Одна из малозаметных, но важных функций наших сайтов объявлений — сохранение и отображение количества их просмотров. Наши сайты следят за просмотрами объявлений уже больше 10 лет. Техническая реализация функциональности успела несколько раз измениться за это время, и сейчас представляет из себя (микро)сервис на Go, работающий с Redis в качестве кэша и очереди задач, и с MongoDB в качестве персистентного хранилища. Несколько лет назад он научился работать не только с суммой просмотров объявления, но еще и со статистикой за каждый день. А вот делать все это действительно быстро и надежно он научился совсем недавно.
В сумме по проектам, сервис обрабатывает ~300 тысяч запросов на чтение и ~9 тысяч запросов на запись в минуту, 99% которых выполняются до 5мс. Это, конечно, не астрономические показатели и не запуск ракет на Марс — но и не такая тривиальная задача, какой может показаться простое хранение чисел. Оказалось, что делать все это, обеспечивая сохранение данных без потерь и чтение согласованных, актуальных значений требует определенных усилий, о которых мы расскажем ниже.
Хоть счетчики просмотров и не так критичны для бизнеса, как, скажем, обработка платежей или запросов на получение кредита, они важны в первую очередь нашим пользователям. Людей увлекает слежение за популярностью своих объявлений: некоторые даже звонят в службу поддержки, когда замечают неточную информацию о просмотрах (такое происходило с одной из предыдущих реализаций сервиса). Кроме того, мы храним и отображаем детальную статистику в личных кабинетах пользователей (например, для оценки эффективности применения платных услуг). Все это заставляет нас заботливо относиться к сохранению каждого события просмотра и к отображению наиболее актуальных значений.
В целом функциональность и принципы работы проекта выглядят так:
Хотя описанные выше шаги выглядят довольно просто, проблемой здесь является организация взаимодействия между БД и экземплярами микросервиса так, чтобы данные не терялись, не дублировались, и не запаздывали.
Использование только одного хранилища (например, только MongoDB) решило бы часть этих проблем. На самом деле раньше сервис так и работал, пока мы не уперлись в проблемы масштабирования, стабильности и скорости работы.
