
Ссылка на часть 2: парсинг и выполнение JS
Ссылка на часть 3: деревья специальных возможностей и рендеринга
Примечания переводчиков:
1. Статья предназначена для начинающих разработчиков и интересующихся разработкой. Здесь нет глубоких технических деталей.
2. В оригинальной статьей используются два сокращения: SYN и SYNC. Пониманию это особенно не помогает, поэтому, чтобы не запутывать читателя, мы оставили только SYN.
Браузеры — это программное обеспечение, установленное у нас на устройствах и позволяющее получать доступ к Интернету. Одним из них вы пользуетесь, когда читаете этот текст. Браузеров много, и по состоянию на 2021 год наиболее часто применяются следующие: Google Chrome, Safari, Microsoft Edge и Firefox.
Но как они работают, и что происходит от момента ввода адреса до тех пор, пока нужная страница не отобразится на экране?
Если максимально упростить, то всё происходит так: когда мы запрашиваем страницу определённого сайта, браузер извлекает необходимый контент с сервера, а затем отображает страницу на устройстве. Довольно просто, да? Да, но в этом, казалось бы, очень простом процессе гораздо больше составляющих.
В этом цикле статей мы поговорим о навигации, получении данных, синтаксическом анализе и визуализации. Надеемся, что эти процессы станут для вас понятнее.
Содержание:
НАВИГАЦИЯ
Навигация — первый шаг к загрузке страницы. Это процесс, когда пользователь запрашивает страницу: нажимает на ссылку, пишет адрес в адресной строке браузера, отправляет форму и т. д.
Поиск DNS (разрешение адреса)
Первый шаг при переходе на страницу – поиск того, где находятся ресурсы этой страницы (HTML, CSS, JavaScript и другие типы файлов). Если перейти на https://example.com, то HTML-страница расположена на сервере с IP-адресом 93.184.216.34. Для нас сайты — это имена доменов, а для компьютеров — IP-адреса. Если мы не посещали этот сайт раньше, происходит поиск системы доменных имен (DNS).
DNS-серверы содержат базу данных публичных IP-адресов и связанных с ними имен хостов (их обычно сравнивают с телефонной книгой, в которой имена связаны с номерами). В большинстве случаев серверы служат для разрешения или преобразования имен в IP-адреса по запросу (в настоящее время существует более 600 различных корневых серверов DNS, распределенных по всему миру).

