
В последнее время на рынке появилось огромное количество новых языков программирования: Go, Swift, Rust, Dart, Julia, Kotlin, Hack, Bosque – и это только из числа тех, которые на слуху.
Ценность того, что эти языки привносят в мир программирования, тяжело переоценить, но, как правильно в прошлом году отмечал Y Combinator, говоря про инструменты разработки:
Фреймворки становятся лучше, языки немного умнее, но в основном мы делаем то же самое.В данной статье будет рассказано о языке, построенном на подходе, принципиально отличающемся от подходов, используемых во всех существующих языках, в том числе вышеперечисленных. По большому счету, этот язык можно считать языком общего назначения, хотя некоторые его возможности и текущая реализация платформы, построенной на нем, все же, наверное, ограничивают его применение немного более узкой областью – разработкой информационных систем.
Сразу оговорюсь, речь пойдет не об идее, прототипе, и даже не о MVP, а о полноценном production-ready языке со всей необходимой языку инфраструктурой – от среды разработки (с отладчиком) до автоматической поддержки нескольких версий языка (с автоматическими merge багфиксов между ними, release-note и т.п.). Кроме того, с использованием этого языка уже реализовано несколько десятков проектов сложности уровня ERP, с сотнями одновременных пользователей, терабайтными базами, сроками «нужно вчера», ограниченными бюджетами и разработчиками без опыта в IT. Причем все это одновременно. Ну и, конечно, следует учесть, что сейчас не 2000 год, и все эти проекты реализовывались поверх существующих систем (чего там только не было), а значит, сначала нужно было постепенно, без остановки бизнеса сделать «как было», а потом, также постепенно, сделать «как должно быть». В общем, это как продавать первые электромобили не богатым хипстерам в Калифорнии, а лоукост-службам такси где-нибудь в Омске.
Платформа, построенная на этом языке, выпускается под лицензией LGPL v3. Честно, не хотел это писать прямо во вступлении, так как это далеко не самое главное ее преимущество, но, пообщавшись с людьми, работающими на одном из ее основных потенциальных рынков – ERP платформ, заметил одну особенность: все эти люди без исключения говорят, что даже если вы сделаете то же самое, что уже есть на рынке, но бесплатно, то это уже будет очень круто. Так что оставлю это тут.
Немного теории
Начнем с теории, чтобы обозначить разницу в фундаментальных подходах, используемых в этом и других современных языках.
Небольшой дисклеймер, дальнейшие рассуждения в какой-то степени являются попыткой натянуть сову на глобус, но с фундаментальной теорией в программировании в принципе, скажем прямо, не очень, поэтому приходится использовать то, что есть.
Одной из самых первых и главных задач, решаемых программированием, является задача вычисления значений функций. С точки зрения теории вычислений, в решении этой задачи существует два принципиально разных подхода.
Первым таким подходом являются различные машины (самой известной из которых является машина Тьюринга) – модель, которая состоит из текущего состояния (памяти) и машины (процессора), которая на каждом шаге тем или иным образом изменяет это текущее состояние. Этот подход также принято называть архитектурой Фон Неймана, и именно он лежит в основе всех современных компьютеров и 99 процентов существующих языков.
Второй подход основан на использовании операторов, его используют так называемые частично-рекурсивные функции (далее ЧРФ). При этом самое главное отличие этого подхода не в использовании операторов как таковых (операторы, к примеру, есть и в структурном программировании, использующим первый подход), а в возможности итерирования по всем значениям функции (см. оператор минимизации аргумента) и в отсутствии состояния в процессе вычисления.
Как и машина Тьюринга, частично-рекурсивные функции полны по Тьюрингу, то есть с их помощью можно задать любое возможное вычисление. Здесь сразу уточним, что и машина Тьюринга, и ЧРФ – это только минимальные базисы, а дальше речь пойдет о них именно как о подходах, то есть о модели с памятью-процессором и о модели с операторами без использования переменных и возможностью итерирования по всем значениям функций соответственно.
У ЧРФ как подхода есть три основных преимущества:
- Он гораздо лучше оптимизируется. Это касается как непосредственно оптимизации самого процесса вычисления значения, так и возможности параллелизма такого вычисления. В первом же подходе эффект последействия, наоборот, вносит очень большую сложность в эти процессы.
- Он гораздо лучше инкрементируется, то есть для построенной функции можно гораздо эффективнее определить, как будут изменяться ее значения при изменении значений функций, которые эта построенная функция использует. Строго говоря, это преимущество является частным случаем первого, но именно оно дает огромное количество возможностей, которых принципиально не может быть в первом подходе, поэтому выделено отдельным пунктом.
- Он значительно проще для понимания. То есть, грубо говоря, описание функции подсчета суммы одного показателя в разрезе двух других показателей гораздо проще для понимания, чем если то же самое описать в терминах первого подхода. Впрочем, в алгоритмически сложных задачах ситуация диаметрально противоположная, но тут стоит отметить, что алгоритмически сложных задач в абсолютном большинстве областей хорошо если 5%. Вообще, если немного обобщить, то ЧРФ – это математика, а машины Тьюринга – это информатика. Соответственно, математику изучают чуть ли не в детском саду, а информатику факультативно и со старших классов. Так себе сравнение, конечно, но все же какую-то метрику в данном вопросе дает.
У машин Тьюринга есть как минимум два преимущества:
- Уже упомянутая лучшая применимость в алгоритмически сложных задачах
- Все современные компьютеры построены на этом подходе.
Плюс, в этом сравнении речь идет только о задачах вычисления данных, в задачах изменения данных без машин Тьюринга все равно не обойтись.
Дочитав до этого места, любой внимательный читатель задаст резонный вопрос: “Если ЧРФ подход так хорош, почему он не используется ни в одном распространенном современном языке?”. Так вот, на самом деле, это не так, он используется, причем в языке, который применяется в подавляющем большинстве существующих информационных систем. Как легко догадаться, этим языком является SQL. Тут, конечно, тот же внимательный читатель резонно возразит, что SQL – это язык реляционной алгебры (то есть работы с таблицами, а не функциями), и будет прав. Формально. Фактически же можно вспомнить, что таблицы в СУБД обычно находятся в третьей нормальной форме, то есть имеют колонки-ключи, а значит, любую оставшуюся колонку этой таблицы можно рассматривать как функцию от ее колонок-ключей. Не очевидно, прямо скажем. И то, почему SQL так и не перерос из языка реляционной алгебры в полноценный язык программирования (то есть работы с функциями) – большой вопрос. На мой взгляд, причин тому много, самая главная из которых – «русский (на самом деле любой) человек на голодный желудок работать не может, а на сытый не хочет», в том смысле, что, как показывает практика, необходимая для этого работа поистине титаническая и несет слишком большие риски для небольших компаний, а у крупных компаний – во-первых, и так все хорошо, а во-вторых, эту работу невозможно форсировать деньгами – здесь важнее качество, а не количество. Собственно, самой наглядной иллюстрацией того, что бывает, когда проблему пытаются решать количеством, а не качеством, является Oracle, который даже самое базовое применение инкрементальности – обновляемые материализованные представления – ухитрился реализовать так, что у этого механизма количество ограничений размером с несколько страниц (справедливости ради, у Microsoft все еще хуже). Впрочем, это уже отдельная история, возможно, про нее будет отдельная статья.
В то же время речь не идет о том, что SQL плох. Нет. На своем уровне абстрагирования он отлично выполняет свои функции, и текущая реализация платформы использует его чуть менее, чем полностью (во всяком случае, значительно больше, чем все остальные платформы). Другое дело, что сразу после своего рождения SQL фактически остановился в развитии и так и не стал тем, кем мог стать, а именно языком, о котором сейчас пойдет речь.
Но хватит теории, пора переходить непосредственно к языку.
Итак, встречаем:

Конкретно эта статья будет первой частью из трех (так как материала все же слишком много даже для двух статей), и в ней будет рассказано только про логическую модель – то есть только про то, что связано непосредственно с функционалом системы и никак не связано с процессами разработки и выполнения (оптимизации производительности). Более того, речь пойдет только об одной из двух частей логической модели – логике предметной области. Эта логика определяет, какую информацию хранит система, и что с этой информацией можно делать (при разработке бизнес-приложений ее также часто называют бизнес-логикой).
Графически все понятия логики предметной области в lsFusion можно представить следующей картинкой:
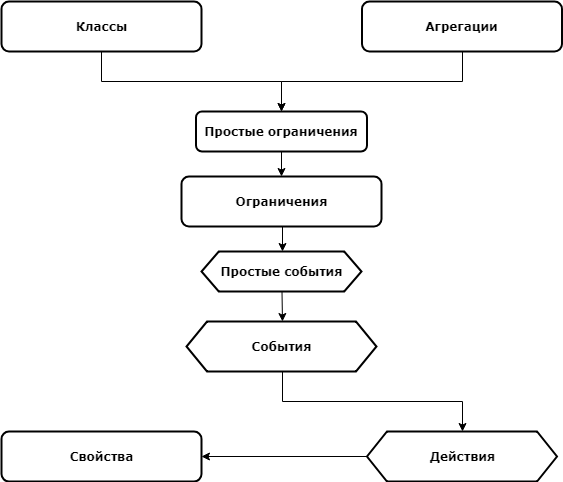
Стрелки на этой картинке обозначают направления использования понятиями друг друга, таким образом, понятия образуют своего рода стек, и, соответственно, именно в порядке этого стека я и буду про них рассказывать.
