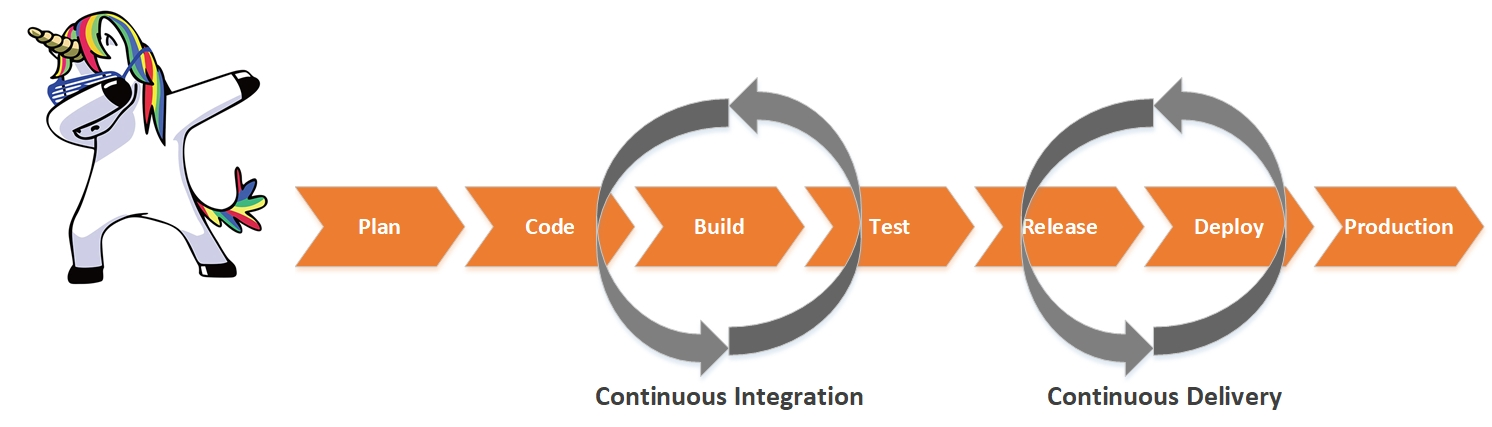
Сейчас на хайпе тема DevOps. Конвейер непрерывной интеграции и доставки CI/CD внедряют все, кому не лень. Но большинство не всегда уделяют должное внимание обеспечению надежности работы информационных систем на различных этапах CI/CD Pipeline. В данной статье я хотел бы поговорить о своем опыте автоматизации проверок качества ПО и реализации возможных сценариев по его «самовосстановлению».
 Источник
Источник
Я работаю инженером в отделе управления ИТ-услугами в компании «ЛАНИТ-Интеграция». Мое профильное направление — внедрение различных систем мониторинга производительности и доступности приложений. Я часто общаюсь с ИТ-заказчиками из разных сегментов рынка на предмет актуальных вопросов по мониторингу качества их ИТ-сервисов. Основная задача — минимизировать время цикла релиза и увеличить частоту их выпуска. Это, конечно, все хорошо: больше релизов – больше новых фич — больше довольных пользователей — больше прибыли. Но на деле не всегда все получается хорошо. При очень высоких темпах развертывания сразу всплывает вопрос о качестве наших релизов. Даже при полностью автоматизированном конвейере одна из самых больших проблем — перевод сервисов из тестирования в производство, не влияющий при этом на время безотказной работы и взаимодействие пользователей с приложением.
По итогам многочисленных бесед с заказчиками я могу сказать, что контроль качества релизов, проблема надежности приложения и возможность его «самовосстановления» (например, откат к стабильной версии) на различных этапах конвейера CI/CD – среди самых волнующих и актуальных тем.
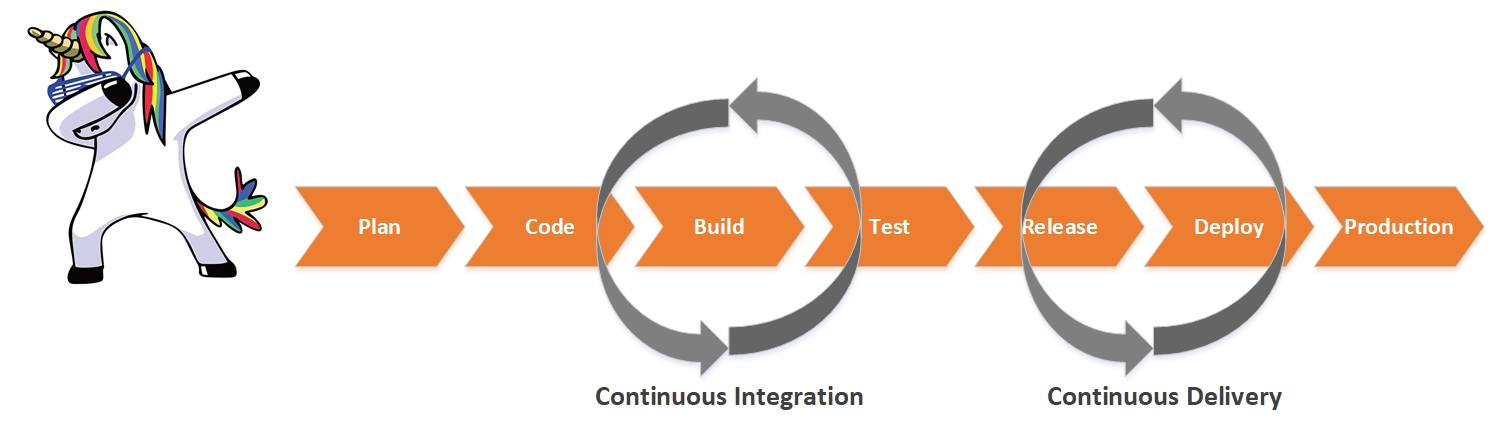
Недавно я сам работал на стороне заказчика — в службе сопровождения прикладного ПО онлайн-банка. В архитектуре нашего приложения использовалось большое количество самописных микросервисов. Самое печальное, что не все разработчики справлялись с высокими темпами разработки, качество некоторых микросервисов страдало, что порождало смешные прозвища для них и их создателей. Появлялись байки, о том, из каких материалов создаются данные продукты.

