
Проекту Lingualeo уже 10 лет. Более 23 миллионов человек из России, Турции, Испании и стран Латинской Америки учат с помощью нашего сервиса английский.
LinguaLeo создавали в конце нулевых – начале десятых годов и использовали передовые на тот момент технологии и методы. Но прошло время, и они сильно устарели. Так что мы решили, что систему пора обновить.
Мы попросили нашего лидера бэкэнд разработки, Олега Правдина, рассказать о том, как они с командой параллельно с поддержкой основного продукта собрали новую модульную структуру сервиса на базе PostgreSQL, перенесли бизнес-логику в базы данных и провели миграцию с миллионами пользователей.
Проблемы зрелого продукта
«Я пришёл в Lingualeo в августе 2018 руководить бэкэнд разработкой. Тогда бэком занималась команда из 8 разработчиков и 2 админов, которые обслуживали монолит на 1 миллион строк кода преимущественно на PHP. Чтобы внедрить даже небольшую новую фичу, уходило 2 месяца. А затраты на инфраструктуру на 10 000 активных пользователей превышали 1 000 $ в год.
Как это произошло? Дело в том, что за 10 лет в проекте сменилось несколько команд разработки. Приходили новые люди, как и я, они по-своему добавляли новые модули и фичи. Команды менялись, новички не всегда понимали, как работают старые части системы, в итоге код Lingualeo постепенно превратился в чёрный ящик: непрозрачная логика в бэкенде, перегруженный фронт, обилие костылей, большие пробелы в документации.
Всего у нас в штате было 20 разработчиков, но развивать продукт было невозможно: если что-то добавить, вылезали неожиданные проблемы. У команды уходило 2–3 недели, чтобы всё починить. Разработчики занимались поддержкой кода из 2013 года, и ресурсов на обновление функциональности не было.
С такими проблемами сталкивается большое количество компаний, которые развивают зрелые ИТ-продукты, написанные на технологиях десятилетней давности. Тренды меняются, но из-за старой архитектуры не все новинки можно использовать.
Продукт развивается и обрастает функциями, но их не успевают подробно документировать. Эти проблемы решают по-разному, но мы решили так: нужно выстроить новую систему с нуля и сохранить максимум продуктовой логики, чтобы пользовательский опыт в Lingualeo не поменялся.
Шаг 1. Собрали прототип новой архитектуры
Нам предстояло придумать, как обновить техническую составляющую сервиса и заново выстроить Lingualeo на современных технологиях. Я предложил руководству полностью сменить философию бэкенда: перенести бизнес-логику в базу данных, а саму базу данных MySQL заменить на PostgreSQL.
Я начал с прототипа на бумаге: нарисовал новую архитектуру, объяснил, как получится увеличить производительность и сколько ресурсов уйдёт на подготовку. Защищать проект было сложно, потому что под рукой не было однозначных историй успеха: никто не пишет о том, как провести миграцию сервиса с 20 миллионами пользователей без остановки бизнеса. Но в Lingualeo решили пойти на риск и одобрили план изменений.
