
Введение
В недавней статье наш боевой товарищ actopolus рассказал о том, как мы научились применять Postman для реализации функционального тестирования нашего API проекта. Научившись писать функциональные тесты, и написав их порядка полутора сотен, мы решили, что настало то самое время — время прикрутить эти тесты к нашим CI-сборочкам.
Вообще, изначально процесс интеграции Postman-тестов в сборки можно было разбить на 3 простых этапа:
- Формирование production-ready коллекции тестов для Postman
- Подготовка docker-образа среды для запуска тестов
- Написание тасков для того, чтобы собрать всё воедино и запускать на агентах
Однако, нами не был учтён один очень важный нюанс — у нас не было инструмента для измерения покрытия нашего кода Postman-тестами. Без информации о том, насколько хорошо мы покрываем тестами код, нам было сложно понять где мы находимся сейчас и к чему нам нужно стремиться. Следовательно, план был дополнен ещё одним пунктом:
- Написание тасков для того, чтобы собрать всё воедино и запускать на агентах.
1. Коллекция тестов
Итак, приступим к самому процессу. С первым пунктом наша команда справилась героически быстро, тем более, что production-ready версия не так уж сильно отличалась от dev, в том смысле, что качество тестов, которое мы писали в Postman для «пробы пера» оказалось достаточно высоким. О том, как правильно писать Postman-тесты и что к чему, уже рассказывал actopolus в своей статье Введение в Postman. Каким же образом запустить Postman из консоли? Ответ прост — никак. Но, к счастью, есть специальная консольная утилита, которая умеет почти всё тоже самое, что и Postman, и имя ей… Newman!
Именно благодаря Newman мы и будем проводить интеграцию Postman-тестов в CI.
2. Docker
Тем временем я принялся за докер образ. Сначала был собран собственный образ на базе alpine, на котором были проведены первичные запуски. После чего я обнаружил, что в недрах докер-хаба таки есть уже готовый образ с Newman, собранный на все том же alpine, но более легковесный. Казалось, задача свелась лишь к тому, чтобы слить уже существующий образ с докер-хаба в наш локальный хаб, однако, выяснилось, что он не подходит нам в чистом виде из-за несоответствия стандартам, принятым внутри компании. Поэтому пришлось всё же собрать свой образ. Для этого прежде всего мы сменили базовый образ на наш alpine который используется у нас во всех образах подобного рода. Следующим шагом мы выпилили все неиспользуемые компоненты и сменили точку входа таким образом, чтобы нам было достаточно передать образу только параметры для newman, не передавая всю строку запуска. Именно так и получился образ, который нас устроил по всем параметрам и попал в наш докер-хаб.
3. Кочергатор для измерения покрытия
После неудачных попыток родить ежа прикрутить к newman-тестам библиотеку c3 от codeception, я решил, что пожалуй быстрее будет изобрести велосипед написать свою библиотеку для сбора покрытия тестов newman (согласен, звучит очень по-профански).
Почему я решил изобрести велосипед:
- Простота использования. Если вам необходимо родить пару ежей против шерсти для того, чтобы подключить измерение покрытия кода тестами в вашем приложении, вероятнее всего с реализацией что-то не так. Наша библиотека подключается 1ой строкой.
- Так как у нас не один, а множество проектов, мы можем учесть все их особенности в библиотеке, что в последствие позволит легко её использовать.
- Мы сами гарантируем поддержку работоспособности библиотеки. Она не исчезнет никуда через полгода и мы всегда сможем перенести её на новую версию php.
«Чего тянуть кота за яйца?» — подумал я и решил начать писать кочергатор для измерения покрытия, тем более, что большая часть работы (пожалуй все 90%) для такой цели уже реализована в библиотеке php-code-coverage, использующей в своей основе xDebug. Осталось лишь немного переложить её на свой лад.
Итак, наш кочергатор будет состоять из 2х частей. Первая будет отвечать за сбор и подготовку отчетов о запущенных во время прохождения теста файлах и строках, вторая будет представлять из себя CLI-приложение, которое будет собирать все отчеты воедино и форматировать в указанный формат.
Как это работает в библиотеке SebastianBerghmann?
По сути, php-codecoverage это надстройка над парой драйверов на выбор (phpdbg, xDebug). Суть проста, вы инициализируете скрипт на сбор информации о выполняемых (и не выполняемых) строках, и на выходе получаете массив с этими данными. Библиотека php-codecoverage создана для того, чтобы из этих массивов делать сексуальные отчеты в форматах xml, html, json и text. Она также разделена на 2 части, и также одна часть занимается сбором информации, а вторая форматированием.
Что делает наш велосипед?
- Подключается одной строкой
$coverage = new Coverage(); - Имеет дефолтную конфигурацию
- Начинает слушать тогда и только тогда, когда встречает в заголовке запроса определенный флаг.
