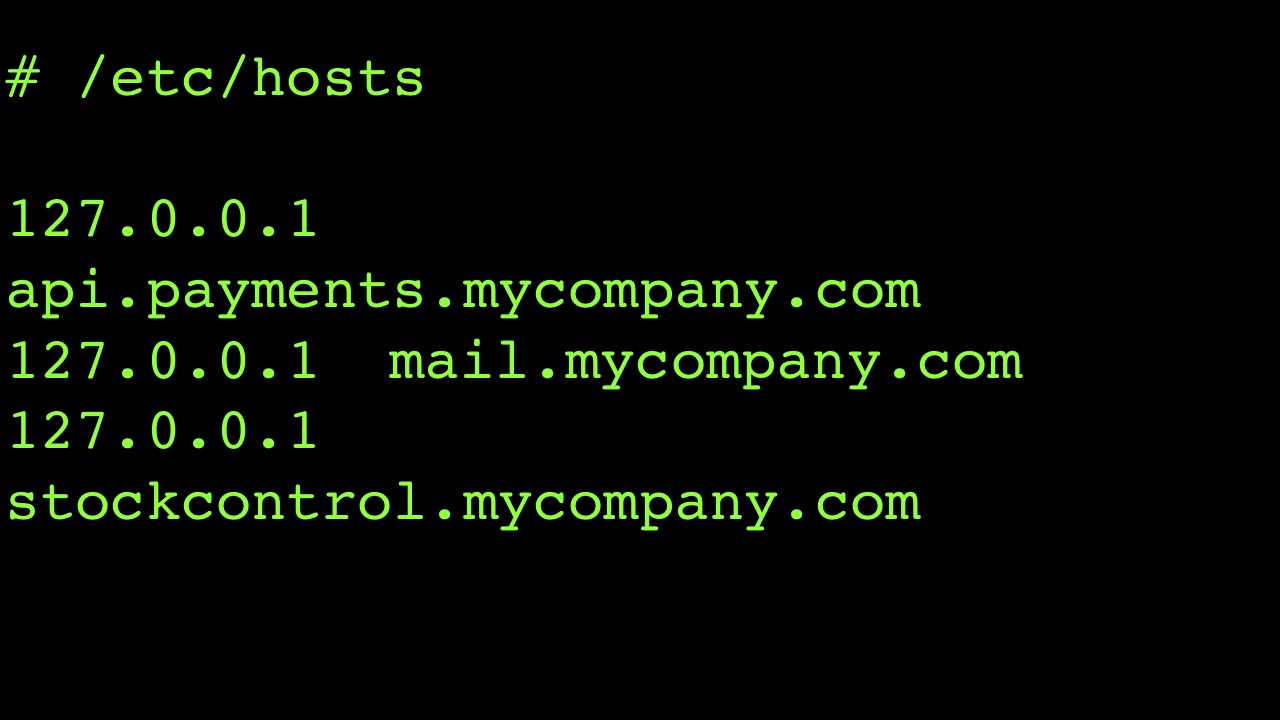
Это позволяло мне наблюдать все сетевые взаимодействия, чтобы затем создавать стабы. Например, я вижу, что нечто из моего DLL обращается к api.payments.mycompany.com. Я не могу ничего поменять в самом DLL, но я контролирую среду, в которой работает софт, переменные, то, к чему этот DLL подключается, входящий и исходящий трафик. И в этом заключается первый шаг: вам нужно добиться контроля над кодом.
Когда это сделано, можно начинать думать о втором шаге: как вносить изменения в код, а затем переносить их из безопасной песочницы в продакшн. Этот процесс может быть крайне сложным. Есть компании, у которых цикл развёртывания составляет три месяца: вы вносите некоторое изменение, другая команда копирует этот код в свой репозиторий и так далее.
Это слишком долго. Я отношусь с пониманием, если так работает фармацевтическая компания или центр управления воздушным движением, потому что они своими ошибками могут меня убить. Но большинство из нас в таких организациях не работает, и нам нужно добиться, чтобы изменения попадали в продакшн как можно быстрее. Здесь проще всего начать с невидимых изменений: например, добавить невидимый комментарий на главную страницу вашего сайта, и посмотреть, насколько быстро он попадёт в продакшн. Вы сможете найти все точки этого процесса, где вам необходимо что-либо делать руками, и автоматизировать их. Постепенно улучшайте этот процесс.
Мы опробовали этот подход в Spotlight, когда с классического ASP на наших серверах мы решили перейти на Amazon Web Services. Нам потребовалось два года, чтобы процесс развёртывания кода с GitHub в продакшне стал выполняться без каких-либо ручных «сдержек и противовесов». Зачастую у людей опускаются руки после двух дней, и они возвращаются к прежней системе, поэтому нужно здраво оценивать количество труда, необходимое, чтобы добиться автоматизации.
Интересная особенность легаси-систем в том, что зачастую чем они старше, тем лучше их поддержка. В Windows 2016 года достаточно поставить один флаг, чтобы включить поддержку классического ASP, который перестали поддерживать в 2003 году.