Оглавление
- Свойства
- Действия
- Цикл (FOR), Рекурсивный цикл (WHILE)
- Вызов (EXEC), Последовательность ({…}), Ветвление (CASE, IF), Прерывание (BREAK), Выход (RETURN)
- Изменение свойства (CHANGE)
- Добавление объектов (NEW)
- Удаление объектов (DELETE)
- Сессии изменений
- Создание сессий (NEWSESSION, NESTEDSESSION)
- Применение изменений (APPLY), Отмена изменений (CANCEL)
- Операторы работы с изменениями (PREV, CHANGED, SET, DROPPED)
- События
- Ограничения
- Классы
- Агрегации
Свойства
Свойство – это абстракция, которая принимает на вход один или несколько объектов в качестве параметров и возвращает некоторый объект в качестве результата. Свойство не имеет последействия, и, по сути, является чистой функцией, однако, в отличие от последней, может не только вычислять значения, но и хранить их. Собственно, само название “свойство” позаимствовано из других современных языков программирования, где оно используется приблизительно для тех же целей, но при этом гвоздями прибито к инкапсуляции и, соответственно, поддерживается только для функций с одним параметром. Ну и в пользу использования именно этого термина сыграло то, что это само слово “свойство” короче, чем «чистая функция», плюс не имеет ненужных ассоциаций.
Свойства задаются рекурсивно при помощи предопределенного набора операторов. Этих операторов достаточно много, поэтому рассмотрим только основные из них (эти операторы покрывают 95% любого среднестатического проекта).
Первичное свойство (DATA)
Первичное свойство – это свойство, значение которого хранится в базе данных и может изменяться в результате выполнения соответствующего действия (о нем чуть позже). По умолчанию значение каждого такого свойства для любого набора параметров равно специальному значению NULL.
quantity = DATA INTEGER (Item); |
Фактически этот оператор обобщает поля и коллекции в современных языках. Так:
class X {
Y y;
Map<Y, Z> f;
Map<Y, Map<M, Z>> m;
List<Y> n;
LinkedHashSet<Y> l; // упорядоченное множество
static Set<Y> s;
}
Эквивалентно:
y = DATA Y (X); |
Композиция (JOIN), Константа, Арифметические (+,-,/,*), Логические (AND, OR), Строковые (+, CONCAT), Сравнение (>,<,=), Выбор (CASE, IF), Принадлежность классу (IS)
f(a) = IF g(h(a)) > 5 AND a IS X THEN ‘AB’ + ‘CD’ ELSE x(5); |
- В логических операторах и операторах выбора в качестве условий можно использовать не только свойства со значениями логических типов, а вообще любые свойства. Соответственно, условием в этом случае будет определенность значения свойства (то есть отличие от NULL). Собственно, сам логический тип в lsFusion – это, по сути, константа, то есть его множество значений состоит из ровно одного элемента – значения TRUE (роль FALSE выполняет значение NULL), никаких крышесносящих 3-state’ов.
- Для арифметических и строковых операторов есть специальные формы работы с NULL: (+), (-), CONCAT с сепаратором. При использовании этих форм:
- в арифметических операторах: NULL на входе интерпретируется как 0, а на выходе – наоборот, 0 заменяется на NULL (то есть 5 (+) NULL = 5, 5 (-) 5 = NULL, но 5 + NULL = NULL и 5 — 5 = 0).
- в строковых операторах: NULL на входе игнорируется и соответственно сепаратор не добавляется (то есть CONCAT ‘ ‘, ‘John’,’Smith’ = ‘John Smith’, а CONCAT ‘ ‘, ‘John’, NULL = ‘John’, но ‘John’ + ‘ ‘ + NULL = NULL).
- в арифметических операторах: NULL на входе интерпретируется как 0, а на выходе – наоборот, 0 заменяется на NULL (то есть 5 (+) NULL = 5, 5 (-) 5 = NULL, но 5 + NULL = NULL и 5 — 5 = 0).
- Для оператора простого выбора (IF) существует (и очень часто используется) постфиксная форма: f(a) IF g(a), которая возвращает f(a) если g(a) не NULL, и NULL – в обратном случае.
Группировка (GROUP)
Группировка – самый часто используемый оператор работы со множествами. Этот оператор берет свойство и для всех его значений вычисляет некоторую агрегирующую функцию (например, сумму) в разрезе значений других свойств.
