Наша компания занимается аутсорсингом, мы делаем проекты в совершенно разных сферах. Последние полтора года я работал с картами, с визуализацией больших данных, и сейчас я хочу поделиться своим опытом.
В статье будет две части:
теоретическая расскажет о визуализации данных на картах в принципе, о распространенных JS библиотеках для решения этой задачи и их основных возможностях.
в практической рассказ пойдет о трудностях, с которыми мы столкнулись, и о путях их преодоления.
Наверняка вы видели сервисы, показывающие пробки на дорогах. Так вот, большинство примеров будет из одного похожего проекта, где мы показывали рейтинг опасности на дорогах: уклон, резкий поворот, туман, обледенение, аварии — всё это отображается на карте в режиме реального времени. Хотите знать, как? Прошу под кат.
Теория: что можно показывать на картах
На картах могут отображаться:
точки — маркеры любого вида, символизирующие какой-либо объект, о котором вы можете получить информацию;
линии — дороги, границы городов, реки, в общем, что-то протяженное;
полигоны — уровни высот, уровни давления, любые уровни;
растровые изображения — снимки погоды, это всегда актуально.

В принципе, на карте можно показать вообще всё, что угодно:
распределение республиканцев и консерваторов
распространение генов в мире
достопримечательности на пути вашего путешествия
распределение сельскохозяйственных культур на полях и многое другое.

А зачем нам вообще визуализировать данные
Представим, что у нас есть какие-то данные. Обычно данные хранятся в табличном виде, возможно, в структурированных файлах, или это вполне может быть реляционная база данных:

Человеку будет сложно соотнести, где это место расположено и насколько оно опасно или безопасно. Другое дело, если эти данные визуализировать, на карте все сразу отчетливо видно:

Как можно использовать такую визуализацию
Мы говорим о больших данных, их обычно нужно анализировать.
К примеру, вы разрабатываете модель для расчета риска на дороге, у вас есть разнообразные входные данные, ваш алгоритм превращает сырые данные в результирующий риск для каждого кусочка дороги, в итоге вы можете:
посмотреть результат глазами, не утруждая себя изучением цифр;
показать наглядное демо клиентам, если вы продаете свой продукт;
выполнить ручное (визуальное) тестирование модели и данных: ошибки часто бросаются в глаза.
Чего обычно ждут пользователи от карты
Карта должна быть наглядной. Помните, ее основное отличие от таблицы в том, что не нужно долго думать и разбираться, достаточно взглянуть на карту — и вы уже поняли ситуацию, увидели ошибки и сориентировались на местности.
Ждать загрузки карты минутами, естественно, никто не захочет. Поэтому карта должна быть быстрой. Так как мы говорим о больших данных, несколько секунд может быть приемлемым временем загрузки сегмента данных, но следует внимательно следить за производительностью как API, предоставляющего данные, так и рендеринга на клиенте.
Детальная информация на карте — это хорошо, но в совокупности с аналитикой — ещё лучше! Вот пользователь окинул взглядом карту, но насколько в среднем рискованно ездить в городе? Сколько всего предложений аренды квартир выведено на экран? Какой длины поездки совершают служебные машины в течении дня? На многие вопросы анализа можно быстро ответить с помощью графиков, построенных для видимого сегмента карты.
Иногда хочется сравнить данные. Делать это на карте можно как минимум двумя способами: глядя на схожие данные в разных локациях или изучая разные данные (например, разные моменты времени) в определенном месте. В интерфейсе пользователя это будет пара карт напротив друг друга.
Очень удобно бывает сохранить настроенный вид на карте, для себя в будущем или чтобы поделиться с другими заинтересованными
Интересным на картах также получается проигрывание, когда можно нажать play и увидеть, как с течением времени изменялась ситуация в определенной области.
Инструменты для отображения карты
Чтобы нарисовать карту, нам понадобится как минимум 2 вещи:
SDK для рендеринга карты, которая выведет ваши данные на экран и передаст вам управление, когда пользователь будет двигать карту/кликать на карте;
Базовая карта — данные и стили для рендеринга основных географических данных (суша, вода, страны, дороги и прочее важное для вашего приложения)
Я не буду в этой статье вдаваться в детали сравнения разных инструментов, приведу только основные черты нескольких инструментов, с которыми мне довелось поработать и ссылки на них.
Говоря про SDK, важно упомянуть ключевое понятие для отображения данных на карте: фича — это не то, что мы привыкли называть фичами в разработке, здесь речь пойдет об объектах, у которых есть геометрия, положение в пространстве и набор произвольных свойств, важных для приложения.
Mapbox и Google Maps (с Yandex опыта не было)
Mapbox, Google Maps, Yandex — гиганты в сфере визуализации данных на карте предоставляют разное, но богатое API для отображения данных, навигации, поиска на карте и обработки действий пользователя. У них есть свои данные для базовой карты. Новые фичи, поддержка, стабильность — всё на высоком уровне.
С другой стороны, эти сервисы платные. У них бывают бесплатные квоты (например, 10 000 загрузок карты у Mapbox). Если пользователей в системе будет много, придется аккуратно считать расходы на работу с разными API.
Второй недостаток не так значителен — трудности настройки библиотеки “под себя”. Эти библиотеки не предполагают расширения кодом, вся настройка отображения делается через API, широкое, но не безграничное. Однако, на практике мы ни разу не столкнулись с задачей, которую не смогли бы решить так или иначе.
Leaflet, OpenLayers и OpenStreetMap
Leaflet и OpenLayers — это бесплатные SDK для рендеринга карт с открытым исходным кодом. Они не имеют своих данных, поэтому обычно их используют в паре с OpenStreetMap.
OpenStreetMap — бесплатная публично доступная базовая карта. Карта здесь передается в виде картинок, то есть у вас не будет возможности модифицировать стиль базовой карты. Если возникнет такая нужда, придется регулярно скачивать данные OpenStreetMap (они публично доступны) и хостить свой сервис предоставления базовой карты, что может быть довольно напряжно в плане ресурсов, поэтому не буду смущать вас ссылками.
OpenLayers имеет богатое API, схожее функционалом с Mapbox. При этом часть конфигурации задается классами и функциями, что открывает разработчику всю широту модификации под нужды приложения. Однако, «с большой силой приходит большая ответственность» — вам придется самостоятельно и постоянно заботиться о производительности вашего кода.
Leaflet вообще предоставляет только базовые API из коробки. Расширять можно как угодно и сколько угодно, у него есть система плагинов. Существуют признанные разработчиками Leaflet списки плагинов, расширяющих функционал. Для элементарных задач использовать удобно, для более трудных может и быть сложнее, и требовать больших затрат на разработку (например, фрагментированная загрузка и отображение данных).
Как данные попадают на карту
Все данные выводятся с помощью слоев. Слой на карте — это совокупность данных и стилей их отображения. Есть 2 верхнеуровневых типа слоев: векторные и растровые.

Векторные слои строятся на основе данных в форме векторной геометрии, т.е. отрезках, точках и полигонах. Фронтенд получает описание геометрии и свойств объектов, применяет к ним заданные стили и генерирует изображение для пользователя.
Здесь есть два основных подхода к загрузке данных — Vector Tiles и GeoJSON.
При использовании Vector Tiles вся карта делится на фрагменты-прямоугольники. Когда вы двигаете карту, SDK карты запрашивает данные для видимых фрагментов. Затем к данным применяются заданные стили и получившееся изображение выводится на экран в соответствующем месте карты. Здесь важно, что данные для тайлов вы грузите отдельными частями. Вы могли заметить загрузку данных частями на любой карте при быстром перемещении, например в Яндекс или в Google.
GeoJSON — специальный формат, который содержит геометрию, а данные передаются в формате JSON. Допустим, данных не очень много, вы можете загрузить их все разом с сервера, это может быть файл, или эндпоинт API, неважно; здесь важно то, что данных не очень много и вы их грузите все сразу, и сразу все показываете.
Растровые слои — это видео, картинки или кусочки картинок, используя их, вы можете:
взять целую картинку и наложить ее на карту;
грузить тайлами и кусочками накладывать;
наложить видео поверх карты.
Практическая часть: наш опыт и советы
На этом с теорией заканчиваем, теперь будем разбираться с практической частью, а точнее, я расскажу о проблемах, с которыми мы столкнулись (и вы можете в будущем столкнуться) при работе с картами.
Примечание: код будет довольно порезанным для упрощения понимания, т.е. запускаться он не должен, но понимание идеи даст.
Добавление слоев с данными на карту
Ну вот добавили… Поверх базовой карты… Размыто? Это потому что слои выводятся в заданном порядке, верхние закрывают нижние. Уделяйте внимание порядку отображения данных на карте: фон внизу, детали посередине, надписи на самый верх.

На картинке слева всё размыто, потому что погода лежит поверх всей карты, ничего больше не видно, ни надписей, ни дорог; на картинке справа дороги уже находятся выше погоды, но название городов, дорог и т.д. — всё ещё лежат под погодой.
Как загрузить данные на слой
Что может быть проще? Пользователь в любой момент видит прямоугольник на карте. Мы можем для видимой зоны запросить данные и показать... Только вот данные нужно будет полностью перезагружать при выходе из загруженной зоны.

Серый прямоугольник — это загруженные данные. Мы можем добавить буфер (зеленую зону), пока пользователь находится внутри нее, перезагрузка не требуется. Но как только он уходит влево, придется полностью данные перезагрузить.
С кодом тут всё просто: на фронтенде нам нужно было получить данные, указав, для какой зоны они нам нужны, затем полученные данные надо было добавить в качестве источника.

Мы добавляем source на карту, добавляем новый слой, указываем, что он векторный, и передаем ему данные. Собственно, это всё, что нужно на фронте сейчас.
На бэкенде все тоже несложно.

Многие базы данных умеют работать с геометрией, если не из коробки, то с помощью плагинов. Bbox — географическая граница, определяющая, какие данные нужно достать из базы, затем мы эти данные превращаем в GeoJSON и отправляем на фронтенд.
Вначале это решение работало, но с течением времени система усложнялась, фронтенд тоже, стала появляться дополнительная логика:
логика обработки данных,
логика определения границ области, которую пользователь сейчас видит и которую мы хотим ему предоставить,
логика отслеживания загрузки данных, которая может быть полезна для отображения лоадеров, для отображения слоёв по мере загрузки, для проигрывания и т.д.,
логика кэширования, чтобы не перегружать бэкенд запросами.
А в случае с GeoJSON кэшировать очень сложно, потому что всякое новое перемещение может быть уникальным, оно ни к чему не привязано. Тогда и возникают проблемы: перезагрузка части ранее загруженных данных и ожидание одного большого запроса, так что пользователь получает картинку с заметной задержкой.
Можно ли загружать данные иначе, чтобы решить проблемы кэширования, отслеживания состояния и скорости загрузки? Как я уже говорил в теоретической части статьи, есть тайлы, это разделение всей области карты на прямоугольники определённого размера. Когда вы смотрите на всю карту целиком, таких прямоугольников будет 4, при приближении, каждый тайл делится на 4, то есть на определенном уровне приближения мы будем видеть примерно 4-9 тайлов соответствующего размера.
Давайте разберем на примере.

Серые зоны — то, что видит пользователь. Мы грузим тайлы, но они не должны совпадать с размером наших экранов, вы видите зеленые полоски — это то, что выходит за область видимости, но будет загружено. Красная область — тайлы, которые не видны пользователю (целиком за пределами зоны видимости), для них данные не будут загружены.
В этом случае, по сравнению с GeoJSON, мы грузим меньше данных и каждый прямоугольник будет меньшего размера, то есть загрузится быстрее.

Если пользователь перемещается по карте влево, мы подгружаем пару новых тайлов, а все те, что были ранее видны, остаются без изменений. Получается, что мы догрузили только одну треть данных.

