Комментарии 20
OceanStor Dorado V6 all-flash storage supports various VMware features, including VAAI, VASA, SRM, vSphere web client Plug-in, vRealize Operations, and vRealize Orchestrator. It is deeply integrated with VMware, providing customers with comprehensive storage services in VMware virtualization environment.
Про VVol не в курсе
www.vmware.com/resources/compatibility/search.php?deviceCategory=san&details=1&partner=242&dateRanges=360&isSVA=0&page=1&display_interval=10&sortColumn=Partner&sortOrder=Asc
Тут или ошибка или неточность:
Если встроенная дедупликация не может быть выполнена с высокой вероятностью, система вычисляет «аналогичный» отпечаток (SFP) данных и вставляет его в таблицу «возможностей». Затем система сжимает пользовательские данные, записывает сжатые данные в пул хранения и возвращает сообщение об успешной записи.
Т.е. хост все это время ждет? Или имеется ввиду, что возвращает сообщение контроллерам СХД? Вроде как обычно ack возвращается хосту после записи данных в кэш контроллера СХД. Или я что то не так понял или эта СХД работает по другому?
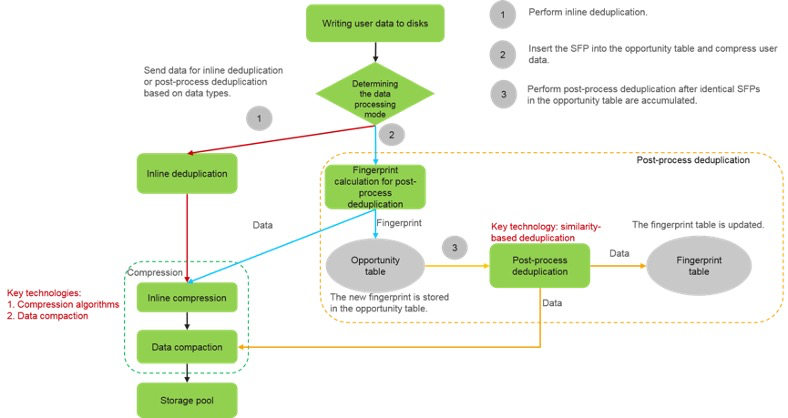
Уточню этот момент у инженеров вендора, нет ли ошибки в документации.
Ну из этой схемы этого не видно. Возможно в тексте описано словами :).
Смотря что вы имеете в виду под записью на СХД. Запись в память контроллера или запись на диски. Судя по приведенной выше схеме запись на диски происходит после вычисления SFP. Постпроцесс это все же уже работа с данными записанными на диски.
ну либо схему китайцы неправильно нарисовали :)
В общепринятом понимании так и должно быть. Но всегда интересна конкретная реализация конкретного производителя, так как из нее могут вытекать как плюсы, так и минусы конкретного решения. А в данном случае не совсем понятно, что имелось в виду и как на самом деле работает, если приведенная схема из официальной документации, да еще и описана не корректно.
Хотя я все равно придерживаюсь мнения, что дедуп на первичных данных — это попытка натянуть "сову на глобус" и продать идею, что "так all-flash обойдется вам дешевле". Дедуп реально эффективен на бэкапах, на первичных данных при определенного рода авариях от него больше вреда, чем пользы.
To balance the compression ratio and performance, OceanStor Dorado V6 uses both inline and post-process compression algorithms. Data that has not been deduplicated is compressed using the inline compression algorithm, and deduplicated data is compressed using the post-process compression algorithm.
- Inline compression
OceanStor Dorado V6 performs inline compression by using the Huawei-developed algorithm that combines LZ matching and Huffman entropy encoding. This provides a compression ratio much higher than that of the LZ4 algorithm while having no impact on write performance.
- Post-process compression
On OceanStor Dorado V6, post-process compression works with similarity-based deduplication and is implemented using the deep compression algorithm developed by Huawei. The deep compression algorithm uses stronger matching rules to provide a higher compression ratio.
К сожалению, разработчики не раскрывают деталей алгоритма оффлайн-дедупликации на основе SFP.
Да на самом деле есть у них более подробное описание. Inline используется дедупликация с постоянным размером блока. Она менее требовательна к ресурсам, но и коэффициент дедупа меньший получается. SFP используются в постпроцессной дедупликации с блоком данных переменной длинны. Она выполняется соответственно в фоне в моменты наименьшей нагрузки, но требует дополнительного места под хранение недедуплицированных данных. Тип дедупликации назначается конкретному disk domain-у и может быть изменен на лету. Но в конкретный момент времени к конкретному disk domain-у применяется только один из алгоритмов дедупа. По умолчанию используется Inline дедуп с постоянным блоком. Дополнительно к уже дедуплицированным данным применяются еще и алгоритмы сжатия. Причем, что касается постпроцессной дедупликации с переменным блоком, там перед сохранением данных на диски выполняется предварительное Inline сжатие входящих данных, затем в фоне их постпроцессная дедупликация, после которой уже дедуплицированные данные дополнительно еще проходят через алгоритм постпроцессного сжатия. При Inline сжатии комбинируют LZ и Huffman entropy encoding. При постпроцессном сжатии дедуплицированных данных используются какие-то свои проприетарные deep compression algorithm.
Глобальный кеш: позволяет, чтобы LUN не имели владельцев. Каждый контроллер обрабатывает полученные запросы на чтение и запись, обеспечивая балансировку нагрузки между контроллерами.
Тут если зарыться в документацию тоже не все так просто. Внезапно, как раз из-за отсутствия Shared Frontend и FIMs модулей режим active-active для контроллеров СХД будет корректно работать только при установленном на хосте UltraPath (MPIO) от Huawei. Так как он начинает вместо FIMs модулей определять в какой порт на front-е отправить I/O, что бы не пришлось выполнять его перенаправление внутри контролера СХД в другую VNode на другой CPU или даже на другой контроллер для обработки.
А с точки зрения владения луном, на этих массивах все происходит несколько ниже уровнем. Если упростить, то по факту различными кусочками одного луна в конкретный момент времени владеют разные CPU обоих контроллеров. Т.е. если I/O случайно прилетит не к тому CPU (не к той VNode), то что бы не менять владельца, все равно придется его перенаправить в правильный VNode, что больше похоже на режим ALUA и может выливаться в дополнительные задержки ввода/вывода. По факту получается, что лучше не использовать нативный MPIO в OS, а всегда ставить вендорский UltraPath.
Кто поддерживает СХД дистрибутор или вендор?
По предыдущему опыту обращаться в L3 HW бесполезно.
«Вы кто? Я Вас не знаю, идите на...»
Кто поддерживает СХД дистрибутор или вендор?
Вендор, уже даже пару кейсов завёл в мае, пока нареканий к саппорту нет
с использованием HyperMetro про SmartDedupe и SmartCompression можно забыть, как и в предыдущих версиях?
Вот тут, к сожалению, не подскажу. Можно попробовать позвать beibaraban
Обзор и тестирование Huawei Dorado 5000V6