Высокая частота релизов и большое количество микросервисов вносят трудности в понимание работы приложения в целом, как на этапе тестирования, так и на этапе эксплуатации. Изменения происходят постоянно и контролировать их без хороших инструментов мониторинга очень трудно. Часто после ночного релиза утром разработчики сидят как на пороховой бочке и ждут, чтобы ничего не сломалось, хотя на этапе тестирования все проверки были успешными.
Есть еще один момент. На этапе тестирования проверяют работоспособность ПО: выполнение основных функций приложения и отсутствие ошибок. Качественные оценки производительности либо отсутствуют, либо не учитывают все аспекты работы приложения и интеграционный слой. Некоторые метрики вообще могут не проверяться. В итоге при возникновении поломки в продуктивной среде отдел технической поддержки узнает об этом только когда реальные пользователи начинают жаловаться. Хочется минимизировать влияние некачественного ПО на конечных пользователей.
Один из путей решения – это внедрять процессы проверки качества ПО на различных этапах CI/CD Pipeline, добавлять различные сценарии по восстановлению системы при возникновении аварий. Также помним, что у нас DevOps. Бизнес ожидает максимально быстрого получения нового продукта. Поэтому все наши проверки и сценарии должны быть автоматизированы.
Задача разбивается на две составляющие:
Для того, чтобы реализовать поставленные задачи, требуется система мониторинга, способная обнаруживать проблемы и передавать их в системы автоматизации на различных этапах конвейера CI/CD. Также положительным моментом будет, если данная система предоставит полезные метрики для различных команд: разработки, тестирования, эксплуатации. И совсем замечательно, если и для бизнеса.
Для сбора метрик можно использовать совокупность различных систем (Prometheus, ELK Stack, Zabbix и тд), но, на мой взгляд, под данные задачи лучше всего подходят решения класса APM (Application Performance Monitoring), которые способны сильно упростить вам жизнь.
В рамках моей работы в службе сопровождения я начинал делать аналогичный проект, используя решение класса APM от компании Dynatrace. Сейчас, работая в интеграторе, я достаточно хорошо знаю рынок систем мониторинга. Мое субъективное мнение: Dynatrace лучше всего подходит для решения таких задач.
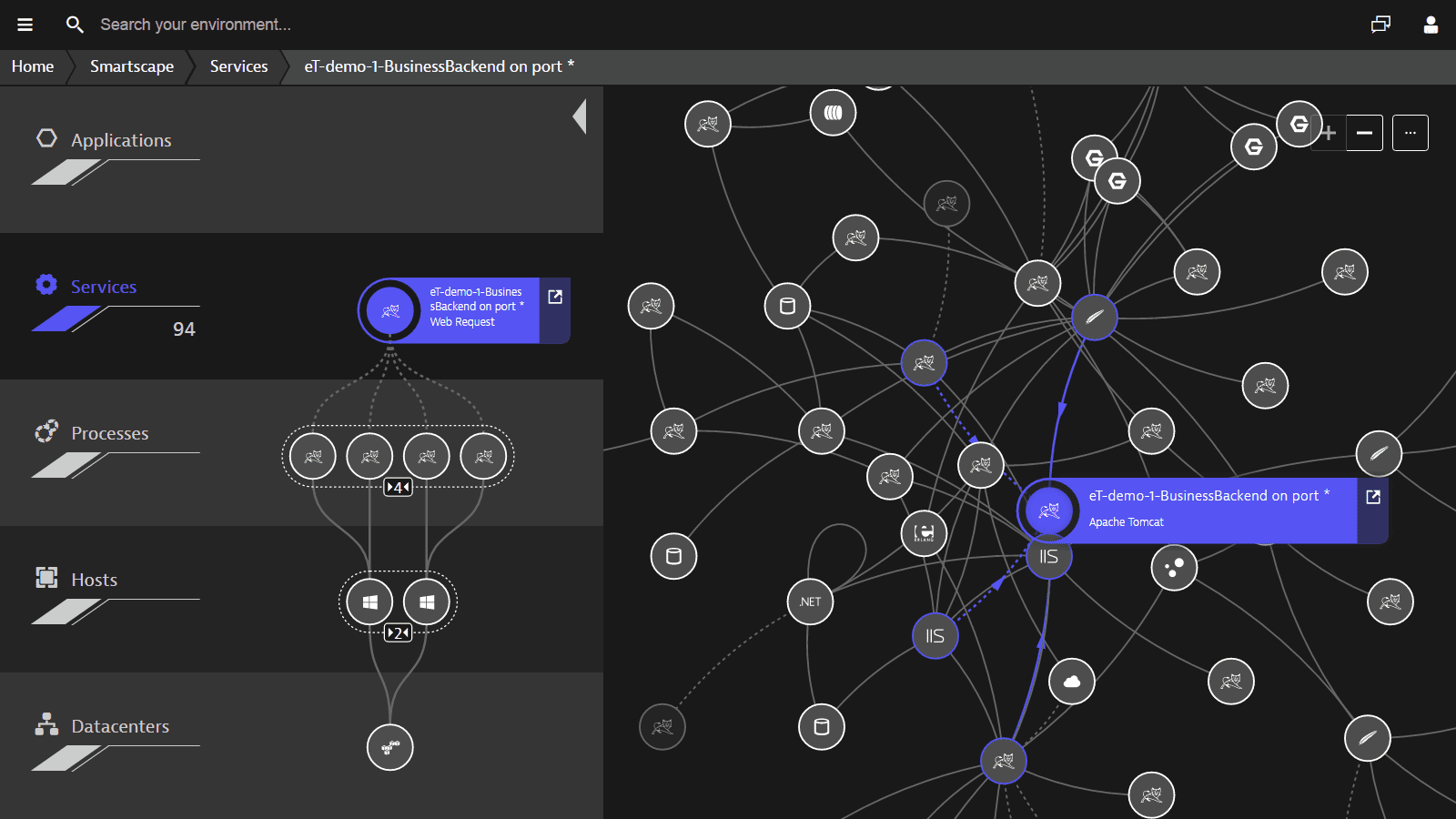
Решение Dynatrace предоставляет горизонтальное отображение каждой пользовательской операции с глубокой степенью детализации до уровня выполнения кода. Можно отследить всю цепочку взаимодействия между различными информационными сервисами: от уровней фронтенд веб- и мобильных приложений, back-end серверов приложений, интеграционной шиной до конкретного вызова в БД.
 Источник. Автоматическое построение всех зависимостей между компонентами системы
Источник. Автоматическое построение всех зависимостей между компонентами системы
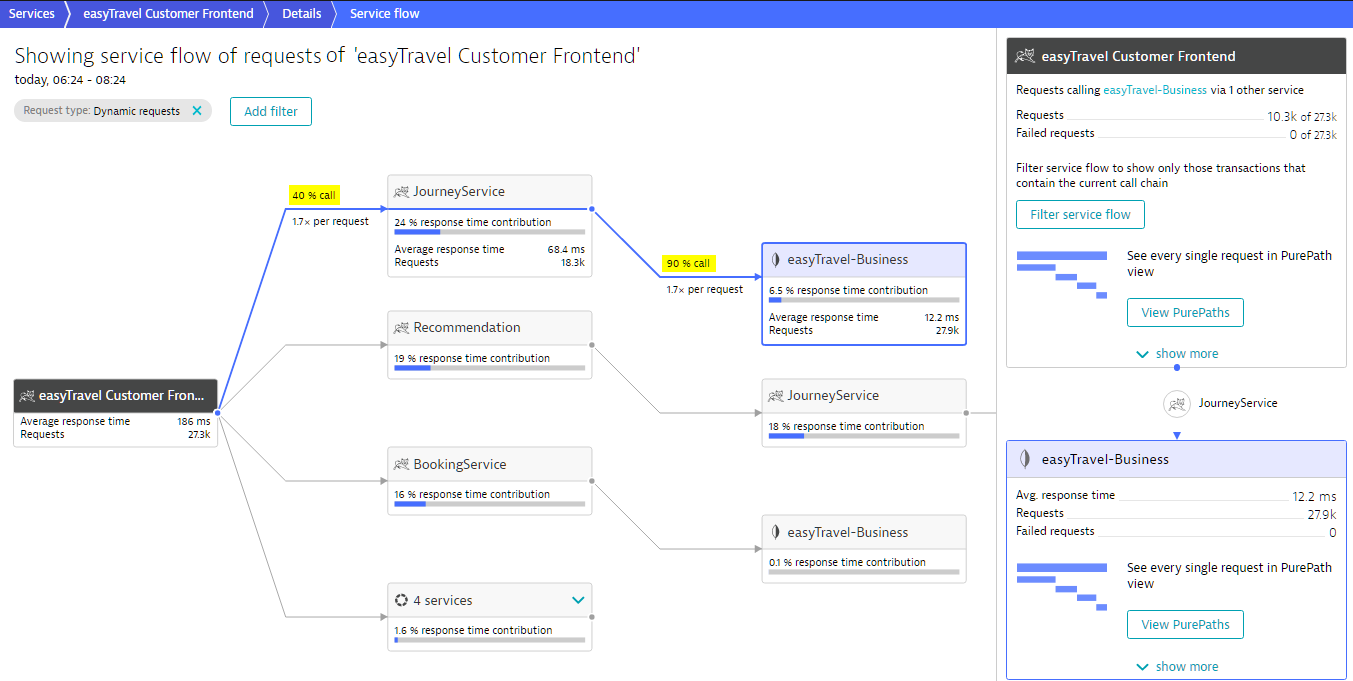 Источник. Автоматическое определение и построение пути прохождения операции сервиса
Источник. Автоматическое определение и построение пути прохождения операции сервиса
Также помним, что нам необходимо интегрироваться с различными инструментами автоматизации. Тут решение имеет удобный API, который позволяет отдавать и получать различные метрики и события.
Далее перейдем к более подробному рассмотрению, как решать поставленные задачи с помощью системы Dynatrace.
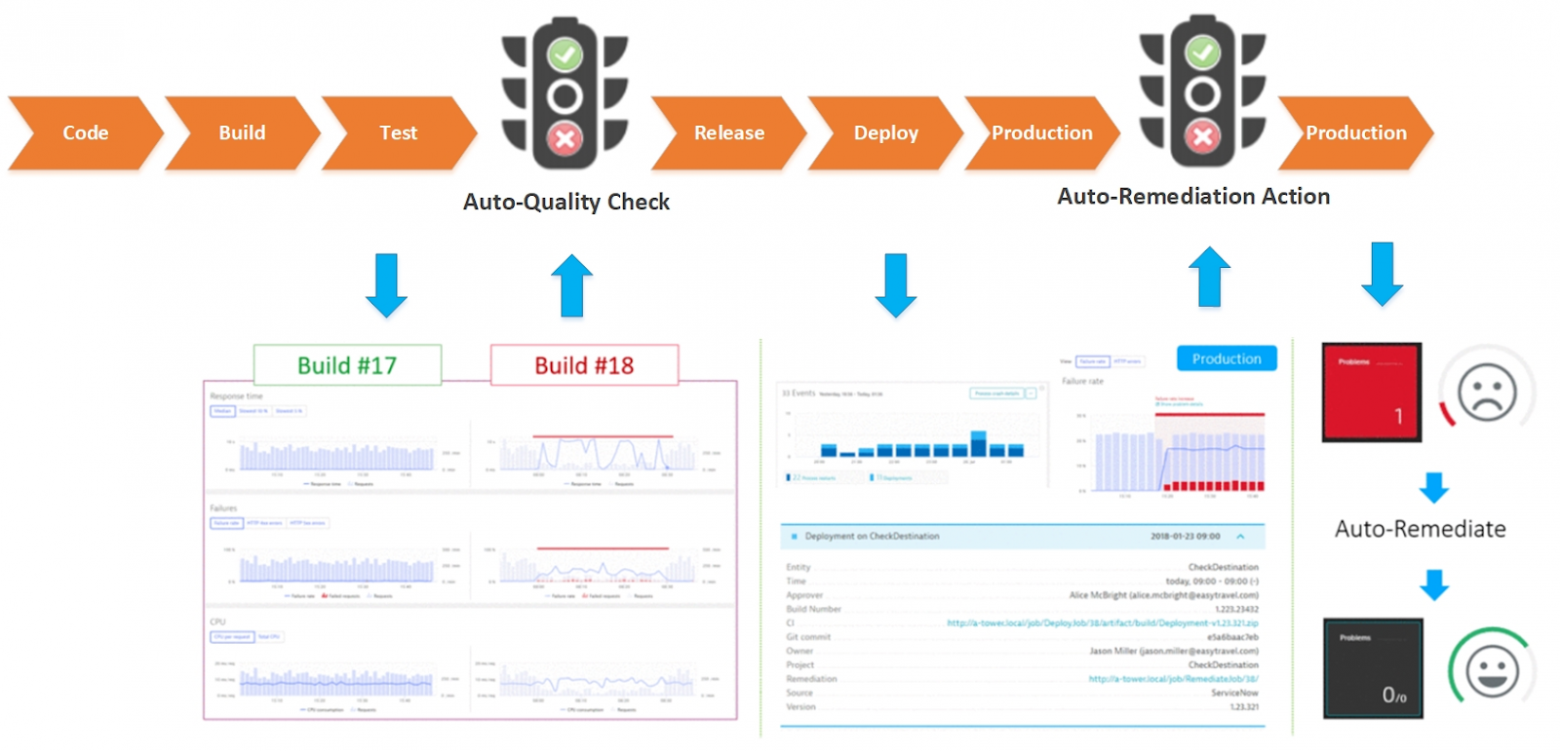
Первая задача – это найти проблемы как можно раньше на этапах конвейера доставки приложения. Только «хорошие» сборки кода должны достигать прод среды. Для этого в ваш pipeline на этапе тестирования должны быть включены дополнительные мониторы по проверки качества ваших сервисов.