Более того, когда пользователь уходит еще левее, те тайлы, что он раньше видел, остаются на время закэшированым (желтый цвет). А так как у нас есть строгая структура, мы можем легко к этому кэшу вернуться и показать данные, не запрашивая их заново.
Итак, выгода от тайлов:
более высокая скорость загрузки
меньшее время ожидания
кэширование.
На фронтенде код становится все еще более простым:

Нам нужно создать новый векторный источник данных и просто указать путь, по которому нужно ходить за тайлами. Здесь вы можете заметить переменные z, x y:
Z — zoom, насколько близко мы находимся к карте, какого размера зону мы видим;
X и Y — это порядковые номера тайлов, но здесь указывается не широта и долгота, а именно порядковые номера. На преобразование широты и долготы в порядковый номер тайлов и обратно существуют библиотеки под все языки.
Это всё, всю оставшуюся работу за нас сделает библиотека карты.
Теперь научим бэкенд работать с тайлами:

Во-первых, нужно превратить координаты x, y, z в bounding box в широте и долготе, для этого тоже есть библиотеки. Запрос в базу остается без изменений. Ответ мы преобразуем уже в векторный тайл, т.е. берём тот же самый GeoJSON, вызываем библиотечный метод преобразования в векторный тайл, нужно только указать имя слоя, так как в одном тайле можно передать несколько наборов данных, разбитых на слои.
Тайлы тоже не безгрешны, их границы могут обрезать протяженные объекты.

Красные участки — это те дороги, которые могли быть обрезаны на границе тайлов. Сейчас мы разберем это на примере.
У нас на карте есть дорога. Дорога может иметь сложную геометрию, она кривая, она может быть достаточно длинной. Если мы будем вычислять, в какие тайлы она попадает, мы потратим очень много ресурсов базы, гораздо быстрее вычислить геометрический центр и использовать его для поиска в базе. Тогда при запросе дорога попадет строго в один тайл, тот, что содержит ее геометрический центр.

Теперь часть дороги оказывается за границей тайла и будет обрезана при кодировании этого тайла на бэкенде. То есть часть информации будет утеряна, линия будет отображена частично.
Что можно сделать? Данные о тайле нужно передавать с запасом, достаточным для отображения объектов целиком. Для этого при кодировании тайла следует задать опцию buffer нужного размера. Название опции будет зависеть от языка и библиотеки, выполняющей кодирование.

Фильтрование данных по запросу пользователя
Зачем, спросите вы? Ну например, мы хотим видеть данные в определенный момент времени. Или нас интересуют только автомагистрали и нет никакой нужды грузить дворовые дороги. А может, мы желаем знать только об опасных участках, чтобы их объехать, а до безопасных нам никакого дела нет?
Как обновить состояние фильтра в приложении, можно найти в документации фреймворка проекта. Далее нужно сообщить о новом фильтре карте. Так как мы решили работать с векторными тайлами, карта грузит данные сама, а мы только меняем URL так, чтобы он содержал новый фильтр.
При смене источника данных карта сочтет данные устаревшими и сотрет их, затем дождется новых и отобразит их по мере получения. Данные на карте моргнут. Обычно это не проблема, потому что пользователь ожидает реакции интерфейса на его действие.
Но в случае, если вам уж очень не хочется такое моргание наблюдать, можно добавить новый слой для нового фильтра, дождаться полной загрузки данных и только после этого скрыть старый и показать новый.
Сколько данных можно выводить на карте
Представьте, у нас есть 10 000 точек. Рисуются они мгновенно, можно по ним двигаться мгновенно и, если мы откроем консоль разработчика (в chrome, к примеру), мы увидим, что карта наша потребляет 100 МБ.

Если мы нарисуем 100 000 точек, здесь уже можно заметить переходы, приходится ждать, пока все будет нарисовано, а приложение уже потребляет 500 МБ памяти.

Обратите внимание, что точки эти практически без свойств (это просто точки, а не какая-нибудь квартира на сайте недвижимости, где у этой карточки может быть около полусотни свойств)
Как показать больше данных
Что можно сделать, когда мы хотим показать больше точек, скажем, у нас сотни миллионов записей? Нам нужны агрегаты — объединение точек по признаку (например, положению) с указанием объединяющей цифры, вроде количества точек или суммарного или среднего значения.
Самый простой вариант агрегации — это кластеризация на фронтенде.
Возьмем наши 100 000 точек и 450 мб. Если мы их нарисуем, а затем отдалим, то увидим, что все наши точки слились в один большой прямоугольник:

А если мы точки кластеризуем (те же самые данные, но сгруппированные силами карты или какого-то плагина), то точки при изменении уровня зума собираются в кластера. И вот наши 100 000 точек легко различимы на карте и совершенно не едят памяти.