Наивная реализация перемещения данных между хранилищами могла бы привести, например, к таким аномалиям:
Могут возникнуть и другие ошибки, причины которых также кроются в неатомарной природе операций между БД, например — конфликт при одновременном удалении и увеличении просмотров одной и той же сущности.
Наш подход к хранению и обработке данных в этом проекте основан на ожидании, что в любой момент времени MongoDB может отказать с большей вероятностью, чем Redis. Это, конечно, не абсолютное правило — по крайней мере, не для каждого проекта — но в нашем окружении мы действительно привыкли наблюдать периодические таймауты на запросы в MongoDB, вызванные производительностью дисковых операций, что ранее было одной из причин потери части событий.
Чтобы избежать многих упомянутых выше проблем, мы используем очереди задач для отложенного сохранения и lua-скрипты, которые дают возможность атомарно менять данные в нескольких структурах редиса сразу. С учетом этого, в деталях схема сохранения просмотров выглядит так:
Благодаря тому, что lua-скрипты выполняются атомарно, мы избегаем множество потенциальных проблем, которые могли быть вызваны конкурентной записью.
Еще одна важная деталь — обеспечение безопасного переноса обновлений из очереди pending queue в MongoDB. Для этого мы применили шаблон «надежная очередь», описанный в документации Redis, который существенно уменьшает шансы потери данных благодаря созданию копии обрабатываемых элементов в отдельной, ещё одной очереди до момента их окончательного сохранения в персистентном хранилище.
Чтобы лучше понять шаги процесса целиком, мы подготовили небольшую визуализацию. Для начала посмотрим на обычный, успешный сценарий (шаги пронумерованы в правом верхнем углу и подробно описаны ниже):
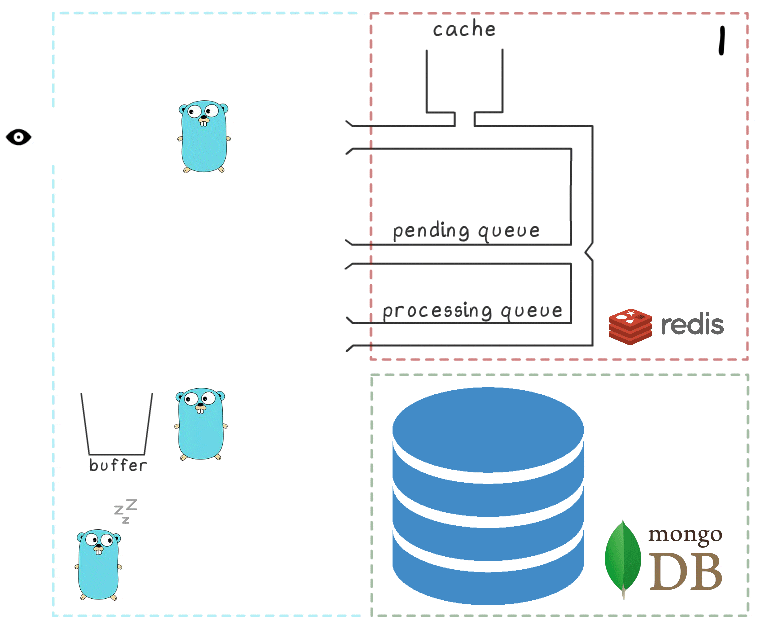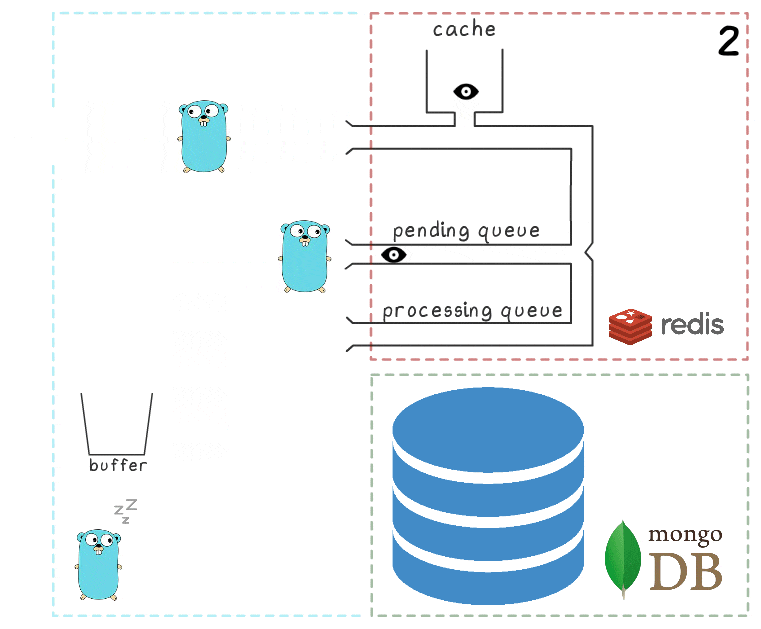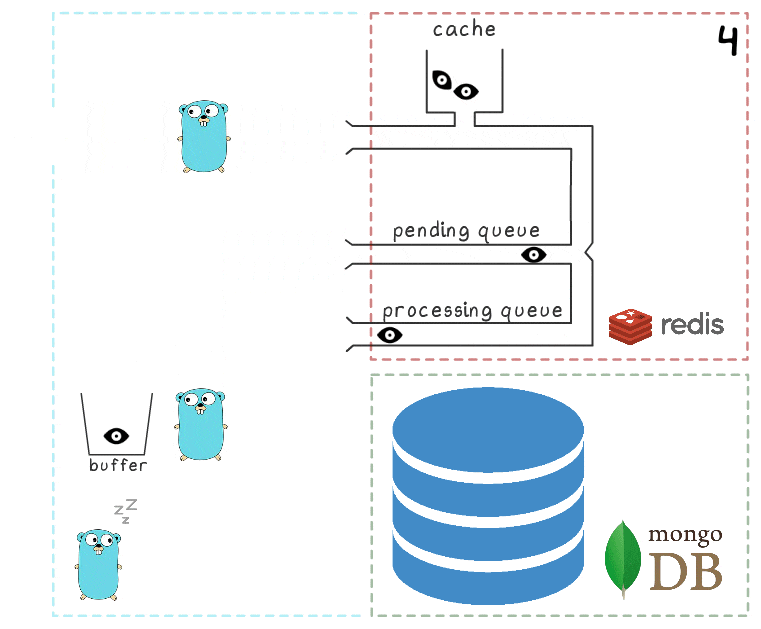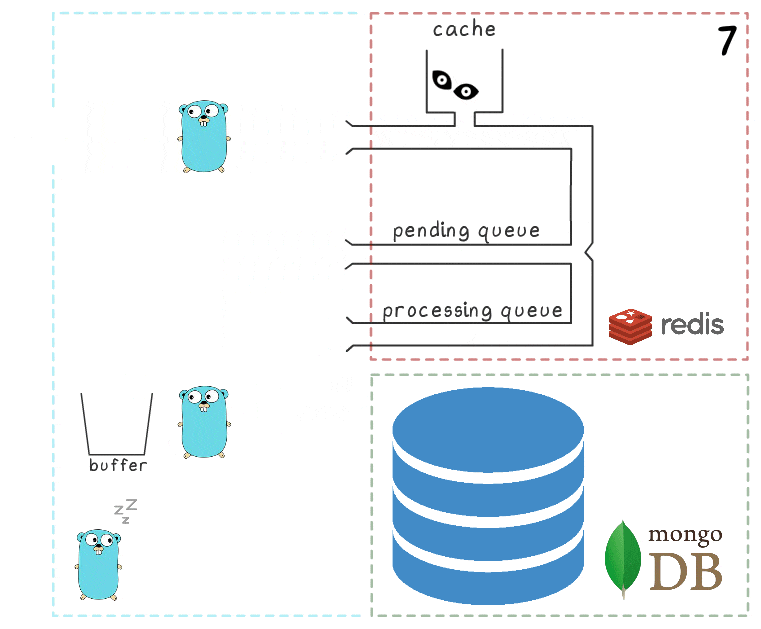
Когда все подсистемы в порядке, часть этих шагов может показаться излишней. А у внимательного читателя также может возникнуть вопрос о том, что делает спящий в левом нижнем углу гофер.