Рассмотрим по шагам, как это реализовать и автоматизировать данный процесс:
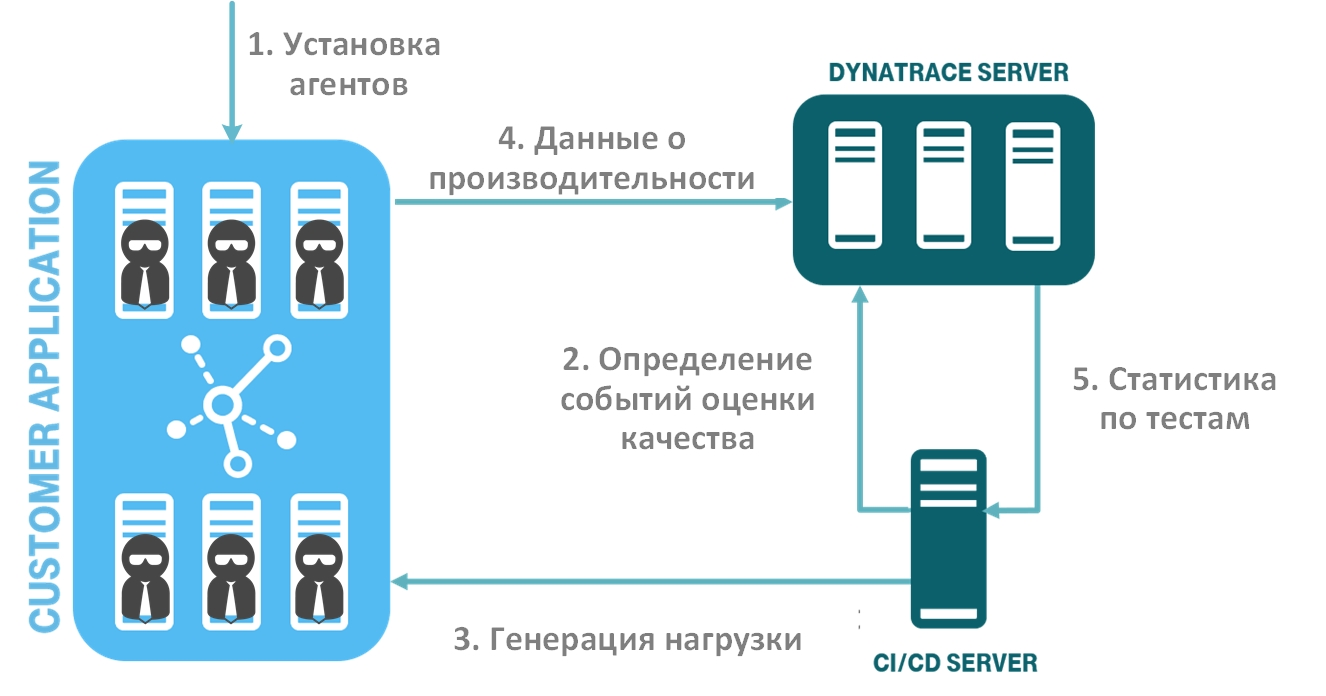 Источник
Источник
На рисунке показан поток автоматизированных шагов проверки качества ПО:
Шаг 1. Разворачивание системы мониторинга
Сначала необходимо установить агенты в вашу тестовую среду. При этом решение Dynatrace имеет приятную особенность – оно использует универсальный агент OneAgent, который устанавливается на OS инстанс (Windows, Linux, AIX), автоматически обнаруживает ваши сервисы и начинает собирать данные мониторинга по ним. Вам не требуется настраивать отдельно агент для каждого процесса. Аналогичная ситуация будет для облачных и контейнерных платформ. При этом процесс установки агентов вы также можете автоматизировать. Dynatrace отлично вписывается в концепт «инфраструктура как код» (Infrastructure as code или IaC): есть уже готовые скрипты и инструкции под все популярные платформы. Встраиваете агент в конфигурацию вашего сервиса, и при его развертывании вы сразу получаете новый сервис с уже работающим агентом.
Шаг 2. Определение событий оценки качества вашего ПО
Теперь необходимо определиться с перечнем сервисов и бизнес-операций. Важно учитывать именно те операции пользователей, которые являются бизнес-критичными для вашего сервиса. Тут рекомендую проконсультироваться с бизнес- и системными аналитиками.
Далее необходимо определить, какие метрики вы хотите включить в проверку для каждого из уровней. Например, это могут быть время выполнения (с разделением на среднее, медиану, перцентили и др.), ошибки (логические, сервисные, инфраструктурные и др.) и различные инфраструктурные метрики (memory heap, garbage collector, thread count и др.).
Для автоматизации и удобства использования командой DevOps появляется концепция «Мониторинг как код». Что я под этим подразумеваю — разработчик/тестировщик может написать простой JSON файл, который определяет показатели проверки качества ПО.
Давайте рассмотрим пример такого JSON-файла. В качестве пары ключ/значение используются объекты из Dynatrace API (описание API можно посмотреть тут Dynatrace API).
Файл представляет собой массив определений временных рядов (timeseries):
На следующем рисунке представлен пример использования таких трешолдов.
 Источник
Источник
Шаг 3. Генерация нагрузки
После того, как мы определи уровни качества нашего сервиса, необходимо сгенерировать тестовую нагрузку. Вы можете использовать любой из удобных вам инструментов тестирования, например, Jmeter, Selenium, Neotys, Gatling и т.д.
Система мониторинга Dynatrace позволяет захватывать различные метаданные из ваших тестов и распознавать, какой из тестов относится к какому циклу релиза и какому сервису. Рекомендуется добавлять дополнительные заголовки в HTTP-запросы теста.
На следующем рисунке представлен пример, где с помощью дополнительного заголовка X-Dynatrace-Test мы помечаем, что этот тест относится к тестированию операции по добавлению товара в корзину.
 Источник
Источник
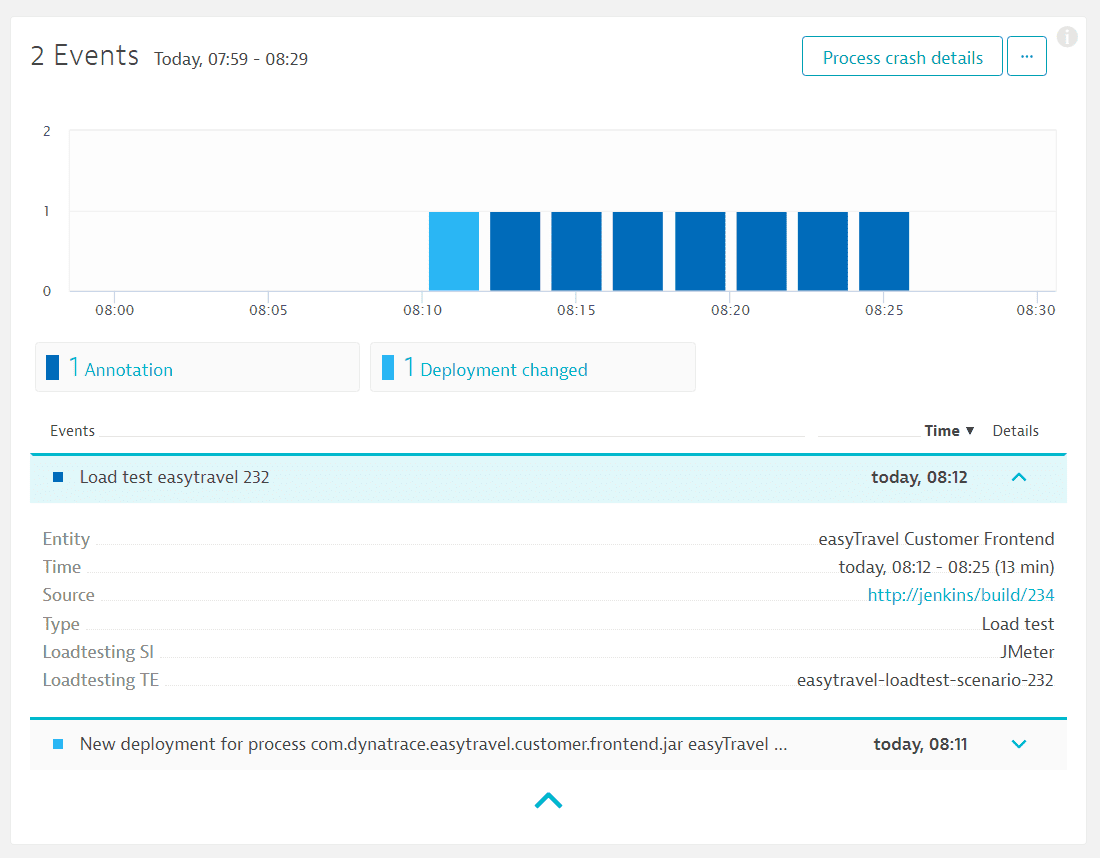
При запуске каждого нагрузочного теста вы отправляете дополнительную контекстную информацию в Dynatrace с помощью API события из сервера CI/CD. Таким образом, система может различать различные тесты между собой.
 Источник. Событие в системе мониторинга о запуске нагрузочного тестирования
Источник. Событие в системе мониторинга о запуске нагрузочного тестирования
Шаг 4-5. Сбор данных о производительности и передача данных в систему CI/CD
Вместе с генерированным тестом в систему мониторинга передается событие о необходимости сбора данных о проверки показателей качества сервиса. Также указывается наш JSON-файл, в котором определены ключевые метрики.
 Событие о необходимости проверки качества ПО формируемое на сервере CI/CD для отправки в систему мониторинга
Событие о необходимости проверки качества ПО формируемое на сервере CI/CD для отправки в систему мониторинга
В нашем примере событие о проверки качества называется perfSigDynatraceReport (Performance_Signature) – это готовый плагин для интеграции с Jenkins, который разработали ребята из T-Systems Multimedia Solutions. В каждом событии о запуске проверки содержится информация о сервисе, номере сборке, времени тестирования. Плагин собирает значения производительности во время сборки, оценивает их и сравнивает результат с предыдущими сборками и нефункциональными требованиями.
 Событие в системе мониторинга о старте проверки качества сборки. Источник
Событие в системе мониторинга о старте проверки качества сборки. Источник
После завершения теста все метрики по оценке качества ПО передаются назад в систему непрерывной интеграции, например, Jenkins, которая формирует отчет по результатам.
 Результат статистики по сборкам на сервере CI/CD. Источник
Результат статистики по сборкам на сервере CI/CD. Источник
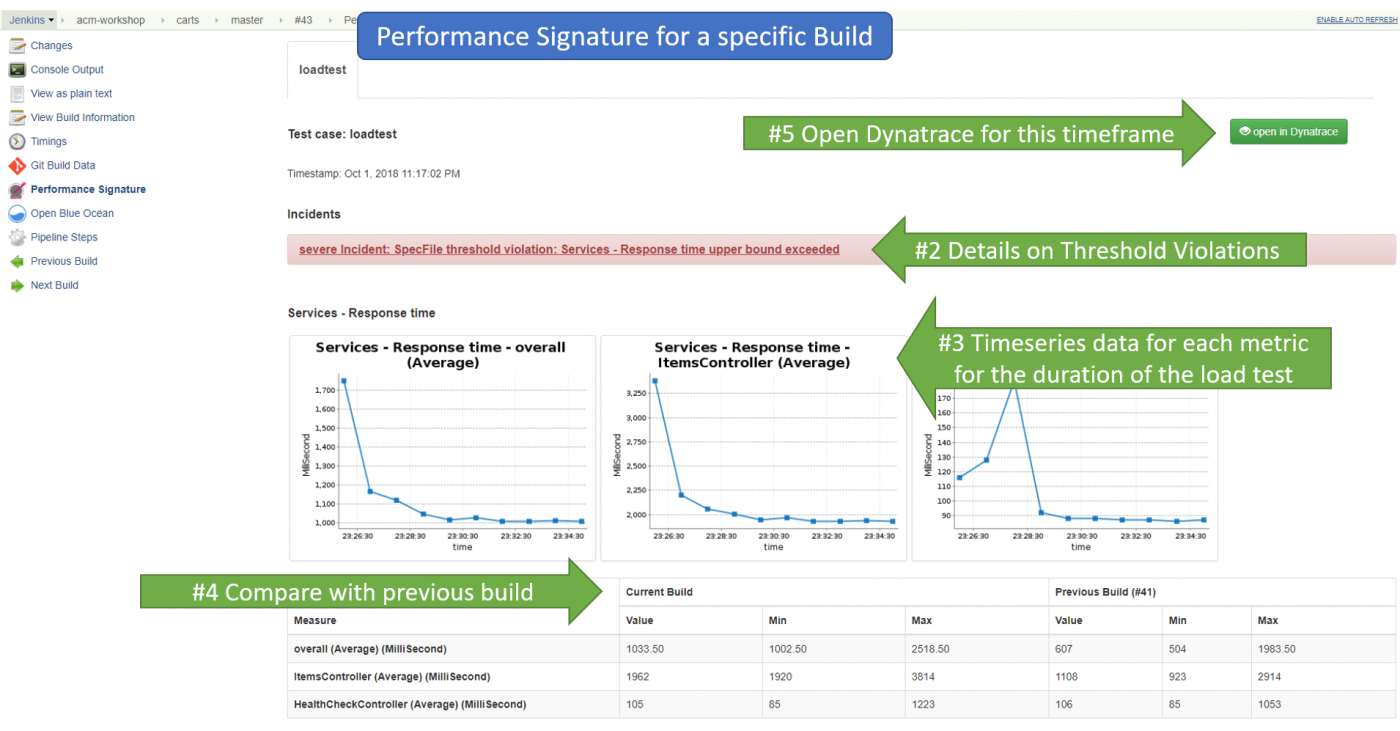
Для каждой отдельной сборки мы видим статистику по каждой заданной нами метрике на протяжении выполнения всего теста. Мы также видим, если были нарушения в определенных пороговых значениях (warning и severe-трешолды). На основе совокупных показателей вся сборка помечается как стабильная, нестабильная или провальная. Также для удобства вы можете добавить в отчет показатели сравнения текущей сборки с предыдущей.
 Просмотр детализированной статистики по сборкам на сервере CI/CD. Источник
Просмотр детализированной статистики по сборкам на сервере CI/CD. Источник
Детализированное сравнение двух сборок
При необходимости можно перейти в интерфейс Dynatrace и там более детально просмотреть статистику по каждой вашей сборке и сравнить их между собой.
 Сравнение статистики по сборкам в Dynatrace. Источник
Сравнение статистики по сборкам в Dynatrace. Источник
Выводы
В итоге мы получаем сервис «мониторинг как услуга», автоматизированный в конвейере непрерывной интеграции. Разработчику или тестировщику необходимо только определить список метрик в JSON-файле, а все остальное происходит автоматически. Мы получаем прозрачный контроль качества релизов: все уведомления о производительности, потреблении ресурсов или архитектурных регрессиях.
Итак, мы решили задачу, как автоматизировать процесс мониторинга на этапе тестирования в Pipeline. Таким образом мы минимизируем процент некачественных сборок, доходящих до прод среды.
Но что делать, если плохое ПО все же дошло до прода, ну или просто что-то ломается. Для утопии нам хотелось, чтобы присутствовали механизмы автоматического обнаружения проблем и по возможности система сама восстанавливала свою работоспособность, хотя бы ночью.
Для этого нам надо по аналогии с предыдущим разделом предусмотреть автоматические проверки качества ПО в прод среде и заложить под них сценарии по самовосстановлению системы.

