

Перевод статьи: Experimenters Rules of Thumb
Владельцы веб-порталов, от самых маленьких, до таких крупных, как Amazon, Facebook, Google, LinkedIn, Microsoft и Yahoo, пытаются улучшить свой сайты, оптимизируя различные метрики, начиная с количества повторных использований до проведенного у них времени и выручки. Нас привлекали к проведению тысячи экспериментов на Amazon, Booking.com, LinkedIn и Microsoft, и хотим поделиться семью эмпирическими правилами, которые мы вывели из этих экспериментов и их результатов. Мы верим, что эти правила широко применимы как при оптимизации веба, так и в ходе анализа за пределами контрольных экспериментов. Хотя бывают исключения.
Чтобы сделать эти правила более весомыми, мы приведём реальные примеры из нашей работы, причем большинство из них будут опубликованы впервые. Некоторые правила озвучивались и ранее (например, «Скорость имеет значение»), но мы дополнили их допущениями, которые можно использовать при проектировании экспериментов, и делимся дополнительными примерами, которые улучшили наше понимание того, где скорость особенно важна, а в каких областях веб-страниц она не критична.
Эта статья преследует две цели.
Первая: научить экспериментаторов правилам хорошего тона, которые помогут оптимизировать сайты.
Вторая: предоставить сообществу KDD новые темы для исследований применимости этих правил, их улучшения и наличия исключений.
Введение
Владельцы веб порталов от самых маленьких, до крупнейших гигантов пытаются улучшить свои сайты. Передовые компании используют для оценки изменений контрольные тесты (например, А/Б-тесты). Это делают Amazon [1], Ebay, Etsy [2], Facebook [3], Google [4], Groupon, Intuit [5], LinkedIn [6], Microsoft [7], Netflix [8], ShopDirect [9], Yahoo и Zynga [10].
Мы получили опыт оптимизации сайтов, работая со многими компаниями, в том числе Amazon, Booking.com, LinkedIn и Microsoft. К примеру, Bing и LinkedIn проводят сотни параллельных экспериментов в каждый момент времени [6; 11]. Благодаря разнообразию и многочисленности экспериментов, в которых мы принимали участие, сложились эмпирические правила, о которых мы здесь расскажем. Они подтверждены реальными проектами, но из любого правила бывают исключения (о них мы тоже расскажем). Например, «правило 72-ух» — хороший пример полезного эмпирического правила в финансовой сфере. Оно утверждает, что необходимо умножить годовой процент роста на 72, чтобы примерно определить, через сколько лет вы удвоите свои инвестиции. В обычных ситуациях правило очень полезное (когда процентная ставка колеблется между 4 и 12 %), но в других сферах оно не работает.
Так как эти правила были сформулированы по результатам контрольных экспериментов, то они хорошо применимы для оптимизации сайтов и простого анализа, даже если на сайтах не проводят контрольные эксперименты (хотя в этом случае не получится точно оценить влияние сделанных изменений).
Что вы найдёте в этой статье:
- Полезные правила для экспериментов над веб-сайтами. Они ещё развиваются, и нужно дополнительно оценить широту их применения и выяснить наличие новых исключений из этих правил. Важность использования контрольных экспериментов обсуждалось в статье «Online Controlled Experiments at Large Scale»[11]
- Усовершенствование предыдущих правил. Наблюдения вроде «скорость имеет значение» уже озвучивались другими авторами [12;13] и нами [14]. Но мы сделали некоторые допущения при проектировании эксперимента, и расскажем об исследованиях, которые демонстрируют, что в одних областях страницы скорость особенно критична, а в других — нет. Еще мы усовершенствовали старое правило «тысячи пользователей», отвечающее на вопрос, сколько нужно человек для проведения контрольного эксперимента.
- Реальные примеры контрольных экспериментов, публикуются впервые. В Amazon, Bing и LinkedIn контрольные эксперименты используются как часть процесса разработки [7;11]. Многие компании, которые до сих пор не используют контрольные эксперименты, могут извлечь большую пользу из дополнительных примеров работы с изменениями при введении новых парадигм разработки [7;15]. Компании, которые уже используют контрольные эксперименты, извлекут пользу из описанных инсайтов.
Контрольные эксперименты, данные и процесс извлечения знания из данных
Мы обсудим здесь контрольные online-эксперименты, в которых пользователи делятся на группы случайным образом (например, для показа различных вариантов сайта). При этом деление выполняется на постоянной основе, то есть каждый пользователь будет иметь одинаковый опыт на протяжении всего эксперимента (ему всегда будут показывать одну и ту же версию сайта). Взаимодействие пользователя с сайтом (клики, просмотры страницы и т.п.) фиксируется, и на его основе вычисляются ключевые метрики (CTR, количество сессий на пользователя, выручка с пользователя). Проводятся статистические тесты для анализа посчитанных метрик. И если разница между метриками контрольной группы (которая видела старую версию сайта) и экспериментальной (которая видела новую версию) группы статистически значима, то мы, с высокой вероятностью, можем говорить и том, что сделанные изменения повлияют на метрики наблюдаемым в эксперименте образом. Подробнее рассказывается в «Controlled experiments on the web: survey and practical guide» [16].
Мы участвовали в проведении множества экспериментов, чьи результаты были некорректными, и потратили много времени и усилий, чтобы понять причины и найти способы исправления. Многие подводные камни описаны в статьях [17] и [18]. Мы хотим осветить некоторые вопросы о данных, которые используются в проведение контрольных онлайн экспериментах, и о процессе получения знаний из этих данных:
- Источник данных — это реальные сайты, о которых мы говорили выше. Здесь не будет никаких искусственно сгенерированной информации. Все примеры основаны на реальном пользовательском взаимодействии, а метрики вычислены после удаления ботов [16].
- Группы пользователей в примерах взяты случайно из равномерного распределения целевой аудитории (т.е. пользователей, которые, например, должны кликнуть по ссылке, чтобы увидеть изучаемые изменения) [16]. Способ идентификации пользователя зависит от сайта: если пользователь не залогинен, используются Cookies, а если он вошел в систему, то используется его логин.
- Размеры групп пользователей, после очистки от ботов, колеблются от сотен тысяч до миллионов (точные значения указаны в примерах). В большинстве экспериментов, это необходимо для того, чтобы незначительные отличия в метриках имели высокую статистическую значимость.
- Отмеченные результаты были статистически значимыми при p-value<0.05, а обычно и того меньше. Удивительные результаты (в правиле 1) были воспроизведены как минимум еще раз, так, что совокупное p-value, основанное на тесте совокупной вероятности Фишера, имело значение гораздо меньше необходимого.