С точки зрения синтаксиса есть две формы этого оператора:
- Функциональный:
Эта форма допускает замыкания на лексический контекст, то есть внутри оператора можно использовать параметры внешнего контекста (в примерах выше параметры i и sk). Особенность функциональной формы в том, что ее можно использовать в выражениях, то есть писать что-то вроде:sum(Invoice i) = GROUP SUM sum(InvoiceDetail id) IF invoice(id) = i;
currentBalance(Sku sk) = GROUP SUM currentBalance(sk, Stock st);x() = (GROUP SUM f(a)) + 5; - SQL-стиль:
В отличие от функциональной эту форму оператора можно использовать только при объявлении свойств (как и, скажем, оператор создания первичного свойства)sum = GROUP SUM sum(InvoiceDetail id) BY invoice(id);
currentBalance = GROUP SUM currentBalance(Sku sk, Stock st) BY sk;
С точки зрения лаконичности кода первую форму имеет смысл использовать, когда группировка идет по параметрам (пример с остатком), вторую – по свойствам (пример с инвойсом). Хотя, по большому счету, это все же дело вкуса, кому как привычнее (для людей больше работавших с функциональным программированием, скорее будет привычна первая форма, для работавших с SQL – вторая). Кстати говоря, при желании можно использовать смесь этих форм (то есть когда можно и обращаться к верхним параметрам и использовать опцию BY), что-то вроде:
// BY отображается только на неиспользованные параметры, то есть s |
В качестве агрегирующей функции кроме суммы также поддерживаются:
- Максимум/минимум,
- Строковое объединение в заданном порядке
- Последнее значение в заданном порядке.
Разбиение / Упорядочивание (PARTITION … ORDER)
Описанный выше оператор группировки разбивает все объекты (а точнее, наборы объектов) в системе на группы, после чего для каждой группы вычисляет некоторое значение. Однако в некоторых случаях значение нужно вычислять не для самой группы, а для непосредственно группируемых наборов объектов (но делать это в контексте группы, в которую этот набор входит). Для выполнения такого рода вычислений в языке существует специальный оператор разбиения / упорядочивания.
place(Team t) = PARTITION SUM 1 ORDER DESC points(t) BY conference(t); |
Аналогом этого оператора в SQL (и то, при помощи чего он реализуется) являются оконные функции (OVER PARTITION BY… ORDER BY).
Рекурсия (RECURSION)
Рекурсия – наверное, самый сложный для понимания оператор работы с множествами. Он нужен для реализации вычислений с неизвестным заранее количеством итераций, в частности, для работы с графами.
Для оператора рекурсии необходимо задать начальное свойство и свойство шага. Соответственно, алгоритм вычисления этого оператора состоит в следующем (далее почти дословная цитата из документации):
- Сначала рекурсивно строится промежуточное свойство (result) с дополнительным первым параметром (номером операции) следующим образом:
- result(0, o1, o2, ..., oN) = initial(o1, ..., oN), где initial – начальное свойство
- result(i+1, o1, o2, ..., oN) = step(o1, ..., oN, $o1, $o2, ..., $oN) IF result(i, $o1, $o2, ..., $oN), где step – свойство шага.
- result(0, o1, o2, ..., oN) = initial(o1, ..., oN), где initial – начальное свойство
- Затем для всех значений полученного свойства вычисляется сумма в разрезе всех его параметров, за исключением номера операции (то есть o1, o2, …, oN). Теоретически вместо суммы может быть любая агрегирующая функция, но в текущей реализации поддерживается только сумма.
Не самое очевидное определение, скажем прямо, поэтому суть этого оператора, наверное, все же проще понять по примерам:
// итерация по integer от from до to (это свойство по умолчанию входит в модуль System) |
Кстати, забавно, что хотя определение этого оператора очень похоже на определение оператора примитивной рекурсии в ЧРФ, в ЧРФ примитивную рекурсию можно применять, только если количество итераций заранее известно, а в lsFusion – наоборот.
Аналогом оператора рекурсии в SQL являются рекурсивные CTE, правда, при выполнении платформа редко их использует, так как там очень большое количество ограничений. В частности, в Postgres там нельзя использовать GROUP BY для шага, что, по сути, означает, что при пробеге по графу для вершин нельзя использовать пометки, а значит, количество итераций растет экспоненциально. Поэтому на практике платформа, как правило, использует табличные функции с WHILE’ом внутри.
На этом с описанием операторов создания свойств закончим. Это не все операторы, но остальные либо значительно реже используются, либо относятся к другим уровням абстракции языка и будут рассмотрены там.
Действия
Действие – это некоторая абстракция, которая принимает на вход некоторые объекты в качестве параметров, и, используя их тем или иным способом, изменяет состояние системы (как той, в которой это действие выполняется, так и состояние любой другой внешней системы). Тут конечно, наверное, можно было бы использовать термин “процедура”, но, во-первых, он уже достаточно давно устарел, а, во-вторых, само слово более громоздкое и непонятное, чем “действие”.
Вообще, свойства и действия – это своего рода Инь и Янь программирования в lsFusion. Свойства используют подход ЧРФ, действия – подход машины Тьюринга. Свойства обрабатываются на сервере БД, действия – на сервере приложений (тут на самом деле есть достаточно много магии, когда платформа перемещает эти обработки между серверами, поэтому речь тут скорее идет о том, где эти абстракции обрабатываются по умолчанию). Свойства отвечают за хранение и вычисление данных, действия – за изменение. И так далее.
Стоит отметить, что разбиение на свойства и действия неявно есть и в других языках. Так арифметические / логические операторы, переменные, поля и вообще все, что можно использовать в выражениях, можно отнести к логике свойств, все остальное к логике действий. Но если в других языках это соотношение хорошо если 3 на 97, то в lsFusion в среднестатистическом проекте – минимум 60 на 40.
Действия, как и свойства, задаются рекурсивно при помощи предопределенного набора операторов. Этих операторов, опять-таки, достаточно много (на самом деле их в несколько раз больше, чем операторов создания свойств), поэтому также рассмотрим только основные из них.
Начнем с операторов, отвечающих за порядок выполнения:
Цикл (FOR), Рекурсивный цикл (WHILE)
Несмотря на такое же название, цикл в lsFusion существенно отличается от аналогичного понятия в других языках программирования, и построен на упомянутой ранее операции итерирования по всем наборам объектов, для которых значение заданного свойства не NULL (будем называть это свойство условием цикла).
FOR selected(Team team) DO |
showAllDetails(Invoice i) { |
Рекурсивный цикл (WHILE) отличается от обычного цикла только тем, что:
- продолжает выполнения до тех пор, пока для условия цикла есть хоть одно не NULL значение (в этом смысле он очень похож на оператор рекурсии в свойствах)
- не обязан вводить новый параметр
Вызов (EXEC), Последовательность ({…}), Ветвление (CASE, IF), Прерывание (BREAK), Выход (RETURN)
f(a) { |
Изменение свойства (CHANGE)
Этот оператор позволяет изменять значения первичных свойств. При этом, делать это, он может не только для одного набора значений объектов, но и для всех наборов объектов, для которых значение заданного свойства не равно NULL. Например:
// изменить скидку для выбранных товаров для клиента |
setDiscount(Customer c) { |
Добавление объектов (NEW)
Этот оператор добавляет объект заданного класса (про классы вот уже совсем скоро, хотя ничего особенного, во всяком случае, в их способе задания, нет). Так же как и для оператора изменения свойства, можно добавлять не один, а сразу много объектов для заданного условия.
Синтаксис оператора добавления объектов похож на синтаксис оператора изменения свойства:
newSku () { |
FOR iterate(i, 1, 3) NEW s=Sku DO { |
NEW s=Sku DO { |
Удаление объектов (DELETE)
Тут все достаточно просто и во многом аналогично двум верхним операторам – оператор удаления объектов удаляет один или множество объектов для заданного условия:
DELETE Sku s WHERE name(s) = 'MySku'; |
Перед тем как перейти к следующим операторам, необходимо рассказать еще об одном важном понятии, используемом в логике действий.
Сессии изменений
Как уже упоминалось ранее, действие в результате своего выполнения может изменять состояние системы, в которой оно выполняется. Записывать эти изменения сразу в базу данных не всегда желательно, как с точки зрения целостности, так и с точки зрения эргономики системы. Поэтому в платформе существует возможность накапливать эти изменения локально в так называемых сессиях изменений.
Изменениями в сессии могут быть изменения первичных свойств, а также изменения классов объектов. Первые осуществляются при помощи описанного выше оператора изменения свойства, вторые — при помощи операторов добавления / удаления объектов.
Каждый раз, когда действие выполняется, в зависимости от контекста выполнения для него определяется текущая сессия. Например, если действие вызывается как обработчик некоторого события формы (наиболее частый случай), то текущей сессией для него будет сессия этой формы.
Если действие в процессе выполнения обращается к некоторому свойству, то его значение вычисляется с учетом изменений, сделанных в текущей сессии этого действия. Так, например:
LOCAL f = INTEGER (INTEGER, INTEGER); |
Создание сессий (NEWSESSION, NESTEDSESSION)
Сессии создаются автоматически в самых верхних по стеку операциях (например, вызов действия из навигатора, через http-запрос и т.п.). Однако в процессе выполнения одного действия часто возникает необходимость выполнить другое действие в новой, отличной от текущей, сессии. Обычно такая необходимость возникает, если неизвестен контекст выполнения действия, и, применяя изменения текущей сессии «вслепую», можно случайно применить «чужие» изменения (то есть те, которые не надо было применять). Для реализации такой возможности в платформе есть специальный оператор NEWSESSION, при оборачивании в который действие выполнится в новой сессии (при этом по окончании выполнения этого действия сессия автоматически закроется). Например:
run() { |
run(Store s) { |
g = DATA LOCAL NESTED INTEGER (); |
- все изменения текущей сессии автоматически копируются в создаваемую сессию, то есть, грубо говоря, вложенная сессия < — текущая сессия
- при отмене изменений во вложенной сессии, она не очищается, а возвращается в состояние на момент создания: вложенная сессия < — текущая сессия
- при применении изменений во вложенной сессии, все ее изменения копируются обратно в текущую сессию: текущая сессия < — вложенная сессия.