Автоисправление как код
В большинстве компаний уже присутствует накопленная база знаний по различным типам распространённых проблем и список действий по их исправлению, например, перезапуск процессов, очистка ресурсов, откат версий, восстановление неверных изменений конфигурации, увеличение или уменьшение количества компонентов в кластере, переключение синего или зеленого контура и др.
Несмотря на то, что эти варианты использования известны уже много лет многим командам, с которыми я общаюсь, лишь немногие задумывались и вложили средства в их автоматизацию.
Если подумать, то в реализации процессов по самовосстановлению работоспособности приложения нет ничего сверхсложного, необходимо уже известные сценарии работы ваших админов представить в виде сценариев кода (концепция «автоисправление как код»), которые вы заранее написали для каждого конкретного случая. Сценарии автоматического исправления должны быть направлены на устранение первопричины проблемы. Вы сами устанавливаете правильные действия реагирования на инцидент.
В качестве триггера для запуска сценария может выступать любая метрика из вашей системы мониторинга, главное, чтобы эти метрики точно определяли, что все плохо, так как не хотелось бы получить ложные срабатывания в продуктивной среде.
Вы можете использовать любую систему или совокупность систем: Prometheus, ELK Stack, Zabbix и т.д. Но я приведу несколько примеров на основе решения APM (в качестве примера опять будет Dynatrace), которое также поможет облегчить вашу жизнь.
Во-первых, тут есть все, что касается работоспособности с точки зрения работы приложения. Решение предоставляет сотни метрик на различных уровнях, которые вы можете использовать в качестве триггеров:
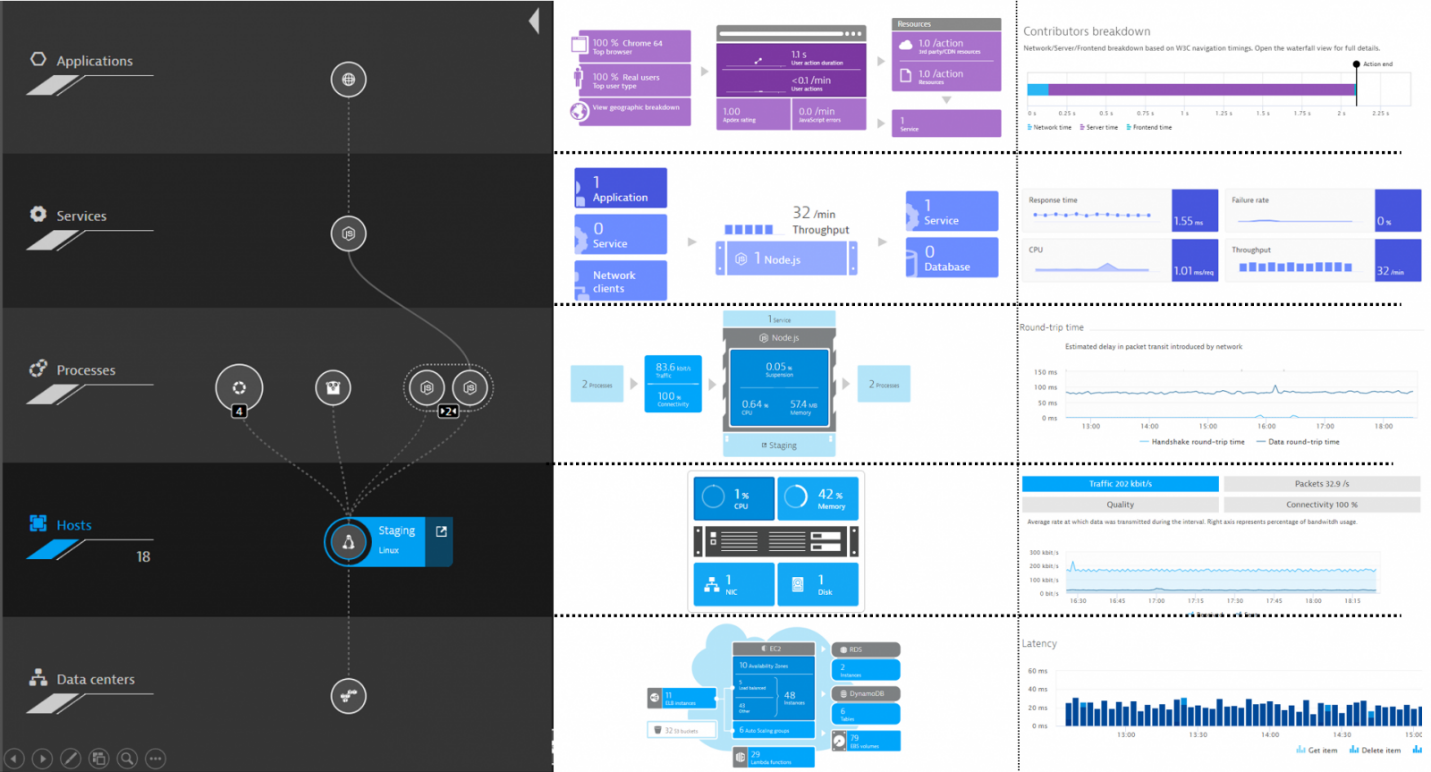 Уровни мониторинга в Dynatrace. Источник
Уровни мониторинга в Dynatrace. Источник
Во-вторых, как я говорил ранее, Dynatrace имеет открытый API, который позволяет очень удобно интегрировать его с различными сторонними системами. Например, отправка уведомления в систему автоматизации при превышении контрольных параметров.
Ниже представлен пример для взаимодействия с Ansible.
 Источник
Источник
Далее приведу несколько примеров, какие именно автоматизации можно делать. Это всего лишь часть кейсов, их перечень в вашей среде может ограничиваться только вашей фантазией и возможностями ваших инструментов мониторинга.
1. Плохой deploy – откат версии
Даже если мы все очень хорошо проверяем в тестовой среде, то все равно есть шанс, что новый релиз может убить ваше приложение в прод среде. Тот же человеческий фактор никто не отменял.
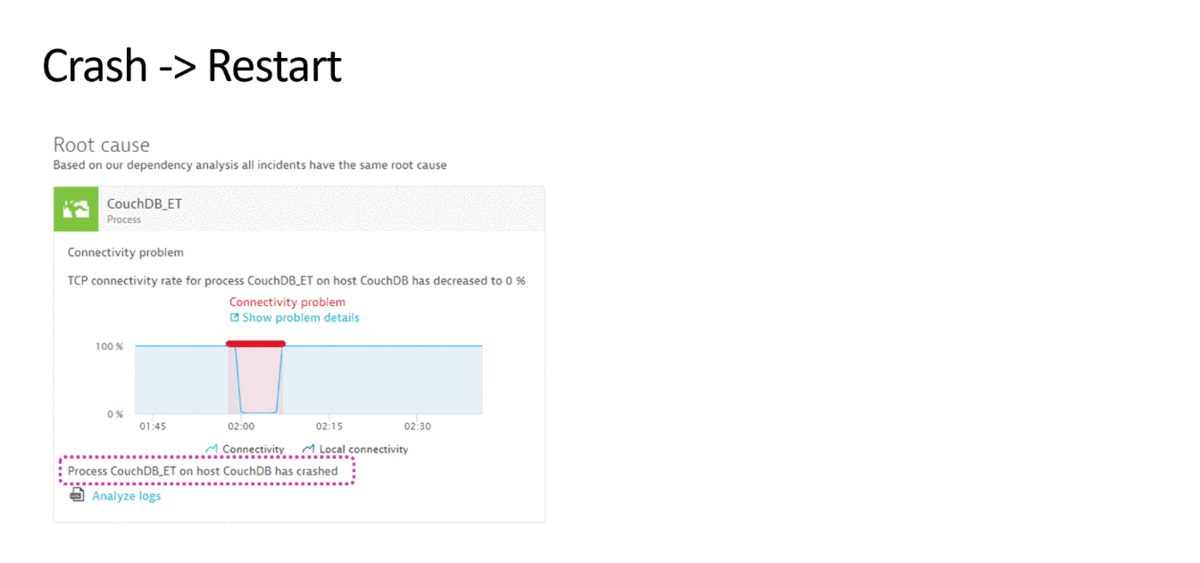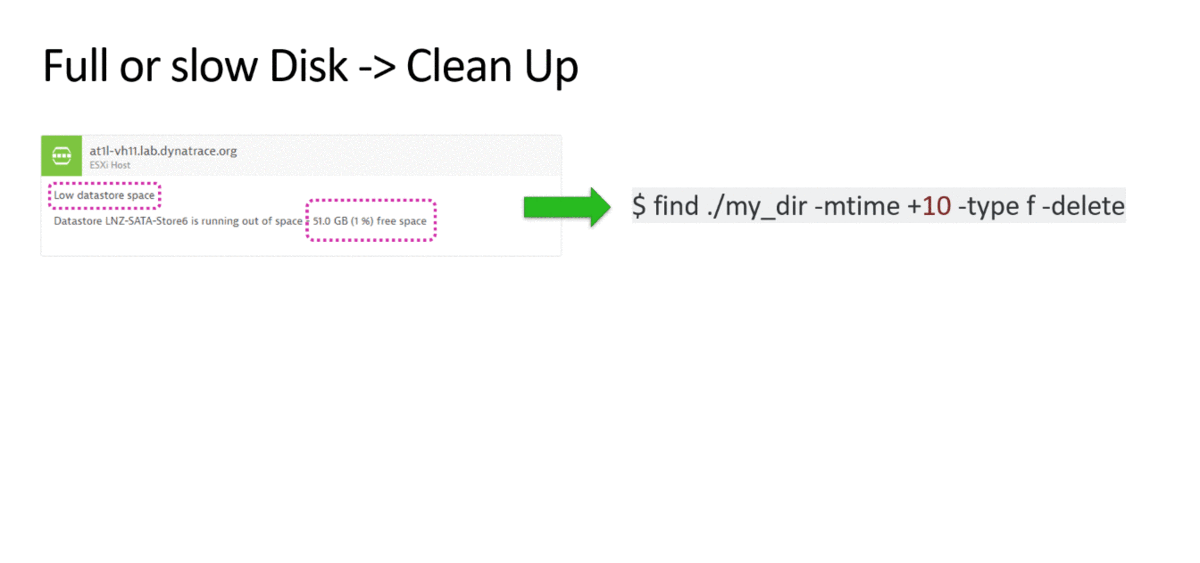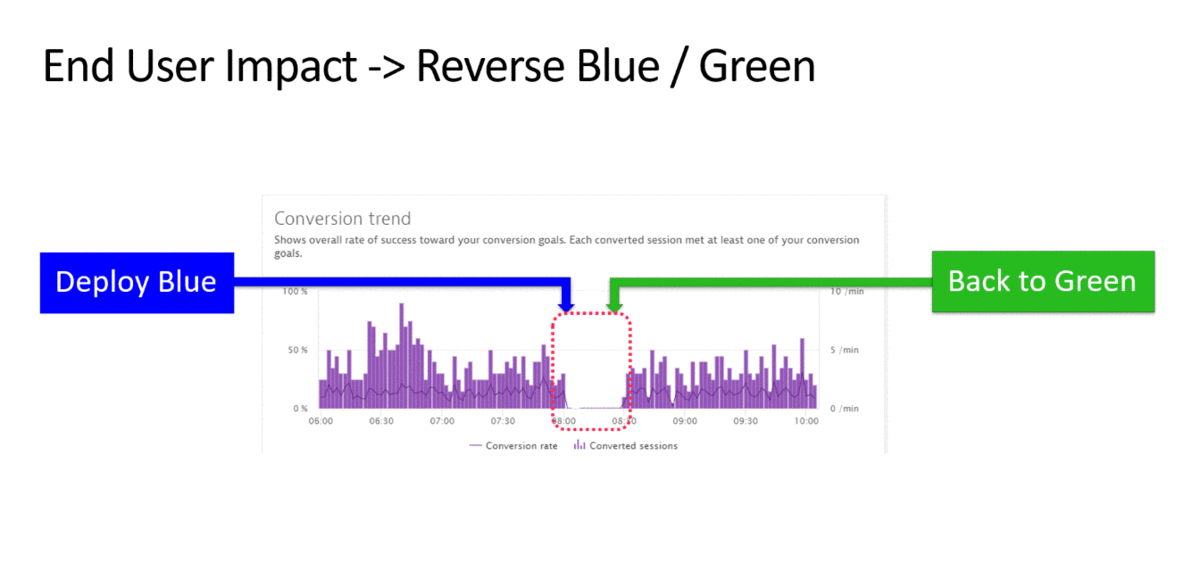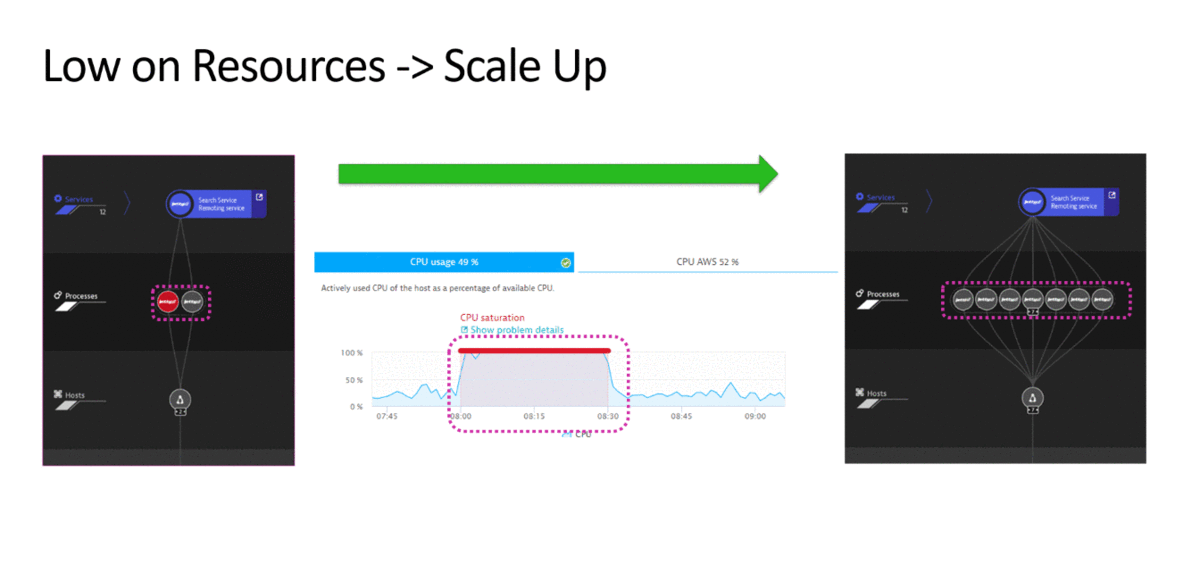
На следующем рисунке мы видим, что происходит резкий скачок времени выполнения операций на сервисе. Начало этого скачка совпадает с временем деплоя на приложение. Всю эту информацию в качестве событий мы передаем в систему автоматизации. Если работоспособность сервиса не нормализуется по истечении заданного нами времени, то автоматически вызывается скрипт, который производит откат версии до старой.
 Деградация производительности операций после деплоя. Источник
Деградация производительности операций после деплоя. Источник
2. Загрузка ресурсов под 100% — добавить ноду в маршрутизацию
На следующем примере система мониторинга определяет, что на одном из компонентов наблюдается загрузка CPU на 100%.
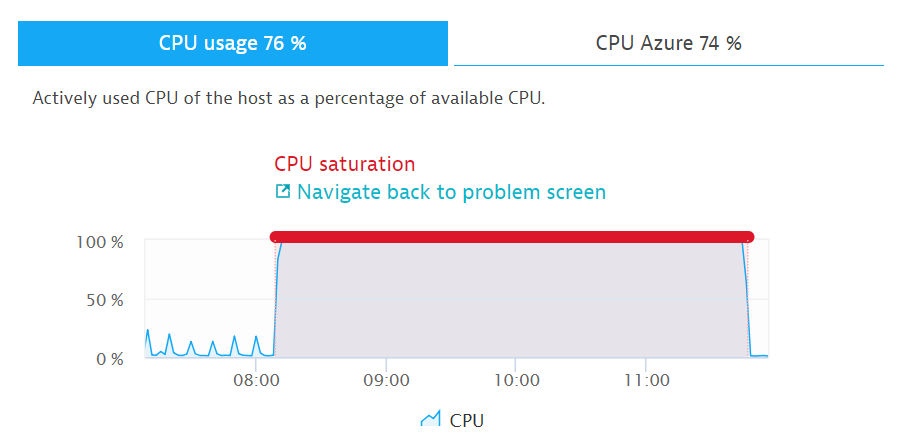 Загрузка CPU 100%
Загрузка CPU 100%
По данному событию возможно несколько различных сценариев. Например, система мониторинга проверяет дополнительно, связана ли нехватка ресурсов с ростом нагрузки на сервис. Если, да то выполняется скрипт, который автоматически добавляет ноду в маршрутизацию, тем самым восстанавливая работоспособность системы в целом.
 Масштабирование нод после инцидента
Масштабирование нод после инцидента
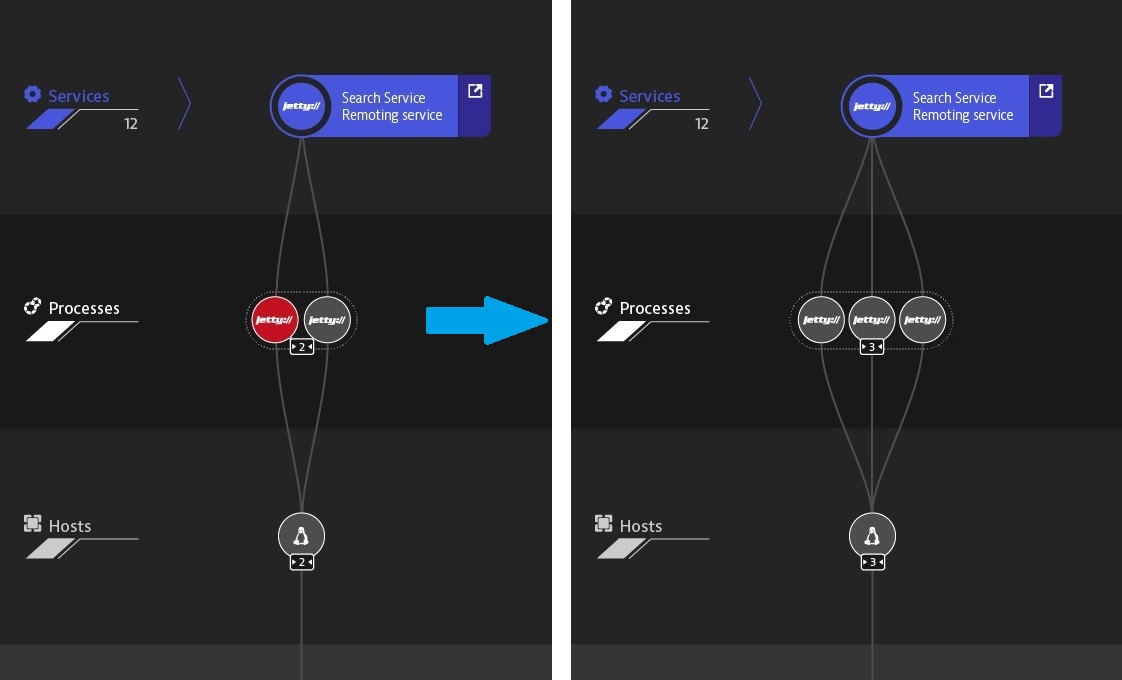
3. Отсутствие места на жестком диске – чистка диска
Я думаю, что данные процессы у многих уже автоматизированы. С помощью APM тоже можно следить за свободным местом на дисковой подсистеме. При отсутствии места или медленной работе диска вызываем скрипт для чистки или добавляем место.