Все объясняется при рассмотрении сценария, когда MongoDB оказывается недоступна:
В этой схеме есть несколько важных таймаутов и эвристик, выведенных через тестирование и здравый смысл: например, элементы перемещаются назад из processing queue в pending queue через 15 минут их неактивности. Кроме того, горутина, ответственная за эту задачу, перед выполнением выполняет блокировку, чтобы несколько экземпляров микросервиса не пытались восстановить «зависшие» просмотры одновременно.
Строго говоря, даже эти меры не дают теоретически обоснованных гарантий (например, мы игнорируем сценарии вроде зависания процесса на 15 минут) — но на практике это работает достаточно надежно.
Также в этой схеме остается еще как минимум 2 известных нам уязвимых места, которые важно осознавать:
Может показаться, что проблем получилось больше, чем хотелось бы. Однако на самом деле оказывается, что сценарий, от которого мы изначально защищались — отказ MongoDB — действительно является намного более реальной угрозой, а новая схема обработки данных успешно обеспечивает доступность сервиса и предотвращает потери.
Одним из ярких примеров этого был случай, когда инстанс MongoDB на одном из проектов по нелепой случайности был недоступен всю ночь. Все это время счетчики просмотров накапливались и ротировались в редисе из одной очереди в другую, пока в итоге не были сохранены в БД после разрешения инцидента; большинство пользователей сбоя даже не заметили.
Запросы на чтение выполняются гораздо проще, чем на запись: микросервис сначала проверяет кэш в редисе; все, что не найдено в кэше, дозаполняется данными из MongoDb и возвращается клиенту.
Сквозной записи в кэш при операциях чтения нет, чтобы избежать накладных расходов на защиту от конкурентной записи. Хитрейт кэша при этом остается неплохим, так как чаще всего он и без того оказыватся прогретым благодаря прочим запросам на запись.
Статистика просмотров по дням читается из MongoDB напрямую, так как запрашивается она гораздо реже, а кэшировать её сложнее. Это также означает, что когда БД недоступна, чтение статистики перестает работать; но сказывается это лишь на малой части пользователей.
Схема коллекций MongoDB для проекта основана на этих рекомендациях от самих разработчиков БД, и выглядит так:
Транзакционные возможности MongoDb по обновлению нескольких коллекций одновременно мы пока не используем, а значит рискуем тем, что данные могут записаться лишь в одну коллекцию. Такие случаи мы пока что просто логируем; их насчитываются единицы, и пока это не представляет такой же существенной проблемы, как прочие сценарии.
Я бы не стал доверять своим же словам о том, что описанные сценарии действительно работают, если бы они не были покрыты тестами.
Так как большая часть кода проекта тесно работает с редисом и MongoDb, большая часть тестов в нём — интеграционные. Тестовое окружение поддерживается через docker-compose, а значит разворачивается быстро, обеспечивает воспроизводимость за счет сброса и восстановления состояния при каждом запуске, и дает возможность экспериментировать, не затрагивая чужие БД.
В этом проекте можно выделить 3 основных области тестирования:
Чтобы проверять неудачные сценарии, код бизнес-логики сервиса работает с интерфейсами клиентов БД, которые в нужных тестах подменяются на реализации, возвращающие ошибки и\или имитирующие сетевые задержки. Также мы симулируем параллельную работу нескольких экземпляров сервиса, используя паттерн "environment object". Это вариант известного подхода «инверсия управления», где функции не обращаются к зависимостям самостоятельно, а получают их через переданный в аргументах объект окружения. Помимо прочих достоинств подход позволяет симулировать несколько независимых копий сервиса в одном тесте, каждый из которых имеет свой пул подключений к БД и более-менее эффективно воспроизводит продакшен-окружение. Некоторые тесты запускают каждый такой инстанс параллельно и убеждаются, что все они видят одинаковые данные, а состояния гонки отсутствуют.
Также мы проводили рудиментарный, но все равно довольно полезный стресс-тест на основе
siege, который помог примерно оценить допустимую нагрузку и скорость ответа от сервиса.
Для 90% запросов время обработки очень незначительно, а главное — стабильно; вот пример измерений на одном из проектов в течение нескольких дней:
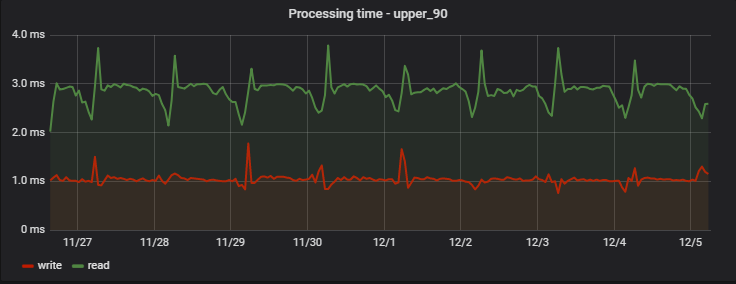
Интересно, что запись (которая на самом деле является операцией записи+чтения, т.к. возвращает обновленные значения) оказывается немного быстрее чтения (но только с точки зрения клиента, который не наблюдает фактическую отложенную запись).
А регулярный утренний рост задержек — побочный эффект работы нашей команды аналитики, которая ежедневно собирает свою собственную статистику на основе данных сервиса, создавая нам «искусственный хайлоад».
Максимальное же время обработки сравнительно велико: среди самых медленных запросов себя проявляют новые и непопулярные объявления (если объявление не было просмотрено и выводится только в списках — его данные не попадают в кэш и считываются из MongoDB), групповые запросы за множеством объявлений сразу (их стоило бы вынести в отдельный график), а также возможные сетевые задержки:

Практика, в какой-то степени контринтуитивно, показала, что использование Redis в качестве основного хранилища для сервиса просмотров повысило общую стабильность и улучшило общую скорость его работы.
Основную нагрузку сервиса составляют запросы на чтение, 95% которых возвращаются из кэша, а потому работают очень быстро. Запросы на запись же выполняются отложенно, хотя с точки зрения конечного пользователя работают также быстро и становятся видимыми для всех клиентов немедленно. В целом почти все клиенты получают ответы менее чем за 5мс.
В результате текущая версия микросервиса на основе Go, Redis и MongoDB успешно работает под нагрузкой и умеет переживать периодическую недоступность одного из хранилищ данных. Исходя из предыдущего опыта с инфраструктурными проблемами мы определили основные сценарии ошибок и успешно защитились от них, так что большинство пользователей не испытывают неудобств. А мы в свою очередь получаем гораздо меньше жалоб, алертов и сообщений в логах — и готовы к дальнейшему росту посещаемости.

В сумме по проектам, сервис обрабатывает ~300 тысяч запросов на чтение и ~9 тысяч запросов на запись в минуту, 99% которых выполняются до 5мс. Это, конечно, не астрономические показатели и не запуск ракет на Марс — но и не такая тривиальная задача, какой может показаться простое хранение чисел. Оказалось, что делать все это, обеспечивая сохранение данных без потерь и чтение согласованных, актуальных значений требует определенных усилий, о которых мы расскажем ниже.
Задачи и обзор проекта
Хоть счетчики просмотров и не так критичны для бизнеса, как, скажем, обработка платежей или запросов на получение кредита, они важны в первую очередь нашим пользователям. Людей увлекает слежение за популярностью своих объявлений: некоторые даже звонят в службу поддержки, когда замечают неточную информацию о просмотрах (такое происходило с одной из предыдущих реализаций сервиса). Кроме того, мы храним и отображаем детальную статистику в личных кабинетах пользователей (например, для оценки эффективности применения платных услуг). Все это заставляет нас заботливо относиться к сохранению каждого события просмотра и к отображению наиболее актуальных значений.
В целом функциональность и принципы работы проекта выглядят так:
- Веб-страница или экран приложения делают запрос за счетчиками просмотров объявлений (запрос обычно асинхронный, чтобы приоритизировать вывод основной информации). А если отображается страница самого объявления, клиент вместо этого попросит увеличить и вернуть обновленную сумму просмотров.
- Обрабатывая запросы на чтение, сервис пытается получить информацию из кэша Redis, а ненайденное дополняет, выполняя запрос к MongoDB.
- Запросы на запись отправляются в 2 структуры в редисе: очередь инкрементальных обновлений (обрабатываемая в фоне, асинхронно) и кэш общего количества просмотров.
- Фоновый процесс в том же сервисе считывает элементы из очереди, накапливает их в локальном буфере, и периодически записывает его в MongoDB.
Запись счетчиков просмотров: подводные камни
Хотя описанные выше шаги выглядят довольно просто, проблемой здесь является организация взаимодействия между БД и экземплярами микросервиса так, чтобы данные не терялись, не дублировались, и не запаздывали.
Использование только одного хранилища (например, только MongoDB) решило бы часть этих проблем. На самом деле раньше сервис так и работал, пока мы не уперлись в проблемы масштабирования, стабильности и скорости работы.
Наивная реализация перемещения данных между хранилищами могла бы привести, например, к таким аномалиям:
- Потеря данных при конкурентной записи в кэш:
- Процесс A увеличивает счетчик просмотров в кэше Redis, но обнаруживает, что там еще нет данных для этой сущности (это может быть как новое объявление, так и старое, вытесненное из кэша), поэтому процесс сперва должен получить это значение из MongoDB.
- Процесс A получает счетчик просмотров из MongoDB — к примеру, число 5; затем добавляет к нему 1 и собирается записать в Redis 6.
- Процесс B (инициированный, скажем, другим пользователем сайта, одновременно зашедшим на это же объявление) параллельно делает то же самое.
- Процесс A записывает в Redis значение 6.
- Процесс B записывает в Redis значение 6.
- В итоге один просмотр оказывается потерян из-за гонки при записи данных.
Сценарий не так уж и маловероятен: у нас, например, есть платная услуга, которая помещает объявление на главную страницу сайта. Для нового объявления такой ход событий может привести к потере сразу множества просмотров из-за их внезапного наплыва.
- Процесс A увеличивает счетчик просмотров в кэше Redis, но обнаруживает, что там еще нет данных для этой сущности (это может быть как новое объявление, так и старое, вытесненное из кэша), поэтому процесс сперва должен получить это значение из MongoDB.
- Пример другого сценария — потеря данных при перемещении просмотров из Redis в MongoDb:
- Процесс забирает ожидающее записи значение из Redis и сохраняет к себе в память для последующей записи в MongoDB.
- Запрос на запись заканчивается ошибкой (или процесс падает до его выполнения).
- Данные снова потеряны, что станет очевидно в следующий раз, когда закэшированное значение вытеснится и заменится значением из базы.