Поэтому, когда мы запрашиваем поиск DNS, на самом деле мы взаимодействуем с одним из этих серверов и просим выяснить, какой IP-адрес соответствует имени https://example.com. Если найден соответствующий IP-адрес, он предоставляется. Если поиск почему-то не удался, в браузере появляется сообщение об ошибке.
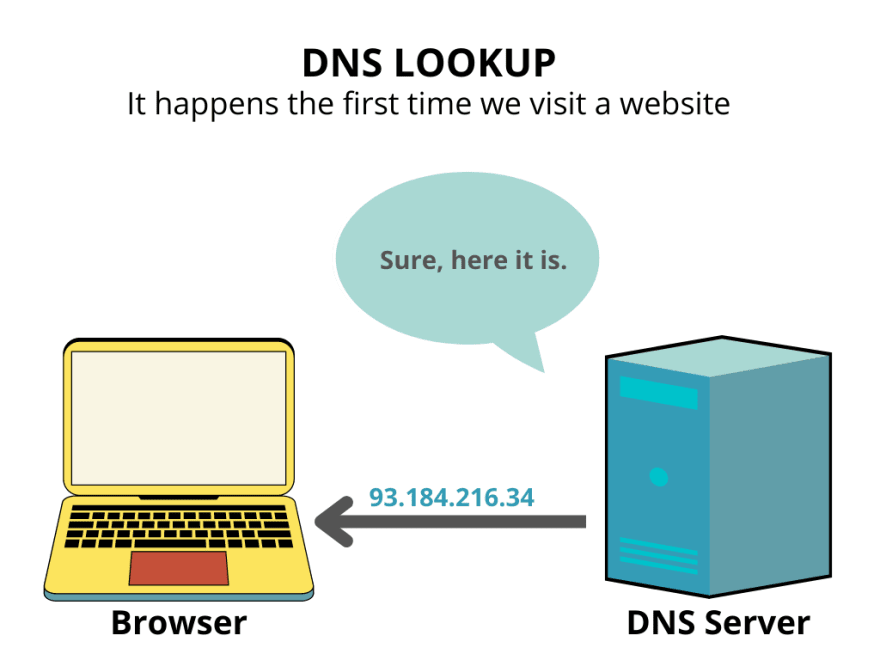
После этого первоначального поиска IP-адрес, вероятно, на некоторое время будет сохранён в кэше. Поэтому следующие посещения того же сайта будут происходить быстрее, так как не нужно искать DNS. Помните, поиск DNS происходит только при первом посещении сайта.
Подтверждение TCP (протокол управления передачей)
Как только браузер узнает IP-адрес сайта, он попытается установить соединение с сервером, на котором хранятся ресурсы, с помощью трехэтапного подтверждения TCP (также называемого SYN-SYN-ACK, или, точнее, SYN, SYN-ACK, ACK, потому что согласно TCP передаются три сообщения для согласования и начала сеанса TCP между двумя компьютерами).
TCP означает «протокол управления передачей», стандарт связи, который позволяет прикладным программам и вычислительным устройствам обмениваться сообщениями по сети. Он предназначен для отправки пакетов данных через Интернет и обеспечения успешной доставки данных и сообщений по сети.
Подтверждение TCP – это механизм, предназначенный для того, чтобы два объекта (в нашем случае браузер и сервер), которые хотят передавать информацию друг другу, согласовали параметры соединения перед передачей данных.
Таким образом, если представить, что браузер и сервер – два человека, разговор между ними будет выглядеть примерно так:

Браузер отправляет серверу сообщение SYN и запрашивает синхронизацию (синхронизация означает подключение).
Затем сервер отвечает сообщением SYN-ACK (синхронизация и подтверждение):
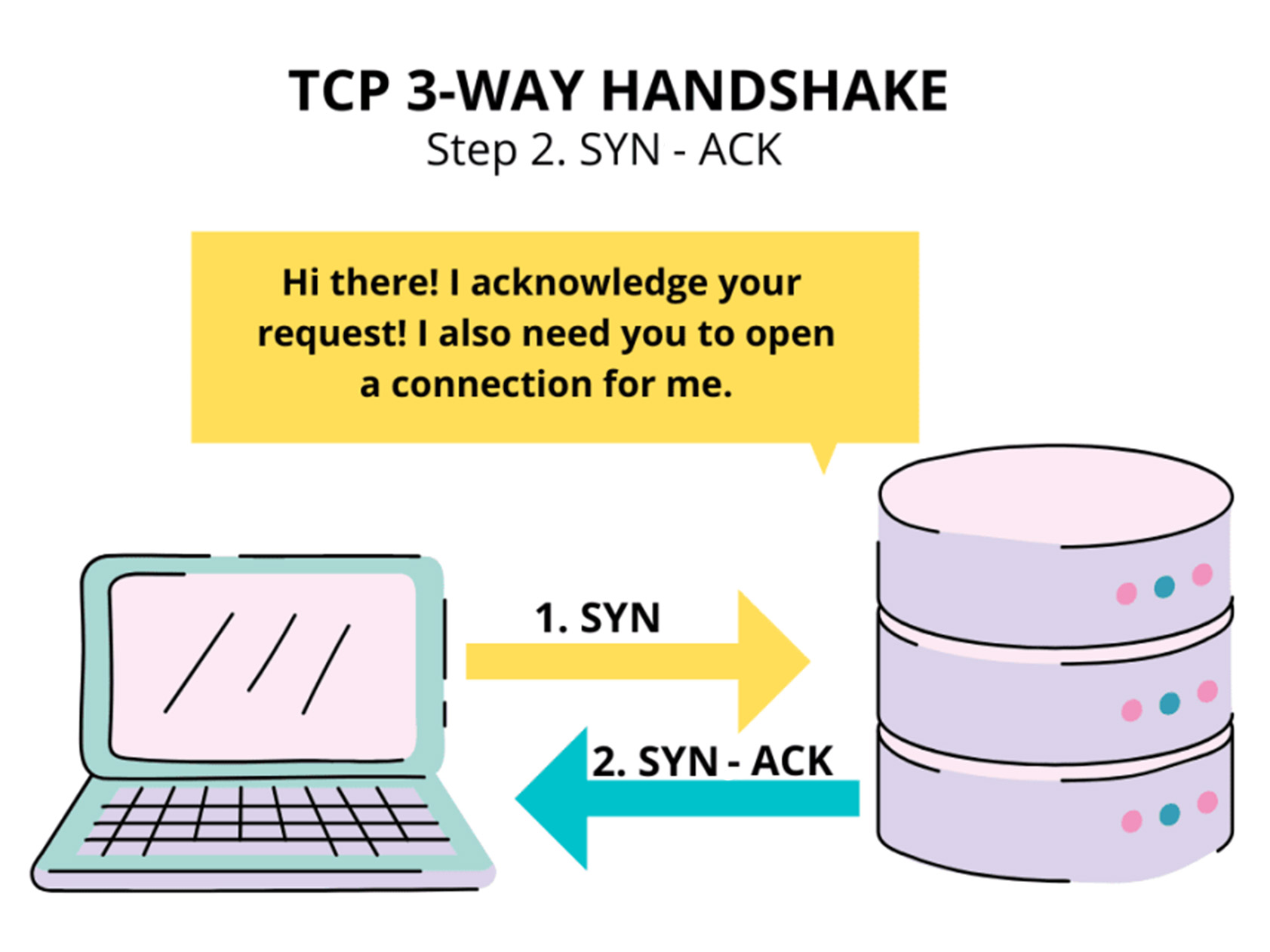
На последнем этапе браузер отвечает сообщением ACK.
Теперь, когда соединение TCP (двустороннее соединение) установлено посредством трехэтапного подтверждения, можно начинать обмен данными по TLS.
Переговоры в TLS
Для безопасных соединений, установленных по протоколу HTTPS, требуется еще одно подтверждение.
Это подтверждение (переговоры в TLS) определяет, какой шифр будет использоваться для шифрования связи, проверяет сервер и подтверждает, что безопасное соединение установлено до начала фактической передачи данных.
Протокол защиты транспортного уровня (TLS), преемник уже устаревшего слоя защищённых сокетов (SSL), представляет собой криптографический протокол, предназначенный для обеспечения безопасности связи по компьютерной сети. Протокол широко используется в электронной почте и при обмене мгновенными сообщениями, но применение в защите HTTPS наиболее заметно. Поскольку приложения обмениваются данными как в TLS (или SSL), так и без него, клиенту (браузеру) необходимо запросить, чтобы сервер настроил соединение в TLS.

На этом шаге происходит обмен сообщениями между браузером и сервером.
Клиент приветствует. Браузер отправляет серверу сообщение, в котором указывается, какую версию TLS и набор шифров он поддерживает, а также строка случайных байтов, известная как случайное число клиента.
Приветственное сообщение сервера и сертификат. Сервер отправляет обратно сообщение, содержащее сертификат SSL сервера, выбранный сервером набор шифров и случайное число сервера – строку случайных байтов, которую генерирует сервер.
Аутентификация. Браузер проверяет сертификат SSL сервера в центре сертификации, который его выдал. Таким образом, браузер убеждается, что сервер тот, за кого себя выдает.
Предварительный секретный ключ. Браузер отправляет еще одну строку случайных байтов – предварительный секретный ключ, зашифрованный открытым ключом, который браузер взял из сертификата SSL с сервера. Сервер может расшифровать предварительный секретный ключ только с помощью закрытого ключа.
Используется закрытый ключ. Сервер расшифровывает предварительный секретный ключ.
Ключи сеанса созданы. Браузер и сервер генерируют ключи сеанса из случайного числа клиента, случайного числа сервера и секретного ключа.
Клиент завершает работу. Браузер отправляет на сервер сообщение о том, что он завершил работу.
Сервер завершает работу. Сервер отправляет браузеру сообщение о том, что он также завершил работу.
Достигнуто надежное симметричное шифрование. Подтверждение завершено, и связь можно продолжать с помощью ключей сеанса.
Теперь можно запрашивать и получать данные с сервера.
ПОЛУЧЕНИЕ ДАННЫХ
В предыдущей статье мы говорили о навигации — первом этапе, который проходит браузер, чтобы отобразить сайт. Сегодня посмотрим, как происходит получение ресурсов.
HTTP Request (запрос)
После установления безопасного соединения с сервером браузер отправит первоначальный HTTP-запрос методом GET. Сначала браузер запросит HTML-документ с разметкой страницы. Для этого используется протокол HTTP.
HTTP (протокол передачи гипертекста) – протокол для получения ресурсов, например, HTML-документов. Основа любого обмена данными в Интернете – это протокол взаимодействия клиента и сервера, который означает, что запросы инициирует получатель, обычно браузер.

Метод – например: POST (отправить), GET (получить), DELETE (удалить) и т. д.
URI – это унифицированный (единообразный) идентификатор ресурса. URI используется для идентификации абстрактных или физических ресурсов в Интернете, например сайтов или адресов электронной почты. У URI насчитывается до 5 частей:
Схема: используется для обозначения используемого протокола.
Иерархическая часть: используется для идентификации домена.
Путь: используется для отображения точного пути к ресурсу.
Запрос: используется для представления запроса.
Фрагмент: используется для ссылки на часть ресурса.

Поля заголовка HTTP – это список строк, отправляемых и получаемых как браузером, так и сервером при каждом HTTP-запросе и ответе (обычно они невидимы для конечного пользователя). В запросах они содержат больше информации о ресурсе, который нужно получить, или о браузере, запрашивающем ресурс.
HTTP Response (ответ)
Как только сервер получит запрос, он обработает его и отправит HTTP-ответ. В приложении к основному тексту ответа находятся все соответствующие заголовки и содержимое запрошенного HTML-документа.

Код состояния – например: 200, 400, 401, 504 Gateway Timeout (Время ожидания шлюза сервера истекло) и т. д. Мы стремимся к коду состояния 200, так как он означает, что всё прошло хорошо, и запрос выполнен успешно.
Поля заголовка ответа содержат дополнительную информацию об ответе, например о местоположении или сервере, предоставляющем ответ.
Пример HTML-документа выглядит примерно так:

Если посмотреть на HTML-документ, видно, что он ссылается на различные файлы CSS и JavaScript. Запроса на данные файлы не будет до тех пор, пока браузер не столкнется с этими ссылками, но это произойдёт не на данном этапе, а во время парсинга — синтаксического анализа, о котором пойдёт речь в следующей статье. На данный момент запрашивается и принимается от сервера только HTML.
В ответе на такой первоначальный запрос содержится первый байт полученных данных. Время до получения первого байта (TTFB, Time to First Byte) – время между моментом, когда пользователь сделал запрос (введя имя сайта в адресную строку), и моментом получения первого пакета HTML (обычно 14 кб).
Алгоритмы медленного запуска и предотвращения перегрузки TCP
Медленный старт TCP – это алгоритм, который уравновешивает скорость сетевого соединения. Первый пакет данных составляет 14 кб (или меньше), и его роль заключается в том, что объем передаваемых данных постепенно увеличивается, пока не достигнет заранее определённого порога.
После получения каждого пакета данных от сервера клиент отвечает сообщением ACK. Поскольку пропускная способность соединения ограничена, если сервер отправляет слишком много пакетов слишком быстро, они будут потеряны. В таком случае, сервер не получит ACK-собщение, интерпретирует это как перегрузку сети и запустит алгоритмы предотвращения перегрузки. Они отслеживают поток отправленных пакетов и ACK-сообщений, определяют оптимальную скорость и создают устойчивый поток трафика.
Ещё одна статья про frontend для начинающих:
Как работают браузеры: навигация и получение данных, парсинг и выполнение JS, деревья спец возможностей и рендеринга
Другие статьи про frontend для продвинутых:
