
В предыдущих частях я создал и развернул в облаке лямбда функцию и БД, настроил VPC, в которой работают мои ресурсы:
В этой части напишу код, который будет взаимодействовать с БД. Для удобства при развертывании кода в этой части я буду использовать отдельный стек serverless-bugtracker-ch3. Для этого стека я добавлю новый профиль в ./samconfig.toml.
Настройка работы в VPC
Чтобы лямбда функция могла обращаться к БД в RDS, мне нужно настроить ее на работу в той же самой VPC, где уже развернута БД — в противном случае не будет доступа до базы данных. По умолчанию в облаке AWS существует отдельная VPC для лямбда функций, и, конечно же, она никак не связана с моей проектной VPC. Чтобы запустить лямбду в моей VPC, необходимо добавить свойство VpcConfig с двумя параметрами, указывающими на подсеть, в которой будет создан сетевой интерфейс для лямбды, и на соответствующую security group. Все необходимые VPC ресурсы ранее уже были созданы, также был настроен cross-stack reference для VPC параметров.
Глобальные ресурсы развернуты в стеке с именем serverless-bugtracker-global-resources.Я не хочу жестко зашивать в свой шаблон имя этого стека, поэтому в ./template.yaml я сделаю новый параметр GlobalResourceStack — имя стека с глобальными ресурсами. Это на тот случай, если я захочу переименовать стек с глобальными ресурсами, или если захочу еще одно окружение с БД для каких-нибудь экспериментов. Значение по умолчанию будет serverless-bugtracker-global-resources, так потребуется меньше телодвижений при развертывании основного стека.
# ./template.yaml
Parameters:
GlobalResourceStack:
Description: Name of the global resources stack
Type: String
Default: serverless-bugtracker-global-resources
Resources:
...
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
...
VpcConfig:
SecurityGroupIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSecurityGroup'
SubnetIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSubnet'Импорт параметров осуществляется при помощи функции ImportValue, которая возвращает значение из другого стека при использовании cross-stack-reference.
Интеграция базы данных и лямбда функции
Для создания подключения к БД требуется знать логин, пароль, имя базы данных, имя хоста RDS. Очевидно, что хранить эти параметры в лямбда функции — это очень плохое решение. Все значения, кроме хоста, уже хранятся в SSM. Необходимо передать эти данные в функцию.
Передача логина и имени базы данных
Как я уже писал ранее, получать обычные (не secured) SSM параметры в CF шаблоне можно через динамические ссылки или параметры стека. Для лямбда-функций динамические ссылки не работают, поэтому для передачи значений из SSM буду использовать параметры стека:
# ./template.yaml
Parameters:
...
DbLogin:
Description: Required. Password stored in SSM
Type: AWS::SSM::Parameter::Value<String>
Default: /global/serverless-bugtracker/db-login
DbName:
Description: Database name
Type: AWS::SSM::Parameter::Value<String>
Default: /dev/serverless-bugtracker/db-nameТеперь эти параметры можно передать в функцию. У лямбда функции есть специальная настройка Environment для передачи параметров:
# ./template.yaml
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
...
Environment:
Variables:
LOGIN: !Ref DbLogin
DB_NAME: !Ref DbNameПередача хоста БД
Для того, чтобы создать подключение к БД, необходимо знать хост RDS. Это значение можно получить из ресурсов, которые заданы в шаблоне rds.yaml. Я уже настраивал cross-stack reference для VPC параметров, сделаю аналогичным образом и для хоста.
# ./global-resources/rds.yaml
Outputs:
DBHost:
Description: database host
Value: !Sub "${DB.Endpoint.Address}"Экспортируем переменную в ./global-resources/template.yaml:
# ./global-resources/template.yaml
Outputs:
DBHost:
Description: database host
Value: !GetAtt rds.Outputs.DBHost
Export:
Name: !Sub '${AWS::StackName}-DBHost'Теперь можно использовать переменную в лямбде:
Environment:
Variables:
LOGIN: !Ref DbLogin
HOST: !ImportValue
'Fn::Sub': '${GlobalResourceStack}-DBHost'Все параметры, которые я мог передать через переменные окружения, я передал.
Передача пароля
Из всех параметров остался только пароль. Ни параметры стека, ни динамические ссылки не подходят для передачи secured данных. Как же быть?
Есть еще одна опция — самостоятельно получать параметр в коде функции, используя код клиента. Для реализации этой опции потребуется клиент для SSM сервиса:
serverless-bugtracker/src/handlers/get-project-by-id> npm install @aws-sdk/client-ssmОчевидно, если запрашивать параметр на каждом запросе, то я получу замедление работы, к тому же есть ограничение на максимальное число запросов к API SSM сервиса (по умолчанию 40 запросов в секунду). Поэтому параметр надо либо вычитывать редко, например, один раз за все время работы лямбда функции, либо кэшировать это значение на какое-то продолжительное время. К плюсам кэширования можно отнести еще и возможность обнаруживать изменения в SSM. Если я поменяю параметр в SSM, то мои функции спустя какое-то время применят новые параметры без перезагрузки или обновления окружения.
Поскольку я не планирую делать поддержку изменений в настройках, да и вообще параметры подключения к БД вряд ли будут меняться, то я сделаю чтение параметра один раз. В этом случае я увеличу время cold start, но не увеличу время обработки последующих запросов:
// ./src/handlers/get-project-by-id/app.js
const { SSMClient, GetParameterCommand } = require("@aws-sdk/client-ssm");
const fetchParamsPromise = getParameterFromSsm("/global/serverless-bugtracker/db-password");
const client = new SSMClient({ region: "us-east-1" });
var dbPassword;
exports.lambdaHandler = async (event, context) => {
try {
dbPassword = await fetchParamsPromise;
//lambda handler code
//...
} catch (err) {
console.log("Cannot retrieve project by id", err);
}
};
async function getParameterFromSsm(parameter) {
console.log("Fetching parameter from SSM...");
try {
const input = {
Name: parameter,
WithDecryption: true
};
const cmd = new GetParameterCommand(input);
const result = await client.send(cmd);
return result.Parameter.Value ?? result.Parameter;
} catch(error) {
console.log("Cannot fetch parameter", error);
throw error;
}
}Переменная fetchParamsPromise будет посчитана один раз за все время жизни экземпляра функции, а результат ее выполнения будет использоваться каждый раз, когда экземпляр будет обрабатывать очередной запрос.
Весь код вне основного обработчика lambdaHandler работает в фазе Init лямбда-функции. Вообще любые инициализации лучше всего делать вне обработчика запросов по нескольким причинам.
Во-первых, фаза инициализации бесплатна. AWS не учитывает эту фазу, когда считает деньги за использование лямбда функций. Поэтому, для экономии денег, имеет смысл по максимуму использовать Init фазу: размещать инициализацию переменных, подготовку данных. Но надо помнить, что Init фаза не резиновая и не должна превышать 10 секунд. Иначе AWS посчитает запуск вашей лямбды ошибочным и будет пытаться ее создать снова, но на этот раз это время будет оплачиваться по полной.
Во-вторых, на время фазы Init AWS предоставляет больше вычислительных мощностей. Это значит, что логика по расчетам/вычислению может работать гораздо быстрее, если будет запущена в фазе инициализации лямбда функции.
Я в блоке инициализации создаю promise, который запрашивает данные из SSM. К сожалению, я не могу дождаться результата выполнения в фазе инициализации, из-за асинхронности ssm-client. И фактически получение ответа происходит, когда началась обработка события. В моем случае это вряд ли бы на что-то повлияло, потому что I/O операции работают одинаково вне зависимости от фазы, в которой они происходят.
Совсем недавно AWS стал поддерживать объявленные на самом верхнем уровне await (вне async функций), но это работает только для ES модулей.
Запрос в БД
Теперь можно приступить к интеграции с RDS. Поскольку каждый экземпляр лямбда функции будет синхронно обрабатывать строго один запрос, то нет необходимости внедрять пулы коннекций. В обработчике лямбда функции я буду создавать ровно одно соединение.
Если создавать коннекцию к БД на каждом запросе, то время работы моей функции будет больше и это время будет оплачено из моего кармана. В идеале создавать коннекцию надо вне обработчика функции, но получение SSM параметров возможно только внутри async функции (для не es-модулей), поэтому и создание соединения придется разместить в обработчике функции. Но надо позаботиться о том, чтобы коннекция создавалась один раз за все время жизни экземпляра функции.
Все значения, переданные в шаблоне через Environment.Variables, становятся доступны в коде как глобальные переменные, поэтому есть все данные для создания подключения:
// ./src/handlers/get-project-by-id/app.js
const mysql = require('mysql2/promise');
const { SSMClient, GetParameterCommand } = require("@aws-sdk/client-ssm");
const client = new SSMClient({ region: "us-east-1" });
const fetchParamsPromise = getParameterFromSsm("/global/serverless-bugtracker/db-password");
var dbConnection;
var dbPassword;
exports.lambdaHandler = async (event, context) => {
try {
if(!dbConnection) {
dbPassword = await fetchParamsPromise;
dbConnection = await mysql.createConnection({
database: process.env.DB_NAME,
host: process.env.HOST,
user: process.env.LOGIN,
password: dbPassword
});
}
const [rows, fields] = await dbConnection.execute("SELECT * FROM `projects` where `id` = ?", [event.id]);
//return result...
} catch (err) {
//error handling
}
};При реализации обработчиков надо держать в голове, что все асинхронные действия, которые выполняются в лямбда функции, должны быть закончены до того, как обработчик вернет результат. В моем случае до последнего return. Это следствие того, как AWS поступает со средой выполнения после окончания обработки события. Как я уже упоминал в первой части, после отработки фазы Invoke (после того, как обработчик вернул результат), AWS “замораживает” среду выполнения при отсутствии следующих событий. Незаконченные действия могут привести к интересным ситуациям.
Пример: предположим, в моей функции помимо основной логики требуется сделать обновление какого-то счетчика в БД, и я не ожидаю окончания этой операции. Выполнил UPDATE и не ожидаю результата. Возможна ситуация, когда AWS “заморозит” мое окружение с этой операцией: запрос может не успеть улететь в БД, а лямбда уже вернула ответ, тем самым спровоцировав “заморозку”. Следующее событие “разморозит” мою среду выполнения и мою операцию. И только тогда мой счетчик наконец-то обновится.
Что это значит? Если не ожидать окончания асинхронных вычислений, то результаты этих вычислений могут появиться с задержкой. Поэтому всегда надо завершать такие вычисления до последнего return.
Запуск функции
Лямбда готова. Теперь я проверю, запускается ли она локально. Способы запуска я обсуждал в первой части. Поскольку в коде моей функции активно используются глобальные переменные, то простой локальный запуск приведет к ошибкам. При локальном запуске SAM не достает параметры из SSM, поэтому необходимо самостоятельно заполнить эти глобальные переменные.
Запуск при помощи VSCode
Если запуск осуществляется при помощи плагина, то настройки передаются через конфигурационный файл VSCode. Для этих целей в настройках предусмотрен раздел environmentVariables, в котором необходимо прописать переменные окружения:
// ./.vscode/launch.json
"lambda": {
"payload": {
"json": {
"id": 1
}
},
"environmentVariables": {
"HOST": "SOMEHOST.us-east-1.rds.amazonaws.com",
"LOGIN": "user",
"DB_HOST": "bugtracker"
}
}Запуск в консоли
Передача параметров при консольном запуске осуществляется при помощи специального файла. Содержимое этого файла — обычный json объект. Ключами являются логические имена функций из шаблона, а значениями является объект с переменными:
// ./env.json
{
"GetProjectByIdFunction": {
"HOST": "SOMEHOST.us-east-1.rds.amazonaws.com",
"LOGIN": "user",
"DB_HOST": "bugtracker"
}
}Этот файл надо передать при запуске через консоль:
serverless-bugtracker> sam local invoke GetProjectByIdFunction --env-vars ./env.jsonПробую запустить лямбду и получаю ошибку при подключении к БД:
Cannot retrieve project by id Error: connect ETIMEDOUTАналогичная ошибка происходит при попытке подключиться любым клиентом. Причина кроется в VPC. Я настроил доступ лямбды к базе в облаке, но я ничего не сделал для того, чтобы получить доступ с локальной машины. Учитывая, что моя БД запущена в приватной подсети в AWS, для исправления этой проблемы мне потребуется обеспечить доступ до БД из локального окружения.
Доступ к БД
Глобально я вижу несколько возможных вариантов организации доступа в БД.
Первый способ - это сделать БД публично-доступной с разумным уровнем безопасности. Да, для своего проекта я сделал ее приватной по ряду причин, но, возможно, для ваших задач вполне хватит варианта с публичной БД, для которой предприняты меры безопасности. Например, если у вас статический IP, то посредством настройки Security Group вы можете ограничить доступ до БД только с вашего IP. В этом случае никаких проблем с доступом до БД при локальным запуском лямбды не будет.
Второй способ - сделать БД приватной. Это именно мой вариант. В простейшем случае можно запустить отдельную тестовую БД локально — например, в отдельном докер-контейнере или же прямо на моей машине. То есть, БД в RDS остается и будет работать для лямбды в AWS, а для локального тестирования и разработки будет использоваться отдельный экземпляр БД, запущенный, например, в Docker-контейнере на моей машине. В принципе, особых проблем с данным вариантом не было — работает нормально и фактически не требует глобальных изменений. Единственное, что нужно сделать — это для локального запуска использовать локальный адрес службы MySQL.
В более продвинутом варианте можно создать VPN подключение и подключаться к БД через VPN — реализовать данный вариант можно двумя способами:
собственноручно установить и настроить OpenVPN на отдельном EC2-инстансе. В данном случае требуются навыки настройки VPN-службы и маршрутизации в AWS. Плюс не забываем про стоимость постоянно запущенного EC2-инстанса;
воспользоваться готовым VPN-сервисом от AWS. Сервис называется AWS Client VPN и позволяет подключаться к VPC посредством OpenVPN-клиента. Из подводных камней при настройке данного сервиса можно отметить необходимость генерации/добавления SSL-сертификатов - это можно сделать самостоятельно или воспользоваться готовым центром сертификации от AWS - ACM Private CA. И если в случае первой опции необходимы только навыки работы с OpenSSL, то вторая опция требует значительных дополнительных финансовых вложений (~ $400). В целом данный вариант организации VPN требует определенных технических знаний и навыков работы с AWS/VPN/SSL. При этом стоимость данного варианта будет достаточно высокой - по моим подсчетам, актуальным на дату публикации статьи, это примерно $80 в месяц при самостоятельной генерации сертификатов или примерно $480 если воспользоваться сервисом ACM Private CA.
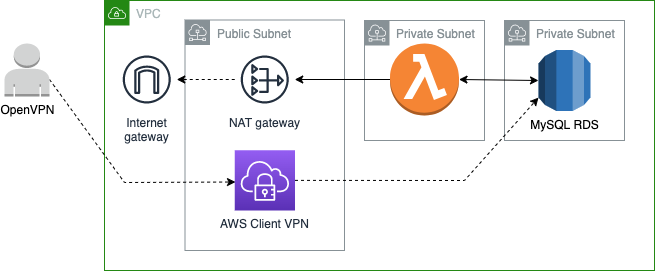

Альтернативой использования VPN клиента может быть SSH-туннель до RDS. Данный вариант фактически тоже реализует приватный туннель до RDS, но делает это посредством функционала SSH-протокола. Для данного варианта потребуется наличие EC2-инстанса, через который собственно и будет происходить туннелирование трафика до RDS.

Каждый из этих вариантов имеет свои плюсы и минусы — я же для своего проекта реализовал вариант с VPN-службой от AWS и самостоятельной подготовкой необходимых сертификатов для ее работы. Да, стоимость этого решения достаточно высокая, но для меня это не долгосрочное решение и плюс я решил заодно познакомиться с данным сервисом от AWS. Какой из вариантов предпочтителен для вашего случая, зависит от требований/возможностей и т.д., но результат в любом случае должен позволить полноценно работать с БД при локальном запуске лямбды. Инструкцию, а также код для развертывания варианта с VPN-службой от AWS можно найти в репозитории проекта по ссылке.
Теперь локально я могу запускать лямбду, подключаться к БД. Попробую развернуть лямбду в облаке. Получаю новую ошибку:
User: arn:aws:sts::123456789:assumed-role/serverless-bugtracker-ch3-GetProjectByIdFunctionRo-1N2ELYNEXQUPT/get-project-by-id is not authorized to perform: ssm:GetParameter on resource ...У моей лямбда функции не хватает прав, чтобы вычитать SSM параметр /global/serverless-bugtracker/db-password. Во время локального запуска все работало, потому что использовались права моего аккаунта.
Добавлю права:
# ./template.yaml
GetProjectByIdFunction:
Type: AWS::Serverless::Function
...
Properties:
Policies:
- Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- ssm:GetParameter
Resource:
- !Sub 'arn:aws:ssm:${AWS::Region}:${AWS::AccountId}:parameter/global/serverless-bugtracker/db-password'После этих изменений лямбда может работать и при локальном запуске, и при запуске в облаке. Миссия выполнена.
Общие зависимости
Первая лямбда готова, теперь можно реализовать оставшиеся три. Кажется, что проблем возникнуть не должно, но… Достаточно быстро становится ясно, что у всех моих функций есть похожий код, а именно код, который получает SSM параметры. Ведь в каждой из них требуется пароль для создания подключения к RDS. Ситуация понятна и решение очевидно — выделить общий метод в отдельный файл и изменить функции, чтобы они использовали функцию из этого файла.
Если вспомнить, какую структуру я выбрал для проекта и как работает сборка проекта, то станет ясно, что работать с общим кодом надо как-то по-другому. Ведь в артефакт после сборки попадает только код, который расположен в директории из CodeUri. Получается, мне надо общий код скопировать во все артефакты?
Amazon для лямбда функций в случае, когда у них есть общие зависимости, рекомендует использовать слои. Слой — это архив c кодом, данными, настройками. Во время команды sam deploy слой упаковывается в архив и заливается на S3. Когда создается среда выполнения для функции, AWS Lambda сервис скачивает слои из S3 и распаковывает их в папку /opt. После этого можно работать с файлами в этой папке.

Таким образом, слой позволяет использовать одни и те же данные/файлы в нескольких функциях. Помимо того, что слои являются способом использовать общий код, этот инструмент позволяет ускорить развертывание за счет выделения общих зависимостей в отдельный слой. Как правило, зависимости меняются реже кода функций. Выделение общих зависимостей приводит к уменьшению размера артефакта функции. Меньше размер — меньше времени уходит на загрузку данных в S3, а это влечет за собой ускоренное развертывание. Конечно, в моем приложении с 4 функциями разница будет не критичной, но, если предполагается разворачивать большое число функций и размеры артефактов могут исчисляться десятками мегабайт, то выигрыш будет заметным.
Слои поддерживают версионирование. Это означает, что я могу настроить использование определенной версии слоя в функции. В этом случае обновление слоя не потребует обновления функции.
Я создам слой, который будет содержать мой утилитный класс по работе с SSM и две общие библиотеки (mysql2, aws-sam/client-ssm). Создам отдельную директорию src/layers/common-function-dependencies. Все общие зависимости перенесу в слой.
// ./src/layers/common-function-dependencies/package.json
{
"name": "common-function-dependencies",
"version": "1.0.0",
"dependencies": {
"@aws-sdk/client-ssm": "^3.47.1",
"mysql2": "^2.3.3"
}
}Мои утилиты:
// ./src/layers/common-function-dependencies/ssm_utils.js
const { SSMClient, GetParameterCommand } = require ("@aws-sdk/client-ssm");
const util = require ("util");
const client = new SSMClient({ region: "us-east-1" });
exports.getParameterFromSsm = async (parameter) => {
console.log(util.format("Fetching %s from SSM...", parameter));
...
}Теперь добавлю в SAM шаблон сборку моего слоя
# ./template.yaml
CommonFunctionDependencies:
Type: AWS::Serverless::LayerVersion
Properties:
LayerName: common-function-dependencies
Description: Common dependencies for all functions.
ContentUri: ./src/layers/common-function-dependencies
CompatibleRuntimes:
- nodejs14.x
RetentionPolicy: Delete
Metadata:
BuildMethod: nodejs14.xСвойство ContentUri указывает на директорию, где располагается package.json. Свойство Retention Policy определяет поведение SAM, когда слой обновляется. Значение Delete определяет стратегию, когда старые версии слоев удаляются при обновлении. Слой готов, теперь его можно подключать к функции.
# ./template.yaml
Resources:
GetProjectByIdFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: src/handlers/get-project-by-id
Handler: app.lambdaHandler
Runtime: nodejs14.x
Layers:
- !Ref CommonFunctionDependenciesКогда создается окружение для запуска функции, все слои для nodejs распаковываются в папку /opt/nodejs. Если несколько слоев будут содержать файл с одним именем, то будет конфликт имен, который придется решать самостоятельно.
sh-4.2# cd /opt/nodejs
sh-4.2# ls
node_modules package.json ssm_utils.jsПуть /opt/nodejs/node_modules уже входит в значение NODE_PATH. Поэтому импорт библиотек будет работать из этой директории автоматически. А вот мой утилитный файл придется подключать, используя полный путь.
// ./src/handlers/get-project-by-id/app.js
const { createConnection } = require('mysql2/promise');
const { getParameterFromSsm } = require('/opt/nodejs/ssm_utils');Такой код будет работать локально, если запускать его при помощи SAM CLI или при помощи плагина VSCode. А вот где такие импорты работать не будут, так это в тестах. Я использую jest для тестирования. Чтобы исправить проблему отсутствующих зависимостей, придется настроить jest.
// package.json
"jest": {
"moduleNameMapper": {
"/opt/nodejs/(.*)": "$1"
},
"modulePaths": ["./src/layers/common-function-dependencies",
"./src/layers/common-function-dependencies/node_modules"]
},
Импорт /opt/nodejs/ssm_utils в тестах будет импортировать ssm_utils из папки ./src/layers/common-function-dependencies.Теперь можно спокойно писать тесты для функций. Все моки будут успешно работать.
// ./src/handlers/get-project-by-id/__tests__/app.test.js
jest.mock('mysql2/promise');
jest.mock('/opt/nodejs/ssm_utils');
const { createConnection } = require('mysql2/promise');
const app = require('../app.js');
beforeEach(() => {
jest.clearAllMocks();
});
...Подведение итогов
Подведу промежуточный итог.
Есть лямбда функция, которая вычитывает запись из rds по идентификатору.
Есть SAM шаблон, который позволяет развернуть полностью приложение (лямбда функция + база данных + настройка vpc).
Лямбда по прежнему работает и локально, и в облаке, не ограничивая нужды разработчика.
Общие зависимости и вспомогательные утилиты выделены в отдельный слой, который подключен к функции.
Путь от заглушки до интеграции с БД пройден, полученных знаний хватит для реализации остальных трех лямбда функций.
Настройки всех функций очень похожи, всем им необходимы одни и те же SSM параметры, один и тот же слой, одни и те же VPC настройки. Чтобы не плодить дублирование в шаблоне, в CF предусмотрен специальный блок Globals, в котором можно определить некоторые общие настройки для ресурсов.
Воспользуюсь этим разделом в шаблоне для определения общих настроек функций:
Globals:
Function:
Timeout: 3
VpcConfig:
SecurityGroupIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSecurityGroup'
SubnetIds:
- !ImportValue
'Fn::Sub': '${GlobalResourceStack}-LambdaSubnet'
Environment:
Variables:
LOGIN: !Ref DbLogin
DB_NAME: !Ref DbName
HOST: !ImportValue
'Fn::Sub': '${GlobalResourceStack}-DBHost'
Layers:
- !Ref CommonFunctionDependenciesКод можно найти тут.
В следующей главе я еще на один шаг стану ближе к полноценному работающему приложению — объединю все функции в единое API.