Но кластеризация на UI в этом случае — не панацея. Ведь нам нужно получить данные с бэкенда. А если у нас 100 000 точек, то сколько трафика они съедят? А если миллион? А если 10 млн?
Решением проблемы трафика будет агрегация на бэкенде. На каждое изменение зума, на перемещение мы отправляем запрос на бэкенд, и бэкенд нам отдает уже подготовленный агрегат.
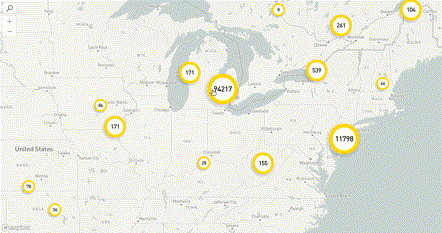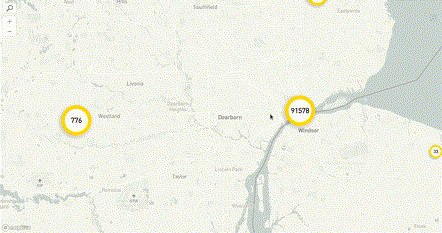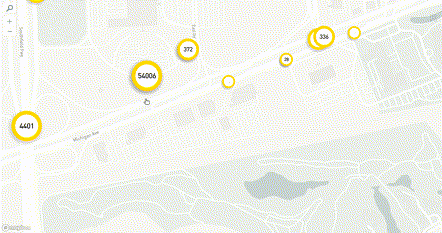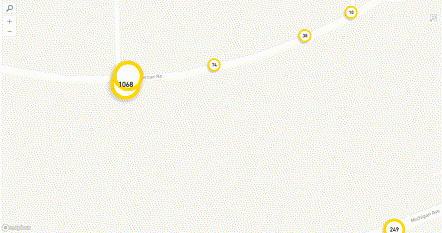
Бэкенд может работать довольно быстро, поэтому время ожидания при приближении может быть всего полсекунды, на фронтенде это незаметно. Таким образом, у нас нет нагрузки на трафик, потому что с бэкенда приходят агрегаты, и у нас нет нагрузки на рендеринг, потому что мы рисуем всего-то 100 точек. Этот вариант не вполне бесплатный — теперь нам нужно правильно хранить данные, чтобы быстро строить и отдавать агрегаты.
Как подготовить агрегаты на бэкенде
GeoHash — самый простой вариант. Geohash позволяет закодировать положение точки с помощью символьной строки. Строка представляет прямоугольник на карте. Размер прямоугольника тем меньше, чем длиннее строка. Если длина — один символ, точность будет порядка 20 или 50 км; если у вас длина строки — 9 символов, точность будет 20 м. Таким образом, подбирая длину строки, можно получить данные, попадающие в определенную область.
Разделение примерно показано на картинке ниже, с допущением разделения прямоугольника на 4 вместо 32 на каждом следующем уровне.

На каждом уровне добавляется символ, который определяет положение более мелкого сегмента в более крупном. Таким образом можно хранить максимально длинный Geohash в базе, а для поиска на нужном уровне просто брать часть строки подходящего размера.
Ещё есть Admin Area — вариант разделения по административным зонам: страны, города, почтовые коды. Этот вариант сложнее, потому что требует наличия в системе данных о геометрии всех административных зон. Более того, эта информация может измениться в будущем.