- Каждый эксперимент — это наш персональный опыт, проверенный хотя бы одним из авторов на наличие стандартных подводных камней. Каждый эксперимент проводился хотя бы неделю. Доли аудитории, которым демонстрировались варианты сайта, были стабильны на протяжении всего периода эксперимента (чтобы избежать эффекта парадокса Симпсона) и соотношения между аудиторией, которые мы наблюдали в процессе эксперимента, совпадали с соотношениями, которые мы задавали при запуске эксперимента [17].
Эмпирические правила для проведения экспериментов
Первые три правила относятся к влиянию изменений на ключевые метрики:
- маленькие изменения могут иметь большое влияние;
- изменения редко имеют большое позитивное влияние;
- ваши попытки повторить звездные успехи, заявленные другими, скорее всего, будут не настолько успешными.
Последующие 4 правила не зависят друг от друга, но каждое из них очень полезно.
Правило №1: маленькие изменения могут иметь БОЛЬШОЕ влияние на ключевые метрики
Любой, кто сталкивался с жизнью сайтов, знает, что любое маленькое изменение может иметь большое негативное влияние на ключевые метрики. Маленькая ошибка в JavaScript’е может сделать оплату невозможной, а маленькие баги, разрушающие стек, могут вызывать падение сервера. Но мы сосредоточимся на позитивных изменениях ключевых метрик. Хорошие новости состоят в том, что есть много примеров, когда маленькое изменение привело к улучшению ключевой метрики. Bryan Eisenberg написал, что удаление поля ввода купона в форме покупки увеличило конверсию на 1000 % на сайте Doctor Footcare [20]. Jared Spool писал, что удаление требования зарегистрироваться при покупке принесло большому ритейлеру $300 000 000 в год [21].
Тем не менее, мы не видели столь значимых изменений в процессе лично проводимых экспериментов. Но мы видели значительные улучшения от малых изменений с удивительно высокой окупаемостью инвестиций (высокое отношение прибыли к стоимости вложенных усилий).
Также хотим отметить, что мы обсуждаем стабилизировавшийся эффект, не «вспышку на Солнце» или фичу с особым новостным/вирусным эффектом. Пример чего-то такого, чего мы не ищем, был описан в книге «Yes!:50 Scientifically proven ways to be Persuasive» [22]. Collen Szot, автор телевизионной передачи, которая побила 20-летний рекорд продаж на телеканале «магазин на диване», заменила три слова в стандартной информационной бегущей строке, что привело к огромному скачку количества покупок. Коллен вместо привычной и знакомой всем фразы «Операторы ждут, пожалуйста, позвоните сейчас» вывела «если операторы будут заняты, пожалуйста, перезвоните снова». Авторы объясняют это следующим социологическим доказательством: зрители думают, что если линия занята, то такие же люди как они, смотрящие информационный канал тоже звонят.
Если уловками вроде той, что упомянута выше, пользуются регулярно, то их эффект нивелируется, потому что пользователи привыкают. В контрольных экспериментах в подобных случаях эффект быстро сходит на нет. Поэтому рекомендуем проводить эксперимент как минимум две недели и следить за динамикой. Хотя на практике подобные вещи встречаются редко [11; 18]. Ситуации, в которых мы наблюдали положительный эффект влияния подобных изменений, были связаны с рекомендательными системами, когда изменение само по себе даёт кратковременный эффект или когда для обработки используются конечные ресурсы.
Например, когда в LinkedIn изменили алгоритм фичи «люди, которых вы можете знать», это породило только одноразовый всплеск метрик количества кликов. Более того, даже если бы алгоритм работал значительно лучше, то каждый пользователь знает конечное количество людей, и после того, как он связался с основными своими знакомыми, эффект любого нового алгоритма упадет.
Пример: Открытие ссылок в новой вкладке. Серия из трех экспериментов
В августе 2008 MSN UK проводила эксперимент на более чем 900 000 пользователей, в котором ссылка на HotMail открывалась в новой вкладке (или новом окне у старых браузеров). Мы раньше сообщали [7], что это минимальное изменение (одна строка кода) привела к увеличению вовлеченности MSN-пользователей. Вовлеченность, измеренная в количестве кликов на пользователя на домашней странице, выросла на 8,9 % среди тех пользователей, кто кликал на HotMail.
В июне 2010 мы воспроизвели эксперимент на аудитории в 2,7 млн пользователей MSN в США, и результаты были аналогичными. На самом деле это тоже пример фичи с эффектом новизны. В первый день её выкатки на всех пользователей 20 % отзывов имели негативный характер. На второй неделе доля недовольных упала до 4 %, а на протяжении третьей и четвертой недели — до 2 %. Улучшение в ключевой метрике было стабильным на протяжении всего этого времени.
В апреле 2011 MSN в США проводила очень большой эксперимент на более чем 12 млн пользователей, которым страницу с результатами поиска открывали в новой вкладке. Вовлеченность, измеренная в кликах на пользователя, выросла на колоссальные 5 %. Это была одна из лучших фич, относящихся к вовлеченности пользователя, которую когда либо реализовывала MSN, и это было тривиальное изменение в коде.
Все основные поисковые системы экспериментируют с открыванием ссылок в новых вкладках/окнах, но полученные результаты для «страницы результатов поиска» не столь впечатляющие.
Пример: Цвет шрифта
В 2013 году Bing проводил ряд экспериментов с цветами шрифтов. Победивший вариант показан на рисунке 1 справа. Вот как были изменены три цвета:
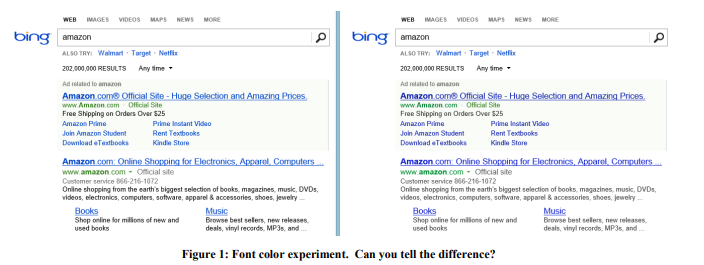
Стоимость таких изменений? Копеечная: просто заменить несколько цветов в CSS-файле. А результат эксперимента показал, что пользователи достигают своих целей (строгое определение успеха — коммерческая тайна) быстрее, а монетизация от этой доработки повысилась более чем на $10 млн в год. Мы скептически отнеслись к таким удивительным результатам, поэтому воспроизвели этот эксперимент на гораздо большей выборке в 32 миллиона пользователей, и результаты подтвердились.

Пример: Правильное предложение в правильное время
В далеком 2004 году стартовая страница Amazon содержала два слота, содержимое которых тестировалось автоматически, чтобы контент, который сильнее улучшает целевую метрику, отображался чаще. Предложение оформить кредитную карту Amazon попадало в топовый слот, что было удивительно, т.к. это предложение имело очень маленькое количество кликов на показ. Но дело в том, что данное приложение было очень прибыльное, поэтому, несмотря на маленький CTR, ожидаемая ценность была очень велика. Вот только удачно ли было выбрано место для такого объявления? Нет! В результате предложение вместе с простым примером выгоды переместили в корзину покупок, которую пользователь видит после добавления товара. Тем самым подчеркивалась выгодность этого предложения на примере каждого товара. Если пользователь добавил в корзину товар, это явное намерение совершить покупку и самое время для такого предложения.

Контрольный эксперимент показал, что такое простое изменение принесло десятки миллионов долларов в год.
Пример: Антивирус
Реклама — прибыльный бизнес, и «бесплатный» софт, установленный пользователями, часто содержит вредоносную часть, которая засоряет страницы рекламой. Например, на рисунке 2 показано, как выглядит страница результатов Bing для пользователя с вредоносной программой, которая добавила на страницу множество рекламы (выделено красным).
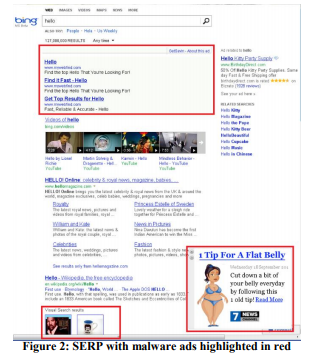
Пользователи обычно даже не замечают, что так много рекламы показывает вовсе не тот сайт, который они посещают, a вредоносный код, который они случайно установили. Эксперимент был сложен в реализации, но относительно прост идеологически: изменение базовых процедур, которые модифицируют DOM, и ограничение приложений, которые способны модифицировать страницу. Эксперимент проводили над 3,8 млн пользователей, на чьих компьютерах был сторонний код, который редактировал DOM. У тестовой группы эти изменения были заблокированы. Результаты показали улучшение всех ключевых метрик, включая такую путеводную из них, как количество сессий на пользователя, т.е. люди приходили на сайт чаще. Вдобавок к этому, пользователи успешнее и быстрее выполняли свои задачи, и годовая выручка увеличилась на несколько миллионов долларов. Скорость загрузки страницы, которую мы обсудим в правиле №4, уменьшилась на сотни миллисекунд для страниц, затронутых экспериментом.
Два других маленьких изменения в Bing, которые строго конфиденциальны, заняли дни разработки, и каждое привело к увеличению прибыли от рекламы почти на 100 миллионов долларов в год. В квартальном отчёте Microsoft в октябре 2013 отмечено: «Рекламная выручка от поиска выросла на 47 % благодаря увеличению прибыли от каждого поиска и каждой страницы». Те два изменения внесли значительный вклад в упомянутый рост прибыли.
После этих примеров вы можете подумать, что организации должны сосредоточиться на множестве маленьких изменений. Но ниже вы увидите, что это совсем не так. Да, случаются прорывы на основе маленьких изменений, но они очень редки и неожиданны: в Bing, наверное, один из 500 экспериментов достигает такого высокого ROI и воспроизводимого положительного результата. Мы не утверждаем, что эти результаты будут воспроизводимы на других доменах, лишь хотим донести мысль: проведение простых экспериментов стоит усилий и в итоге может привести к прорыву.
Опасность, возникающая из-за сосредоточенности на маленьких изменениях — это инкрементализм: уважающая себя организация должна иметь набор изменений с потенциально высоким ROI, но в то же время в планах должно быть и несколько крупных изменений, чтобы сорвать большой куш [23].
Правило №2: Изменения редко имеют большое положительное влияние на ключевые метрики
Как говорил Аль Пачино в фильме «Каждое воскресенье», победа дается сантиметр за сантиметром. На сайтах вроде Bing ежегодно крутятся сотни и тысячи экспериментов. Большинство проваливаются, а те, что завершились успехом, влияют на ключевую метрику на 0,1 %-1,0 %, добавляя свою каплю в общее влияние. Маленькие изменения с большим эффектом, описанные в предыдущем правиле, случаются, но они редки.
Важно отметить две вещи:
- Ключевые метрики — это не что-то специфическое, относящееся к отдельной фиче, что можно легко улучшить, а это метрика, значимая для всей организации: например, количество сессий на пользователя [18] или время достижения пользовательской цели [24].
Разрабатывая фичу, очень легко значительно улучшить количество кликов на эту фичу (или другую метрику фичи), просто подсветив её или сделав крупнее. А вот увеличить CTR всей страницы или всего пользовательского опыта — вот где сложная задача. Большинство фич лишь гоняют клики по странице, перераспределяя их между разными областями. - Метрики должны быть разделены на маленькие сегменты, так их гораздо проще оптимизировать. Например, команда может легко улучшить метрики для запросов о погоде в Bing или покупки TV-программ на Amazon? добавив хороший инструмент сравнения. Тем не менее, 10-процентное улучшение ключевой метрики растворится в метриках всего продукта из-за размеров сегмента. Например, 10-процентное улучшение на 1--процентном сегменте повлияет на весь проект примерно на 0,1 % (примерно, потому что если метрики сегмента отличаются от средних, то и влияние тоже может отличаться).
Важность этого правила велика потому, что во время экспериментов случаются ложноположительные ошибки. У них два вида причин:
- Первые вызваны статистикой. Если мы проводим тысячу экспериментов в год, то вероятность ложноположительной ошибки 0,05 приводит к тому, что для фиксированной метрики мы сотни раз получим ложноположительный результат. А если мы используем несколько не коррелирующих между собой метрик, то этот результат только усиливается. Даже такие большие сайты как Bing не имеют достаточно трафика, чтобы повысить чувствительность и делать выводы с меньшим p-value для таких метрик, как количество сессий на пользователя.
- Вторые вызваны плохой архитектурой, аномалиями в данных, багам или ошибками инструмента.
Результаты на границе статистической значимости считаются предварительными и должны быть воспроизведены для подтверждения результата [11]. Это можно формализовать с помощью Байесовского вывода [25;26]. Если вероятность истинноположительного результата мала, то большинство экспериментов потерпят неудачу в улучшении ключевой метрики, а вероятность положительного влияния на ключевую метрику при p-value близком к 0,05 по-прежнему будет мала. Пусть






Подставляя

Забавным следствием из этого правила является тот факт, что держаться кого-то гораздо проще, чем развиваться в одиночку. Решения, принятые в компании, которая ориентируется на статистическую значимость, с большей вероятностью и у вас будут иметь положительный эффект. Например, если у нас уровень успешности экспериментов равен 10-20 %, то если мы возьмем тесты тех фичей, которые были успешными и выкатились на бой в других поисковых системах, то наш уровень успешности будет выше. Верно и обратное: другие поисковые системы тоже должны тестировать и вводить в бой вещи, которые реализовал Bing.
С опытом мы научились не доверять результатам, которые выглядят слишком хорошо, чтобы быть правдой. Люди по-разному реагируют на разные ситуации. Они подозревают неладное и изучают негативные результаты от экспериментов с их великой новой фичей, задают вопросы и погружаются глубже в поиск причин такого результата. Но если результат просто положительный, то подозрительность отступает и люди начинают праздновать, а не изучать глубже и не искать аномалии.
Когда результаты исключительно выдающиеся, мы привыкли следовать закону Twyman’а [27]: Все то выглядит интересным или отличающимся — обычно ложно.
Закон Twyman’а можно объяснить с помощью Байесовского вывода. По нашему опыту мы знали, что прорыв — редкое явление. Например, несколько экспериментов значимо улучшили нашу путеводную метрику, количество сессий на пользователя. Представим, что распределение, которое мы встречаем в экспериментах, нормальное с центром в точке 0 и со стандартным отклонением 0,25 %. Если эксперимент показал +2 % к значению ключевой метрики, тогда мы призываем закон Twyman’а и говорим, что это очень интересный результат, который находится на расстоянии 8 стандартных отклонений от среднего и имеет вероятность 10-15, исключая прочие факторы. Даже при наличии статистической значимости, предварительное ожидание настолько сильное, что мы отложим празднование успеха и углубимся в поиски причины ложноположительной ошибки второго типа. Закон Twyman’а часто применяется к доказательству того, что
Р=NP. Сегодня ни один редактор сайта не обрадуется, если ему придет такое доказательство. Скорее всего, он сразу ответит шаблонным ответом: «в вашем доказательстве, что P = NP, допущена ошибка на странице Х».Пример: Суррогатная метрика Office Online
Cook и его команда [17] рассказали об интересном эксперименте, который они провели c Microsoft Office Online. Команда тестировал новый дизайн страницы в котором сильно выделялась кнопка, призывающая заплатить за продукт. Ключевая метрика, которую хотела измерить команда: количество покупок на пользователя. Но отслеживание реальных покупок требовало модифицирования системы биллинга, а в то время это было сложно сделать. Тогда команда решила использовать метрику «клики, приводящие к покупке» и применять формулу
(количество кликов) * конверсию = количество покупок, где берётся конверсия из кликов в покупку. К их удивлению, в эксперименте количество кликов снизилось на 64 %. Такие шокирующие результаты заставили глубже проанализировать данные, и оказалось, что предположение о стабильной конверсии из клика в покупку является ложным. Экспериментальная страница, которая показывала стоимость продукта, привлекала меньше кликов, но те пользователи, которые по ней кликали, были лучше квалифицированы и имели гораздо большую конверсию из клика в покупку.
Пример: Больше кликов с медленной страницы
На страницу результатов поиска Bing добавили JavaScript-код. Этот скрипт обычно замедлял работу страницы, поэтому все ожидали увидеть небольшое негативное влияние на основные метрики вовлеченности, такие как количество кликов на пользователя. Но результаты показали обратное, кликов стало больше! [18] Несмотря на положительную динамику, мы последовали закону Twyman’а и разгадали загадку. Клик-трекеры основаны на веб-маяках, и некоторые браузеры не совершали вызов, если пользователь покидал страницу. [28] Таким образом, JavaScript повлиял на достоверность подсчета кликов.
Пример: Bing Edge
На протяжении нескольких месяцев в 2013-м Bing менял свою Content Delivery Network с Akamai на свою собственную Bing Edge. Переключение трафика на Bing Edge было совмещено со многими другими улучшениями. Несколько команд рапортовало, что они улучшили ключевые метрики: CTR главной страницы Bing повысился, фичи стали использоваться чаще, а отток начал снижаться. И так вышло, что все эти улучшения были связаны с чистотой подсчета кликов: Bing Edge улучшило не только скорость страницы, но и доставляемость кликов. Чтобы оценить эффект, мы запустили эксперимент в котором маячковый подход к отслеживанию кликов заменили на подход с перезагрузкой страницы. Этот прием используется в рекламе и ведет к незначительной потере кликов, замедляя действие каждого клика. Результаты показали, что доля потерянных кликов упала более чем на 60 %! И большинство заявленных в тот период достижений оказались результатом улучшения доставки клика.
Пример: MSN Поиск в Bing
Автодополнение — выпадающий список, в котором предлагаются варианты завершения запроса, пока человек его набирает. MSN планировала улучшить эту фичу с помощью нового и улучшенного алгоритма (команды разработки фич всегда готовы объяснить, почему их новый алгоритм априори лучше старого, но часто расстраиваются, когда видят результаты экспериментов). Эксперимент имел большой успех, количество поисковых запросов, которые приходили в Bing с MSN, значительно выросло. Следуя нашим правилам, мы начали разбираться и выяснили, что когда пользователь кликал в подсказку, новый код делал два поисковых запроса (один из которых сразу закрывался браузером, как только появлялась поисковая выдача).
Так что объяснение многих положительных результатов может быть не столь захватывающим. А наша задача — найти реальное влияние на пользователя, и правило Twyman’а очень помогло в этом и в понимании многих результатов экспериментов.
Правило №3. Ваша выгода будет варьироваться
Существует много задокументированных примеров успешных контрольных экспериментов. Например, "Which Test Won?" содержит сотни примеров A/B-тестов, и список пополняется каждую неделю.
Хотя это отличный генератор идей, у этих примеров есть несколько проблем:
- Качество варьируется. В этих исследованиях кто-то из какой-то компании рассказывает о результате A/B-теста. Была ли там экспертная оценка? Правильно ли он проводился? Были там выбросы? Было p-value достаточно маленьким (мы видели опубликованные A/B-тесты с p-value больше 0,05, что обычно считается статистически незначимым)? Были там подводные камни, о которых мы рассказывали раньше, и которые авторы теста не проверили должным образом?
- То, что работает в одном домене, может не работать в другом. Например, Neil Patel [29] рекомендует использовать слово «free» в рекламе, предлагающей 30-дневную пробную версию, вместо «30-ти дневная гарантия возврата денег». Это может работать с одним продуктом и одной аудиторией, но мы подозреваем, что результат будет сильно зависеть и от продукта, и от аудитории. Joshua Porter [30] заявляет, что «Красный лучше зеленого» для кнопок с призывом к присоединиться «Get Started Now». Но так как мы не видели много сайтов с красной кнопкой призыва к действию, то, видимо, данный результат не столь хорошо воспроизводится.
- Эффект новизны и первого раза. Мы добиваемся стабильности в наших экспериментах, а многие эксперименты во многих примерах не проводились достаточно долго, чтобы проверить наличие таких эффектов.