Схема архитектуры до миграции
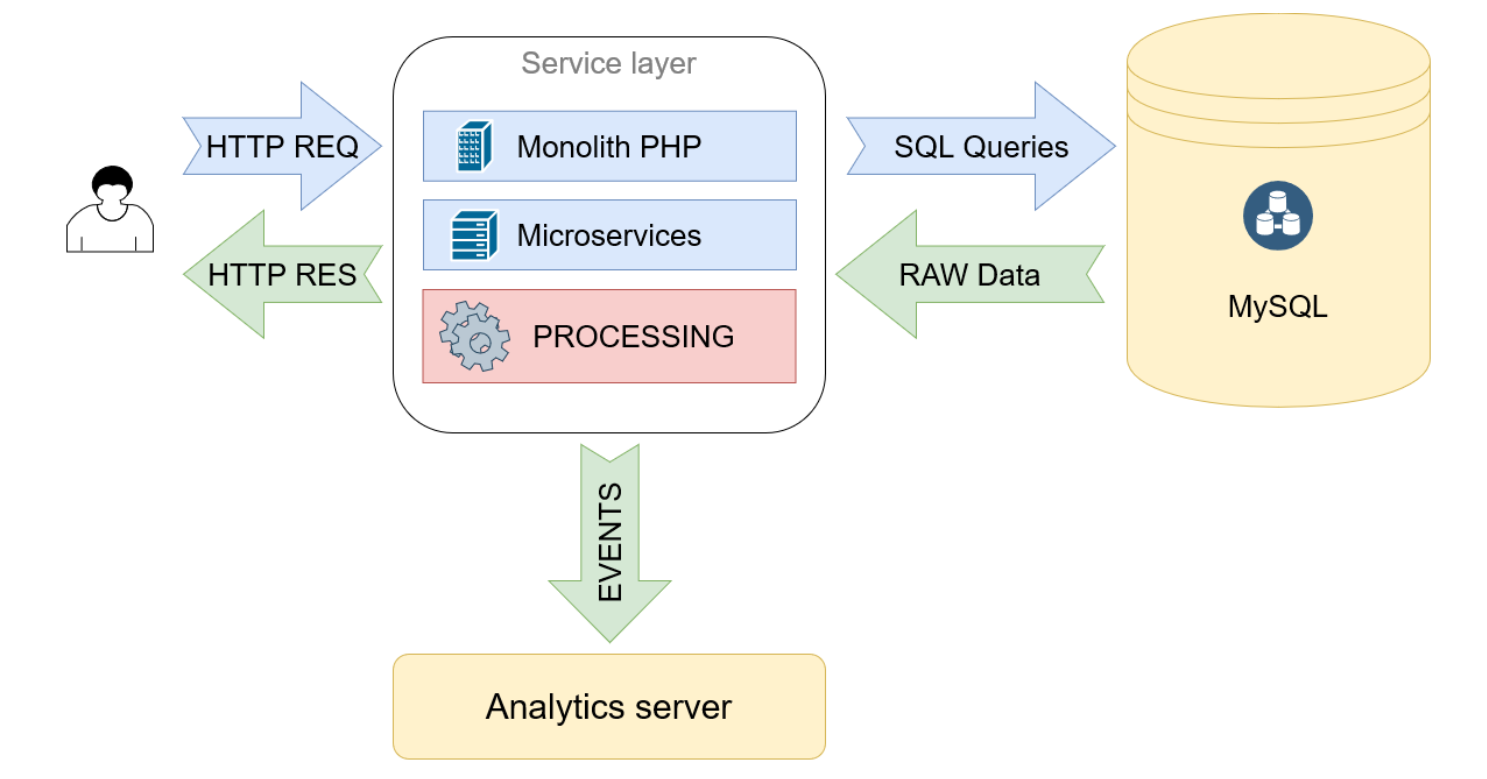
Запросы с фронта приходят в монолит на PHP, он обрабатывает их, многократно обращается к БД в MySQL и получает оттуда сырые данные. Затем обрабатывает их и формирует ответы в JSON
Схема новой архитектуры

Меняем SQL на PostgreSQL, переносим туда расчёты и создание JSON. Убираем монолит и ставим вместо него прокси-сервис, который направляет запросы в нужную базу данных, а затем отдаёт готовый JSON на фронт
Шаг 2. Обновили команду
Когда мы поделились планами с разработчиками, стало понятно, что команда не готова к изменениям. Большинство людей покинули компанию: остались только те, кто пришёл совсем недавно. Чтобы провести миграцию, мы решили заново собрать команду разработки.Искали амбициозных и готовых к переменам, профессиональных и ответственных. Старались обращать внимание не только на качество кода, но и на софт скиллз. Мы заново выстраивали архитектуру сервиса, поэтому нужны были люди, которые не испугаются сложных проектов и будут готовы решать задачи, с которыми раньше не сталкивались.
Некоторых людей нашли случайно, как, например, и меня: я познакомился с CEO Lingualeo Владимиром Сиротинским в самолёте. Будущего лидера фронтэнда Владимир встретил на консультации другого стартапа. Но большинство новых разработчиков мы набрали с рынка. Чтобы закрыть 8 вакансий, мы изучили 1118 откликов и провели 124 собеседования:
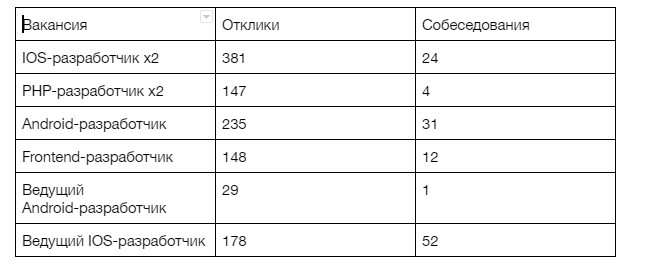
Воронка кандидатов на вакансии новых разработчиков в Lingualeo.
Шаг 3. Упростили оргструктуру
У нас три направления разработки: веб, бэкэнд и мобильные приложения, также есть отдел тестировщиков. Найти кого-то, кто понимает во всех отраслях сразу, в короткий срок очень сложно. Поэтому мы решили отказаться от технического директора и сделать оргструктуру новой команды максимально плоской. В компании остался только один уровень менеджмента — по одному лидеру в каждом направлении.
Мы проводим регулярные встречи и общаемся напрямую, поэтому разработка стала более прогнозируемой, сроки сократились. Технический директор может принять нерациональное решение, например, неправильно распределить ответственность между командами. В системе, где лиды общаются без дополнительного слоя менеджеров, вероятность нерациональных решений снижается: любую проблему мы всегда можем обсудить в личной беседе.
Например, если я понимаю, что какую-то функцию в новой структуре будет логичнее реализовать в базе данных, а не на фронте, я пишу в чат и обсуждаю идею с лидером фронтэнда. Не нужно договариваться о встрече с техническим директором или готовить презентацию, чтобы подкрепить свою идею.
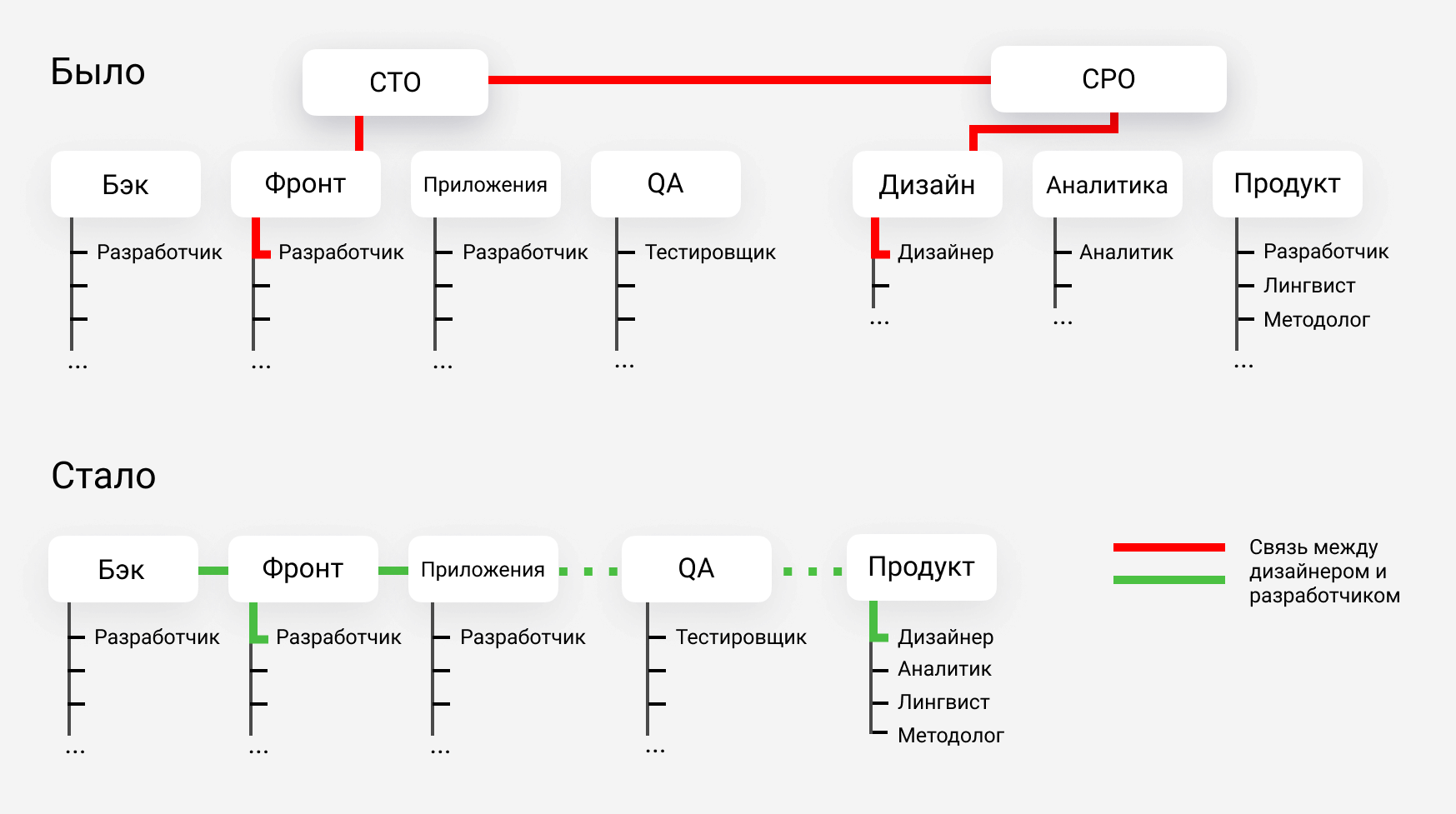
Оргструктура до и после изменений: отказались от технического директора в разработке и упростили структуру в продуктовом отделе. Сейчас продуктовому дизайнеру не нужно общаться с двумя уровнями менеджеров, чтобы передать идею на фронт
Шаг 4. Перенесли бизнес-логику в базы данных
Раньше бизнес-логика Lingualeo была на фронте и в приложениях. Функции продукта решались системами, которые не предназначены для обработки данных, например, в коде на JavaScript или PHP. Поэтому мы перенесли бизнес-логику Lingualeo в базы данных на PostgreSQL.
Джунгли
Один из 4 главных разделов сервиса Lingualeo — Джунгли. Это набор материалов на иностранном языке — текстов, аудио и видео, — в которых к любому слову можно узнать перевод. То есть, пользователи изучают реальный контент на английском, а если что-то непонятно, могут кликнуть на слово в тексте или в субтитрах к видео и посмотреть перевод.
Текст в Джунглях
Видео в Джунглях
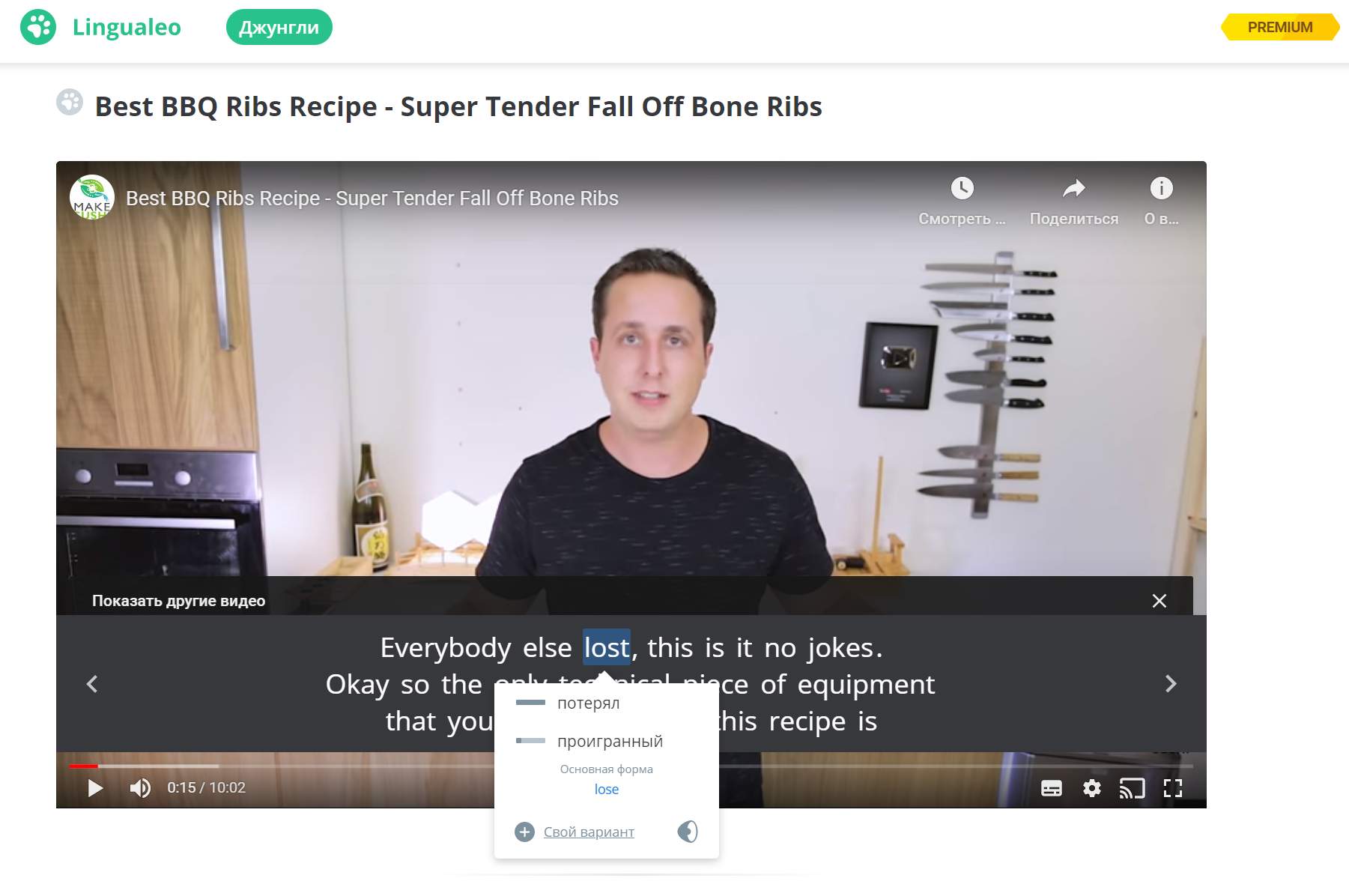
Чтобы заработала функция перевода слов по клику, текст надо разделить на слова, выражения и словосочетания. Затем — обратиться к словарю и вывести пользователю перевод в новом окошке поверх текста. Разбить текст для перевода довольно трудно: есть устойчивые выражения и фразовые глаголы, которые нет смысла делить на два слова. Например, take off и take — разные по значению единицы контента, хотя включают в себя одно и то же слово.
Вся логика этой функции вместе с исключениями и сложными правилами деления текста раньше была написана на JavaScript на фронте. Функция была очень громоздкой, перевод мог занимать много времени.
