
Всем привет!
Так сложилось, что наша небольшая команда разработки, не сказать, чтобы недавно, и уж точно не внезапно, доросла до переноса некоторых (а в перспективе и всех) продуктов в Kubernetes.
Причин тому было множество, но наша история не про холивар.
Из инфраструктурной основы выбор у нас был небольшой. vCloud Director и vCloud Director. Выбрали версию поновее и решили начать.
В очередной раз полистав «The Hard Way», я очень быстро пришёл к выводу, что инструмент для автоматизации хотя бы базовых процессов, таких как деплой и сайзинг, нужен ещё вчера. Глубокое погружение в Google явило на свет такой продукт как VMware Container Service Extension (CSE) — опенсорсный продукт, позволяющий автоматизировать создание и сайзинг k8s кластеров для тех, кто в vCloud-е.
Disclaimer: CSE имеет свои ограничения, но для наших целей он подошёл идеально. Также решение должно поддерживаться облачным провайдером, но так как серверная часть также open-source, требуйте его наличия у ближайшего менеджера :)
Установка клиента CSE
- Для начала вам понадобится аккаунт администратора в организации vCloud и заблаговременно созданная routed-сеть для кластера. Важно: в процессе деплоя необходим доступ в интернет из этой сети, не забудьте настроить Firewall/NAT.
Адресация не имеет значения. В данном примере возьмём 10.0.240.0/24:

Так как после создания кластером нужно будет как-то управлять, рекомендуется наличие VPN с маршрутизацией в созданную сеть. Мы используем стандартный SSL-VPN, настроенный на Edge Gateway нашей организации.
- Далее необходимо установить CSE клиент туда, откуда будет осуществляться управление кластерами k8s. В моем случае это рабочий ноут и пара
хорошо припрятанныхконтейнеров, которые рулят автоматизацией.
Клиент требует наличия установленного Python версии 3.7.3 и выше и установленного модуля vcd-cli, поэтому установим и то и другое.
pip3 install vcd-cli pip3 install container-service-extension - После установки проверяем версию CSE и получаем следующее:
# vcd cse version Error: No such command "cse".
Неожиданно, но поправимо. - Как оказалось, CSE необходимо прикрутить как модуль к vcd-cli.
Для этого необходимо сначала залогинить vcd-cli в нашу организацию:
# vcd login MyCloud.provider.com org-dev admin Password: admin logged in, org: 'org-dev', vdc: 'org-dev_vDC01' - После этого vcd-cli создаст файл конфигурации ~/.vcd-cli/profiles.yaml
В его конец необходимо добавить следующее:
extensions: - container_service_extension.client.cse - После чего повторно проверяем:
# vcd cse version CSE, Container Service Extension for VMware vCloud Director, version 2.5.0

Этап установки клиента завершён. Попробуем развернуть первый кластер.
Развертывание кластера
CSE имеет несколько наборов параметров использования, все их можно посмотреть здесь.
- Для начала создадим ключи для беспарольного доступа к будущему кластеру. Этот момент важен, так как по умолчанию вход по паролю на ноды будет отключен. И, если не задать ключи, можно получить много работы через консоли виртуальных машин, что не сказать, чтобы удобно.
# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. - Пробуем запустить создание кластера:
vcd cse cluster create MyCluster --network k8s_cluster_net --ssh-key ~/.ssh/id_rsa.pub --nodes 3 --enable-nfs - Если получаем ошибку Error: Session has expired or user not logged in. Please re-login. — снова логиним vcd-cli в vCloud, как описано выше, и повторяем попытку.
В этот раз всё хорошо, и задача создания кластера запустилась.
cluster operation: Creating cluster vApp 'MyCluster' (38959587-54f4-4a49-8f2e-61c3a3e879e0) from template 'photon-v2_k8-1.12_weave-2.3.0' (revision 1) - На завершение задачи понадобится около 20 минут. А пока разберем основные параметры запуска.
- --network — созданная нами ранее сеть.
- --ssh-key — созданные нами ключи, которые будут записаны на ноды кластера.
- --nodes n — Количество Worker нод кластера. Мастер будет всегда один, это ограничение CSE.
- --enable-nfs — создать дополнительную ноду для NFS шары под persistent volumes. Немного педальная опция, к донастройке того, что она делает, мы вернёмся чуть позже.
- Тем временем в vCloud можно визуально наблюдать за созданием кластера.

- Как только задача создания кластера завершилась, он готов к работе.
- Проверим корректность деплоя командой vcd cse cluster info MyCluster.