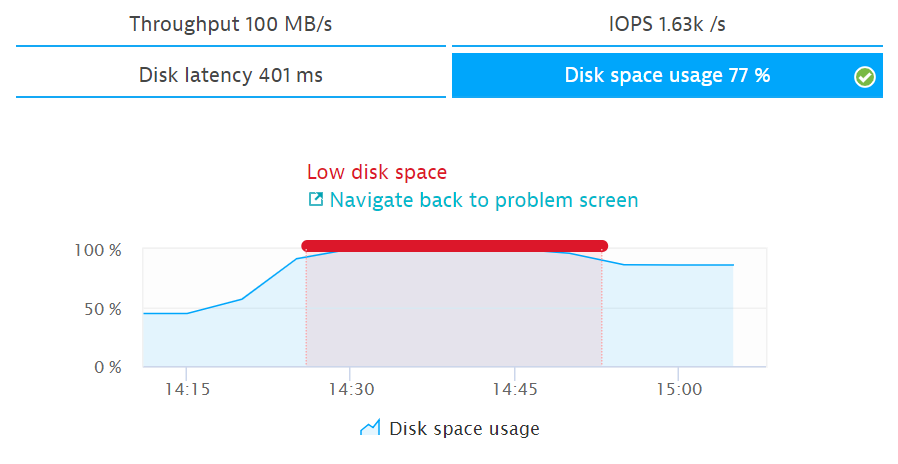 Загрузка диска 100%
Загрузка диска 100%
4. Низкая активность пользователей или низкая конверсия – переключение между синей и зеленой веткой
Я часто встречаю заказчиков, использующих два контура (blue-green deploy) для приложений в прод среде. Это позволяет быстро переключаться между ветками при доставке новых релизов. Часто после деплоя могут произойти кардинальные изменения, которые не сразу удается заметить. При этом деградация по производительности и доступности может не наблюдаться. Для оперативного реагирования на такие изменения лучше использовать различные метрики, отражающие поведения пользователей (количество сессий и действий пользователей, конверсия, bounce rate). На следующем рисунке показан пример, на котором при падении конверсии происходит переключение между ветками ПО.
 Падение конверсии после переключения между ветками ПО. Источник
Падение конверсии после переключения между ветками ПО. Источник
Механизмы автоматического определения проблем
В конце приведу еще один пример, за что мне больше всего нравится Dynatrace.
В части моего рассказа про автоматизацию проверки качества сборок в тестовой среде все пороговые значения мы определяли в ручном режиме. Для тестовой среды это нормально, тестировщик сам определяет показатели перед каждой проверкой в зависимости от нагрузки. В прод среде желательно, чтобы проблемы обнаруживались автоматический с учетом различных механизмов baseline.
Dynatrace имеет интересные встроенные инструменты искусственного интеллекта, которые на основе механизмов определения аномальных метрик (baselining) и построения карты взаимодействия между всеми компонентами, сопоставляя и коррелируя события между собой, определяют аномалии в работе вашего сервиса и предоставляют детализированную информацию по каждой проблеме и корневой причине.
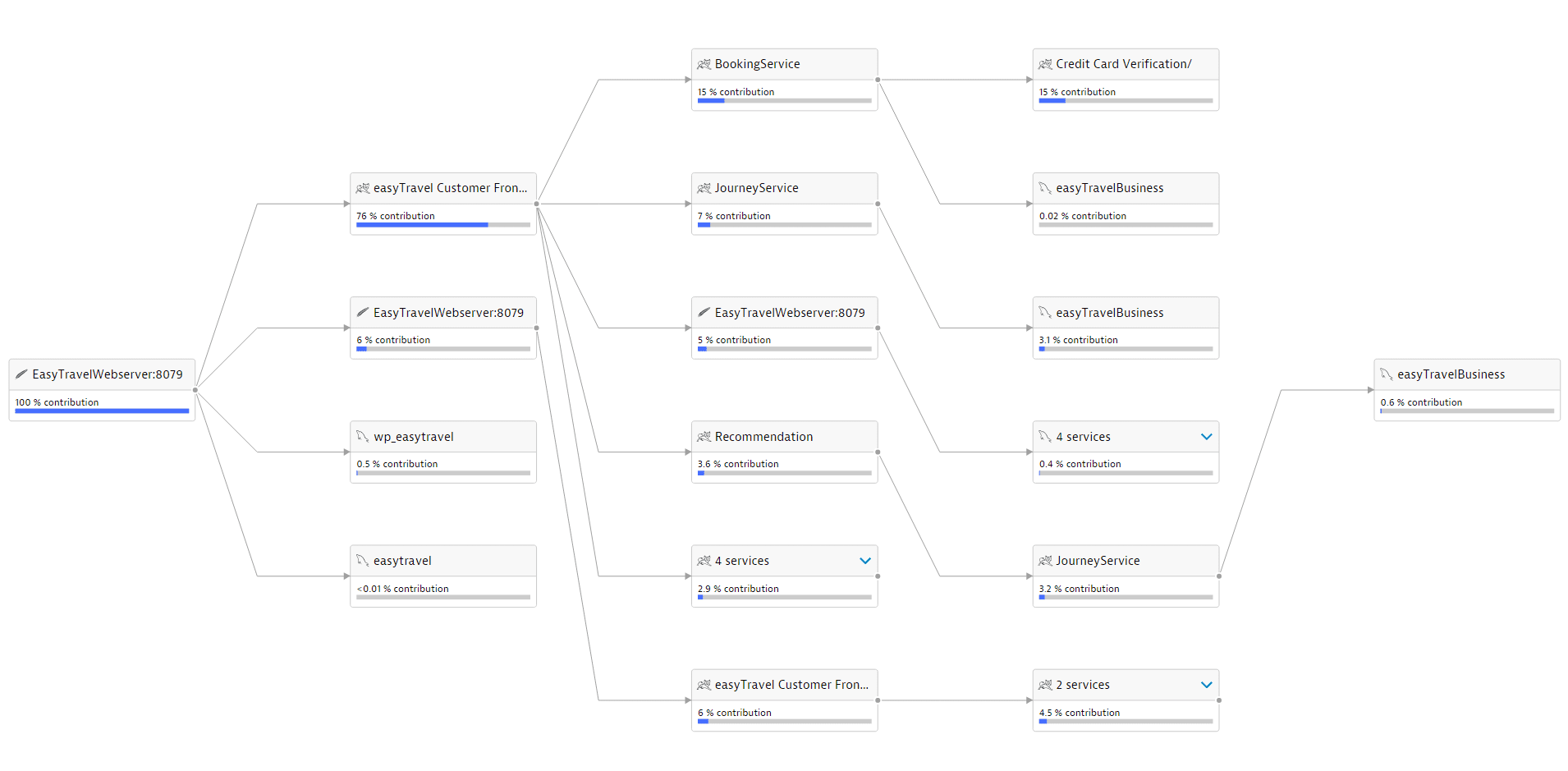
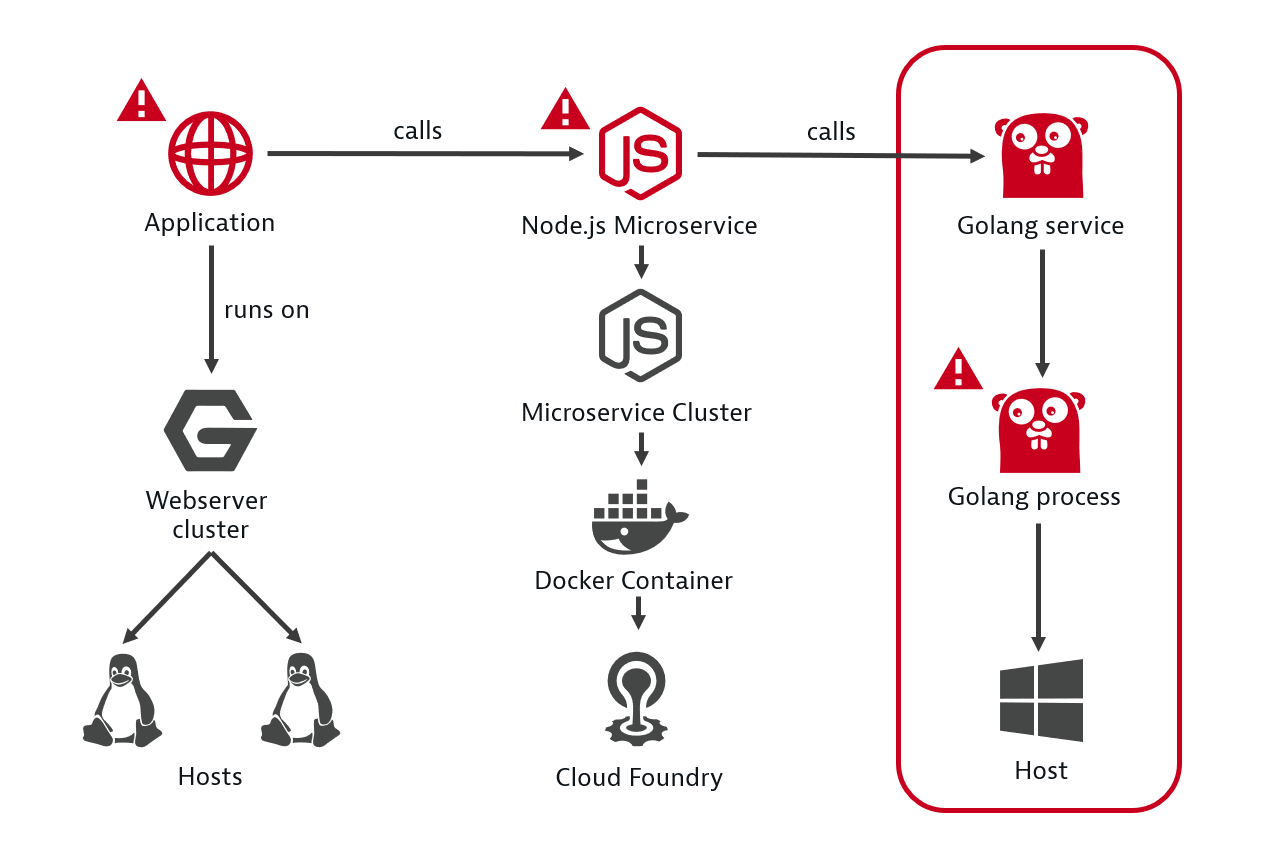
Путем автоматического анализа зависимостей между компонентами Dynatrace определяет не только то, является ли проблемная служба основной причиной, но и ее зависимость от других служб. В приведенном ниже примере Dynatrace автоматически отслеживает и оценивает работоспособность каждого сервиса в рамках выполнения транзакций, идентифицирует службу Golang в качестве основной причины.
 Пример определения корневой причины сбоя. Источник
Пример определения корневой причины сбоя. Источник
На следующем рисунке изображен процесс мониторинга проблем с вашим приложением со старта инцидента.
 Визуализация возникающей проблемы с отображением всех компонентов и событий на них
Визуализация возникающей проблемы с отображением всех компонентов и событий на них
Система мониторинга собрала полную хронологию событий по возникшей проблеме. В окне под временным графиком мы видим все ключевые события на каждом из компонентов. По данным событиям вы можете задать процедуры для автоматического исправления в виде сценариев кода.
Дополнительно советую интегрировать систему мониторинга с Service Desk или баг-трекер. При возникновении проблемы разработчики оперативно получают полную информацию для ее анализа на уровне кода в прод среде.
В итоге у нас получился конвейер CI/CD со встроенными автоматизированными проверками качества ПО в Pipeline. Мы минимизируем количество некачественных сборок, повышаем надежность системы в целом и, если у нас все-таки нарушается работоспособность системы, мы запускаем механизмы по ее восстановлению.
В автоматизацию мониторинга качества ПО точно стоит вкладывать усилия, не всегда это быстрый процесс, но со временем он принесет свои плоды. Рекомендую после решения нового инцидента в прод среде сразу продумать о том, какие мониторы добавить для проверок в тестовой среде во избежание попадания плохой сборки в прод, а также составить скрипт для автоматического исправления данных проблем.
Надеюсь, мои примеры помогут вам в ваших начинаниях. Также мне будет интересно увидеть ваши примеры используемых метрик для реализации самовосстановления работоспособности систем.
 Источник
Источник