Иначе говоря, код, который я написал, когда «Тату» выступали на Евровидении, будет работать «из коробки» на Windows 2016 без флагов компилятора, зависимостей или изменений. А вот код на ASP.NET MVC 2 так не заработает, поскольку это был передовой на тот момент продукт, который очень быстро перешёл на версию 3, а затем 4. DLL, которые нужны, чтобы собрать проекты на ASP.NET MVC 2, по-прежнему лежат где-то на microsoft.com, но в тех проектах, которые есть у нас, не используется Nuget для зависимостей, потому что они были написаны до его появления. Они ищут зависимости в Program Files. Мы пару недель пытались запустить код на ASP.NET MVC 2, пока не поняли, в чём же дело.
Проблема в том, что знания о надёжных и долговечных системах распространены хуже всего. Понять, почему это так, можно на примере стоп-сигнала в машине. Если вы водите, задайте себе вопрос: знаете ли вы, как устроен обычный стоп-сигнал?

А теперь взгляните на фото: знает ли человек, который сделал вот это устройство, как устроен стоп-сигнал?

Я думаю, он хорошо разбирается в том, как работает эта система, потому что она у него постоянно ломается, и ему приходится заниматься её поддержкой. В этом примере именно исправный стоп-сигнал — легаси-система, потому что её оператор не знает, как она устроена. А собранный на коленке выключатель — активно поддерживаемая система. Сами посмотрите, её поддерживает изолента!
Поэтому всегда возникают большие трудности, когда в системе, годами исправно работавшей, вдруг оказывается нужно что-то поменять — никто уже не знает, как она функционирует.
В нашей компании был прекрасный пример такой ситуации с системой, которая при размещении актёрских вакансий генерировала персонализированные уведомления для подходящих кандидатов. Поначалу у нас было 50 000 потенциальных адресатов, и система каждый раз искала среди них подходящих и отправляла уведомления. Позже количество возможных адресатов росло — 100 000, 200 000… В общем, спустя четыре с половиной года у нас произошло переполнение Int32. Поняли мы, что произошло, только когда кто-то заметил id в два миллиарда с чем-то. Здесь интересно, что база данных-то поддерживала такие числа, но вот в коде, отправлявшем сообщения, использовался int, и у него происходило переполнение.
У каждого из нас есть стеки, в которых кроются такого рода проблемы, и они никого не беспокоят только потому, что пока не дали сбоя. Одно из самых мощных средств для борьбы с этим положением вещей — создание наглядности. Разберитесь, что в функционировании компонентов вашей системы наиболее важно, и сделайте так, чтобы это видели.

Для этого можно проводить измерения, использовать панели мониторинга, следить за производительностью вашей базы данных и так далее. Взгляните на то, какие идентичности используются в вашей базе данных, 32 у них бита или 64, и насколько они далеки от переполнения. Посмотрите, сколько у вас осталось места на жёстком диске, хватает ли вам ресурсов и как используется сеть. Все эти показатели должны быть на виду. Если вы ответственны за огромную систему, в которой невозможно разобраться, просто прочитав её, вам необходимо как можно больше точек обзора. Запустите систему в песочнице, сделайте мониторы для продакшна, обеспечьте видимость в пайплайне развёртывания. Вам нужно видеть всё, что делает ваша система, чтобы понять, как она устроена.
Одна из причин возникновения всех этих трудностей заключается в том, что в 80-е и 90-е, когда создавались многие из этих легаси-систем, мы активно убеждали всех остальных людей в том, что раз и навсегда решим все их проблемы. Сотрудники из отделов продаж и консультанты создавали у людей впечатление, что можно всё автоматизировать и уволить всех сотрудников. Мы продавали идею того, что продукт можно завершить.

Но на самом деле продукт никогда не бывает завершён. Только недавно мы стали понимать, что разработка софта — это долгосрочное вложение усилий, софт требует постоянной поддержки. Точно так же здание вашего офиса нужно не только построить, но и обеспечить постоянную работу санузла, электричества, его нужно всё время чистить и мыть, менять лампочки и так далее. Мы в своё время не потрудились объяснить, что софту необходима постоянная поддержка на протяжении всего времени его функционирования.
При этом мы часто продавали системы, которые реализовали лишь один режим функционирования бизнеса. Когда люди делают работу привычным образом, то есть вручную, они обладают значительной степенью гибкости. Если постоялец отеля говорит, что у него аллергия на грибы, сотрудник просто запишет эту информацию на бумажке и отправит её на кухню. А когда вместо живого человека постоялец общается системой автоматической регистрации, у него нет возможности сообщить ей о своей проблеме — специальной кнопки «не подавать грибы» в системе нет. Постоялец в конечном итоге обратится к администрации, а там выясняется, что нужно сделать запрос на изменение, который будет стоить пять тысяч долларов. Тогда в администрации думают: «Может, постоялец один раз всё-таки может покушать грибы?»
Альтернатива системе, приспособленной к выполнению своей функции одним-единственным образом — система, в которой все компоненты гибкие и настраиваемые. Когда пытаешься сделать такую, обычно она становится настолько большой, что никогда не оказывается выпущена. И тот, и другой подход далеки от идеала; нам не нужны абсолютно гибкие системы, и нам не нужны однозадачные системы — нам необходимо постоянное взаимодействие с системой, благодаря которому код не станет легаси. Добиться этой цели очень непросто. Вам всё время необходимо иметь дело то с акционерами, то с владельцами продукта, а им вместо поддержки всегда нужны новые фичи. И тем не менее, обеспечивать постоянное взаимодействие с системой необходимо.