- Неправильная интерпретация результатов. Какая-то скрытая причина или специфический фактор может быть не распознан или понят неправильно. Приведем два примера. Один из них — первый задокументированный контрольный эксперимент.
Пример 1. Цинга — это заболевание, обусловленное дефицитом витамина C. Она убила более 100 000 человек в 16-18 веках, большинство из них — моряки, которые уходили в дальние плавания и оставались в море дольше, чем могли бы сохраниться фрукты и овощи. В 1747 году доктор James Lind заметил, что цингой меньше страдают на кораблях в Средиземноморье. Он начал давать некоторым морякам лимоны и апельсины, другим оставив обычное питание. Эксперимент оказался очень успешным, но доктор не понял причины. В Королевском Морском Госпитале в Великобритании он лечил пациентов с цингой концентрированным лимонным соком, который он называл «rob». Врач концентрировал его с помощью нагревания, что уничтожало витамин C. Lind потерял веру и стал часто прибегать к кровопусканию. В 1793 году были проведены настоящие испытания. и лимонный сок стал частью дневного рациона моряков. Цинга быстро исчезла, а британских моряков до сих пор называют лимонниками.
Пример 2. Marissa Mayer рассказала об эксперименте, в ходе которого Google увеличил количество результатов на странице поиска с 10 до 30. Трафик и прибыль от пользователей, которые искали в Google, упали на 20 %. И как же она это объяснила? Мол, страница требовала на полсекунды больше, чтобы сгенерироваться. Конечно, производительность — важный фактор, но мы подозреваем, что это повлияло только на малую долю потерь. Вот наше видение причин:
- В Bing проводились изолированные замедляющие эксперименты [11], в ходе которых менялась только производительность. Задержка реакции сервера в 250 миллисекунд повлияла на выручку примерно на 1,5 % и на CTR на 0,25 %. Это большое влияние, и можно предположить, что 500 миллисекунд повлияют на выручку и CTR на 3 % и 0,5 % соответственно, но никак не на 20 % (предположим, что здесь применима линейная аппроксимация). Старые тесты в Bing [32] показывали схожее влияние на клики и меньшее влияние на выручку при задержке в 2 секунды.
- Jake Brutlag из Google писал в своем блоге об эксперименте [12], показывающем, что замедление выдачи результатов поиска со 100 миллисекунд до 400 имеет значительное влияние на удельное количество поисков и колеблется между 0,2 % и 0,6 %, что очень хорошо сочетается с нашими экспериментами, но очень далеко от результатов Marissa Mayer.
- В BIng провели эксперимент с показом 20 результатов поиска вместо 10. Потеря прибыли полностью нивелировала добавление дополнительной рекламы (которая сделала страницу еще чуть-чуть медленнее). Мы верим, что соотношение рекламы и алгоритмов поиска гораздо важнее, чем производительность.
Мы скептично относимся ко многим замечательным результатам A/B-тестов, опубликованных в разных источниках. Когда проверяете результаты экспериментов, спрашивайте самих себя, какой уровень доверия у вас к ним? И запомните, даже если идея работала на одном сайте, то совершенно не обязательно, что она будет работать на другом. Самое лучше, что мы можем сделать, это рассказать о воспроизведении экспериментов и об их успехе или провале. Это принесет больше всего пользы науке.
Правило №4: Скорость значит многое
Веб-разработчики, которые проверяют свои фичи с помощью контрольных экспериментов, быстро поняли, что производительность или скорость сайта — критичные параметры [13;14;33]. Даже небольшая задержка при работе сайта может влиять на ключевые метрики тестовой группы.
Лучший способ оценить влияния производительности — произвести изолированный эксперимент с замедлением, т.е. просто с добавить задержку. На рисунке 3 показан стандартный график зависимости между производительностью и проверяемой метрикой (CTR, удельные успешность и выручка). Обычно чем быстрее сайт, тем лучше (выше на этом графике). Замедляя работу у тестовой группы по отношению к контрольной группе, вы можете измерить влияние производительности на интересующую вас метрику. Важно отметить:
- Влияние замедления на тестовую группу замеряется здесь и сейчас (пунктирная линия на графике) и зависит от сайта и аудитории. Если изменится сайт или аудитория, то снижение производительности может по-другому влиять на ключевую метрику.
- Эксперимент показывает влияние замедления на ключевую метрику. Это может быть очень полезно, когда вы пытаетесь измерить эффект от новой фичи, первая реализация которой не эффективна. Допустим, что она улучшает метрику M на X %, и в то же время замедляет сайт на T %. С помощью эксперимента с замедлением мы можем оценить влияние замедление на метрику М, подкорректировать влияние фичи и получить прогнозируемый эффект X’ % (логично предположить, что эти эффекты обладают свойством аддитивности). И таким образом сможем ответить на вопрос: «Как оно повлияет на ключевую метрику, если будет реализовано эффективно?».
- Мы можем предположить, как повлияет на ключевую метрику тот факт, что сайт начнет работать быстрее и поможет вычислить ROI усилий на оптимизацию. Воспользовавшись линейной аппроксимацией (первый член ряда Тейлора), мы можем предположить, что влияние на метрику одинаково в обоих направлениях. Мы предполагаем, что вертикальная дельта одинакова в обоих направлениях и просто отличается по знаку. Поэтому экспериментируя с замедлением на различные значения мы можем примерно представить, как будет влиять ускорение на эти же значения. Мы проводили такие тесты в Bing и наша теория полностью подтвердилась.
Насколько важна производительность? Критически важна. В Amazon замедление работы на 100 миллисекунд приводит к падению продаж на 1 %, как говорил Greg Linded [34 p.10]. А докладчики из Bing и Google [32] свидетельствуют о значительном влиянии производительности на ключевые метрики.
Пример: Эксперимент по замедлению сервера
Мы проводили в Bing двухнедельный эксперимент по замедлению работы сервиса на 100 миллисекунд у 10 % пользователей, на 250 миллисекунд у других 10 % пользователей. Оказалось, что каждые 100 миллисекунд ускорения работы сервиса увеличивали выручку на 0,6 %. Отсюда даже появилась фраза, которая хорошо отражает суть нашей организации: Инженер, который улучшит производительность сервера на 10 миллисекунд (1/30 от скорости моргания нашего глаза) заработает для компании более чем годовой свой заработок. Каждая миллисекунда имеет значение.
В описанном эксперименте мы замедляли время ответа сервера, потом замедляли время работы всех элементов на странице. Но у страницы есть более важные части, а есть менее важные. Например, пользователи не могут знать, что элементы за границей видимости экрана еще не подгрузились. Но есть ли отображаемые сразу элементы, которые можно замедлить без ущерба для пользователя? Как вы увидите ниже, такие элементы есть.