Механизм вложенных сессий очень удобен, когда нужно организовать ввод большого количества информации (возможно, состоящий из нескольких этапов), но при этом надо либо применить все изменения в конце одновременно, либо не применить вообще ничего. Так, например, если нужно ввести какой-нибудь большой документ, в процессе ввода которого, в свою очередь, необходимо иметь возможность вводить товар, если его нет, но при этом чтобы:
- пользователь мог отменить ввод этого товара и продолжить ввод документа
- если пользователь отменит ввод всего документа, ввод этого товара также должен быть отменен
Применение изменений (APPLY), Отмена изменений (CANCEL)
Применение и отмена изменений – операции, для которых сессии собственно и создавались. В описании сессий они уже были упомянуты, и их семантика следует из их названия. Единственное, что стоит отметить:
- При применении и отмене изменений все изменения локальных первичных свойств удаляются. Иногда такое поведение нежелательно, поэтому, как и для создания сессий, для этих операторов поддерживается опция NESTED (с аналогичным поведением).
- При применении изменений есть возможность указать дополнительное действие, которое будет выполнено сразу после начала транзакции. Главное отличие выполнения этого дополнительного действия внутри транзакции от его выполнения сразу перед применением изменения заключается в том, что если применение по какой-либо причине будет отменено, то и изменения, сделанные в этом дополнительном действии, также будут отменены. Более того, если причиной отмены применения был конфликт записи (update conflict), а значит, применение будет автоматически выполнено еще раз, то в этом случае указанное дополнительное действие также будет выполнено еще раз. К примеру, такое поведение можно использовать для реализации долгосрочной пессимистичной блокировки:
// -------------------------- Object locks ---------------------------- // |
Следующий набор операторов – это операторы создания свойств, а не действий, но они по своей природе ближе к логике изменений, а не вычислений, поэтому описываются тут (а не в свойствах).
Операторы работы с изменениями (PREV, CHANGED, SET, DROPPED)
Для сессии поддерживается набор операторов работы с изменениями: получение предыдущего значения в сессии (PREV), определение изменилось ли значение свойства в сессии (CHANGED), изменилось ли оно с NULL на не NULL значение (SET) и т.п. Вообще эти операторы в основном используются в логике событий (о них чуть позже), но при необходимости их можно применять внутри действий, вызываемых откуда угодно, например:
f = DATA INTEGER (INTEGER); |
События
Действия отвечают на вопрос “Что делать?”, но не отвечают на вопрос “Когда это делать?”. Для определения моментов, когда нужно выполнять те или иные действия, в платформе существуют события.
Сразу оговорюсь, дальше речь пойдет о событиях предметной области, помимо них в логике представления также существуют события формы. Это два совершенно не связанных механизма, и на событиях формы мы подробнее остановимся в статье про логику представления. Но в дальнейшем события без уточнения их вида будем считать событиями предметной области.
События предметной области бывают двух типов:
- Синхронные – происходят непосредственно после изменения данных.
- Асинхронные – происходят в произвольные моменты времени по мере того, как сервер успевает выполнить все заданные обработки и / или по истечению некоторого периода времени.
В свою очередь, с точки зрения области видимости изменений, события можно разделить на:
- Локальные – происходят локально для каждой сессии изменений.
- Глобальные – происходят глобально для всей базы данных.
Таким образом, события могут быть синхронными локальными, синхронными глобальными, асинхронными локальными и асинхронными глобальными.
Преимущества синхронных событий:
- При необходимости в обработках можно выполнять отмену изменений, если, например, эти изменения не удовлетворяют необходимым условиям.
- Они гарантируют большую целостность, так как после окончания записи изменений пользователь гарантированно будет работать уже с обновленными данными.
Преимущества асинхронных событий:
- Можно сразу отпустить пользователя, а обработки выполнять «на фоне». Это улучшает эргономику системы, правда, возможно, только когда обновление данных не критично для дальнейшей работы пользователя (для глобальных событий, например, в течение ближайших 5-10 минут, пока сервер не успеет выполнить очередной цикл обработок).
- Обработки группируются для большого количества изменений, в том числе сделанных различными пользователями (в случае глобальных событий), и, соответственно, выполняются меньшее число раз, тем самым улучшая общую производительность системы.
Преимущества локальных событий:
- Пользователь видит результаты обработок событий сразу, а не только после того, как он сохранил их в общую базу.