Подготовка агрегатов требует расширения структуры данных. Теперь мы храним не только широту и долготу точки (или геометрию линии), но и соответствующий Geohash или коды административных зон разного уровня.
Подготовленные таким образом данные можно очень быстро достать из базы, агрегировать, и передать на фронтенд.
Сравнение с помощью карт
Вот жили мы с картой, наладили загрузку и отображение дорог, и вдруг прилетает запрос на добавление второй карты на той же странице для сравнения. Мы, конечно, были к этому не готовы. Приложение было написано на Vue2, мы использовали Vuex store и состояние карты было одно на всё приложение. Мы потратили две недели разработки на добавление второй карты, у нас была регрессия. Достаточно трудно и болезненно, чтобы извлечь урок.
Мы учли этот опыт. В следующем приложении мы на всякий случай использовали уже известную архитектуру, поддерживающую несколько карт на одной странице. И, когда “вдруг” пришёл запрос на две карты, нам понадобилось только добавить одну кнопку.
Приведу пример на основе Vue. Речь пойдёт про модули в сторе Vuex, где мы можем динамически регистрировать кусочки хранилища. Store для Angular и React строятся на той же концепции, так что похожее можно реализовать и на других современных фреймворках.
Итак, следует разделить стейт на::
общую часть, содержащую неспецифичный для отдельной карты стейт, назовем ее “report”
специфичную часть, уникальное состояние для каждой карты — map

При создании компонента карты мы делаем специальную обертку, которая при инициализации регистрирует новый модуль в сторе. Карта внутри должна знать, какой стор ей следует использовать. При закрытии второй карты мы удаляем ее кусок стейта.

Такой подход не требует много времени на разработку, если применен изначально. Воспользоваться его преимуществами можно будет в любой момент, если понадобится показать пару карт одновременно.

Разные карты при этом могут быть независимыми или связаны нужной приложению логикой и транслировать данные из одной в другую.
Сохранение и возможность поделится видом
Есть несколько вариантов, как сохранить и воспроизвести определенный набор настроек отображения карты.
Во-первых, можно записывать состояние приложения с помощью query параметров в URL. Чтобы открыть тот же вид позже или на другом клиенте, достаточно иметь правильный URL. Ограничение размера здесь будет 2 КБ.
Во-вторых, можно сохранять набор настроек на бэкенде и генерировать короткий URL для быстрого доступа. При обращении по URLу приложение восстановит свой стейт, запросив его у бэкенда.
Еще можно сделать удобный интерфейс для просмотра, редактирования и использования всех состояний, сохраненных в базе данных. Это бывает очень удобно для демок.
Полезные советы при сохранении состояния приложения
Сделайте абстрактный компонент, который будет следить за полным состоянием приложения и синхронизировать его с постоянным хранилищем при обновлении или по запросу пользователя. Гораздо удобнее будет управлять всем процессом сохранения в одном месте, чем заставлять каждый компонент отвечать за свой кусочек стейта.
То же и с восстановлением — делайте его централизованно, это гораздо проще, чем следить за URLом из каждого компонента.
Используйте свободное JSON поле при сохранении в базе — тогда вам не потребуется менять бэкенд при расширении фронтенда. Только не забывайте об обратной совместимости с предыдущими версиями стейта.
Вишенка на торте: изменение данных со временем на карте
Данные часто распределены не только в пространстве, но и во времени. В некоторых случаях можно очень наглядно “проиграть” определенный интервал времени и наглядно показать пользователю все изменения на карте.
Логика проигрывания довольно проста:
запустить управляющий таймер
на каждом тике проверять, есть ли еще кадры или проиграно уже всё, что пользователь хотел посмотреть,
если кадры ещё есть, то проверить, загружены ли данные следующего момента и достаточно ли мы показывали последний кадр пользователю
если пользователь достаточно полюбовался текущим кадром и данные следующего подгрузились, то можно перейти к следующему и сбросить loader с полосы проигрывания.
если же пользователь уже достаточно посмотрел на кадр, но новых данных еще не пришло, тогда мы показываем полосу загрузки.
если кадры закончились, то следует остановить таймер, указать на это приложению, чтобы кнопка «паузы» превратилась в кнопку «play», и можно было все запустить сначала.