Пример: производительность правой панели не так критична
В Bing некоторые элементы, называемые снапшотами, находятся на правой панели и загружаются поздно (после события window.onload). Недавно мы провели эксперимент: элементы правой панели замедлили на 250 миллисекунд. Если это и повлияло на ключевые метрики, то столь незначительно, что мы ничего не заметили. А в эксперименте участвовало почти 20 миллионов пользователей.
Время загрузки страницы (PLT) часто вычисляется с помощью события window.onload, как признака завершения полезной активности браузера. Но сегодня такая метрика имеет серьезный изъян при работе с современными браузерами. Как показал Steve Souders [32], верхняя часть страницы Amazon рендерится за 2 секунды, тогда как windows.onload срабатывает через 5,2 секунды. В Schurman [32] заявляли, что умеют рендерить страницу динамически, поэтому им важно показать шапку очень быстро. Бывает верно и обратное: в Gmail windows.onload срабатывает через 3,3 секунды, тогда как на экране в этот момент появилась только полоса загрузки, а весь контент будет показан через 4,8 секунды.
Существуют метрики, связанные со временем, например: время до первого результата (скажем, время до первого твита в Twitter, первый результат поиска на странице с результатами). Но термин «Perceived performance» всегда используется для описания такой скорости работы страницы, чтобы пользователь воспринимал её достаточно полноценной. Концепцию «Perceived performance» проще описать интуитивно, чем строго сформулировать, поэтому ни у одно из браузеров нет в планах реализации события
perception.ready(). Для решения этой задачи используется много предположений и допущений, например:- Время показа верхней части страницы (AFT) [37]. Измеряется как момент, когда будут отображены все верхние пикселы страницы. Реализация основана на эвристиках, которые особенно сложны, когда имеем дело с видео, гифками, прокручивающимися галереями и прочим динамическим контентом, который изменяет верхнюю часть страницы. Можно выставлять пороги на «процент нарисованных пикселей», чтобы избежать влияния мелких и незначительных элементов, которые могут увеличить измеряемую метрику.
- Индекс скорости [38] — некоторое обобщение AFT, которое усредняет время, в течение которого видимые элементы страницы появляются на экране. Скорость не страдает от мелких элементов, которые появляются поздно, но на неё всё ещё влияет динамический контент, который меняет верхнюю часть страницы.
- Время фаз страниц и время готовности пользователя [39]. Время фаз страниц — время, требуемое на каждую отдельную фазу рендеринга страницы. Тоже является мерой того, как быстро меняются пиксели на странице. Время готовности пользователя — время, необходимое для отображения главных для пользователя элементов.
Новый W3C-интерфейс работы со временем, предложенный в новом стандарте HTML, предоставляет доступ к более детальному разделению событий на странице и, скорее всего, позволит лучше понять проблемы с производительностью. Все эксперименты, о которых мы говорили выше, проводились для десктопной версии сайтов, но из них можно многое извлечь и для мобильных интерфейсов.
В Bing мы используем множество метрик производительности для диагностики состояния сервиса, но наша ключевая метрика «Время до выполнения своей задачи» (TTS) [24] находится за рамками обсуждения проблем измерения метрик. Цель поискового движка — чтобы пользователь решил свою задачу как можно быстрее. Для кликабельных элементов считается успехом, если пользователь как минимум 30 секунд не возвращался обратно после клика на элемент. Метрика времени необходимого для успеха пользователя — она коррелирует с «Perceived performance». Если страница отображается медленно, то пользователи медленнее кликают и медленнее достигнут желаемого; если страница начинает работать быстрее, то быстрее отработают все скрипты, пользователь раньше сможет интерпретировать страницу и быстрее добьётся желаемого. Кроме того, этой относительно простой метрике не нужны эвристики, которые обычно появляются, когда разговор заходит об измерениях времени. Эта метрика очень устойчива к изменениям, но при этом достаточно чувствительна. Её недостаток в том, что она подходит для тех случаев, когда необходим клик, когда бывают запросы, при которых пользователю для достижения цели кликать никуда не надо — в подобных ситуациях эта метрика не применима.
Правило №5: уменьшить отток со страницы — тяжело, а вот перекидывать клики из одной области в другую — просто
Ключевая метрика, которая измеряется в Bing во время контрольных экспериментов — уровень оттока, то есть какой процент пользователей покинул страницу, ни кликнув ни по одной ссылке. Увеличение пользовательского вовлечения в продукт, уменьшение оттока — это очень положительные результаты, но это те метрики, которые очень тяжело изменить. Большинство экспериментов показывают, что можно значительно перемещать клики из одной области в другую, но отток меняется редко или на ничтожно маленькие значения. Ниже мы опишем несколько экспериментов, в ходе которых были сделаны большие изменения, но отток статистически значимо не изменился.
Пример: Связанные поиски в правой колонке
В Bing в правой колонке показываются связанные поисковые запросы. например, если вы искали «data mining», Bing покажет справа «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» и т.д. Это может помочь пользователям изменить свой запрос и успешнее находить нужную информацию. В эксперименте связанные поисковые запросы убрали из правой колонки для 10 миллионов пользователей. В результате пользовательские клики переехали в другую область, но статистически значимого изменения оттока не произошло (p-value 0,64).
Пример: Связанные поиски под верхней рекламой
Bing показывается связанные поиски в строках, которые могут плавать в поисковой выдаче, если поисковик считает, что они более релевантны, чем верхние результат работы алгоритма. В эксперименте мы зафиксировали связанные поиски прямо под верхней рекламой. В результате этого эксперимента клики на связанные поисковые запросы упали на 17 %, но статистически значимого изменения уровня оттока не произошло (p-value 0,71).
Пример: Обрезание страницы поисковой выдачи
Bing задает размер страницы с поисковой выдачей динамически, а не всегда показывает классические 10 голубых ссылок. Это изменение стало возможным благодаря стабильности уровня оттока, который показали два эксперимента:
- Когда возникает блок со вложенными ссылками, например, для запроса «ebay», то CTR на этот верхний блок равен 75 %. Показывать 10 результатов для такого запроса бессмысленно. Поэтому провели эксперимент: для 8 миллионов пользователей, по чьим запросам была выдача с вложенным блоком, показали под ним всего 4 результата работы поискового алгоритма. Статистически значимого изменения уровня оттока не произошло (p-value 0,92), но страницы стали грузиться значительно быстрее и эта фича была реализована в production.
- Когда пользователь уходит из поисковой выдачи, а потом возвращается с помощью кнопки «назад» в браузере или повторяет запрос, Bing в этом случае выдаёт больше строк с результатами поиска (14 результатов). Эксперимент, который затронул 3 миллиона «целевых» пользователей, показал статистически значимое изменение метрик: на 1,8 % упала выручка с пользователей, на 30 миллисекунд замедлилась загрузка страницы, на 18 % упала пагинация (листание результатов поиска), но статистически значимого изменения уровня оттока не произошло (p-value 0,93). Это изменение не было вынесено на бой.
Пример: цвет фона рекламной ссылки
Все основные поисковые движки экспериментируют с фоном для рекламы. В недавнем эксперименте с 10 миллионами пользователей тестовый цвет привел к тому, что выручка упала на 12 % (годовые потери порядка $150 млн, если бы это изменение было выкачено на бой). Клики пользователей переехали с рекламы в другие места сайта, но статистически значимого изменения уровня оттока не произошло (p-value 0,83)
Мы видели эксперименты, когда уровень оттока улучшался, значительно повышалась релевантность поисковой выдачи. Но это необычные эксперименты, а изменение оказалось значительно меньше, чем можно было бы ожидать.
Это правило очень важно потому, что мы наблюдали много экспериментов (в Microsoft, Amazon и по рассказам других.), в которых на страницу добавляли модуль или виджет с хорошим CTR. Далее люди заявляли, что это очень полезный для пользователей модуль, потому что они на него кликают. Но может быть так, что модуль просто перетягивает на себя клики из других областей страницы. И если такая каннибализация имеет место, то этот модуль хороший только если клики на него лучше. При этом понятие «лучше» для каждого сайта и ситуации определяется отдельно. В заключение можно сказать следующее: локальное улучшение — это простая задача, а глобальное улучшение — гораздо сложнее.
Правило №6: избегать сложных экспериментов, действовать итеративно
Добротный и подробный план эксперимента жизненно необходим для получения хорошего результата. Сэр Р.А.Фишер однажды сказал [40]: «Консультация с аналитиком после того, как эксперимент закончился, это словно проведение посмертного обследования. Единственное, что он сможет сказать — что эксперимент мертв». Опыт подсказывает нам, что простые эксперименты являются лучшими в online-мире, и несмотря на то, что у них есть свои подводные камни [17;41], их проще понять и проверить корректность, следовательно, они более надёжны. В сложных экспериментах нет необходимости, к тому же в них могут таиться баги. Вот несколько примеров из опыта LinkedIn.
Пример: Объединенный поиск в LinkedIn
В LinkedIn запуск продукта включает в себя множество фич и компонентов. В 2013 году было проведено масштабное обновление поиска, в благодаря которому появилось автозавершение, предложение вариантов, и, самое главное — универсальный поиск по всему LinkedIn, который позволял одновременно искать среди различных категорий сервиса. В прошлом человек должен был выбрать, что именно он ищет: людей, должности или работодателей. С универсальным поиском стал достаточно умным, чтобы самому догадаться, что именно ты ищешь, и выдать релевантный результат. Но это было не всё. Изменили практически каждый элемент поисковой страницы: от левого ползунка навигации до сниппетов и кнопок. Первый эксперимент провели со всеми изменениями, собранными в одну кучу, и множеством метрик, и получили билиберду в целевых метриках. Затем долго удаляли фичи одну за другой, и обнаружили, что падение кликов и выручки произошло из-за пачки фич, не включенных в итоговую версию, а не из-за самого универсального поиска. После исправления этих фич универсальный поиск положительно повлиял на поведение пользователей и был раскачен на всю аудиторию сервиса.
Пример: Контакты в LinkedIn
Недавно LinkedIn показал широкой публике новую страницу контактов. Предполагалась, что с ней людям будет проще поддерживать связь друг с другом. Все верили, что это очень хорошая фича для пользователей. Но когда пришли результаты эксперимента, то все пришли в ужас. Эксперимент был очень сложен, поэтому было достаточно тяжело разбираться, где и что пошло не так. Прежде всего, не предполагалось участия людей из белого списка. Поэтому перед тем, как отнести пользователя к контрольной или тестовой группе, проверяли, подходит ли пользователь для участия в эксперименте. Далее, в зависимости от от выбранной группы запускалось еще два эксперимента, которые решали, какую страницу контактов показать пользователю. План эксперимента был достаточно сложен и потребовалось время, чтобы понять, что был баг в процедуре отбора пользователя. Если пользователь однажды видел новую страницу контактов, то он попадал в белый список и навсегда вычеркивался из эксперисмента. Ничего удивительного, что мы увидели растущий отток и падение вовлеченности пользователя на тестовой группе.
В offline-экспериментах сложный проект может иметь значение, потому что тестируемый объект конечен или дорог, но в online, когда мы имеем бесконечный поток пользователей, мы можем проводить сотни параллельных экспериментов, тестируя различные изменения [4;11]. Литературы по многопеременным (Mullty-Variable) тестам достаточно много, и коммерческие продукты рекламируют свою возможность проводить MV-тесты. Но мы предпочитаем однопеременные (такие как А/B/C/D) или двухпеременные тесты.
Один из аргументов в пользу однопеременных тестов — их совместимость с идеологией Agile, в которой приветствуется создание MVP [15]: вместо написания кода для сложного MVT, запускаете тест, как только готова основная фича. Вы узнаете важные вещи после того, как покажете фичу пользователю. Увидите динамику в неожиданных метриках, получите голосовую обратную связь, встретитесь с багами и т.д. Большие MV-тесты на новом коде чаще всего оказываются некорректными из-за допущенной ошибки хотя бы в одной переменной.
Мы поощряем наши команды за быструю выкатку кода и проведение экспериментов и предлагаем им форму контроля эффективности: начиная с 1 % контрольной группы с дальнейшим повышением, если не наблюдалось никаких вопиющих ухудшений в метриках. Придерживаясь Agile-методологий и не контролируя эффективность через контрольные тесты вы рискуете повторить одну из выкаток Knight Capital, которая в августе 2012 привела к потере 440 миллионов долларов и понизила стоимость Knights на 75 %.
Правило №7: Имейте достаточное количество пользователей
Методологии проведения экспериментов часто основаны на мат. ожиданиях, про которые предполагается, что они распределены нормально. Центральная предельная теорема гласит, что среднее случайной величины распределено нормально, если выборка достаточно велика. Книги по прикладной статистике часто предполагают, что будет достаточно маленького числа. Например, в статье [42] говорится, что в большинстве практических случаев, если n > 30, распределение средних можно считать нормальным несмотря на форму исходного распределения. Так как мы добиваемся статистической значимости ориентируясь на хвосты распределений, нам понадобятся гораздо большие выборки. Мы давали совет в предыдущих статьях — использовать тысячи пользователей, Neil Patel советует десятки тысяч месячных пользователей, но фактическое количество зависит от интересующей вас метрики.