- Далее нам необходимо получить конфигурацию кластера для использования kubectl.
# vcd cse cluster config MyCluster > ./.kube/config - И можно проверить состояние кластера уже с помощью неё:

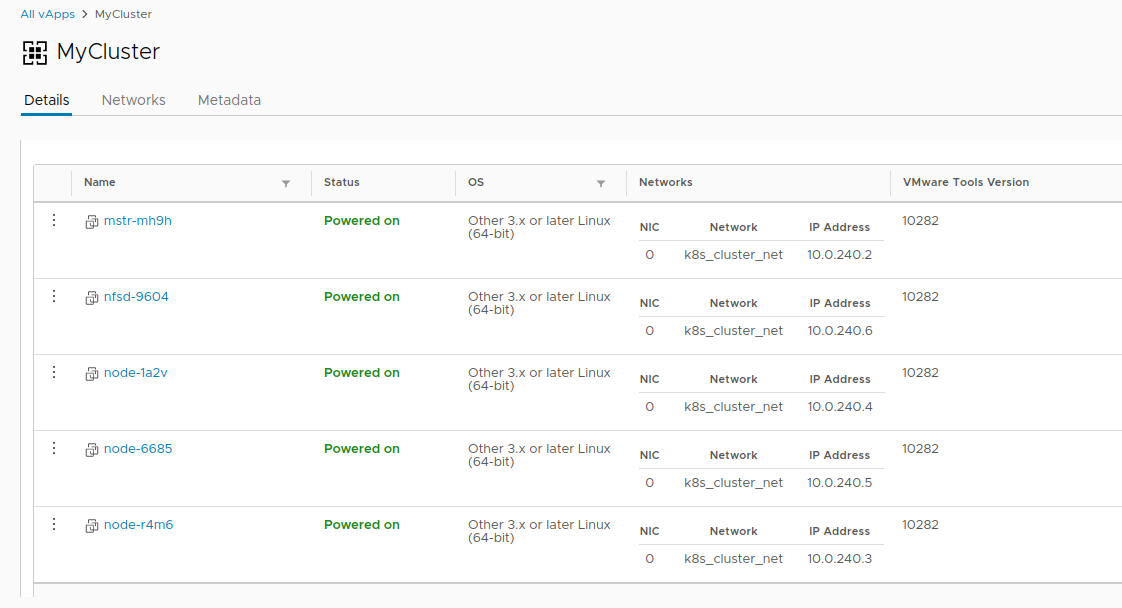


Не всё так просто
На этом моменте кластер можно считать условно рабочим, если бы не история с persistent volumes. Так как мы в vCloud-е, использовать vSphere Provider не получится. Опция --enable-nfs призвана сгладить эту неприятность, но получилось не до конца. Требуется ручная донастройка.
- Для начала нашей ноде необходимо создать отдельный Independent диск в vCloud. Это даёт гарантию того, что наши данные не исчезнут вместе с кластером, буде он удалён. Также, подключим диск к NFS.
# vcd disk create nfs-shares-1 100g --description 'Kubernetes NFS shares' # vcd vapp attach mycluster nfsd-9604 nfs-shares-1 - После этого идём по ssh (вы же правда, создали ключи?) на нашу NFS ноду и окончательно подключаем диск:
root@nfsd-9604:~# parted /dev/sdb (parted) mklabel gpt Warning: The existing disk label on /dev/sdb will be destroyed and all data on this disk will be lost. Do you want to continue? Yes/No? yes (parted) unit GB (parted) mkpart primary 0 100 (parted) print Model: VMware Virtual disk (scsi) Disk /dev/sdb: 100GB Sector size (logical/physical): 512B/512B Partition Table: gpt Disk Flags: Number Start End Size File system Name Flags 1 0.00GB 100GB 100GB primary (parted) quit root@nfsd-9604:~# mkfs -t ext4 /dev/sdb1 Creating filesystem with 24413696 4k blocks and 6111232 inodes Filesystem UUID: 8622c0f5-4044-4ebf-95a5-0372256b34f0 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done - Создаём директорию под данные и маунтим туда свежий раздел:
mkdir /export echo '/dev/sdb1 /export ext4 defaults 0 0' >> /etc/fstab mount -a - Cоздадим пять тестовых разделов и расшарим их для кластера:
>cd /export >mkdir vol1 vol2 vol3 vol4 vol5 >vi /etc/exports #Добавим это в конец файла /export/vol1 *(rw,sync,no_root_squash,no_subtree_check) /export/vol2 *(rw,sync,no_root_squash,no_subtree_check) /export/vol3 *(rw,sync,no_root_squash,no_subtree_check) /export/vol4 *(rw,sync,no_root_squash,no_subtree_check) /export/vol5 *(rw,sync,no_root_squash,no_subtree_check) #:wq! ;) #Далее - экспортируем разделы >exportfs -r - После всей этой магии можно создать PV и PVC в нашем кластере примерно так:
PV
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: PersistentVolume metadata: name: nfs-vol1 spec: capacity: storage: 10Gi accessModes: - ReadWriteMany nfs: # Same IP as the NFS host we ssh'ed to earlier. server: 10.150.200.22 path: "/export/vol1" EOF
PVC
cat <<EOF | kubectl apply -f - apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs-pvc spec: accessModes: - ReadWriteMany storageClassName: "" resources: requests: storage: 10Gi EOF
На этом история создания одного кластера заканчивается и начинается история его жизненного цикла. В качестве бонуса — ещё две полезные команды CSE, позволяющие временами неплохо экономить
#Увеличиваем размер кластера до 8 воркер нод
>cse cluster resize MyCluster --network k8s_cluster_net --nodes 8
#Выводим ненужные ноды из кластера с их последующим удалением
>vcd cse node delete MyCluster node-1a2v node-6685 --yes
Всем спасибо за уделённое время, если будут вопросы — задавайте в коментариях.