Теперь мы можем показывать пользователю кадр за кадром. Но если загрузка следующего кадра занимает больше времени, чем мы хотим показывать текущий, пользователь будет видеть индикатор загрузки на каждом кадре. Согласитесь, это нервирует.
Для решения этой проблемы нам следует добавить буфер воспроизведения, сродни серой полоске на Youtube. Пока мы смотрим текущий кадр, система подгружает несколько следующих. Тогда мы немного ждем в начале, пока буфер заполнится, а потом проигрывание идет без задержек, если соединение пользователя быстрое и стабильное.
В случае с картой и тайлами такой буфер делается созданием нескольких невидимых слоев. То есть карта грузит данные, сообщает приложению о завершении загрузки, но сами данные пользователю не показывает, пока приложение не даст сигнал о смене кадра. У каждого слоя есть ключ, включающий в себя метку времени, каждый слой показывает данные в определенный момент времени.

Для каждого слоя мы указываем, перед каким слоем его поставить и проверяем, будет ли он следующим. Когда мы определяем, можно ли пользователю показывать следующий кадр, нас интересуют только два кадра — текущий и следующий. Они оба должны быть полностью загружены.
Так мы заполняем список.
В процессе проигрывания для каждого слоя из этого списка мы будем менять свойства с помощью метода карты “setPaintProperty”. Например, мы обращаемся к слою по ключу, и настраиваем, как должен быть произведен переход — новый слой должен мгновенно появиться, а старый постепенно исчезнуть. Так мы получим анимацию перехода. После того как, анимация настроена, мы все слои показываем/скрываем с помощью прозрачности — в зависимости от того, пора/не пора их показывать.
Документация — хорошо, рабочий код — лучше
Тут мы наткнулись на ошибку в коде Mapbox. У библиотеки есть метод, который позволяет узнать, загружены ли все данные для определённого слоя, но этот метод возвращает значение true и в том случае, если данные ещё не были запрошены.

Поэтому нам пришлось самостоятельно следить за загрузкой данных для слоя:
так как нам важно знать, полностью ли загружены два слоя: текущий и следующий, мы запоминаем перечень видимых тайлов для каждого из них и будем ждать окончания загрузки каждого
каждый раз, когда загрузка завершается успешно или с ошибкой, нам нужно обновить состояние одного тайла на соответствующем слое — указать, что загрузка окончена
в случае возникновения ошибки мы делали всё тоже самое, только дополнительно записывали, что загрузка тайла не удалась. Если таких тайлов было выше определённого порога, например, половина проваливалась, т.е. мы пользователю показывали половину картинки, мы останавливали проигрывание и показывали ему, что что-то пошло не так и предлагали перезапустить с начала.
Лимиты в колеса, или ограничения протокола HTTP1.1
Теперь у нас есть предварительная загрузка данных и все должно быть хорошо… Но почему-то мы загружаем только 1 кадр за раз, хотя настроили буфер на 3, чтобы пользователю не было заметно задержек. Что же происходит теперь?
Для плавности переходов нам нужно три дополнительных кадра, один мы видим, три подгружаем. На один кадр нам нужно от 8 до 18 запросов — это два слоя, в каждом некоторое количество тайлов, итого на 3 кадра может быть до 54 запросов. В браузерах есть ограничение максимального количества одновременных соединений с 1 доменом. В большинстве браузеров предел — 6 одновременных соединений, то есть 6 запросов. Можно использовать несколько поддоменов (domain sharding), чтобы слать запросы, тогда вы сможете расширить этот лимит, но в общем, он всё равно упрется в совокупный потолок 18 одновременных запросов из одной вкладки, а это далеко от наших 54. Итак, у нас 48 запросов стоят в очереди, это ограничение протокола HTTP/1.1.
Обойти эту проблему можно, включив версию HTTP/2.0. По этому протоколу браузер устанавливает только один активный connection с бэкендом для всех запросов и мультиплексирует их. Connection — это тот ресурс, который у браузера ограничен, а количество запросов — не ограничено.

На бэкенде нам нужно перенаправить весь трафик на 443 порт, потому что HTTP/2.0 требует обязательное наличие SSL сертификата. Мы указываем, что на этом порту у нас будет включён SSL и HTTP/2.0.
Все готово. Браузер автоматически подстроится под настройки бэкенда.
Надеюсь, что статья поможет справиться с возможными проблемами при визуализации данных. Если остались вопросы - пишите в комментарии.
Полезные ссылки:
