
Мир онлайн-покупок становится всё привычнее, а значит, и обезличенных данных про каждого пользователя всё больше. Билайн ТВ использует для онлайн-кинотеатра рекомендательную систему на основе данных: она советует пользователю новый триллер, если он уже посмотрел пять похожих фильмов.
Чтобы реализовать такую систему, компания CleverData (группа ЛАНИТ) сформировала эмбеддинги для пользователей Билайн ТВ. Ассоциация больших данных помогла сделать этот кейс возможным.
В этой статье расскажем подробности этой задачи:
посмотрим, как работают на практике три подхода к векторизации данных — Tfidfvectorizer, BERT, LASER;
проведём кластерный анализ;
увидим результаты магии, использованной для улучшения рекомендательной системы Билайн ТВ;
добавим немного философии в конце — для самых стойких.
Зачем крупным компаниям нужны «чужие» эмбеддинги?
Обезличенные данные об онлайн-покупках могут принести пользу не только бизнесу, но и его клиентам. Билайн ТВ использует рекомендательную систему для онлайн-кинотеатра, советуя пользователям конкретный фильм. Когда накапливается статистика о поведении пользователей (просмотры, рейтинги и т. д.), эти данные вполне можно использовать для разработки рекомендательной системы. Но для накопления статистики требуется время — много времени, если пользователи не очень активны. Для таких случаев есть накопленная обезличенная статистика о пользовательских онлайн-покупках, которые в итоге улучшают метрики рекомендательной системы Билайн ТВ.
А что насчёт пользы для клиентов? Рекомендательная система помогает им смотреть больше фильмов, и с бóльшей вероятностью действительно интересных. Вспомните, сколько раз вы хотели посмотреть фильм, но выбор так сильно затягивался, что уже и времени не оставалось, и желание пропадало.
Роль CleverData и Ассоциации больших данных (АБД)
В этом кейсе CleverData формировали эмбеддинги для пользователей Билайн ТВ, а АБД выступили в роли «IT-свахи» между Билайн ТВ и CleverData. АБД смогли не только обезопасить соединение данных от CleverData с данными Билайн ТВ, но и предоставили «песочницу» для всех этих процессов.
Процесс взаимодействия АБД с молодыми командами можно разделить на следующие этапы:
знакомство с командой;
определение целевого партнёра в зависимости от опыта /продуктов;
подбор партнёра (речь обо всех процессах, связанных с согласованиями);
предоставление инфраструктуры для реализации кейса;
сбор обратной связи и дальнейшее сотрудничество.
Песочница данных у АБД построена по следующим принципам:
равноудалённость от участников инфраструктуры;
изолированность дата-сетов и их неотчуждаемость;
универсальный технологический стек;
защищённый контур (технологические и организационные меры).
Очень много кейсов могли быть когда-то реализованы крупными компаниями совместно со стартапами, но вопросы безопасности, доверия и технологического стека этого просто не позволили. Сейчас АБД доверяют многие известные компании, поэтому подобных кейсов будет ещё больше. Цель АБД — предоставить возможность всем перспективным стартапам реализовывать кейсы для крупных компаний.
Цель
Векторизовать сэмпл данных об онлайн-покупках (e-commerce) при помощи имеющихся подходов (tf-idf, BERT, LASER), выполнить кластерный анализ с помощью PCA/TSNE и сравнить результаты всех этих подходов.
Модели
— Tfidfvectorizer — scikit learn (baseline, его использование не предполагаем из-за высокой интерпретируемости построенных векторов).
— BERT — State-of-the-Art Pre-training for Natural Language Processing от Google.
— LASER — Language-Agnostic SEntence Representations от Facebook.
Tfidfvectorizer, BERT, LASER
Теперь давайте глубже погружаться в контекст задачи, а для этого разберёмся с Tfidfvectorizer, BERT и LASER.
Про эмбеддинги уже написаны хорошие статьи с подробными примерами. Советуем почитать здесь:
Чудесный мир Word Embeddings: какие они бывают и зачем нужны?
Квантование эмбеддингов: что это, зачем оно нужно и как его правильно готовить
Лирическое отступление. Как было раньше?
Ах, если бы близкие по смыслу слова были действительно «ближе друг к другу» и в числовом виде. Как определить правильный порядок нумерации? Например: есть слово «курица» под номером девять. А под номерами семь и восемь что стоит — «яйцо», «петух»? Встал вопрос об адекватном ранжировании слов по их схожести.
Мы можем заменить слово не одним числом, а целым вектором. Векторы можно представить в геометрическом пространстве, где у каждого слова-вектора может быть много соседей на одинаковом расстоянии. Такой вектор называется word embedding или эмбеддингом.
Текстовые данные требуют специальной обработки, чтобы использовать их для прогнозного моделирования. Необходимо проанализировать текст, удалить лишние слова и в итоге сделать ту самую векторизацию: закодировать текст как целые числа или значения с плавающей запятой, чтобы в дальнейшем использовать для решения ML-задач. Способы векторизации:
преобразовать текст в векторы количества слов с помощью CountVectorizer;
преобразовать текст в частотные векторы слова с помощью TfidfVectorizer;
преобразовать текст в уникальные целые числа с помощью HashingVectorizer.
BERT, или Bidirectional Encoder Representations from Transformers, — это нейросеть от Google, показавшая несколько лучших результатов в решении многих NLP-задач — от ответов на вопросы до машинного перевода. Код модели выложен в открытый доступ, ещё есть несколько версий BERT, весь список которых можно найти на официальной странице. Подробности про BERT можно почитать здесь.
LASER, или Language-Agnostic SEntence Representations, — это нейросеть, которая может инкапсулировать и понимать почти все естественные языки, какими бы уникальными они ни были (сейчас это 93 языка и 23 различных алфавита). Нейросеть базируется на библиотеке глубокого обучения PyTorch.
Что на практике?
Основные выводы и выбор подходов осуществлялся на основании обучения тестовых моделей поверх предсказанных эмбеддингов. А теперь боевые расчёты! Подробнее про время, затраченное на векторизацию с помощью трёх подходов — TfidfVectorizer, BERT, LASER, кластеризацию PCA/TSNE. И результаты. Данный эксперимент наглядно показывает способность моделей эмбеддингов к разделению классов.
Tfidfvectorizer + PCA/TSNE
1) Проводим векторизацию с помощью TfidfVectorizer.
Время, затраченное на TfidfVectorizer:

Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

3) PCA — это способ понижения размерности вектора. Мы использовали 2 и 3 размерности, потому что это наглядно.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score*:

Silhouette score, или «коэффициент силуэта» / «силуэт», рассчитывается с использованием среднего внутрикластерного расстояния (a) и среднего расстояния до ближайшего кластера (b) для каждого образца. Коэффициент силуэта для образца равен (b – a) / max(a, b), где b — это расстояние между образцом и ближайшим кластером, частью которого образец не является. Обратите внимание, что коэффициент силуэта определяется только в том случае, если количество меток равно 2 <= n_labels <= n_samples –1. silhouette_score возвращает средний коэффициент силуэта по всем выборкам, а чтобы получить значения для каждого образца, используйте silhouette_samples.
Лучшее значение = 1, а худшее = –1. Значения около 0 указывают на перекрытие кластеров, а отрицательные значения обычно указывают на то, что выборка была назначена не тому кластеру, так как другой кластер более похож.
4) TSNE — алгоритм, который применялся для визуализации на плоскости. Он отвечает за сжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

5) TSNE — сжатие векторов до трёх измерений.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

Промежуточные выводы (качество кластеризации): время, затраченное на TSNE, значительно превышает PCA, а метрики стали намного хуже. Первое место в этой схватке сейчас занимает Tfidfvectorizer + PCA (сжатие до двух измерений).
BERT + PCA/TSNE
Условия: тексты лемматизированы (приведены к именительному падежу и единственному числу), удалены стоп-слова.
1) Векторизация с помощью BERT занимает столько времени:

2) PCA — cжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

3) PCA — сжатие векторов до трёх измерений.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

4) TSNE — сжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

5) TSNE — cжатие векторов до трёх измерений
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

Промежуточные выводы (качество кластеризации): BERT + PCA/TSNE не показал результаты метрик лучше, чем Tfidfvectorizer + PCA (сжатие до двух измерений). Первое место в этой схватке остаётся у Tfidfvectorizer + PCA (2D).
LASER
Векторизация с помощью LASER занимает столько времени:

2) PCA — сжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:
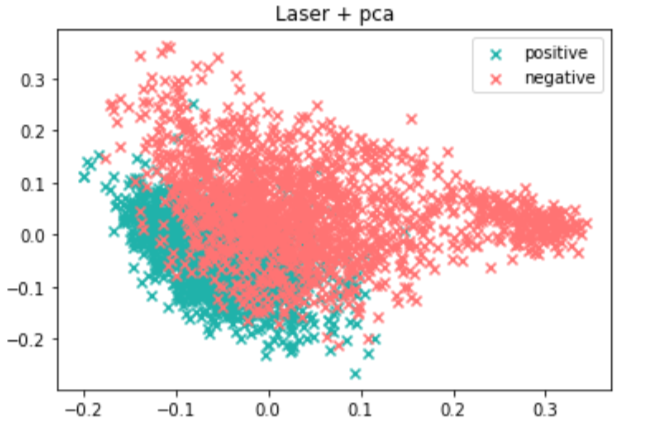
3) PCA — сжатие векторов до трёх измерений.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

4) TSNE — сжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

5) TSNE — cжатие векторов до трёх измерений.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

Новое условие: тексты не обработаны. Попробуем проделать то же самое, но без предварительной обработки.
1) Время, затраченное на векторизацию:

2) PCA — cжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

3) PCA — сжатие векторов до трёх измерений.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

4) TSNE — cжатие векторов до двух измерений.
Время, затраченное на сжатие до двух измерений:

Визуализация в 2D-пространстве:

5) TSNE — cжатие векторов до трёх измерений.
Время, затраченное на сжатие до трёх измерений:

Визуализация в 3D-пространстве:

Результат метрики silhouette_score:

Промежуточные выводы (качество кластеризации): LASER показал результаты ещё хуже, чем BERT и Tfidfvectorizer. Если посмотреть на результаты LASER + PCA (2d) с предварительной обработкой текста и без неё, на удивление результаты без предварительной обработки лучше.
Немного подробностей, как обрабатывался текст
Необходимо сузить признаковое пространство перед векторизацией. Для этого проводится стандартный набор процедур:
приведение текстов к нижнему регистру;
исключение небуквенных символов;
лемматизация — один из ключевых этапов предобработки текстов, приведение слова к начальной форме, инфинитиву;
удаление стоп-слов — тоже очень важный этап, здесь идёт исключение неинформативных слов по словарю, который включает часть стандартного словаря и специальные словари, разработанные для конкретного типа текстов;
преобразование стандартных сокращений в удобный формат, например: ж/д -> ж д -> железнодорожный;
удаление короткосимвольных выражений.
На выходе из такого пайплайна препроцессинга получаем предобработанный текст, готовый к вероятностной векторизации. Важно заметить, что для tf-idf подхода исключение предобработки из пайплайна нерелевантно, так как это раздувает размерность латентного пространства и, соответственно, повышает вероятность переобучения тестовых моделей.
Выводы:
Сжатие с помощью PCA 2D и 3D полезно применять для понимания разделимости классов (то есть для оценки эмбеддингов на предмет разделимости классов).
Если смотреть на результаты метрик качества кластеризации и время, призовые места можно отдать Tfidfvectorizer + PCA (2D). На практике всё
немногонамного сложнее: подход tf-idf вероятностный и является baseline, его применение исключено из соображений конфиденциальности. Поскольку, получив tf-idf словарь, мы легко сможем восстановить описание купленных товаров :(На вопрос «что использовать в бою?» ответят результаты тестов. А дизайн экспериментов, тестирование различных алгоритмов и т. д. — отдельная вселенная.
Что нас ждёт в ближайшем будущем?
В современном мире любая реклама и рекомендации хранят «под капотом» ваши онлайн-следы.
Сначала в голову приходят минусы этих инструментов:
Есть действительно навязчивая реклама.
Возникает повышенная тревожность и мнительность: пользователи боятся оставлять данные в интернете и всеми способами стараются этого не делать.
Есть ощущение, что вам это навязали, это тоже сопровождается повышенной тревожностью.
Почему рекомендательные системы всё-таки хороши:
Качественные рекомендации помогают сделать выбор.
Есть возможность получить гибкое образование. Речь не только о формирующихся на основе действий пользователей рекомендациях курсов и программ, но и о динамичной программе конкретного курса, которая подстроится под уровень пользователя в течение всего обучения.
Тревожность уменьшается благодаря снижению разношёрстного информационного потока и «уровня шума и хаоса». Согласитесь, реклама и рекомендации догоняют нас, даже несмотря на использование даркнета и стремление не оставлять онлайн-следы. Сомневаюсь, что вы хотите видеть рекламу художественных школ или кружков вышивания, если ваш круг интересов — бег и IT. Реклама позволяет узнавать вам о том, что действительно важно и ценно для вас, и не отвлекаться на посторонний шум.