Преимущества глобальных событий:
- Обеспечивают лучшую производительность и целостность, как за счет того, что обработки выполняются только после сохранения изменений в общую базу (то есть существенно реже), так и за счет использования многочисленных возможностей СУБД, связанных с работой с транзакциями.
Пока в платформе поддерживаются только синхронные глобальные и асинхронные локальные (как самые часто используемые, поддержка остальных видов событий также планируется в будущем), поэтому дальше будем говорить просто о глобальных и локальных событиях.
ON { // по умолчанию глобальное, то есть будет выполняться при каждом APPLY |
// отправить email, когда остаток в результате применения изменений сессии стал меньше нуля |
На самом деле, простые события – это не более, чем синтаксический сахар. Так, первое событие эквивалентно:
ON { |
Некоторым аналогом простых событий в SQL (а точнее его расширениях) являются триггеры. Впрочем, триггеры ограничены одной таблицей, работают целиком для записи, выполняются для каждой записи таблицы отдельно (то есть не умеют выполняться одним запросом) ну и много чего еще, и для реализации простых событий никак платформой не используются.
Важно отметить, что внутри обработки событий предметной области изменяется поведение некоторых операторов:
- Отмена изменений – отменяет применение изменений, а не очищает сессию (этот оператор можно использовать только внутри синхронных событий)
- Операторы работы с изменениями – возвращают значение на момент окончания обработки предыдущего события, а не текущее значение в базе. Впрочем, для глобальных событий эти значения совпадают, плюс при помощи специальной опции можно «вернуть» эти операторы в стандартный режим и возвращать текущее значение в базе.
Ограничения
Ограничения в платформе определяют, какие значения могут иметь первичные свойства, а какие нет. В общем случае, ограничение задается как свойство, значение которого всегда должно быть NULL:
// остаток не меньше 0 |
Так же как и для событий, для ограничений есть специальный подвид – простые ограничения (синтаксический сахар для наиболее распространенных случаев ограничений), но как показала практика, кроме ограничения, что заданное свойство должно быть задано (тут все более менее очевидно), простые ограничения используются очень редко, поэтому подробно останавливаться на них не будем.
Классы
Ну вот мы и подошли к классам. Обычно с них принято начинать, но, строго говоря, логически классы – это не более чем один из видов ограничений. Так, например:
f = DATA A (INTEGER); |
f = Object (INTEGER); |
Вообще, концепция классов в lsFusion не сильно отличается от аналогичной в ООП. Правда, в отличие от ООП в lsFusion нет инкапсуляции. Во всяком случае, пока. Но даже если инкапсуляция в lsFusion и появится, то только в виде синтаксического сахара, что-то вроде:
CLASS A { |
CLASS Animal; |
Полиморфизм
В текущей версии lsFusion полиморфизм – явный. Для его реализации сначала объявляется абстрактное свойство или действие для некоторого, возможно абстрактного, класса:
speed = ABSTRACT LONG (Transport); |
CLASS Breed; |
CLASS Thing; |
speed(Transport t) = CASE |
В будущем планируется, что кроме явного полиморфизма в языке будет поддерживаться и неявный полиморфизм, то есть:
speed(Horse h) = speed(breed(h)); |
Встроенные классы
Выше речь шла только о пользовательских классах, то есть классах, которые создают разработчики. Вместе с тем в платформе также поддерживаются так называемые встроенные (примитивные) классы: числа, строки, даты и так далее. Ничего сильно особенного по сравнению с другими языками в них нет, нужно, правда, учитывать, что в текущей реализации их нельзя смешивать ни друг с другом, ни с пользовательскими классами. То есть свойство не может возвращать не NULL значение одновременно и для некоторого числа, и некоторого объекта, то есть вот так делать нельзя:
f = DATA LONG (LONG); |
Статические объекты
Статические (или встроенные) объекты – объекты, которые создаются при старте сервера и которые нельзя удалить. Кроме того, к статическим объектам можно обращаться, как к константам, прямо в языке:
CLASS Direction 'Направление' { |
Аналогом статических объектов в современных языках программирования являются enum’ы, соответственно, обычно статические объекты используются ровно для тех же целей.
Агрегации
У механизма классов (как в lsFusion, так и в других языках) есть как минимум три ограничения:
- Принадлежность классу не может вычисляться (только задаваться явно при добавлении и изменении класса объекта).
- Класс определяется только для одного объекта (а не для набора объектов).
- Невозможно несколько раз наследовать один и тот же класс.
Для обхода этих ограничений в платформе есть механизм так называемых агрегаций.
Под агрегацией понимается создание уникального (агрегируемого) объекта, соответствующего каждому не NULL значению некоторого агрегируемого свойства. Для такого объекта предполагается наличие свойств, которые отображают этот объект на каждый из параметров агрегируемого свойства, и наличие свойства, которое, наоборот, отображает параметры агрегируемого свойства на этот объект.