По моему опыту, проще всего добиться от собственников продукта времени на работу с системой следующим образом. Предположим, вы говорите, что вам нужно четыре недели. В течение этого времени вы не сделаете никаких новых фич для клиентов и не обеспечите непосредственного дохода, и тем не менее это время потратить необходимо. А потом на каждом обсуждении у вас должен быть готов анализ технического долга, от которого вам удалось избавиться за эти четыре недели. Так что если вас спрашивают, сколько времени уйдёт на то, чтобы увеличить количество клиентов, с которыми может работать система, вы отвечаете — вообще говоря, 12 недель, но благодаря тому рефакторингу, который мы провели, это займёт только 3 недели.
При таком подходе собственники продукта начинают понимать, что рефакторинг жизненно необходим, это не просто развлечение для гиков, как они поначалу считали. Они сделали вложение в вас, позволив вам четыре недели заниматься непонятными для них вещами. Вы должны вернуть это вложение, объяснив, что наш софт теперь стал лучше и наращивать его возможности теперь значительно проще.
Наконец, давайте ответим на вопрос — какой проект можно считать завершённым? Что является нашим «definition of done»?
Проект, код которого удалён, репозитории на GitHub заархивированы, база данных отключена, серверы больше не работают, а команда сидит на пляже и пьёт пиво.

Очень часто в коде вашей организации будут большие куски, в которых уже нет никакой потребности. Они существуют только потому, что от них боятся избавиться. Благодаря инструментам вроде Google Analytics вы теперь знаете, что на вашем сайте есть страница, на которую никто никогда не заходил. Такая страница точно есть у нас. Эти страницы по-прежнему существуют, потому что никто не прошёл по ним и не удалил всё ненужное. Просто софт делает это «невидимым», мы не видим всех этих ненужных вещей, и поэтому не обращаем на них внимания. Но со временем они дают о себе знать — код становится всё более объемным, развёртывание происходит медленнее. Количество мест, в которых у вас может быть уязвимость в JavaScript, прямо пропорционально размеру запускаемого кода. Поэтому вам нужно подумать о том, как удалить весь этот лишний код.
Когда мы создаём проект, у нас обычно есть метрики, которым мы стараемся соответствовать — продолжительность цикла развёртывания, производительность и так далее. Мне всегда было интересно попробовать сделать ограничение по количеству строк в проекте — скажем, не больше 20 тысяч. И если вам нужна новая фича — надо решить, от какой фичи мы должны избавиться.
Такой подход вполне успешно применяется в самолётостроении: при проектировании самолёта мы заранее знаем вес, который нам нельзя превышать. В строительстве мы заранее знаем размеры, больше которых здание быть не может. Люди прекрасно умеют работать с такого рода жёсткими ограничениями на размер проекта в других инженерных отраслях, но при разработке софта размер считается произвольным. В нашем распоряжении терабайтные жёсткие диски и столько места на GitHub, сколько нужно. Но из-за этого отсутствия ограничений накапливается код, который уже не производит никакой стоимости. И в этом моя третья мысль: когда вы уже разобрались в коде, не бойтесь начать его чистить и удалять ненужные сегменты.
Наш мир работает на легаси-коде. Я уверен, что среди вас множество людей, которые пишут потрясающие новые прогрессивные системы, но я также уверен, что среди вас полно тех, кто занимается, например, интеграцией с банковскими системами на COBOL. В зале никто не имел дела с MUMPS? Ах, счастливчики. Это худший в мире язык программирования, он был создан в 1960-е годы, до сих пор используется в 26 крупнейших госпиталях в США. Если хотите много заработать программистом в США — учите его. Он ужасен, его знание очень высоко оплачивается, и здоровье миллионов людей в США по-прежнему зависит от такого рода софта.
Легаси-код очень важен, и нельзя просто «добавить юнит-тесты» или «заменить на микросервисы». Нам нужно научиться разбираться в унаследованном коде и становиться его владельцами.

И отсюда название моего доклада: нам надо научиться контролировать (control), изменять (alter) и удалять (delete) легаси-код.
Спасибо за внимание.
Если вы дотнетчик, обратите внимание: следующий DotNext состоится 15-16 мая в Петербурге. Там будет много конкретики по .NET-разработке (для примера можете посмотреть топ-10 предыдущей конференции), и некоторые спикеры уже известны — например, Джон Гэллоуэй из .NET Foundation. Увидеть всю актуальную информацию можно на сайте конференции, приобрести билеты там же — и со временем они дорожают.