Есть формула вычисления минимального размера выборки, она зависит от стандартного отклонения метрики и от чувствительности (ожидаемого эффекта на этой метрике) [16], но предполагается, что распределение средних является нормальным. Наш опыт говорит о том, что многие интересующие вас метрики будут смещенными и нижняя граница должна будет проходить слишком высоко, чтобы можно было считать распределение нормальным.
Мы пришли к тому, что для каждого варианта формула
355 * s^2 определяет минимальное количество независимых и одинаково распределенных наблюдений, необходимое для того, чтобы среднее считалось нормально распределенным. Здесь s — это степень смещенности распределения переменной, определяемая как:$$s = \frac{E (X-E (X))^3}{\Var (X)^{3/2}}$$Мы рекомендуем использовать это правило, когда смещение больше 1. Ниже приведена таблица со значениями смещений, размерами выборки и чувствительностью, которые получены в экспериментах с некоторыми метриками в Bing:
| Метрика |
Смещение |
Размер выборки |
Чувствительность |
| Revenue/User |
17,9 |
114 тыс. |
4,4 % |
| Revenue/User (capped) |
5,2 |
9,7 тыс. |
10,5 % |
| Sessions/User |
3,6 |
4,7 тыс. |
5,4 % |
| Time To Success |
2,1 |
1,55 тыс. |
12,3 % |
В нашей практике был случай, когда на одном сайте смещенность метрики «количество покупок на человека» была больше 10, а смещённость метрики «выручка с пользователя» — больше 30. Наше правило дает 95 % вероятность того, что оба конца распределения, которые обычно равны 0,025, будут на самом деле не больше 0,3 и не меньше 0,2. Это правило было взято из работы Boos и Hughes-Oliver [43]. Смещённые распределения с тяжелым хвостом очень часты в работе с веб данными, поэтому наша формула очень полезна. Из таблицы видно, что выручка на пользователя имеет коэффициент смещения 18,2, поэтому необходимо 114 тыс. пользователей для проведения достоверного эксперимента. Ниже на графике 4 видно, что если семплируем только 100 или 1000 пользователей, то точки плохо ложаться на диагональ QQ. Это говорит о смещенности распределения и поэтому 95-процентный доверительный двусторонний интервал, предполагающий нормальность, не совпадёт с реальным более чем на 5 %. Когда же мы взяли 100 000 пользователей, распределение стало очень близким к нормальному в интервале от -2 до 2.

Если метрика сильно смещена, то иногда можно как-то трансформировать её значения для уменьшения смещения, чтобы среднее сходилось к нормальному быстрее. После того, как мы ограничили метрику «доход на пользователя» десятью долларами в неделю, то увидели, что смещенность упала с 18 до 5, чувствительность значительно выросла. При равных размерах выборки ограничение удельной выручки помогает обнаружить изменения, которые на 30 % меньше, чем при использовании оригинальной метрики.
Наше правило позволяет оценить количество пользователей, необходимое для того, чтобы считать распределение средних нормальным. Если предполагается, что контрольная и тестовые группы имеют одно распределение, то никаких ценных советов мы дать не можем убедитесь только, что они имеют одинаковый размер, тогда распределение их разницы будет идеально симметричным и смещенность будет близка к 0. В этом случае наше правило не будет иметь смысла, так как оно действует при коэффициенте смещенности большем по модулю 1.
Есть более сложные вычисления, которые могут помочь снизить нижнюю границу количества пользователей [16]. А для смещенных распределений с малым количеством семплов можно использовать bootstrap [44].
Заключение
В этой статье мы рассказали про 7 правил проведения контрольных экспериментов с примерами, которые мы вынесли из своего опыта, проведя тысячи экспериментов. Первые два правила говорят нам, что даже маленькие изменения на сайте могут дать большое изменение метрики, но положительное изменение случается редко, и чаще всего движение идет за счет небольших подвижек, полученных в разных экспериментах. Если результаты эксперимента кажутся слишком хорошими, то воспользуйся правилом Twyman’а и не доверяй этому эксперименту, разберись в нем глубже, в большинстве случаев найдёте ошибку. Третье правило касается любых публикуемых экспериментов, мы научились относиться к ним осторожно, и при попытке внедрять аналогичные решения всегда проверяем результат контрольным тестом, будучи готовыми к тому, что у нас результат может отличаться. Четвертое правило — наше любимое — касается скорости. Мы провели множество экспериментов, чтобы понять взаимоотношение между скоростью, производительностью и ключевыми метриками, показали, что скорость ответа сервера — критичный показатель для нашего сервиса. Также мы показали, что скорость ключевых частей страниц важнее, чем остальных элементов (например, боковой панели). Несмотря на наше отношение, мы сомневаемся в некоторых примерах, которые привели в рамках третьего правила. Пятое правило — это эмпирическое наблюдение, которое, как мы думаем, будет уточнено в дальнейшем. Но поражает то, насколько широко это правило применимо: можно легко и сколько угодно гонять клики пользователей по разным частям страницы, но уровень покидания изменить очень трудно. Поэтому, когда делаете локальные оптимизации убедитесь, что вы не снизили ключевую метрику у другого блока. Шестое правило предлагает не планировать сложные эксперименты, а выкатывать маленькие итерации. Эта идея хорошо сочетается с современной парадигмой Agile. Седьмое правило — предоставляем нижнюю границу количества пользователей, необходимого для контрольного эксперимента со смещенным распределением. Большинство примеров, приведённых в этой статье, демонстрируются впервые. Они зиждятся на эмпирических правилах и усиливают наше убеждение, что эксперименты — необходимая вещь в разработке продукта. Мы надеемся, что эти правила помогут сообществу и стимулируют новые исследования, которые, возможно добавят новые правила.
Благодарности
Мы хотим поблагодарить наших коллег, которые провели с нами множество экспериментов, что помогло нам составить этот список из семи правил. Mujtaba Khambatti, John Psaroudakis, и Sreenivas Addagatke, были вовлечены в процесс оценки быстродействия и его анализа. Мы хотим поблагодарить за отзывы и комментарии к черновикам статьи Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, и Jonas Alves. Комментарии к последним черновикам дали Eytan Bakshy, Brooks Bell и Colin McFarland.
Литература
- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: s.n., 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf.
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation.
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010.
- Moran, Mike. Multivariate Testing in Action: Quicken Loan’s Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action.
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive.
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx.
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html.
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. s.l.: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana.
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale.
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html.
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation.
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf.
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. s.l.: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx.
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx.
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx.
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method.
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031.
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button.
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. s.l.: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. s.l.: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info:doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long.
- Ehrenberg, A. S. C. The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: s.n., 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/.
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-A-B-Test-Red-Beats-Green.aspx.
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html.
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. s.l.: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. s.l.: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold.
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload.
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692.
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index.
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882.
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. s.l.: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.