Я работаю инженером в отделе управления ИТ-услугами в компании «ЛАНИТ-Интеграция». Мое профильное направление — внедрение различных систем мониторинга производительности и доступности приложений. Я часто общаюсь с ИТ-заказчиками из разных сегментов рынка на предмет актуальных вопросов по мониторингу качества их ИТ-сервисов. Основная задача — минимизировать время цикла релиза и увеличить частоту их выпуска. Это, конечно, все хорошо: больше релизов – больше новых фич — больше довольных пользователей — больше прибыли. Но на деле не всегда все получается хорошо. При очень высоких темпах развертывания сразу всплывает вопрос о качестве наших релизов. Даже при полностью автоматизированном конвейере одна из самых больших проблем — перевод сервисов из тестирования в производство, не влияющий при этом на время безотказной работы и взаимодействие пользователей с приложением.
По итогам многочисленных бесед с заказчиками я могу сказать, что контроль качества релизов, проблема надежности приложения и возможность его «самовосстановления» (например, откат к стабильной версии) на различных этапах конвейера CI/CD – среди самых волнующих и актуальных тем.
Недавно я сам работал на стороне заказчика — в службе сопровождения прикладного ПО онлайн-банка. В архитектуре нашего приложения использовалось большое количество самописных микросервисов. Самое печальное, что не все разработчики справлялись с высокими темпами разработки, качество некоторых микросервисов страдало, что порождало смешные прозвища для них и их создателей. Появлялись байки, о том, из каких материалов создаются данные продукты.

«Постановка задачи»
Высокая частота релизов и большое количество микросервисов вносят трудности в понимание работы приложения в целом, как на этапе тестирования, так и на этапе эксплуатации. Изменения происходят постоянно и контролировать их без хороших инструментов мониторинга очень трудно. Часто после ночного релиза утром разработчики сидят как на пороховой бочке и ждут, чтобы ничего не сломалось, хотя на этапе тестирования все проверки были успешными.
Есть еще один момент. На этапе тестирования проверяют работоспособность ПО: выполнение основных функций приложения и отсутствие ошибок. Качественные оценки производительности либо отсутствуют, либо не учитывают все аспекты работы приложения и интеграционный слой. Некоторые метрики вообще могут не проверяться. В итоге при возникновении поломки в продуктивной среде отдел технической поддержки узнает об этом только когда реальные пользователи начинают жаловаться. Хочется минимизировать влияние некачественного ПО на конечных пользователей.
Один из путей решения – это внедрять процессы проверки качества ПО на различных этапах CI/CD Pipeline, добавлять различные сценарии по восстановлению системы при возникновении аварий. Также помним, что у нас DevOps. Бизнес ожидает максимально быстрого получения нового продукта. Поэтому все наши проверки и сценарии должны быть автоматизированы.
Задача разбивается на две составляющие:
- контроль качества сборок на этапе тестирования (автоматизировать процесс отлавливания некачественных сборок);
- контроль качества ПО в прод среде (механизмы автоматического обнаружения проблем и возможные сценарии по их самовосстановлению).
Инструмент для мониторинга и сбора метрик
Для того, чтобы реализовать поставленные задачи, требуется система мониторинга, способная обнаруживать проблемы и передавать их в системы автоматизации на различных этапах конвейера CI/CD. Также положительным моментом будет, если данная система предоставит полезные метрики для различных команд: разработки, тестирования, эксплуатации. И совсем замечательно, если и для бизнеса.
Для сбора метрик можно использовать совокупность различных систем (Prometheus, ELK Stack, Zabbix и тд), но, на мой взгляд, под данные задачи лучше всего подходят решения класса APM (Application Performance Monitoring), которые способны сильно упростить вам жизнь.
В рамках моей работы в службе сопровождения я начинал делать аналогичный проект, используя решение класса APM от компании Dynatrace. Сейчас, работая в интеграторе, я достаточно хорошо знаю рынок систем мониторинга. Мое субъективное мнение: Dynatrace лучше всего подходит для решения таких задач.
Решение Dynatrace предоставляет горизонтальное отображение каждой пользовательской операции с глубокой степенью детализации до уровня выполнения кода. Можно отследить всю цепочку взаимодействия между различными информационными сервисами: от уровней фронтенд веб- и мобильных приложений, back-end серверов приложений, интеграционной шиной до конкретного вызова в БД.


Также помним, что нам необходимо интегрироваться с различными инструментами автоматизации. Тут решение имеет удобный API, который позволяет отдавать и получать различные метрики и события.
Далее перейдем к более подробному рассмотрению, как решать поставленные задачи с помощью системы Dynatrace.
Задача 1. Автоматизация контроля качества сборок на этапе тестирования
Первая задача – это найти проблемы как можно раньше на этапах конвейера доставки приложения. Только «хорошие» сборки кода должны достигать прод среды. Для этого в ваш pipeline на этапе тестирования должны быть включены дополнительные мониторы по проверки качества ваших сервисов.