- Складывает все отчеты туда, куда мы ему скажем.
- CLI — умеет не только собирать отчеты, но и чистить за собой.
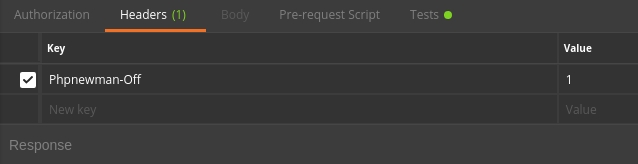
Для того, чтобы всё это богатство заработало, нам пришлось добавить в наши тесты заголовок-маркер.
Выглядеть это стало вот так:
«Скомпилированные» отчёты позволяют посмотреть в каком тесте запускаются те или иные строки кода и выглядят следующим образом:

Так выглядит экран с покрытием кода

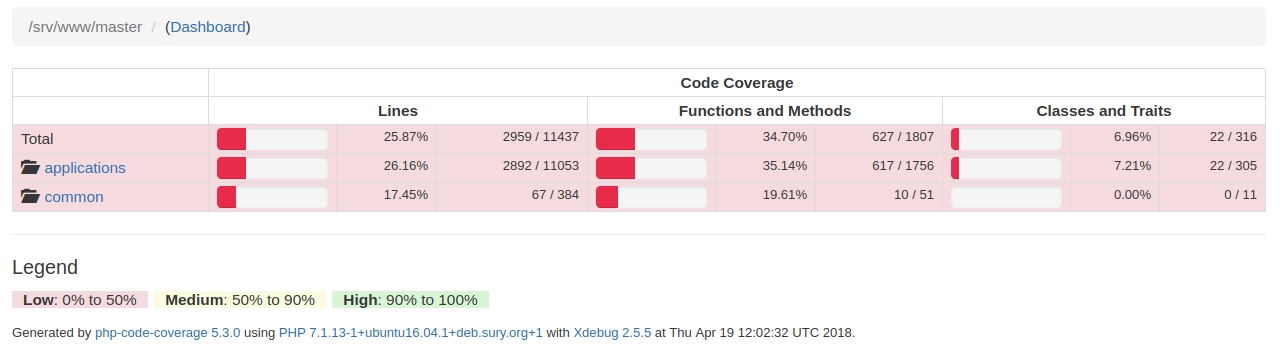
Так выглядит покрытие кода по папкам
Отчёты генерируются утилитой, которая входит в состав пакета php-code-coverage.
Если уважаемому читателю будет интересно, то мы расскажем про то, как работает этот кочергатор в отдельной небольшой статье.
Итак с пунктом 3 мы тоже разобрались. Остался не менее интересный пункт… 4ый
Пункт 4ый, драматический
Для того чтобы реализовать нормальное функциональное тестирование проекта и оценку покрытия давайте посмотрим на схему того, как же оно все-таки работает.
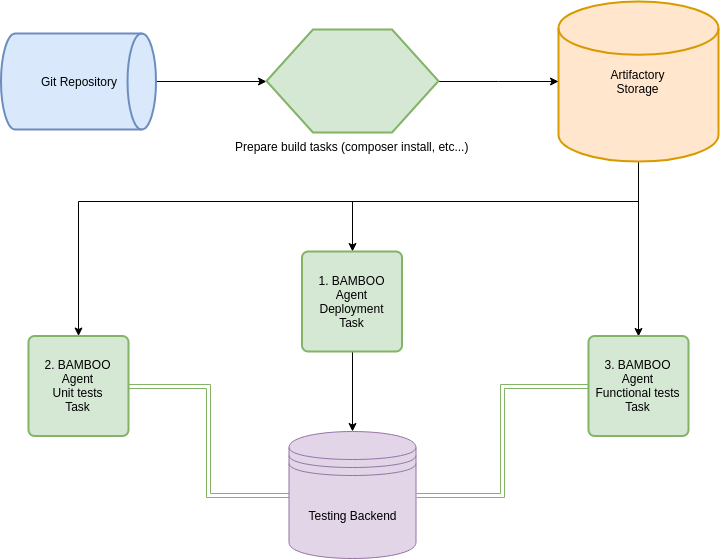
1. Итак, сначала кодовая база сливается из GIT-репозитория на агент BAMBOO и далее на нем происходит сборка проекта.
В нашем случае собирается composer и происходит обработка файлов конфигурации под Development окружение. Именно на этом этапе мы подменяем в наших тестах значение заголовка PHPNEMWMAN_OFF на PHPNEWMAN_ON (это потому, что билд-план призван замерять покрытие, однако не стоит это делать в билд-плане, который своей целью ставит именно сборку проекта, т.к. измерение покрытия значительно замедляет процесс сборки).
sed -i -e "s/Phpnewman-Off/Phpnewman-On/" ./code/newman/collection.json2. Следующим шагом собранный проект выливается в хранилище артефактов. Делается это для того, чтобы не собирать его каждый раз, для каждого отдельного таска.
3. После того как собранный проект благополучно слит в артефактори, следующий таск также благополучно его оттуда сливает и выгружает на тестовый бэкенд.
4. Следующий таск также сливает проект из артефактори и запускает на нем newman-тесты. Нужно сразу отметить, что ходить эти тесты будут не на localhost bamboo-агента, а на тестовый бэкенд, куда мы вылили проект шагом ранее. Тесты запускаются в докер-контейнере.
Запустить тесты в докер-контейнере можно достаточно просто:
docker pull docker-hub-utils.kolesa:5000/build/nodejs/newman:latest
#Скачиваем образ из репозитория
docker run \ #запускаем контейнер
--rm \ #удаляем контейнер сразу после остановки
--volume $(pwd):/code \ #монтируем корень агента в папку /code в контейнере
--volume /etc/passwd:/etc/passwd:ro \ #монтируем passwd
--volume /etc/group:/etc/group:ro \#монтируем group
--user $(id -u):$(id -g) \ #устанавливаем пользователя и группу, от имени которой действуем в контейнере
--interactive \ #режим запуска - интерактивный
docker-hub-utils.kolesa-team.org:5000/build/nodejs/newman:latest \
run collection.json --folder Tests -r junit,html --reporter-junit-export _out/newman-report.xml --reporter-html-export _out/newman-report.html -e _envs/qa.json -xСтроку запуска newman разберем отдельно:
run collection.json #Запустить тесты из файла collection.json
--folder Tests #Директория в json-объекте(collection.json) где лежат тесты
-r junit,html #Отчеты о прохождении (не покрытие!) тестов готовим в 2х форматах
--reporter-junit-export _out/newman-report.xml #указываем явно, куда сложить отчет
--reporter-html-export _out/newman-report.html #указываем явно, куда сложить отчет
-e _envs/qa.json #указываем json с переменными окружения
-x #возвращать exit-code основываясь на результате прохождения тестов
После этих манипуляций на нашем тестовом бэкенде сформируется коллекция COV-отчётов, совпадающая численно с количеством запросов к бэкенду.
Осталось всего-ничего собрать все эти cov-отчеты в один большой жирный отчет.
Для простоты понимания в скрипте ниже будем использовать `SCP`.
Итак, сбор отчетов происходит следующим образом:
BRANCH_NAME=$(echo "${bamboo.currentBranch}" | sed 's|/|-|g' | sed 's@\(.*\)@\L\1@')
#кладём имя ветки из бамбу в переменную окружения
echo "BRANCH NAME IS $BRANCH_NAME"
#пишем имя ветки в логи
ssh www-data@testing.backend.dev "php /srv/www/$BRANCH_NAME/vendor/wallend/newman-php-coverager/phpnewman --collect-reports merge /srv/www/$BRANCH_NAME/phpnewman --clover /srv/www/$BRANCH_NAME/newman/_output/clover.xml --html /srv/www/$BRANCH_NAME/newman/_output/html"
#запускаем сборку отчётов на удалённом бэкенде
scp www-data@testing.backend.dev:/srv/www/$BRANCH_NAME/newman/_output/clover.xml ./clover.xml
scp -r www-data@testing.backend.dev:/srv/www/$BRANCH_NAME/newman/_output/html ./
# сливаем готовые отчёты на агент
ssh www-data@testing.backend.dev "rm -r /srv/www/$BRANCH_NAME/newman/_output/html && rm /srv/www/$BRANCH_NAME/phpnewman/* && rm /srv/www/$BRANCH_NAME/newman/_output/clover.xml"
#чистим за собой на бэкенде
Для того, чтобы в сборке были доступны ваши отчёты, необходимо расшарить артефакты с этими отчётами:

далее мы можем использовать эти артефакты для автоматического парсинга и дальнейшей визуализации покрытия кода в нашей сборочке. Для этого достаточно поставить галочку и указать файл с xml-отчётом покрытия.
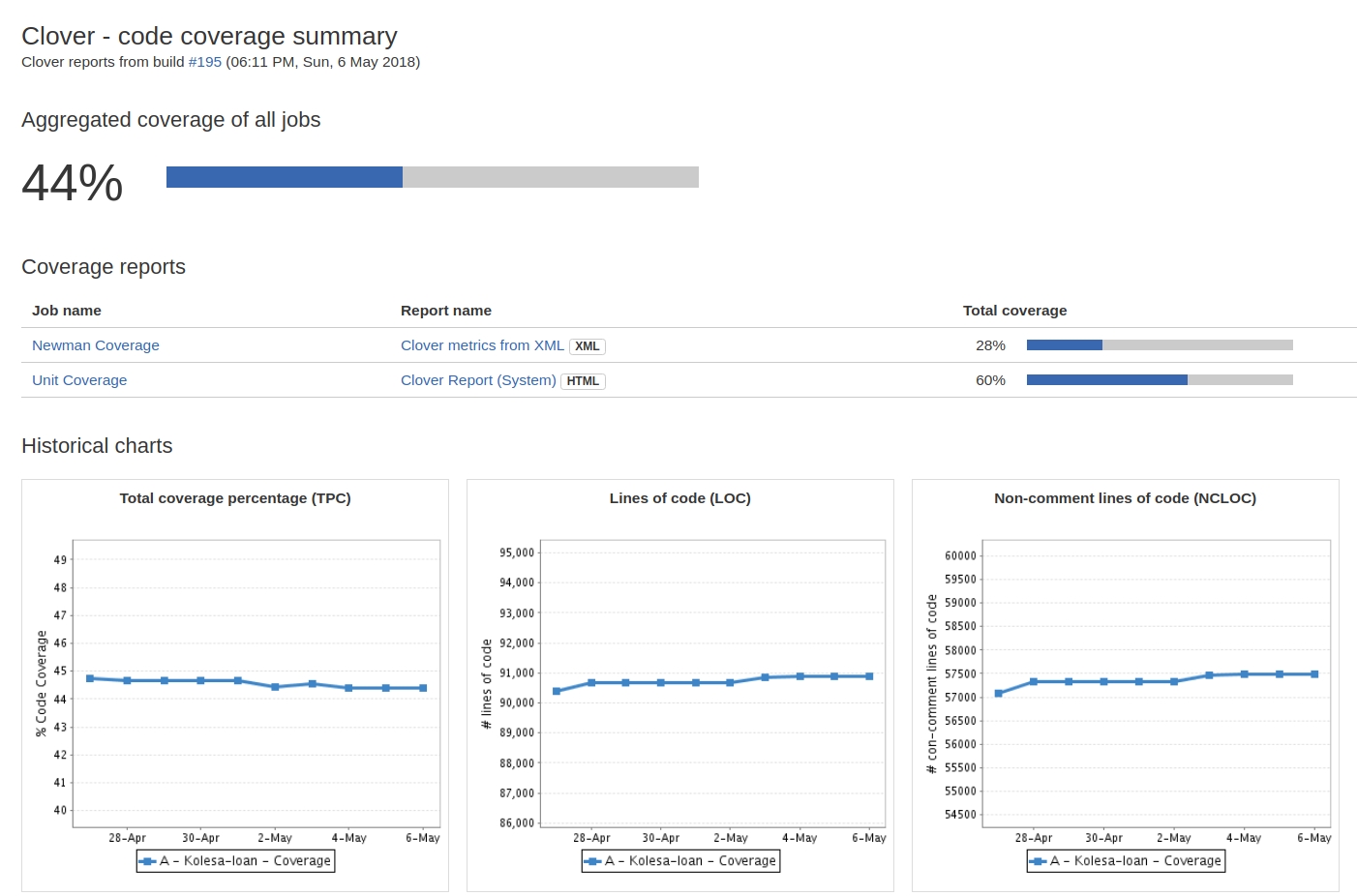
На выходе получаем вот такую красоту (В данном случае аналогичные операции проделаны для отчетов UNIT-тестов).
Важно!
В нашем проекте я разделил на 2 разных билд-плана тесты без измерения покрытия и тесты с включенным измерением покрытия. Покрытие измеряется только для мастер-ветки. Запускается билд-план с измерением покрытия каждый день по расписанию. Всё это сделано по причине того, что тесты с включенным покрытием проходят значительно дольше!
Заключение
Подводя итог проделанной работы, хочу отметить лишь несколько фактов.
Факт первый. Нет ничего сложного в том чтобы прикрутить к Continuous Intgration новый, понравившийся вам инструмент. Было бы желание.
Факт второй. Если чего-то в инструменте нет из коробки, то совсем не обязательно, что доработать это самому окажется сложным и муторным занятием. Иногда, если разобраться, то всё решается в пару-тройку десятков строк кода. Добавьте сюда огромный профит от использования инструмента, когда всё заработает. Ну и плюс ко всему это ещё один повод прокачать свои навыки.
Факт третий. Никто не утверждает что newman это панацея от всех бед, и что он лучший в качестве инструмента функционального тестирования. Однако, мы попробовали — и нам понравилось, особенно после того как он был прикручен к CI!
Ну и, конечно же, мы будем рады, если наша библиотека принесет вам пользу. А если у вас возникнет необходимость ее доработать – feel free to contribute!