Могут возникнуть и другие ошибки, причины которых также кроются в неатомарной природе операций между БД, например — конфликт при одновременном удалении и увеличении просмотров одной и той же сущности.
Запись счетчиков просмотров: решение
Наш подход к хранению и обработке данных в этом проекте основан на ожидании, что в любой момент времени MongoDB может отказать с большей вероятностью, чем Redis. Это, конечно, не абсолютное правило — по крайней мере, не для каждого проекта — но в нашем окружении мы действительно привыкли наблюдать периодические таймауты на запросы в MongoDB, вызванные производительностью дисковых операций, что ранее было одной из причин потери части событий.
Чтобы избежать многих упомянутых выше проблем, мы используем очереди задач для отложенного сохранения и lua-скрипты, которые дают возможность атомарно менять данные в нескольких структурах редиса сразу. С учетом этого, в деталях схема сохранения просмотров выглядит так:
- Когда запрос на запись попадает в микросервис, он выполняет lua-скрипт IncrementIfExists для увеличения счетчика, только если он уже существует в кэше. Скрипт сразу же возвращает -1, если данных для просматриваемой сущности в редисе нет; в противном случае он увеличивает значение просмотров в кэше через HINCRBY, добавляет событие в очередь на последующее сохранение в MongoDB (называемую нами pending queue) через LPUSH, и возвращает обновленную сумму просмотров.
- Если IncrementIfExists вернул положительное число, это значение возвращается клиенту и запрос завершается.
Иначе микросервис забирает счетчик просмотров из MongoDb, увеличивает его на 1 и отправляет в редис.
- Запись в редис выполняется через еще один lua-скрипт — Upsert — который сохраняет сумму просмотров в кэш, если он еще пуст, или увеличивает их на 1, если кто-то другой успел заполнить кэш между шагами 1 и 3.
- Upsert также добавляет событие просмотра в очередь pending queue, и возвращает обновленную сумму, которая затем отправляется клиенту.
Благодаря тому, что lua-скрипты выполняются атомарно, мы избегаем множество потенциальных проблем, которые могли быть вызваны конкурентной записью.
Еще одна важная деталь — обеспечение безопасного переноса обновлений из очереди pending queue в MongoDB. Для этого мы применили шаблон «надежная очередь», описанный в документации Redis, который существенно уменьшает шансы потери данных благодаря созданию копии обрабатываемых элементов в отдельной, ещё одной очереди до момента их окончательного сохранения в персистентном хранилище.
Чтобы лучше понять шаги процесса целиком, мы подготовили небольшую визуализацию. Для начала посмотрим на обычный, успешный сценарий (шаги пронумерованы в правом верхнем углу и подробно описаны ниже):
- В микросервис поступает запрос на запись
- Обработчик запроса передает его в lua-скрипт, который пишет просмотр в кэш (сразу же делая его доступным для чтения) и в очередь на последующую обработку.
- Фоновая горутина (периодически) выполняет операцию BRPopLPush, которая атомарно перемещает элемент из одной очереди в другую (её мы называем «processing queue» — очередь с обрабатываемыми в данный момент элементами). Этот же элемент затем сохраняется в буфер в памяти процесса.
- Приходит и обрабатывается еще один запрос на запись, что оставляет нас с 2 элементами в буфере и 2 элементами в очереди processing queue.
- По истечении некоторого таймаута фоновый процесс решает сбросить буфер в MongoDB. Запись множества значений из буфера выполняется одним запросом, что положительно сказывается на пропускной способности. Также перед записью процесс пытается объединить несколько просмотров в один, суммируя их значения для одних и тех же объявлений.
На каждом из наших проектов используется по 3 инстанса микросервиса, каждый со своим буфером, который сохраняется в базу каждые 2 секунды. За это время в одном буфере накапливается примерно 100 элементов.
- После успешной записи процесс удаляет элементы из processing queue, сигнализируя, что обработка успешно завершена.
Когда все подсистемы в порядке, часть этих шагов может показаться излишней. А у внимательного читателя также может возникнуть вопрос о том, что делает спящий в левом нижнем углу гофер.
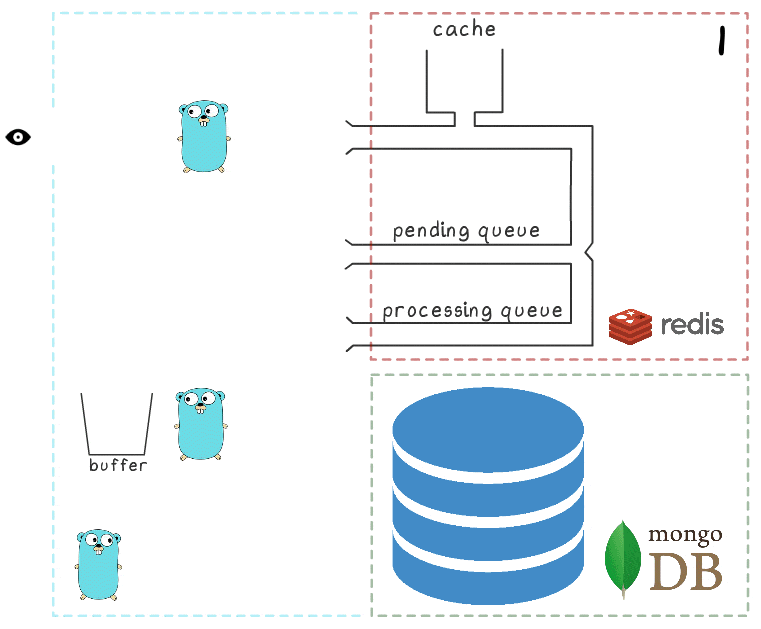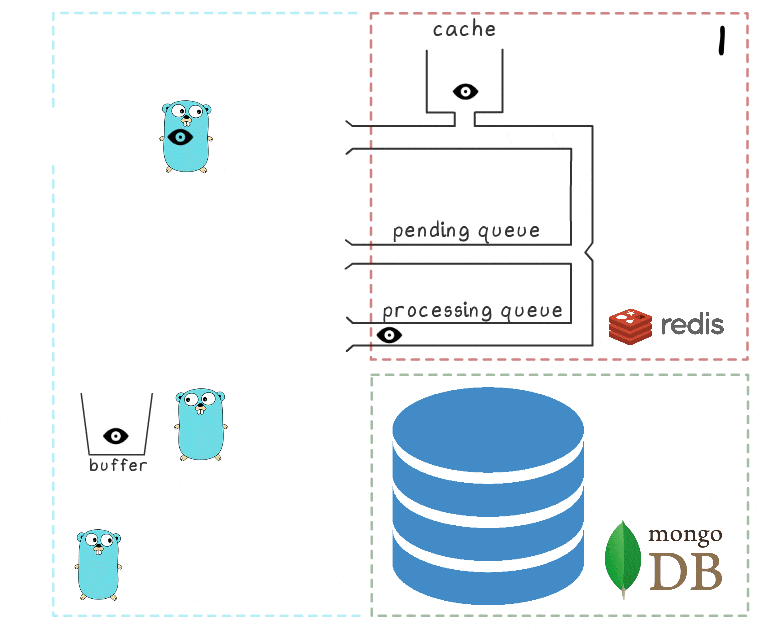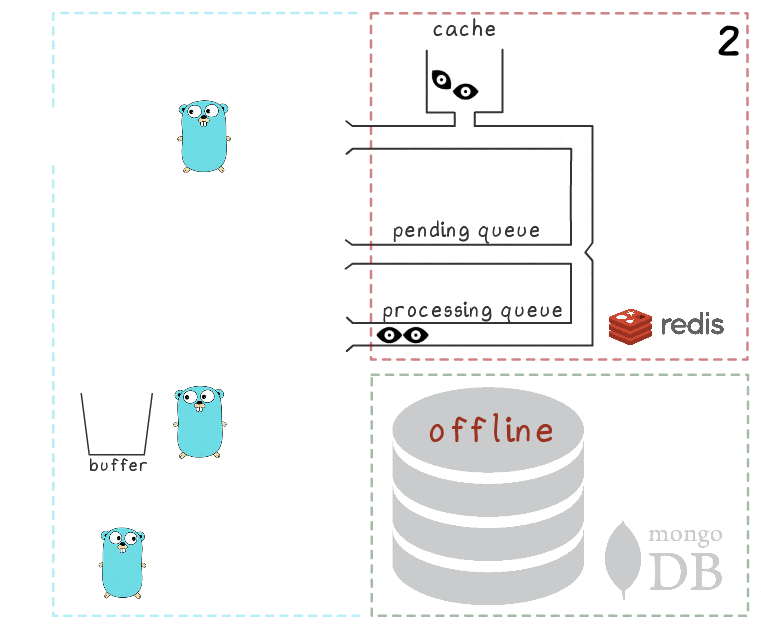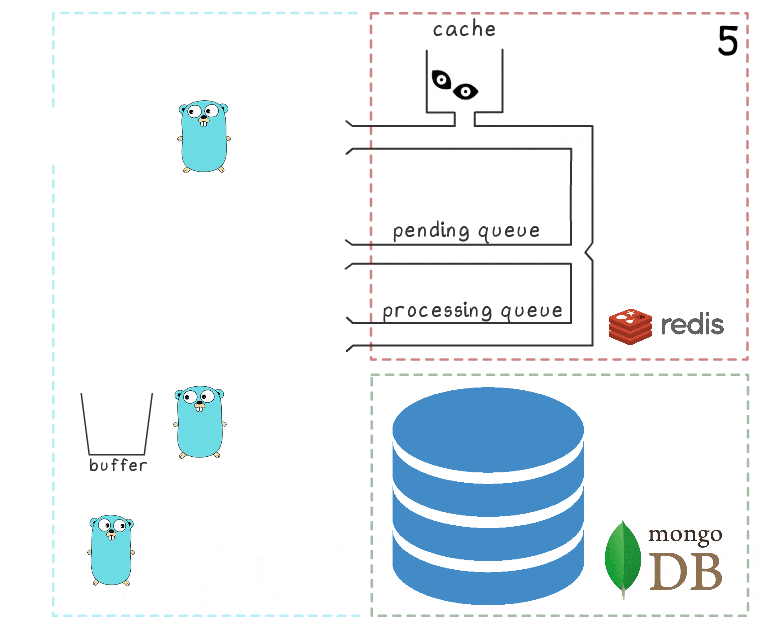
Все объясняется при рассмотрении сценария, когда MongoDB оказывается недоступна:
- Первый шаг идентичен событиям из предыдущего сценария: сервис получает 2 запроса на запись просмотров и обрабатывает их.
- У процесса пропадает соединение с MongoDB (сам процесс об этом, конечно, ещё не знает).
Горутина-обработчик, как и раньше, пытается сбросить свой буфер в базу — но на этот раз безуспешно. Она возвращается к ожиданию следующей итерации.
- Просыпается другая фоновая горутина и проверяет очередь обрабатываемых элементов (processing queue). Она обнаруживает, что элементы были добавлены в неё уже давно; делая вывод, что их обработка не удалась, она перемещает их назад в pending queue.
- Через некоторое время соединение с MongoDB восстанавливается.
- Первая фоновая горутина снова пытается выполнить операцию записи — на этот раз успешно — и в итоге окончательно удаляет элементы из processing queue.
В этой схеме есть несколько важных таймаутов и эвристик, выведенных через тестирование и здравый смысл: например, элементы перемещаются назад из processing queue в pending queue через 15 минут их неактивности. Кроме того, горутина, ответственная за эту задачу, перед выполнением выполняет блокировку, чтобы несколько экземпляров микросервиса не пытались восстановить «зависшие» просмотры одновременно.
Строго говоря, даже эти меры не дают теоретически обоснованных гарантий (например, мы игнорируем сценарии вроде зависания процесса на 15 минут) — но на практике это работает достаточно надежно.
Также в этой схеме остается еще как минимум 2 известных нам уязвимых места, которые важно осознавать:
- Если микросервис упал сразу после успешного сохранения в MongoDb, но до очистки списка processing queue, то эти данные будут считаться несохраненными — и через 15 минут будут сохранены повторно.
Для уменьшения вероятности такого сценария у нас предусмотрены повторные попытки удаления из processing queue в случае ошибок. В реальности же таких случаев в продакшене мы еще не наблюдали.
- При перезагрузке редис может потерять не только кэш, но и часть несохраненных просмотров из очередей, так как настроен на периодическое сохранение RDB снэпшотов каждые несколько минут.
Хотя в теории это может быть серьезной проблемой (особенно если проект имеет дело с действительно критичными данными), на практике узлы перезапускаются крайне редко. При этом, согласно мониторингу, элементы проводят в очередях меньше 3 секунд, то есть возможный объем потерь сильно ограничен.
Может показаться, что проблем получилось больше, чем хотелось бы. Однако на самом деле оказывается, что сценарий, от которого мы изначально защищались — отказ MongoDB — действительно является намного более реальной угрозой, а новая схема обработки данных успешно обеспечивает доступность сервиса и предотвращает потери.
Одним из ярких примеров этого был случай, когда инстанс MongoDB на одном из проектов по нелепой случайности был недоступен всю ночь. Все это время счетчики просмотров накапливались и ротировались в редисе из одной очереди в другую, пока в итоге не были сохранены в БД после разрешения инцидента; большинство пользователей сбоя даже не заметили.
Чтение счетчиков просмотров
Запросы на чтение выполняются гораздо проще, чем на запись: микросервис сначала проверяет кэш в редисе; все, что не найдено в кэше, дозаполняется данными из MongoDb и возвращается клиенту.
Сквозной записи в кэш при операциях чтения нет, чтобы избежать накладных расходов на защиту от конкурентной записи. Хитрейт кэша при этом остается неплохим, так как чаще всего он и без того оказыватся прогретым благодаря прочим запросам на запись.
Статистика просмотров по дням читается из MongoDB напрямую, так как запрашивается она гораздо реже, а кэшировать её сложнее. Это также означает, что когда БД недоступна, чтение статистики перестает работать; но сказывается это лишь на малой части пользователей.
Схема хранения данных в MongoDB
Схема коллекций MongoDB для проекта основана на этих рекомендациях от самих разработчиков БД, и выглядит так:
- Просмотры сохраняются в 2 коллекции: в одной находится их общая сумма, в другой — статистика по дням.
- Данные в коллекции со статистикой огранизованы по принципу один документ на одно объявление в месяц. Для новых объявлений в коллекцию вставляется документ, заполненный тридцать одним нулем за текущий месяц; соглано упомянутой выше статье, это позволяет сразу выделить достаточно места для документа на диске, чтобы базе не пришлось перемещать его при добавлении данных.
Этот пункт делает процесс чтения статистики немного неуклюжим (запросы приходится формировать по месяцам на стороне микросервиса), но в целом схема остается довольно интуитивной.
- Для записи используется операция upsert, чтобы в рамках одного запроса обновлять и, при необходимости, создавать документ для нужной сущности.
Транзакционные возможности MongoDb по обновлению нескольких коллекций одновременно мы пока не используем, а значит рискуем тем, что данные могут записаться лишь в одну коллекцию. Такие случаи мы пока что просто логируем; их насчитываются единицы, и пока это не представляет такой же существенной проблемы, как прочие сценарии.
Тестирование
Я бы не стал доверять своим же словам о том, что описанные сценарии действительно работают, если бы они не были покрыты тестами.
Так как большая часть кода проекта тесно работает с редисом и MongoDb, большая часть тестов в нём — интеграционные. Тестовое окружение поддерживается через docker-compose, а значит разворачивается быстро, обеспечивает воспроизводимость за счет сброса и восстановления состояния при каждом запуске, и дает возможность экспериментировать, не затрагивая чужие БД.