Мы реализовали эту функцию в базе данных. Бэк передаёт на фронт готовый JSON, в котором текст уже разбит на слова и выражения. Каждому слову и выражению в базе присвоен ID, по которому легко найти перевод. Также в JSON учитывается, какие слова есть в словаре у пользователя, а каких — пока нет. На фронте остаётся просто отобразить информацию и подсветить слова с определёнными признаками.
Словари
С разделом Словарей сделали так же: вся работа теперь происходит в базе данных. У нас есть пользователи, у которых в словаре больше 100 000 слов и выражений. В словаре нужно обеспечить удобный поиск, разбить слова на группы, дать пользователю широкий набор фильтров.
Раньше логика словарей была на стороне фронта или в прослойке на PHP, а сейчас в системе появился полноценный API между фронтом и бэкендом. Можно отправить один запрос с большим количеством параметров в базу данных, и оттуда придёт готовый JSON:

Фильтры словаря: поиск по словам, выбор слов по видам тренировки, выбор между словами и фразами, фильтр по изученным и новым словам
Курсы
Перенос бизнес-логики в базу данных многократно уменьшил количество кода и ускорил работу сервиса. Например, изменился бэкенд-код страницы Курсов после миграции. Её видят зарегистрированные пользователи, а курсы туда отбираются системой по десятку критериев. Раньше такая страница формировалась 600 мсек и отправляла 12 запросов в базу данных, сейчас — всего один:

Шаг 5. Учли обратную связь пользователей после релиза
На разработку ушло примерно полгода: мы занялись обновлениями в конце 2018, а релиз состоялся в мае 2019 года. Большинство пользователей ощутили, что сервис стал работать гораздо быстрее. Раньше в Lingualeo могли без потери скорости заниматься не более 2 000 человек одновременно, а сейчас система выдерживает пики больше 100 000 пользователей.
Часть людей заметили и негативные последствия. Мигрируя с чёрным ящиком, сложно обеспечить сохранность ста процентов данных, поэтому у кого-то потерялись слова из словаря, у кого-то — некорректно отображался прогресс в курсах.
Постепенно мы с командой пофиксили все проблемы. Главный результат перемен в том, что теперь мы работаем не с чёрным ящиком, а с простой и прозрачной системой, поэтому отрабатывать обратную связь было гораздо легче.
Lingualeo стал быстрее для пользователей и удобнее для разработчиков
В апреле 2020 во время самоизоляции нагрузка на Lingualeo была в пять раз больше по сравнению с аналогичным периодом год назад. Это не вызвало проблем: скорость работы сервиса не просела, пользователи ничего не заметили. Я уверен: если бы мы не обновили систему, сервис бы просто не выдержал.
Продукт стал не только быстрее для пользователей, но и гораздо проще для работы: теперь команде легче вводить и тестировать новые функции. Мы привели документацию в порядок, а код стал примерно в 40 раз меньше, так что новые разработчики легко разберутся в том, как устроен сервис.
Продукт стал обходиться дешевле, поэтому для него нужно арендовать меньше вычислительных мощностей. Затраты на активного пользователя в Lingualeo сократились более чем в 50 раз, хотя после обновлений число активных юзеров уже удвоилось.
Наконец, продукт стал безопаснее. Раньше, когда вся бизнес-логика была в прослойке на PHP, оттуда из разных функций шли запросы в базу данных. Открытая для SQL-запросов база данных — это проблема: можно сделать SQL-инъекцию и заставить её выполнить опасный код, например, удаление данных. Сейчас снаружи не приходит ни одного SQL-запроса, потому что мы перенесли всю логику внутрь».
Мы хотим и дальше регулярно писать в блог о том, как устроена разработка в обновлённом Lingualeo. Пишите в комментариях, о чём стоит рассказать в первую очередь: у нас поменялась и команда, и структура управления, и технологии. Будем рады ответить на все вопросы.