Рассмотрим по шагам, как это реализовать и автоматизировать данный процесс:
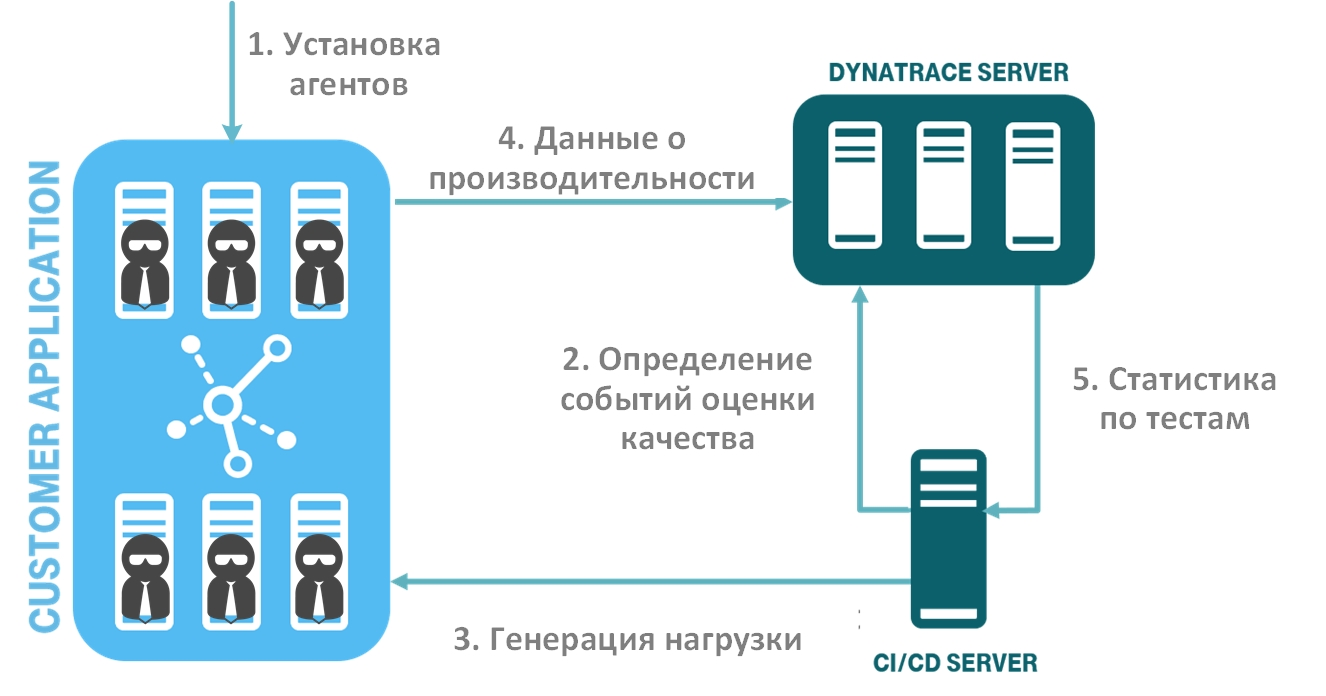
На рисунке показан поток автоматизированных шагов проверки качества ПО:
- разворачивание системы мониторинга (установка агентов);
- определение событий оценки качества вашего ПО (метрики и пороговые значения) и передача их в систему мониторинга;
- генерация нагрузки и тестов производительности;
- сбор данных о производительности и доступности в системе мониторинга;
- передача данных о тестах, основанных на событиях оценки качества ПО, из системы мониторинга в систему CI/CD. Автоматический анализ сборок.
Шаг 1. Разворачивание системы мониторинга
Сначала необходимо установить агенты в вашу тестовую среду. При этом решение Dynatrace имеет приятную особенность – оно использует универсальный агент OneAgent, который устанавливается на OS инстанс (Windows, Linux, AIX), автоматически обнаруживает ваши сервисы и начинает собирать данные мониторинга по ним. Вам не требуется настраивать отдельно агент для каждого процесса. Аналогичная ситуация будет для облачных и контейнерных платформ. При этом процесс установки агентов вы также можете автоматизировать. Dynatrace отлично вписывается в концепт «инфраструктура как код» (Infrastructure as code или IaC): есть уже готовые скрипты и инструкции под все популярные платформы. Встраиваете агент в конфигурацию вашего сервиса, и при его развертывании вы сразу получаете новый сервис с уже работающим агентом.
Шаг 2. Определение событий оценки качества вашего ПО
Теперь необходимо определиться с перечнем сервисов и бизнес-операций. Важно учитывать именно те операции пользователей, которые являются бизнес-критичными для вашего сервиса. Тут рекомендую проконсультироваться с бизнес- и системными аналитиками.
Далее необходимо определить, какие метрики вы хотите включить в проверку для каждого из уровней. Например, это могут быть время выполнения (с разделением на среднее, медиану, перцентили и др.), ошибки (логические, сервисные, инфраструктурные и др.) и различные инфраструктурные метрики (memory heap, garbage collector, thread count и др.).
Для автоматизации и удобства использования командой DevOps появляется концепция «Мониторинг как код». Что я под этим подразумеваю — разработчик/тестировщик может написать простой JSON файл, который определяет показатели проверки качества ПО.
Давайте рассмотрим пример такого JSON-файла. В качестве пары ключ/значение используются объекты из Dynatrace API (описание API можно посмотреть тут Dynatrace API).
{
"timeseries": [
{
"timeseriesId": "service.ResponseTime",
"aggregation": "avg",
"tags": "Frontend",
"severe": 250000,
"warning": 1000000
},
{
"timeseriesId": "service.ResponseTime ",
"aggregation": "avg",
"tags": "Backend",
"severe": 4000000,
"warning": 8000000
},
{
"timeseriesId": "docker.Container.Cpu",
"aggregation": "avg",
"severe": 50,
"warning": 70
}
]
}Файл представляет собой массив определений временных рядов (timeseries):
- timeseriesId – проверяемая метрика, например, Response Time, Error count, Memory used и т.д.;
- aggregation — уровень агрегации метрик, в нашем случае avg, но вы можете использовать любую необходимую для вас (avg, min, max, sum, count, percentile);
- tags – тег объекта в системе мониторинга, или можно указать конкретный идентификатор объекта;
- severe и warning – данные показатели регулируют пороговые значения наших метрик, если значение тестов превышает порог severe, то наша сборка помечается как не успешная.
На следующем рисунке представлен пример использования таких трешолдов.

Шаг 3. Генерация нагрузки
После того, как мы определи уровни качества нашего сервиса, необходимо сгенерировать тестовую нагрузку. Вы можете использовать любой из удобных вам инструментов тестирования, например, Jmeter, Selenium, Neotys, Gatling и т.д.
Система мониторинга Dynatrace позволяет захватывать различные метаданные из ваших тестов и распознавать, какой из тестов относится к какому циклу релиза и какому сервису. Рекомендуется добавлять дополнительные заголовки в HTTP-запросы теста.
На следующем рисунке представлен пример, где с помощью дополнительного заголовка X-Dynatrace-Test мы помечаем, что этот тест относится к тестированию операции по добавлению товара в корзину.

При запуске каждого нагрузочного теста вы отправляете дополнительную контекстную информацию в Dynatrace с помощью API события из сервера CI/CD. Таким образом, система может различать различные тесты между собой.
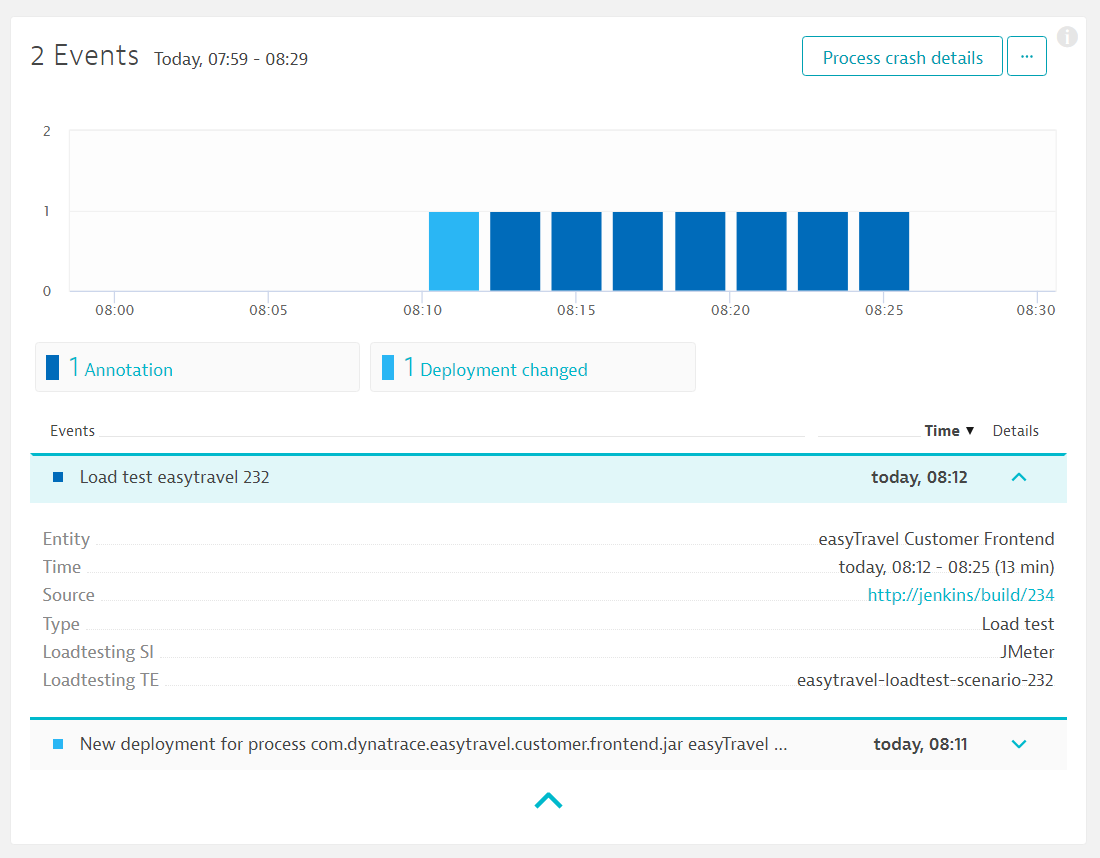
Шаг 4-5. Сбор данных о производительности и передача данных в систему CI/CD
Вместе с генерированным тестом в систему мониторинга передается событие о необходимости сбора данных о проверки показателей качества сервиса. Также указывается наш JSON-файл, в котором определены ключевые метрики.

В нашем примере событие о проверки качества называется perfSigDynatraceReport (Performance_Signature) – это готовый плагин для интеграции с Jenkins, который разработали ребята из T-Systems Multimedia Solutions. В каждом событии о запуске проверки содержится информация о сервисе, номере сборке, времени тестирования. Плагин собирает значения производительности во время сборки, оценивает их и сравнивает результат с предыдущими сборками и нефункциональными требованиями.

После завершения теста все метрики по оценке качества ПО передаются назад в систему непрерывной интеграции, например, Jenkins, которая формирует отчет по результатам.

Для каждой отдельной сборки мы видим статистику по каждой заданной нами метрике на протяжении выполнения всего теста. Мы также видим, если были нарушения в определенных пороговых значениях (warning и severe-трешолды). На основе совокупных показателей вся сборка помечается как стабильная, нестабильная или провальная. Также для удобства вы можете добавить в отчет показатели сравнения текущей сборки с предыдущей.

Детализированное сравнение двух сборок
При необходимости можно перейти в интерфейс Dynatrace и там более детально просмотреть статистику по каждой вашей сборке и сравнить их между собой.

Выводы
В итоге мы получаем сервис «мониторинг как услуга», автоматизированный в конвейере непрерывной интеграции. Разработчику или тестировщику необходимо только определить список метрик в JSON-файле, а все остальное происходит автоматически. Мы получаем прозрачный контроль качества релизов: все уведомления о производительности, потреблении ресурсов или архитектурных регрессиях.
Задача 2. Автоматизация контроля качества ПО в прод среде
Итак, мы решили задачу, как автоматизировать процесс мониторинга на этапе тестирования в Pipeline. Таким образом мы минимизируем процент некачественных сборок, доходящих до прод среды.
Но что делать, если плохое ПО все же дошло до прода, ну или просто что-то ломается. Для утопии нам хотелось, чтобы присутствовали механизмы автоматического обнаружения проблем и по возможности система сама восстанавливала свою работоспособность, хотя бы ночью.
Для этого нам надо по аналогии с предыдущим разделом предусмотреть автоматические проверки качества ПО в прод среде и заложить под них сценарии по самовосстановлению системы.