В этом проекте можно выделить 3 основных области тестирования:
- Проверка бизнес-логики в типичных сценариях, т.н. happy-path. Эти тесты отвечают на вопрос — когда все подсистемы в порядке, работает ли сервис согласно функциональным требованиям?
- Проверка негативных сценариев, при которых ожидается, что сервис продолжит свою работу. Например, действительно ли сервис не теряет данные при падении MongoDb?
Уверены ли мы, что информация остается согласованной при периодических таймаутах, зависаниях и конкурентных операциях записи? - Проверка негативных сценариев, при которых мы не ожидаем продолжения работы сервиса, но минимальный уровень функциональности все равно должен быть обеспечен. Например, нет никаких шансов, что сервис продолжит сохранять и отдавать данные, когда недоступны ни редис, ни монго — но мы хотим быть уверены, что в таких случаях он не падает, а ожидает восстановления системы и затем возвращается к работе.
Чтобы проверять неудачные сценарии, код бизнес-логики сервиса работает с интерфейсами клиентов БД, которые в нужных тестах подменяются на реализации, возвращающие ошибки и\или имитирующие сетевые задержки. Также мы симулируем параллельную работу нескольких экземпляров сервиса, используя паттерн "environment object". Это вариант известного подхода «инверсия управления», где функции не обращаются к зависимостям самостоятельно, а получают их через переданный в аргументах объект окружения. Помимо прочих достоинств подход позволяет симулировать несколько независимых копий сервиса в одном тесте, каждый из которых имеет свой пул подключений к БД и более-менее эффективно воспроизводит продакшен-окружение. Некоторые тесты запускают каждый такой инстанс параллельно и убеждаются, что все они видят одинаковые данные, а состояния гонки отсутствуют.
Также мы проводили рудиментарный, но все равно довольно полезный стресс-тест на основе
siege, который помог примерно оценить допустимую нагрузку и скорость ответа от сервиса.
О производительности
Для 90% запросов время обработки очень незначительно, а главное — стабильно; вот пример измерений на одном из проектов в течение нескольких дней:
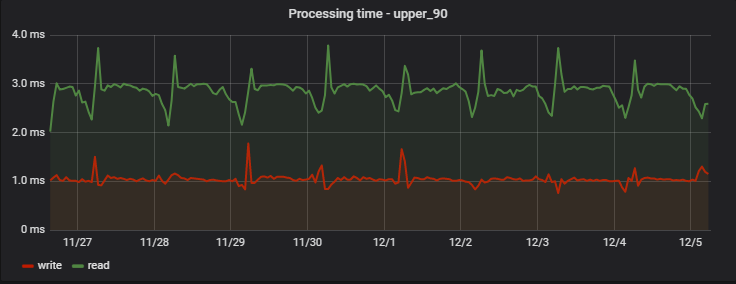
Интересно, что запись (которая на самом деле является операцией записи+чтения, т.к. возвращает обновленные значения) оказывается немного быстрее чтения (но только с точки зрения клиента, который не наблюдает фактическую отложенную запись).
А регулярный утренний рост задержек — побочный эффект работы нашей команды аналитики, которая ежедневно собирает свою собственную статистику на основе данных сервиса, создавая нам «искусственный хайлоад».
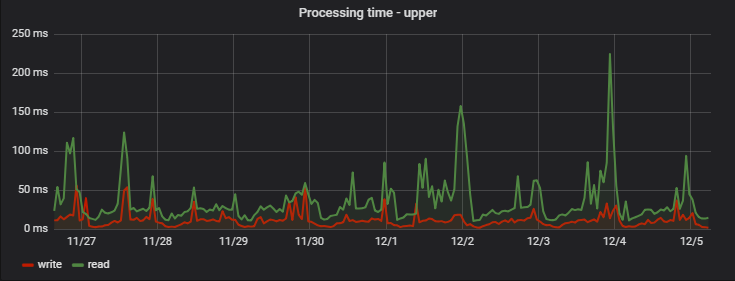
Максимальное же время обработки сравнительно велико: среди самых медленных запросов себя проявляют новые и непопулярные объявления (если объявление не было просмотрено и выводится только в списках — его данные не попадают в кэш и считываются из MongoDB), групповые запросы за множеством объявлений сразу (их стоило бы вынести в отдельный график), а также возможные сетевые задержки:
Заключение
Практика, в какой-то степени контринтуитивно, показала, что использование Redis в качестве основного хранилища для сервиса просмотров повысило общую стабильность и улучшило общую скорость его работы.
Основную нагрузку сервиса составляют запросы на чтение, 95% которых возвращаются из кэша, а потому работают очень быстро. Запросы на запись же выполняются отложенно, хотя с точки зрения конечного пользователя работают также быстро и становятся видимыми для всех клиентов немедленно. В целом почти все клиенты получают ответы менее чем за 5мс.
В результате текущая версия микросервиса на основе Go, Redis и MongoDB успешно работает под нагрузкой и умеет переживать периодическую недоступность одного из хранилищ данных. Исходя из предыдущего опыта с инфраструктурными проблемами мы определили основные сценарии ошибок и успешно защитились от них, так что большинство пользователей не испытывают неудобств. А мы в свою очередь получаем гораздо меньше жалоб, алертов и сообщений в логах — и готовы к дальнейшему росту посещаемости.