Например:
// для каждого A создается объект класса B |
CLASS Shipment 'Поставка'; |
На этом с логикой предметной области закончим, это конечно далеко не все, но и так, возможно, слишком много для одной статьи. Впрочем, скоро будет еще минимум две статьи с описанием возможностей языка, одна – про логику представления, вторая – про физическую модель, и там, к сожалению или к счастью, будет тяжело обойтись фразами «тут все более-менее стандартно», так что, как говорится, не уходите далеко от своих экранов.
Заключение
Конечно, в противопоставлении lsFusion языкам общего назначения во вступлении есть определенная доля лукавства. Да, классы, агрегации, ограничения, события и остальные абстракции языка, по большому счету, действительно не принадлежат никакой конкретной предметной области, и в том или ином виде существуют, в том числе, в системном программировании (то есть, к примеру, при разработке условных ОС или СУБД). Но реализовать виртуальную машину, поддерживающую всю спецификацию lsFusion (даже без ACID), которая не будет настолько тяжеловесной, как современные SQL-сервера, будет очень тяжело. Как следствие, избавиться от ярлыка DSL lsFusion вряд ли удастся, а значит, и рассчитывать на благосклонность большинства системных программистов – основных потребителей языков общего назначения – вряд ли приходится. Строго говоря, и SQL большинство из них недолюбливают, слишком уж там много магии под капотом, а в lsFusion этой магии еще больше. Мы, конечно, по максимуму будем пытаться сгладить этот эффект – свободная лицензия, исходники на github (как самой платформы, так и всей ее инфраструктуры), максимальное использование существующих экосистем (IDE, отчетности, VCS, автоматических сборок), slack и telegram-каналы общения, наличие в общедоступных репозиториях (linux и maven, опять-таки с исходниками), ну и, в принципе, общая открытость во взаимодействии с разработчиками, но будем реалистами, если среднестатистический системный программист будет просто не любить lsFusion меньше, чем SQL, ABAP и 1С – это уже успех.
С другой стороны, понятно, что в ближайшее время основным рынком lsFusion, будет не системное, а прикладное программирование (уже упомянутая разработка ИС), и тут сейчас есть пять основных игроков: ERP-платформы, SQL-сервера с процедурными расширениями, ORM-фреймворки, RAD-фреймворки, и просто электронные таблицы. Первый, четвертый и пятый типы платформ имеют пользовательский интерфейс в комплекте, во втором и третьем для этого используются сторонние технологии.
У каждого из этих пяти типов платформ есть своя ниша, где они в основном обитают:
- SQL-сервера с процедурными расширениями – бизнес-приложения с относительно сложной логикой и большими объемами данных – это, как правило, ритейл и банки.
- ERP-платформы – остальные бизнес-приложения со сложной логикой – оптовая торговля, производство, финансы и т.п.
- ORM-фреймворки – веб-приложения (сервисы, порталы), ну и очень высоконагруженные приложения с относительно несложной логикой.
- RAD – узкоспециализированные низконагруженные бизнес-приложения с простой логикой, там где, как правило, сильно ограничен IT-бюджет.
- Электронные таблицы – используются там же, где и RAD, правда, из-за низкого порога вхождения их можно встретить везде, где только можно, начиная от крупных корпораций и заканчивая полной автоматизацией малого бизнеса чисто на Excel (да, такое тоже встречается, и даже не знаю, какие ощущения это больше вызывает – восторг или страх).
На мой сугубо субъективный взгляд, в глобальной перспективе lsFusion под силу полностью заменить ERP, RAD и SQL платформы, которые lsFusion превосходит по всем нефункциональным требованиям (а по многим из них превосходит на порядок). Правда, что касается SQL, тут речь скорее идет не о замене, а о надстройке, то есть так же, как, скажем, Fortran и C пришли на смену ассемблеру (на ассемблере по прежнему можно писать, но непонятно зачем). С ORM-фреймворками очевидно будет тяжело конкурировать в предельных гибкости и масштабируемости, а с электронными таблицами – с порогом вхождения в очень простых задачах и в работе с неструктурированными данными. Хотя все же, возможно, какую-то часть рынка удастся отвоевать и у них.
Ну и в среднесрочной перспективе фокус в основном будет сделан на SME (у которых ограничены человеческие ресурсы и бюджеты на ИТ, но при этом большие потребности в гибкости и эргономике используемых решений), а также на нестандартные задачи (где мало готовых решений и их кастомизация по объему превосходит сами эти решения). То есть занять ту нишу, которую сейчас занимает 1С в России, но только сделать это в мировом масштабе.
Это все, конечно, звучит чересчур амбициозно, но после того пути, который уже удалось пройти, чтобы просто заставить всю эту технологию работать (а на это ушло без малого 12 лет), такая задача уже не кажется настолько невыполнимой.
UPD: Вторую часть статьи можно найти тут.