Автоисправление как код
В большинстве компаний уже присутствует накопленная база знаний по различным типам распространённых проблем и список действий по их исправлению, например, перезапуск процессов, очистка ресурсов, откат версий, восстановление неверных изменений конфигурации, увеличение или уменьшение количества компонентов в кластере, переключение синего или зеленого контура и др.
Несмотря на то, что эти варианты использования известны уже много лет многим командам, с которыми я общаюсь, лишь немногие задумывались и вложили средства в их автоматизацию.
Если подумать, то в реализации процессов по самовосстановлению работоспособности приложения нет ничего сверхсложного, необходимо уже известные сценарии работы ваших админов представить в виде сценариев кода (концепция «автоисправление как код»), которые вы заранее написали для каждого конкретного случая. Сценарии автоматического исправления должны быть направлены на устранение первопричины проблемы. Вы сами устанавливаете правильные действия реагирования на инцидент.
В качестве триггера для запуска сценария может выступать любая метрика из вашей системы мониторинга, главное, чтобы эти метрики точно определяли, что все плохо, так как не хотелось бы получить ложные срабатывания в продуктивной среде.
Вы можете использовать любую систему или совокупность систем: Prometheus, ELK Stack, Zabbix и т.д. Но я приведу несколько примеров на основе решения APM (в качестве примера опять будет Dynatrace), которое также поможет облегчить вашу жизнь.
Во-первых, тут есть все, что касается работоспособности с точки зрения работы приложения. Решение предоставляет сотни метрик на различных уровнях, которые вы можете использовать в качестве триггеров:
- уровень пользователей (браузеры, мобильные приложения, IoT-устройства, поведение пользователей, конверсия и тд.);
- уровень сервиса и операций (производительность, доступность, ошибки и тд.);
- уровень инфраструктуры приложения (OS-метрики хоста, JMX, MQ, web-server и тд);
- уровень платформ (виртуализация, облако, контейнер и т.д).
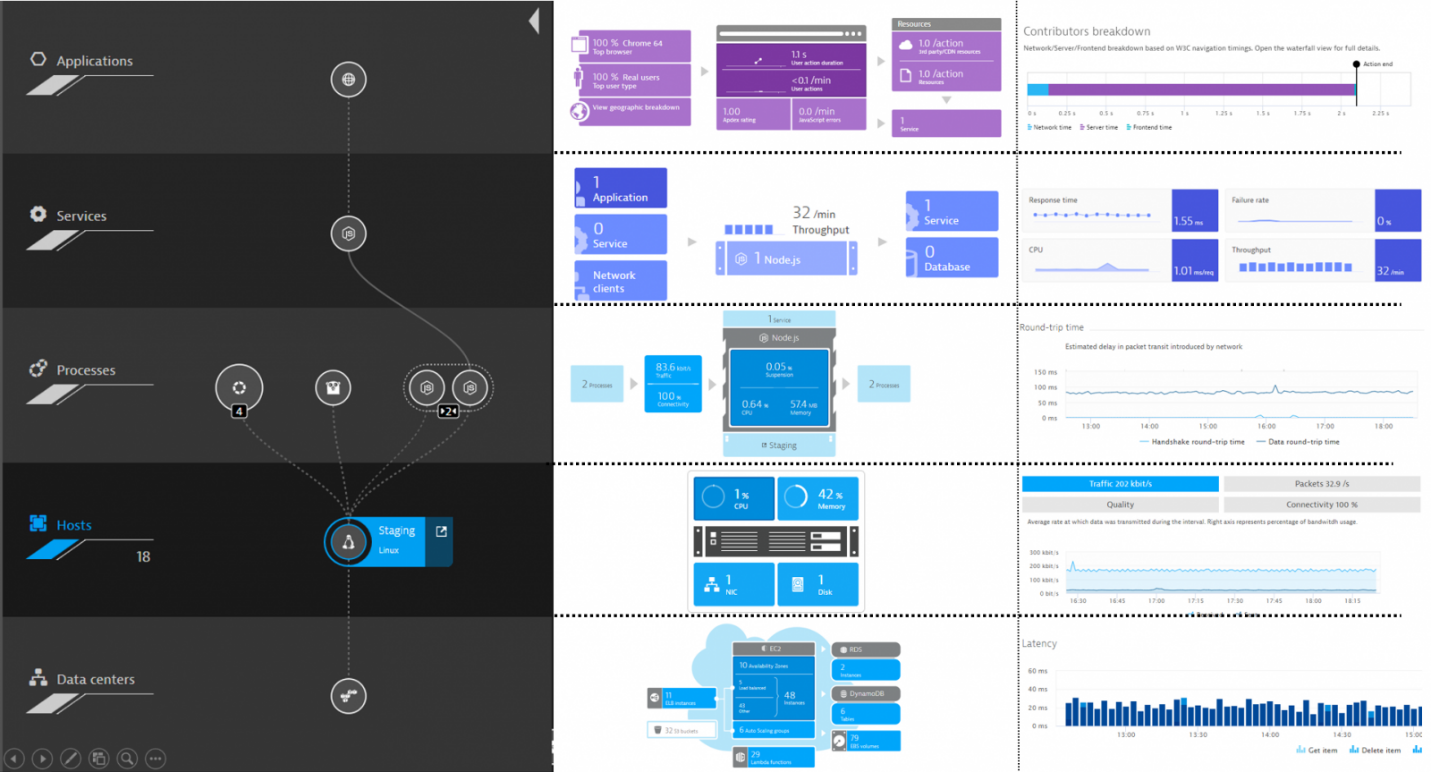
Во-вторых, как я говорил ранее, Dynatrace имеет открытый API, который позволяет очень удобно интегрировать его с различными сторонними системами. Например, отправка уведомления в систему автоматизации при превышении контрольных параметров.
Ниже представлен пример для взаимодействия с Ansible.
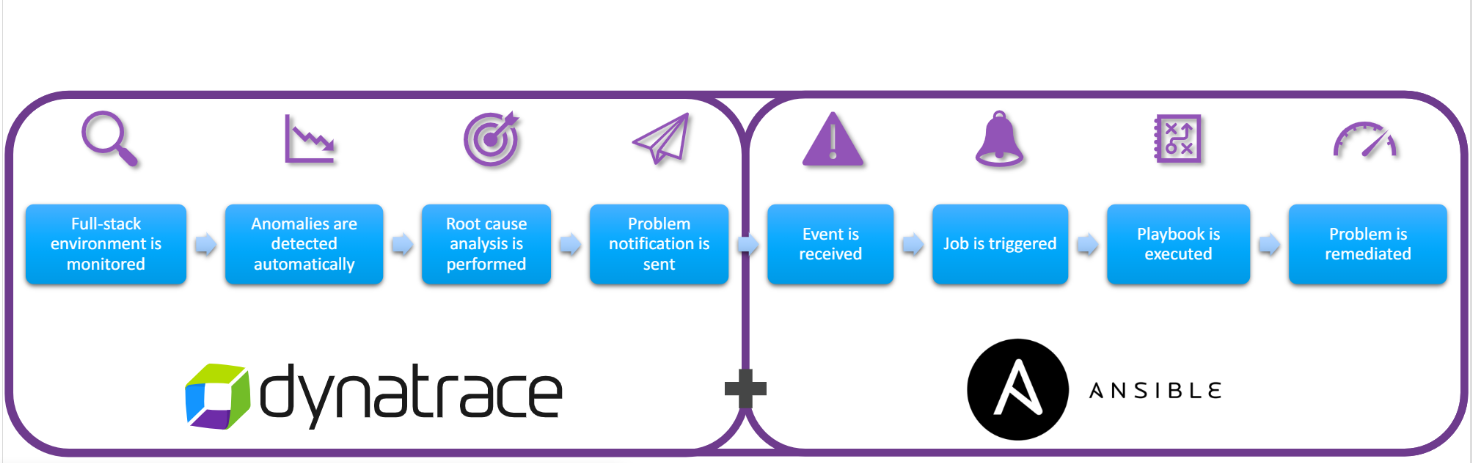
Далее приведу несколько примеров, какие именно автоматизации можно делать. Это всего лишь часть кейсов, их перечень в вашей среде может ограничиваться только вашей фантазией и возможностями ваших инструментов мониторинга.
1. Плохой deploy – откат версии
Даже если мы все очень хорошо проверяем в тестовой среде, то все равно есть шанс, что новый релиз может убить ваше приложение в прод среде. Тот же человеческий фактор никто не отменял.
На следующем рисунке мы видим, что происходит резкий скачок времени выполнения операций на сервисе. Начало этого скачка совпадает с временем деплоя на приложение. Всю эту информацию в качестве событий мы передаем в систему автоматизации. Если работоспособность сервиса не нормализуется по истечении заданного нами времени, то автоматически вызывается скрипт, который производит откат версии до старой.

2. Загрузка ресурсов под 100% — добавить ноду в маршрутизацию
На следующем примере система мониторинга определяет, что на одном из компонентов наблюдается загрузка CPU на 100%.

По данному событию возможно несколько различных сценариев. Например, система мониторинга проверяет дополнительно, связана ли нехватка ресурсов с ростом нагрузки на сервис. Если, да то выполняется скрипт, который автоматически добавляет ноду в маршрутизацию, тем самым восстанавливая работоспособность системы в целом.
3. Отсутствие места на жестком диске – чистка диска
Я думаю, что данные процессы у многих уже автоматизированы. С помощью APM тоже можно следить за свободным местом на дисковой подсистеме. При отсутствии места или медленной работе диска вызываем скрипт для чистки или добавляем место.

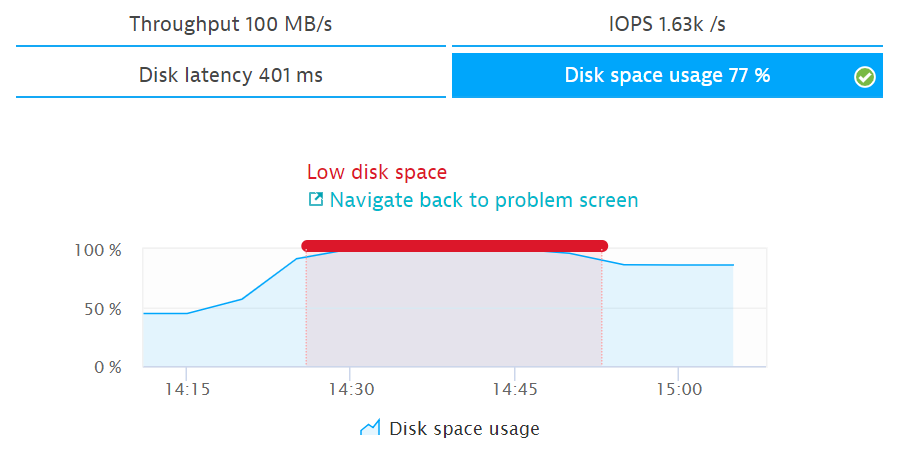
4. Низкая активность пользователей или низкая конверсия – переключение между синей и зеленой веткой
Я часто встречаю заказчиков, использующих два контура (blue-green deploy) для приложений в прод среде. Это позволяет быстро переключаться между ветками при доставке новых релизов. Часто после деплоя могут произойти кардинальные изменения, которые не сразу удается заметить. При этом деградация по производительности и доступности может не наблюдаться. Для оперативного реагирования на такие изменения лучше использовать различные метрики, отражающие поведения пользователей (количество сессий и действий пользователей, конверсия, bounce rate). На следующем рисунке показан пример, на котором при падении конверсии происходит переключение между ветками ПО.
Механизмы автоматического определения проблем
В конце приведу еще один пример, за что мне больше всего нравится Dynatrace.
В части моего рассказа про автоматизацию проверки качества сборок в тестовой среде все пороговые значения мы определяли в ручном режиме. Для тестовой среды это нормально, тестировщик сам определяет показатели перед каждой проверкой в зависимости от нагрузки. В прод среде желательно, чтобы проблемы обнаруживались автоматический с учетом различных механизмов baseline.
Dynatrace имеет интересные встроенные инструменты искусственного интеллекта, которые на основе механизмов определения аномальных метрик (baselining) и построения карты взаимодействия между всеми компонентами, сопоставляя и коррелируя события между собой, определяют аномалии в работе вашего сервиса и предоставляют детализированную информацию по каждой проблеме и корневой причине.
Путем автоматического анализа зависимостей между компонентами Dynatrace определяет не только то, является ли проблемная служба основной причиной, но и ее зависимость от других служб. В приведенном ниже примере Dynatrace автоматически отслеживает и оценивает работоспособность каждого сервиса в рамках выполнения транзакций, идентифицирует службу Golang в качестве основной причины.

На следующем рисунке изображен процесс мониторинга проблем с вашим приложением со старта инцидента.
Система мониторинга собрала полную хронологию событий по возникшей проблеме. В окне под временным графиком мы видим все ключевые события на каждом из компонентов. По данным событиям вы можете задать процедуры для автоматического исправления в виде сценариев кода.
Дополнительно советую интегрировать систему мониторинга с Service Desk или баг-трекер. При возникновении проблемы разработчики оперативно получают полную информацию для ее анализа на уровне кода в прод среде.
Заключение
В итоге у нас получился конвейер CI/CD со встроенными автоматизированными проверками качества ПО в Pipeline. Мы минимизируем количество некачественных сборок, повышаем надежность системы в целом и, если у нас все-таки нарушается работоспособность системы, мы запускаем механизмы по ее восстановлению.

В автоматизацию мониторинга качества ПО точно стоит вкладывать усилия, не всегда это быстрый процесс, но со временем он принесет свои плоды. Рекомендую после решения нового инцидента в прод среде сразу продумать о том, какие мониторы добавить для проверок в тестовой среде во избежание попадания плохой сборки в прод, а также составить скрипт для автоматического исправления данных проблем.
Надеюсь, мои примеры помогут вам в ваших начинаниях. Также мне будет интересно увидеть ваши примеры используемых метрик для реализации самовосстановления работоспособности систем.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}